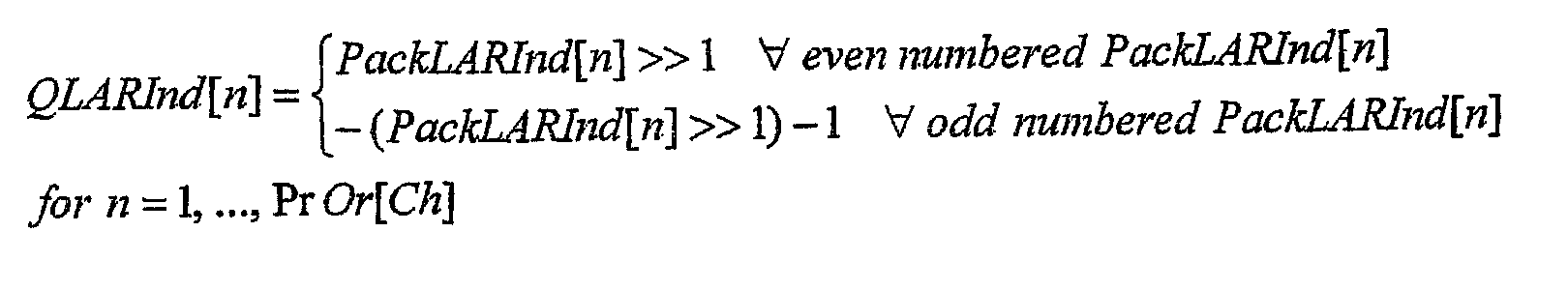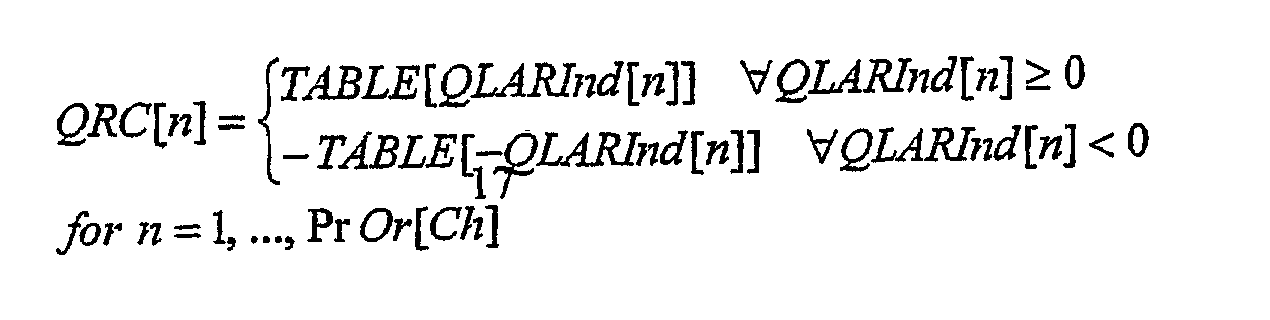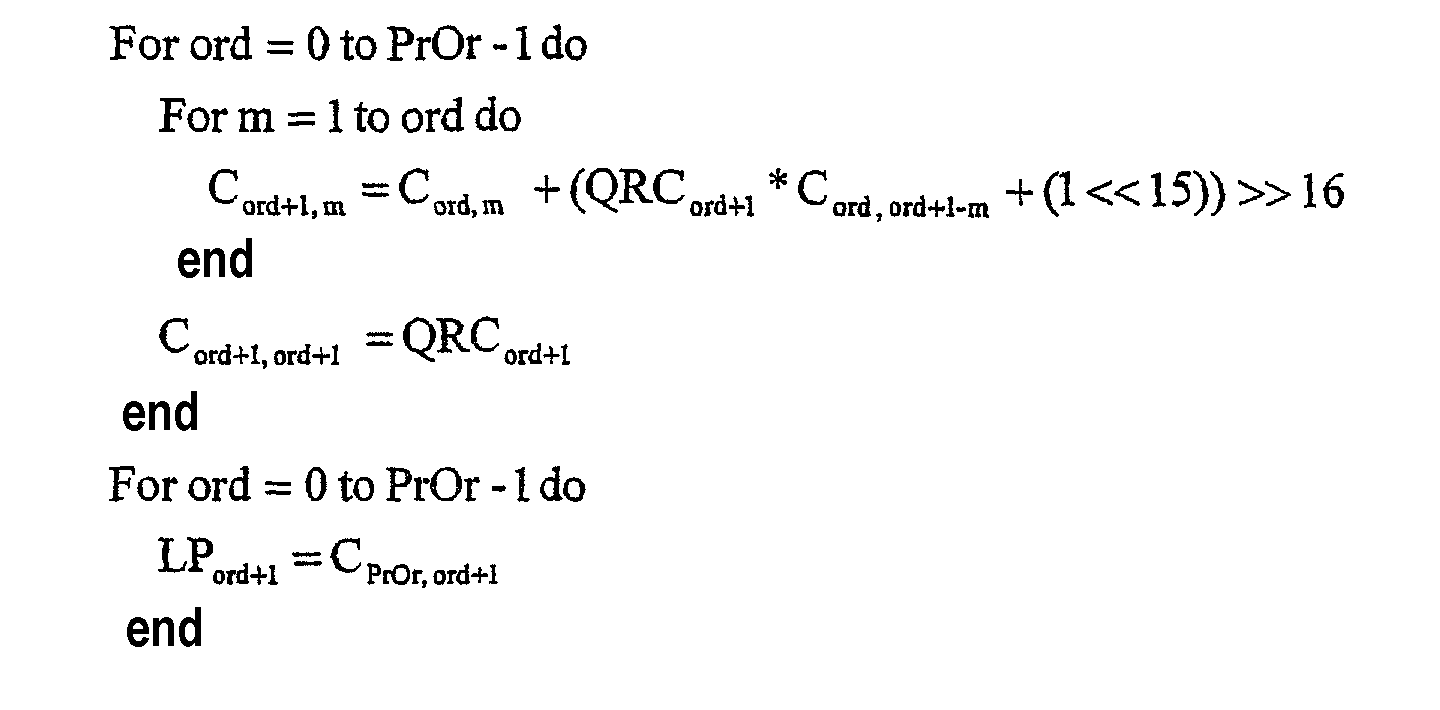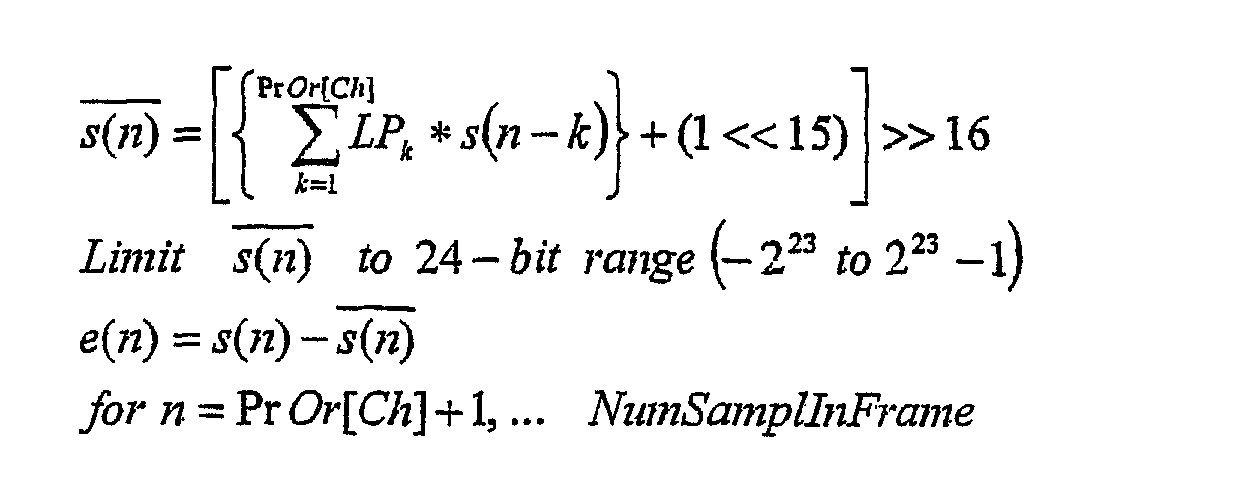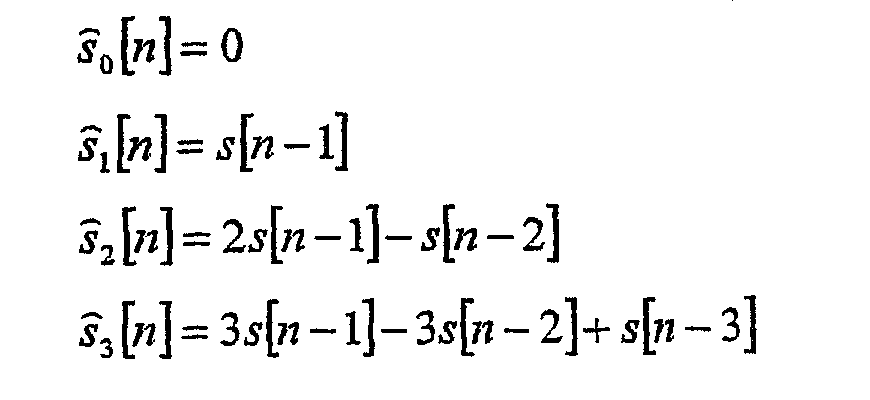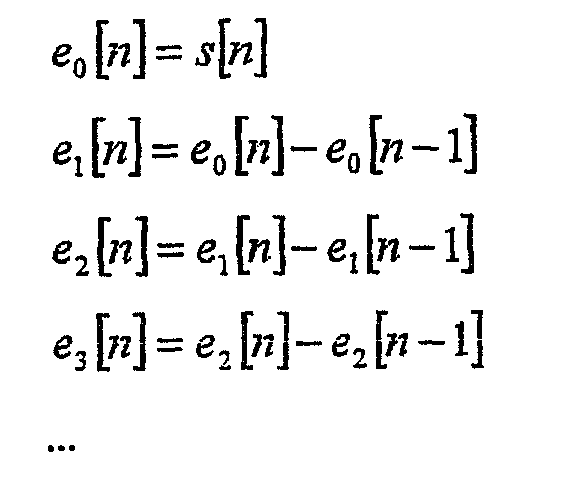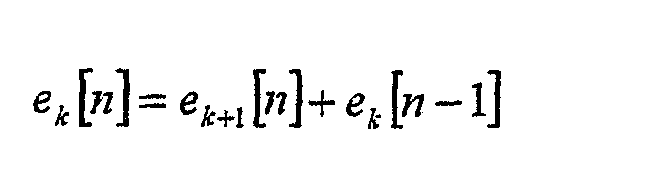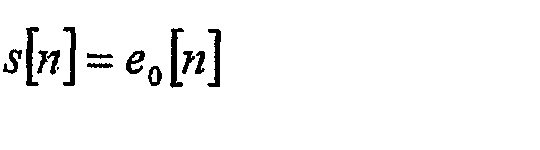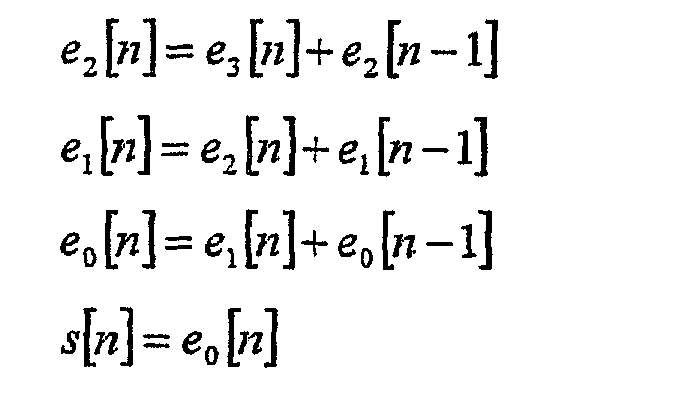Патент на изобретение №2387023
|
||||||||||||||||||||||||||
(54) МНОГОКАНАЛЬНЫЙ АУДИОКОДЕР БЕЗ ПОТЕРЬ
(57) Реферат:
Изобретение относится к аудиокодекам без потерь, более конкретно к многоканальным аудиокодекам без потерь. Аудиокодек без потерь сегментирует аудиоданные в пределах каждого кадра при условии ограничения, что каждый сегмент должен полностью декодироваться и быть меньше максимального размера. Для каждого кадра кодек выбирает длительность сегмента и параметры кодирования, например, конкретный энтропийный кодер и его параметры для каждого сегмента, которые минимизируют кодированную полезную нагрузку для всего кадра, при условии данных ограничений. Для каждого канала можно выбирать отличающиеся наборы параметров кодирования, или для всех каналов можно выбирать глобальный набор параметров кодирования. Эффективность сжатия можно дополнительно увеличивать с помощью формирования М/2 декоррелированных каналов для М-канального аудиосигнала. Триплет каналов, состоящий из основного, коррелированного и декоррелированного каналов, обеспечивает две возможные комбинации пар из основного и коррелированного каналов и основного и декоррелированного каналов, которые могут учитываться при оптимизации сегментации и энтропийного кодирования. Технический результат – обеспечение улучшения эффективности сжатия. 11 н. и 45 з.п. ф-лы, 14 ил.
