Патент на изобретение №2183034
|
||||||||||||||||||||||||||
(54) ВОКОДЕРНАЯ ИНТЕГРАЛЬНАЯ СХЕМА ПРИКЛАДНОЙ ОРИЕНТАЦИИ
(57) Реферат: Изобретение относится к обработке речевых сигналов. Его использование позволяет получить технический результат в виде сокращения количества циклов обработки. Технический результат достигается благодаря тому, что вокодер содержит цифровой процессор сигналов, предназначенный для выполнения рекурсивного вычисления свертки и для выдачи результата этой рекурсивной свертки, и минимизирующий процессор, отдельный от цифрового процессора сигналов, предназначенный для приема упомянутого результата рекурсивной свертки и для выполнения поиска минимизации в соответствии с результатом рекурсивной свертки, причем минимизирующий процессор прерывает выполнение поиска, когда удовлетворен критерий минимума. 4 с. и 11 з.п. ф-лы, 12 ил., 4 табл. 1. Область техники Изобретение относится к обработке речевых сигналов. Конкретнее настоящее изобретение относится к новым и усовершенствованным способу и устройству для воплощения вокодера в интегральной схеме прикладной ориентации. 2. Предшествующий уровень техники Передача речевых сигналов цифровыми методами стала широко распространенной, особенно в системах, обеспечивающих передачу на большие дальности и в цифровых радиотелефонах. Если речевой сигнал передается путем простой дискретизации и оцифровки, требуется скорость передачи данных порядка 64 килобит в секунду (кбит/с) для достижения качества речи обыкновенных аналоговых телефонов. Однако при использовании анализа речевых сигналов, сопровождаемого соответствующим кодированием, передачей и синтезированием в приемнике, может достигаться значительное снижение скорости передачи данных. Устройства, которые выполняют анализ речевых сигналов, кодирование в передатчике и синтезирование в приемнике, известны как вокодеры. Последние разработки стандартных цифровых сотовых телефонов и систем способствовали интенсивным разработкам вокодеров. Потребности в развитых алгоритмах вокодирования, которые используют доступный диапазон передачи более эффективно и воспроизводят исходную речь в приемнике более точно, сделали необходимым создание процессоров с большими вычислительными способностями, обеспечивающими выполнение этих более сложных алгоритмов вокодирования. Преимуществом вокодеров является долговременная и кратковременная избыточность в речевом сигнале, что требует реализации интенсивных вычислительных операций. Некоторые из этих операций включают в себя свертки длинных последовательностей, инвертирование матриц, коррелирование длинных последовательностей и т.д. Для проведения этих операций в реальном масштабе времени без внесения недопустимых задержек на кодирование и декодирование в передаче речевых сигналов требуются мощные вычислительные ресурсы. Появление процессоров цифровой обработки сигналов стало важным фактором в осуществлении вокодерных алгоритмов в реальном масштабе времени. Процессы цифровой обработки сигналов (ПЦОС) являются высокоэффективными в выполнении арифметических операций, обычных для вокодерных алгоритмов. Прогресс в ПЦОС увеличил их вычислительные способности до скорости 40 миллионов команд в секунду (Мкоманд/с) и более. Вокодерный алгоритм, используемый в иллюстративных целях, является регулируемым по скорости алгоритмом кодостимулированного линейного предсказания (КСЛП), описанным в совместно поданной патентной заявке 08/004484 от 14 января 1993 г. на “Регулируемый по скорости вокодер” заявителя настоящего изобретения. Показанная ниже таблица 1 представляет собой профиль времени выполнения для одного 20-миллисекундного речевого кадра в кодирующей части иллюстративного вокодерного алгоритма, воплощенного с использованием ПЦОС. Поскольку кодирующая часть иллюстративного вокодерного алгоритма требует значительно большей обработки, чем декодирующая часть, в таблице 1 подробно показан лишь процесс кодирования. ПЦОС, представленный данными таблицы 1, тактируется с частотой 40 МГц и выполняет арифметические операции и другие операции, занимающие один или более тактовых периодов в зависимости от операции. Первый столбец представляет основные операции иллюстративного вокодерного алгоритма. Второй столбец представляет число тактовых периодов, требуемых для совершения каждой конкретной операции вокодерного алгоритма с использованием иллюстративного ПЦОС. Третий столбец представляет долю в процентах от общей выработки для каждой конкретной операции. Иллюстративный вокодерный алгоритм требует, чтобы все операции были выполнены за 20 мс для работы иллюстративного вокодерного алгоритма в реальном масштабе времени. Это предъявляет требование к ПЦОС, выбранному для воплощения алгоритма, необходимости работать с тактовой частотой не ниже, чем требуемая для совершения обработки за 20-миллисекундный кадр. Для типичного ПЦОС, описываемого таблицей 1, это ограничивает число тактов до 800000. Как видно из таблицы 1, операции поиска основного тона и поиска кодового словаря занимают более 75% от времени обработки в кодирующей части вокодерного алгоритма. Поскольку преобладающая часть вычислительной нагрузки лежит в этих двух поисковых алгоритмах, первая цель разработки эффективной ПСИС для выполнения вокодирования состоит в уменьшении числа тактов, потребных для этих двух операций. Способ и устройство согласно настоящему изобретению существенно снижают число командных циклов, необходимых для выполнения этих поисковых операций. Настоящее изобретение обеспечивает также создание способов и устройств, которые оптимизированы для более эффективного выполнения операций, особенно значимых для вокодерных алгоритмов. Применение способов и устройств согласно настоящему изобретению не ограничивается выполнением описываемых примеров операций вокодироваяия или выполнения кодирования и декодирования. Представляется, что эти способы и устройства могут использоваться в любой системе, которая использует алгоритмы цифровой обработки сигналов, такой как эхоподавители и выравниватели каналов. Раскрытие изобретения Настоящее изобретение относится к новым способу и устройству для осуществления вокодирования. Иллюстративное выполнение настоящего изобретения, описанное здесь, характеризует собой реализацию на основе интегральной схемы прикладной ориентации регулируемого по скорости алгоритма КСЛП, подробно описанного в вышеуказанной совместно поданной патентной заявке. Признаки настоящего изобретения в равной мере приложимы к любому алгоритму кодирования с линейным предсказанием (КЛП). Настоящее изобретение обеспечивает создание архитектуры, оптимизированной для выполнения вокодерного алгоритма за уменьшенное число тактовых периодов и со сниженным потреблением мощности. Конечной целью оптимизации является минимизация потребления мощности. Уменьшение числа тактов, требуемых для выполнения алгоритма, также представляет собой задачу, решаемую изобретением, т.к. сниженная тактовая частота, как напрямую, так и косвенно, влияет на снижение потребления мощности. Прямое влияние имеет место вследствие соотношения между потреблением мощности и тактовой частотой для комплементарных металлооксидных полупроводниковых (КМОП) приборов. Косвенное воздействие имеет место вследствие квадратичного соотношения между потреблением мощности и напряжением в КМОП приборе и возможности понизить напряжение с уменьшением тактовой частоты. Эффективность вокодерной интегральной схемы прикладной ориентации может быть оценена через количество операций, которые совершаются за тактовый период. Следовательно, повышение эффективности позволит понизить общее число тактовых периодов, потребных для завершения алгоритма. Первым методом повышения эффективности при выполнении алгоритма вокодирования является использование специализированной структуры ПЦОС. ПЦОС в иллюстративном выполнении повышает пропускную способность памяти за счет использования трех элементов оперативного запоминающего устройства (ОЗУ). Каждый из трех элементов ОЗУ имеет специализированный блок генерирования адресов памяти. Это подразделение памяти на три части позволяет осуществить эффективное выполнение таких операций, как рекурсивная свертка, за счет получения операндов, вычисления результатов и запоминания результатов полностью в одном периоде. Выборка операндов, вычисление результатов и запоминание результатов являются конвейерными, так что полная рекурсивная свертка для одного результата совершается за три периода, однако новый результат вырабатывается каждый период. Подразделенная на три части память снижает требования к тактовой частоте и для других операций в вокодерном алгоритме. Эффективное выполнение рекурсивной свертки обеспечивает наиболее значительную экономию в вокодерном алгоритме. Второй метод для повышения эффективности в выполнении алгоритма вокодирования состоит в том, чтобы использовать отдельный ведомый процессор в основном ПЦОС, называемый минимизирующим процессором. Минимизирующий процессор выполняет корреляции, вычисляет среднеквадратичные ошибки (СКО) и проводит поиск по минимуму СКО по данным, подаваемым на него из ПЦОС. Минимизирующий процессор совместно с ПЦОС осуществляет интенсивные в вычислительном отношении корреляционные и минимизационные задачи. Минимизирующий процессор снабжен управляющим элементом, который осуществляет надзор за работой минимизирующего процессора и может прекратить выполнение задачи минимизации СКО при определенных условиях. Это такие условия, когда продолжающийся поиск не может дать СКО ниже текущего минимального СКО из-за математических ограничений. Способы прекращения выполнения задачи минимизации СКО определяются как режим экономии мощности минимизирующего процессора. Третий метод повышения эффективности в выполнении алгоритма вокодирования в иллюстративном выполнении состоит в предоставлении специализированного аппаратного обеспечения для эффективного выполнения блоковой нормировки. В вычислениях алгоритма вокодирования требуется поддерживать наивысший возможный в вычислениях уровень точности. Путем предоставления специализированного аппаратного обеспечения блоковая нормировка может выполняться одновременно с другими операциями вокодерного алгоритма, снижая число командных периодов, потребных для выполнения алгоритма вокодирования. Краткое описание чертежей Признаки, цели и преимущества настоящего изобретения станут понятнее из нижеследующего подробного описания, иллюстрируемого чертежами, на которых одинаковыми ссылочными позициями обозначены одни и те же элементы. Фиг.1 является блок-схемой устройства, соответствующего настоящему изобретению. Фиг. 2 является функциональной иллюстрацией работы устройства, соответствующего настоящему изобретению. Фиг. 3 является блок-схемой алгоритма осуществления кодирования в соответствии с настоящим изобретением. Фиг. 4а-d являются набором карт, иллюстрирующих распределение разрядов вокодера для различных скоростей и индицирующих число подкадров основного тона и кодового словаря, использованных для каждой скорости. Фиг.5а-d иллюстрируют блок-схемы примера выполнения ПЦОС согласно настоящему изобретению. Фиг.6а-d иллюстрируют блок-схемы примера выполнения минимизирующего процессора согласно настоящему изобретению. Фиг. 7 является иллюстрацией операции поиска основного тона, реализуемой в примере выполнения настоящего изобретения. Фиг. 8 является блок-схемой алгоритма операции поиска основного тона в примере выполнения настоящего изобретения. Фиг. 9 является иллюстрацией операции поиска кодового словаря, реализуемой в примере выполнения настоящего изобретения. Фиг.10 является блок-схемой алгоритма осуществления операции поиска кодового словаря в примере выполнения настоящего изобретения. Фиг. 11 является блок-схемой кодерного декодера, обеспечивающего поддержание одинаковыми фильтровых памятей кодера на одном конце и декодера на другом конце линии связи в операции вокодирования в примере выполнения настоящего изобретения. Фиг. 12 является блок-схемой декодера в примере выполнения настоящего изобретения. Подробное описание предпочтительных выполнении Как показано на чертежах, ПСОЦ 4 (фиг.1), иллюстрируемый на фиг.5а-d, разработан на основе разделенного на три части ОЗУ (ОЗУ А 104, ОЗУ В 122 и ОЗУ С 182), постоянного запоминающего устройства (ПЗУ)(ПЗУ Е 114) и эффективного арифметико-логического блока (АЛБ) (АЛБ 143). Строенное ОЗУ обеспечивает более эффективное использование АЛБ и расширение полосы частот ОЗУ по сравнению с тем, что может быть достигнуто единичным ОЗУ. Специализированное ПЗУ Е 114 выдает 16-разрядные постоянные. ОЗУ А 104, ОЗУ В 122 и ОЗУ С 182, а также ПЗУ Е 114 подают данные на АЛБ 143. ОЗУ С 182 принимает и выдает 32-разрядные данные от АЛБ 143 и к нему, а ОЗУ А 104 и ОЗУ В 122 принимают и выдают 16-разрядные данные, проводя вычисления с 16-разрядными операндами, и запоминают 32-разрядные результаты с высокой эффективностью. Каждое подразделение имеет специализированный блок генерирования адреса. ОЗУ А 104 имеет адресный блок А 102, ОЗУ В 122 имеет адресный блок В 120, ОЗУ С 182 имеет адресный блок С 186, а ПЗУ Е 114 имеет адресный блок Е 112. Каждый из адресных блоков выполнен на регистровых, мультиплексорных и сумматорно-вычитательных элементах (не показаны). В одном тактовом периоде ПЦОС 4 может выполнять три операции запоминания, три обновления адресов, арифметическую операцию (например, умножение-накопление-нормализацию) и перемещение данных на минимизирующий процессор 6. Командное ПЗУ I 194 хранит команды, которые управляют последовательностью исполнения в ПЦОС 4. Последовательность команд, хранимая в ПЗУ I 194, описывает функции обработки, подлежащие выполнению ПЦОС 4. ПЗУ I 194 имеет специализированный блок генерирования адреса, счетчик идентификационных указателей (ИУ) и стек 196. Блоки генерирования адреса ОЗУ или регистровые файлы – адресный блок А 102, адресный блок В 120 и адресный блок С 186 – выдают адреса или данные для соответствующих операций ОЗУ. Данные могут перемещаться из регистровых файловых элементов в другие регистровые файловые элементы внутри тех же адресных блоков либо в соответствующее ОЗУ. В описываемом примере выполнения адресный блок А 102 выдает данные через мультиплексор 106 на ОЗУ А 104, адресный блок В 120 выдает данные через мультиплексор 124 на ОЗУ 122, а адресный блок С 186 выдает данные через мультиплексор 180 на ОЗУ С 182. Регистровые файловые элементы принимают непосредственно получаемые данные (НПД) (как представлено на фиг.5а-d), данные от других регистровых файловых элементов в том же самом адресном блоке и данные от ОЗУ. Здесь и далее во всех случаях упоминание слов “непосредственно получаемые данные” будут относиться к данным, выдаваемым командным декодером 192. В описываемом примере выполнения ОЗУ А 104 выдает данные через мультиплексор 100 в адресный блок А 102, ОЗУ В 122 выдает данные через мультиплексор 118 в адресный блок В 120, а ОЗУ С 182 выдает данные через мультиплексор 184 в адресный блок С 186. Каждый адресный блок для автоматического послеоперационного приращения и послеоперационного уменьшения снабжен внтуренним сумматором-вычитателем (не показан). В примере выполнения адресный блок В 120 снабжен автоматической модульной адресацией и двумя специализированными регистровыми файловыми элементами (не показаны), используемыми в качестве указателей для прямого доступа к памяти (ПДП). Адресный блок Е 112 оптимизирован для поиска коэффициентов. Он содержит индексный регистр, который принимает непосредственно получаемые данные через мультиплексор 110, и регистр смещения, который принимает непосредственно получаемые данные через мультиплексор 110 или данные от накопителя (регистры C0REG 164 или C1 REG 166) через мультиплексоры 168 и 110. Регистр смещения для автоматического послеоперационного приращения и послеоперационного уменьшения снабжен внутренним сумматором-вычитателем (не показан). Счетчик ИУ и стек 196 содержат адресные указатели, которые выполняют функции адресации ПЗУ I 194. Адресное упорядочивание управляется командным декодером 192. Адресные данные перемещаются либо внутри счетчика ИУ и стека 196, либо принимаются как непосредственно получаемые данные. Данные могут перемещаться от ОЗУ А 104, ОЗУ В 122 или ОЗУ С 182 к регистрам внутри АЛБ 143. Данные могут также перемещаться от накопителя (регистры C0RЕG 164 или C1REG 166) к ОЗУ А 103, ОЗУ В 122 или ОЗУ С 182. Данные могут перемещаться от накопителя ОREG 162 к ОЗУ С 182. ОЗУ А 104 принимает данные от адресного блока А 102 через мультиплексор 106. ОЗУ А 104 принимает также данные от накопителя (регистры С0REG 164 или C1REG 166) через мультиплексоры 168 и 106. ОЗУ В 122 принимает данные от адресного блока В 120 через мультиплексор 124. ОЗУ В 122 принимает также данные от накопителя (регистры C0REG 164 или C1REG 166) через мультиплексоры 168 и 124. ОЗУ В 122 принимает также данные со входа DMA-UNPUT (как показано на фиг.5а-d) или от входного регистра 128 через мультиплексор 124. ОЗУ С 182 принимает данные от адресного блока С 186 через мультиплексор 180. ОЗУ С 182 принимает также данные от накопителя (регистры C0REG 164 или С1REG 166) через мультиплексоры 168 и 180. ОЗУ А 104 выдает данные на адресный блок А 102 через мультиплексор 100 и на регистр А 130 через мультиплексор 108. ОЗУ В 122 выдает данные на адресный блок В 120 через мультиплексор 118, на выход RАМВ-DOUT (как представлено на фиг.5a-d), на регистр SREG 136 через мультиплексор 126, на регистр BREG 134 через мультиплексор 116 и на регистр DREG 156 через мультиплексор 158. Регистр AREG 130 принимает непосредственно получаемые данные, данные от ПЗУ Е 114 или данные от ОЗУ А 104 через мультиплексор 108. Регистр BREG 134 принимает непосредственно получаемые данные, данные от ПЗУ Е 114 или данные от ОЗУ В 122 через мультиплексор 116. Регистр BREG 134 принимает также данные от накопителя (регистры C0REG 164 или C1REG 166) через мультиплексоры 168 и 116. Регистры C0REG 164 или C1REG 166 принимают данные через мультиплексор 148 от ОЗУ С 182, от сумматора 146, от логического элемента 144 И или от логического элемента 142 ИЛИ. Регистр SREG 136 сдвига указателя принимает непосредственно получаемые данные или данные от ОЗУ В 122 через мультиплексор 126. АЛБ 143 выполняет умножение, сложение, вычитание, умножение-накопление, умножение-сложение, умножение-вычитание, округление, приращение, очистку, инверсию знака и логические операции И, ИЛИ и НЕ. Входы к перемножителю 132, регистру AREG 130 и регистру BREG 134 стробируются (не показано), снижая потребление мощности в перемножителе 132 обеспечением того, что входные сигналы изменяются только после выполнения перемножения. АЛБ 143 снабжен двумя 36-разрядными накопителями (регистры C0REG 164 или C1REG 166) для эффективности и двумя многорегистровыми циклическими сдвигателями 140 и 150 для нормировки. Многорегистровым циклическим сдвигателем 140 и многорегистровым циклическим сдвигателем 150 выполняются сдвиги влево или вправо на величину до 16 разрядов. Указатель сдвига определяется либо прямо через непосредственно поступающие данные, либо специализированным сдвиговым индексным регистром SREG 136 через мультиплексор 149. Сдвиговый индексный регистр SREG 136 вместе с многорегистровыми циклическими сдвигателями 140 и 150, подзарядным логическим элементом 160 ИЛИ и регистром OREG 162 введены для минимизации потерь при выполнении блоковой нормировки. AЛБ 143 задает состояние на командный декодер 192, разрешая условные переходы на основании арифметических и логических состояний регистров C0REG 164 или C1REG 166. К примеру, в примере выполнения знаки для значений в регистрах C0REG 164 или C1REG 166 сравниваются для задания условного перехода по смене знака. Переход происходит, когда непосредственно получаемые данные выдаются на счетчик ИУ и стек 196. Переполнение и потеря значимости (отрицательное переполнение) накопителя обнаруживаются и насыщение выполняется автоматически посредством шестнадцатеричного значения 0X7FFFFFFF в случае переполнения и 0Х80000001 в случае потери значимости, согласно арифметике с дополнением до двух. Последовательность исполнения команд представляет собой поиск, декодирование, исполнение. Счетчиком ИУ и стеком 196 выдаются значения адресов для управления ПЗУ I 194, которое в ответ выдает команду на командный декодер 192. Командный декодер 192 в ответ на эту входную команду декодирует ее и выдает управляющие сигналы на соответствующие элементы в ПЦОС для исполнения команды. Специализированный счетчик циклов и стек 190 со счетчиком ИУ и стеком 196 обеспечивают вызовы вложенных подпрограмм с низкими непроизводительными затратами и вложенных циклов. Поиск команды блокируется во время однокомандных циклов, снижая потребление мощности. Счетчик циклов и стек 190 принимают непосредственно получаемые данные через мультиплексор 188 для выполнения циклов форсированной длины. Счетчик циклов и стек 190 принимают также данные от накопителя (регистры C0REG 164 или C1REG 166) через мультиплексоры 168 и 188 для выполнения циклов переменной длины. Статический командный кэш на 256 слов (не показан) внутри ПЗУ I 194 обеспечивает командный поиск с низкой мощностью для большинства часто исполняемых циклов и подпрограмм. Команда ОЖИДАНИЕ блокирует командный поиск и декодирование команд во время события, снижая потребление мощности. Примеры таких событий могут включать в себя передачу ПДП, временное стробирование от интерфейса 2 ИКМ или внешнее событие. На ПЦОС 4 подаются внешние данные и управление через портовый вход PORT- INPUT (как показано на фиг.5а-d), DMA-INPUT от интерфейса 2 ИКМ, а также статические проверочные разряды, используемые в командах условного перехода. Данные обеспечиваются извне посредством ПЦОС 4 через регистр CREG (как показано на фиг.5а-d, 6а-d) и выход RAMB-DOUT. ПДП между ПЦОС 4 и интерфейсом 2 ИКМ выполняется путем занятия цикла, как известно в технике. Данные от регистров C0REG 164 или C1REG 166 подаются через мультиплексор 168 вместе с сигналом OUTREG-EN (как показано на фиг.5а-d, 6а-b) от командного декодера 192. Активный сигнал OUTREG-EN означает наличие достоверных данных CREG, подаваемых на минимизирующий процессор 6. Минимизирующий процессор 6, представленный на фиг.6а-b, участвует в процедурах обработки с высокими вычислительными затратами – в поиске основного тона и в поиске кодового словаря. Для выполнения процедуры минимизации минимизирующий процессор 6 принимает последовательность взвешенных с учетом человеческого восприятия отсчетов входного речевого сигнала, набор значений усиления и набор последовательностей отсчетов синтезированной речи от ПЦОС 4. Минимизирующий процессор 6 вычисляет автокоррелацию между синтезированным речевым сигналом и входным речевым сигналом, взвешенным с учетом человеческого восприятия. В результате этой корреляционной обработки определяется относительная мера среднеквадратичной ошибки (СКО) между синтезированной речью и входной речью как функция от усиления и указателя синтезированной речи. Минимизирующий процессор 6 сообщает значения указателя и усиления, соответствующие минимальной СКО. Режим сбережения мощности обеспечивает прерывание вычисления СКО, когда дальнейшая минимизация невозможна. Минимизирующий процессор 6 осуществляет связь с ПЦОС 4 через выход CREG, порт I/О и специализированные команды ПЦОС. Работа минимизирующего процессора 6 определяется блоком 220 управления. Блок 220 управления содержит счетчик для поддержания отслеживания текущих значений указателя, регистры для сохранения оптимальных результатов поиска основного тона или поиска кодового словаря, схему генерирования адреса для обращения к ОЗУХ 212 и схему ввода-вывода. Кроме того, управляющий элемент 220 отвечает за управление сигналами выбора на мультиплексоры 224, 234, 230 и 246 и подает разрешающие сигналы на фиксаторы (“защелки”) 210, 214, 226, 228, 236, 238, 244 и 250. Блок 220 управления отслеживает также различные значения в элементах в минимизирующем процессоре 6, управляет режимами сбережения мощности, которые укорачивают поиски при некоторых заранее заданных условиях прекращения поиска, и управляет циклированием значений усиления в кольцевом буфере 259. Кроме того, блок 220 управления отвечает за выполнение операций ввода-вывода. Блок 220 управления отвечает за выдачу результатов минимизации на ПЦОС 4 (например, наилучшие период основного тона и усиление основного тона, или наилучшие указатель кодового словаря и усиление кодового словаря, определенные в соответствующих поисках) через входные порты 12. Сигнал OUTREG-EN подается на блок управления 220 для индикации того, что данные на входе в фиксатор 210 достоверны и присутствуют на входе CREG сигнала с выхода накопителя. В ответ на это блок 220 управления генерирует сигнал разрешения и подает сигнал разрешения на фиксатор 210 для приема данных. Сигналы OUTPORT – EN (как представлено на фиг.5а-d, 6а-b) и PORT-ADD (как представлено на фиг.5а-d, 6а-b) подаются на блок управления 220 от ПЦОС 4. Сигнал PORT-ADD обеспечивает адрес на минимизирующий процессор 6. Минимизирующий процессор 6 принимает данные с СREG, когда значение PORT-ADD определяет данные для минимизирующего процессора 6, a OUTPORT-EN индицирует достоверность значения PORT-ADD. Сигналы управления и данные подаются на минимизирующий процессор 6, как описано выше. На фиг.1 представлена блок-схема возможной структуры согласно настоящему изобретению. Интерфейс 2 ИКМ принимает от кодека (не показан) и передает на него данные речевых отсчетов импульсно-кодовой модуляции (ИКМ)(РСМ), которые в иллюстративном выполнении присутствуют в виде данных компандированных по  -закону или по А-закону отсчетов или данных линейных отсчетов. Интерфейс 2 ИКМ принимает информацию тактирования от синхрогенератора 10 и принимает данные и управляющую информацию от микропроцессорного интерфейса 8.
