Патент на изобретение №2392660
|
||||||||||||||||||||||||||
(54) СПОСОБ ПОИСКА ИНФОРМАЦИИ В МАССИВЕ ТЕКСТОВ
(57) Реферат:
Изобретение относится к обработке естественно-языковых текстов и может быть использовано для автоматизации поиска необходимых документов в большой их коллекции. Изобретение позволяет проводить сравнение фраз по смыслу. При поступлении запроса его содержимое обрабатывают по предложениям, происходит попарное сопоставление предложений массива текстов и поискового запроса, по результатам которого вычисляют релевантность каждого документа массива текстов запросу на основе входящих в документы предложений. Индексирование массива текста происходит по отдельным предложениям. В предложениях вначале распознают точные значения слов и устанавливают семантические связи между ними, затем точные значения слов заменяют их разложением на элементарные значения, которые хранятся для каждого значения в тезаурусе, после чего для каждого предложения строят матрицу, содержащую связи между всеми парами объектов, входящих в предложение, затем составляют инвертированный индекс, где для каждого объекта, входящего в массив текста, указано в каких документах и в каких предложениях сколько раз он встречается. 1 з.п. ф-лы.
Изобретение относится к области информационных технологий, а именно к обработке естественно-языковых текстов, и может быть использовано для автоматизации поиска необходимых документов в большой их коллекции. В настоящее время для поиска в больших коллекциях документов используют либо ключевые слова, учитывая форму слов лишь по отдельности и расстояния между словами, либо используют результаты синтаксического и первичного семантического анализа и учитывают семантическую роль слова, но при этом не учитывают многозначность слов и возможность выражения того же смысла другими словами. Известен способ синтеза самообучающейся системы извлечения знаний из текстовых документов для поисковых систем путем обеспечения механизма самообучения в виде стохастически индексированной системы искусственного интеллекта. Проводят морфологический и синтаксический анализ, а также стохастическое индексирование текстовых документов по заданной схеме для формирования баз знаний семантического анализа. Преобразуют запрос пользователя в стохастически индексированном виде во множество новых запросов, эквивалентных исходному запросу, и осуществляют выбор стохастически индексированных фрагментов текстовых документов во всеми словосочетаниями преобразованного запроса, из которых формируют стохастически индексированную систематическую структуру, формируют краткий ответ системы на основе этой структуры и проверяют релевантность краткого ответа системы запросу путем их сравнения (RU 2273879, МПК 7 G06F 17/30, опубл. 10.04.2006). Недостатком известного решения является использование слов естественного языка как неделимых элементов, в то время как слова многозначны и одна и та же фраза может быть выражена разными словами, что приводит к невозможности учета эквивалентности по смыслу между разными выражениями. Технический результат заключается в обеспечении возможности детального семантического анализа естественно-языкового текста, включающего обработку значений, входящих в текст слов за счет возможности описания значений слов в виде составных элементов, над которыми возможно выполнять действия и преобразования, что позволяет проводить сравнение фраз по смыслу. Указанный технический результат достигается тем, что способ поиска информации в массиве текстов заключается в том, что предварительно выполняют индексирование массива текстов по входящим в него предложениям. При поступлении запроса его содержимое обрабатывают по предложениям, происходит попарное сопоставление предложений массива текстов и поискового запроса, по результатам которого вычисляют релевантность каждого документа массива текстов запросу на основе входящих в документы предложений, затем в порядке снижения релевантности документы массива текстов представляют пользователю как результат поиска. Индексирование массива текста происходит по отдельным предложениям. В предложениях вначале распознают точные значения слов и устанавливают семантические связи между ними, затем точные значения слов заменяют их разложением на элементарные значения, которые хранятся для каждого значения в тезаурусе, после чего для каждого предложения строят матрицу, содержащую связи между всеми парами объектов, входящих в предложение, затем составляют инвертированный индекс, где для каждого объекта, входящего в массив текста, указано в каких документах и в каких предложениях сколько раз он встречается. Обработка поискового запроса при его поступлении предусматривает определение точных значений всех слов, входящих в предложения запроса, затем точные значения слов заменяют их разложением на элементарные значения, которые хранятся для каждого значения в тезаурусе, после чего для каждого предложения запроса строят матрицу, содержащую связи между всеми парами