Настоящая заявка испрашивает приоритет, согласно разделу 35 Кодекса законов США 119 (e), предварительной заявки США Область техники Настоящее изобретение относится к аудиокодекам без потерь, более конкретно – к многоканальному аудиокодеку без потерь с улучшенной эффективностью сжатия. Описание предшествующего уровня техники Множество систем аудиокодирования с потерями с низкой битовой скоростью используются в настоящее время в широком диапазоне потребительских и профессиональных продуктов и услуг аудиовоспроизведения. Например, система кодирования аудиосигнала Dolby AC3 (Dolby digital) является международным стандартом для кодирования стереозвука и звуковых дорожек формата 5.1 для лазерных дисков, кодированного с помощью стандарта NTSC видео DVD (цифрового видеодиска) и ATV, с использованием битовых скоростей до 640 кбит/с. Стандарты аудиокодирования MPEG I (экспертной группы по вопросам движущихся изображений) и MPEG II широко используются для стерео и многоканального кодирования звуковых дорожек для кодированного с помощью стандарта PAL видео DVD, наземного цифрового радиовещания в Европе и спутникового радиовещания в США, на битовых скоростях до 768 кбит/с. Системы кодирования звука Coherent Acoustics DTS (Digital Theater Systems, Системы цифрового театра) часто используют для звуковых дорожек формата 5.1 со студийным качеством для компакт-диска, видео DVD, спутникового радиовещания в Европе и лазерных дисков на битовых скоростях до 1536 кбит/сек. В последнее время многие потребители проявляют заинтересованность в этих так называемых кодеках «без потерь». Кодеки «без потерь» основаны на алгоритмах, которые сжимают данные, не отказываясь ни от какой информации, и формируют декодированный сигнал, который идентичен (цифровому) исходному сигналу. Этот результат обеспечивается ценой соответствующих затрат: такие кодеки обычно требуют большей полосы пропускания, чем кодеки с потерями, и сжимают данные в меньшей степени. На фиг.1 представлена структурная схема операций, обеспечивающих сжатие без потерь одного аудиоканала. Хотя каналы в многоканальном аудиосигнале в общем случае не являются независимыми, такая зависимость часто слаба и ее трудно учитывать. Поэтому, каналы обычно сжимают отдельно. Однако некоторые кодеры пытаются устранить корреляцию путем формирования простого остаточного сигнала и кодирования (Ch1, Ch1-CH2). Более сложные подходы используют, например, несколько последовательных ортогональных отображений по размерности канала. Все методы основаны на принципе сначала удаления избыточности из сигнала, и затем кодирования результирующего сигнала с помощью схемы эффективного цифрового кодирования. Кодеки без потерь включают в себя MLP (аудио DVD), Monkey’s audio (компьютерные приложения), кодер без потерь Apple, Windows Media Pro без потерь, AudioPak, DVD, LTAC, MUSICcompress, OggSquish, Philips, Shorten, Sonarc и WA. Обзор многих из этих кодеков содержится в публикации в Mat Hans, Ronald Schafer «Lossless Compression of Digital Audio» Hewlett Packard, 1999. Разделение 10 на кадры вводится для обеспечения возможности редактирования, полный объем данных запрещает повторную декомпрессию всего сигнала, предшествующего области, подлежащей редактированию. Аудиосигнал делится на независимые кадры равной длительности. Эта длительность не должна быть слишком короткой, так как значительное количество служебной информации может быть обусловлено заголовком перед каждым кадром. С другой стороны, длительность кадра не должна быть слишком длинной, так как это может ограничить адаптивность во временной области и сделать редактирование более трудным. Во многих приложениях размер кадра ограничен пиковой битовой скоростью среды передачи аудиосигнала, возможностями буферизации декодера и желательностью независимого декодирования каждого кадра. Внутриканальная декорреляция 12 удаляет избыточность с помощью декорреляции выборок аудиосигнала в каждом канале в пределах кадра. Большинство алгоритмов удаляют избыточность путем моделирования сигнала с помощью линейного предсказания некоторого вида. При таком подходе линейный предсказатель применяется к выборкам аудиосигнала в каждом кадре, что приводит к последовательности выборок ошибок предсказания. Второй, менее традиционный, подход состоит в том, чтобы получить квантованное с низкой битовой скоростью представление сигнала или представление сигнала с потерями, и затем без потерь сжать разницу между версией с потерями и исходной версией. Энтропийное кодирование 14 удаляет избыточность из ошибки от разностного сигнала без потери информации. Типичные способы включают в себя кодирование Хаффмана, кодирование длины серий и кодирование Райса. Выходным сигналом является сжатый сигнал, который можно восстановить без потерь. Существующие спецификация DVD (цифрового видеодиска) и предварительная спецификация HD DVD (цифрового видеодиска высокой плотности) устанавливают жесткое предельное значение для размера одного блока доступа к данным, который представляет часть аудиопотока, который после извлечения может быть полностью декодирован, и восстановленные выборки аудиосигнала могут быть посланы на выходной буфер. Это означает для потока без потерь, что время, которое может представлять каждый блок доступа, должно быть достаточно малым, чтобы в наихудшем случае пиковой битовой скорости кодированная полезная нагрузка не превышала жесткое предельное значение. Временная длительность также должна быть снижена для увеличения частот дискретизации и увеличения количества каналов, что увеличивает пиковую битовую скорость. Для обеспечения совместимости эти существующие кодеры должны устанавливать длительность всего кадра достаточно короткой для того, чтобы не превышать жесткий предел в наихудшем случае конфигурации каналов /частоты дискретизации/ битовой длительности. В большинстве конфигураций это будет за пределами допустимого и может серьезно ухудшить эффективность сжатия. Кроме того, данный подход наихудшего случая не обеспечивает удовлетворительное масштабирование дополнительными каналами. СУЩНОСТЬ ИЗОБРЕТЕНИЯ Настоящее изобретение обеспечивает аудиокодек без потерь, в котором эффективность сжатия оптимизированы при условии ограничения максимального размера по каждому независимо декодируемому блоку данных. Аудиокодек без потерь сегментирует аудиоданные в пределах каждого кадра для улучшения эффективности сжатия при условии ограничения, что каждый сегмент должен полностью декодироваться и быть меньше максимального размера. Для каждого кадра кодек выбирает длительность сегмента и параметры кодирования, например, конкретный энтропийный кодер и его параметры для каждого сегмента, что минимизирует кодируемую полезную нагрузку для всего кадра при условии ограничений. Для каждого канала могут выбираться отличающиеся наборы параметров кодирования, или для всех каналов может выбираться глобальный набор параметров кодирования. Эффективность сжатия можно дополнительно увеличивать с помощью формирования M/2 каналов декоррелеции для M-канального аудиосигнала. Триплет каналов (основной, коррелированный, декоррелированный) обеспечивает две возможные комбинации пар (основной, коррелированный) и (основной, декоррелированный), которые могут приниматься во внимание при оптимизации сегментации и энтропийного кодирования для дополнительного улучшения эффективности сжатия. Пары каналов могут определяться на каждый сегмент или на каждый кадр. В примерном варианте осуществления кодер разделяет на кадры аудиоданные и затем извлекает упорядоченные пары каналов, включающие в себя основной канал и коррелированный канал, и генерирует декоррелированный канал для формирования, по меньшей мере, одного триплета – (основной, коррелированный, декоррелированный). Если количество каналов нечетно, то обрабатывается дополнительный основной канал. Адаптивное или фиксированное полиномиальное предсказание применяется к каждому каналу для формирования остаточных сигналов. Кодер определяет длительность сегмента, пары каналов ((основной, коррелированный) или (основной, декоррелированный)) для кадра и наборы параметров кодирования (выбор энтропийного кода и параметры) для каждого сегмента с помощью первого разделения кадра на максимальное количество сегментов минимальной длительности. Оптимальные параметры кодирования для текущего разделения определяются с помощью вычисления параметров для одного или более энтропийных кодеров (двоичного, Райса, Хаффмана и т.