Патент на изобретение №2398272
|
||||||||||||||||||||||||||
(54) СПОСОБ И СИСТЕМА ДЛЯ ИНДЕКСИРОВАНИЯ И ПОИСКА В БАЗАХ ДАННЫХ
(57) Реферат:
Поисковая система создает индекс для баз данных путем порождающей выборки баз данных и использует этот индекс для идентификации и формулирования запросов для поиска в базах данных. Созданный индекс называется индексом домен-атрибут и содержит индекс на уровне домена и индексы на уровне сайта. Индекс на уровне сайта для базы данных отображает атрибуты сайта в определенные значения атрибутов в базе данных. Индекс на уровне домена для домена отображает значения атрибута в пары атрибутов базы данных и сайта, которые содержат значения этих атрибутов. Для создания индекса на уровне сайта для базы данных в определенном домене поисковая система начинает с начального набора выборочных данных для этого домена. Поисковая система создает запросы выборки на основе выборочных данных и подает запросы выборки в базу данных. Поисковая система обновляет индекс на уровне сайта на основе результатов выборки и использует эти результаты для создания дополнительных запросов выборки. Технический результат – повышение эффективности поиска. 4 н. и 23 з.п. ф-лы, 10 ил.
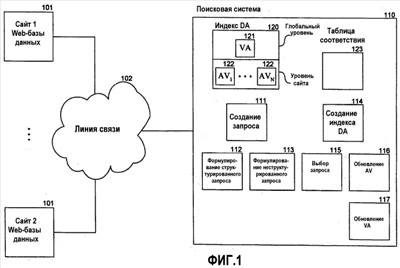
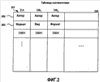
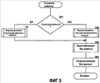
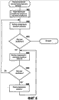
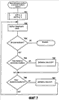
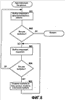
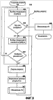
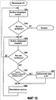
Область техники, к которой относится изобретение Описанная технология относится в общем случае к поиску в базах данных и, в частности, касается поиска в Web-базах данных. Уровень техники Всемирная Паутина («Сеть») обеспечивает огромный объем информации, которая доступна через Web-страницы. Web-страницы могут содержать либо статический контент, либо динамический контент. Статический контент относится обычно к информации, которая может оставаться неизменной на протяжении множества обращений к Web-странице. Динамический контент обычно относится к информации, которая хранится в Web-базе данных, и добавляется в Web-страницу в ответ на поисковый запрос. Динамический контент представляет собой то, что называют углубленной Сетью или скрытой Сетью. Услуги множества поисковых механизмов дают возможность пользователям осуществлять поиск статического контента в Сети. После того, как пользователь подал поисковое требование или запрос, который включает в себя условия поиска, служба поискового механизма идентифицирует Web-страницы, которые могут иметь отношение к указанным условиям поиска. Эти Web-страницы являются результатом поиска. Для быстрой идентификации соответствующих Web-страниц услуги поискового механизма могут поддерживать отображение ключевых слов в Web-страницы. Это отображение может быть создано путем «медленного продвижения» по Сети для идентификации ключевых слов каждой Web-страницы. Для медленного продвижения по Сети служба поискового механизма может использовать список корневых Web-страниц для идентификации всех Web-страниц, которые доступны через упомянутые корневые Web-страницы. Ключевые слова любой конкретной Web-страницы можно идентифицировать, используя различные и хорошо известные способы извлечения информации, такие как идентификация слов заголовка, слов, предоставляемых в метаданных Web-страницы, специально выделенных слов и т.п. Однако указанные услуги поискового механизма в общем случае не обеспечивают поиск в динамическом контенте, который также рассматривают как контент, который не подлежит медленному просмотру. Одна из проблем, связанная с поиском в динамическом контенте, заключается в том, что контент Web-баз данных невозможно эффективно извлекать и индексировать по нескольким причинам. Одна из причин состоит в том, что объем контента множества Web-баз данных может быть слишком велик, для того чтобы его можно было извлечь и индексировать. Другой причиной является то, что схема Web-баз данных скрыта за интерфейсом поиска, то есть пользователю видны только атрибуты просматриваемой Web-страницы (и результирующей Web-страницы). Другой проблемой, связанной с поиском в динамическом контенте, является то, что созданный индекс должен будет поддерживать как неструктурированные, так и структурированные запросы. Неструктурированный запрос представляет собой список условий поиска, которые обычно используют при поиске документов. Например, неструктурированный запрос может представлять собой запись: «Гарри Поттер Роулинг». Структурированный запрос – это список атрибутов и значений атрибутов, которые обычно используют при поиске в базе данных. Например, структурированный запрос может выглядеть следующим образом: «название = Гарри Поттер и автор = Роулинг». В последнее время были проведены серьезные исследования, имевшие в качестве своей цели разработку «метаискателя», который обеспечивает поиск во множестве Web-баз данных. При получении запроса метаискатель отбирает Web-базы данных, которые с максимальной вероятностью содержат искомый контент, что называется «выбор источника». Затем метаискатель преобразует запрос в подходящий формат для каждой из идентифицированных Web-баз данных, что называется «преобразование запроса». Например, метаискатель должен будет понять, каким образом отобразить атрибуты полученных им запросов в атрибуты сайта каждой выбранной Web-базы данных. Например, метаискатель может использовать атрибут под названием «формат» для ссылки на обложку (например, бумажная обложка или твердый переплет) книги, в то время как Web-база данных может использовать атрибут под названием «вид» для ссылки на те же данные. Преобразование запроса требует отображения атрибута