объектов, входящих в предложение, затем выполняют поиск по тезаурусу объектов, имеющих корреляцию с объектами, входящими в запрос, после чего все объекты, входящие в запрос, и коррелирующие объекты находят в инвертированном индексе и на основе его данных из массива текстов отбирают предложения, для которых затем выполняют попарные сопоставления с предложениями запроса. При попарном сопоставлении предложений массива текстов и предложений запроса предварительно строят матрицу, отражающую соответствия между входящими в текст объектами и объектами, входящими в запрос, и коррелирующими с объектами запроса. Затем для объектов, связанных в полученной матрице, сопоставляют значения соответствующих этим объектам ячеек матриц, построенных для предложений массива текстов и для предложений запроса, на основе чего вычисляют релевантность предложений запроса предложениям массива текстов. Затем путем вычисления среднего арифметического определяют релевантность каждого предложения массива текста всему запросу. Для каждого документа массива текста на основе релевантностей, входящих в него предложений, вычисляют релевантность всего документа запросу с помощью статистических показателей. Ниже приведены определения терминов, используемых в описании. Документ – единица массива текстов, одну или несколько из которых требуется найти пользователю. Денотат (интенсионал) – точное однозначное значение слова в контексте. Объект – предмет или явление окружающего мира, имеющее соответствие в языке как самостоятельное конкретное значение, т.е. разновидность денотата. Предикат – денотат, отличающийся возможностью быть дополненным другими денотатами для получения значения, не имеющий в отличие от объекта сам по себе конкретного значения. Аргументы (актанты) – денотаты, дополняющие предикаты для получения конкретных значений. Клауза – простое предложение в составе сложного. Референциальные связи – связи, указывающие, что разные выражения подразумевают под собой один и тот же предмет или явление. Семантические связи – связи между денотатами, с помощью которых они образуют единый смысл. Синтаксические связи – связи между словами в предложении, задаваемые грамматикой языка. Семантический класс – группа денотатов, имеющих одинаковые возможности по установлению семантических связей. Индексирование – предварительная обработка массива текстов, позволяющая затем более быстро осуществлять поиск. Релевантность – величина в диапазоне от 0 до 1, характеризующая степень соответствия фрагмента текста запросу. Инвертированный индекс – структура данных, в которой перечислены некоторые элементы коллекции документов, а для каждого из них перечислены все места, где они встречаются. Структура – составной тип данных, включающий в себя набор элементов определенного типа с определенными названиями. Курсивом с заглавной буквы написаны названия типов данных, структур, их элементов и их возможных значений. Способ представления значений слов основывается на следующем. Для анализа должны быть представлены не просто отдельные слова, а конкретные интенсионалы (денотаты) лексем с учетом анафорических выражений, причем каждая лексема должна быть определена одновременно, как конкретный экстенсионал, либо как атрибутивное или автономное использование. В случае диффузного значения, либо употребления лексемы сразу в нескольких значениях требуется проводить анализ отдельно для каждого интенсионала. Составляющие значения делятся на объекты и предикаты. Объекты и предикаты делятся на элементарные (базовые) и составные. Базовых предикатов существует ограниченное количество, объектов и составных предикатов – неограниченное. Предикаты имеют аргументы (актанты), объекты их не имеют. Составные предикаты могут включать в свой состав объекты. Объекты делятся на семантические классы, причем один объект может принадлежать нескольким семантическим классам, имеющим иерархии, притом существует несколько разных иерархий, начиная с разных семантических классов. Объекты имеют иерархии аналогично семантическим классам. Аргументами предиката могут быть другие объекты и предикаты, причем для конкретного аргумента должен быть задан тип – объект или предикат, и если объект, то указан его семантический класс, при этом допускаются объекты всех нижестоящих в иерархии семантических классов. Предикаты могут быть вложенными как аргументы других предикатов неограниченное количество раз. Аргументы составного предиката делятся на основные и дополнительные. Число основных аргументов равно числу неуказанных аргументов всех вложенных предикатов. Дополнительные аргументы составляют объекты в составе предиката, которые могут быть заменены на нижестоящие в иерархии. Составной предикат со всеми указанными основными аргументами может рассматриваться как объект, а может как предикат с использованием только дополнительных аргументов. В качестве аргументов-объектов могут выступать также универсальный и пустой объект, а также в качестве аргументов-объектов вложенного предиката могут