Патент на изобретение №2167939
|
||||||||||||||||||||||||||
(54) СПОСОБ ПРОДУЦИРОВАНИЯ ПОЛИПЕПТИДА В ДРОЖЖАХ
(57) Реферат: Изобретение относится к биотехнологии. Способ продуцирования полипептида в дрожжах заключается в культивировании дрожжевой клетки, способной экспрессировать этот полипептид, трансформированной дрожжевым вектором экспрессии, содержащим экспрессирующую кассету. Кассета включает промоторную последовательность, ДНК последовательность, кодирующую сигнальный пептид, терминаторную последовательность, ДНК, кодирующую желаемый пептид, ДНК, кодирующую процессинговый сайт, и ДНК последовательность LS, кодирующую лидерный пептид общей формулы 1: GlnProlle(Asp/Glu)(Asp/Glu)X1(Glu/Asp)X2AsnZ(Thr/Ser)X3 1, где Х1 обозначает пептидную связь или кодируемую аминокислоту, Х2 обозначает пептидную связь или кодируемую аминокислоту, или последовательность до 4 одинаковых или разных кодируемых аминокислот, Z обозначает кодируемую аминокислоту кроме Рro, и Х3 обозначает последовательность от 4 до 30 одинаковых или разных кодируемых аминокислот. Культивирование проводят в подходящей среде для достижения экспрессии и секреции указанного полипептида, после чего это полипептид выделяют из среды. 22 з.п. ф-лы, 22 ил., 2 табл. Настоящее изобретение относится к синтетическим лидерным пептидным последовательностям для секреции полипептидов в дрожжах. ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ Дрожжевые организмы продуцируют большое число белков, синтезируемых внутриклеточно, но функционирующих за пределами клетки. Такие внеклеточные белки называют секретируемыми белками. Эти секретируемые белки сначала экспрессируются внутри клетки в форме предшественника (или пре-белка), содержащего предпоследовательность, обеспечивающую эффективное направление экспрессированного продукта через мембрану эндоплазматического ретикулума (ЭР). Предпоследовательность, которую обычно называют сигнальным пептидом, обычно отщепляется от интересующего нас продукта в ходе транслокации. Предназначенный для секреции белок транспортируется в аппарат Гольджи. Из аппарата Гольджи белок может быть различными путями доставлен в компартменты, такие как клеточная вакуоль или клеточная мембрана, или может быть выведен из клетки для секреции во внешнюю среду [1]. Было предложено несколько подходов к экспрессии и секреции в дрожжах гетерологичных для них белков. Известен [2] способ, при котором гетерологичные для дрожжей белки экспрессируются, процессируются и секретируются путем трансформации дрожжевого организма вектором экспрессии, несущим кодирующую интересующий нас белок ДНК и сигнальный пептид, получения культуры трансформированного организма, выращивания этой культуры и выделения указанного белка из такой культуральной среды. Сигнальный пептид может быть собственным сигнальным пептидом интересующего нас белка, гетерологичным сигнальным пептидом или гибридом нативного и гетерологичного сигнального пептида. При использовании гетерологичных для дрожжей сигнальных пептидов может встать проблема необеспечения гетерологичным сигнальным пептидом эффективной транслокации и/или последующего отщепления такого сигнального пептида. Известно [3], что MF 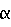 1 (-фактор) Saccharomyces cerevisiae синтезируется в препро форме из 165 аминокислот, содержащей сигнальный или препептид из 19 аминокислот, за которым следует “лидер” или пропептид из 64 аминокислот, включающий в себя три N-связанных сайта гликозилирования, за которым следует (Ly-sArg(Asp/Glu, Ala)2-3 -фактор)4. Сигнально-лидерная часть препpoMF1 широко используется для достижения синтеза и секреции гетерологичных белков в S. cerevisiae.
Использование сигнал/лидер пептидов гомологичных для дрожжей известно из [4-10].
Для секреции чужеродных белков описано использование предшественника -фактора S. cerevisiae [9], сигнального пептида инвертазы S.cerevisiae [10] и использование сигнального пептида PH05 S.cerevisiae [11].
Описаны [4-8] способы, при помощи которых сигнал-лидер -фактора S.cerevisiae (MF и MF2) используют для секреции экспрессированных гетерологичных белков в дрожжах. Путем присоединения ДНК-последовательности, кодирующей сигнал/лидер последовательность MF1 S.cerevisiae, к 5′ концу гена, кодирующего интересующий нас белок, была продемонстрирована секреция и процессинг интересующего нас белка.
Известна [12] система секреции полипептидов из S.cerevisiae с использованием лидерной последовательности -фактора, усеченной для исключения четырех единиц -фактора, присутствующих на нативной лидерной последовательности, с тем чтобы оставить сам лидерный пептид, присоединенный к гетерологичному полипептиду через процессинговый сайт -фактора LysArgGluAlaGluAla. Указано, что такая конструкция приводит к эффективному процессингу небольших пептидов (менее 50 аминокислот). Для секреции и процессинга более крупных пептидов нативная лидерная последовательность -фактора была усечена, чтобы оставить одну или две единицы -фактора между лидерным пептидом и полипептидом.
Множество секретируемых белков подвергается воздействию протеолитической процессинговой системы, способной расщеплять пептидную связь на карбокси-конце двух последовательных основных аминокислот. Эта ферментативная активность кодируется в S.cerevisiae геном KEX 2 [13]. Процессинг продукта протеазой KEX 2 необходим для секреции активного скрещивающего фактора 1 (MF1 или -фактора) S. cerevisiae, в то время как KEX 2 не вовлечена в секрецию активного скрещивающего фактора a S.cerevisiae.
Секреция и корректный процессинг полипептида, который должен быть секретирован, достигается в некоторых случаях при культивировании дрожжевых организмов, которые трансформированы вектором, сконструированным, как указано в приведенных выше ссылках. Однако во многих случаях уровень секреции очень низок или секреция отсутствует, или протеолитический процессинг осуществляется некорректно или неполностью. Таким образом, задачей данного изобретения является создание лидерных пептидов, которые обеспечивают более эффективную экспрессию и/или процессинг полипептидов.
РЕЗЮМЕ 1 (-фактор) Saccharomyces cerevisiae синтезируется в препро форме из 165 аминокислот, содержащей сигнальный или препептид из 19 аминокислот, за которым следует “лидер” или пропептид из 64 аминокислот, включающий в себя три N-связанных сайта гликозилирования, за которым следует (Ly-sArg(Asp/Glu, Ala)2-3 -фактор)4. Сигнально-лидерная часть препpoMF1 широко используется для достижения синтеза и секреции гетерологичных белков в S. cerevisiae.
Использование сигнал/лидер пептидов гомологичных для дрожжей известно из [4-10].
Для секреции чужеродных белков описано использование предшественника -фактора S. cerevisiae [9], сигнального пептида инвертазы S.cerevisiae [10] и использование сигнального пептида PH05 S.cerevisiae [11].
Описаны [4-8] способы, при помощи которых сигнал-лидер -фактора S.cerevisiae (MF и MF2) используют для секреции экспрессированных гетерологичных белков в дрожжах. Путем присоединения ДНК-последовательности, кодирующей сигнал/лидер последовательность MF1 S.cerevisiae, к 5′ концу гена, кодирующего интересующий нас белок, была продемонстрирована секреция и процессинг интересующего нас белка.