формата метаискателя в атрибут вида Web-базы данных. Метаискатель посылает преобразованные запросы в выбранные Web-базы данных, что называется «диспетчеризация». Когда метаискатель получает результаты поисков, он объединяет их в итоговый результат, что называется «интеграция результата». Желательно иметь способ эффективного создания индексов для Web-баз данных, которые позволили бы осуществлять эффективный поиск с использованием как неструктурированных, так и структурированных запросов. Раскрытие изобретения Предложен способ и система для индексирования и поиска в Web-базах данных в домене. В одном варианте поисковая система создает индекс для Web-баз данных путем порождающей выборки баз данных и использует этот индекс для идентификации и формулирования запросов на поиск в этих базах данных. Созданный индекс называется индексом домен-атрибут и содержит индекс на уровне домена и, для каждой базы данных, индекс на уровне сайта. Индекс на уровне сайта для базы данных отображает атрибуты сайта в определенные значения атрибутов в базе данных. Индекс на уровне домена для домена отображает значения атрибутов в пары атрибутов базы данных и сайта, которые содержат указанные значения атрибутов. Для создания индекса на уровне сайта для базы данных в конкретном домене поисковая система начинает с начального набора выборочных данных для этого домена. Поисковая система выбирает атрибут сайта базы данных, который соответствует атрибуту домена, используя отображение домен – сайт. Поисковая система выбирает значение атрибута из выборочных данных для этого атрибута домена. Затем поисковая система создает и подает запрос выборки в базу данных для поиска записей, которые соответствуют выбранному значению атрибута в выбранном атрибуте сайта. После получения записей в виде результата запроса поисковая система создает для этой базы данных индекс на уровне сайта, который отображает атрибуты сайта в определенные значения атрибутов, содержащиеся в указанных атрибутах сайта. Поисковая система может создавать индекс на уровне домена из различных индексов на уровне сайта. В одном варианте поисковая система дает возможность пользователю задавать неструктурированные запросы или структурированные запросы при поиске во множестве баз данных. Поисковая система отображает неструктурированный запрос в ряд структурированных запросов, идентифицируя сначала, представляют ли условия неструктурированного запроса атрибут или значение атрибута на основе индекса на уровне домена. После идентификации набора членов-атрибутов и членов-значений атрибутов поисковая система создает запрос для каждой комбинации, состоящей из члена-атрибута и члена-значения атрибута. Поисковая система может использовать пары «атрибут – значение атрибута» структурированного запроса непосредственно, без необходимости выполнения отображения, аналогичного отображению, используемому для неструктурированных запросов. Поисковая система использует индекс на уровне домена для идентификации того, в какие базы данных следует подать запросы. Краткое описание чертежей Фиг.1 – блок-схема, иллюстрирующая компоненты поисковой системы в одном варианте осуществления изобретения; Фиг.2 – таблица соответствия в одном варианте осуществления изобретения; Фиг.3 – индекс на уровне сайта для индекса домен-атрибут в одном варианте осуществления изобретения; Фиг.4 – индекс на уровне домена для индекса домен-атрибут в одном варианте осуществления изобретения; Фиг.5 – блок-схема, иллюстрирующая процесс обработки для компоненты, создающей запрос, в одном варианте осуществления изобретения; Фиг.6 – блок-схема, иллюстрирующая процесс обработки для компоненты, формулирующей неструктурированный запрос, в одном варианте осуществления изобретения; Фиг.7 – блок-схема, иллюстрирующая процесс обработки для компоненты, которая идентифицирует члены-атрибуты и члены-значения атрибута в запросе в одном варианте осуществления изобретения; Фиг.8 – блок-схема, которая иллюстрирует процесс обработки для компоненты, выбирающей базы данных для подачи запросов, в одном варианте осуществления изобретения; Фиг.9 – блок-схема, иллюстрирующая процесс обработки для компоненты, создающей индекс домен-атрибут, в одном варианте осуществления изобретения; Фиг.10 – блок-схема, которая иллюстрирует процесс обработки для компоненты, обновляющей индекс на уровне сайта, в одном варианте осуществления изобретения. Осуществление изобретения Предлагается способ и система для индексирования и поиска в Web-базах данных. В одном варианте поисковая система создает индекс для Web-баз данных путем порождающей выборки баз данных и использует этот индекс для идентификации и формулирования запросов на поиск в базах данных. Созданный индекс называется индексом домен-атрибут, который содержит индекс на уровне домена и, для каждой базы данных, индекс на уровне сайта. Домен – это совокупность баз данных, ориентированных на конкретную тему (например, книги или автомобили). Каждый домен имеет схему домена (которую называют также «глобальная схема»), определяющую набор атрибутов домена, которые обычно ищут в схемах баз данных этого домена. Например, если домен относится к книгам, то схема домена может включать в себя атрибут автора и атрибут названия, поскольку большинство баз данных по книгам имеют эти атрибуты. Индекс на уровне сайта для базы данных отображает атрибуты сайта в определенные значения атрибутов в базе данных. Например, если база данных содержит запись с атрибутом автора, который имеет значение атрибута «Толкиен (Tolkien)», то тогда индекс на уровне сайта отображает атрибут автора в «Толкиен». Поисковая система создает индексы на уровне сайта путем выборки баз данных, как описано ниже. Индекс на уровне домена отображает