выступать ссылки на аргументы рассматриваемого предиката. Некоторые базовые предикаты имеют числовые аргументы. Составляющие значения могут объединяться не только предикатами, но и конъюнкциями и дизъюнкциями, такое объединение записывается в конъюнктивной нормальной форме, притом конъюнктивные члены делятся на дифференциальные и характеристические. При выполнении конъюнкции или записи одиночного предиката должно быть указано, является ли он дифференциальным или характеристическим конъюнктивным членом. Дизъюнкция возможна либо между двумя дифференциальными, либо между двумя характеристическими членами. Любой объект или предикат может иметь отрицание, притом отрицание бывает либо логическим (полным), либо лингвистическим. Лингвистическое отрицание отрицает только дифференциальные составляющие (для составных предикатов дизъюнктивные члены в конъюнктивной нормальной форме). При преобразовании объектов предикатами с указанием всех аргументов и при переходе по иерархии объектов возможно взаимное преобразование дифференциальных и характеристических составляющих. Объекты имеют признаки, присоединяемые предикатами. Признаки также делятся на дифференциальные и характеристические. Набор признаков определяет принадлежность объекта к семантическому классу. При этом под объектами подразумевается все, что означает предмет или явление вне зависимости от того, что семантическая роль может соответствовать субъекту. В их число, таким образом, попадают существительные, обозначающие предмет или явление, местоимения, заменяющие существительные, в ряде случаев числительные, если они указывают просто число, а не количество предметов. Главным отличием лексемы объекта является наличие конкретного значения самого по себе. Конкретным является такое значение, какое можно представить или изобразить в какой-либо форме (не обязательно в визуальной, возможны аудиальный, эмоциональный и т.п. смыслы), не прибегая к метафоре или метонимии. Те же денотаты, что требуют дополнения другими денотатами для получения конкретного значения, относятся к предикатам. В их число попадают существительные, не имеющие определенного значения и служащие для детализации значений других существительных (например, слово часть), глаголы, прилагательные и причастия, наречия, порядковые числительные и числительные, обозначающие количество предметов. Особые части речи, как деепричастия, в эту классификацию не входят, для их интерпретации требуется грамматическая перестройка фразы с использованием других частей речи, что для таких частей речи всегда возможно. Характерной чертой базового предиката является абсолютно абстрактное значение, применимое к любой теме, т.е., например, в то время как образование относительного и качественного прилагательного от существительного являются разными базовыми предикатами, конкретный тип относительного прилагательного (время, материал и т.п.) уже не может задаваться самим базовым предикатом, такие характеристики могут быть только аргументами (объектами). Иерархии объектов при этом отражают тот факт, что нижестоящий по иерархии объект является разновидностью объекта, стоящего выше по иерархии, при этом он наследует признаки последнего, но с возможным переходом дифференциальных признаков в характеристические, а также может иметь свои собственные признаки. Базовые предикаты с числовыми аргументами применяются при описании недискретных объектов, как сами числа или цвета. Если распознаны денотаты, а также семантические и референциальные связи, то возможно построение связей в клаузах. Для этого лексемы-объекты становятся аргументами лексем-предикатов, при соблюдении семантических классов, т.е. так, чтоб объекты имели соответствующие предикатам признаки. Связи считаются простроенными, если указаны все аргументы всех предикатов. Применение предикатов к объектам в клаузе создает ситуационные объекты, притом они могут использовать нечеткие дизъюнкцию, конъюнкцию и отрицания, преобразования выполняются по правилам нечеткой логики. В качестве примера осуществления предлагаемого способа необходимо рассмотреть систему поиска, позволяющую находить эквивалентные по смыслу выражения. Для этого требуется использовать семантический анализатор, дающий на выходе точные значения (денотаты) всех слов в предложении и структуру семантических связей между ними. При этом в пределах клауз семантические связи должны быть описаны с помощью базовых предикатов, принятых в системе. Сама задача поиска при этом разделяется на две части: предварительная обработка (индексирование) текста и сам процесс поиска при поступлении запросов. Индексирование требуется один раз для заданного массива текстов, после чего может обрабатываться неограниченное количество поисковых запросов. Индексирование состоит из следующего: 1. Семантический анализ всего текста. Результатом являются установленные по словарю денотаты лексем и семантические связи между ними. 2. Подстановка вместо денотатов их разложения на элементарные значения по тезаурусу. Если лексема не найдена в словаре семантическим анализатором, либо значению лексемы в контексте не подходит ни один семантический класс, то лексема считается неделимым объектом с возможными дополнениями базовыми предикатами для обеспечения синтаксической роли, и далее приравнивается ко всем одинаковым по начальной форме лексемам с неизвестным семантическим классом. Итогом является единый базовый предикат с вложенными объектами и другими базовыми предикатами для каждой клаузы. 