Известна [12] система секреции полипептидов из S.cerevisiae с использованием лидерной последовательности -фактора, усеченной для исключения четырех единиц -фактора, присутствующих на нативной лидерной последовательности, с тем чтобы оставить сам лидерный пептид, присоединенный к гетерологичному полипептиду через процессинговый сайт -фактора LysArgGluAlaGluAla. Указано, что такая конструкция приводит к эффективному процессингу небольших пептидов (менее 50 аминокислот). Для секреции и процессинга более крупных пептидов нативная лидерная последовательность -фактора была усечена, чтобы оставить одну или две единицы -фактора между лидерным пептидом и полипептидом.
Множество секретируемых белков подвергается воздействию протеолитической процессинговой системы, способной расщеплять пептидную связь на карбокси-конце двух последовательных основных аминокислот. Эта ферментативная активность кодируется в S.cerevisiae геном KEX 2 [13]. Процессинг продукта протеазой KEX 2 необходим для секреции активного скрещивающего фактора 1 (MF1 или -фактора) S. cerevisiae, в то время как KEX 2 не вовлечена в секрецию активного скрещивающего фактора a S.cerevisiae.
Секреция и корректный процессинг полипептида, который должен быть секретирован, достигается в некоторых случаях при культивировании дрожжевых организмов, которые трансформированы вектором, сконструированным, как указано в приведенных выше ссылках. Однако во многих случаях уровень секреции очень низок или секреция отсутствует, или протеолитический процессинг осуществляется некорректно или неполностью. Таким образом, задачей данного изобретения является создание лидерных пептидов, которые обеспечивают более эффективную экспрессию и/или процессинг полипептидов.
РЕЗЮМЕНеожиданно был обнаружен новый тип лидерного пептида, который позволяет достигать высокого уровня секреции полипептидов в дрожжах. Согласно этому данное изобретение относится к ДНК экспрессирующей кассете, включающей в себя следующую последовательность: 5′-P-SP-LS-PS-*ген*-(Т)i-3′, где P обозначает промоторную последовательность, SP обозначает ДНК последовательность, кодирующую сигнальный пептид, LS обозначает ДНК последовательность, кодирующую лидерный пептид общей формулы I: GlnProIle(Asp/Glu)(Asp/Glu)X1(Glu/Asp)X2AsnZ(Thr/Ser)X3, (I) где Х1 обозначает пептидную связь или кодируемую аминокислоту, Х2 обозначает пептидную связь или кодируемую аминокислоту, или последовательность до 4 одинаковых или разных кодируемых аминокислот, Z обозначает кодируемую аминокислоту кроме Pro, и Х3 обозначает последовательность от 4 до 30 одинаковых или разных кодируемых аминокислот, PS обозначает ДНК последовательность, кодирующую процессинговый сайт, *ген* обозначает ДНК последовательность, кодирующую полипептид, Т обозначает терминаторную последовательность, и i равно 0 или 1. В данном контексте под термином “лидерный пептид” понимают пептид, чей функцией является позволить экспрессированному полипептиду быть направленным из эндоплазматического ретикулума в аппарат Гольджи и далее в секреторные везикулы для секреции в среду (то есть передвижение экспрессированного полипептида через клеточную стенку или по меньшей мере через клеточную мембрану в периплазматическое пространство клетки). Выражение “синтетический”, используемое по отношению к лидерным пептидам, подразумевает, что такой лидерный пептид не обнаруживается в природе. Выражение “сигнальный пептид” обозначает препоследовательность, главной особенностью которой является гидрофобная природа, и которая присутствует как N-концевая последовательность в предшественнике внеклеточного белка, экспрессируемого в дрожжах. Функция сигнального пептида заключается в том, чтобы позволить экспрессированному белку, который должен быть секретирован, попасть в эндоплазматический ретикулум. Сигнальный пептид в норме отщепляется в течение данного процесса. Сигнальный пептид может быть гетерологичным или гомологичным для дрожжевого организма, продуцирующего указанный белок. Выражение “полипептид” обозначает как гетерологичный полипептид, то есть полипептид, который не продуцируется в природе хозяйским дрожжевым организмом, так и гомологичный полипептид, то есть полипептид, который продуцируется в природе хозяйским дрожжевым организмом, и любые их проформы. В предпочтительном воплощении экспрессирующая кассета по изобретению кодирует гетерологичный полипептид. Выражение “кодируемая аминокислота” подразумевает аминокислоту, которая может быть закодирована при помощи триплета (“кодона”) нуклеотидоов. Если в аминокислотной последовательности, приведенной в настоящем описании, трехбуквенные коды двух аминокислот, разделенных косой чертой, даны в скобках, например (Asp/Glu), то подразумевается, что данная последовательность содержит либо одну, либо другую из этих аминокислот в соответствующем положении. Еще одним аспектом данного изобретения является способ продуцирования полипептидов в дрожжах, при котором в подходящей среде культивируют дрожжевую клетку, способную экспрессировать полипептид и которая трансформирована дрожжевым вектором экспрессии, как описано выше, содержащим лидерную пептидную последовательность по изобретению, с достижением экспрессии и секреции полипептида, после чего этот полипептид выделяют из среды. КРАТКОЕ ОПИСАНИЕ ФИГУР Настоящее изобретение иллюстрируется далее со ссылкой на прилагаемые фигуры. Фиг. 1 схематично изображает плазмиду pAK492. Фиг. 2 показывает часть последовательности ДНК, кодирующей сигнальный пептид/лидер/М13 предшественник инсулина. Фиг. 3 показывает конструкцию плазмиды pAK546. Фиг. 4 показывает аминокислотную последовательность лидера SEQ ID N 4 и кодирующую ее последовательность ДНК. Фиг. 5 показывает ДНК последовательность экспрессионной плазмиды pAK546 S. cerevisiae, кодирующей YAP3 сигнальный пептид, лидера SEQ ID N 4 и предшественник инсулина M13, и закодированную аминокислотную последовательность. Фиг. 6 показывает аминокислотную последовательность лидера SEQ ID N 6 и кодирующую ее последовательность ДНК. Фиг. 7 показывает аминокислотную последовательность лидера SEQ ID N 8 и кодирующую ее последовательность ДНК. Фиг. 8 показывает аминокислотную последовательность лидера SEQ ID N 17 и кодирующую ее последовательность ДНК. Фиг. 9 показывает аминокислотную последовательность лидера SEQ ID N 16 и кодирующую ее последовательность ДНК. Фиг. 10 показывает аминокислотную последовательность лидера SEQ ID N 19 и кодирующую ее последовательность ДНК. Фиг. 11 показывает аминокислотную последовательность лидера SEQ ID N 20 и кодирующую ее последовательность ДНК. Фиг. 12 показывает аминокислотную последовательность лидера SEQ ID N 21 и кодирующую ее последовательность ДНК. Фиг. 13 показывает фрагмент ДНК pAK527, используемый как прямая матрица в конструкции SEQ ID N 4 и 6. Фиг. 14 показывает фрагмент ДНК pAK531, используемый как прямая матрица в конструкции SEQ ID N 8. Фиг. 15 показывает фрагмент ДНК pAK555, используемый как прямая матрица в конструкции SEQ ID N 16 и 17. Фиг. 16 показывает фрагмент ДНК pAK559, используемый как прямая матрица в конструкции SEQ ID N 19 и 20. Фиг. 17 показывает фрагмент ДНК pAK562, используемый как прямая матрица в конструкции SEQ ID N 21. Фиг. 18 показывает аминокислотную последовательность лидера SEQ ID N 27 и кодирующую ее последовательность ДНК SEQ ID N 66. Фиг. 19 показывает аминокислотную последовательность SEQ ID N 70, удлиненного с N-конца предшественника инсулина M13, и кодирующую ее последовательность ДНК SEQ ID N 71. Фиг. 20 показывает аминокислотную последовательность лидера SEQ ID N 67 и кодирующую ее последовательность ДНК SEQ ID N 69. Фиг. 21 показывает фрагмент ДНК SEQ ID N 72 pAK614, используемый как прямая матрица в конструкции SEQ ID N 27. Фиг. 22 показывает фрагмент ДНК SEQ ID N 73 pAK625, используемый как прямая матрица в конструкции SEQ ID N 67. ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ Когда X1 в общей формуле I обозначает аминокислоту, она предпочтительно является Ser, Thr или Ala. Когда X2 в общей формуле I обозначает аминокислоту, она предпочтительно является Ser, Thr или Ala. Когда X2 в общей формуле I обозначает последовательность двух аминокислот, она предпочтительно представляет собой SerIle. Когда X2 в общей формуле I обозначает последовательность трех аминокислот, она предпочтительно представляет собой SerAlaIle. Когда X2 в общей формуле 1 обозначает последовательность четырех аминокислот, она предпочтительно представляет собой SerPheAlaThr. В предпочтительном воплощении X3 является аминокислотной последовательностью общей формулы II X4-X5-X6, (II) где X4 обозначает последовательность от 1 до 21 одинаковой или разной кодируемой аминокислоты, X5 обозначает Pro или одну из аминокислотных последовательностей ValAsnLeu или LeuAlaAsnVal- AlaMetAla, и X6 обозначает последовательность от 1 до 8 одинаковых или разных кодируемых аминокислот. В общей формуле II X4 предпочтительно обозначает аминокислотную последовательность, которая включает в себя один или несколько мотивов LeuValAsnLeu, SerValAsnLeu, MetAlaAsp, ThrGluSer, ArgPheAlaThr или ValAlaMetAla; или X4 обозначает аминокислотную последовательность, которая включает в себя последовательность AsnSerThr или AsnThrThr; или X4 обозначает аминокислотную последовательность, которая включает в себя последовательность (Ser/Leu)ValAsnLeu, (Ser/Leu)ValAsnLeuMetAlaAsp, (Ser/Leu)ValAsnLeuMetAlaAspAsp, (Ser/Leu)ValAsnLeuMetAlaAspAspThrGluSer, (Ser/Leu)ValAsnLeuMetAlaAspAspThrGluSer Ile или (Ser/Leu)ValAsnLeuMetAlaAspAspThrGluSerArgPheAlaThr; или X4 обозначает аминокислотную последовательность, которая включает в себя последовательность Asn(Thr/Ser)ThrLeu, Asn(Thr/Ser)ThrLeuAsnLeu или Asn(Thr/Ser)ThrLeuValAsnLeu; или любую их комбинацию. В общей формуле II X5 предпочтительно обозначает Pro или аминокислотную последовательность, которая включает в себя последовательность ValAsnLeu, LeuAlaAsnValAlaMetAla, LeuAspValValAsnLeuProGly или LeuAspValValAsnLeuIleSerMet. Когда X6 в общей формуле II обозначает одну аминокислоту, она предпочтительно является Ala, Gly, Leu, Thr, Val или Ser. Когда X6 в общей формуле II обозначает последовательность двух аминокислот, она предпочтительно представляет собой GlyAla или SerAla. Когда X6 в общей формуле II обозначает последовательность трех аминокислот, она предпочтительно представляет собой AlaValAla. Когда X6 в общей формуле II обозначает последовательность восьми аминокислот, она предпочтительно представляет собой GlyAlaAspSerLysThrValGlu. Примерами предпочтительных лидерных пептидов, кодируемых последовательностью ДНК LS, являются последовательности 1-67, приведенные в конце описания. Сигнальная последовательность (SP) может кодировать любой сигнальный пептид, который обеспечивает эффективное направление экспрессированного полипептида по секреторному пути в клетке. Этот сигнальный пептид может быть встречающимся в природе сигнальным пептидом или его функциональной частью либо синтетическим пептидом. Было обнаружено, что подходящими сигнальными пептидами являются сигнальный пептид -фактора, сигнальный пептид амилазы из слюны мыши [14], модифицированный сигнальный пептид карбоксипептидазы [15] или дрожжевой BAR1 сигнальный пептид [16] или сигнальный пептид липазы из Humicola lanuginosa или их производные. Описан [17] сигнальный пептид дрожжевой аспартиновой протеазы 3.
Подходящим дрожжевым процессинговым сайтом, кодируемым последовательностью ДНК PS, может быть любая парная комбинация Lys и Arg, такая как LysArg, ArgLys, LysLys или ArgArg, которая позволяет осуществлять процессинг данного полипептида с помощью KEX2 протеазы Saccharomyces cerevisiae или эквивалентной протеазы в других видах дрожжей [13]. Если KEX2 процессинг не подходит, например если он будет вести к расщеплению полипептидного продукта, например из-за присутствия двух последовательных основных аминокислот в самом интересующем нас продукте, то может быть выбран процессинговый сайт для другой протеазы, включающий в себя комбинацию аминокислот, не встречающуюся в полипептидном продукте, например процессинговый сайт для FXa, IleGluGlyArg [18].
Белком, продуцированным способом по изобретению, может быть любой белок, который успешно продуцируется в дрожжах. Примерами таких белков являются апротинин, ингибитор тканевого фактора пути метаболизма или ингибиторы других протеаз, инсулин или предшественники инсулина, человеческий или бычий гормон роста, интерлейкин, глюкагон, глюкагон-подобный пептид-1 (GLP-I), IGF-I, IGF-11, тканевой активатор плазминогена, трансформирующий фактор роста или  , происходящий из тромбоцитов фактор роста, ферменты или функциональный аналог любого из этих белков. В данном контексте термин “функциональный аналог” обозначает белок со сходными с нативным белком функциями (подразумевается скорее природа, чем уровень биологической активности нативного белка). Белок может быть структурно схож с нативным белком и может быть получен из нативного белка путем добавления одной или нескольких аминокислот к С- и/или N-концу нативного белка, путем замещения одной или нескольких аминокислот в одном или нескольких различных сайтах нативной аминокислотной последовательности, путем делеции одной или нескольких аминокислот с одного или с обоих концов нативного белка или в одном или нескольких сайтах аминокислотной последовательности, или путем вставки одной или нескольких аминокислот в один или несколько сайтов нативной аминокислотной последовательности. Такие модификации хорошо известны для некоторых упомянутых выше белков. Также предшественники или промежуточные продукты для других белков могут быть получены способом по изобретению. Примером подходящего предшественника является предшественник инсулина M13, содержащий аминокислотную последовательность B(l-29)-Ala-Ala-Lys-A(l-21), где А(1-21) обозначает А цепь человеческого инсулина и В(1-29) обозначает В цепь человеческого инсулина, в которой отсутствует Thr (B30).