значения атрибута в пары атрибутов база данных и сайта, которые содержат указанные значения атрибутов. Например, индекс на уровне домена может включать в себя запись для значения атрибута «Толкиен», которое отображается в базу данных, содержащую запись для книги Толкиена, и в атрибут автора этой базы данных. Поисковая система может создать индекс на уровне домена из индексов на уровне сайта. Индекс на уровне домена является совмещенной и инвертированной формой индексов на уровне сайта. Для обработки запроса поисковая система использует индекс домен-атрибут для выбора тех баз данных, в которых следует выполнять поиск, и использует отображение атрибута домен – сайт для преобразования запроса в запрос, подходящий для каждой выбранной базы данных. Затем поисковая система подает преобразованные запросы в выбранные базы данных. Далее поисковая система объединяет результаты запросов, используя отображение атрибута домен – сайта для отображения результатов из атрибутов сайта в атрибуты домена. Для создания индекса на уровне сайта для базы данных в некотором домене поисковая система начинает свои действия с начального набора выборочных данных для этого домена. Выборочные данные обеспечивают выборочные записи для баз данных в домене. Записи предоставляют значения атрибутов для атрибутов схемы домена. Например, выборочные данные в домене книг могут содержать одну запись с атрибутом названия, установленным со значением «Гарри Поттер и Орден Феникса», и с атрибутом автора, установленным со значением «Роулинг», и еще одну запись с атрибутом названия, установленным со значением «Братство кольца», и с атрибутом автора, установленным со значением «Толкиен». Для выборки базы данных поисковая система выбирает атрибут сайта этой базы данных, который соответствует атрибуту домена, используя отображение домен – сайт. Поисковая система выбирает значение атрибута из выборочных данных для указанного атрибута домена. Затем поисковая система создает и подает запрос выборки в базу данных для поиска записей, которые соответствуют выбранному значению атрибута в выбранном атрибуте сайта. Например, если выбранным атрибутом сайта является автор, а выбранным значением атрибута является «Толкиен», то тогда по данному запросу будет осуществляться поиск записей для книг, написанных Толкиеном. После получения этих записей в виде результата запроса поисковая система создает индекс на уровне сайта для этой базы данных, который отображает атрибуты сайта в определенные значения атрибутов, содержащиеся в указанных атрибутах сайта. Например, результат может включать в себя запись для книги Толкиена «Silmarillion», опубликованной издательством Del Ray, запись для книги Толкиена «Roverandom», опубликованной издательством Houghton Mifflin и запись для книги Толкиена «Хоббит», опубликованной издательством Houghton Mifflin. В этом случае индекс на уровне сайта отобразит атрибут сайта для названия в слова Silmarillion, Roverandom и Хоббит, а атрибут сайта для издателя в слова Del Ray, Houghton и Mifflin. Поисковая система может также отслеживать количество появлений значения каждого атрибута в результатах выборки. Например, со значением атрибута Houghton будет связано количество появлений, равное двум, поскольку это значение появилось в двух записях данного результата выборки. Для увеличения охвата базы данных, то есть количества записей, которые представлены в индексе на уровне сайта, поисковая система использует данные в результатах выборки для формулирования новых запросов выборки для этой базы данных. Например, поисковая система сможет сформулировать запрос выборки с атрибутом издателя для сайта, установленным со значением Houghton, который извлечет все записи для книг, опубликованных издательством Houghton Mifflin. Затем поисковая система выполнит обновление индекса на уровне сайта так, чтобы он «охватил» все книги Houghton Mifflin в этой базе данных, что увеличивает покрытие базы данных. Поисковая система может использовать этот результат выборки для создания дополнительных запросов выборки. Таким образом, поисковая система расширяет охват базы данных на основе предыдущих результатов выборочных поисков. В одном варианте поисковая система создает индекс на уровне домена из различных индексов на уровне сайта. Поисковая система добавляет запись в индекс на уровне домена для каждого определенного значения атрибута из числа индексов на уровне сайта. Например, если пять баз данных имеют записи для книг Толкиена, то тогда индекс на уровне домена будет иметь запись для Толкиена, по меньшей мере, с пятью подзаписями, каждая из которых идентифицирует одну из пяти баз данных, и атрибут сайта этой базы данных для автора. Когда одна из баз данных содержит запись для книги «J.R. Tolkien: Architect of Middle Earth: A Biography», эта запись индекса на уровне домена для «Толкиен» может также содержать подзапись для базы данных, которая идентифицирует атрибут сайта для названия. Индекс на уровне домена может также содержать информацию о частоте в каждой подзаписи, которая указывает частоту появления значения этого атрибута в каждой базе данных. Поисковая система может использовать информацию о частоте при выборе баз данных для подачи запросов. В одном варианте поисковая система может разделить или выделить индекс на уровне домена на основе атрибутов домена. Например, индекс на уровне домена может иметь субиндекс для атрибута домена для названия и еще один субиндекс для атрибута домена для автора. Каждый из этих субиндексов может включать в себя запись для каждого определенного значения атрибута для данного атрибута в базах данных. Использование субиндексов облегчает преобразование структурированных запросов, позволяя поисковой системе