3. Выделение списка объектов для каждого предложения и построение матрицы, где и набор строк, и набор столбцов составляют объекты, присутствующие в предложении. Итогом является указанная матрица для каждого предложения, причем в ячейках содержатся массивы структур следующего вида Связь объектов { Подуровни предикатов [массив] предикаты первого объекта; Подуровни предикатов [массив] предикаты второго объекта; Подуровни предикатов [массив] общие предикаты; Тип объединения объектов; Отрицание <отрицание первого объекта>, <отрицание второго объекта>; номера аргументов текущего предиката; имя предиката; } где Подуровни предикатов – также структура следующего вида: Подуровни предикатов { имя предиката; номер аргумента; отрицание на предикате; } Предикаты первого объекта, Предикаты второго объекта и Общие предикаты составляют массивы структур Подуровней предикатов. Первые два представляют собой вложенные предикаты, аргументами которых являются первый и второй объект соответственно, для некоторого (текущего) предиката, вложенными подаргументами которого являются оба объекта. Общие предикаты – перечень всех вложенных предикатов по отношению к главному предикату клаузы, по отношению к которому объединяющий два объекта (текущий) предикат является следующим по уровню вложения. Таким образом, в первых трех элементах структуры хранится информация о наименованиях и номерах аргументов предикатов, определяющих путь по вложенным предикатам до обоих объектов. Тип объединения объектов принимает одно из четырех значений: – совместные аргументы текущего предиката; – конъюнкция; – дизъюнкция; – сам объект. Тип Совместные аргументы текущего предиката означает, что оба объекта объединяются по уровням вложения на некотором базовом (текущем) предикате, разными аргументами которого они являются. Это означает, что либо объекты являются сами аргументами одного базового предиката, либо в качестве одного или обоих таких аргументов выступает некоторый базовый предикат, в одном из дальнейших уровней вложения которого оказывается соответствующий объект. Информацию о предикатах на уровнях вложения содержат описанные выше массивы структуры Подуровни предикатов. Значение Сам объект означает, что речь идет о рассмотрении диагональной ячейки, роль которой состоит просто в установлении наличия объекта, а не связей его с другими объектами, для которой Предикаты первого объекта, Предикаты второго объекта не имеют смысла, но сохраняют свой смысл Общие предикаты. Значения Дизъюнкция и Конъюнкция означают соответственно объединение объектов дизъюнкцией и конъюнкцией. Отрицание первого объекта и Отрицание второго объекта содержат информацию, имеет ли каждый из объектов на себе отрицание. Как уже говорилось, отрицание бывает двух типов, из чего следует, что Отрицание может иметь три значения: Отрицание отсутствует, Лингвистическое отрицание, Логическое отрицание. Элемент Номера аргументов текущего предиката содержит два целых числа и используется только в случае, если Тип объединения объектов имеет значение Совместные аргументы текущего предиката. Эти два числа указывают, по каким аргументам текущего предиката содержатся оба объекта соответственно. Имя предиката обозначает тип текущего предиката. Смысл массива структур в том, что каждая структура отражает только одну связь между объектами, в то время как в предложении одни и те же пары объектов могут быть связаны несколько раз. Каждый элемент массива соответствует одной связи соответственно, если объекты связаны один раз, то используется один элемент. Таким образом, в матрице описаны связи между всеми парами объектов, входящих в предложение. 4. Построение инвертированного индекса по содержащимся в тексте объектам, где для каждого объекта указано, во-первых, встречается ли он и сколько раз в документе, а во-вторых, встречается ли он и сколько раз в каком предложении. В итоге сохраняются описанные в п.3 матрицы для каждого предложения и инвертированный индекс. После проведения индексирования возможен поиск. Он состоит из следующего: 1. Семантический анализ запроса. Результатом являются установленные по словарю денотаты лексем запроса и семантические связи между ними. Аналогично п.1 для индексирования. 2. Подстановка вместо денотатов запроса их разложения на элементарные значения по тезаурусу. Итогом является единый базовый предикат с вложенными объектами и другими базовыми предикатами для каждой клаузы запроса. Аналогично п.2 для индексирования. 3. Построение матрицы для каждого предложения запроса, описанной в п.3 для индексирования. 