Интерфейс 2 ИКМ подает на ПЦОС 4 ИКМ-данные речевых отсчетов, которые он принял от кодека (не показан) для кодирования. Интерфейс 2 ИКМ принимает от ПЦОС 4 ИКМ-данные речевых отсчетов, которые затем подаются на кодек (не показан). ИКМ-данные передаются между ПЦОС 4 и интерфейсом 2 ИКМ через ПДП.
Интерфейс 2 ИКМ подает информацию тактирования на синхрогенератор 10 на основании тактирования отсчетов, принятых от кодека (не показан).
ПЦОС подает данные и управляющую инфорацию на свой сопроцессор, минимизирующий процессор 6. ПЦОС 4 принимает также информацию тактирования от синхрогенератора 10. ПЦОС 4 способен также выдавать внешнюю адресную информацию и принимать внешние команды и данные.
Минимизирующий процессор 6 принимает информацию тактирования от синхрогенератора 10 и принимает данные и сигналы управления от ПЦОС 4. Минимизирующий процессор 6 выдает результаты минимизирующих процедур на ПЦОС 4 через входные порты 12.
Синхрогенератор 10 выдает информацию тактирования на все другие блоки. Синхрогенератор 10 принимает внешние синхросигналы и принимает информацию тактирования от микропроцессорного интерфейса 8 и от интерфейса 2 ИКМ.
Интерфейс 16 действующей группы встроенной проверки (ДГВП) обеспечивает способность проверки функционирования интегральной схемы прикладной ориентации. Интерфейс 16 ДГВП принимает внешние данные и управляющую информацию и выдает внешние данные.
Выходные порты 14 принимают данные от ПЦОС и подают эти данные на микропроцессорный интерфейс 8 и могут также выдавать данные на внешние устройства (не показаны).
Входные порты 12 принимают данные от микропроцессорного интерфейса 8 и от минимизирующего процессора 6 и подают эти данные на ПЦОС 4. Входные порты 12 могут также принимать внешние данные от внешних устройств (не показаны) и подавать эти данные на микропроцессорный интерфейс 8.
Микропроцессорный интерфейс 8 принимает от микропроцессора (не показан) и выдает на него данные и управляющую информацию. Эта информация подается на другие блоки.
В иллюстративном выполнении настоящего изобретения вокодерная интегральная схема прикладной ориентации (ИСПО) выполняет регулируемый по скорости алгоритм КСЛП, который детально описан в совместно поданной патентной заявке 08/004484, от 14 января 1993 года на “Регулируемый по скорости вокодер” заявителя настоящего изобретения.
На фиг.2 представлены общие функции, выполняемые в ИСПО. Согласно фиг.2, подлежащие кодированию выборки подаются на вокодерную ИСПО через интерфейс 2 ИКМ от кодека (не показан). Эти выборки подаются затем на элемент 32 декомпандирования, который преобразует выборки, компандированные по -закону или по А-закону, в линейные выборки. Выборки, выдаваемые в линейном формате, проходят через элемент 32 декомпандирования без изменения. Линейные выборки подаются на передающий элемент 34 аудио-обработки, который функционально содержит управляемый голосом переключатель (УГП) 36, аудио-выравнивающий элемент 38, кодирующий элемент 40 QCELP и двухтональный многочастотный (ДТМЧ) детектирующий элемент 41. Передающий элемент 34 аудио-обработки подает затем кодированные речевые пакеты через микропроцессорный интерфейс 42 на микропроцессор (не показан), внешний относительно ИСПО.
Кодированные речевые пакеты подаются микропроцессором (не показан) через микропроцессорный интерфейс 42 на приемный элемент 44 аудио-обработки, где они декодируются в выборки речевого сигнала. Приемный элемент 44 аудио-обработки функционально содержит декодирующий элемент 46 QCELP, аудио-выравниватель 48 и ДТМЧ генерирующий элемент 47. Декодированные выборки подаются на элемент 50 компандирования, который преобразует линейные выборки в формат -закона или А-закона или пропускает линейные выборки без изменения на интерфейс 30 ИКМ. ИСПО подает декодированные выборки через интерфейс 30 ИКМ на кодек (не показан), внешний относительно ИСПО.
Операция декомпандирования, представленная на фиг.2 как элемент 32 декомпандирования, и операция компандирования, представленная на фиг.2 как элемент 50 компандирования, выполняются в ПЦОС 4, представленном на фиг.5a-d. Передающие операции аудио-обработки, представленные на фиг.2 как передающий элемент 34 аудио-обработки, выполняются в ПЦОС 4 и минимизирующем процессоре 6, представленном на фиг.6а-b. Приемные операции аудио-обработки, представленные на фиг.2 как приемный элемент 44 аудио-обработки, выполняются в ПЦОС 4, представленном на фиг.5a-d.
В иллюстративном выполнении выборки, поступающие от кодека (не показан) в формате 8-разрядного -закона или 8-разрядного А-закона, преобразуются в 14-разрядный линейный формат. Соотношение между -законом и линейным показано в уравнении 1: -закону или по А-закону отсчетов или данных линейных отсчетов. Интерфейс 2 ИКМ принимает информацию тактирования от синхрогенератора 10 и принимает данные и управляющую информацию от микропроцессорного интерфейса 8.
Интерфейс 2 ИКМ подает на ПЦОС 4 ИКМ-данные речевых отсчетов, которые он принял от кодека (не показан) для кодирования. Интерфейс 2 ИКМ принимает от ПЦОС 4 ИКМ-данные речевых отсчетов, которые затем подаются на кодек (не показан). ИКМ-данные передаются между ПЦОС 4 и интерфейсом 2 ИКМ через ПДП.
Интерфейс 2 ИКМ подает информацию тактирования на синхрогенератор 10 на основании тактирования отсчетов, принятых от кодека (не показан).
ПЦОС подает данные и управляющую инфорацию на свой сопроцессор, минимизирующий процессор 6. ПЦОС 4 принимает также информацию тактирования от синхрогенератора 10. ПЦОС 4 способен также выдавать внешнюю адресную информацию и принимать внешние команды и данные.
Минимизирующий процессор 6 принимает информацию тактирования от синхрогенератора 10 и принимает данные и сигналы управления от ПЦОС 4. Минимизирующий процессор 6 выдает результаты минимизирующих процедур на ПЦОС 4 через входные порты 12.
Синхрогенератор 10 выдает информацию тактирования на все другие блоки. Синхрогенератор 10 принимает внешние синхросигналы и принимает информацию тактирования от микропроцессорного интерфейса 8 и от интерфейса 2 ИКМ.
Интерфейс 16 действующей группы встроенной проверки (ДГВП) обеспечивает способность проверки функционирования интегральной схемы прикладной ориентации. Интерфейс 16 ДГВП принимает внешние данные и управляющую информацию и выдает внешние данные.
Выходные порты 14 принимают данные от ПЦОС и подают эти данные на микропроцессорный интерфейс 8 и могут также выдавать данные на внешние устройства (не показаны).
Входные порты 12 принимают данные от микропроцессорного интерфейса 8 и от минимизирующего процессора 6 и подают эти данные на ПЦОС 4. Входные порты 12 могут также принимать внешние данные от внешних устройств (не показаны) и подавать эти данные на микропроцессорный интерфейс 8.
Микропроцессорный интерфейс 8 принимает от микропроцессора (не показан) и выдает на него данные и управляющую информацию. Эта информация подается на другие блоки.
В иллюстративном выполнении настоящего изобретения вокодерная интегральная схема прикладной ориентации (ИСПО) выполняет регулируемый по скорости алгоритм КСЛП, который детально описан в совместно поданной патентной заявке 08/004484, от 14 января 1993 года на “Регулируемый по скорости вокодер” заявителя настоящего изобретения.
На фиг.2 представлены общие функции, выполняемые в ИСПО. Согласно фиг.2, подлежащие кодированию выборки подаются на вокодерную ИСПО через интерфейс 2 ИКМ от кодека (не показан). Эти выборки подаются затем на элемент 32 декомпандирования, который преобразует выборки, компандированные по -закону или по А-закону, в линейные выборки. Выборки, выдаваемые в линейном формате, проходят через элемент 32 декомпандирования без изменения. Линейные выборки подаются на передающий элемент 34 аудио-обработки, который функционально содержит управляемый голосом переключатель (УГП) 36, аудио-выравнивающий элемент 38, кодирующий элемент 40 QCELP и двухтональный многочастотный (ДТМЧ) детектирующий элемент 41. Передающий элемент 34 аудио-обработки подает затем кодированные речевые пакеты через микропроцессорный интерфейс 42 на микропроцессор (не показан), внешний относительно ИСПО.
Кодированные речевые пакеты подаются микропроцессором (не показан) через микропроцессорный интерфейс 42 на приемный элемент 44 аудио-обработки, где они декодируются в выборки речевого сигнала. Приемный элемент 44 аудио-обработки функционально содержит декодирующий элемент 46 QCELP, аудио-выравниватель 48 и ДТМЧ генерирующий элемент 47. Декодированные выборки подаются на элемент 50 компандирования, который преобразует линейные выборки в формат -закона или А-закона или пропускает линейные выборки без изменения на интерфейс 30 ИКМ. ИСПО подает декодированные выборки через интерфейс 30 ИКМ на кодек (не показан), внешний относительно ИСПО.
Операция декомпандирования, представленная на фиг.2 как элемент 32 декомпандирования, и операция компандирования, представленная на фиг.2 как элемент 50 компандирования, выполняются в ПЦОС 4, представленном на фиг.5a-d. Передающие операции аудио-обработки, представленные на фиг.2 как передающий элемент 34 аудио-обработки, выполняются в ПЦОС 4 и минимизирующем процессоре 6, представленном на фиг.6а-b. Приемные операции аудио-обработки, представленные на фиг.2 как приемный элемент 44 аудио-обработки, выполняются в ПЦОС 4, представленном на фиг.5a-d.