сначала выбрать подходящий субиндекс для данного атрибута структурированного запроса, а затем и запись, которая содержит значение атрибута (содержащую подзаписи, каждая из которых соответствует данному атрибуту), вместо того, чтобы сначала выбирать значение атрибута, а затем обязательно искать подзаписи, которые соответствуют этому атрибуту. В одном варианте поисковая система позволяет пользователю задавать неструктурированные запросы или структурированные запросы при поиске во множестве баз данных. Поисковая система отображает неструктурированный запрос в ряд структурированных запросов, идентифицируя сначала, представляют ли члены неструктурированного запроса атрибут или значение атрибута, на основе индекса на уровне домена. Например, неструктурированный запрос может выглядеть как «название, автор, Толкиен», если пользователь хочет найти книги, написанные автором Толкиеном. Поисковая система идентифицирует, что как член-название, так и член-автор являются атрибутами домена, поскольку они являются именами атрибутов в схеме домена. Поисковая система может также определить, что члены: название, автор и Толкиен – это значения атрибутов, поскольку они являются значениями атрибутов в базе данных. Члены: название и автор могут являться значениями атрибутов, поскольку в одной из баз данных имеется запись для книги «1997 Harvard Business School Core Collection: An Author, Title, and Subject Guide». После идентификации набора членов-атрибутов и членов-значений атрибутов поисковая система создает запрос для каждой комбинации члена-атрибута и члена-значения атрибута. Например, поисковая система может создать запросы для атрибута названия со значениями атрибутов: название, автор и Толкиен и создать запросы для атрибута автора со значениями атрибутов: название, автор и Толкиен. Поисковая система может использовать пары «атрибут и значение атрибута» структурированного запроса непосредственно, без необходимости выполнения отображения, аналогичного отображению, используемому для неструктурированных запросов. В случае неструктурированных запросов или в случае структурированных запросов поисковая система выполнит преобразование атрибутов домена в атрибуты сайта выбранных баз данных. Затем поисковая система подает эти запросы в базы данных, выбранные на основе индекса домен-атрибут, поскольку, например, известно, что они имеют записи, соответствующие атрибуту и значению атрибута в запросе. Поисковая система может также определить порядок подачи запросов на основе информации об индексе домен-атрибут. Например, поисковая система может отдать предпочтение базам данных на основе того, указывает ли индекс домен-атрибут на то, что от них с большой вероятностью можно получить много записей (например, значение частоты указывает на то, что в ответ будет получено большое количество записей). Поскольку выборка базы данных может представлять для нее большую нагрузку, поисковая система может обеспечить различные способы, гарантирующие больший охват базы данных при меньшей выборке. Поисковая система может использовать различные критерии выборки, которые могут включать в себя случайную выборку, выборку, настроенную на атрибуты, и выборку, настроенную на значения. При использовании случайной выборки поисковая система выбирает случайным образом атрибут сайта и выбирает случайным образом значение атрибута для выбранного атрибута, которое еще не было выбрано. При использовании выборки, настроенной на атрибуты, поисковая система выбирает атрибут сайта, который имеет минимальное количество определенных значений атрибута среди всех атрибутов баз данных. Затем поисковая система выбирает случайным образом неиспользованное значение атрибута для данного атрибута сайта. При использовании выборки, настроенной на значения, поисковая система выбирает атрибут сайта, который имеет минимальное количество определенных значений атрибута (как и в случае выборки, настроенной на атрибуты), но выбирает значение атрибута для данного атрибута, которое еще не было выбрано, и которое имеет максимальное количество появлений среди всех значений атрибута, которые еще не были выбраны. Атрибут с минимальным количеством определенных значений в индексе домен-атрибут может также иметь небольшое количество определенных значений в базе данных, подвергающейся выборке. То есть в среднем одно значение этого атрибута может иметь более высокую вероятность совпадения с большей частью записей в базе данных, где происходит выборка, чем значения других атрибутов. Аналогичным образом, значение с большим числом появлений в индексе домен-атрибут также может чаще появляться в базе данных, где происходит выборка. То есть выборка базы данных значения с большим количеством появлений может извлечь большую часть записей базы данных. В одном варианте поисковая система применяет критерий остановки выборки для завершения выборки базы данных, где выполняется выборка. Хотя исчерпывающая выборка базы данных возможна, она накладывает большую нагрузку на базу данных, и Web-сайт базы данных может заблокировать пользователей, которые слишком часто обращаются к базе данных. Поисковая система может использовать абсолютный критерий остановки выборки, который основан на максимальном количестве запросов или максимальном времени. В альтернативном варианте поисковая система может использовать относительный критерий остановки выборки на основе предельного значения нескольких последних запросов выборки, которое определяется количеством нового контента, который был добавлен в индекс на уровне сайта на основе результатов запроса. Поисковая система может использовать комбинацию абсолютного и относительного критериев остановки выборки. Например, поисковая система может прекратить выборку