4. Поиск по тезаурусу объектов, имеющих связи с объектами запроса, т.е. способные к взаимному преобразованию с использованием предикатов и других объектов. Для этого используется специальный список, содержащий не пути преобразования между объектами, а численно выраженное в диапазоне от 0 до 1 значение корреляции между объектами. Имеющими связь признаются объекты, имеющие уровень корреляции выше заданного порогового значения, определяемого выбранным режимом соотношения скорости и точности поиска. Т.е. чем выше скорость, тем больше пороговое значение и тем меньше связанных объектов выбирается. При наибольшей точности и наименьшей скорости можно использовать все объекты, для которых значение корреляции больше нуля. Результатом является список объектов самого предложения и связанных с ними объектов. 5. Все объекты предложения и связанные с ними объекты ищутся в инвертированном индексе и, таким образом, отбираются нужные документы и предложения. В режиме высокой точности и низкой скорости отбираются все документы, где хотя б один объект из запроса или связанный объект встречается хотя б один раз. В режимах более высокой скорости выбираются только документы и предложения, где встречается достаточное количество объектов достаточное количество раз, что определяется по любой заданной заранее формуле (например, среднее арифметическое или любым другим образом усредненная величина значений частоты объектов в документе или предложении, отнесенных к частоте тех же объектов во всем массиве текстов, либо указанное значение, взвешенно суммированное с долей объектов запроса, входящих в документ или предложение, либо использование отдельных пороговых значений для этих двух критериев). Результатом являются выбранные документы и предложения в них. 6. Для всех объектов всех отобранных предложений текста устанавливается их соответствие с объектами запроса. Это соответствие может быть двух типов: либо объекты совпадают, либо путем использования базовых предикатов и других объектов один объект можно преобразовать в другой. Для получения преобразуемых объектов должны совпасть связанные с объектами запроса объекты и встречающиеся в предложении объекты. Результатом является матрица соответствий между объектами. В ячейках содержатся структуры: Соответствие объектов { Наличие связи; Совпадение; Подуровни предикатов [массив] преобразующие предикаты; } Первый элемент булевского типа указывает на наличие связи между объектами, если его значение равно истине, то второй элемент также булевского типа указывает на факт совпадения, и если его значение не равно истине, то в третьем элементе, описанным в п.3 образом, содержится информация о преобразовании между объектами. При этом, если объекты связаны иерархией, связь строится в виде одного элемента массива Преобразующие предикаты, в котором отражено, что они связаны иерархией. Смысл элемента Совпадение состоит в том, что при истинном значении он позволяет установить соответствие номеров столбцов и строк матриц предложений запроса и предложений текста, поскольку номера строк и столбцов для одних и тех же объектов в обоих матрицах вполне могут различаться. 7. Для всего декартова произведения выбранных предложений массива текстов и предложений запроса попарно считается отображение описанных в п.3 матриц. Для этого используются описанные в п.6 отображения между объектами. Для заданной пары предложений для каждой структуры в каждой ячейке в матрице объектов из предложения запроса и для каждой пары связанных с ними объектов ищется соответствующая пара объектов в предложении массива текстов. Между парами одних и тех же объектов рассчитывается релевантность отображения структур, описанных в п.3. При этом используются все элементы структуры Связь объектов. Если массив соответствующей ячейки и в предложении запроса, и в предложении текста имеет более одного элемента, то вычисляются релевантности для всего декартова произведения тех и других структур. Во-первых, сравнивается значение Имя предиката. Если оно совпадает, то релевантность этого элемента считается равной 1, т.е. полной. Если не совпадает, то используется таблица корреляции между базовыми предикатами, и из этой таблицы берется некоторое значение от 0 до 1, отражающее корреляцию соответствующих предикатов. Затем сравниваются Номера аргументов текущего предиката. Их релевантность берется равной единице в случае совпадения и меньшей при несовпадении, точно также по таблице, отражающей корреляции между аргументами предикатов. Затем сравниваются Отрицание первого объекта и Отрицание второго объекта. Точно также полная релевантность соответствует совпадению – частичная таблице корреляций между отрицаниями. Аналогично используется Тип объединения объектов, т.е. либо полная релевантность при совпадении, либо корреляция. При анализе отображения всех трех массивов Подуровни предикатов в первую очередь определяется кодовое расстояние между ними. Т.