В иллюстративном выполнении выборки, поступающие от кодека (не показан) в формате 8-разрядного -закона или 8-разрядного А-закона, преобразуются в 14-разрядный линейный формат. Соотношение между -законом и линейным показано в уравнении 1:2Y=-1S(33+2M)2N-33, (1) где Y есть линейное значение (от -4015,5 до 4015,5), N является показателем экспоненты (от 0 до 7), М есть величина значения (от 0 до 15), а S есть знак (0 для положительных, 1 для отрицательных). Соотношение между А-законом и линейным показано в уравнениях 2 и 3: 2Y=-1S(1+2М)22Y для N=0, (2) 2Y=-1S(33+2М)2N для N=1,..,7, (3) где Y есть линейное значение (от -4032 до 4032), N, М и S те же, что и вышеуказанные. Согласно фиг.5а-d, выборки, подаваемые через интерфейс 30 ИКМ на фиг.2, преобразуются в линейный формат посредством просмотровой таблицы в ПЗУ Е 114. В предпочтительном выполнении для выполнения преобразования используются просмотровые таблицы перевода -закона в линейный и А-закона в линейный половинного размера 128х14. Предпочтительное выполнение имеет преимущество полномерной таблицы преобразования со свойствами, показанными в уравнении 4:ПЗУ(n+128)=-ПЗУ(n) 0 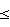 n127. (4) n127. (4)Перед вычислением коэффициентов автокорреляции и коэффициентов КЛП требуется удаление любой составляющей постоянного тока из входного речевого сигнала. Операция блокирования постоянной составляющей выполняется в ПЦОС 4 вычитанием отфильтрованного по низкой частоте среднего значения речевых отсчетов – смещения по постоянному току – из каждого входного отсчета в текущем окне. Т.е. смещение по постоянному току для текущего кадра является взвешенным средним среднего значения отсчетов текущего и предыдущего кадра. Вычисление смещения по постоянному току показано в уравнении 5: Смещение=а(среднее(предыд.кадра))+(1-а)среднее(текущ.кадра), (5) где а=0,75 в примере выполнения. Низкочастотная фильтрация используется для предотвращения больших разрывов на границах кадров. Эта операция выполняется в ПЦОС 4 запоминанием среднего значения выборки для текущего кадра и для предыдущего кадра в одном из элементов ОЗУ (например, ОЗУ А 104, ОЗУ В 122 или ОЗУ С 182) с коэффициентом a интерполяции, выдаваемым ПЗУ Е 114. Сложение выполняется сумматором 146, а умножение – перемножителем 132. Функция блокирования постоянной составляющей может разрешаться или отменяться под микропроцессорным управлением. Свободный от постоянной составляющей входной речевой сигнал S(n) обрабатывается по методу окна для снижения воздействий от нарезания речевой последовательности на кадры фиксированной длины. В иллюстративном выполнении используется функция хэммингового окна. Для кадра длиной LA=160 обработанная по методу окна речь SW(n) вычисляется, как показано в уравнении 6: SW(n)=S(n+60)WH(n), 0 nLA-1, (6)где хэммингово окно определяется в уравнении 7 и 8: WH(n)=0,54-0,46cos[2  n/(LA-1)], n/(LA-1)],0 nLA-1 = 0 для всех прочих значений. (8)В предпочтительном выполнении, поскольку WH(n) является четно-симметричной функцией, просмотровая таблица из 80 коэффициентов – половина коэффициентов хэммингового окна хранится в ПЗУ Е 114. Обработка по методу окна может тогда выполняться выдачей оконных коэффициентов H(n) из ПЗУ Е 114 согласно адресному значению, выдаваемому адресным блоком Е 112 через мультиплексор 108 на регистр AREG 130. Регистр AREG 130 подает эти данные на первый вход перемножителя 132. Выборка речевого сигнала S (n+60) выдается ОЗУ В 122 на регистр BREG 134. Регистр BREG 134 подает это значение на второй вход перемножителя 132. Выходным сигналом перемножителя 132 является обработанная по методу окна выборка речевого сигнала, который выдается на регистр C0REG 164, а затем подается на ОЗУ С 182 через мультиплексор 168. Процедура блоковой нормировки состоит из двух функциональных частей: определения коэффициента нормировки и нормировки предназначенных для этого данных. В рассматриваемом примере выполнения данные запоминаются в записи с дополнением до двух. Обработанные по методу окна выборки обсчитываются согласно вышеприведенному уравнению 7. По команде нормировки DETNORM из ПЗУ I 194, результирующее значение обработанной по методу окна выборки, генерируемое в регистре С0REG 164, подлежит следующей процедуре. Если значение в регистре C0REG 164 отрицательно, то инвертирующий элемент 152 инвертирует двоичные цифры числа и пропускает значение с инвертированными разрядами на первый вход сумматора 146. На второй вход сумматора 146 подается нуль через мультиплексоры 137 и 138. Сумматор 146 затем добавляет через свой вход переноса (не показан) единицу к значению с инвертированными разрядами. Если значение в регистре C0REG 164 положительно, это значение пропускается через мультиплексоры 168 и 154, инвертирующий элемент 152 и сумматор 146 в своем исходном виде. Назначение этой процедуры состоит в том, чтобы вычислить абсолютное значение из регистра C0REG 164. Затем абсолютное значение подается на первый вход поразрядного логического элемента 160 ИЛИ. На второй вход поразрядного логического элемента 160 ИЛИ подается сигнал с регистра OREG 162. Вышеописанное вычисление абсолютного значения показано в уравнениях 8а-с: OREG новое = (абс.знач.(C0REG)) или (OREG)старое, (8а) где абс.знач.(C0REG)=C0REG, С0REG 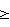 0, (8b) 0, (8b)=-C0REG, C0REG<0. (8c) Описанная в уравнениях 8а-с операция может просто выполняться на регистре C1REG 166 с использованием команды DETNORM, если предназначенные для нормировки данные находятся в регистре C1REG 166. Регистр OREG 162 очищается в начале операции нормировки. Эта процедура повторяется для всех обработанных по методу окна отсчетов (предназначенных данных) так, что в конце операции запомненное в регистре OREG 162 значение представляет результат выполнения поразрядной операции логическое ИЛИ от абсолютных значений всех обработанных по методу окна выборок. Из самого старшего разряда, помещенного в регистр OREG 162, определяется масштабирующий коэффициент, поскольку значение в регистре ОREG 162 больше или равно наибольшей величине в блоке обработанных по методу окна выборок. Значение в регистре ОREG 162 передается через мультиплексор 168 в ОЗУ С 182. Это значение затем загружается в регистр C0REG 164. Коэффициент нормировки определяется путем подсчета числа левых и правых сдвигов значения в регистре C0REG 164, требуемых для того, чтобы сдвиги обработанных по методу окна данных на эту величину обеспечили значение с желательной пиковой величиной для последующей операции. Этот масштабирующий коэффициент известен также как коэффициент нормировки. Поскольку нормировка выполняется через сдвиги, коэффициент нормировки представляет собой степень числа 2. Для поддержания обработанных по методу окна выборок с наибольшей возможной точностью предназначенные для нормировки значения умножаются на коэффициент нормировки, так что наибольшая величина занимает максимальное число разрядов, предназначенных для последующей операции. Поскольку коэффициент нормировки является степенью числа 2, нормировка предназначенных для этого данных может быть достигнута простым выполнением некоторого числа сдвигов, как определено коэффициентом нормировки. Коэффициент нормировки подается ОЗУ В 122 через мультиплексор 126 в регистр SREG 136. Обработанные по методу окна выборки подаются затем из ОЗУ С 182 через мультипексор 158 в регистр DREG 156. Регистр DREG 156 передает затем эти значения через мультиплексор 154 и заблокированный инвертор 152 в многорегистровый циклический сдвигатель 150, где они сдвигаются согласно коэффициенту нормировки, поданному в многорегистровый циклический сдвигатель 150 регистром SREG 136 через мультиплексор 149. Выход многорегистрового циклического сдвигателя 150 пропускается через заблокированный элемент 146 сложения и мультиплексор 148 на регистр C0REG 164. Нормализованные обработанные по методу окна выборки проходят затем через мультиплексор 168 и подаются через мультиплексоры 124 и 180 в ОЗУ В 122 и в ОЗУ С 182 соответственно. В результате в ОЗУ появляются две копии нормированных обработанных по методу окна выборок, что обеспечивает осуществление последующих вычислений коэффициентов автокорреляции с большей эффективностью. Вычисление Р+1 коэффициентов R(k) автокорреляции выполняется согласно уравнению (9):  где Р есть порядок формантного предсказывающего фильтра в кодере. В данном примере выполнения Р=10. Нормированные обработанные по методу окна выборки SW(n) подаются ОЗУ В 122 через мультиплексор 116 и регистр BREG 134 на первый вход перемножителя 132. Задержанные варианты нормированных обработанных по методу окна выборок W(m+k) подаются ОЗУ С 182 через мультиплексор 148 и регистр C1REG 166, ОЗУ А 104 и регистр АREG 130 на второй вход перемножителя 132. Каждое значение R>(k) есть накопление LA-k значений. Для первой итерации каждого R(k), выходной сигнал перемножителя 132 подается на накопитель С0REG 164 через мультиплексор 138 и многорегистровый циклический сдвигатель 140, на первый вход сумматора 146. Мультиплексор 154 подает нуль на второй вход сумматора через заблокированный многорегистровый циклический сдвигатель 150. Для последующих итераций выходной сигнал перемножителя 132 подается на первый вход сумматора 146 через мультиплексор 138 и многорегистровый циклический сдвигатель 140. На второй вход сумматора 146 подается выходной сигнал регистра C0REG 164 через мультиплексоры 168 и 154, заблокированный инвертирующий элемент 152 и заблокированный многорегистровый циклический сдвигатель 150. Эта процедура повторяется для каждого значения R(k). Ни один из коэффициентов автокорреляции не превосходит R(0). В данном примере выполнения после вычисления R(0) определяется его коэффициент нормировки. Этот коэффициент нормировки используется затем для уже вычисленного R(0) и для остальных коэффициентов автокорреляции по мере их вычисления. Нормировка коэффициентов автокорреляции на этой стадии максимизирует точность для последующего вычисления коэффициентов КЛП. Теперь перейдем к блоку 62 на фиг.3, в котором вычисляются коэффициенты КЛП для устранения кратковременной корреляции (избыточности) в выборках речевого сигнала. Формативный предсказывающий фильтр порядка Р имеет передаточную функцию A(z), описываемую уравнением 10:  Каждый коэффициент КЛП ai, вычисляется из значений автокорреляции нормированного обработанного по методу окна входного речевого сигнала. В примере выполнения для вычисления коэффициентов КЛП используется эффективный итеративный способ, названный “реккурентный способ Дурбина” (см. Rabiner Z. R. and Schafer R.W. “Digital Processing of Speech Signals”, Prentice-Hall, 1978). Этот итеративный способ описывается уравнениями 11-17: E(0)=R(0), i=1 (11)  ai (i) = ki, (13) aj (i) = aj (i-1)-kiai-j (i-1), 1 ji-1, (14)E(i) = (1-ki 2) E(i-1). (15) Если i< P (16), то увеличить i и продолжить с уравнения (12). Значения последних коэффициентов КЛП: a’j = a(p) j, 1 jp. (17)Итеративный алгоритм Дурбина работает, только когда входной сигнал имеет нулевое среднее значение, требуя, чтобы любое смещение по постоянной составляющей было удалено до того, как выполняются вычисления автокорреляции, как рассмотрено ранее. В данном примере выполнения используется расширение полосы частот в 15 Гц для гарантии стабильности формантного предсказывающего фильтра. Это может быть сделано масштабированием полюсов формантного синтезирующего фильтра радиально внутрь. Расширение полосы частот достигается масштабированием коэффициентов КЛП согласно уравнению 18:  где  = 0,9883 в иллюстративном выполнении. 10 коэффициентов i расширения полосы частот для 1iP запомнены в просмотровой таблице, имеющейся в ПЗУ Е 114. Функции блока 62 выполняются в ПЦОС 4.
Теперь перейдем к блоку 64 на фиг.3, в котором определяется скорость кодирования для текущего кадра речевых данных. Решение по скорости основано на мере голосовой активности в каждом кадре. Голосовая активность, в свою очередь, измеряется согласно кадровой энергии R(0), описанной ранее. Для определения скорости кодирования для кадра i кадровая энергия сравнивается с тремя порогами, определяемыми уравнениями 19-21: = 0,9883 в иллюстративном выполнении. 10 коэффициентов i расширения полосы частот для 1iP запомнены в просмотровой таблице, имеющейся в ПЗУ Е 114. Функции блока 62 выполняются в ПЦОС 4.
Теперь перейдем к блоку 64 на фиг.3, в котором определяется скорость кодирования для текущего кадра речевых данных. Решение по скорости основано на мере голосовой активности в каждом кадре. Голосовая активность, в свою очередь, измеряется согласно кадровой энергии R(0), описанной ранее. Для определения скорости кодирования для кадра i кадровая энергия сравнивается с тремя порогами, определяемыми уравнениями 19-21:T1(Bi) = -(5,544613  10-6)Bi 2 + (4,047152) Bi + 362, (19) 10-6)Bi 2 + (4,047152) Bi + 362, (19)T2(Bi) = -(1,529733 10-6)Bi 2 + (8,750045) Bi + 1136, (20)T3(Bi) = -(3,957050 10-6)Bi 2 + (18,899622) Bi + 3347, (21)где уровень вi фонового шума для кадра i обновляется на каждом кадре, как описано в уравнении 22: Bi = min[Ri-1 (O), 160000, max[1,005478 Bi-1, Bi-1+1]] Скорость будет составлять одну восьмую (от номинала), если кадровая энергия ниже всех трех порогов, одну четверть, если кадровая энергия находится в пределах между Т1(Вi) и Т2(Вi), половину, если кадровая энергия находится между T2(Вi) и Т3(Вi), и полное значение, если кадровая энергия выше Т3(Вi). За исключением случая, когда задается конкретное значение скорости микропроцессором (не показан) через микропроцессорный интерфейс 8, скорость выдачи данных может подниматься до любой величины, но не может опускаться более, чем на одну ступень за кадр (т.е. от половины до четверти). В ПЦОС 4 коэффициенты, связанные с порогами, выбираются в просмотровой таблице в ПЗУ Е 114. Алгоритм дробной скорости также имеет место и в предпочтительном выполнении, позволяя ограничивать среднюю скорость микропроцессором (не показан) через микропроцессорный интерфейс 8. При данном коэффициенте S ограничения скорости максимальная средняя скорость вокодера ограничена величиной (2S+1)/[2(S+1)] путем ограничения числа следующих друг за другом кадров с полной скоростью. Функции блока 64 выполняются в ПЦОС 4. Теперь перейдем к блоку 66 на фиг.3, в котором коэффициенты КЛП с расширенной полосой частот преобразуются в частоты линейных спектральных пар (ЛСП) (см. Soong and Juang “Zine Spectrum Pair (ZSP) and Speech Data Compression, ” ICASSP, 1984). Показано, что частоты ЛСП проявляют значительно лучшие свойства для передачи и хранения и могут кодироваться более эффективно, чем коэффициенты КЛП. Частоты ЛСП, представляющие десять коэффициентов КЛП, являются десятью корнями многочленов, показанных в уравнениях 23 и 24:   где Pi и q’i для 1 i5 вычисляются в ПЦОС 4 согласно уравнениям 25-27:P’o = q’o =1, (25) P’i = -ai-a11-i -P’i-1 1 i5, (26)q’i = -ai-a11-i +q’i-1 1 i5. (27)Корни P  ( ( ) находятся в предположении, что в пределах каждых /32 радиан имеется не более одного корня. P() оценивается на каждых /32 радиан величиной от 0 до радиан. Существование корня на каждом интервале /32 радиан выражается в смене знака функции P() на интервале.
Если корень найден, выполняется двоичный поиск для изолирования корня в области размером /256. Двоичный поиск включает в себя оценку P() в центре текущей области для определения того, какая половина области содержит корень. Текущая область затем обужается до половины области, в которой оказался корень. Этот процесс продолжается до тех пор, пока корень не будет изолирован в области размером /256. Затем выполняется линейная интерполяция для оценки положения корня в области /256 радиан.
Свойство упорядоченности частот ЛСП гарантирует, что между каждой парой корней P() существует один корень Q(). Пятый корень Q() находится между пятым корнем P() и точкой радиан. Вышеописанный двоичный поиск выполняется между каждой парой корней P() и между пятым корнем P() и точкой радиан для определения корней Q(). ) находятся в предположении, что в пределах каждых /32 радиан имеется не более одного корня. P() оценивается на каждых /32 радиан величиной от 0 до радиан. Существование корня на каждом интервале /32 радиан выражается в смене знака функции P() на интервале.
Если корень найден, выполняется двоичный поиск для изолирования корня в области размером /256. Двоичный поиск включает в себя оценку P() в центре текущей области для определения того, какая половина области содержит корень. Текущая область затем обужается до половины области, в которой оказался корень. Этот процесс продолжается до тех пор, пока корень не будет изолирован в области размером /256. Затем выполняется линейная интерполяция для оценки положения корня в области /256 радиан.
Свойство упорядоченности частот ЛСП гарантирует, что между каждой парой корней P() существует один корень Q(). Пятый корень Q() находится между пятым корнем P() и точкой радиан. Вышеописанный двоичный поиск выполняется между каждой парой корней P() и между пятым корнем P() и точкой радиан для определения корней Q().Поскольку двоичный поиск продолжается, пока местоположение корня не будет изолировано в пределах области размером /256, требуется 256 значений косинуса, равномерно размещенных между 0 и точкой радиан. Значения косинуса хранятся в просмотровой таблице в ПЗУ Е 114. Для нахождения корней P() и Q() требуется максимально 48 и 30 оценок функций соответственно. Эти оценки функций являются наиболее напряженной в вычислительном отношении частью в преобразовании коэффициентов КЛП в частоты ЛСП. Функции блока 66 выполняются в ПЦОС 4.
Перейдем теперь к блоку 68 на фиг.3, который выполняет квантование частот ЛСП. Каждая из частот ЛСП сосредоточена около связанного с ней значения смещения. Перед квантованием это смещение вычитается из каждой связанной частоты ЛСП для снижения числа разрядов, требуемых при квантовании. Это смещение вычисляется, как показано в уравнении 28: После того, как смещение вычтено из частоты ЛСП, эта частота ЛСП квантуется с использованием квантователя дифференциальной импульсно-кодовой модуляции (ДИКМ). Квантователь ДИКМ используется из-за того, что частоты ЛСП изменяются во времени медленно и квантование изменений в частотах ЛСП снижает число разрядов, потребное для квантования, по сравнению с тем, что потребовалось бы для прямого квантования частот ЛСП. В ПЦОС 4 значения смещений частот ЛСП хранятся в просмотровой таблице в ПЗУ Е 114. Используемое число разрядов квантования и размер шага квантования являются функциями того, какая из 10 частот ЛСП квантуется, а также функциями скорости кодирования. Число разрядов квантования и размер шага квантования хранятся в просмотровой таблице в ПЗУ Е 114 для каждой частоты ЛСП на каждой скорости кодирования. Просмотровая таблица, описанная выше, показана в таблице 2. Например, частота ЛСП 1 на полной скорости квантуется с использованием 4 разрядов и с размером шага 0,025.
После квантования и интерполяции выполняется проверка, чтобы убедиться, что формантный фильтр будет устойчивым после того, как учтены эффекты квантования. Частоты ЛСП должны разделяться промежутками по меньшей мере 80 Гц, чтобы гарантировать стабильность результирующего формантного фильтра. Если какая-либо из частот ЛСП отнесена от соседней частоты ЛСП меньше, чем на 80 Гц, то необходимо выполнить расширение полосы частот. Функции блока 68 выполняются в ПЦОС 4.
Теперь перейдем к блоку 70 на фиг.3, который выполняет низкочастотную фильтрацию частот ЛСП для снижения эффектов квантования, как показано в уравнении 29: где в данном примере выполнения SМ=0 для полной скорости, SМ=0,125 для половинной скорости. Для скорости в одну четверть и одну восьмую, если число следующих друг за другом кадров со скоростью одна четверть и одна восьмая меньше 10, SМ=0,125 и для прочих случаев SМ=0,9. Частоты ЛСП интерполируются для каждого подкадра основного тона. Интерполированные частоты ЛСП для подкадра основного тона используются для соответствующих пар подкадров кодового словаря, за исключением скорости в одну восьмую. Частоты ЛСП интерполируются согласно уравнению 30:  где веса a хранятся в просмотровой таблице в ПЗУ Е 114 для каждого подкадра основного тона и подкадра кодового словаря.
Вышеописанная просмотровая таблица показана в таблице 3. Например, a для полной скорости составляет 0,75 для подкадра 1 основного тона и подкадров 1 и 2 кодового словаря.
Интерполированные частоты ЛСП преобразуются обратно в коэффициенты КЛП для использования в поисках основного тона и по кодовому словарю. Коэффициенты КЛП вычисляются из РA(z) и QA(z), как показано в уравнениях 31-33:A(z) = [PA(z) + QA(z)]/2, (31) где   В иллюстративном выполнении в ПЦОС 4 оценивается расширение рядов Тэйлора для вычисления значений косинуса в A(z) и QA(z). Расширение рядов Тэйлора обеспечивает более точные значения косинусов, чем используемые в ранее описанном поиске корней. Значения РA(z) и QA(z) вычисляются в ПЦОС 4 путем выполнения свертки квадратичных многочленов, как показано в уравнениях 32-33. Функции блока 70 выполняются в ПЦОС 4. Рассмотрим теперь блок 72 на фиг.3, который выполняет полный анализ посредством синтезной операции поиска основного тона. Исчерпывающая поисковая процедура представлена циклом, образованным блоками 72-74. В иллюстративном выполнении проводится предсказание основного тона на подкадрах основного тона на всех скоростях, кроме одной восьмой. Кодер основного тона, представленный на фиг.7, проводит анализ, пользуясь синтезным способом для определения параметров предсказания основного тона (например, период L основного тона и усиление b основного тона). Выбранные параметры таковы, что минимизируют СКО между взвешенной с учетом человеческого восприятия входной речью и синтезированной речью, генерируемой с использованием этих параметров предсказания основного тона. В предпочтительном выполнении настоящего изобретения при выделении параметров предсказания основного тона используется неявное взвешивание с учетом человеческого восприятия, как представлено на фиг.7. На фиг.7 взвешенный с учетом человеческого восприятия фильтр с откликом, определяемым уравнением 34:  воплощен в виде последовательного соединения фильтра 320 и фильтра 324. Неявное взвешивание с учетом человеческого восприятия снижает вычислительную сложность взвешивающей с учетом человеческого восприятия фильтрации путем повторного использования выходного сигнала фильтра 320 в качестве формантного остатка разомкнутой системы. Эта операция разделения фильтра из уравнения (34) на две части исключает одну операцию фильтрации в поиске основного тона. Входные речевые выборки S(n) пропускаются через формантный предсказывающий фильтр 320, коэффициентами которого являются коэффициенты КЛП, получающиеся из интерполяции ЛСП и преобразования ЛСП в КЛП блока 70 на фиг.3, описанные здесь ранее. Выходным сигналом формантного предсказывающего фильтра является формантный остаток р0(n) разомкнутой системы. Формантный остаток р0(n) разомкнутой системы пропускается через взвешенный формантный фильтр 324 синтеза с передаточной функцией, определяемой уравнением (35):  (35) (35)где  = 0,8.
Выходной сигнал взвешенного формантного синтезирующего фильтра 324 представляет собой взвешенный с учетом человеческого восприятия речевой сигнал х(n). Влияние начального состояния фильтра или памяти фильтра во взвешенном формантном синтезирующем фильтре 324 исключается вычитанием нулевого входного отклика (НВО) взвешенного формантного синтезирующего фильтра 324 из выходного сигнала взвешенного формантного синтезирующего фильтра 324. Вычисление НВО взвешенного формантного синтезирующего фильтра 324 производится в элементе 328 НВО. НВО aZIR(n) вычитается из взвешенной с учетом человеческого восприятия речи х(n) в сумматоре 326. В начале каждого подкадра основного тона состояние фильтровой памяти в элементе 328 НВО и во взвешенном формантном синтезирующем фильтре 324 одинаково.
При поиске основного тона предполагается нулевой вклад вектора кодового словаря в вычислении формантного остатка разомкнутой системы. Поиск основного тона выполняется с использованием как формантного остатка ро(n) разомкнутой системы, описанной ранее, так и формантного остатка рс(n) замкнутой системы. Формантным остатком рс(n) замкнутой системы являются отсчеты, восстанавливаемые в фильтре 322 синтеза основного тона в течение предыдущих подкадров основного тона. Передаточная функция фильтра 322 синтеза основного тона показана в уравнении 36: = 0,8.
Выходной сигнал взвешенного формантного синтезирующего фильтра 324 представляет собой взвешенный с учетом человеческого восприятия речевой сигнал х(n). Влияние начального состояния фильтра или памяти фильтра во взвешенном формантном синтезирующем фильтре 324 исключается вычитанием нулевого входного отклика (НВО) взвешенного формантного синтезирующего фильтра 324 из выходного сигнала взвешенного формантного синтезирующего фильтра 324. Вычисление НВО взвешенного формантного синтезирующего фильтра 324 производится в элементе 328 НВО. НВО aZIR(n) вычитается из взвешенной с учетом человеческого восприятия речи х(n) в сумматоре 326. В начале каждого подкадра основного тона состояние фильтровой памяти в элементе 328 НВО и во взвешенном формантном синтезирующем фильтре 324 одинаково.