после 1000 запросов или когда предельное значение оказывается ниже некоего порога, что бы ни произошло первым. На фиг.1 представлена блок-схема, иллюстрирующая компоненты поисковой системы в одном варианте осуществления изобретения. Web-базы 101 данных соединены через линию 102 связи с поисковой системой 110. Поисковая система включает в себя компоненту 111 создания запроса, компоненту 112 формулирования структурированного запроса, компоненту 113 формулирования неструктурированного запроса, компоненту 114 создания индекса домен-атрибут (DA), компоненту 115 выбора запроса, компоненту 116 обновления индекса на уровне сайта и компоненту 117 обновления индекса на уровне домена. Поисковая система также включает в себя индекс 120 домен-атрибут (DA), который включает в себя индекс 121 на уровне домена (VA) и, для каждой базы данных, индекс 122 на уровне сайта (AV). Поисковая система также включает в себя таблицу 123 соответствия. Индекс на уровне домена – это индекс значение-атрибут, который отображает значения атрибутов в атрибуты баз данных и сайта в базах данных. Индекс на уровне сайта – это индекс атрибут-значение, который отображает атрибуты сайта базы данных в соответствующие определенные значения. Таблица соответствия отображает атрибуты домена в атрибуты сайта каждой базы данных. Специалистам в данной области техники должно быть очевидно, что, поскольку атрибуты сайта отображаются в атрибуты домена и наоборот, всякий раз, когда нечто отображается в атрибут сайта, оно может быть отображено непосредственно или косвенно через атрибут домена и в обратном порядке для атрибутов домена. Компонента создания запроса получает запрос пользователя, определяет, является ли этот запрос структурированным или неструктурированным, и запускает компоненту формулирования структурированного запроса или компоненту формулирования неструктурированного запроса соответственно. Компонента формулирования структурированного запроса создает запросы на основе атрибута и значений атрибута структурированного запроса. Компонента формулирования неструктурированного запроса идентифицирует члены-атрибуты и члены-значения атрибутов запроса и создает запросы на основе комбинаций членов-атрибутов и членов-значений атрибутов. Компонента создания запроса выбирает базы данных и подает запросы в эти базы данных. Компонента создания индекса домен-атрибут управляет созданием индекса домен-атрибут, включающего в себя индекс на уровне домена и индексы на уровне сайта. Компонента создания индекса домен-атрибут запускает компоненту выбора запроса для создания запросов, используемых для выборки базы данных. Компонента создания индекса домен-атрибут запускает компоненту обновления индекса на уровне сайта для обновления индекса на уровне сайта для базы данных, где проводится выборка. Компонента создания индекса домен-атрибут запускает компоненту обновления индекса на уровне домена для обновления индекса на уровне домена на основе информации об индексах на уровне сайта. Вычислительное устройство, в котором реализована поисковая система, может включать в себя центральный процессор, память, устройства ввода (например, клавиатура и указательные устройства), устройства вывода (например, устройства отображения), и запоминающие устройства (например, накопители на дисках). Память и запоминающие устройства являются считываемой компьютером средой, которая может содержать команды, реализующие поисковую систему. Вдобавок, структуры данных и структуры сообщений могут храниться или передаваться через среду передачи данных, например, в виде сигнала по линии связи. Можно использовать различные линии связи, такие как Интернет, локальная сеть, глобальная сеть или прямое коммутируемое соединение по телефонной линии. Специалистам в данной области техники должно быть очевидно, что поисковую систему можно использовать с базами данных, отличными от Web-баз данных. Например, базы данных могут представлять собой базы данных различных организаций (например, компаний или правительственных органов), поиск в которых может осуществляться через метаискатель. Поисковая система может быть реализована в различных операционных средах, которые включают в себя персональные компьютеры, компьютеры-серверы, карманные устройства или лэптопы, многопроцессорные системы, системы на базе микропроцессоров, электронные устройства, программируемые пользователем, сетевые ПК, миникомпьютеры, универсальные компьютеры, распределенные вычислительные среды, которые включают в себя любую из вышеуказанных систем или устройств, и т.п. Поисковую систему можно описать в общем контексте исполняемых компьютером команд, таких как программные модули, выполняемые одним или несколькими компьютерами или иными устройствами. Обычно программные модули включают в себя стандартные программы, программы, объекты, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют конкретные типы абстрактных данных. Как правило, функциональные возможности программных модулей можно комбинировать или распределять согласно требованиям различных вариантов. Специалистам в данной области техники очевидно, что показанные структуры данных являются просто иллюстративными типами структур данных, которые можно использовать для организации данных. На фиг.2 показана таблица соответствия согласно одному варианту осуществления изобретения. Таблица 200 соответствия (называемая также отображением атрибутов домен-сайт) отображает каждый атрибут 201 домена в соответствующий атрибут сайта для каждой базы данных. Например, строка 202 таблицы соответствия показывает, что атрибут домена «автор» соответствует атрибуту сайта «автор» первой базы данных и атрибуту сайта «au» (автор) второй базы данных. Строка 203 показывает, что атрибут