Предпочтительны ДНК-конструкции, кодирующие лидерные последовательности, показанные на фиг. 4-12 или их подходящие модификации. Примерами подходящих модификаций последовательности ДНК являются замены нуклеотидов, которые не приводят к получению другой аминокислотной последовательности белка, а соответствуют использованию кодонов дрожжевого организма, в который вводят эту последовательность ДНК, или замены нуклеотидов, которые не приводят к получению другой аминокислотной последовательности и, следовательно, возможно, другой структуре белка. Другими примерами возможных модификаций являются вставки одного или нескольких кодонов в последовательность или добавление одного или нескольких кодонов к любому концу последовательности, или делеция одного или нескольких кодонов на любом конце или внутри данной последовательности.
Рекомбинантным вектором экспрессии, несущим экспрессирующую кассету , происходящий из тромбоцитов фактор роста, ферменты или функциональный аналог любого из этих белков. В данном контексте термин “функциональный аналог” обозначает белок со сходными с нативным белком функциями (подразумевается скорее природа, чем уровень биологической активности нативного белка). Белок может быть структурно схож с нативным белком и может быть получен из нативного белка путем добавления одной или нескольких аминокислот к С- и/или N-концу нативного белка, путем замещения одной или нескольких аминокислот в одном или нескольких различных сайтах нативной аминокислотной последовательности, путем делеции одной или нескольких аминокислот с одного или с обоих концов нативного белка или в одном или нескольких сайтах аминокислотной последовательности, или путем вставки одной или нескольких аминокислот в один или несколько сайтов нативной аминокислотной последовательности. Такие модификации хорошо известны для некоторых упомянутых выше белков. Также предшественники или промежуточные продукты для других белков могут быть получены способом по изобретению. Примером подходящего предшественника является предшественник инсулина M13, содержащий аминокислотную последовательность B(l-29)-Ala-Ala-Lys-A(l-21), где А(1-21) обозначает А цепь человеческого инсулина и В(1-29) обозначает В цепь человеческого инсулина, в которой отсутствует Thr (B30).
Предпочтительны ДНК-конструкции, кодирующие лидерные последовательности, показанные на фиг. 4-12 или их подходящие модификации. Примерами подходящих модификаций последовательности ДНК являются замены нуклеотидов, которые не приводят к получению другой аминокислотной последовательности белка, а соответствуют использованию кодонов дрожжевого организма, в который вводят эту последовательность ДНК, или замены нуклеотидов, которые не приводят к получению другой аминокислотной последовательности и, следовательно, возможно, другой структуре белка. Другими примерами возможных модификаций являются вставки одного или нескольких кодонов в последовательность или добавление одного или нескольких кодонов к любому концу последовательности, или делеция одного или нескольких кодонов на любом конце или внутри данной последовательности.
Рекомбинантным вектором экспрессии, несущим экспрессирующую кассету5′-P-SP-LS-PS-*ген*-(T)i-3′, где P, SP, LS, *ген*, Т и i определены выше, может быть любой вектор, способный реплицироваться в дрожжевых организмах. Промотором может быть любая последовательность ДНК, обнаруживающая транскрипционную активность в дрожжах, и которая может быть получена из генов, кодирующих либо гомологичные, либо гетерологичные для дрожжей белки. Такой промотор предпочтительно получают из генов, кодирующих гомологичные для дрожжей белки. Примерами подходящих промоторов являются промоторы Saccharomyces cerevisiae MF 1, TPI, ADH или PGK.
Показанные выше последовательности должны также предпочтительно быть присоединены к соответствующему терминатору, например TPI терминатору [19].
Рекомбинантный вектор экспрессии по изобретению содержит далее последовательность ДНК, способствующую репликации данного вектора в дрожжах. Примерами таких последовательностей являются гены репликации REP 1-3 и сайт инициации репликации дрожжевой плазмиды 2 . Такой вектор также может содержать селективный маркер, например TPI ген Schizosaccharomyces pombe [20].
Методы, используемые для лигирования последовательности 5′-P-SP-LS-PS-*ген*-(T)i-3′ и вставки их в подходящие дрожжевые векторы, содержащие необходимую для репликации в дрожжах информацию, являются хорошо известными специалистам [18]. Очевидно, что такой вектор может быть сконструирован либо путем получения ДНК-конструкции, содержащей полную последовательность 5′-P-SP-LS-PS-*ген*-(T)i-3′ с последующей вставкой этого фрагмента в подходящий вектор экспрессии, либо путем последовательной вставки в подходящий вектор фрагментов ДНК, кодирующих информацию об индивидуальных элементах (таких как промоторная последовательность, сигнальный пептид, лидерная последовательность GlnProlle (Asp/Glu) (Asp/Glu) X1 (Glu/Asp)X2AsnZ (Thr/Ser)X3, процессинговый сайт, полипептид и, если имеется, терминаторная последовательность), с последующим лигированием.
Дрожжевым организмом, используемым в способе по изобретению, может быть любой подходящий дрожжевой организм, который при культивировании продуцирует большие количества интересующего нас полипептида. Примерами подходящих дрожжевых организмов служат штаммы дрожжей видов Saccharomyces cerevisiae, Saccharomyces kluyveri, Saccharomyces pombe или Saccharomyces uvarum. Трансформацию дрожжевых клеток можно осуществить путем создания протопластов с последующей трансформацией известными способами. Средой, используемой для культивирования клеток, может быть любая традиционная среда, подходящая для выращивания дрожжевых организмов. Секретированный полипептид, значительная часть которого должна присутствовать в среде в правильно процессированной форме, может быть выделен из среды традиционными способами, включая отделение дрожжевых клеток от среды путем центрифугирования или фильтрации, осаждение белковых компонентов супернатанта или фильтрата с помощью соли, например сульфата аммония, с последующей очисткой различными хроматографическими методами, например ион-обменной хроматографией, аффинной хроматографией и т. д.
Настоящее изобретение далее демонстрируется на следующих примерах, которые не ограничивают рамки заявленного изобретения.
ПРИМЕРЫ . Такой вектор также может содержать селективный маркер, например TPI ген Schizosaccharomyces pombe [20].
Методы, используемые для лигирования последовательности 5′-P-SP-LS-PS-*ген*-(T)i-3′ и вставки их в подходящие дрожжевые векторы, содержащие необходимую для репликации в дрожжах информацию, являются хорошо известными специалистам [18]. Очевидно, что такой вектор может быть сконструирован либо путем получения ДНК-конструкции, содержащей полную последовательность 5′-P-SP-LS-PS-*ген*-(T)i-3′ с последующей вставкой этого фрагмента в подходящий вектор экспрессии, либо путем последовательной вставки в подходящий вектор фрагментов ДНК, кодирующих информацию об индивидуальных элементах (таких как промоторная последовательность, сигнальный пептид, лидерная последовательность GlnProlle (Asp/Glu) (Asp/Glu) X1 (Glu/Asp)X2AsnZ (Thr/Ser)X3, процессинговый сайт, полипептид и, если имеется, терминаторная последовательность), с последующим лигированием.
Дрожжевым организмом, используемым в способе по изобретению, может быть любой подходящий дрожжевой организм, который при культивировании продуцирует большие количества интересующего нас полипептида. Примерами подходящих дрожжевых организмов служат штаммы дрожжей видов Saccharomyces cerevisiae, Saccharomyces kluyveri, Saccharomyces pombe или Saccharomyces uvarum. Трансформацию дрожжевых клеток можно осуществить путем создания протопластов с последующей трансформацией известными способами. Средой, используемой для культивирования клеток, может быть любая традиционная среда, подходящая для выращивания дрожжевых организмов. Секретированный полипептид, значительная часть которого должна присутствовать в среде в правильно процессированной форме, может быть выделен из среды традиционными способами, включая отделение дрожжевых клеток от среды путем центрифугирования или фильтрации, осаждение белковых компонентов супернатанта или фильтрата с помощью соли, например сульфата аммония, с последующей очисткой различными хроматографическими методами, например ион-обменной хроматографией, аффинной хроматографией и т. д.