д.) и выбора кодера и параметров с наименьшей кодируемой полезной нагрузкой для каждого канала (основного, коррелированного, декоррелированного) для каждого сегмента. Для каждого триплета выбирается пара каналов (основной, коррелированный) или (основной, декоррелированный) с наименьшей кодируемой полезной информацией. Используя выбранную пару каналов, глобальный набор параметров кодирования может быть определен для каждого сегмента по всем каналам. Кодер выбирает глобальный набор или отличающиеся наборы параметров кодирования, на основе которого он имеет наименьшую полную кодируемую полезную информацию (заголовок и аудиоданные). Когда оптимальный набор параметров кодирования и пары каналов для текущего разделения определены, кодер вычисляет кодированную полезную нагрузку в каждом сегменте по всем каналам. Предполагая, что ограничения на максимальный размер сегмента удовлетворены, кодер определяет, является ли полная кодированная полезная нагрузка для всего кадра для текущего разделения меньшей текущего оптимального значения для предыдущего разделения. Если это так, то сохраняется текущий набор параметров кодирования и кодированная полезная информация, и увеличивается длительность сегмента. Этот процесс повторяется до тех пор, пока или размер сегмента нарушит ограничение максимального размера, или длительность сегмента достигнет длительности кадра. Кодер энтропийно кодирует (используя выбранный энтропийный кодер и параметры) остаточные сигналы в каждом аудиоканале выбранных пар канала и всех непарных каналов. Эти и другие признаки и преимущества изобретения будут очевидны специалистам из последующего подробного описания предпочтительных вариантов осуществления, иллюстрируемых чертежами. КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ Фиг.1 – структурная схема стандартного аудиокодера без потерь; фиг.2a и 2b – структурные схемы аудиокодера и декодера без потерь, соответственно, в соответствии с настоящим изобретением; фиг.3 – диаграмма информации заголовка, которая относится к сегментации и выбору энтропийного кода; фиг.4a и 4b – структурные схемы обработки с помощью окон анализа и обратной обработки с помощью окон анализа; фиг.5 – последовательность операций межканальной декорреляции; фиг.6a и 6b – структурные схемы анализа и обработки адаптивного предсказания и обратной обработки адаптивного предсказания; фиг.7a и 7b – последовательность операций оптимальной сегментации и выбора энтропийного кода; фиг.8a и 8b – последовательности операций выбора энтропийного кода для набора каналов; фиг.9 – структурные схемы основного плюс добавочного кодека без потерь. ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ Настоящее изобретение обеспечивает аудиокодек без потерь, в котором оптимизируется эффективность сжатия при условии ограничения максимального размера каждого независимо декодируемого блока данных. Аудиокодер масштабируется, когда количество каналов в многоканальном аудиосигнале продолжает расти. Аудиокодек без потерь Как показано на фиг.2a и 2b, основные операционные блоки подобны существующим кодерам и декодерам без потерь, за исключением сегментации и выбора энтропийного кода. Многоканальный модулированный с помощью импульсно-кодовой модуляции (ИКМ, PCM) аудиосигнал 20 подвергается обработке 22 с помощью окон анализа, которая разделяет данные на кадры постоянной длительности и удаляет избыточность путем декоррелеции выборок аудиосигнала в каждом канале в пределах кадра. Вместо энтропийного кодирования непосредственно остаточных сигналов настоящее изобретение выполняет процесс 24 оптимальной сегментации и выбора энтропийного кода, который сегментирует данные на множество сегментов и определяет длительность сегмента и параметры кодирования, например выбирает конкретный энтропийный кодер и его параметры для каждого сегмента, что минимизирует кодированную полезную нагрузку для всего кадра, при условии ограничения, что каждый сегмент должен полностью декодироваться и быть меньше максимального размера. Наборы параметров кодирования оптимизируются для каждого отдельного канала, и могут оптимизироваться для глобального набора параметров кодирования. Каждый сегмент затем энтропийно кодируется 26 согласно определенному набору параметров кодирования. Кодированная информация данных и заголовка упаковывается 28 в битовый поток 30. Как показано на фиг.3, заголовок 32 включает в себя дополнительную информацию для осуществления сегментации и выбора энтропийного кода, кроме той информации, которая обычно обеспечивается для кодека без потерь. Более конкретно, заголовок включает в себя обычную информацию 34 заголовка, такую как количество сегментов (NumSegments) и количество выборок в каждом сегменте (NumSamplesInSegm), информацию 36 заголовка набора каналов, такую как квантованные коэффициенты декорреляции (QuantChDecorrCoeff [] []), и информацию 38 заголовка сегмента, такую как количество байтов в текущем сегменте для набора каналов (ChSetByteCons), флаг глобальной оптимизации (AllChSameParamFlag) и флаги энтропийного кодера (RiceCodeFlag [], CodeParam []), которые указывают, используется ли кодирование Райса или двоичное кодирование, и параметр кодирования. Как показано на фиг.2b, для выполнения операции декодирования битовый поток 30 распаковывается 40 для извлечения информации заголовка и кодированных данных. Энтропийное декодирование 42 выполняется для каждого сегмента каждого канала согласно назначенным параметрам кодирования для восстановления без потерь остаточных сигналов. Эти сигналы затем подвергают обратной обработке 44 с помощью окон анализа, которая выполняет обратное предсказание для восстановления без потерь исходного ИКМ аудиосигнала 20. Обработка с помощью окон анализа Как показано на фиг.4a и 4b, примерный вариант осуществления обработки 22 с помощью окон анализа осуществляет выбор из адаптивного предсказания 46 или из фиксированного полиномиального предсказания 48 для декорреляции каждого канала, что является довольно обычным подходом. Как будет описано ниже со ссылкой на фиг.6, оптимальный порядок предиктора оценивается для каждого канала. Если порядок больше нуля, то применяется адаптивное предсказание. В противном случае используется более простое фиксированное полиномиальное предсказание. Аналогичным образом в декодере обратная обработка 44 с помощью окон анализа выбирается из обратного адаптивного предсказания 50 или из обратного фиксированного полиномиального предсказания 52 для восстановления ИКМ аудиосигнала из остаточных сигналов. Порядок адаптивного предсказателя и коэффициенты адаптивного предсказания индексируются и порядок фиксированного предсказателя упаковываются 53 в информацию заголовка набора каналов. Межканальная декорреляция В соответствии с настоящим изобретением эффективность сжатия можно дополнительно увеличивать, осуществляя межканальную декорреляцию 54, которая упорядочивает M входных каналов в пары каналов согласно показателю корреляции между каналами. Один из каналов определяется как «основной» канал, а другой определяется как «коррелированный» канал. Декоррелированный канал генерируется для каждой пары каналов для формирования «триплета» (основной, коррелированный, декоррелированный). Структура триплета обеспечивает две возможные комбинации пар (основной, коррелированный) и (основной, декоррелированный), которые могут учитываться при оптимизации сегментации и энтропийного кодирования для дополнительного улучшения эффективности сжатия (см. фиг.8a). Более простой, но менее эффективный подход состоит в том, чтобы заменить коррелированный канал декоррелированным каналом, если, например, его дисперсия меньше. Оба аудиосигнала, и исходный M-канальный ИКМ аудиосигнал 20, и M/2-канальный декоррелированный ИКМ аудиосигнал 56 направляются для выполнения операции адаптивного предсказания и фиксированного полиномиального предсказания, которые генерируют остаточные сигналы для каждого из каналов. Как показано на фиг.3, индексы (OrigChOrder []), которые указывают исходный порядок каналов до сортировки, выполняемой во время процесса попарной декорреляции, и флаг PWChDecorrFlag [] для каждой пары каналов, указывающей присутствие кода для квантованных коэффициентов декорреляции, сохраняются в заголовке 36 набора каналов на фиг.3. Как показано на фиг.4b, для выполнения операции декодирования обратной обработки 44 с помощью окон анализа, информация