домена «формат» соответствует атрибуту сайта «вид» первой базы данных и атрибуту сайта «формат» второй базы данных. Создание таблицы соответствия описано в патентной заявке США На фиг.3 показан индекс на уровне сайта для индекса домен-атрибут в одном варианте осуществления изобретения. Индекс 300 на уровне сайта содержит запись для каждого атрибута сайта для базы данных Web-сайта. В данном примере записи для атрибутов сайта представлены строками в таблице. Каждая запись включает в себя код записи для каждого определенного значения в базе данных для данного атрибута сайта. Подзаписи могут также указывать частоту или количество появлений значения атрибута, обнаруженного при выборке базы данных. Например, запись для атрибута сайта «автор» имеет подзапись для значения атрибута «Роулинг» и еще одну подзапись для значения атрибута «Толкиен». Запись для атрибута сайта «название» включает в себя подзапись для значения атрибута «волшебник» и подзапись для значения атрибута «кольцо». На фиг.4 показан индекс на уровне домена для индекса домен-атрибут в одном варианте осуществления изобретения. Индекс 400 на уровне домена включает в себя запись для каждого определенного значения атрибута в индексах на уровне сайта и подзаписи, которые отображают значение атрибута в базы данных, а также атрибуты сайта, которые содержат это значение. В данном примере запись 401 соответствует значению атрибута «Толкиен» и имеет подзаписи, которые указывают, что значение атрибута «Толкиен» находится в атрибуте сайта «название» первой базы данных, атрибуте сайта «автор» первой базы данных и атрибуте сайта «название» второй базы данных. Запись 402 соответствует значению атрибута «Houghton» и имеет подзаписи, которые указывают, что значение атрибута «Houghton» находится в атрибуте сайта «издатель» первой базы данных, атрибуте сайта «издатель» второй базы данных, атрибуте сайта «автор» второй базы данных и атрибуте сайта «название» второй базы данных. На фиг.5 показана блок-схема, иллюстрирующая процесс обработки, выполняемой компонентой создания запроса в одном варианте осуществления изобретения. Запрос, который может быть структурированным или неструктурированным, проходит через эту компоненту, которая создает запросы, подаваемые в различные базы данных. В блоке 501 принятия решения, если пришедший запрос является структурированным, указанная компонента продолжает обработку в блоке 502, а в противном случае – в блоке 503. В блоке 502 компонента создания запроса запускает компоненту формулирования структурированного запроса для создания запросов для баз данных. В блоке 503 компонента создания запроса запускает компоненту формулирования неструктурированного запроса для формулирования запросов из неструктурированного запроса. В блоке 504 компонента создания запроса запускает компоненту выбора баз данных для выбора баз данных, куда следует подавать запросы. Эта компонента может также преобразовывать запросы из атрибутов домена в атрибуты сайта выбранных баз данных. В блоке 505 компонента создания запроса упорядочивает базы данных так, чтобы запросы можно было подавать в том порядке, при котором наиболее желательные результаты можно получить скорейшим образом. Например, базы данных могут быть упорядочены на основе того, какие из них могут иметь наибольшее количество записей, относящихся к конкретному значению атрибута. Компонента создания запроса может также комбинировать запрос для базы данных, объединяя атрибут и значения атрибута логической функцией ИЛИ. Затем компонента создания запроса завершает свою работу. На фиг.6 представлена блок-схема, иллюстрирующая процесс обработки, выполняемой компонентой формулирования неструктурированного запроса, в одном варианте осуществления изобретения. В блоке 601 эта компонента запускает компоненту, идентифицирующую в запросе члены-атрибуты и члены-значения атрибутов. В блоках 602-606 компонента формулирования неструктурированного запроса выбирает пары, состоящие из члена-атрибута и члена-значения атрибута, и формулирует запрос для данной пары. В блоке 602 упомянутая компонента выбирает следующий член-атрибут. В блоке 603 принятия решения, если все члены-атрибуты уже выбраны, компонента возвращается в точку вызова; в противном случае компонента продолжает обработку в блоке 604. В блоке 604 компонента выбирает следующий член-значение атрибута. В блоке 605 принятия решения, если все члены-значения атрибута уже выбраны, то компонента возвращается по циклу к блоку 603 для выбора следующего члена-атрибута; в противном случае компонента продолжает обработку в блоке 606. В блоке 606 компонента формулирует запрос, устанавливая атрибут домена, соответствующий выбранному члену-атрибуту, равному выбранному члену-значению атрибута. Затем компонента возвращается по циклу к блоку 604 для выбора следующего члена-значения атрибута. На фиг.7 представлена блок-схема, иллюстрирующая процесс обработки, выполняемый компонентой, которая идентифицирует члены-атрибуты и члены-значения атрибутов в запросе согласно одному варианту изобретения. В блоке 701 эта компонента инициализирует список членов-атрибутов (АТ) и список членов-значений атрибутов (AVT) как пустые. В блоках 702-707 компонента выполняет цикл, выбирая каждый член в запросе и определяя, является ли он членом-атрибутом, членом-значением атрибута или и тем, и другим. В блоке 702 компонента выбирает следующий член в запросе. В блоке 703 принятия решения, если все члены в запросе уже выбраны, то компонента возвращается в точку вызова; в противном случае компонента продолжает обработку в блоке 704. В блоке 704 принятия решения, если выбранный член является членом-значением атрибута, то компонента переходит к блоку 705; в противном случае компонента