Настоящее изобретение далее демонстрируется на следующих примерах, которые не ограничивают рамки заявленного изобретения.
ПРИМЕРЫПлазмиды и ДНК Все плазмиды для экспрессии имеют C-POT тип. Такие плазмиды описаны [21] , и характеризуются наличием гена триозо фосфат изомеразы (РОТ) из Schizosaccharomyces pombe для селекции и стабилизации плазмид. Содержащие ген РОТ плазмиды могут быть получены из депонированного штамма E.coli (ATCC 39685). Далее эти плазмиды содержат промотор и терминатор триозо фосфат изомеразы из S. cerevisiae (PTPI и TTPI). Они идентичны pMT742 [22] (см.фиг.1), за исключением области, определенной рестрикционным сайтом EcoRI-XbaI, охватывающим область, кодирующую сигнал/лидер/продукт. Плазмиды pAK527, pAK531, pAK555, pAK559, pAK562, pAK614 и pAK625 были использованы в качестве ДНК-матриц в ПЦР, примененной в конструкции лидеров, описанной в примерах. Синтетические фрагменты ДНК, служащие в качестве прямых матриц, показаны на фиг. 13-17. За исключением показанных областей ДНК эти плазмиды идентичны pAK492, показанной на фиг. 1. Синтетические фрагменты ДНК были синтезированы на автоматическом ДНК-синтезаторе (Applied Biosystems model 380A) с использованием фосфорамидитной химии и коммерчески доступных реагентов [23]. Все остальные использованные материалы и методы являются широко известными [18]. Пример 1 Синтез лидера SEQ ID N 4 для экспрессии предшественника инсулина M13 в S.cerevisiae (штамм yAK546). Лидер SEQ ID N 4 имеет следующую аминокислотную последовательность: GlnProIleAspAspGluAsnThrThrSerValAsnLeuProVal. Были синтезированы следующие олигонуклеотиды: # 94 5′-TAAATCTATAACTACAAAAAACACATA-3′ SEQ ID N 29 # 333 5′-GACTCTCTTAACTGGCAAGTTGACA-3′ SEQ ID N 30 # 312 5′-AAGTACAAAGCTTCAACCAAGTGAGAACCACACAAGTGTTGGTTAACGAATCTCTT-3′ SEQ ID N 31 # 1845 5′-CATACACAATATAAACGACGG-3′ SEQ ID N 32 Следующие полимеразные цепные реакции (ПЦР) были осуществлены с использованием набора реагентов Gene Amp PCR (Perkin Elmer, 761 Main Avewalk, CT 06859, USA), согласно инструкции производителя. В течение реакции на ПЦР-смесь наслаивали 100 мкл минерального масла (Sigma Chemical СО, St. Louis MO, USA): Полимеразная цепная реакция N 1 5 мкл олигонуклеотида # 94 (50 пмоль) 5 мкл олигонуклеотида # 333 (50 пмоль) 10 мкл 10x ПЦР-буфера 16 мкл смеси dNTP 0,5 мкл Taq фермента 0,5 мкл плазмиды pAK527 (фиг. 13) в качестве матрицы (0,2 мкг ДНК) 63 мкл воды Было проведено в общем 12 циклов, один цикл составлял 94oC в течение 1 мин, 37oC в течение 2 мин, 72oC в течение 3 мин. ПЦР-смесь затем наносили на 2%-ный агарозный гель и стандартным образом проводили электрофорез [18]. Полученные фрагменты ДНК вырезали из агарозного геля и выделяли, используя Gene Clean kit (Bio 101 inc., PO BOX 2284, La Jolla, CA 92038, USA), согласно инструкции производителя. Полимеразная цепная реакция N 2 5 мкл олигонуклеотида # 312 (50 пмоль) 5 мкл олигонуклеотида # 94 (50 пмоль) 10 мкл 10x ПЦР-буфера 16 мкл смеси dNTP 0,5 мкл Taq фермента 10 мкл очищенного фрагмента ДНК из ПЦР N1 53,5 мкл воды Было проведено в общем 12 циклов, один цикл составлял 94oC в течение 1 мин, 37oC в течение 2 мин, 72oC в течение 3 мин. Полученные после ПЦР N 2 фрагменты ДНК выделяли и очищали, используя Gene Clean kit (Bio 101 inc., PO BOX 2284, La Jolla, CA 92038, USA), согласно инструкции производителя. Очищенные ПЦР фрагменты ДНК растворяли в 10 мкл воды и буфера для рестрикционных нуклеаз, и разрезали рестрикционными эндонуклеазами Asp 718 и Hind III в общем объеме 15 мкл, используя стандартные методики [18]. Фрагмент ДНК 167 пн Asp 718/Hind III подвергали электрофорезу на агарозном геле и очищали, используя Gene Clean kit, как описано. S.cerevisiae экспрессионная плазмида pAK492 (показано на фиг. 1) является производной описанной выше плазмиды pMT742, в которой фрагмент, кодирующий сигнал/лидер/предшественник инсулина был заменен на EcoRI-Xbal фрагмент, показанный на фиг. 2. Этот фрагмент был синтезирован на Applied Biosystem ДНК синтезаторе, согласно инструкциям производителя. Плазмиду pAK492 разрезали рестрикционными эндонуклеазами Asp 718 и Hind III и выделяли фрагмент ДНК 140 пн, кодирующий часть предшественника инсулина M13. Три фрагмента ДНК лигировали вместе, используя N4 ДНК-лигазу в стандартных условиях [18]. Затем лигированной смесью трансформировали компетентный штамм E.coli (R-, М+) и определяли трансформантов по устойчивости к ампицилину. Выделяли плазмиды из полученных колоний E.coli, используя стандартные методики [18], осуществляя проверку подходящими рестрикционными эндонуклеазами, то есть EcoRI,- XbaI, NcoI и Hind III. С помощью ДНК сиквенс- анализа (Sequenase, U.S. Biochemical Corp. ) с использованием праймера # 94 было показано, что отселектированная плазмида pAK546 содержит последовательность ДНК, кодирующую лидер SEQ ID N 4. Последовательность ДНК, кодирующая лидер SEQ ID No. 4, показана на фиг. 4. Плазмидой pAK546 трансформировали штамм MT663 S.cerevisiae [24] и назвали полученный штамм yAK546. Последовательность ДНК области экспрессионной плазмиды, кодирующей белок, дана на фиг. 5. Пример 2 Синтез лидера SEQ ID N 6 для экспрессии предшественника инсулина M13 в S.cerevisiae (штамм YAK531). Лидер SEQ ID N 6 имеет следующую аминокислотную последовательность: GlnProIleAspAspThrGluSerAsnThrThrSerValAsnLeuProAla. Были синтезированы следующие олигонуклеотиды: # 331 5′-GAATCTCTTAGCTGGCAAGTTGACAGAAGTAGTGTTAG TTTCAGAGTCGTCAATT-3′ SEQ ID N 33 Полимеразная цепная реакция была проведена, как описано в примере 1, но вместо олигонуклеотида # 333 использовали олигонуклеотид # 331. Фрагмент ДНК 168 пн Asp 718/Hind III подвергали электрофорезу на агарозном геле и очищали, как описано в примере 1. Фрагмент ДНК Asp 718/Hind III субклонировали в S. cerevisiae экспрессионной плазмиде, как описано в примере 1. С помощью ДНК сиквенс-анализа, как описано в примере 1, было показано, что отселектированная плазмида