заголовка распаковывается 58 и остаточные значения проходят обратное фиксированное полиномиальное предсказание 52 или обратное адаптивное предсказание 50 в соответствии с информацией заголовка, а именно в соответствии с порядком адаптивного и фиксированного предиктора для каждого канала. M-канальный декоррелированный ИКМ аудиосигнал (M/2 каналов отбрасываются во время сегментации) проходит обратную межканальную декорреляцию 60, которая считывает индексы OrigChOrder[] и флаг PWChDecorrFlagg[] из заголовка набора каналов и без потерь восстанавливает M-канальный ИКМ аудиосигнал 20. Примерный процесс для выполнения межканальной декорреляции 54 показан на фиг.5. Для примера, ИКМ аудиосигнал обеспечивается как M=6 отдельных каналов, L, R, C, Ls, Rs и LFE, которые также непосредственно соответствуют конфигурации одного из набора каналов, сохраненой в кадре. Другими наборами каналов могут быть, например, левый от центра задний фоновый канал и правый от центра задний фоновый канал для создания фонового аудиосигнала формата 7.1. Процесс начинается с запуска цикла кадров и с запуска цикла наборов каналов (этап 70). Вычисляется оценка автокорреляции при нулевой задержке для каждого канала (этап 72) и оценка корреляции при нулевой задержке для всех возможных комбинаций пар каналов в наборе каналов (этап 74). Затем коэффициенты корреляции пар каналов CORCOEF оцениваются как оценка корреляции при нулевой задержке, деленная на результат оценки автокорреляции при нулевой задержке для составляющих пару каналов (этап 76). Коэффициенты CORCOEF сортируются от наибольшего абсолютного значения до наименьшего и сохраняются в таблице (этап 78). Начиная с верха таблицы извлекаются соответствующие индексы пар каналов, пока все пары не будут сконфигурированы (этап 80). Например, данные 6 каналов могут объединяться в пары на основе их коэффициентов CORCOEF, как (L, R), (Ls, Rs) и (C, LFE). Процесс запускает цикл пар каналов (этап 82), и выбирает «основной» канал, как канал с меньшей оценкой автокорреляции при нулевой задержке, которая указывает на более низкую энергию (этап 84). В данном примере каналы L, Ls и C формируют основные каналы. Коэффициент декорреляции для пары каналов (ChPairDecorrCoeff) вычисляется как оценка корреляции при нулевой задержке, деленная на оценку автокорреляции при нулевой задержке основного канала (этап 86). Декоррелированный канал генерируется путем умножения выборок основного канала на CHPairDecorrCoeff и вычитания этого результата из соответствующих выборок коррелированного канала (этап 88). Пары каналов и связанный с ними декоррелированный канал определяют «триплеты» (L, R, R-ChPairDecorrCoeff [1] *L), (Ls, Rs, Rs-ChPairDecorrCoeff [2] *Ls), (C, LFE, LFE-ChPairDecorrCoeff [3] *C) (этап 89). ChPairDecorrCoeff [] для каждой пары каналов (и каждого набора каналов) и индексы каналов, которые определяют конфигурацию пары, сохраняются в информации заголовка набора каналов (этап 90). Этот процесс повторяется для каждого набора каналов в кадре и затем для каждого кадра в ИКМ аудиосигнале, который подвергается обработке с помощью окон анализа (этап 92). Адаптивное предсказание Анализ адаптивного предсказания и генерация остаточного сигнала Линейное предсказание пытается удалить корреляцию между выборками аудиосигнала. Основным принципом линейного предсказания является предсказание значения выборки s(n) с использованием предыдущих выборок s(n-1), s(n-2)…, и вычитание предсказанного значения В примерном варианте осуществления аудиокодека модель пресказателя FIR описывается следующим уравнением:
где Q {} обозначает операцию квантования, M обозначает порядок предсказателя, и ak – квантованные коэффициенты предсказания. Конкретное квантование Q {} необходимо для сжатия без потерь, так как исходный сигнал восстанавливается на декодирующей стороне, используя процессорную архитектуру различной конечной точности. Определение Q {} доступно и для кодера, и для декодера, и реконструкция исходного сигнала просто получается с помощью
где предполагается, что те же самые квантованные коэффициенты предсказания ak доступны и для кодера, и для декодера. Новый набор параметров предсказателя передается в каждое окно анализа (кадр), позволяя предсказателю настраивать во времени переменную структуру аудиосигнала. Коэффициенты предсказания предназначены для минимизации среднеквадратичного остатка от предсказания. Квантование Q {} делает предсказатель нелинейным предсказателем. Однако в примерном варианте осуществления квантование выполняется с 24-битовой точностью, и разумно предположить, что результирующие нелинейные эффекты можно игнорировать во время оптимизации коэффициентов предсказателя. Игнорируя квантование Q {}, основная проблема оптимизации может быть представлена как набор линейных уравнений, связывающих задержки последовательности автокорреляции сигнала, и неизвестных коэффициентов предсказателя. Этот набор линейных уравнений может быть эффективно решен с использованием алгоритма Левинсона-Дурбина (Levinson-Durbin) (LD). Результирующие коэффициенты линейного предсказания (LPC) нужно квантовать так, чтобы их можно было эффективно передавать в кодированном потоке. К сожалению, прямое квантование LPC – не самый эффективный подход, так как малые ошибки квантования могут вызывать большие спектральные ошибки. Альтернативное представление LPC – представление коэффициента отражения (RC), которое имеет меньшую чувствительность к ошибкам квантования. Это представление можно также получить из алгоритма LD. При определении с помощью алгоритма LD гарантируется, что RC будут иметь величину 1) преобразование RC в представление коэффициента логарифмической области (LAR) посредством функции отображения
где log обозначает натуральный логарифм. 2) однородное квантование LAR. Преобразование RC -> LAR искажает масштаб амплитуды параметров так, что результат этапов 1 и 2 эквивалентен неоднородному квантованию с более мелкими шагами квантования около единицы. Как показано на фиг.6a, в примерном варианте осуществления анализа адаптивного предсказания квантованные LAR параметры используются для представления параметров адаптивного предсказателя и передаются в кодированном битовом потоке. Выборки в каждом входном канале обрабатываются независимо друг от друга, и, следовательно, описание учитывает только обработку в одиночном канале. На первом этапе должна вычисляться последовательность автокорреляции по длительности окна анализа (кадра) (этап 100). Для минимизации эффектов блокирования, которые вызваны разрывами непрерывности на границах кадра, данные сначала организуют в окна. Последовательность автокорреляции для указанного количества (равного максимальному порядку LP +1) задержек оценивается из организованного в окно блока данных. Алгоритм Левинсона-Дурбина (LD) применяется к набору оцененных задержек автокорреляции, и вычисляется набор коэффициентов отражения (RC), до максимального порядка LP (этап 102). Промежуточный результат алгоритма (LD) является набором оцененных дисперсий остаточных значений предсказания для каждого порядка линейного предсказания до максимального порядка LP. В следующем блоке, используя этот набор дисперсий остаточных значений, выбирается порядок линейного предсказателя (PrOr) (этап 104). Для выбранного порядка предсказателя набор коэффициентов отражения (RC) преобразуется в набор параметров коэффициентов логарифмической области (LAR) с использованием указанной выше функции отображения (этап 106). Ограничение RC вводится перед преобразованием, чтобы исключить деление на 0
где Tresh обозначает число, близкое к 1, но меньше 1. Параметры LAR квантуются (этап 108) согласно следующему правилу:
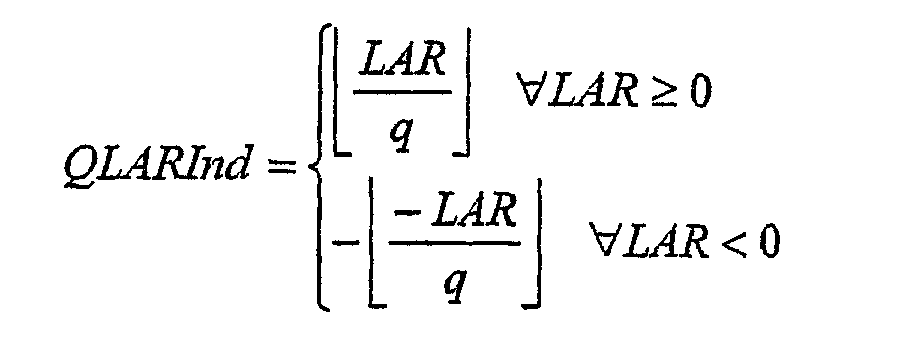
где QLARInd означает квантованные индексы LAR, x указывает операцию обнаружения наибольшего целочисленного значения, меньшего или равного x, и q обозначает размер шага квантования. В примерном варианте осуществления, область [от -8 до 8] кодируется с использованием 8 битов, т.е. q=2*8/28 и, следовательно, QLARIndis ограничивается согласно
Перед упаковокой (этап 110), QLARInd преобразуется из значений со знаком в значения без знака с использованием следующего отображения:
В блоке «RC LUT», обратное квантование параметров LAR и преобразование в параметры RC выполняются на одном этапе с использованием таблицы преобразования (этап 112). Таблица преобразования состоит из квантованных значений обратного отображения RC -> LAR, т.е. отображения LAR -> RC, заданного с помощью