переходит к блоку 706. Член является членом-значением атрибута, когда этот член имеется в записи индекса на уровне домена. В блоке 705 компонента добавляет выбранный член в список членов-значений атрибутов, а затем переходит к блоку 706. В блоке 706 принятия решения, если выбранный член является атрибутом, то компонента переходит к блоку 707; в противном случае компонента возвращается по циклу к блоку 702 для выбора следующего члена запроса. Член является членом-атрибутом, когда этот член имеется в подзаписи в любой одной из записей индекса на уровне домена. В блоке 707 компонента добавляет выбранный член в список членов-атрибутов, а затем возвращается по циклу к блоку 702 для выбора следующего члена в запросе. На фиг.8 показана блок-схема, иллюстрирующая процесс обработки, выполняемой компонентой выбора баз данных, для подачи запросов согласно одному варианту настоящего изобретения. Эта компонента выбирает базы данных на основе того, имеется ли эта база данных в подзаписи записи для значения атрибута запроса в индексе на уровне домена. В блоке 801 компонента выбирает следующий сформулированный запрос. В блоке 802 принятия решения, если все запросы уже выбраны, компонента возвращается в точку вызова; в противном случае компонента переходит к блоку 803. В блоке 803 компонента выбирает подзапись в записи для атрибута выбранного запроса. В блоке 804 принятия решения, если все указанные подзаписи уже выбраны, компонента возвращается по циклу к блоку 801 для выбора следующего запроса; в противном случае компонента переходит к блоку 805. В блоке 805 компонента создает триплет, состоящий из базы данных, атрибута и значения атрибута, для запроса, а затем возвращается по циклу к блоку 803 для выбора следующей подзаписи. Триплет указывает на запрос, подлежащий подаче в базу данных. Компонента может также преобразовать атрибут домена в соответствующий атрибут сайта базы данных. На фиг.9 представлена блок-схема, иллюстрирующая процесс обработки, выполняемый компонентой создания индекса домен-атрибут, согласно одному варианту настоящего изобретения. В этом варианте компонента создает исчерпывающие запросы для всех комбинаций «атрибут-значение атрибута» и случайно выбирает атрибут и значение атрибута. Блоки 901-904 могут быть заменены компонентой, которая реализует другой критерий выборки (например, выборку, настроенную на атрибут) и критерий остановки выборки. В блоке 901 компонента выбирает следующий атрибут домена. В блоке 902 принятия решения, если все атрибуты домена уже выбраны, то компонента переходит к блоку 980; в противном случае компонента переходит к блоку 903. В блоке 903 компонента выбирает следующие значения атрибута. В блоке 904 принятия решения, если все значения атрибута уже выбраны, то компонента переходит к блоку 901; в противном случае компонента переходит к блоку 905. В блоке 905 компонента подает запрос выборки на основе выбранного атрибута домена (отображенного в соответствующий атрибут сайта) и выбранного значения атрибута. В блоке 906 компонента извлекает записи, являющиеся результатом выборки. Например, компонента может выделить только первые 10 записей или какое-либо другое количество записей. В блоке 907 компонента создания индекса домен-атрибут запускает компоненту обновления индекса на уровне сайта для обновления индекса на уровне сайта для базы данных, где проводится выборка. Затем компонента создания индекса домен-атрибут возвращается по циклу к блоку 903, чтобы выбрать следующее значение атрибута для выбранного атрибута домена. В блоке 908 компонента создания индекса домен-атрибут запускает компоненту обновления индекса на уровне домена для обновления индекса, на уровне домена на основе обновленных индексов на уровне сайта. На фиг.10 представлена блок-схема, иллюстрирующая процесс обработки, выполняемый компонентой обновления индекса на уровне сайта, в одном варианте осуществления изобретения. Когда в компоненту поступает результат выборки, она выбирает каждую пару, состоящую из атрибута и значения атрибута, в результате выборки и определяет, имеется ли эта пара в индексе на уровне сайта. Если нет, то компонента добавляет эту пару в индекс. В противном случае компонента обновляет значение частоты для существующей пары. В блоке 1001 компонента выбирает следующую запись из результата выборки. В блоке 1002 принятия решения, если все записи уже выбраны, то компонента возвращается в точку вызова; в противном случае компонента переходит к блоку 1003. В блоке 1003 компонента выбирает следующий атрибут из выбранной записи. В блоке 1004 принятия решения, если все атрибуты выбранной записи уже выбраны, то компонента циклически возвращается к блоку 1001 для выбора следующей записи; в противном случае компонента переходит к блоку 1005. В блоке 1005 принятия решения, если выбранный атрибут и значение этого атрибута уже составляют пару в индексе на уровне сайта, то компонента переходит к блоку 1006; в противном случае компонента переходит к блоку 1007. В блоке 1007 компонента добавляет пару, состоящую из атрибута и значения атрибута, в индекс на уровне сайта, а затем переходит к блоку 1006. В блоке 1006 компонента обновляет значение частоты для пары, состоящей из атрибута и значения атрибута, в индексе на уровне сайта, а затем возвращается по циклу к блоку 1003 для выбора следующего атрибута для выбранной записи из результата выборки. Специалистам в данной области техники должно быть ясно, что хотя здесь в иллюстративных целях были описаны конкретные варианты поисковой системы, могут быть предложены их различные модификации, не выходящие за рамки существа и объема изобретения. Соответственно, изобретение ничем не ограничено, кроме как прилагаемой формулой изобретения.