pAK531 содержит последовательность ДНК, кодирующую лидер SEQ ID N 6. Последовательность ДНК, кодирующая лидер SEQ ID N 6, показана на фиг.6. Плазмидой pAK531 трансформировали штамм MT663 S.cerevisiae [25] и назвали полученный штамм yAK531. Последовательности ДНК, кодирующие сигнальный пептид и предшественник инсулина M13, являются такими же, как на фиг.5. Пример 3 Синтез лидера SEQ ID N 8 для экспрессии предшественника инсулина M13 в S.cerevisiae (штамм yAK547). Лидер SEQ ID N 8 имеет следующую аминокислотную последовательность: GinProIleAspAspThrGluSerAsnThrThrSerValAsnLeuProAla. Были синтезированы следующие олигонуклеотиды: # 345 5′-AACGAATCTCTTAGCACCTGGCAAGTTGACAGAAGT-3′ SEQ ID N 34 Полимеразная цепная реакция была проведена, как описано в примере 1, но вместо олигонуклеотида # 333 использовали олигонуклеотид # 345 и в качестве матрицы-плазмиду pAK531 (фиг.14). Фрагмент ДНК 171 пн Asp 718/Hind III подвергали электрофорезу на агарозном геле и очищали, как описано в примере 1. Фрагмент ДНК Asp 718/Hind III субклонировали в S. cerevisiae экспрессионной плазмиде, как описано в примере 1. С помощью ДНК сиквенс-анализа, как описано в примере 1, было показано, что отселектированная плазмида pAK547 содержит последовательность ДНК, кодирующую лидер SEQ ID N 8. Последовательность ДНК, кодирующая лидер SEQ ID N 8, показана на фиг. 7. Плазмидой pAK547 трансформировали штамм MT663 S. cerevisiae [25] и назвали полученный штамм yAK547. Последовательности ДНК, кодирующие сигнальный пептид и предшественник инсулина M13, являются такими же, как на фиг. 5. Пример 4 Синтез лидера SEQ ID N 17 для экспрессии предшественника инсулина M13 в S.cerevisiae (штамм yAK561). Лидер SEQ ID N 17 имеет следующую аминокислотную последовательность: GlnProIleAspAspThrGluSerAsnThrThrLeuValAsnLeuProGlyAla. Были синтезированы следующие олигонуклеотиды: 25 # 376 5′-AACGAATCTCTTAGCACCTGGCAAGTTGACCAAAGTAGTGTTGATAGATTCAGTGTCGTC-3′ SEQ ID N 35 Полимеразная цепная реакция была проведена, как описано в примере 1, но вместо олигонуклеотида # 333 использовали олигонуклеотид # 376 и в качестве матрицы – плазмиду pAK555 (фиг. 15). Фрагмент ДНК 180 пн Asp 718/Hind III подвергали электрофорезу на агарозном геле и очищали, как описано в примере 1. Фрагмент ДНК Asp 718/Hind III субклонировали в S.cerevisiae экспрессионной плазмиде, как описано в примере 1. С помощью ДНК сиквенс-анализа, как описано в примере 1, было показано, что отселектированная плазмида pAK561 содержит последовательность ДНК, кодирующую лидер SEQ ID N 17. Последовательность ДНК, кодирующая лидер SEQ ID No. 17, показана на фиг. 8. Плазмидой pAK561 трансформировали штамм MT663 S. cerevisiae [25] и назвали полученный штамм yAK561. Последовательности ДНК, кодирующие сигнальный пептид и предшественник инсулина M13, являются такими же, как на фиг. 5. Пример 5 Синтез лидера SEQ ID N 16 для экспрессии предшественника инсулина M13 в S.cerevisiae (штамм VAK559). Лидер SEQ ID N 16 имеет следующую аминокислотную последовательность: GinProIleAspAspThrGluSerAsnThrThrSerValAsnLeuMet- AlaAspAspThrGluSerIleAsnThrThrLeuValAsnLeuProGlyAla. Были синтезированы следующие олигонуклеотиды: # 375 5′-AACGAATCTCTTAGCACCTGGCAAGTTAACCAAAGTAGT GTTGATAGATTCAGTGTCGTCAGCCATCAAGTTGAC-3′ SEQ ID N 36 Полимеразная цепная реакция была проведена, как описано в примере 1, но вместо олигонуклеотида # 333 использовали олигонуклеотид # 375 и в качестве матрицы – плазмиду pAK555 (фиг.15). Фрагмент ДНК 222 пн Asp 718/Hind III подвергали электрофорезу на агарозном геле и очищали, как описано в примере 1. Фрагмент ДНК Asp 718/Hind III субклонировали в S.cerevisiae экспрессионной плазмиде, как описано в примере 1. С помощью ДНК сиквенс-анализа, как описано в примере 1, было показано, что отселектированная плазмида pAK559 содержит последовательность ДНК, кодирующую лидер SEQ ID N 16. Последовательность ДНК, кодирующая лидер SEQ ID N 16, показана на фиг. 9. Плазмидой pAK559 трансформировали штамм MT663 S. cerevisiae [25] и назвали полученный штамм yAK559. Последовательности ДНК, кодирующие сигнальный пептид и предшественник инсулина M13, являются такими же, как на фиг. 5. Пример 6 Синтез лидера SEQ ID N 19 для экспрессии предшественника инсулина M13 в S.cerevisiae (штамм yAK580). Лидер SEQ ID N 19 имеет следующую аминокислотную последовательность: GlnProIleAspAspThrGluSerAsnThrThrSerValAsnLeuMet- AlaAspAspThrGluSerArgPheAlaThrAsnThrThrLeuValAsnLeuProLeu. Были синтезированы следующие олигонуклеотиды: # 384 5′-AACGAATCTCTTCAATGGCAAGTTAACCAAAGTAGTGT TAGTAGCGAATCTAGATTCAGTGTCGTCAGCCAT-3′ SEQ ID N 37 Полимеразная цепная реакция была проведена, как описано в примере 1, но вместо олигонуклеотида # 333 использовали олигонуклеотид # 384 и в качестве матрицы – плазмиду pAK559 (фиг.16). Фрагмент ДНК 228 пн Asp 718/Hind III подвергали электрофорезу на агарозном геле и очищали, как описано в примере 1. Фрагмент ДНК Asp 718/Hind III субклонировали в S. cerevisiae экспрессионной плазмиде, как описано в примере 1. С помощью ДНК сиквенс-анализа, как описано в примере 1, было показано, что отселектированная плазмида pAK580 содержит последовательность ДНК, кодирующую лидер SEQ ID N 19. Последовательность ДНК, кодирующая лидер SEQ ID N 19, показана на фиг. 10. Плазмидой pAK580 трансформировали штамм MT663 S. cerevisiae [25] и назвали полученный штамм yAK580. Последовательности ДНК, кодирующие сигнальный пептид и предшественник инсулина M13, являются такими же, как на фиг. 5. Пример 7 Синтез лидера SEQ ID N 20 для экспрессии предшественника инсулина M13 в S.cerevisiae (штамм yAK583). Лидер SEQ ID N 20 имеет следующую аминокислотную последовательность: GlnProIleAspAspThrGluSerAsnThrThrSerValAsnLeuMet- AlaAspAspThrGluSerIleAsnThrThrLeuValAsnLeuAlaAsnValAlaMetAla Были синтезированы следующие олигонуклеотиды: # 390 5′-AACGAATCTCTTAGCCATGGCAACGTTAGCCAAGTTAA CCAAAGT-3′ SEQ ID N 38 Полимеразная цепная реакция была