Таблица преобразования вычисляется по квантованным значениям LAR, равным 0, 1,5*q, 2,5*q… 127,5*q. Соответствующие значения RC, после масштабирования на 216, округляются до 16-битных целых чисел без знака и сохраняются как числа с фиксированной точкой без знака Q16 в таблице из 128 записей. Квантованные параметры RC вычисляются из данной таблицы и индексов квантования LAR QLARInd как
Квантованные параметры RC QRCord для ord = 1… PrOr преобразуются в квантованные параметры линейного предсказания (LPord для ord = 1… PrOr) согласно следующему алгоритму (этап 114):
Так как квантованные коэффициенты RC были представлены в формате Q16 с фиксированной точкой со знаком, приведенный выше алгоритм генерирует коэффициенты LP также в формате Q16 с фиксированной точкой со знаком. Вычислительный тракт декодера без потерь разработан для поддержания до 24-битовых промежуточных результатов. Поэтому необходимо выполнять проверку насыщения после того, как вычислен каждый COrd+1,m. Если на какой-нибудь стадии алгоритма происходит насыщение, то устанавливается флаг насыщения, и порядок PrOr адаптивного предсказателя для конкретного канала устанавливается в 0 (этап 116). Для этого конкретного канала с PrOr = 0 выполняется предсказание с фиксированными коэффициентами вместо адаптивного предсказания (См. предсказание с фиксированными коэффициентами). Следует отметить, что индексы квантования LAR без знака (PackLARInd [n] для n = 1… PrOr [Ch]) упаковывают в кодированный поток только для каналов с PrOr [Ch] > 0. Наконец, для каждого канала с PrOr > 0 выполняется адаптивное линейное предсказание, и предсказанные остаточные значения e(n) вычисляются согласно следующим уравнениям (этап 118):
Так как цель – проектирование в примерном варианте осуществления состоит в том, чтобы каждый кадр был «точкой произвольного доступа», хронологию выборок не переносится между кадрами. Вместо этого предсказание используется только для выборки PrOr+1 в кадре. Остаточные значения e(n) адаптивного предсказания дополнительно энтропийно кодируются и упаковываются в кодированный битовый поток. Обратное адаптивное предсказание на декодирующей стороне На декодирующей стороне первым этапом при выполнении обратного адаптивного предсказания является распаковывание информации заголовка и извлечение порядка адаптивного предсказания PrOr [Ch] для каждого канала Ch=1,… NumCh (этап 120). Затем для каналов с PrOr [Ch] > 0 извлекается версия без знака индексов квантования LAR (PackLARInd [n] для n=1,
где >> обозначает целочисленную операцию сдвига вправо. Обратное квантование параметров LAR и преобразование в параметры RC выполняется на одном этапе с использованием Quant LUT RC (этап 122). Это та же самая таблица преобразования ТАБЛИЦА {}, которая определена на кодирующей стороне. Квантованные коэффициенты отражения для каждого канала Ch [QRC [n] для n=1… PrOr [Ch]) вычисляются из ТАБЛИЦЫ {} и индексов квантования LAR QLARInd [n], как
Для каждого канала Ch квантованные параметры RC QRCord для ord=1… PrOr [Ch] преобразуются в квантованные параметры линейного предсказания (LPord для ord=1… PrOr [Ch]) согласно следующему алгоритму (этап 124):
На кодирующей стороне удалена любая возможность насыщения промежуточных результатов. Поэтому на декодирующей стороне нет необходимости выполнять проверку на насыщение после вычисления каждого Cord+1,m. Наконец, для каждого канала с PrOr [Ch] > 0 выполняется обратное адаптивное линейное предсказание (этап 126). Предполагая, что остаточные значения e(n) предсказания предварительно извлечены и энтропийно декодированы, восстановленные исходные сигналы s(n) вычисляются согласно следующим уравнениям:
Поскольку хронология выборок не сохраняется между кадрами, обратное адаптивное предсказание следует начинать с (PrOr [Ch] +1) выборки в кадре. Предсказание с фиксированными коэффициентами Найдено, что полезна очень простая форма линейного предсказателя с фиксированными коэффициентами. Фиксированные коэффициенты предсказания получают согласно очень простому полиномиальному способу аппроксимации, описанному в работе T. Robinson. SHORTEN: Simple lossless and near lossless waveform compression. Technical report 156. Cambridge University Engineering Department Trumpington Street, Cambridge CB2 IPZ, UK December 1994. В этом случае коэффициенты предсказания определяются как соответствующие p-порядковому полиному последним p точкам данных. Разложение для четырех аппроксимаций имеет вид:
Интересным свойством этих полиномиальных аппроксимаций является то, что результирующий остаточный сигнал ek[n] = s[n] –
Анализ предсказания с фиксированными коэффициентами применяется на покадровой основе и он не зависит от выборок, вычисленных в предыдущем кадре (ek[-1] = 0). Набор остаточных значений с наименьшей величиной суммы по всему кадру определяется как лучшая аппроксимация. Оптимальный порядок остаточных значений вычисляется для каждого канала отдельно и упаковывается в поток как порядок фиксированного предсказания (FPO [Ch]). Остаточные значения eFPO[Ch][n] в текущем кадре дополнительно энтропийно кодируются и упаковываются в поток. Процесс обратного предсказания с фиксированными коэффициентами на декодирующей стороне определяется рекурсивной формулой порядка для вычисления остаточного значения k-го порядка при дискретизации n-го экземпляра
где полезный исходный сигнал s[n] определяется как
где для каждого остаточного значения k-го порядка ek[-1] = 0. В качестве примера представлены рекурсии для предсказания с фиксированными коэффициентами 3-го порядка, где остаточные значения e3[n] кодируются, передаются в потоке и распаковываются на декодирующей стороне
Сегментация и выбор энтропийного кода Примерный вариант осуществления сегментации и выбора 24 энтропийного кода показан на фиг.7 и 8. Для установки оптимальной длительностью сегмента, параметров кодирования (выбора энтропийного кода и параметров) и пар каналов, параметры кодирования и пары каналов определяются для множества различных длительностей сегментов, и из числа этих кандидатов выбирается длительность с минимальной кодированной полезной нагрузкой на кадр, которая удовлетворяет ограничениям, что каждый сегмент должен независимо декодироваться и не превышать максимальный размер. «Оптимальная» сегментация, параметры кодирования и пары каналов должны подчиняться ограничениям процесса кодирования, а также ограничениям на размер сегмента. Например, в примерном процессе временная длительность всех сегментов в кадре равна, поиск оптимальной длительности выполняется на двухэлементном модуляторе, и выбор пары каналов действителен по всему кадру. Ценой дополнительной сложности кодера и служебных битов, временная длительность может изменяться в пределах кадра, поиск оптимальной длительности может выполняться более точно, и выбор пары каналов может выполняться на основе сегмента. Примерный процесс начинается путем инициализации параметров сегмента (этап 150), таких как минимальное количество выборок в сегменте, максимальный разрешенный размер сегмента, максимальное количество сегментов и максимальное количество разделений. После этого процесс запускает цикл разделений, который индексируется от 0 до максимального количества разделений минус один (этап 152), и инициализирует параметры разделения, включающие в себя количество сегментов, цифровых выборок в сегменте и количество байтов, используемых в разделении (этап 154). В данном конкретном варианте осуществления сегменты имеют равную временную длительность, и количество сегментов масштабируется как степень двух при каждой итерации разделения. Количество сегментов предпочтительно инициализируется на максимальном значении, следовательно, на минимальной временной длительности. Однако, процесс может использовать сегменты переменной временной длительности, что может обеспечивать лучшее сжатие аудиоданных, но за счет дополнительной служебной информации. Кроме того, количество сегментов не должно ограничиваться степенью двух или находиться в диапазоне от минимальной до максимальной длительности. После инициализации, процесс запускает цикл наборов каналов (этап 156) и определяет оптимальные параметры энтропийного кодирования и выбор пары каналов для каждого сегмента и соответствующее количество используемых байтов (этап 158). Параметры кодирования PWChDecorrFlag [] [], AllChSameParamFlag [] [], RiceCodeFlag [] [] [], CodeParam [] [] [] и ChSetByteCons [] [] сохраняются (этап 160). Это повторяется для каждого набора каналов до конца цикла наборов каналов (этап 162). Процесс запускает цикл сегментов (этап 164) и вычисляет количество используемых байтов (SegmByteCons) в каждом сегменте по всем наборам каналов (этап 166) и обновляет количество используемых байтов (ByteConsInPart) (этап 168). В данной точке размер сегмента сравнивается с ограничением максимального размера (этап 170). Если ограничение нарушено, то от текущего разделения отказываются. Кроме того, из-за того, что процесс начинается с наименьшей временной длительности, когда размер сегмента слишком большой, цикл разделений заканчивается (этап 172), и лучшее решение (временная длительность, пары каналов, параметры кодирования) в этой точке упаковывается в заголовок (этап 174), и процесс переходит к следующему кадру. Если ограничение не выполняется при минимальном размере сегмента (этап 176), то процесс заканчивается и сообщает об ошибке (этап 178), потому что ограничение максимального размера не может быть выполнено. Предполагая, что ограничение выполнено, данный процесс повторяется для каждого сегмента в текущем разделении до концов цикла сегментов (этап 180). Когда закончен цикл сегментов и вычислено количество используемых байтов для всего кадра, которое представлено ByteConsinPart, эта полезная информация сравнивается с текущей минимальной полезной информацией (MinBytelnPart) из предыдущей итерации разделения (этап 182). Если текущее разделение представляет лучший результат, то текущее разделение (Partlnd) сохраняется как оптимальное разделение (OptPartind), и минимальная полезная нагрузка обновляется (этап 184). Эти параметры и сохраненные параметры кодирования затем сохраняются как текущее оптимальное решение (этап 186). Это повторяется до конца цикла разделений (этап 172), где информацию сегментации и параметры кодирования упаковываются в заголовок (этап 150), как показано на фиг.3. Примерный вариант осуществления для определения оптимальных параметров кодирования и соответствующего количества используемых битов для набора каналов для текущего разделения (этап 158) показан на фиг. 8a и 8b. Процесс начинает цикл сегментов (этап 190) и цикл каналов (этап 192), причем каналы для данного текущего примера: Ch1: L, Ch2: R Ch3: R-ChPairDecorrCoeff [1] *L Ch4: Ls Ch5: Rs Ch6: Rs – ChPairDecorrCoeff [2] *Ls Ch7: C Ch8: LFE Ch9: LFE-ChPairDecorrCoeff [3] *C) Процесс определяет тип энтропийного кода, соответствующие параметры кодирования и соответствующее количество используемых битов для основного и коррелированного каналов (этап 194). В данном примере процесс вычисляет оптимальные параметры кодирования для двоичного кода и кода Райса и затем выбирает параметры с самым низким количеством используемых битов для канала и каждого сегмента (этап 196). В общем случае оптимизация может выполняться для одного, двух или большего количества возможных энтропийных кодов. Для двоичных кодов количество битов вычисляется из максимального абсолютного значения всех выборок в сегменте текущего канала. Параметр кодирования Райса вычисляется из среднего абсолютного значения всех выборок в сегменте текущего канала. На основе данного выбора устанавливается RiceCodeFlag, устанавливается BitCons и устанавливается CodeParam или в NumBitsBinary, или в RiceKParam (этап 198). Если текущий обрабатываемый канал, который является коррелированным каналом (этап 200), то та же самая оптимизация повторяется для декоррелированного канала передачи данных (этап 202), выбирается лучший энтропийный код (этап 204) и устанавливаются параметры кодирования (этап 206). Процесс повторяется до конца цикла каналов (этап 208) и конца цикла сегментов (этап 210). К данному моменту определены оптимальные параметры кодирования для каждого сегмента и для каждого канала. Эти параметры кодирования и полезная информация могут возвращаться для пар каналов (основной, коррелированный) из исходного ИКМ аудиосигнала. Однако эффективность сжатия можно улучшать с помощью выбора между каналами (основной, коррелированный) и (основной, декоррелированный) в триплетах. Для определения пар каналов (основной, коррелированный) или (основной, декоррелированный) для этих триплетов запускается цикл пар каналов (этап 211) и вычисляется вклад каждого коррелированного канала (Ch2, Ch5 и Ch8) и каждого декоррелированного канала (Ch3, Ch6 и Ch9) в количество используемых битов всего кадра (этап 212). Вклад в количество используемых битов для кадра для каждого коррелированного канала сравнивается с вкладом в количество используемых битов для кадра для передачи декоррелированных каналов, т.е. Ch2 с Ch3, Ch5 с Ch6 и Ch8 с Ch9 (этап 214). Если вклад декоррелированного канала больше, чем коррелированного канала, то PWChDecorrrFlag устанавливают в «ложно» (этап 216). В противном случае, коррелированный канал заменяется декоррелированным каналом (этап 218), и PWChDecorrrFlag устанавливается в «истинно», и пары каналов конфигурируются как (основной, декоррелированный) (этап 220). На основе результатов сравнения алгоритм выбирает: 1. Ch2 или Ch3 как канал, который будет составлять пару с соответствующим основным каналом Ch1; 2. Ch5 или Ch6 как канал, который будет составлять пару с соответствующим основным каналом Ch4; 3. Ch8 или Ch9 как канал, который будет составлять пару с соответствующим основным каналом Ch7. Эти этапы повторяются для всех пар каналов до конца цикла (этап 222). К данному моменту определены оптимальные параметры кодирования для каждого сегмента и каждого отличающегося канала и оптимальные пары каналов. Эти параметры кодирования для каждой отличающейся пары каналов и полезная нагрузка могут возвращаться в цикл разделений. Однако дополнительная эффективность сжатия может быть доступна с помощью вычисления набора глобальных параметров кодирования для каждого сегмента по всем каналам. В лучшем случае кодированная часть данных полезной нагрузки будет иметь тот же самый размер, что и параметры кодирования, оптимизированные для каждого канала, а наиболее вероятно – несколько большей. Однако уменьшение служебной информации может более чем компенсировать эффективность кодирования данных. Используя те же самые пары каналов, процесс начинает цикл сегментов (этап 230), вычисляет количество используемых битов (ChSetByteCons[seg]) в сегменте для всех каналов, используя отличающиеся наборы параметров кодирования (этап 232), и сохраняет ChSetByteCons[seg] (этап 234). Глобальный набор параметров кодирования (выбранный энтропийный код и параметры) затем определяется для сегмента по всем каналам (этап 236) с использованием, как и прежде, вычисление двоичного кода и кода Райса, за исключением того, что он выполняется по всем каналам. Выбираются лучшие параметры и вычисляется количество используемых байтов (SegmByteCons) (этап 238). Параметр SegmByteCons сравнивается с CHSetByteCons[seg] (этап 240). Если использование общих параметров не уменьшает количество используемых битов, то AllChSamParamFlag[seg] устанавливается в «ложно» (этап 242). В противном случае AllChSameParamFlag[seg] устанавливается в «истинно» (этап 244), и глобальные параметры кодирования и соответствующее количество используемых битов сохраняются в сегменте (этап 246). Этот процесс повторяется до достижения конца цикла сегментов (этап 248). Весь процесс повторяется до окончания цикла наборов каналов (этап 250). Процесс кодирования структурируется таким образом, что различные функциональные возможности можно запрещать с помощью управления несколькими флагами. Например, один единственный флаг управляется тем, должен или нет выполняться анализ декорреляции пар каналов. Другой флаг управляет тем, должен или нет выполняться анализ адаптивного предсказания (еще один флаг для фиксированного предсказания). Кроме того, один флаг управляет тем, должен или нет выполняться поиск общих параметров по всем каналам. Сегментацией также управляют, устанавливая количество разделений и минимальную длительность сегмента (в самой простой форме, это может быть одно разделение с предопределенной длительностью сегмента). В сущности, с помощью установки нескольких флагов в кодере данный кодер может быть сведен к простому созданию кадра и энтропийному кодированию. Обратно совместимый аудиокодек без потерь Кодек без потерь может использоваться как «добавочный кодер» в