Формула изобретения
1. Способ, реализуемый в компьютерной системе, для улучшения поиска в Web-базах данных, причем система содержит поисковую машину и Web-базы данных, при этом способ содержит 2. Способ по п.1, в котором упомянутое отображение представляет собой индекс домен-атрибут. 3. Способ по п.2, в котором индекс домен-атрибут обеспечивает для множества значений атрибута, содержащихся каждое, по меньшей мере, в одном атрибуте одной записи одной Web-базы данных, отображение из значения атрибута в Web-базу данных и атрибут указанной Web-базы данных, которая содержит это значение атрибута в указанном атрибуте записи указанной Web-базы данных. 4. Способ по п.2, в котором индекс домен-атрибут обеспечивает для каждой Web-базы данных и для каждого атрибута в этой Web-базе данных отображение в определенные значения атрибута, которые содержатся в этом атрибуте записи в этой базе данных. 5. Способ по п.2, в котором индекс домен-атрибут включает в себя индекс на уровне домена и индекс на уровне сайта. 6. Способ в компьютерной системе для улучшения поиска в Web-базах данных, причем система содержит поисковую машину и Web-базы данных, при этом способ содержит 7. Способ по п.6, в котором индекс домен-атрибут включает в себя индекс на уровне домена и индекс на уровне сайта. 8. Способ в компьютерной системе для выборки в базах данных в пределах домена, причем система содержит поисковую машину и Web-базы данных, при этом способ содержит 9. Способ по п.8, включающий в себя обновление наборов значений атрибутов домена на основе результата, так что значение атрибута из обновленного набора можно использовать при подаче запроса в следующий раз. 10. Способ по п.8, в котором созданное отображение является индексом домен-атрибут. 11. Способ по п.10, в котором созданное отображение является индексом на уровне сайта. 12. Способ по п.10, в котором созданное отображение является индексом на уровне домена. 13. Способ по п.8, в котором выбирают атрибут, который имеет минимальное количество определенных значений атрибута. 14. Способ по п.8, в котором среди значений атрибута, которые еще не были выбраны, выбирают значение атрибута, которое имеет наибольшее количество появлений. 15. Способ по п.8, включающий в себя этап на котором обеспечивают таблицу соответствия, которая для упомянутых баз данных отображает атрибуты домена в специфические для баз данных атрибуты. 16. Способ по п.15, в котором подача запроса включает в себя использование таблицы соответствия для определения для атрибута домена специфического для баз данных атрибута для упомянутых баз данных, в которые должен быть подан запрос. 17. Способ по п.15, включающий в себя создание отображения для каждой базы данных, которое отображает специфические для баз данных атрибуты упомянутой базы данных в значения атрибутов, содержащихся в упомянутой базе данных. 18. Компьютерная система для создания отображения между значениями атрибутов и базами данных, имеющими атрибуты с упомянутыми значениями атрибутов, причем упомянутые базы данных принадлежат домену, компьютерная система содержит 19. Система по п.18, в которой компонент поисковой машины при создании отображения отображает каждое значение атрибута на упомянутые базы данных и атрибуты баз данных, содержащие упомянутое значение атрибута. 20. Система по п.18, в котором компонент поисковой машины при создании отображения отображает каждый атрибут баз данных на значения атрибута того атрибута, который содержится в упомянутой базе данных. 21. Система по п.18, включающая в себя компонент, который принимает запрос, идентифицирует атрибут и значение атрибута для принятого запроса, идентифицирует из упомянутого отображения базы данных, которые содержат упомянутый идентифицированный атрибут с упомянутым идентифицированным значением атрибута, и подает запрос в отношении упомянутого идентифицированного атрибута с упомянутым идентифицированным значением атрибута в упомянутые идентифицированные базы данных. 22. Система по п.18, включающая в себя компонент, который добавляет новые атрибуты и значения атрибутов к упомянутым обеспеченным атрибутам и обеспеченным значениям атрибутов, основываясь на упомянутых результатах, так что новый атрибут и новое значение атрибута могут быть использованы при последующей подаче запроса. 23. Система по п.18, в которой упомянутое множество пар, состоящих из упомянутых обеспеченных атрибутов и обеспеченных значений атрибутов, выбирают случайным образом. 24. Система по п.18, в которой обеспечиваемый атрибут выбирают таким образом, что он имеет минимальное количество определенных значений атрибута. 25. Система по п.18, в которой упомянутое обеспечиваемое значение атрибута выбирают таким образом, что оно имеет наибольшее количество появлений среди значений атрибута, которые еще не были выбраны. 26. Система по п.18, включающая в себя таблицу соответствия, которая для упомянутых баз данных отображает атрибуты домена в специфические для баз данных атрибуты. 27. Система по п.26, в которой упомянутый компонент поисковой машины при подаче запроса использует таблицу соответствия для определения для атрибута домена специфического для баз данных атрибута для упомянутых баз данных, в которые должен быть подан запрос.
РИСУНКИ
|
||||||||||||||||||||||||||
 595
595