При поиске основного тона предполагается нулевой вклад вектора кодового словаря в вычислении формантного остатка разомкнутой системы. Поиск основного тона выполняется с использованием как формантного остатка ро(n) разомкнутой системы, описанной ранее, так и формантного остатка рс(n) замкнутой системы. Формантным остатком рс(n) замкнутой системы являются отсчеты, восстанавливаемые в фильтре 322 синтеза основного тона в течение предыдущих подкадров основного тона. Передаточная функция фильтра 322 синтеза основного тона показана в уравнении 36: где период L основного тона и усиление b основного тона вычисляются во время процедуры поиска основного тона для предыдущих подкадров основного тона. Входом в фильтр 322 синтеза основного тона является вектор Cb(n) возбуждения, генерируемый перемножением вводимых данных b(I) кодового словаря для указателя I и усиления G кодового словаря, вычисляемого во время процедуры поиска кодового словаря для предыдущих подкадров кодового словаря. Генерируемый таким образом формантный остаток называется формантным остатком замкнутой системы. В данном примере выполнения рс(n) состоит из 143 восстановленных выборок замкнутой системы. Поиск движется от поиска по большей части разомкнутой системы к поиску по большей части замкнутой системы для окна длиной в подкадр основного тона. Для подкадра основного тона длины Lp величина n изменяется между – Lmax=-143 и Lp – 17. В примере выполнения Lp=40 для полной скорости, Lp= 80 для половинной скорости и Lp=160 для скорости в одну четверть. В примере выполнения выборки рс(n) и ро(n) запоминаются непрерывно, как показано, мультиплексором 322, что позволяет считывать последовательно значения рс(n) и ро(n), как единый блок выборок длины Lp+143. Выборки хранятся в ОЗУ В 122. Формантный остаток р(n) состоит из pс(n) и ро(n) и пропускается через взвешенный формантный фильтр 330 синтеза с передаточной функцией, показанной в уравнении 37:  где = 0,8.Взвешенный формантный фильтр 330 синтеза используется для генерирования последовательности из Lp взвешенных синтезированных речевых выборок YL(n) для каждого значения периода L основного тона. Взвешенная синтезированная речевая последовательность YL(n) и взвешенная речевая последовательность х(n) подаются на минимизирующий процессор 334. Поскольку воздействие начального состояния взвешенного формантного синтезирующего фильтра 324 вычтено, будет вычисляться только импульсный отклик взвешенного формантного синтезирующего фильтра 330. Вычисление YL(n) влечет за собой свертку импульсного отклика h(n) взвешенного формантного синтезирующего фильтра подходящей последовательностью в остатке р(n) для получения взвешенных синтезированных речевых отсчетов YL(n) для периода L основного тона. Свертка выполняется в рекурсивном виде в ПЦОС 4, как представлено на фиг.5а-d. Набор значений YL(n) вычисляется для каждого значения периода основного тона от L=17 до L=143. Импульсный отклик h(n) взвешенного формантного синтезирующего фильтра 330 усечен до первых двадцати выборок в данном примере выполнения и хранится в ОЗУ А 104. Формантный остаток р(n) хранится в ОЗУ В 122. Свертка для первого периода основного тона L=17 выполняется в нерекурсивном виде, как показано в уравнении 38:  где Lp есть длина подкадра основного тона. Первая последовательность Y17(n) вычисляется и запоминается в ОЗУ С 182. Остальные последовательности YL(n) для периодов основного тона от L=18 до L= 143 вычисляются рекурсивно, как показано в уравнениях (39)-(41): YL(n) = h(0)p (-L) n=0, (39) YL(n) = YL-1(n-1)+h(n)p(-L) 1 YL(n)=YL-1(n-1) 20 Отметим соотношение, показанное в уравнении (42): PL(n)=P(n-L)=PL-1(n-1), 17 nЭффективность рекурсивной свертки оптимизируется разделением ОЗУ на три части, каждая со специализированным адресным блоком для управления операциями загрузки и хранения. Т.е. получается строенное ОЗУ. При этом возможно вычисление значений свертки по уравнению (40) и выдача результата каждый тактовый период. Например, в единичном тактовом периоде вычисляется Y18(10), запоминается Y18(9), выбирается Y17(10) и выбирается h(10). Таким образом, уравнение (40) может выдавать результат на каждом тактовом периоде. Также возможна выдача результата на каждом тактовом периоде для уравнения (41). Например, в единичном тактовом периоде вычисляется Y18(24), выбирается Y17(24) и запоминается Y18(23). Способность выполнять уравнения (40) и (41) без необходимости перемещать предварительно вычисленные взвешенные синтезированные речевые выборки YL-1(n-1) в то же самое исходное ОЗУ между каждым обновлением периода основного тона требует стратегии памяти и возможностей аппаратных средств, именуемых пинг-понговыми, в которых исходное и конечное ОЗУ меняются местами при каждом обновлении периода основного тона. При вычислении YL(n) для четных значений периода основного тона значения YL-1(n-1) выбираются из первого из трех ОЗУ, а результаты запоминаются во втором их трех ОЗУ. При вычислении YL(n) для нечетных значений периода основного тона значения YL-1(n-1) выбираются из второго из трех ОЗУ, а результаты запоминаются в первом из трех ОЗУ. Эта пинг-понговая процедура исключает необходимость перемещать вновь вычисленные значения YL(n) в то же самое ОЗУ, а предварительно вычисленные значения YL-1(n-1) из того же самого ОЗУ между каждым обновлением периода основного тона. На фиг.8 показана блок-схема алгоритма осуществления свертки (как начальной нерекурсивной, так и рекурсивных сверток), являющейся частью процедуры поиска основного тона в данном примере выполнения. В блоке 350 период L основного тона инициализируется на свое наименьшее значение, которое в этом примере составляет 17. Номер n отсчета и указатель m фильтра устанавливаются на нуль и значения Y17(n) устанавливаются на нуль. Блоки 352-360 образуют цикл начальной свертки, которая вычисляется в нерекурсивном виде. Вычисление начальной свертки при L=17 выполняется в соответствии с уравнением 43:  Вычисление начальной свертки использует циклы фиксированной длины для уменьшения сложности вычислений. Таким образом, избегают непроизводительных издержек на установление структуры цикла с переменной длиной во внутреннем цикле (блоки 356-360) уравнения (43). Каждое значение Y17(n) после его вычисления посылается в минимизирующий процессор 334. Блок 352 проверяет указатель n выборки. Если n равно длине p подкадра основного тона, то выполняется начальная свертка и вычисление продолжается в блоке 352. Если в блоке 352 n меньше длины подкадра основного тона, то вычисления продожаются в блоке 356. Блок 356 проверяет указатель m. Если m равно длине импульсного отклика фильтра, 20 в данном примере выполнения, то выполняется текущая итерация и вычисления продолжаются в блоке 354, где m устанавливается на 0, а n увеличивается. Затем вычисления продолжаются в блоке 352. Если в блоке 356 m меньше, чем длина импульсного отклика, то вычисления продолжаются в блоке 360, где накапливаются частичные суммы. Вычисления продолжаются в блоке 358, где указатель m увеличивается, и вычисления переходят в блок 356. Операции, содержащиеся в цикле начальной свертки, образуемом блоками 352-360, выполняются в ПЦОС 4, где предусмотрен соответствующий конвейер, обеспечивающий возможность накапливать произведения, как показано в блоке 360, на каждом тактовом периоде. Последующие операции иллюстрируют конвейерную процедуру вычислений и происходят в ПЦОС 4 в одном тактовом периоде. Отклик h(m+1) фильтра выбирается из ОЗУ А 104 и подается на регистр FREG 130. Значение формантного остатка р(n-17) выбирается из ОЗУ В 122 и подается на регистр BREG 134. Частная сумма Y17(n+m-1), находящаяся в регистре C0REG 164, подается в ОЗУ С 182 через мультиплексоры 168 и 180. Частичная сумма Y17(n+m+1) подается в ОЗУ С 182 на регистр OREG 156 через мультиплексор 158. Значения h(m) и р(n-17) в регистрах АREG 130 и BREG 134 соответственно подаются на перемножитель 132. Выход перемножителя 132 подается через мультиплексор 138 на многорегистровый циклический сдвигатель 140, который нормирует значение согласно масштабирующему значению, выданному регистром SREG 136 через мультиплексор 149. Значение в регистре SREG 136 является значением, необходимым для нормировки последовательности р(n-17). Прилагая этот коэффициент нормировки к произведениям р(n-17) и h(m), достигают того же эффекта, как при нормировке р(n-1), потому что полная точность произведения сохраняется перед тем, как имеет место нормировка в многорегистровом циклическом сдвигателе 140. Нормализованное значение подается на первый вход сумматора 146. Частная сумма Y17 (n+m) выдается регистром DREG 156 через мультиплексор 154, заблокированный инвертор 152 и многорегистровый циклический сдвигатель 150 на второй вход сумматора 146. Выход сумматора 146 подается через мультиплексор 148 на регистр C0REG 164. Когда указатель n достигает своего максимального разрешенного значения в блоке 352, начальная свертка завершается и частные суммы, представленные в ОЗУ С 182, являются теперь конечным результатом свертки. Когда начальная свертка завершена, вычисления продолжаются в блоке 362, где выполняется рекурсивная свертка для остальных значений периода основного тона. В блоке 362 указатель n выборки устанавливается на нуль, а указатель L периода основного тона увеличивается. Вычисления продолжаются в блоке 364. Блок 364 проверяет L. Если L больше, чем максимальное значение периода основного тона, 143 в данном примере выполнения, то вычисления продолжаются в блоке 366, где заканчивается операция поиска основного тона. Если L меньше или равно 143, то вычисления продолжаются в блоке 368. Блок 368 управляет пинг-понговой операцией, описанной ранее. В блоке 368 L проверяется на четность. Если L четно, то вычисления продолжаются в блоке 378 (операция, описанная как случай 1). Если L нечетно, то вычисления продолжаются в блоке 370 (операция, описанная как случай 2). Случай 1: (четное значение периода L основного тона) В блоке 378 вычисляется YL(0) согласно уравнению (39). Адресный блок А 102 выдает адресное значение в ОЗУ А 104, которое в ответ выдает h(0) через мультиплексор 108 на регистр AREG 130. В этом же тактовом периоде адресный блок В 120 выдает адресное значение в ОЗУ В 122, которое в ответ выдает р(-L) через мультиплексор 116 на регистр BREG 134. В течение следующего тактового периода регистр AREG 130 выдает h(0), а регистр BREG 134 выдает р(-L) на перемножитель 132, где два значения перемножаются и произведение подается через мультиплексор 138 на многорегистровый циклический сдвигатель 140. Многорегистровый циклический сдвигатель 140 согласно значению, выданному регистром SREG 136 через мультиплексор 149, нормирует произведение и подает нормированное произведение на первый вход сумматора 146. На второй вход сумматора146 подается нуль через мультиплексор 154, заблокированный инвертирующий элемент 152 и через многорегистровый циклический сдвигатель 152. Выходной сигнал сумматора 146 подается на регистр С0REG 164 через мультиплексор 148. В том же самом тактовом периоде значения L-1(0) и h(1) выбираются из ОЗУ В 122 и ОЗУ А 104 и подаются на регистры DREG 156 и АREG 130 через мультиплексоры 158 и 108 соответственно. В блоке 380 указатель n выборки синтезированной речи получает приращение. В управляющем блоке 382, если указатель n выборки синтезированной речи меньше 20, вычисления передаются в блок 384. В блоке 384 значение YL(n) вычисляется на каждом тактовом периоде согласно уравнению (40). Подходящая установка, требуемая перед первой итерацией в блоке 384 для инициализации значений YL-1(n-1) и h(n), была получена в блоке 378, как описано выше. Требуется также подходящая доводка вслед за последней итерацией блока 384 для запоминания конечного значения Y(19). В первой итерации блока 384 вычисленное в блоке 378 YL(0) присутствует в регистре C0REG 164. Регистр C0REG 164 выдает YL(0) через мультиплексоры 168 и 180 в ОЗУ С 182 для запоминания его с адресным значением, поданным в ОЗУ С 182 от адресного блока С 186. Значение YL(0) подается на минимизирующий процессор 334 в то же самое время, как оно подается в ОЗУ С 182. В блоке 384 последующие операции выполняются в одном тактовом периоде. Значение YL-1(n) выдается от ОЗУ В 122 согласно адресу, выданному адресным блоком В 120, через мультиплексоры 116 и 158 на регистр DREG 156. Значение h(n+1) выдается от ОЗУ А 104 через мультиплексор 108 на регистр AREG 130 согласно адресу, выданному адресным блоком А 102. Регистр DREG 156 выдает значение YL-1(n-1) через мультиплексор 154, заблокированный инвертирующий элемент 152 и многорегистровый циклический сдвигатель 150 на первый вход сумматора 146. Регистр AREG 130 выдает h(n), а регистр BREG 134 выдает p(-L) на перемножитель 132, где два значения перемножаются и произведение подается перемножителем 132 через мультиплексор 138 на многорегистровый циклический сдвигатель 140. Многорегистровый циклический сдвигатель 140 согласно значению, выданному регистром SREG 136, нормирует значение произведения и подает нормированное значение произведения на второй вход сумматора 146. Выходной сигнал сумматора 146 подается через мультиплексор 148 на регистр C0REG 164. Значение в С0REG 164, вычисленное в предыдущей итерации, подается через мультиплексоры 168 и 180 на ОЗУ С 182 для хранения и на минимизирующий процессор 334. В блоке 380 указатель n выборки синтезированной речи получает приращение. В управляющем блоке 382, если указатель n выборки синтезированной речи равен 20, то YL(19), вычисленное в конечной итерации, подается через мультиплексоры 168 и 124 на ОЗУ В 122 для хранения в кольцевом буфере и на минимизирующий процессор 334 перед переходом вычислений к блоку 390. Конец случая 1 Случай 2: (нечетные значения периода L основного тона) В блоке 370 вычисляется YL(0) согласно уравнению (39). Адресный блок А 102 выдает адресное значение в ОЗУ А 104, которое в ответ выдает h(0) через мультиплексор 108 на регистр АREG 130. В этом же тактовом периоде адресный блок В 120 выдает адресное значение в ОЗУ В 122, которое в ответ выдает p(-L) через мультиплексор 116 на регистр BREG 134. В течение следующего тактового периода регистр AREG 130 выдает h(0), а регистр BREG 134 выдает р(-L) на перемножитель 132, где два значения перемножаются и произведение подается через мультиплексор 138 на многорегистровый циклический сдвигатель 140. Многорегистровый циклический сдвигатель 140 согласно значению, выданному регистром SREG 136 через мультиплексор 149, нормирует произведение и подает нормированное произведение на первый вход сумматора 146. На второй вход сумматора 146 подается нуль через мультиплексор 154, заблокированный инвертирующий элемент 152 и многорегистровый циклический сдвигатель 152. Выходной сигнал сумматора 146 подается на регистр C0REG 164 через мультиплексор 148. В том же самом тактовом периоде значения L-1(0) и h(1) выбираются из ОЗУ С 182 и ОЗУ А 104 и подаются на регистры DREG 156 и AREG 130 через мультиплексоры 158 и 108 соответственно. В блоке 372 указатель n выборки синтезированной речи получает приращение. В управляющем блоке 374, если указатель n выборки синтезированной речи меньше 20, вычисления передаются в блок 376. В блоке 376 новое значение YL(n) вычисляется на каждом тактовом периоде согласно уравнению (40). Подходящая установка, требуемая перед первой итерацией в блоке 376 для инициализации значений Y(n-1) и h(n), была получена в блоке 370, как описано выше. Требуется также подходящая доводка вслед за последней итерацией блока 376 для запоминания конечного значения Y(19). В первой итерации блока 376 вычисленное в блоке 370 YL(0) присутствует в регистре C0REG 164. Регистр C0REG 164 выдает YL(0) через мультиплексоры 168 и 180 в ОЗУ В 122 для запоминания его с адресным значением, поданным в ОЗУ В 122 от адресного блока В 120. Значение YL(0) подается на минимизирующий процессор 334 в то же самое время, как оно подается в ОЗУ В 122. В блоке 376 последующие операции выполняются в одном тактовом периоде. Значение YL(n) выдается от ОЗУ С 182 согласно адресу, выданному адресным блоком С 186, через мультиплексор 158 на регистр DREG 156. Значение h(n+1) выдается от ОЗУ А 104 через мультиплексор 108 на регистр AREG 130 согласно адресу, выданному адресным блоком А 102. Регистр DREG 156 выдает значение YL-1(n-1) через мультиплексор 154, заблокированный инвертирующий элемент 152 и многорегистровый циклический сдвигатель 150 на первый вход сумматора 146. Регистр AREG 130 выдает h(n), а регистр BREG 134 выдает p(-L) на перемножитель 132, где два значения перемножаются и произведение подается перемножителем 132 через мультиплексор 138 на многорегистровый циклический сдвигатель 140. Многорегистровый циклический сдвигатель 140 согласно значению, выданному регистром SREG 136, нормирует значение произведения и подает нормированное значение произведения на второй вход сумматора 146. Выходной сигнал сумматора 146 подается через мультиплексор 148 на регистр C0REG 164. Значение в С0REG 164, вычисленное в предыдущей итерации, подается через мультиплексоры 168 и 124 на ОЗУ В 122 для хранения и на минимизирующий процессор 334. В блоке 372 указатель n выборки синтезированной речи получает приращение. В управляющем блоке 374, если указатель n выборки синтезированной речи равен 20, то YL(19), вычисленное в конечной итерации, подается через мультиплексоры 168 и 124 на ОЗУ В 122 для хранения в кольцевом буфере внутри ОЗУ В 122 и на минимизирующий процессор 334 перед переходом вычислений к блоку 390. Конец случая 2 Перед первой итерацией блока 390 выбирается YL-1(19) из кольцевого буфера в ОЗУ В 122 и загружается в регистр BREG 134, затем YL-1(19) перемещается из регистра BREG 134 в регистр C0REG 164, после чего из кольцевого буфера в ОЗУ В 122 выбирается YL-1(20) и загружается в регистр BREG 134. В блоке 390 новое значение YL(n) вычисляется каждый тактовый период согласно уравнению (41). Следующие операции выполняются в одном тактовом периоде. Значение YL-1(n-2)выдается регистром BREG 134 на регистр C0REG 164. Значение YL-1(n-3) выбирается из кольцевого буфера в ОЗУ В 122 и загружается в регистр BREG 134. Представленное в регистре С0REG 164 значение YL-1(n-1) направляется в минимизирующий процессор 334. Вслед за последней итерацией блока 390 значение YL-1(LP-2) стирается из кольцевого буфера в ОЗУ В 122. За счет добавления элемента к кольцевому буферу на каждом периоде основного тона и удаления элемента из кольцевого буфера на каждом периоде основного тона размер кольцевого буфера поддерживается на значении Lp-19. Реализация кольцевого буфера осуществляется посредством специальных адресных регистров в адресном блоке В 120, которые задают точки циклического возврата так, что последовательная память может автоматически адресоваться циклически. В блоке 386 указатель n выборки синтезированной речи получает приращение. В управляющем блоке 388, если указатель n меньше, чем Lр, вычисления передаются опять к блоку 390. Если указатель n равен Lр, то все значения YL(n) вычисляются для текущего значения периода основного тона и вычисления возвращаются к блоку 362. Перед вычислением отсчетов YL(n) синтезированной речи последовательность длины Lр взвешенных с учетом человеческого восприятия речевых отсчетов xр(n) подается на минимизирующий процессор 334. Как описано ранее, последовательности отсчетов Y(n) синтезированной речи длиной Lр для значений периода основного тона от L=17 до L=143 подаются на минимизирующий процессор 334 во время начального и рекурсивных сверточных вычислений. Выборки синтезированной речи последовательно подаются на минимизирующий процессор 334. Минимизирующий процессор 334 вычисляет автокорреляцию каждой последовательности выборок L(n) синтезированной речи и взаимную корреляцию между последовательностью выборок Yl(n) синтезированной речи и последовательностью выборок xр(n), взвешенных с учетом человеческого восприятия. Из этих значений корреляции минимизирующий процессор 334 вычисляет затем относительную меру СКО между каждой последовательностью выборок YL(n) синтезированной речи и последовательностью выборок xр(n), взвешенных с учетом человеческого восприятия. Для каждого периода L основного тона СКО вычисляется для всех возможных значений усиления b основного тона в последовательности отсчетов синтезированной речи. Минимизирующий процессор 334 находит минимум СКО по всем значениям периода L основного тона и по всем возможным значениям усиления b основного тона путем сохранения значения минимального СКО при текущем периоде L основного тона и текущем усилении b основного тона. Минимизирующим процессором 334 сохраняются также оценка  периода основного тона и указатель периода основного тона и указатель  оценки усиления основного тона, соответствующие минимальной СКО. Каждое новое значение СКО сравнивается с минимальной СКО, сохраняемой в минимизирующем