комбинации с основным кодером с потерями. Основной поток кода «с потерями» упаковывается как основной битовый поток, и кодированный остаточный сигнал без потерь упаковывается как отдельный добавочный битовый поток. После декодирования в декодере с расширенными возможностями без потерь, потоки без потерь и с потерями объединяются для создания восстановленного сигнала без потерь. В декодере предшествующего поколения поток без потерь игнорируетя, а основной поток «с потерями» декодируется для обеспечения высококачественного многоканального аудиосигнала с полосой пропускания и отношением сигнал-шум, которые характерны для основного потока. Фиг.9 показывает представление на уровне системы обратно совместимого кодера 400 без потерь для одного канала многоканального сигнала. Цифровой аудиосигнал, соответственно, M-битовые выборки ИКМ аудиосигнала, обеспечивают на входе 402. Предпочтительно, цифровой аудиосигнал имеет частоту дискретизации и полосу пропускания, которые превышают полосу пропускания модифицированного основного кодера 404 с потерями. В одном из вариантов осуществления частота дискретизации цифрового аудиосигнала – 96 кГц (соответствует полосе пропускания 48 кГц для дискретизированного аудиосигнала). Также следует понимать, что входной аудиосигнал может быть, и предпочтительно является, многоканальным сигналом, в котором каждый канал дискретизирован с частотой 96 кГц. Последующее обсуждение сконцентрировано на обработке одного канала, но расширение на множество каналов не вызывает затруднений. Входные сигналы дублируются в узле 406 и обрабатываются в параллельных ветвях. В первой ветви пути сигнала, модифицированный широкополосный кодер 404 с потерями кодирует сигнал. Модифицированный основной кодер 404, который описан подробно ниже, формирует кодированный основной битовый поток 408, который передают средству упаковывания, или мультиплексору 410. Основной битовый поток 408 также передается на модифицированный основной декодер 412, который формирует выходной модифицированный восстановленный основной сигнал 414. Тем временем, оцифрованный аудиосигнал, вводимый 402 по параллельному пути, подвергается компенсирующей задержке 416, которая по существу равна задержке, введенной в восстановленный аудиопоток (с помощью модифицированного кодера и модифицированных декодеров) для создания задержанного цифрового аудиопотока. Аудиопоток 400 вычитается из задержанного цифрового аудиопотока 414 с помощью узла 420 суммирования. Узел 420 суммирования формирует разностный сигнал 422, который представляет исходный сигнал и восстановленный основной сигнал. Для реализации кодирования совсем «без потерь» необходимо кодировать и передавать разностный сигнал методом кодирования без потерь. Соответственно, разностный сигнал 422 кодируется с помощью кодера 424 без потерь, и добавочный битовый поток 426 упаковывается с основным битовым потоком 408 в средстве 410 упаковывания для формирования выходного битового потока 428. Следует отметить, что при кодировании без потерь формируется добавочный битовый поток 426, который имеет переменную скорость передачи данных с учетом требований кодера без потерь. Упакованный поток затем дополнительно подвергается кодированию других уровней, включая канальное кодирование, и затем передается или записывается. Следует отметить, что в целях данного раскрытия запись может рассматриваться как передача через канал. Основной кодер 404 описывается как «модифицированный» потому, что в варианте осуществления, который может обрабатывать расширенную полосу пропускания, основной кодер потребует модификации. 64-полосный блок 430 фильтров анализа в кодере отбрасывает половину своих выходных данных 432, и основной кодер 434 подполос кодирует только нижние 32 полосы частот. Эта отброшенная информация не представляет никакого интереса для обычных декодеров, которые в любом случае не смогут восстановить верхнюю половину спектра сигнала. Остальная информация кодируется согласно немодифицированному кодеру для формирования обратно совместимого основного выходного потока. Однако, в другом варианте осуществления, работающем с частотой дискретизации 48 кГц или ниже, основной кодер может быть по существу немодифицированной версией основного кодера согласно предшествующему уровню техники. Точно так же для описанной выше работы с частотой дискретизации обычных декодеров, модифицированный основной декодер 412 включает в себя основной декодер 436 подполос, который декодирует выборки в нижних 32 подполосах. Модифицированный основной декодер берет выборки подполос из нижних 32 подполос и обнуляет не переданные выборки подполос для верхних 32 полос 438 и восстанавливает все 64 полосы, используя 64-полосный фильтр 440 синтеза QMF. Для работы на обычной частоте дискретизации (например, 48 кГц и ниже) основной декодер может быть по существу немодифицированной версией основного декодера предшествующего уровня техники или эквивалентен ему. В некоторых вариантах осуществления частота дискретизации может выбираться во время кодирования, и модули кодирования и декодирования реконфигурируются в это время с помощью программного обеспечения, как требуется. Так как кодер без потерь используется для кодирования разностного сигнала, может показаться, что достаточно простого энтропийного кода. Однако из-за ограничений скорости передачи данных для существующих основных кодеков с потерями значительное общее количество битов, требуемое для обеспечения битового потока без потерь, все еще остается. Кроме того, из-за ограничений полосы пропускания основного кодека объем информации выше 24 кГц в разностном сигнале все еще является коррелированным. Например, большое количество гармонических составляющих, которые включают в себя трубу, гитару, треугольник Для примера, 8-канальный 24-битовый ИКМ аудиосигнал с частотой 96 кГц требуют скорости передачи данных 18,5 Мбит/с. Сжатие без потерь может уменьшить ее приблизительно до 9 Мбит/с. С помощью DTS Coherent Acoustics можно кодировать основной поток со скоростью 1,5 Мбит/с, оставляя разностный сигнал 7,5 Мбит/с. Для максимального размера сегмента, равного 2 килобайта, средняя длительность сегмента – 2048*8/7500000 = 2,18 мс или примерно 209 выборок с частотой 96 кГц. Типичный размер кадра для основного кодирования с потерями для соответствия максимальному размеру составляет от 10 до 20 мс. На уровне системы, кодек без потерь и обратно совместимый кодек без потерь могут объединяться для кодирования без потерь дополнительных аудиоканалов при расширенной полосе пропускания, поддерживая обратную совместимость с существующими кодеками с потерями. Например, 8-канальный аудиосигнал с частотой 96 кГц со скоростью 18,5 Мбит/с можно кодировать без потерь так, чтобы поток включал в себя каналы формата 5.1 с частотой 48 кГц со скоростью 1,5 Мбит/с. Основной кодер плюс кодер без потерь можно использовать для кодирования этих каналов формата 5.1. Кодер без потерь будет использоваться для кодирования разностных сигналов в этих каналах формата 5.1. Остальные 2 канала кодируют в отдельном наборе каналов, используя кодер без потерь. Поскольку все наборы каналов необходимо учитывать при попытке оптимизировать длительность сегмента, все инструментальные средства кодирования будут использоваться так или иначе. Совместимый декодер декодирует все 8 каналов и без потерь восстанавливает аудиосигнал с частотой 96 кГц со скоростью 18,5 Мбит/с. Более старый декодер декодирует только каналы формата 5.1 и восстанавливает аудиосигнал с частотой 48 кГц со скоростью 1,5 Мбит/с. В общем случае более одного набора каналов совсем без потерь можно обеспечивать для масштабирования сложности декодера. Например, для исходной смеси сигналов формата 10.2 наборы каналов можно организовывать так, чтобы: – CHSET1 переносит формат 5.1 (с внедренным понижающим микшированием от формата 10.2 к формату 5.1) и кодируется с использованием основного кодирования + кодирования без потерь – CHSET1 и CHSET2 переносят формат 7.1 (с внедренным понижающим микшированием от 10.2 к 7.1), причем CHSET2 кодирует 2 канала с использованием кодирования без потерь – CHSET1 + CHSET2 + CHSET3 переносят всю смесь дискретных сигналов формата 10.2, причем CHSET3 кодирует оставшиеся каналы формата 3.1 с использованием только кодирования без потерь. Декодер, который может декодировать только формат 5.1, декодирует только CHSET1 и игнорирует все другие наборы каналов. