Патент на изобретение №2226713
|
||||||||||||||||||||||||||
(54) МЕХАНИЗМ ПОИСКА С ДВУМЕРНОЙ ЛИНЕЙНО РАСШИРЯЕМОЙ ПАРАЛЛЕЛЬНОЙ АРХИТЕКТУРОЙ
(57) Реферат: Изобретение относится к поисковым системам. Технический результат заключается в расширении функциональных возможностей. Первая система обработки данных, реализующая механизм поиска с двумерной линейно-расширяемой параллельной архитектурой, содержит устройства обработки данных, которые образуют множества узлов (N), соединенных в сети, причем что первое множество узлов содержит а узлов (Nal,…,Naa) распределения, второе множество узлов содержит b узлов (Nbl,…,Nbb) поиска, третье множество узлов содержит g узлов (Ngl,…,Ngg) индексирования, при этом каждый из узлов (Nb) поиска выполнен с возможностью содержания программного обеспечения поиска, узлы (Ng) индексирования обычно выполнены с возможностью генерирования индексов i для программного обеспечения поиска и необязательно с возможностью генерирования зависящих от разделения множеств dp, k данных для узлов (Nb) поиска. Вторая система обработки дополнительно содержит четвертое множество узлов, содержащее е узлов (Ndl,…,Nde) сбора. 2 с. и 19 з.п.ф-лы, 9 ил. Текст описания в факсимильном виде (см. графическую часть). Формула изобретения 1. Система обработки данных, реализующая механизм поиска с двумерной линейно расширяемой параллельной архитектурой, для поиска совокупности текстовых документов D, причем документы могут быть разделены на ряд разделов d1, d2…,dn, совокупность документов D предварительно обрабатывается в системе фильтрации текста так, что получается предварительно обработанная совокупность Dp документов и соответствующие предварительно обработанные разделы dp1, dp2,…,dpn, при этом индекс I может быть сгенерирован из совокупности D документов так, что для каждого предыдущего предварительно обработанного раздела dp1, dp2…,dpn получается соответствующий индекс i1, i2,…,in, кроме того, поиск раздела d совокупности D документов происходит с зависящим от разделения множеством dp,k данных, содержащая устройства обработки данных, которые образуют множества узлов (N), соединенных в сети, отличающаяся тем, что первое множество узлов содержит а узлов (N 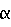 1…,Na) распределения, второе множество узлов содержит b узлов (N 1…,Na) распределения, второе множество узлов содержит b узлов (N 1,…,Nb) поиска, третье множество узлов содержит g узлов (N 1,…,Nb) поиска, третье множество узлов содержит g узлов (N 1,…,Ng) индексирования, причем узлы (N) распределения соединены в многоуровневой конфигурации в сети, узлы (N) поиска сгруппированы в 1,…,Ng) индексирования, причем узлы (N) распределения соединены в многоуровневой конфигурации в сети, узлы (N) поиска сгруппированы в  столбцов (S), которые соединены параллельно в сети между узлами (N) распределения и узлами (N) индексирования, узлы (N) распределения выполнены с возможностью обработки запросов поиска и ответов поиска, причем запросы поиска распределяются далее во все узлы (N) поиска, а ответы поиска возвращаются в узлы (N) распределения и там объединяются в конечный результат поиска, при этом каждый из узлов (N) поиска выполнен с возможностью содержания программного обеспечения поиска, узлы (N) индексирования обычно выполнены с возможностью генерирования индексов i для программного обеспечения поиска и необязательно с возможностью генерирования зависящих от разделения множеств dp,k данных для узлов (N) поиска, каждый из которых содержит модуль процессора поиска, число столбцов (S) узлов поиска расширяется на число n разделов d, таким образом, реализуя расширение объема данных, а число b/ узлов (N) поиска в каждом столбце (S) узлов поиска расширяется на оцененную или ожидаемую нагрузку графика, таким образом, реализуя расширение производительности, посредством чего в любом случае поиск совокупности D документов происходит с помощью каждого из столбцов (S) узла (N) поиска, содержащего одно из зависящих от разделения множеств dp,k данных и все узлы (N) поиска в столбце (S) узлов (N) поиска содержат одинаковые зависящие от разделения множества dp,k данных.
2. Система по п.1, отличающаяся тем, что многоуровневая конфигурация узлов (N) распределения в сети обеспечена с помощью иерархических древовидных структур.
3. Система по п.2, отличающаяся тем, что иерархические древовидные структуры являются двоичными древовидными структурами.
4. Система по п.1, отличающаяся тем, что каждый из узлов (N) поиска содержит модуль программного обеспечения (ПО) поиска.
5. Система по п.4, отличающаяся тем, что, по меньшей мере, некоторый из узлов (N) поиска содержит, по меньшей мере, один модуль (М) специализированного процессора поиска, причем каждый модуль (М) специализированного процессора поиска реализован с помощью одной или нескольких микросхем поиска по шаблону (МПШ) специализированного процессора поиска, каждая из которых выполнена с возможностью параллельной обработки ряда q запросов поиска.
6. Система по п.5, отличающаяся тем, что микросхемы (МПШ) специализированного процессора поиска предусмотрены в модулях (М) процессора поиска в у группах (G) процессоров, каждая с z микросхемами (МПШ) процессоров поиска, и соединена с памятью (ОЗУ) и выполнена с возможностью приема данных из памяти (ОЗУ), выделенной для группы (G) процессоров.
7. Система по п.1, отличающаяся тем, что увеличение числа разделов d при расширении объема данных сопровождается соответствующим увеличением числа узлов (N) распределения и необязательно также увеличением числа узлов (N) индексирования.
8. Система по п.1, отличающаяся тем, что каждый из узлов (N) поиска содержит только модуль программного обеспечения (ПО), а зависящее от разделения множество данных содержит только индекс ik.
9. Система по п.1, отличающаяся тем, что один или несколько узлов поиска содержат модуль программного обеспечения (ПО) поиска и один или несколько модулей (М) специализированного процессора поиска, а зависящее от разделения множество dp,k данных содержит как предварительно обработанный раздел dp, так и соответствующий индекс ik.
10. Система по п.1, отличающаяся тем, что каждое из отдельных множеств узлов (N, N, N) реализовано посредством одной или нескольких рабочих станций, соединенных в сети передачи данных.
11. Система обработки данных, реализующая механизм поиска с двумерной линейно расширяемой параллельной архитектурой, для поиска совокупности текстовых документов D, причем документы могут быть разделены на ряд разделов d1, d2,…,dn, совокупность документов D предварительно обрабатывается в системе фильтрации текста так, что получается предварительно обработанная совокупность Dp документов и соответствующие предварительно обработанные разделы dp1, dp2,…,dpn, при этом индекс I может быть сгенерирован из совокупности D документов так, что для каждого предыдущего предварительно обработанного раздела dp1, dp2,…,dpn, получается соответствующий индекс i1, i2, in, кроме того, поиск раздела d совокупности D документов происходит с зависящим от разделения множеством dp,k данных, содержащая устройства обработки данных, которые образуют множества узлов (N), соединенных в сети, отличающаяся тем, что первое множество узлов содержит а узлов (N1,…,Na) распределения, второе множество узлов содержит b узлов (N1,…,N2) поиска, третье множество узлов содержит g узлов (N1,…,Ng) индексирования и четвертое множество узлов содержит е узлов (N столбцов (S), которые соединены параллельно в сети между узлами (N) распределения и узлами (N) индексирования, узлы (N) распределения выполнены с возможностью обработки запросов поиска и ответов поиска, причем запросы поиска распределяются далее во все узлы (N) поиска, а ответы поиска возвращаются в узлы (N) распределения и там объединяются в конечный результат поиска, при этом каждый из узлов (N) поиска выполнен с возможностью содержания программного обеспечения поиска, узлы (N) индексирования обычно выполнены с возможностью генерирования индексов i для программного обеспечения поиска и необязательно с возможностью генерирования зависящих от разделения множеств dp,k данных для узлов (N) поиска, каждый из которых содержит модуль процессора поиска, число столбцов (S) узлов поиска расширяется на число n разделов d, таким образом, реализуя расширение объема данных, а число b/ узлов (N) поиска в каждом столбце (S) узлов поиска расширяется на оцененную или ожидаемую нагрузку графика, таким образом, реализуя расширение производительности, посредством чего в любом случае поиск совокупности D документов происходит с помощью каждого из столбцов (S) узла (N) поиска, содержащего одно из зависящих от разделения множеств dp,k данных и все узлы (N) поиска в столбце (S) узлов (N) поиска содержат одинаковые зависящие от разделения множества dp,k данных.
2. Система по п.1, отличающаяся тем, что многоуровневая конфигурация узлов (N) распределения в сети обеспечена с помощью иерархических древовидных структур.
3. Система по п.2, отличающаяся тем, что иерархические древовидные структуры являются двоичными древовидными структурами.
4. Система по п.1, отличающаяся тем, что каждый из узлов (N) поиска содержит модуль программного обеспечения (ПО) поиска.
5. Система по п.4, отличающаяся тем, что, по меньшей мере, некоторый из узлов (N) поиска содержит, по меньшей мере, один модуль (М) специализированного процессора поиска, причем каждый модуль (М) специализированного процессора поиска реализован с помощью одной или нескольких микросхем поиска по шаблону (МПШ) специализированного процессора поиска, каждая из которых выполнена с возможностью параллельной обработки ряда q запросов поиска.
6. Система по п.5, отличающаяся тем, что микросхемы (МПШ) специализированного процессора поиска предусмотрены в модулях (М) процессора поиска в у группах (G) процессоров, каждая с z микросхемами (МПШ) процессоров поиска, и соединена с памятью (ОЗУ) и выполнена с возможностью приема данных из памяти (ОЗУ), выделенной для группы (G) процессоров.
7. Система по п.1, отличающаяся тем, что увеличение числа разделов d при расширении объема данных сопровождается соответствующим увеличением числа узлов (N) распределения и необязательно также увеличением числа узлов (N) индексирования.
8. Система по п.1, отличающаяся тем, что каждый из узлов (N) поиска содержит только модуль программного обеспечения (ПО), а зависящее от разделения множество данных содержит только индекс ik.
9. Система по п.1, отличающаяся тем, что один или несколько узлов поиска содержат модуль программного обеспечения (ПО) поиска и один или несколько модулей (М) специализированного процессора поиска, а зависящее от разделения множество dp,k данных содержит как предварительно обработанный раздел dp, так и соответствующий индекс ik.
10. Система по п.1, отличающаяся тем, что каждое из отдельных множеств узлов (N, N, N) реализовано посредством одной или нескольких рабочих станций, соединенных в сети передачи данных.