проведена, как описано в примере 1, но вместо олигонуклеотида # 333 использовали олигонуклеотид # 390 и в качестве матрицы – плазмиду pAK559 (фиг. 16). Фрагмент ДНК 231 пн Asp 718/Hind III подвергали электрофорезу на агарозном геле и очищали, как описано в примере 1. Фрагмент ДНК Asp 718/Hind III субклонировали в S.cerevisiae экспрессионной плазмиде, как описано в примере 1. С помощью ДНК сиквенс-анализа, как описано в примере 1, было показано, что отселектированная плазмида pAK583 содержит последовательность ДНК, кодирующую лидер SEQ ID N 20. Последовательность ДНК, кодирующая лидер SEQ ID N 20, показана на фиг.11. Плазмидой pAK583 трансформировали штамм MT663 S. cerevisiae [25] и назвали полученный штамм yAK583. Последовательности ДНК, кодирующие сигнальный пептид и предшественник инсулина M13, являются такими же, как на фиг. 5. Пример 8 Синтез лидера SEQ ID N 21 для экспрессии предшественника инсулина M13 в S.cerevisiae (штамм yAK586). Лидер SEQ ID N 21 имеет следующую аминокислотную последовательность: GlnProIleAspAspThrGluSerAlaIleAsnThrThrLeuValAsnLeuProGlyAla Были синтезированы следующие олигонуклеотиды: # 401 5′-AACGAATCTCTTAGCACCTGGCAAGTTGACCAAAGTAG TGTTGATAGCAGATTCAGTGTCG-3′ SEQ ID N 39 Полимеразная цепная реакция была проведена, как описано в примере 1, но вместо олигонуклеотида # 333 использовали олигонуклеотид # 401 и в качестве матрицы – плазмиду pAK562 (фиг. 17). Фрагмент ДНК 183 пн Asp 718/Hind III подвергали электрофорезу на агарозном геле и очищали, как описано в примере 1. Фрагмент ДНК Asp 718/Hind III субклонировали в S.cerevisiae экспрессионной плазмиде, как описано в примере 1. С помощью ДНК сиквенс-анализа, как описано в примере 1, было показано, что отселектированная плазмида pAK586 содержит последовательность ДНК, кодирующую лидер SEQ ID N 21. Последовательность ДНК, кодирующая лидер SEQ ID N 21, показана на фиг.12. Плазмидой pAK586 трансформировали штамм MT663 S.cerevisiae [25] и назвали полученный штамм yAK586. Последовательности ДНК, кодирующие сигнальный пептид и предшественник инсулина M13, являются такими же, как на фиг. 5. Пример 9 Экспрессия предшественника инсулина с использованием выбранных лидерных последовательностей согласно настоящему изобретению. Дрожжевой штамм, несущий плазмиды, как описано выше, выращивают на YPD среде [26]. Для каждого штамма помещают на качалку при 30oC на 72 ч 6 индивидуальных культур по 5 мл до финальной OD600 около 15. После центрифугирования удаляют супернатант для HPLC анализа, с помощью которого измеряют концентрацию секретированного предшественника инсулина [27]. В таблице 1 даны уровни экспрессии предшественника инсулина M13, полученные с использованием выбранных лидерных последовательностей согласно изобретению, в виде процента от уровня, полученного у трансформантов pMT742 с использованием MF (1) лидер S.cerevisiae.
Пример 10Синтез лидера SEQ ID N 27 для экспрессии предшественника инсулина M13 в S.cerevisiae (штамм yAK677). Лидер SEQ ID N 27 имеет следующую аминокислотную последовательность: GlnProIleAspAspThrGluSerAsnThrThrSerValAsnLeuMet- AlaAspAspThrGluSerArgPheAlaThrAsnThrThrLeuAspValValAsnLeuIleSerMetAla. Были синтезированы следующие олигонуклеотиды: # 440 5′-GGTTAACGAACTTTGGAGCTTCAGCTTCAGCTTCTTCTCTCTTAGCCAT GGAGATCAAGTTAACAACATCCAAAGTAGTGTT-3′ SEQ ID N 64 и # 441 5′-CAAGTACAAAGCTTCAACCAAGTGGGAACCGCACAAGTGTTGGTTAACG AACTT-3′ SEQ ID N 65 Полимеразная цепная реакция была проведена, как описано в примере 1, но вместо олигонуклеотида # 333 использовали олигонуклеотид # 440 и в качестве матрицы – плазмиду pAK614. Для второй ПЦР вместо олигонуклеотида # 312 использовали олигонуклеотид # 441. Очищенные ПЦР фрагменты ДНК выделяли и разрезали рестрикционными эндонуклеазами Asp 718 и Hind III, как описано в примере 1. Фрагмент ДНК 268 пн Asp 718/Hind III подвергали электрофорезу на агарозном геле и очищали, как описано в примере 1. Фрагмент ДНК Asp 718/Hind III субклонировали в S.cerevisiae экспрессионной плазмиде, как описано в примере 1, за исключением того, что фрагмент 140 пн Hindlll/XbaI был получен из pAK602 и кодирует AspB28 человеческий инсулин. С помощью ДНК сиквенс-анализа, как описано в примере 1, было показано, что отселектированная плазиида pAK616 содержит последовательность ДНК, кодирующую лидер SEQ ID N 27. Последовательность ДНК SEQ ID N 66, кодирующая лидер SEQ ID N 27, показана на фиг.11. Фрагмент ДНК 268 пн Asp 718/Hind III из pAK616 выделяли и лигировали с фрагментом ДНК 10986 пн Asp 718/XbaI из pAK464 (кодирующим удлиненный AspB28 человеческий инсулин), обозначив pAK625. Фрагмент ДНК 180 пн Asp718/NcoI из pAK625 был выделен и лигирован с фрагментом ДНК 221 пн NcoI/XbaI из pJB146 (кодирующим удлиненный предшественник инсулина) и фрагментом ДНК 10824 пн Asp718/XbaI из pAK601, полученную плазмиду обозначили pAK677. Плазмидой pAK677 трансформировали штамм MT663 S.cerevisiae [25] и назвали полученный штамм yAK677. За исключением последовательности ДНК, кодирующей лидер, последовательность ДНК, кодирующая сигнальный пептид, показана на фиг. 5. Последовательность ДНК, кодирующая удлиненный предшественник инсулина M13, показана на фиг. 19. Пример 11 Синтез лидера SEQ ID N 67 для экспрессии предшественника инсулина M13 в S.cerevisiae (штамм yAK680). Лидер SEQ ID N 67 имеет следующую аминокислотную последовательность: GlnProIleAspAspThrGluSerAsnThrThrSerValAsnLeuMet- AlaAspAspThrGluSerArgPheAlaThrAsnThrThrLeuAlaLeuAspValValAsnLeuIleSerMetAla. Были синтезированы следующие олигонуклеотиды: # 577 5′-TCTCTTAGCCATGGAGATCAAGTTAACAACATCCAAAG CCAAAGTAGTGTT-3′ SEQ ID N 68 Полимеразная цепная реакция была проведена, как описано в примере 1, но вместо олигонуклеотида # 333 использовали олигонуклеотид # 557 и в качестве матрицы – плазмиду pAK625, а вторую ПЦР не проводили. ПЦР фрагмент разрезали рестрикционными эндонуклеазами Asp 718 и Nco I, как описано в примере 1. Фрагмент ДНК 190 пн Asp 