е. для каждого из них определяется наименьшее количество замен, модификаций, исключений и добавлений предикатов, необходимое для преобразования одного в другое. Под модификацией подразумевается изменение номера идущего далее аргумента или отрицания. Для вычисления кодового расстояния в режиме высокой точности и низкой скорости следует применять алгоритмы, обеспечивающие полную достоверность, а в режимах, начиная с определенной скорости, возможно применение алгоритмов, дающих достоверное кодовое расстояние лишь с некоторой вероятностью (т.н. рандомизированные алгоритмы). Полное соответствие означает релевантность элемента, равную 1, замены предиката снижают релевантность в соответствии с корреляцией между соответствующими предикатами, модификации в соответствии с корреляциями между аргументами, исключение и добавление – на некоторую, заданную для конкретного предиката величину. При этом особую ситуацию представляют собой модификации отрицания. Если отрицание встречается многократно, то релевантность может повышаться, т.е., во-первых, учитываются отрицания непосредственно на объектах, а во-вторых, на каждом из вложенных предикатов. Если в ячейке матрицы для предложения текста и для предложения запроса отрицания встречаются одинаково четное или одинаково нечетное количество раз, то релевантность будет выше, чем если в одном случае четное, а в другом – нечетное. Но при этом учитывается, сколько и каких предикатов разделяют отрицания, т.е. чем дальше по сопоставленным по кодовому расстоянию встречаются соответствующие для текста и запроса отрицания, тем ниже релевантность, даже если отрицаний одинаковое количество. Это снижение релевантности определяется по таблице значений, заданных для каждого предиката. Если в тексте, либо в запросе встречается больше отрицаний, то если несопоставленных отрицаний четное количество, то аналогично при подсчете релевантностей учитывается количество разделяющих предикатов в соответствии с заданными для них значениями, а если нечетное количество, то приписывается заданная низкая релевантность, устанавливаемая при наличии непарного несопоставленного отрицания. При этом, если используется не объект, входящий в запрос, а связанный с ним объект, то для предикатов соответствующего объекта к имеющемуся массиву Предикаты первого объекта или Предикаты первого объекта добавляются Преобразующие предикаты, и релевантность рассчитывается с учетом их наличия в цепочке, но при этом в образованной слиянием массивов цепочке возможно исключение следующих подряд предикатов, выполняющих противоположные преобразования (например, субстантивизация глагола и далее вербализация существительного). Итоговая релевантность для соответствующих элементов может определяться как произведение всех величин, меньших 1, с домножением на релевантность соответствия отрицаний, либо по любой другой формуле. Полученные релевантности для всех элементов структуры по некоторой заданной заранее формуле (например, частично взвешенное суммирование и частично перемножение) пересчитываются в единую релевантность отображения соответствующих ячеек двух матриц. При этом в указанной формуле, например, Предикаты первого объекта с Общими предикатами и Предикаты второго объекта с Общими предикатами по полученной для них релевантности могут перемножаться, а затем эти две величины суммироваться с весами, пропорциональными величине, обратной частоте каждого из объектов в массиве текстов. Аналогично, например, релевантности отрицаний для двух объектов могут взвешенно суммироваться тем же способом, а затем быть общим множителем для релевантности всей пары структур. 8. Для заданной пары предложений все вычисленные для отдельных структур ячеек релевантности сводятся к общей. При этом основой служат входящие в запрос объекты. Т.е. для каждой связи каждой пары объектов запроса вычисляется их релевантность для соответствующего предложения текста. Если связь пары объектов запроса встречается в предложении текста, то берется значение релевантности по ним. Если для объектов запроса в тексте встречаются связанные с ними объекты, то также используется рассчитанная для них вероятность с учетом поправок на необходимые для преобразования предикаты, как описано в п.7. Если возможны оба варианта, притом несколько раз, то устанавливается некоторая итоговая, вычисленная по некоторой заданной формуле (например, максимум релевантности или единица минус произведение разностей единицы и релевантностей) релевантность для пары объектов запроса, которую описанным в п.7 способом можно найти в предложении текста. Если пара объектов запроса не присутствует в тексте ни в каком виде, то релевантность для этой ячейки считается равной нулю. Если и в запросе, и в предложении текста структура встречается несколько раз, т.е. массив структур для ячейки содержит более одного элемента, то для сопоставления используются те структуры в предложении текста, что обеспечивают для каждой структуры из предложения запроса наибольшую релевантность, т.е. сопоставление происходит по принципу наибольшей релевантности. Если массив ячейки в запросе длиннее, то для оставшихся структур, которым по принципу наибольшей релевантности не было сопоставлено ни одной структуры в предложении текста, релевантность считается равной нулю. После чего считается общая релевантность матрицы предложения запроса, для чего релевантности, полученные описанным образом для структур ячеек матрицы предложения запроса, взвешенно суммируются. Вес каждой такой ячейки определяется значением элемента Общие предикаты, т.е. положением пары объектов по отношению к главному предикату клаузы. Вес определяется по типам и номерам аргументов вложенных предикатов, исходя из заранее заданных значений, притом вес тем больше, чем меньше элементов в массиве Общие предикаты, т.е. чем ближе ячейка к главному предикату клаузы. При этом, естественно, если структура в ячейке встречается несколько раз, то вес для этих структур будет одинаковым. Возможны дополнительные факторы, влияющие на вес ячейки, например, вес диагональных ячеек, указывающих только на наличие объектов, может корректироваться на определенную величину. Результатом оказываются значения релевантностей для каждой пары предложений запроса и выбранных предложений массива текстов. 9. Для каждого выбранного предложения массива текстов вычисляется среднее арифметическое по всем предложениям запроса, что считается релевантностью каждого выбранного предложения массива текстов запросу. 10. Для каждого из выбранных документов берутся релевантности каждого его предложения запросу. Если предложение документа не вошло в выбранные в п.5, то его релевантность запросу считается равной нулю. Исходя из этих значений для каждого документа вычисляются следующие показатели: – среднее арифметическое релевантности предложений; – наибольшее значение релевантности среди всех предложений; – значение диапазона релевантности, в который попадает наибольшее число предложений; – значение порога релевантности, выше которого имеется заданное количество предложений. Все эти показатели взвешенно суммируются, из чего вычисляется релевантность документа запросу. Вес каждого из показателей задается настройками пользователя. Также пользователь настраивает размер диапазона для третьего показателя и число предложений по отношению к числу предложений документа для четвертого показателя. Размер диапазона при этом задается либо фиксировано, либо автоматически корректируемым в зависимости от дисперсии релевантностей предложений, а в качестве значения этого параметра в любом случае берется среднее значение диапазона. В итоге рассчитывается релевантность каждого документа запросу, и в порядке снижения релевантности они выдаются в результатах поиска. В дополнение в результатах поиска могут выводиться несколько самых релевантных предложений для каждого документа. Относительно описанного в п.1 для поиска и для индексирования семантического анализа далее будет приведен один из возможных методов распознавания денотатов. Описанный далее метод будет исходить из уже выполненного синтаксического анализа, результаты которого представлены в виде лексем и синтаксических связей, причем для каждой лексемы определены также граммемы. Согласно предлагаемому способу распознавания денотатов для каждой лексемы задается набор множеств семантических классов. Семантические классы задаются таким образом, что сочетание лексемы и семантического класса однозначно задают денотат. При этом одному денотату могут быть приписаны несколько семантических классов, если последние имеют общие денотаты. В иерархиях семантических классов стоящий выше в иерархии включает в себя все денотаты всех стоящих ниже его в иерархии семантических классов. Иерархий может быть неограниченное количество, один и тот же семантический класс может принадлежать нескольким иерархиям, каждая иерархия имеет один верхний семантический класс, включающий денотаты всех входящих в иерархию семантических классов. Если несколько семантических классов одного множества для одной лексемы находятся в одной иерархии один как разновидность другого, то при дальнейшем рассмотрении множества семантических классов определенного денотата используется только нижний в иерархии семантический класс, несколько семантических классов указывается только если они находятся в параллельных иерархиях. Семантический анализ согласно предлагаемому алгоритму использует метод оперирования контекстно-свободными грамматиками и основывается на множестве правил вида При этом, если встречаются неизвестные слова, то им приписывается неизвестный семантический класс u, при этом возможно По сравнению с известными решениями предлагаемый способ позволяет находить предложения, эквивалентные по смыслу предложениям запроса, даже если то же самое выражено другими словами. Это дает преимущества по сравнению с использованными известными алгоритмами поиска, которые находят только предложения с теми же словами, что и в запросе, либо с очень узкоописанными их синонимами.