11. Система обработки данных, реализующая механизм поиска с двумерной линейно расширяемой параллельной архитектурой, для поиска совокупности текстовых документов D, причем документы могут быть разделены на ряд разделов d1, d2,…,dn, совокупность документов D предварительно обрабатывается в системе фильтрации текста так, что получается предварительно обработанная совокупность Dp документов и соответствующие предварительно обработанные разделы dp1, dp2,…,dpn, при этом индекс I может быть сгенерирован из совокупности D документов так, что для каждого предыдущего предварительно обработанного раздела dp1, dp2,…,dpn, получается соответствующий индекс i1, i2, in, кроме того, поиск раздела d совокупности D документов происходит с зависящим от разделения множеством dp,k данных, содержащая устройства обработки данных, которые образуют множества узлов (N), соединенных в сети, отличающаяся тем, что первое множество узлов содержит а узлов (N1,…,Na) распределения, второе множество узлов содержит b узлов (N1,…,N2) поиска, третье множество узлов содержит g узлов (N1,…,Ng) индексирования и четвертое множество узлов содержит е узлов (N 1,…,Ne) сбора, причем узлы (N) распределения соединены в многоуровневой конфигурации в сети, узлы (N) поиска сгруппированы в столбцов (S), которые соединены параллельно в сети между узлами (N) распределения и узлами (N) индексирования, узлы (N) распределения выполнены с возможностью обработки запросов поиска и ответов поиска, причем запросы поиска распределяются далее во все узлы (N) поиска, при этом каждый из узлов (N) поиска выполнен с возможностью содержания программного обеспечения поиска, узлы (N) индексирования обычно выполнены с возможностью генерирования индексов i для программного обеспечения поиска и необязательно с возможностью генерирования зависящих от разделения множеств dp,k данных для узлов (N) поиска, каждый из которых содержит модуль процессора поиска, при этом узлы (N) сбора соединяются в многоуровневой конфигурации в сети подобно конфигурации узлов (N) распределения и выполнены с возможностью сбора ответов на запросы поиска и вывода из них конечного результата, таким образом, освобождая узлы распределения от этой задачи, число столбцов (S) узлов поиска расширяется на число n разделов d, таким образом, реализуя расширение объема данных, а число b/ узлов (N) поиска в каждом столбце (S) узлов поиска расширяется на оцененную или ожидаемую нагрузку графика, таким образом, реализуя расширение производительности, посредством чего в любом случае поиск совокупности D документов происходит с помощью каждого из столбцов (S) узла (N) поиска, содержащего одно из зависящих от разделения множеств dp,k данных и все узлы (N) поиска в столбце (S) узлов (N) поиска содержат одинаковые зависящие от разделения множества dp,k данных.
12. Система по п.11, отличающаяся тем, что многоуровневая конфигурация узлов (N) распределения и узлов (N) сбора в сети обеспечены с помощью иерархических древовидных структур.
13. Система по п.12, отличающаяся тем, что многоуровневая конфигурация узлов (N) сбора является зеркальным отображением многоуровневой конфигурации узлов (N) распределения.
14. Система по п.12, отличающаяся тем, что иерархические древовидные структуры являются двоичными древовидными структурами.
15. Система по п.11, отличающаяся тем, что каждый из узлов (N) поиска содержит модуль программного обеспечения (ПО) поиска.
16. Система по п.15, отличающаяся тем, что, по меньшей мере, некоторый из узлов (N) поиска содержит, по меньшей мере, один модуль (М) специализированного процессора поиска, причем каждый модуль (М) специализированного процессора поиска реализован с помощью одной или нескольких микросхем поиска по шаблону (МПШ) специализированного процессора поиска, каждая из которых выполнена с возможностью параллельной обработки ряда q запросов поиска.
17. Система по п.16, отличающаяся тем, что микросхемы (МПШ) специализированного процессора поиска предусмотрены в модулях (М) процессора поиска в у группах (G) процессоров, каждая с z микросхемами (МПШ) процессоров поиска, и соединена с памятью (ОЗУ) и выполнена с возможностью приема данных из памяти (ОЗУ), выделенной для группы (G) процессоров.
18. Система по п.11, отличающаяся тем, что увеличение числа разделов d при расширении объема данных сопровождается соответствующим увеличением числа узлов (N) распределения и также числа узлов (N) сбора и необязательно также увеличением числа узлов (N) индексирования.
19. Система по п.11, отличающаяся тем, что каждый из узлов (N) поиска содержит только модуль программного обеспечения (ПО), а зависящее от разделения множество данных содержит только индекс ik.
20. Система по п.11, отличающаяся тем, что один или несколько узлов поиска содержат модуль программного обеспечения (ПО) поиска и один или несколько модулей (М) специализированного процессора поиска, а зависящее от разделения множество dp,k данных содержит как предварительно обработанный раздел dp, так и соответствующий индекс ik.
21. Система по п.11, отличающаяся тем, что каждое из отдельных множеств узлов (N, N, N, N) реализовано посредством одной или нескольких рабочих станций, соединенных в сети передачи данных. 1,…,Ne) сбора, причем узлы (N) распределения соединены в многоуровневой конфигурации в сети, узлы (N) поиска сгруппированы в столбцов (S), которые соединены параллельно в сети между узлами (N) распределения и узлами (N) индексирования, узлы (N) распределения выполнены с возможностью обработки запросов поиска и ответов поиска, причем запросы поиска распределяются далее во все узлы (N) поиска, при этом каждый из узлов (N) поиска выполнен с возможностью содержания программного обеспечения поиска, узлы (N) индексирования обычно выполнены с возможностью генерирования индексов i для программного обеспечения поиска и необязательно с возможностью генерирования зависящих от разделения множеств dp,k данных для узлов (N) поиска, каждый из которых содержит модуль процессора поиска, при этом узлы (N) сбора соединяются в многоуровневой конфигурации в сети подобно конфигурации узлов (N) распределения и выполнены с возможностью сбора ответов на запросы поиска и вывода из них конечного результата, таким образом, освобождая узлы распределения от этой задачи, число столбцов (S) узлов поиска расширяется на число n разделов d, таким образом, реализуя расширение объема данных, а число b/ узлов (N) поиска в каждом столбце (S) узлов поиска расширяется на оцененную или ожидаемую нагрузку графика, таким образом, реализуя расширение производительности, посредством чего в любом случае поиск совокупности D документов происходит с помощью каждого из столбцов (S) узла (N) поиска, содержащего одно из зависящих от разделения множеств dp,k данных и все узлы (N) поиска в столбце (S) узлов (N) поиска содержат одинаковые зависящие от разделения множества dp,k данных.
12. Система по п.11, отличающаяся тем, что многоуровневая конфигурация узлов (N) распределения и узлов (N) сбора в сети обеспечены с помощью иерархических древовидных структур.
13. Система по п.12, отличающаяся тем, что многоуровневая конфигурация узлов (N) сбора является зеркальным отображением многоуровневой конфигурации узлов (N) распределения.
14. Система по п.12, отличающаяся тем, что иерархические древовидные структуры являются двоичными древовидными структурами.
15. Система по п.11, отличающаяся тем, что каждый из узлов (N) поиска содержит модуль программного обеспечения (ПО) поиска.
16. Система по п.15, отличающаяся тем, что, по меньшей мере, некоторый из узлов (N) поиска содержит, по меньшей мере, один модуль (М) специализированного процессора поиска, причем каждый модуль (М) специализированного процессора поиска реализован с помощью одной или нескольких микросхем поиска по шаблону (МПШ) специализированного процессора поиска, каждая из которых выполнена с возможностью параллельной обработки ряда q запросов поиска.
17. Система по п.16, отличающаяся тем, что микросхемы (МПШ) специализированного процессора поиска предусмотрены в модулях (М) процессора поиска в у группах (G) процессоров, каждая с z микросхемами (МПШ) процессоров поиска, и соединена с памятью (ОЗУ) и выполнена с возможностью приема данных из памяти (ОЗУ), выделенной для группы (G) процессоров.
18. Система по п.11, отличающаяся тем, что увеличение числа разделов d при расширении объема данных сопровождается соответствующим увеличением числа узлов (N) распределения и также числа узлов (N) сбора и необязательно также увеличением числа узлов (N) индексирования.
19. Система по п.11, отличающаяся тем, что каждый из узлов (N) поиска содержит только модуль программного обеспечения (ПО), а зависящее от разделения множество данных содержит только индекс ik.
20. Система по п.11, отличающаяся тем, что один или несколько узлов поиска содержат модуль программного обеспечения (ПО) поиска и один или несколько модулей (М) специализированного процессора поиска, а зависящее от разделения множество dp,k данных содержит как предварительно обработанный раздел dp, так и соответствующий индекс ik.
21. Система по п.11, отличающаяся тем, что каждое из отдельных множеств узлов (N, N, N, N) реализовано посредством одной или нескольких рабочих станций, соединенных в сети передачи данных.
РИСУНКИ
|
||||||||||||||||||||||||||