718/NcoI подвергали электрофорезу на агарозном геле и очищали, как описано в примере 1, за исключением того, что векторный фрагмент ДНК 10824 пн Asp 718/XbaI был выделен из pAK601. Фрагмент ДНК 190 пн Asp 718/NcoI субклонировали в S.cerevisiae экспрессионной плазмиде, как описано в примере 1, за исключением того, что фрагмент 221 пн NcoI/XbaI (кодирующий удлиненную версию предшественника инсулина) был получен из pAK677 и использован вместо фрагмента HindIII/XbaI ДНК. С помощью ДНК сиквенс-анализа, как описано в примере 1, было показано, что отселектированная плазмида pAK680 содержит последовательность ДНК, кодирующую лидер SEQ ID N 67. Последовательность ДНК SEQ ID N 69, кодирующая лидер SEQ ID N 67, показана на фиг. 20. Плазмидой pAK680 трансформировали штамм MT663 S.cerevisiae [25] и назвали полученный штамм yAK680. За исключением последовательности ДНК, кодирующей лидер, последовательность ДНК, кодирующая сигнальный пептид, показана на фиг. 5. Последовательность ДНК, кодирующая удлиненный предшественник инсулина M13, показана на фиг. 19. Пример 12 Экспрессия удлиненного с N-конца предшественника инсулина M13 с использованием лидерных последовательностей SEQ ID N 27 и SEQ ID N 67 согласно настоящему изобретению Дрожжевой штамм, несущий плазмиды, как описано выше, выращивают на YPD среде [26] . Для каждого штамма помещают на качалку при 30oC на 72 ч 6 индивидуальных культур по 5 мл до финальной OD600 около 15. После центрифугирования удаляют супернатант для HPLC анализа, с помощью которого измеряют концентрацию секретированного предшественника инсулина [27]. В таблице 2 даны уровни экспрессии некоторых удлиненных с N-конца предшественников инсулина M13, полученных с использованием лидерных последовательностей SEQ ID N 27 и SEQ ID N67 согласно изобретению, в виде процента от уровня, полученного у трансформантов pMT742 с использованием MF (1) лидера S.cerevisiae.
Литература и перечень последовательностей приведены в конце описания.
Формула изобретения
GlnProIle(Asp/Glu)(Asp/Glu)X1(Glu/Asp)X2AsnZ(Thr/Ser)X3, где X1 обозначает пептидную связь или кодируемую аминокислоту; X2 обозначает пептидную связь или кодируемую аминокислоту, или последовательность до 4 одинаковых или разных кодируемых аминокислот; Z обозначает кодируемую аминокислоту кроме Pro; X3 обозначает последовательность от 4 до 30 одинаковых или разных кодируемых аминокислот, в подходящей среде для достижения экспрессии и секреции указанного полипептида, после чего этот полипептид выделяют из среды. 2. Способ по п.1, где X1 в формуле I обозначает Ser, Thr или Ala. 3. Способ по п.1, где X2 в формуле I обозначает Ser, Thr или Ala. 4. Способ по п.1, где X2 в формуле I обозначает SerIle. 5. Способ по п.1, где X2 в формуле I обозначает SerAlaIle. 6. Способ по п.1, где X2 в формуле I обозначает SerPheAlaThr. 7. Способ по п.1, где X3 в общей формуле I обозначает аминокислотную последовательность общей формулы II X4-X5-X6, где X4 обозначает последовательность от 1 до 21 кодируемой аминокислоты; X5 обозначает Pro или аминокислотную последовательность, которая включает в себя аминокислотную последовательность ValAsnLeu, LeuAlaAsnValAlaMetAla, LeuAspValValAsnLeuProGly или LeuAspValValAsnLeuIleSerMet; X6 обозначает последовательность от 1 до 8 кодируемых аминокислот. 8. Способ по п.7, где X4 в общей формуле II обозначает аминокислотную последовательность, которая включает в себя один или более чем один мотив LeuValAsnLeu, SerValAsnLeu, MetAlaAsp, ThrGluSer, ArgPheAlaThr или ValAlaMetAla. 9. Способ по п.7, где X4 в общей формуле II обозначает аминокислотную последовательность, которая включает в себя последовательность AsnSerThr или AsnThrThr. 10. Способ по п.7, где X4 в общей формуле II обозначает аминокислотную последовательность, которая включает в себя последовательность (Ser/Leu)ValAsnLeu; (Ser/Leu)ValAsnLeuMetAlaAsp; (Ser/Leu)ValAsnLeuMetAlaAspAsp; (Ser/Leu)ValAsnLeuMetAlaAspAspThrGluSer; (Ser/Leu)ValAsnLeuMetAlaAspAspThrGluSerIle; (Ser/Leu)ValAsnLeuMetAlaAspAspThrGluSerArgPheAlaThr. 11. Способ по п.7, где X4 в общей формуле II обозначает аминокислотную последовательность, которая включает в себя последовательность. Asn(Thr/Ser)ThrLeu; Asn(Thr/Ser)ThrLeuAsnLeu; Asn(Thr/Ser)ThrLeuValAsnLeu. 12. Способ по п.7, где X5 в общей формуле II обозначает Pro. 13. Способ по п.7, где X5 в общей формуле II обозначает аминокислотную последовательность ValAsnLeu. 14. Способ по п.7, где X5 в общей формуле II обозначает аминокислотную последовательность LeuAlaAsnValAlaMetAla. 15. Способ по п.7, где X5 в общей формуле II обозначает аминокислотную последовательность LeuAspValValAsnLeuProGly. 16. Способ по п.7, где X5 в общей формуле II обозначает аминокислотную последовательность LeuAspValValAsnLeuIleSerMet. 17. Способ по п.7, где X6 в общей формуле II обозначает Ala, Gly, Leu, Thr, Val или Ser. 18. Способ по п.7, где X6 в общей формуле II обозначает GlyAla или SerAla. 19. Способ по п.7, где X6 в общей формуле II обозначает AlaValAla. 20. Способ по п.7, где X6 в общей формуле II обозначает GlyAlaAspSerLysThrValGlu. 21. Способ по п.1, где лидерный пептид, кодируемый ДНК последовательностью LS, выбран из группы, содержащей SEQ ID 1-28,67, приведенной в графической части. 22. Способ по п.1, где сигнальный пептид представляет собой сигнальный пептид -фактора, сигнальный пептид мышиной слюнной амилазы, сигнальный пептид карбоксипептидазы, сигнальный пептид дрожжевой аспартиновой протеазы 3 или дрожжевой BAR1 сигнальный пептид.
23. Способ по п.1, где процессинговый сайт представляет собой LysArg, ArgLys, ArgArg, LysLys или Ile-GluGlyArg.
РИСУНКИ
MM4A – Досрочное прекращение действия патента СССР или патента Российской Федерации на изобретение из-за неуплаты в установленный срок пошлины за поддержание патента в силе
Дата прекращения действия патента: 17.06.2006
Извещение опубликовано: 20.12.2007 БИ: 35/2007
|
||||||||||||||||||||||||||