процессоре 334. Если новая СКО меньше, чем минимальная СКО, то минимальная СКО заменяется новым значением СКО, а оценка оценки усиления основного тона, соответствующие минимальной СКО. Каждое новое значение СКО сравнивается с минимальной СКО, сохраняемой в минимизирующем процессоре 334. Если новая СКО меньше, чем минимальная СКО, то минимальная СКО заменяется новым значением СКО, а оценка  периода основного тона и указатель периода основного тона и указатель  оценки усиления основного тона обновляются для отражения новой минимальной СКО. Минимальная СКО и соответствующая оценка оценки усиления основного тона обновляются для отражения новой минимальной СКО. Минимальная СКО и соответствующая оценка  периода основного тона и указатель периода основного тона и указатель  оценки усиления основного тона, сохраненные в минимизирующем процессоре 334, инициализируются на каждом подкадре основного тона с использованием первого отрицательного значения СКО, вычисленного в течение подкадра основного тона. После того, как все значения периода L основного тона и все значения усиления b основного тона исчерпаны, оценка оценки усиления основного тона, сохраненные в минимизирующем процессоре 334, инициализируются на каждом подкадре основного тона с использованием первого отрицательного значения СКО, вычисленного в течение подкадра основного тона. После того, как все значения периода L основного тона и все значения усиления b основного тона исчерпаны, оценка  периода основного тона и указатель периода основного тона и указатель  оценки усиления основного тона будут соответственно оптимальным указателем периода основного тона и оптимальным указателем усиления основного тона для текущего подкадра основного тона. Минимизирующий процессор 334 выдает оптимальный период оценки усиления основного тона будут соответственно оптимальным указателем периода основного тона и оптимальным указателем усиления основного тона для текущего подкадра основного тона. Минимизирующий процессор 334 выдает оптимальный период  основного тона и оптимальный указатель основного тона и оптимальный указатель  усиления основного тона на ПЦОС 4. Оптимальный период усиления основного тона на ПЦОС 4. Оптимальный период  основного тона и оптимальный указатель основного тона и оптимальный указатель  усиления основного тона таковы, что дают в результате минимальную СКО между взвешенными с учетом человеческого восприятия речевыми отсчетами xp(n) и взвешенными отсчетами YL(n) синтезированной речи. СКО является функцией от периода L основного тона и усиления b основного тона, как описано уравнениями (44)-(46) усиления основного тона таковы, что дают в результате минимальную СКО между взвешенными с учетом человеческого восприятия речевыми отсчетами xp(n) и взвешенными отсчетами YL(n) синтезированной речи. СКО является функцией от периода L основного тона и усиления b основного тона, как описано уравнениями (44)-(46)  =Еxрxр-2bЕxрYL+b2EYLYL (46) Еxрxр есть автокорреляция взвешенных с учетом человеческого восприятия выборок xр(n). ЕxрYL есть взаимная корреляция между взвешенными с учетом человеческого восприятия выборками xр(n) и взвешенными выборками YL(n) синтезированной речи. EYLYL есть автокорреляция взвешенных выборок YL(n) синтезированной речи. Автокорреляция Еxрxр взвешенных с учетом человеческого восприятия выборок xр(n) не является функцией усиления b основного тона. Еxрxр остается постоянным в течение каждого подкадра основного тона и поэтому не влияет на выбор оптимального периода основного тона и оптимального усиления основного тона. Минимизация уравнений (44)-(46) по периоду L основного тона и усилению b основного тона эквивалентна минимизации уравнения (47): MSE(L,b)=-2bExpYL+b2EYLYL. (47) Минимизирующий процессор 334 вычисляет автокорреляции EYLYL последовательностей взвешенных выборок YL(n) синтезированной речи и взаимные корреляции ExpYL между последовательностью взвешенных с учетом человеческого восприятия выборок xр(n) и последовательностями взвешенных выборок YL(n) синтезированной речи. Для каждой корреляционной пары (ExpYL, EYLYL) минимизирующий процессор 334 вычисляет относительную СКО согласно уравнению (47) для набора значений усиления b основного тона. Вычисления корреляций ЕxрYL и EYLYL выполняются в минимизирующем процессоре 334 одновременно. Вычисляются значения относительной СКО и выносятся решения относительно минимизации СКО для периода L основного тона, тогда как значения корреляции вычисляются для периода L+1 основного тона. Фиг. 6а и 6b представляют иллюстративное выполнение минимизирующего процессора 334. Взвешенные с учетом человеческого восприятия речевые выборки xр(n) подаются ПЦОС 4 на фиксатор 210 для хранения в ОЗУ Х 212 в соответствии с адресом, выданным от блока 220 управления. Отмасштабированные значения -2b усиления основного тона для b=0,25 до b=2,0 с шагом 0,25 подаются через мультиплексор 260 от ПЦОС 4 для запоминания в фиксаторах соответственно 264, 268, 272, 276, 280, 284, 288 и 292. Соответствующие масштабированные значения b2 подаются через мультиплексор 260 от ПЦОС 4 для запоминания в фиксаторах соответственно 262, 266, 270, 274, 278, 282, 286 и 290. Мультиплексор 262 подает значения прямо на фиксатор 264. Фиксатор 276 выдает значения фиксатора 278 через мультиплексор 294. Фиксатор 290 выдает значения прямо на фиксатор 292 и т.д. Сдвиг значений через фиксаторы 262-292 и через мультиплексор 294 позволяет значениям проходить через мультиплексор 260 на все фиксаторы в кольцевом буфере 259. Вслед за запоминанием взвешенных с учетом человеческого восприятия речевых выборок xр(n) и запоминанием значений -2b и b2 последовательности взвешенных выборок YL(n) синтезированной речи подаются на фиксатор 210. Взвешенные выборки Y(n) синтезированной речи подаются на фиксатор 210 двухвходового перемножителя 216, который образует квадраты (YL(n))2 взвешенных выборок синтезированной речи. Фиксатор 210 выдает также взвешенные выборки YL(n) на первый вход перемножителя 218. ОЗУ Х 212 подает взвешенные с учетом человеческого восприятия речевые выборки xр(n) через фиксатор 214 на второй вход перемножителя 218. Перемножитель 218 вычисляет значения произведений xр(n)YL(n). Новый квадрат (YL(n))2 и новое произведение xр(n)YL(n) вычисляются на каждом тактовом периоде перемножителями 216 и 218 соответственно. Указатель n отсчета изменяется от 0 до Lр-1 для каждого периода L основного тона. Квадраты (YL(n))2 взвешенных выборок синтезированной речи подаются на накопитель 221. Значения произведений xp(n)YL(n) подаются на накопитель 231. Накопитель 221 вычисляет сумму из Lр квадратов для каждого периода L основного тона. Накопитель 231 вычисляет сумму из Lр значений произведения для каждого периода L основного тона. Перед каждым новым периодом основного тона на фиксатор 226 подается нуль через мультиплексор 224. После этого накопитель 221 готов к вычислениям автокорреляции EYLYL для текущего периода L основного тона. В накопителе 221 квадраты (YL(n))2 подаются на первый вход сумматора 222. Итог прогона подается фиксатором 226 на второй вход сумматора 222. Вновь вычисленный итог прогона подается сумматором 222 через мультиплексор 224 на фиксатор 226 для запоминания. После накопления по всем Lр значениям для периода L основного тона автокорреляция EYLYLподается на фиксатор 228 для запоминания. Перед каждым новым периодом основного тона на фиксатор 236 подается нуль через мультиплексор 234. Накопитель 231 затем сразу вычисляет взаимную корреляцию ЕxpYL для текущего периода L основного тона. В накопителе 231 значения xр(n)YL(n) подаются на первый вход сумматора 232. Итог прогона подается фиксатором 236 на второй вход сумматора 232. Вновь вычисленный итог текущего прогона подается сумматором 232 через мультиплексор 234 на фиксатор 236 для запоминания. После накопления по всем Lp значениям для периода L основного тона взаимная корреляция подается на фиксатор 238 для запоминания. Описываемая уравнением (47) СКО вычисляется затем в двухтактовом процессе, описанном ниже. На первых двух тактовых периодах фиксатор 238 подает взаимную корреляцию ЕxрYL между взвешенными с учетом человеческого восприятия речевыми выборками и взвешенными выборками синтезированной речи через мультиплексор 230 на первый вход перемножителя 240. Кольцевой буфер 259 выдает масштабированное значение -2b усиления основного тона на второй вход перемножителя 240 через мультиплексор 296. Произведение -2bЕхpYL подается перемножителем 240 на первый вход сумматора 242. На второй вход сумматора 242 подается нуль через мультиплексор 246. Выход сумматора 242 подается на фиксатор 244 для запоминания. Значения в фиксаторах 262-292 кольцевого буфера 259 циклически сдвигаются подачей выхода фиксатора 276 на фиксатор 278 через мультиплексор 294 и подачей выхода фиксатора 292 на фиксатор 262 через мультилпексор 260. После этого циклического сдвига фиксаторы 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290 и 292 содержат значения, ранее содержавшиеся в фиксаторах 292, 262, 264, 266, 268, 270, 272, 274, 276, 278, 280, 282, 284, 286, 288, 290 соответственно. В процедуре поиска основного тона кольцевой буфер содержит фиксаторы 262-292 и мультиплексоры 260 и 294 кольцевого буфера 259. Путем циклического сдвига значений в кольцевом буфере 259 фиксатор 292 подает значения -2b и b на первом и втором периодах соответственно. На втором из двух тактовых периодов фиксатор 228 выдает автокорреляцию ЕYLYL взвешенных выборок синтезированной речи через мультиплексор 230 на первый вход перемножителя 240. Кольцевой буфер 259 выдает масштабированное значение b2 усиления основного тона на второй вход перемножителя 240 через мультиплексор 296. Произведение b2ЕYLYL подается перемиожителем 240 на первый вход сумматора 242. На второй вход сумматора 242 подаются выходные данные фиксатора 244 -2b ЕxрYL через мультиплексор 246. Сумматор 242 выдает на фиксатор 244 сумму -2bЕxрYL + b2ЕYLYL для запоминания. Значения в фиксаторах 262-292 кольцевого буфера 259 затем циклически сдвигаются, как описано выше. Вышеописанный двухтактовый процесс повторяется для всех восьми пар (-2b, b2) масштабированных значений усиления основного тона. Во время двух тактов, следующих за вычислением текущего значения СКО -2bЕxрYL+b2ЕYLYL, вычисляется новое значение СКО с использованием новой пары значений -2b и b2. Перед обновлением фиксатора 244 новым значением СКО текущее значение СКО сравнивается с текущим минимальным СКО, хранимым в фиксаторе 250, для текущего подкадра основного тона. Текущее значение СКО -2bЕxрYL+b2ЕYLYL подается фиксатором 244 на вход уменьшаемого вычитателя 28. Фиксатор 250 подает текущее значение минимальной СКО на вход вычитаемого вычитателя 248. Блок 220 управления отслеживает результат на выходе разности вычитателя 248. Если разность отрицательна, текущее значение СКО является новой минимальной СКО для текущего подкадра основного тона и запоминается в фиксаторе 250, а в блоке 220 управления обновляются соответствующие оценка  периода основного тона и указатель периода основного тона и указатель  оценки усиления основного тона. Если разность не отрицательна, то текущее значение СКО игнорируется.
Перед каждым подкадром основного тона ПЦОС 4 выдает команду на минимизирующий процессор 334, извещающую блок 220 управления, что будет следовать новый подкадр основного тона. По получении этой команды текущий период основного тона и текущий указатель усиления основного тона устанавливаются на 0 в блоке 220 управления. Перед тем, как каждая новая последовательность взвешенных отсчетов синтезированной речи подается на минимизирующий процессор 334, ПЦОС 4 выдает команду на минимизирующий процессор 334, информируя блок 220 управления, что будет следовать новая последовательность взвешенных выборок синтезированной речи. По получении этой команды блок 220 управления увеличивает текущий период основного тона и текущий указатель усиления основного тона на 1, соответствующую приращению периода основного тона на 1 и приращению указателя усиления основного тона на 0,25. Во время подачи первой последовательности взвешенных выборок синтезированной речи на минимизирующий процессор 334 текущий период основного тона и текущий указатель усиления основного тона будут равны 1, соответствующей периоду основного тона L=17 и нормированному усилению основного тона b=0,25. Также перед каждым подкадром основного тона текущая оценка оценки усиления основного тона. Если разность не отрицательна, то текущее значение СКО игнорируется.
Перед каждым подкадром основного тона ПЦОС 4 выдает команду на минимизирующий процессор 334, извещающую блок 220 управления, что будет следовать новый подкадр основного тона. По получении этой команды текущий период основного тона и текущий указатель усиления основного тона устанавливаются на 0 в блоке 220 управления. Перед тем, как каждая новая последовательность взвешенных отсчетов синтезированной речи подается на минимизирующий процессор 334, ПЦОС 4 выдает команду на минимизирующий процессор 334, информируя блок 220 управления, что будет следовать новая последовательность взвешенных выборок синтезированной речи. По получении этой команды блок 220 управления увеличивает текущий период основного тона и текущий указатель усиления основного тона на 1, соответствующую приращению периода основного тона на 1 и приращению указателя усиления основного тона на 0,25. Во время подачи первой последовательности взвешенных выборок синтезированной речи на минимизирующий процессор 334 текущий период основного тона и текущий указатель усиления основного тона будут равны 1, соответствующей периоду основного тона L=17 и нормированному усилению основного тона b=0,25. Также перед каждым подкадром основного тона текущая оценка  периода основного тона и текущий указатель периода основного тона и текущий указатель  оценки усиления основного тона устанавливаются на нуль, индицируя неверные период основного тона и усиление основного тона. В течение каждого подкадра основного тона блок 220 управления будет обнаруживать первую отрицательную СКО в фиксаторе 244. Это значение запоминается в фиксаторе 250, и соответствующие оценка оценки усиления основного тона устанавливаются на нуль, индицируя неверные период основного тона и усиление основного тона. В течение каждого подкадра основного тона блок 220 управления будет обнаруживать первую отрицательную СКО в фиксаторе 244. Это значение запоминается в фиксаторе 250, и соответствующие оценка  периода основного тона и указатель периода основного тона и указатель  оценки усиления основного тона обновляются в блоке 220 управления. Это делается для того, чтобы инициализировать минимальную СКО в фиксаторе 250 в каждом подкадре основного тона. Если в течение подкадра основного тона не будет выработано никакого отрицательного значения СКО, оценка оценки усиления основного тона обновляются в блоке 220 управления. Это делается для того, чтобы инициализировать минимальную СКО в фиксаторе 250 в каждом подкадре основного тона. Если в течение подкадра основного тона не будет выработано никакого отрицательного значения СКО, оценка  периода основного тона и указатель периода основного тона и указатель  оценки усиления основного тона будут равны нулю до конца подкадра. Эти оценки будут выдаваться блоком 2 управления на ПЦОС 4. Если ПЦОС 4 принимает неверную оценку периода основного тона, то оптимальное усиление основного тона устанавливается на нуль, т.е. оценки усиления основного тона будут равны нулю до конца подкадра. Эти оценки будут выдаваться блоком 2 управления на ПЦОС 4. Если ПЦОС 4 принимает неверную оценку периода основного тона, то оптимальное усиление основного тона устанавливается на нуль, т.е.  что соответствует нулевой СКО. Установка усиления основного тона в фильтре основного тона на нуль никак не скажется на периоде основного тона. Если ПЦОС 4 принимает верную оценку что соответствует нулевой СКО. Установка усиления основного тона в фильтре основного тона на нуль никак не скажется на периоде основного тона. Если ПЦОС 4 принимает верную оценку  периода основного тона, то это значение используется в качестве оптимального периода основного тона, а используемое оптимальное усиление основного тона будет равно 0,25, 0,5, 0,75, 1,0, 1,25, 1,5, 1,75 и 2,0 для указателей оценки усиления основного тона от 1 до 8 соответственно.
В поиске основного тона свойство функции СКО МSЕ (L, b) в уравнении (47) позволяет уменьшить объем вычислений. Остающиеся вычисления СКО текущего периода основного тона могут быть отброшены после того, как определено, что остающиеся значения СКО, подлежащие еще вычислению в текущем периоде основного тона, не отразятся на значении СКО, которое меньше, чем текущая минимальная СКО, хранящаяся в фиксаторе 250. В данном примере выполнения в минимизирующем процессоре используются три метода сокращения вычислений при поиске основного тона. Функция СКО МSЕ(L, b) является квадратичной по b. Для каждого значения L периода основного тона образуется одно квадратичное уравнение. Все эти квадратичные уравнения пропускаются через начальные условия b= 0 и МSЕ (L,b)=0. Значение b=0 усиления основного тона включается в набор возможных значений усиления основного тона, хотя оно явно не используется для операции поиска основного тона.
Первый способ сокращения вычислений включает в себя отбрасывание вычислений значения СКО в процедуре поиска основного тона для текущего периода основного тона, когда ЕxpYL отрицательно. Все значения усиления основного тона положительны, подтверждая, что нуль является верхней границей минимальной СКО для каждого подкадра. Отрицательное значение ЕxрYL проявится в положительном значении СКО и будет поэтому субоптимальнным.
Второй способ сокращения вычислений включает в себя отбрасывание вычислений остающихся значений СКО в процедуре поиска основного тона для текущего периода основного тона вследствие квадратичной природы функции СКО. Эта функция МSЕ(L, b) вычисляется для значений усиления основного тона, которые возрастают монотонно. Когда для текущего периода основного тона вычисляется положительное значение СКО, все оставшиеся вычисления СКО для текущего периода основного тона отбрасываются, т.к. все остающиеся значения СКО будут также положительны.
Третий способ сокращения вычислений включает в себя отбрасывание вычислений остающихся значений СКО в процедуре поиска основного тона для текущего периода основного тона вследствие квадратичной природы функции СКО. Эта функция MSE (L, b) вычисляется для значений усиления основного тона, которые возрастают монотонно. Когда для текущего периода основного тона вычисляется значение СКО, которое определяется как минимальная СКО, и когда значение СКО вычисляется в текущем периоде основного тона, который определен как не имеющий новой минимальной СКО, все остающиеся вычисления СКО в текущем периоде основного тона отбрасываются, т.к. остающиеся значения СКО не могут быть меньше, чем новая минимальная СКО. Три способа сокращения вычислений, описанные выше, обеспечивают значительное сокращение мощности в минимизирующем процессоре 334.
В блоке 76 квантуются значения основного тона. Для каждого подкадра основного тона выбранные параметры периода основного тона, то это значение используется в качестве оптимального периода основного тона, а используемое оптимальное усиление основного тона будет равно 0,25, 0,5, 0,75, 1,0, 1,25, 1,5, 1,75 и 2,0 для указателей оценки усиления основного тона от 1 до 8 соответственно.
В поиске основного тона свойство функции СКО МSЕ (L, b) в уравнении (47) позволяет уменьшить объем вычислений. Остающиеся вычисления СКО текущего периода основного тона могут быть отброшены после того, как определено, что остающиеся значения СКО, подлежащие еще вычислению в текущем периоде основного тона, не отразятся на значении СКО, которое меньше, чем текущая минимальная СКО, хранящаяся в фиксаторе 250. В данном примере выполнения в минимизирующем процессоре используются три метода сокращения вычислений при поиске основного тона. Функция СКО МSЕ(L, b) является квадратичной по b. Для каждого значения L периода основного тона образуется одно квадратичное уравнение. Все эти квадратичные уравнения пропускаются через начальные условия b= 0 и МSЕ (L,b)=0. Значение b=0 усиления основного тона включается в набор возможных значений усиления основного тона, хотя оно явно не используется для операции поиска основного тона.
Первый способ сокращения вычислений включает в себя отбрасывание вычислений значения СКО в процедуре поиска основного тона для текущего периода основного тона, когда ЕxpYL отрицательно. Все значения усиления основного тона положительны, подтверждая, что нуль является верхней границей минимальной СКО для каждого подкадра. Отрицательное значение ЕxрYL проявится в положительном значении СКО и будет поэтому субоптимальнным.