Формула изобретения
1. Способ поиска информации в массиве текстов, заключающийся в том, что предварительно выполняют индексирование массива текстов по входящим в него предложениям с распознаванием точных значений слов, входящих в предложения запроса, путем замены их разложением на элементарные значения, которые хранятся для каждого значения в тезаурусе, после чего для каждого предложения запроса строят матрицу, содержащую связи между всеми парами объектов, входящих в предложение, затем выполняют поиск по тезаурусу объектов, имеющих корреляцию с объектам, входящими в запрос, после чего все объекты, входящие в запрос, и коррелирующие объекты находят в инвертированном индексе и на основе его данных из массива текстов отбирают предложения, для которых затем выполняют попарные сопоставления с предложениями запроса, для чего предварительно строят матрицу, отражающую соответствия между входящими в текст объектами и объектами, входящими в запрос, и коррелирующими объектами запроса, затем для объектов, связанных в полученной матрице, сопоставляют значения соответствующих этим объектам ячеек матриц, построенных для предложений массива текстов и для предложений запроса, на основе чего вычисляют релевантность предложений запроса предложениям массива текстов с помощью статистических показателей, затем в порядке снижения релевантности документы массива текстов представляют пользователю как результат поиска. 2. Способ по п.1, отличающийся тем, что индексирование массива текста происходит по отдельным предложениям, при этом в предложениях вначале распознают точные значения слов и устанавливают семантические связи между ними, затем точные значения слов заменяют их разложением на элементарные значения, которые хранятся для каждого значения в тезаурусе, после чего для каждого предложения строят матрицу, содержащую связи между всеми парами объектов, входящих в предложение, затем составляют инвертированный индекс, где для каждого объекта, входящего в массив текста, указано в каких документах и в каких предложениях сколько раз он встречается.
|
||||||||||||||||||||||||||
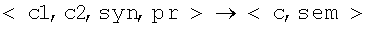 , где c1 – семантический класс, входящий в определенное множество набора для первой лексемы, с2 – семантический класс, входящий в определенное множество набора для второй лексемы, syn – тип синтаксической связи, pr – служебное слово в сочетании с граммемами управляемой лексемы, sem – тип семантической связи, с – семантический класс полученной объединенной группы. Согласно предлагаемому алгоритму, как и для синтаксического анализа, возможны нисходящий и восходящий анализ, поиск в ширину и в глубину. При нисходящим анализе для некоторого <с,sem> подбирается лексема с семантическим классом c1, имеющая синтаксическую связь syn и управление pr с некоторым непосредственным составляющим, в результате чего отделяется семантический класс с2, который раскладывается дальше аналогично семантическому классу с. При восходящем анализе выбираются лексемы с семантическими классами c1 и с2, с синтаксической связью syn и управлением pr, в результате чего образуется семантический класс с, который аналогично c1 и с2 объединяется со следующими лексемами. Алгоритмами, применяемыми при синтаксическом анализе, чередуя нисходящий и восходящий анализ, поиск в ширину и в глубину, необходимо достичь объединения семантическими связями sem всех лексем предложения, изначально связанных синтаксическими связями.
, где c1 – семантический класс, входящий в определенное множество набора для первой лексемы, с2 – семантический класс, входящий в определенное множество набора для второй лексемы, syn – тип синтаксической связи, pr – служебное слово в сочетании с граммемами управляемой лексемы, sem – тип семантической связи, с – семантический класс полученной объединенной группы. Согласно предлагаемому алгоритму, как и для синтаксического анализа, возможны нисходящий и восходящий анализ, поиск в ширину и в глубину. При нисходящим анализе для некоторого <с,sem> подбирается лексема с семантическим классом c1, имеющая синтаксическую связь syn и управление pr с некоторым непосредственным составляющим, в результате чего отделяется семантический класс с2, который раскладывается дальше аналогично семантическому классу с. При восходящем анализе выбираются лексемы с семантическими классами c1 и с2, с синтаксической связью syn и управлением pr, в результате чего образуется семантический класс с, который аналогично c1 и с2 объединяется со следующими лексемами. Алгоритмами, применяемыми при синтаксическом анализе, чередуя нисходящий и восходящий анализ, поиск в ширину и в глубину, необходимо достичь объединения семантическими связями sem всех лексем предложения, изначально связанных синтаксическими связями.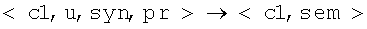 и
и 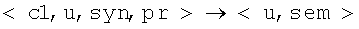 . Если правила не позволяют построить семантические связи в предложении, то делаются попытки приписать и известным словам, крайним случаем может быть, что всем словам приписан неизвестный семантический класс u.
. Если правила не позволяют построить семантические связи в предложении, то делаются попытки приписать и известным словам, крайним случаем может быть, что всем словам приписан неизвестный семантический класс u.