Второй способ сокращения вычислений включает в себя отбрасывание вычислений остающихся значений СКО в процедуре поиска основного тона для текущего периода основного тона вследствие квадратичной природы функции СКО. Эта функция МSЕ(L, b) вычисляется для значений усиления основного тона, которые возрастают монотонно. Когда для текущего периода основного тона вычисляется положительное значение СКО, все оставшиеся вычисления СКО для текущего периода основного тона отбрасываются, т.к. все остающиеся значения СКО будут также положительны.
Третий способ сокращения вычислений включает в себя отбрасывание вычислений остающихся значений СКО в процедуре поиска основного тона для текущего периода основного тона вследствие квадратичной природы функции СКО. Эта функция MSE (L, b) вычисляется для значений усиления основного тона, которые возрастают монотонно. Когда для текущего периода основного тона вычисляется значение СКО, которое определяется как минимальная СКО, и когда значение СКО вычисляется в текущем периоде основного тона, который определен как не имеющий новой минимальной СКО, все остающиеся вычисления СКО в текущем периоде основного тона отбрасываются, т.к. остающиеся значения СКО не могут быть меньше, чем новая минимальная СКО. Три способа сокращения вычислений, описанные выше, обеспечивают значительное сокращение мощности в минимизирующем процессоре 334.
В блоке 76 квантуются значения основного тона. Для каждого подкадра основного тона выбранные параметры  преобразуются в коды передачи PGAIN и PLAG. Указатель b оптимального усиления основного тона является целым числом от 1 до 8 включительно. Оптимальный период преобразуются в коды передачи PGAIN и PLAG. Указатель b оптимального усиления основного тона является целым числом от 1 до 8 включительно. Оптимальный период  основного тона является целым числом от 1 до 127 включительно.
Значение PLAG зависит и от основного тона является целым числом от 1 до 127 включительно.
Значение PLAG зависит и от  и от и от  Если Если  то PLAG =0. В противном случае то PLAG =0. В противном случае  Таким образом, PLAG представляется с использованием семи разрядов. Если b=0, то PGAIN=0. В противном случае Таким образом, PLAG представляется с использованием семи разрядов. Если b=0, то PGAIN=0. В противном случае  Таким образом, PGAIN представляется тремя разрядами. Отметим, что как Таким образом, PGAIN представляется тремя разрядами. Отметим, что как  так и так и  выражаются в PGAIN=0. Эти два случая различаются значением PLАG, которое является нулевым в первом случае и ненулевым во втором случае.
За исключением скорости в одну восьмую, каждый подкадр основного тона заключает в себе два подкадра кодового словаря. Для каждого подкадра кодового словаря в процедуре поиска кодового словаря блока 80 определяется указатель выражаются в PGAIN=0. Эти два случая различаются значением PLАG, которое является нулевым в первом случае и ненулевым во втором случае.
За исключением скорости в одну восьмую, каждый подкадр основного тона заключает в себе два подкадра кодового словаря. Для каждого подкадра кодового словаря в процедуре поиска кодового словаря блока 80 определяется указатель  оптимального кодового словаря и оптимальное усиление оптимального кодового словаря и оптимальное усиление  кодового словаря. Для скорости в одну восьмую определяется только один указатель кодового словаря и одно усиление кодового словаря, и указатель кодового словаря отбрасывается перед передачей.
Как показано на фиг. 9 в рассматриваемом примере выполнения, кодовый словарь возбуждения, выдаваемый блоком 400 кодового словаря, состоит из 2M кодовых векторов, где М=7.
Циклический кодовый словарь в данном примере состоит из 128 значений, заданных в таблице 4. Значения приведены в десятичной записи и хранятся в ПЗУ Е 114.
Способ, используемый для выбора векторного указателя I кодового словаря и усиления G кодового словаря, является способом анализа путем синтеза, подобным тому, который используется для процедуры поиска основного тона. Выбранный указатель кодового словаря. Для скорости в одну восьмую определяется только один указатель кодового словаря и одно усиление кодового словаря, и указатель кодового словаря отбрасывается перед передачей.
Как показано на фиг. 9 в рассматриваемом примере выполнения, кодовый словарь возбуждения, выдаваемый блоком 400 кодового словаря, состоит из 2M кодовых векторов, где М=7.
Циклический кодовый словарь в данном примере состоит из 128 значений, заданных в таблице 4. Значения приведены в десятичной записи и хранятся в ПЗУ Е 114.
Способ, используемый для выбора векторного указателя I кодового словаря и усиления G кодового словаря, является способом анализа путем синтеза, подобным тому, который используется для процедуры поиска основного тона. Выбранный указатель  кодового словаря и выбранное усиление кодового словаря и выбранное усиление  кодового словаря являются приемлемыми значениями из кодового словаря являются приемлемыми значениями из  которые минимизируют среднеквадратичную ошибку MSЕ(L, b) в уравнении (50) между взвешенной синтезированной речью YI(n) и взвешенной с учетом человеческого восприятия речью xc(n) с убранной оценкой основного тона. На фиг. 9 взвешенная речь хc(n) генерируется следующим образом. Здесь используется та же взвешенная с учетом человеческого восприятия речь х(n), что и генерируемая в поиске основного тона для текущего подкадра. Из-за отсутствия поиска основного тона на скорости в одну восьмую, х(n) для этой скорости генерируется в поиске кодового словаря. Значение х(n) подается на первый вход сумматора 410.
Используя оптимальный период которые минимизируют среднеквадратичную ошибку MSЕ(L, b) в уравнении (50) между взвешенной синтезированной речью YI(n) и взвешенной с учетом человеческого восприятия речью xc(n) с убранной оценкой основного тона. На фиг. 9 взвешенная речь хc(n) генерируется следующим образом. Здесь используется та же взвешенная с учетом человеческого восприятия речь х(n), что и генерируемая в поиске основного тона для текущего подкадра. Из-за отсутствия поиска основного тона на скорости в одну восьмую, х(n) для этой скорости генерируется в поиске кодового словаря. Значение х(n) подается на первый вход сумматора 410.
Используя оптимальный период  основного тона и оптимальное усиление основного тона и оптимальное усиление  основного тона, которые выделены в поиске основного тона для текущего подкадра, и текущие состояния памяти фильтра 506 основного тона, в элементе 406 ОНВ вычисляется отклик при нулевом входе (ОНВ) (ZIR) pzIR(n) фильтра 506 синтеза основного тона. ОНВ затем пропускается через взвешенный фильтр 408 синтеза и выход раZIR(n) вычитается из х(n) в сумматоре 410. Выход сумматора 410 c(n) нормирован и подается на минимизирующий процессор 412.
Вектор СI(n) кодового словаря выдается блоком 400 кодового словаря в ответ на указатель I кодового словаря согласно уравнению (53). В данном примере выполнения используется импульсный отклик h(n) взвешенного фильтра 404 синтеза, уже определенный в процедуре поиска основного тона для текущего подкадра основного тона. Однако, на скорости в одну восьмую h(n) вычисляется в поиске кодового словаря во взвешенном фильтре 404 синтеза. В примере выполнения импульсный отклик h(n) ограничен первыми 20 выборками.
В кодовом поиске, вследствие рекурсивной природы кодового словаря, используется рекурсивная сверточная процедура, подобная той, что использовалась в поиске основного тона. Свертка вычисляется, как показано в уравнении (52) основного тона, которые выделены в поиске основного тона для текущего подкадра, и текущие состояния памяти фильтра 506 основного тона, в элементе 406 ОНВ вычисляется отклик при нулевом входе (ОНВ) (ZIR) pzIR(n) фильтра 506 синтеза основного тона. ОНВ затем пропускается через взвешенный фильтр 408 синтеза и выход раZIR(n) вычитается из х(n) в сумматоре 410. Выход сумматора 410 c(n) нормирован и подается на минимизирующий процессор 412.
Вектор СI(n) кодового словаря выдается блоком 400 кодового словаря в ответ на указатель I кодового словаря согласно уравнению (53). В данном примере выполнения используется импульсный отклик h(n) взвешенного фильтра 404 синтеза, уже определенный в процедуре поиска основного тона для текущего подкадра основного тона. Однако, на скорости в одну восьмую h(n) вычисляется в поиске кодового словаря во взвешенном фильтре 404 синтеза. В примере выполнения импульсный отклик h(n) ограничен первыми 20 выборками.
В кодовом поиске, вследствие рекурсивной природы кодового словаря, используется рекурсивная сверточная процедура, подобная той, что использовалась в поиске основного тона. Свертка вычисляется, как показано в уравнении (52) Вектор СI(n) кодового словаря для указателя I определяется, как показано в уравнении (53):  Полная свертка выполняется для указателя I=0 согласно уравнению (54). Выход Yo(n) запоминается в ОЗУ С 182. Для остальных указателей от I=1 до I= 127 свертка выполняется рекурсивно, как показано в уравнениях (55)-(57):   Как и в поиске основного тона, характеристика рекурсивной свертки поиска кодового словаря оптимизируется за счет использования строенных ОЗУ и ПЗУ Е 114 в ПЦОС 4. Вычисление значений свертки в уравнении (56) и выдача результата возможны тогда на каждом такте. Например, в одном тактовом периоде вычисляется Y18(10), запоминается Y18(9), выбирается Y17(10) и выбирается h(10). Таким образом, уравнение (56) может выдавать результат на каждом тактовом периоде. Также возможно получение результата на каждом тактовом периоде для уравнения (57). Например, в одном тактовом периоде вычисляется Y18(24), выбирается Y17(24) и запоминается Y18(23). Способность решать уравнения (56) и (57) без необходимости перемещать предварительно вычисленные взвешенные выборки YI-1(n-1)в то же самое ОЗУ между каждым обновлением указателя кодового словаря требует сильной стратегии и способности аппаратного обеспечения, названной пинг-понговой, в которой исходное и конечное ОЗУ переставляются между каждым обновлением указателя. При вычислении YI(n) для четных значений кодового словаря значения YI-1(n-1) выбираются из первого из трех ОЗУ, а результаты записываются во второе из трех ОЗУ. При вычислении YI(n) для нечетных значений указателя кодового словаря значения YI-1(n-1) выбираются из второго из трех ОЗУ, а результаты записываются в первое из трех ОЗУ. Эта пинг-понговая процедура исключает необходимость перемещать предварительно вычисленные значения YI-1(n-1) в то же самое ОЗУ между обновлением указателя кодового словаря. На фиг. 10 представлена блок-схема алгоритма осуществления рекурсивной свертки, являющейся частью (как первоначальной нерекурсивной, так и рекурсивных сверток) процедуры поиска кодового словаря в данном примере выполнения. В блоке 414 указатель I кодового словаря инициализируется на свое наименьшее значение, равное 0. Номер n выборки и указатель m установлены на нуль, и значения Y(n) установлены на нуль. Блоки 416-424 образуют цикл начальной свертки, которая вычисляется в нерекурсивном виде. Вычисление начальной свертки, где I=0, выполняется согласно уравнению (58):  Вычисление начальной свертки использует циклы фиксированной длины для уменьшения сложности вычислений. Таким образом, исключаются непроизводительные затраты на установку структуры цикла переменной длины во внутреннем цикле (блоки 320-324) уравнения (58). Каждое значение Yo(n) после его вычисления посылается в минимизирующий процессор 412. Блок 416 проверяет указатель n выборки. Если n равно длине c подкадра кодового словаря, то первая свертка завершается и вычисления переходят к блоку 426. Если в блоке 416 n меньше, чем длина подкадра кодового словаря, то вычисления продолжаются в блоке 420. Блок 420 проверяет указатель m. Если m равно длине импульсного отклика фильтра, т.е. 20 в данном примере, то текущая итерация завершается и вычисления продолжаются в блоке 418, где m устанавливается на нуль, а n увеличивается. Затем вычисления возвращаются к блоку 416. Если в блоке 420 m меньше, чем длина импульсного отклика фильтра, т. е. 20, то вычисления переходят к блоку 424, где накапливаются частичные суммы. Вычисления продолжаются в блоке 422, где указатель m получает приращение, и вычисления переходят к блоку 420. Вычисления, включенные в цикл начальной свертки, образованный блоками 414-424, выполняются в ПЦОС 4, где предусмотрена соответствующая процедура конвейерной обработки, чтобы иметь возможность накапливать результаты, как показано в блоке 424. Следующие за этим операции представляют конвейерную процедуру вычислений и происходят в ПЦОС 4 в одном тактовом периоде. Значение h(m+1) отклика фильтра выбирается из ОЗУ А 104 и подается на регистр AREG 130. Значение СI(n) вектора кодового словаря выбирается из ПЗУ Е 114 и подается на регистр BREG 134. Частичная сумма Yo(n+m-1), находящаяся в регистре C0REG 164, подается в ОЗУ С 182 через мультиплексоры 168 и 180. Частичная сумма Yo(n+m+1) подается ОЗУ С 182 на регистр DREG 156. Значения h(m) и СI(n) в регистрах AREG 130 и BREG 134 соответственно подаются на перемножитель 132. Выходные данные перемножителя 132 подаются через мультиплексор 138 и заблокированный многорегистровый циклический сдвигатель 140 на первый вход сумматора 146. Частичая сумма Yo(n+m) подается регистром DREG 156 через мультиплексор 154, заблокированный ивертор 152 и заблокированный многорегистровый циклический сдвигатель 150 на второй вход сумматора 146. В данном примере выполнения кодовый словарь с гауссовым ограничением I(n) содержит большинство нулевых значений. Чтобы в этой ситуации получить такое преимущество, как свойство сокращения мощности, ПЦОС 4 сначала проверяет, равен ли вектор кодового словаря нулю в блоке 424. Если он равен нулю, то операция умножения и сложения, обычно выполняемая в блоке 424 и поясненная выше, пропускается. Эта процедура исключает операции умножения и сложения, занимающие во времени примерно 80%, сокращая тем самым мощность. Выходные данные сумматора 146 подаются через мультиплексор 148 на регистр С0REG 164. Значение в регистре C0REG 164 подается затем через мультиплексоры 168 и 180 в ОЗУ С 182. Когда указатель n достигает максимально допустимого значения в блоке 416, начальная свертка завершается и частичные суммы, представленные в ОЗУ С 182, являются теперь конечным результатом свертки. Когда начальная свертка завершается, вычисления продолжаются в блоке 426, где выполняется рекурсивная свертка в вычислениях для оставшихся значений указателя кодового словаря. В блоке 426 указатель n выборки устанавливается на 0, а указатель кодового словаря увеличивается. Вычисления продолжаются в блоке 428. Блок 428 проверяет I. Если I больше или равно 128, т.е. максимальному значению указателя кодового словаря в данном примере выполнения, то вычисления продолжаются в блоке 430, где операция поиска кодового словаря заканчивается. Если I меньше или равно 127, то вычисления продолжаются в блоке 432. Блок 432 управляет ранее описанной пинг-понговой операцией. В блоке 432 значение I проверяется на четность. Если I четно, то вычисления продолжаются в блоке 442 (операция, описанная как случай 1). Если I нечетно, то вычисления продолжаются в блоке 434 (операция, описанная как случай 2). Случай 1: (четные значения указателя I кодового словаря) В блоке 442 значение YI(0) вычисляется согласно уравнению (55). Адресный блок А 102 выдает адресное значение в ОЗУ А 104, которое в ответ выдает значение h(0) через мультиплексор 108 на регистр AREG 130. В том же самом тактовом периоде адресный блок Е 122 выдает адресное значение на ПЗУ Е 114, которое в ответ выдает значение СI(0) через мультиплексор 116 на регистр BREG 134. В течение следующего тактового периода регистр AREG 130 выдает h(0), а регистр BREG 134 выдает СI(0) на перемножитель 132, где два значения перемножаются и произведение подается через мультиплексор 138 и через заблокированный многорегистровый циклический сдвигатель 140 на первый вход сумматора 146. На второй вход сумматора 146 подается нуль через мультиплексор 154, заблокированный инвертирующий элемент 152 и многорегистровый циклической сдвигатель 150. Выходные данные сумматора 146 подаются на регистр C0REG 164 через мультиплексор 148. В том же самом тактовом периоде из ОЗУ В 122 и ОЗУ А 104 выбираются YI-4(0) и h(1) и подаются на регистры DREG 156, AREG 130 через мультиплексоры 158 и 100 соответственно. В блоке 444 указатель n выборки синтезированной речи увеличивается. В блоке 446 управления, если указатель n выборки синтезированной речи меньше, чем 20, вычисления переходят к блоку 448. В блоке 448 новое значение YI(n) вычисляется на каждом тактовом периоде согласно уравнению (56). Подходящая для этого установка, требуемая перед первой итерацией блока 448 для инициализации значений I-1(n-1) и h(n), получена в блоке 442, как описано выше. Вслед за последней итерацией блока 448 требуется также подходящая доводка для запоминания конечного значения Y (19). В первой итерации блока 448 значение YI(0), вычисленное в блоке 442, присутствует в регистре C0REG 164. Регистр C0REG 164 подает YI (0) через мультиплексоры 168 и 180 на ОЗУ С 182 для запоминания с адресными значениями, выданными в ОЗУ С 182 от адресного блока С 186. Значение YI(0) подается на минимизирующий процессор 412 и в то же время оно подается в ОЗУ С 182. В блоке 448 последующие операции выполняются в одном тактовом периоде. Значение YI-1(n) выдается из ОЗУ В 122 согласно адресу, выданному адресным блоком В 120, через мультиплексоры 116 и 158 на регистр DREG 156. Значение h(n+1) импульсного отклика подается из ОЗУ А 104 согласно адресу, выданному адресным блоком А 102,через мультиплексор 108 на регистр AREG 130. Регистр DREG 156 выдает значение YI-1(n-1) через мультиплексор 154, заблокированный инвертирующий элемент 152 и многорегистровый циклический сдвигатель 150 на первый вход сумматора 146. Регистр AREG 130 подает h(n), а регистр BREG 134 подает СI(n) на перемножитель 132, где два значения перемножаются и произведение подается перемножителем 132 через мультиплексор 138, через заблокированный многорегистровый циклический сдвигатель 140 на второй вход сумматора 146. Выходные данные сумматора 146 подаются через мультиплексор 148 на регистр C0REG 164. Значение в регистре C0REG 164, вычисленное в предыдущей итерации, подается через мультиплексоры 168 и 180 в ОЗУ С 182 для запоминания и в минимизирующий процессор 412. В блоке 446 управления, если указатель n выборки синтезированной речи равен 20, значение YI(19), вычисленное в последней итерации, подается через мультиплексоры 168 и 124 в ОЗУ В 122 для запоминания в кольцевом буфере и в минимизирующий процессор 412 перед тем, как вычисления переходят в блок 454. Конец случая 1 Случай 2: (нечетные значения указателя I кодового словаря) В блоке 434 значение YI(0) вычисляется согласно уравнению (55). Адресный блок А 102 выдает адресное значение в ОЗУ А 104, которое в ответ выдает значение h(0) через мультиплексор 108 на регистр AREG 130. В том же самом тактовом периоде адресный блок Б 122 выдает адресное значение на ПЗУ Е 114, которое в ответ выдает значение СI(0) через мультиплексор 116 на регистр BREG 134. В течение следующего тактового периода регистр АREG 130 выдает h(0), а регистр BREG 134 выдает СI(0) на перемножитель 132, где два значения перемножаются и произведение подается через мультиплексор 138 и через блокированный многорегистровый циклический сдвигатель 140 на первый вход сумматора 146. На второй вход сумматора 146 подается нуль через мультиплексор 154, заблокированный инвертирующий элемент 152 и многорегистровый циклический сдвигатель 150. Выход сумматора 146 подается на регистр C0REG 164 через мультиплексор 148. В том же тактовом периоде из ОЗУ С 182 и ОЗУ А 104 выбираются YI-1(0) и h(1) и подаются на регистры DREG 156, AREG 130 через мультиплексоры 158 и 100 соответственно. В блоке 436 указатель n выборки синтезированной речи увеличивается. В блоке 438 управления, если указатель n выборки синтезированной речи меньше, чем 20, вычисления переходят к блоку 440. В блоке 440 новое значение YI(n) вычисляется на каждом тактовом периоде согласно уравнению (56). Подходящая для этого установка, требуемая перед первой итерацией блока 440 для инициализации значений I-1(n-1) и h(n), получена в блоке 434, как описано выше. Вслед за последней итерацией блока 440 требуется также подходящая доводка для запоминания конечного значения YI(19). В первой итерации блока 440 значение YI(0), вычисленное в блоке 434, присутствует в регистре C0REG 164. Регистр C0REG 164 подает YI(0) через мультиплексоры 168 и 180 на ОЗУ В 122 для запоминания с адресными значениями, выданными в ОЗУ В 122 от адресного блока В 120. Значение YI(0) подается на минимизирущий процессор 412 и в то же время оно подается в ОЗУ В 122. В блоке 440 последующие операции выполняются в одном тактовом периоде. Значение YI-1(n) выдается из ОЗУ С 182 согласно адресу, выданному адресным блоком С 186, через мультиплексор 158 на регистр DREG 156. Значение h(n+1) импульсного отклика подается из ОЗУ А 104 согласно адресу, выданному адресным блоком А 102, через мультиплексор 108 на регистр AREG 130. Регистр BREG 156 выдает значение YI-1(n-1) через мультиплексор 154, заблокированный инвертирующий элемент 152 и многорегистровый циклический сдвигатель 150 на первый вход сумматора 146. Регистр AREG 130 подает h(n), а регистр BREG 134 подает CI(n) на перемножитель 132, где два значения перемножаются и произведение подается перемножителем 132 через мультиплексор 138, через заблокированный многорегистровый циклический сдвигатель 140 на второй вход сумматора 146. Выходные данные сумматора 146 подаются через мультиплексор 148 на регистр C0REG 164. Значение в регистре C0REG 164, вычисленное в предыдущей итерации, подается через мультиплексоры 168 и 124 в ОЗУ В 122 для запоминания и в минимизирующий процессор 412. В блоке 436 указатель n отсчета синтезированной речи увеличивается. В блоке 438 управления, если указатель n выборки синтезированной речи равен 20, значение YI(19), вычисленное в последней итерации, подается через мультиплексоры 168 и 124 в ОЗУ В 122 для запоминания в кольцевом буфере в ОЗУ В 122 и в минимизирующий процессор 412 перед тем, как вычисления переходят в блок 454. Конец случая 2 Перед первой итерацией блока 454 значение YI-1(19) выбирается из кольцевого буфера в ОЗУ В 122 и загружается в регистр ВREG 134. Затем значение YI-1(19) перемещается из регистра BREG 134 в регистр C0REG 164, после чего из кольцевого буфера в ОЗУ В 122 выбирается значение YI-1(20) и загружается в регистр BREG 134. В блоке 454 новое значение YI(n) вычисляется на каждом тактовом периоде согласно уравнению (57). Последующие операции выполняются в одном тактовом периоде. Значение YI-1(n-2) подается регистром BREG 134 на регистр С0REG 164. Значение YI-1(n-3) выбирается из кольцевого буфера в ОЗУ В 122 и загружается в регистр ВREG 134. Значение YI-1(n-1) присутствующее в регистре C0REG 164, подается в минимизирующий процессор 412. Вслед за последней итерацией блока 454 значение YI-1(Lc-2) стирается из кольцевого буфера в ОЗУ В 122. Путем добавления элемента в кольцевой буфер в ОЗУ В 122 и стирания элемента из кольцевого буфера в ОЗУ В 122 для каждого указателя кодового словаря размер кольцевого буфера сохраняется равным Lc-19. Реализация кольцевого буфера в ОЗУ В 122 осуществляется посредством специальных адресных регистров в адресном блоке В 120, которые задают точки циклического возврата так, что последовательная память может автоматически адресоваться циклически. В блоке 450 указатель n выборки синтезированной речи получает приращение. В блоке 452 управления, если указатель n выборки синтезированной речи меньше, чем Lc, то вычисления снова переходят к блоку 454. Если указатель n выборки синтезированной речи равен Lc, то для текущего значения I указателя кодового словаря вычисляются все значения YI(n), и вычисления возвращаются к блоку 426. Перед вычислением выборок YI(n) синтезированной речи на минимизирующий процессор 412 подается последовательность длины Lc взвешенных с учетом человеческого восприятия выборок xc(n) речевого сигнала. Как описано ранее, последовательность выборок YI(n) синтезированной речи длины Lc для значений векторного указателя кодового словаря от I=0 до I=127 подаются на минимизирующий процессор 412 во время вычислений начальной и рекурсивных сверток. Выборки синтезированной речи подаются на минимизирующий процессор 412 последовательно. Минимизирующий процессор 412 вычисляет автокорреляцию каждой последовательности выборок YI(n) синтезированной речи и взаимную корреляцию между каждой последовательностью выборок YI(n) синтезированной речи и последовательностью взвешенных с учетом человеческого восприятия выборок xc(n). По этим корреляционным значениям минимизирующий процессор 412 вычисляет затем относительную меру CKO между каждой последовательностью выборок YI(n) синтезированной речи и взвешенной с учетом человеческого восприятия последовательностью выборок xc(n). Для каждого векторного указателя I кодового словаря вычисляется СКО для всех возможных значений G усиления кодового словаря в последовательности выборок синтезированной речи. Минимизирующий процессор 412 отыскивает минимальную СКО по всем значениям I векторных указателей кодового словаря и всем возможным значениям G усиления кодового словаря путем сохранения минимальной СКО по текущему векторному указателю I кодового словаря и текущему усилению G кодового словаря. Оценка  векторного указателя кодового словаря и оценка векторного указателя кодового словаря и оценка  указателя усиления кодового словаря, соответствующие минимальной СКО, также сохраняются минимизирующим процессором 412. Каждое новое значение СКО сравнивается с минимальной СКО, сохраняемой в минимизирующем процессоре 412. Если новая СКО меньше, чем минимальная СКО, то минимальная СКО заменяется новым значением СКО, а оценка указателя усиления кодового словаря, соответствующие минимальной СКО, также сохраняются минимизирующим процессором 412. Каждое новое значение СКО сравнивается с минимальной СКО, сохраняемой в минимизирующем процессоре 412. Если новая СКО меньше, чем минимальная СКО, то минимальная СКО заменяется новым значением СКО, а оценка  векторного указателя кодового словаря и указатель векторного указателя кодового словаря и указатель  оценки усиления кодового словаря обновляются, чтобы отражать новую минимальную СКО. Минимальная СКО и соответствующие оценка оценки усиления кодового словаря обновляются, чтобы отражать новую минимальную СКО. Минимальная СКО и соответствующие оценка  векторного указателя кодового словаря и указателя векторного указателя кодового словаря и указателя  оценки усиления кодового словаря, сохраняемые в минимизирующем процессоре 412, инициализируются на каждом подкадре кодового словаря использованием первого значения СКО, вычисленного в течение подкадра кодового словаря. После того, как исчерпаны все векторные указатели I кодового словаря и все значения G усиления кодового словаря, оценка оценки усиления кодового словаря, сохраняемые в минимизирующем процессоре 412, инициализируются на каждом подкадре кодового словаря использованием первого значения СКО, вычисленного в течение подкадра кодового словаря. После того, как исчерпаны все векторные указатели I кодового словаря и все значения G усиления кодового словаря, оценка  векторного указателя кодового словаря и указатель векторного указателя кодового словаря и указатель  оценки усиления кодового словаря будут оптимальным векторным указателем кодового словаря и оптимальным указателем усиления кодового словаря соответственно для текущего подкадра кодового словаря. Минимизирующий процессор 412 выдает оптимальный векторный указатель оценки усиления кодового словаря будут оптимальным векторным указателем кодового словаря и оптимальным указателем усиления кодового словаря соответственно для текущего подкадра кодового словаря. Минимизирующий процессор 412 выдает оптимальный векторный указатель  кодового словаря и оптимальный указатель кодового словаря и оптимальный указатель  оценки усиления кодового словаря на ПЦОС 4 через входные порты 12. Оптимальным векторным указателем оценки усиления кодового словаря на ПЦОС 4 через входные порты 12. Оптимальным векторным указателем  и оптимальным указателем и оптимальным указателем  оценки усиления кодового словаря являются те, которые дают в результате минимальную СКО между взвешенными с учетом человеческого восприятия речевыми выборками xc(n) и взвешенными выборками YI(n) синтезированной речи. СКО является функцией от указателя I кодового словаря и усиления G кодового словаря, как описывается уравнениями (59)-(63): оценки усиления кодового словаря являются те, которые дают в результате минимальную СКО между взвешенными с учетом человеческого восприятия речевыми выборками xc(n) и взвешенными выборками YI(n) синтезированной речи. СКО является функцией от указателя I кодового словаря и усиления G кодового словаря, как описывается уравнениями (59)-(63):  =Еxcxc – 2GЕxcYI + G2EYIYI. (61) Еxcxc является автокорреляцией между взвешенными с учетом человеческого восприятия речевыми выборками xc(n). ЕxcYI есть взаимная корреляция между взвешенными с учетом человеческого восприятия выборками xc(n) и взвешенными выборками YI(n) синтезированной речи. EYIYI является автокорреляцией взвешенных с учетом человеческого восприятия выборками YI(n) синтезированной речи. Автокорреляция Еxcxc взвешенных с учетом человеческого восприятия речевых выборок xc(n) не является функцией усиления G кодового словаря. Величина Еxcxc остается постоянной в течение каждого подкадра кодового словаря и поэтому не влияет на выбор оптимального векторного указателя кодового словаря и оптимального усиления кодового словаря. Минимизация уравнений (59)-(61) по векторному указателю I кодового словаря и по усилению G кодового словаря эквивалентна минимизации уравнения (62): MSE(I,G)=-2GЕxсYI+G2EYIYI. (62) Минимизирующий процессор 412 вычисляет автокорреляции ЕYIYI последовательностей взвешенных выборок YI(n) синтезированной речи и взаимные корреляции ЕxcYI между последовательностью взвешенных с учетом человеческого восприятия речевых выборок хc(n) и последовательностями взвешенных выборок YI(n) синтезированной речи. Для каждой корреляционной пары (ЕxсYI, EYIYI) минимизирующий процессор 412 вычисляет относительную СКО согласно уравнению (62) для набора значений усиления G кодового словаря. Вычисления корреляций ЕxcYI и ЕYI-YI выполняются одновременно в минимизирующем процессоре 412. Вычисляются относительные значения СКО и принимается решение относительно минимизации СКО для векторного указателя I, тогда как корреляционные значения вычисляются для векторного указателя I+1 кодового словаря. Фиг. 6а и 6b представляют пример выполнения минимизирующего процессора 412. Взвешенные с учетом человеческого восприятия речевые выборки xc(n) подаются ПЦОС 4 на фиксатор 210 для запоминания в ОЗУ Х 212 согласно адресу, выдаваемому блоком 220 управления. На минимизирующий процессор 412 от ПЦОС 4 подаются два набора значений усиления кодового словаря. Один набор – для положительных значений G усиления кодового словаря, а второй набор – для отрицательных значений -G усиления кодового словаря. Для полной скорости и половинной скорости с ПЦОС 4 через мультиплексор 260 выдаются масштабированные значения -2G усиления кодового словаря, для величин от G=-4,0 дБ до G= +8,0 дБ ступенями по +4,0 дБ для запоминания в фиксаторах 292, 288, 284 и 280 соответственно. Для скорости в одну четверть и одну восьмую с ПЦОС 4 через мультиплексор 260 выдаются масштабированные значения -2G усиления кодового словаря, для величин от G=-4,0 дБ до G=+2,0 дБ ступенями по +2,0 дБ для запоминания в фиксаторах 292, 288, 284 и 280 соответственно. Соответствующие масштабированные значения G усиления кодового словаря выдаются через мультиплексор 260 для запоминания в фиксаторах 290, 286, 282 и 278 соответственно. Для полной скорости и половинной скорости через мультиплексор 260 выдаются масштабированные значения 2G усиления кодового словаря, для величин от G= -4,0 дБ до G=+8,0 дБ ступенями по +4,0 дБ, для запоминания в фиксаторах 276, 272, 268 и 264 соответственно. Для скорости в одну четверть и одну восьмую через мультиплексор 260 выдаются масштабированные значения 2G усиления кодового словаря, для величин от G=-4,0 дБ до G=+2,0 дБ ступенями по +2,0 дБ, для запоминания в фиксаторах 276, 272, 268 и 264 соответственно. Соответствующие масштабированные значения G усиления подаются через мультиплексор 260 для запоминания в фиксаторах 274, 270, 266 и 262 соответственно. Мультиплексор 260 выдает значения непосредственно на фиксатор 262. Фиксатор 262 выдает значения непосредственно на фиксатор 264. Фиксатор 276 выдает значения на фиксатор 278 через мультиплексор 294. Фиксатор 290 выдает значения непосредственно на фиксатор 292 и т.д. Сдвигающиеся через фиксаторы 262-292 и мультиплексор 294 значения позволяют подавать значения через мультиплексор 260 на все фиксаторы в кольцевом буфере 259. В поиске кодового словаря в кольцевом буфере 259 образуются два кольцевых буфера. Вслед за запоминанием взвешенных с учетом человеческого восприятия речевых выборок xc(n) и с запоминанием значений усиления кодового словаря, на фиксатор 210 подаются последовательности взвешенных выборок I(n) синтезированной речи. Взвешенные выборки YI(n) синтезированной речи подаются фиксатором 210 на два входа перемножителя 216, который вырабатывает квадраты (YI(n))2 взвешенных выборок синтезированной речи. Фиксатор 210 выдает также взвешенные выборки YI(n) синтезированной речи на первый вход перемножителя 218. ОЗУ Х 212 выдает взвешенные с учетом человеческого восприятия выборки xc(n) через фиксатор 214 на второй вход перемножителя 218. Перемножитель 218 вычисляет значения произведения xc(n)YI(n). Новые величины квадрата (YI(n))2 и новые величины произведения xc(n)YI(n) вычисляются на каждом тактовом периоде перемножителями 216 и 218 соответственно. Указатель n выборки изменяется от 0 до lc-1 для каждого векторного указателя I кодового словаря. Квадраты (YI(n))2 взвешенных выборок синтезированной речи подаются на накопитель 221. Значения произведений хc(n)YI(n) подаются на накопитель 231. Накопитель 231 вычисляет сумму из Lc квадратов для каждого векторного указателя I кодового словаря. Накопитель 231 вычисляет сумму из Lc значений произведений для каждого векторного указателя I кодового словаря. Перед каждым новым векторным указателем кодового словаря на фиксатор 226 подается нуль через мультиплексор 224. Накопитель 221 готов после этого вычислять автокорреляцию EYIYI для текущего векторного указателя I кодового словаря. В накопителе 221 квадраты (YI(n))2 подаются на первый вход сумматора 222. Текущая сумма подается фиксатором 226 на второй вход сумматора 222. Вновь вычисленная текущая сумма подается сумматором 222 через мультиплексор 224 на фиксатор 226 для запоминания. После накопления по всем Lc значениям для векторного указателя I кодового словаря автокорреляция EYIYI подается в фиксатор 228 для запоминания. Перед каждым новым векторным указателем кодового словаря на фиксатор 236 подается нуль через мультиплексор 234. Накопитель 231 готов после этого вычислять взаимную корреляцию ЕxcYI для текущего векторного указателя I кодового словаря. В накопителе 231 произведения хc(n)YI(n) подаются на первый вход сумматора 232. Текущая сумма подается фиксатором 236 на второй вход сумматора 232. Вновь вычисленная текущая сумма подается сумматором 232 через мультиплексор 234 на фиксатор 236 для запоминания. После накопления по всем Lc значениям для векторного указателя I кодового словаря взаимная корреляция ЕхcYI подается в фиксатор 238 для запоминания. Затем вычисляется СКО, описываемая уравнением (62) в двухпериодном процессе, описанном ниже. В первом из двух периодов фиксатор 238 подает взаимную корреляцию ЕxcYI между взвешенными с учетом человеческого восприятия речевыми выборками и взвешенными выборками синтезированной речи через мультиплексор 230 на первый вход перемножителя 240. Блок 220 управления отслеживает значение ЕxcYI, выданное фиксатором 238. Если значение ЕxcYI неотрицательно, то фиксатор 292 выдает через мультиплексор 296 на второй вход перемножителя 240 масштабированное значение -2G усиления кодового словаря. Перемножитель 240 выдает произведение -2GЕxcYI на первый вход сумматора 242. Если же значение ЕxcYI отрицательно, то фиксатор 276 выдает масштабированное значение 2G усиления кодового словаря на второй вход перемножителя 240 через мультиплексор 296. Произведение 2GЕхcYI подается перемножителем 240 на первый вход сумматора 242. На второй вход сумматора 242 подается нуль через мультиплексор 246. Выход сумматора 242 подается на фиксатор 244 для запоминания. Знак величины ЕхcYI запоминается в блоке 220 управления. Знаки, равные единице и нулю для всех ЕxcYI, соответствуют отрицательным и неотрицательным значениям ЕхcYI соответственно. Значения в фиксаторах 262-276 циклически сдвигаются подачей выхода фиксатора 276 на фиксатор 262 через мультиплексор 260. После циклического сдвига фиксаторы 262, 264, 266, 268, 270, 272, 274 и 276 содержат значения, прежде содержавшиеся в фиксаторах 276, 262, 264, 266, 268, 270, 272 и 274 соответственно. Значения в фиксаторах 278-292 циклически сдвигаются подачей выхода фиксатора 292 на фиксатор 278 через мультиплексор 294. После циклического сдвига фиксаторы 278, 280, 282, 284, 286, 288, 290 и 292 содержат значения, прежде содержавшиеся в фиксаторах 292, 278, 280, 282, 284, 286, 288 и 290 соответственно. Один кольцевой буфер образован фиксаторами 262-276 и мультиплексором 260. Второй кольцевой буфер образован фиксаторами 278-292 и мультиплексором 294. Путем циклического сдвига значений в первом из двух кольцевых буферов в кольцевом буфере 259 фиксатор 292 выдает величины -2G и G2 в первом и втором периодах соответственно. Путем кольцевого сдвига во втором из двух кольцевых буферов в кольцевом буфере 259 фиксатор 276 выдает величины 2G и G2 в первом и втором периодах соответственно. Для каждой пары значений корреляции и взаимной корреляции только один набор из пар усилений кодового словаря выдается кольцевым буфером 259. Набор пар усиления кодового словаря для отрицательных значений ЕxcYI выдается кольцевым буфером, состоящим из фиксаторов 262-276 и мультиплексора 260. Набор пар усилений кодового словаря для неотрицательных значений ЕхcYI выдается кольцевым буфером, состоящим из фиксаторов 278-292 и мультиплексора 294. Во втором из двух периодов фиксатор 228 выдает значения ЕYIYI через мультиплексор 230 на первый вход перемножителя 240. Через мультиплексор 296, фиксаторы 276 и 292 подается значение G2 усиления кодового словаря на второй вход перемножителя 240 для отрицательных и неотрицательных значений ЕxcYI соответственно. Произведение G2ЕхcYI подается перемножителем 240 на первый вход сумматора 242. На второй вход сумматора 242 подается выход фиксатора 244  2GЕxcYI через мультиплексор 246. Сумматор 242 выдает 2GЕxcYI+G2ЕYIYI на фиксатор 244 для запоминания. Значения в фиксаторах 262-292 кольцевого буфера 259 затем подвергаются кольцевому сдвигу, как описано выше.
Вышеописанный двухпериодный процесс повторяется для всех четырех пар (+2G, G2) значений усиления кодового словаря для каждого указателя I кодового словаря. В течение двух периодов, следующих за вычислением текущего значения СКО 2GExcYI+G2ЕYIYI, вычисляется новое значение СКО с использованием следующей пары значений +2G и G2. Перед тем, как фиксатор 244 обновляется новым значением СКО, текущее значение СКО сравнивается с минимальным СКО для текущего подкадра кодового словаря, запомненного в фиксаторе 250. Текущее значение СКО 2GЕxcYI+G2ЕYIYI выдается фиксатором 244 на вход уменьшаемого вычитателя 248. Фиксатор 250 выдает текущее значение минимальной СКО на вход вычитаемого вычитателя 248. Блок 220 управления отслеживает результирующий выходной сигнал разности с вычитателя 248. Если разность отрицательна, текущее значение СКО является новой минимальной СКО для текущего подкадра кодового словаря и запоминается в фиксаторе 250, а соответствующие оценка 2GЕxcYI через мультиплексор 246. Сумматор 242 выдает 2GЕxcYI+G2ЕYIYI на фиксатор 244 для запоминания. Значения в фиксаторах 262-292 кольцевого буфера 259 затем подвергаются кольцевому сдвигу, как описано выше.
Вышеописанный двухпериодный процесс повторяется для всех четырех пар (+2G, G2) значений усиления кодового словаря для каждого указателя I кодового словаря. В течение двух периодов, следующих за вычислением текущего значения СКО 2GExcYI+G2ЕYIYI, вычисляется новое значение СКО с использованием следующей пары значений +2G и G2. Перед тем, как фиксатор 244 обновляется новым значением СКО, текущее значение СКО сравнивается с минимальным СКО для текущего подкадра кодового словаря, запомненного в фиксаторе 250. Текущее значение СКО 2GЕxcYI+G2ЕYIYI выдается фиксатором 244 на вход уменьшаемого вычитателя 248. Фиксатор 250 выдает текущее значение минимальной СКО на вход вычитаемого вычитателя 248. Блок 220 управления отслеживает результирующий выходной сигнал разности с вычитателя 248. Если разность отрицательна, текущее значение СКО является новой минимальной СКО для текущего подкадра кодового словаря и запоминается в фиксаторе 250, а соответствующие оценка  векторного указателя кодового словаря и указатель векторного указателя кодового словаря и указатель  оценки усиления кодового словаря обновляются в блоке 220 управления. Если разность не отрицательна, текущее значение СКО игнорируется.
Перед каждым подкадром кодового словаря ПЦОС 4 выдает команду на минимизирующий процессор 412, информируя блок 220 управления о том, что следует новый подкадр кодового словаря. По получении этой команды текущий векторный указатель кодового словаря и текущий указатель усиления кодового словаря устанавливаются на 0 в блоке 220 управления. Перед тем, как каждая новая последовательность взвешенных выборок синтезированной речи подается на минимизирующий процессор 412, ПЦОС 4 подает команду на минимизирующий процессор 412, информируя блок 220 управления о том, что следует новая последовательность взвешенных выборок синтезированной речи. По получении этой команды блок 220 управления увеличивает текущий векторный указатель кодового словаря и текущий указатель усиления кодового словаря на 1, соответствующую приращению векторного указателя кодового словаря на 1 и приращению усиления кодового словаря на 2 дБ или 4 дБ в зависимости от скорости. Во время же подачи первой последовательности взвешенных выборок синтезированной речи на минимизирующий процессор 412 текущий векторный оценки усиления кодового словаря обновляются в блоке 220 управления. Если разность не отрицательна, текущее значение СКО игнорируется.
Перед каждым подкадром кодового словаря ПЦОС 4 выдает команду на минимизирующий процессор 412, информируя блок 220 управления о том, что следует новый подкадр кодового словаря. По получении этой команды текущий векторный указатель кодового словаря и текущий указатель усиления кодового словаря устанавливаются на 0 в блоке 220 управления. Перед тем, как каждая новая последовательность взвешенных выборок синтезированной речи подается на минимизирующий процессор 412, ПЦОС 4 подает команду на минимизирующий процессор 412, информируя блок 220 управления о том, что следует новая последовательность взвешенных выборок синтезированной речи. По получении этой команды блок 220 управления увеличивает текущий векторный указатель кодового словаря и текущий указатель усиления кодового словаря на 1, соответствующую приращению векторного указателя кодового словаря на 1 и приращению усиления кодового словаря на 2 дБ или 4 дБ в зависимости от скорости. Во время же подачи первой последовательности взвешенных выборок синтезированной речи на минимизирующий процессор 412 текущий векторныйуказатель кодового словаря и текущий указатель усиления кодового словаря будут равны 1, что соответствует векторному указателю кодового словаря, равному 0, и усилению кодового словаря G=-8 дБ или G=-4 дБ в зависимости от скорости. В течение каждого подкадра кодового словаря первая СКО запоминается в фиксаторе 250, а соответствующие оценка I векторного указателя кодового словаря и указатель G оценки усиления кодового словаря обновляются в блоке 220 управления. Это делается для того, чтобы инициализировать минимальную СКО в фиксаторе 250 на каждом подкадре кодового словаря. Векторный указатель кодового словаря и указатель усиления кодового словаря, соответствующие оценке минимальной СКО, будут подаваться блоком 220 управления на ПЦОС 4 вместе со знаком взаимной корреляции ЕхcYI, соответствующей минимальной СКО. Если ПЦОС 4 примет нуль в качестве знака ЕxcYI, он установит оптимальное усиление кодового словаря равным G. Если ПЦОС 4 примет единицу в качестве знака ЕxcYI, он установит оптимальное усиление кодового словаря равным -G. ПЦОС 4 использует оценку векторного указателя кодового словаря и указатель оценки усиления кодового словаря, выдаваемые блоком 220 управления, для определения оптимального вектора кодового словаря и оптимального усиления кодового словаря. Для полной и половинной скорости оптимальное усиление G кодового словаря составляет -4 дБ, 0 дБ, +4 дБ и +8 дБ для указателей усиления кодового словаря от G=1 до G=4 соответственно. Для скорости в одну четверть и одну восьмую оптимальное усиление G кодового словаря составляет -4 дБ, -2 дБ, 0 дБ и +2 дБ для указателей усиления кодового словаря от G=1 до G=4 соответственно. В поиске кодового словаря свойства функции СКО MSЕ(I, G) уравнения (62) позволяют обеспечить сокращение объема вычислений. Остающиеся вычисления СКО для текущего вектора кодового словаря могут быть отброшены, когда определено, что остающиеся значения СКО, еще подлежащие вычислению для текущего вектора кодового словаря, не могут повлиять на значение СКО, которое меньше, чем текущая минимальная СКО, запомненная в фиксаторе 250. В рассматриваемом примере выполнения в минимизирующем процессоре 412 используются три метода для сокращения вычислений в кодовом поиске. Функции СКО МSЕ(I, G) являются квадратичными от G. Одно квадратичное уравнение образуется для каждого векторного указателя I кодового словаря. Все эти квадратичные уравнения пропускаются через начальные условия G =0 и MSE(I,G)=0. Первый способ сокращения вычислений включает в себя поиск по восьми положительным или отрицательным значениям усиления кодового словаря в зависимости от знака ЕxcYI. Отрицательное значение ExcYI и отрицательное значение усиления будут проявляться в отрицательном значении для выражения -2GЕxcYI уравнения (62). Положительное значение ЕxcYI и положительное значение усиления также будут проявляться в отрицательном значении для выражения -2GЕxcYI уравнения (62). Поскольку выражение G2ЕYIYI уравнения (62) всегда положительно, отрицательное значение выражения -2GЕxcYI будет стремиться минимизировать СКО. На кольцевой буфер 259 подаются два набора пар усиления кодового словаря, один с положительными значениями усиления кодового словаря, а второй с отрицательными значениями усиления кодового словаря. Таким образом, только четыре пары значений усиления необходимо для использования вместо восьми пар усиления для каждого векторного указателя I кодового словаря. Второй способ сокращения вычислений включает в себя отбрасывание вычислений остающихся значений СКО в процедуре поиска кодового словаря текущего вектора кодового словаря на основании квадратичной природы функции СКО. Функция СКО МSЕ(I, G) вычисляется для значений усиления кодового словаря, которые возрастают монотонно. Когда положительное значение СКО вычисляется для текущего вектора кодового словаря, все оставшиеся вычисления СКО для текущего вектора кодового словаря отбрасываются, поскольку соответствующие значения СКО будут больше, чем текущее значение СКО. Третий способ сокращения вычислений включает в себя отбрасывание вычислений остающихся значений СКО в процедуре поиска кодового словаря текущего векторного указателя кодового словаря на основании квадратичной природы функции СКО. Функция СКО MSE(I,G) вычисляется для значений усиления кодового словаря, которые изменяются монотонно. Когда значение СКО вычисляется в текущем векторе кодового словаря, который определяется как новая минимальная СКО, и когда значение СКО вычислено в текущем векторе кодового словаря, который был определен как новая минимальная СКО, все оставшиеся вычисления СКО в текущем векторе кодового словаря отбрасываются, поскольку эти оставшиеся значения СКО не могут быть меньше, чем новая минимальная СКО. Три вышеописанных способа сокращения вычислений обеспечивают значительное сбережение мощности в минимизирующем процессоре 412. В блоке 84 квантуются значения кодового словаря. Блок 86 проверяет, обработаны ли все подкадры кодового словаря. Если все подкадры кодового словаря не обработаны, то вычисления возвращаются к блоку 80. Если обработаны все подкадры кодового словаря, то вычисления переходят в блок 88. Блок 88 проверяет, все ли подкадры основного тона обработаны. Если все подкадры основного тона не обработаны, вычисления возвращаются в блок 70. Если обработаны все подкадры основного тона, то вычисления переходят в блок 90. В блоке 90 кодированные результаты компонуются в специальный формат. При полной скорости микропроцессором (не показан) считываются 22 байта данных. При половинной скорости считываются 10 байтов, при скорости в одну четверть считываются 5 байтов, а при скорости в одну восьмую считываются 2 байта. При полной скорости генерируются 11 разрядов проверки четности для обеспечения исправления и обнаружения ошибок для 18 наиболее важных разрядов в данных, передаваемых на полной скорости. Кодер в передатчике должен поддерживать состояние декодера в приемнике для того, чтобы обновлять память фильтров, которые в свою очередь используются кодером в процедурах поиска основного тона и поиска кодового словаря. В иллюстративном выполнении кодер содержит вариант декодера, который используется после каждого подкадра кодового словаря. Последующие операции декодирования выполняются в ПЦОС 4 как часть кодера. Согласно фиг.11, оптимальный векторный указатель  кодового словаря и оптимальное усиление кодового словаря и оптимальное усиление  кодового словаря, определенные для текущего подкадра кодового словаря, используются для генерирования масштабированного вектора Сd(n) кодового словаря. За исключением скорости в одну восьмую, блок 502 кодового словаря снабжается оптимальным указателем кодового словаря, определенные для текущего подкадра кодового словаря, используются для генерирования масштабированного вектора Сd(n) кодового словаря. За исключением скорости в одну восьмую, блок 502 кодового словаря снабжается оптимальным указателем  кодового словаря, определенным для текущего подкадра кодового словаря, и в ответ на это выдает соответствующий вектор возбуждения на первый вход перемножителя 504. В случае скорости в одну восьмую для Сd(n) генератором 500 псевдослучайного вектора генерируется псевдослучайная последовательность и подается на первый вход перемножителя 504. Оптимальное усиление кодового словаря, определенным для текущего подкадра кодового словаря, и в ответ на это выдает соответствующий вектор возбуждения на первый вход перемножителя 504. В случае скорости в одну восьмую для Сd(n) генератором 500 псевдослучайного вектора генерируется псевдослучайная последовательность и подается на первый вход перемножителя 504. Оптимальное усиление  кодового словаря, определенное для текущего подкадра кодового словаря, подается на второй вход перемножителя 504. Эта последовательность генерируется той же самой операцией псевдослучайного генерирования, которая используется декодером в приемнике.
Масштабированные векторы Сd(n) кодового словаря подаются на фильтр 506 синтеза основного тона, который генерирует формантный остаток Pd(n). Памяти фильтра синтеза основного тона инициализируются конечным состоянием, соответствующим последней выборке генерируемой речи. Фильтр 506 синтеза основного тона использует оптимальный период кодового словаря, определенное для текущего подкадра кодового словаря, подается на второй вход перемножителя 504. Эта последовательность генерируется той же самой операцией псевдослучайного генерирования, которая используется декодером в приемнике.
Масштабированные векторы Сd(n) кодового словаря подаются на фильтр 506 синтеза основного тона, который генерирует формантный остаток Pd(n). Памяти фильтра синтеза основного тона инициализируются конечным состоянием, соответствующим последней выборке генерируемой речи. Фильтр 506 синтеза основного тона использует оптимальный период  основного тона и оптимальное усиление основного тона и оптимальное усиление  основного тона, определенные для текущего подкадра основного тона. Для скорости в одну восьмую оптимальное усиление основного тона устанавливается на нуль.Конечное состояние памятей синтезирующего фильтра основного тона сохраняется для использования при генерировании речи для следующего подкадра основного тона, как упомянуто выше, и для использования в последующих операциях поиска основного тона и декодирования в кодере.
Взвешенный формантный синтезирующий фильтр 508 генерирует выход Yd(n) из формантного остатка Pd(n). Этот фильтр инициализируется конечным состоянием, получаемым из последней выборки генерируемой речи. Коэффициенты КЛП, вычисленные из интерполированных значений ЛСП для текущего подкадра, используются в качестве коэффициентов для этого фильтра. Конечное состояние этого фильтра сохраняется для использования в генерировании речи для следующего подкадра кодового словаря и для использования в последующих поисках основного тона и кодового словаря.
Декодирующая операция, показанная блоками 44 и 50 на фиг.2, выполняется в ПЦОС 4. КСПО принимает пакет в специальном формате от микропроцессора (не показан) через микропроцессорный интерфейс 42. ПЦОС 4 декодирует данные в этом пакете и использует их для синтезирования речевых выборок, которые подаются на кодек (не показан) через интерфейс 2 ИКМ. В ПЦОС 4 принятый пакет данных распаковывается для получения данных, необходимых для синтезирования речевых выборок. Данные включают в себя скорость кодирования, частоты ЛСП и параметры основного тона и кодового словаря для соответствующих подкадров на этой скорости. Синтез речевых выборок из принятых пакетных данных выполняется в ПЦОС 4 и показан на фиг.12.
Согласно фиг. 12, оптимальный векторный указатель основного тона, определенные для текущего подкадра основного тона. Для скорости в одну восьмую оптимальное усиление основного тона устанавливается на нуль.Конечное состояние памятей синтезирующего фильтра основного тона сохраняется для использования при генерировании речи для следующего подкадра основного тона, как упомянуто выше, и для использования в последующих операциях поиска основного тона и декодирования в кодере.
Взвешенный формантный синтезирующий фильтр 508 генерирует выход Yd(n) из формантного остатка Pd(n). Этот фильтр инициализируется конечным состоянием, получаемым из последней выборки генерируемой речи. Коэффициенты КЛП, вычисленные из интерполированных значений ЛСП для текущего подкадра, используются в качестве коэффициентов для этого фильтра. Конечное состояние этого фильтра сохраняется для использования в генерировании речи для следующего подкадра кодового словаря и для использования в последующих поисках основного тона и кодового словаря.
Декодирующая операция, показанная блоками 44 и 50 на фиг.2, выполняется в ПЦОС 4. КСПО принимает пакет в специальном формате от микропроцессора (не показан) через микропроцессорный интерфейс 42. ПЦОС 4 декодирует данные в этом пакете и использует их для синтезирования речевых выборок, которые подаются на кодек (не показан) через интерфейс 2 ИКМ. В ПЦОС 4 принятый пакет данных распаковывается для получения данных, необходимых для синтезирования речевых выборок. Данные включают в себя скорость кодирования, частоты ЛСП и параметры основного тона и кодового словаря для соответствующих подкадров на этой скорости. Синтез речевых выборок из принятых пакетных данных выполняется в ПЦОС 4 и показан на фиг.12.
Согласно фиг. 12, оптимальный векторный указатель  кодового словаря и оптимальное усиление кодового словаря и оптимальное усиление  кодового словаря, соответствующие текущему подкадру кодового словаря, используются декодером для генерирования масштабированных векторов Сd(n) кодового словаря. За исключением скорости в одну восьмую, блок 522 кодового словаря снабжается оптимальным указателем кодового словаря, соответствующие текущему подкадру кодового словаря, используются декодером для генерирования масштабированных векторов Сd(n) кодового словаря. За исключением скорости в одну восьмую, блок 522 кодового словаря снабжается оптимальным указателем  кодового словаря, соответствующим текущему подкадру кодового словаря, и в ответ на это выдает соответствующий вектор возбуждения на первый вход перемножителя 524. В случае скорости в одну восьмую для Cd(n) генератором 520 псевдослучайного вектора генерируется псевдослучайная последовательность и подается на первый вход перемножителя 524. Эта последовательность генерируется той же самой операцией псевдослучайного генерирования, которая используется декодером в приемнике. Оптимальное усиление кодового словаря, соответствующим текущему подкадру кодового словаря, и в ответ на это выдает соответствующий вектор возбуждения на первый вход перемножителя 524. В случае скорости в одну восьмую для Cd(n) генератором 520 псевдослучайного вектора генерируется псевдослучайная последовательность и подается на первый вход перемножителя 524. Эта последовательность генерируется той же самой операцией псевдослучайного генерирования, которая используется декодером в приемнике. Оптимальное усиление  кодового словаря, соответствующее текущему подкадру кодового словаря, подается на второй вход перемножителя 524.
Масштабированные векторы Cd(n) кодового словаря подаются на фильтр 526 синтеза основного тона, который генерирует формантный остаток Рd(n). Памяти фильтра синтеза основного тона инициализируются конечным состоянием, соответствующим последней выборке генерируемой речи. Фильтр 526 синтеза основного тона использует оптимальный период кодового словаря, соответствующее текущему подкадру кодового словаря, подается на второй вход перемножителя 524.
Масштабированные векторы Cd(n) кодового словаря подаются на фильтр 526 синтеза основного тона, который генерирует формантный остаток Рd(n). Памяти фильтра синтеза основного тона инициализируются конечным состоянием, соответствующим последней выборке генерируемой речи. Фильтр 526 синтеза основного тона использует оптимальный период  основного тона и оптимальное усиление основного тона и оптимальное усиление  основного тона, определенные для текущего подкадра основного тона. Для скорости в одну восьмую оптимальное усиление основного тона устанавливается на 0. Конечное состояние фильтра синтеза основного тона сохраняется для использования при генерировании речи для следующего подкадра основного тона, как упомянуто выше.
Взвешенный формантный фильтр 526 синтеза генерирует выходной сигнал Yо(n) из формантного остатка Рd(n). Этот фильтр инициализируется конечным состоянием, соответствующим последней выборке генерируемой речи. Коэффициенты КЛП, вычисленные из интерполированных значений ЛСП для текущего подкадра, используются в качестве коэффициентов для этого фильтра. Конечное состояние этого фильтра сохраняется для использования при генерировании речи для следующего подкадра кодового словаря.
Декодированная речь Yd(n) подается на оконечный фильтр 53, который в данном примере выполнения является выходным фильтром установившегося состояния, основанным на использовании коэффициентов КПП, для текущего декодируемого подкадра. Выходной фильтр 530 фильтрует восстановленные речевые выборки Yd(n) и подает отфильтрованную речь на блок 532 управления усилением. Блок 532 управления усилением управляет уровнем выходной речи Sd(n) и может осуществлять автоматическую регулировку усиления (АРУ).
Предыдущее описание предпочтительных выполнений представлено для того, чтобы дать возможность любому специалисту в этой технике осуществить или использовать настоящее изобретение. Различные модификации таких выполнений должны быть понятны для специалистов, а основополагающие принципы, определенные здесь, могут применяться и в других примерах, без дополнительного изобретательства. Таким образом, настоящее изобретение не ограничено показанными здесь примерами выполнения, а характеризуется наиболее широким объемом, определяемым изложенными выше принципами и новыми признаками. основного тона, определенные для текущего подкадра основного тона. Для скорости в одну восьмую оптимальное усиление основного тона устанавливается на 0. Конечное состояние фильтра синтеза основного тона сохраняется для использования при генерировании речи для следующего подкадра основного тона, как упомянуто выше.
Взвешенный формантный фильтр 526 синтеза генерирует выходной сигнал Yо(n) из формантного остатка Рd(n). Этот фильтр инициализируется конечным состоянием, соответствующим последней выборке генерируемой речи. Коэффициенты КЛП, вычисленные из интерполированных значений ЛСП для текущего подкадра, используются в качестве коэффициентов для этого фильтра. Конечное состояние этого фильтра сохраняется для использования при генерировании речи для следующего подкадра кодового словаря.
Декодированная речь Yd(n) подается на оконечный фильтр 53, который в данном примере выполнения является выходным фильтром установившегося состояния, основанным на использовании коэффициентов КПП, для текущего декодируемого подкадра. Выходной фильтр 530 фильтрует восстановленные речевые выборки Yd(n) и подает отфильтрованную речь на блок 532 управления усилением. Блок 532 управления усилением управляет уровнем выходной речи Sd(n) и может осуществлять автоматическую регулировку усиления (АРУ).
Предыдущее описание предпочтительных выполнений представлено для того, чтобы дать возможность любому специалисту в этой технике осуществить или использовать настоящее изобретение. Различные модификации таких выполнений должны быть понятны для специалистов, а основополагающие принципы, определенные здесь, могут применяться и в других примерах, без дополнительного изобретательства. Таким образом, настоящее изобретение не ограничено показанными здесь примерами выполнения, а характеризуется наиболее широким объемом, определяемым изложенными выше принципами и новыми признаками.
Формула изобретения
РИСУНКИ
|
||||||||||||||||||||||||||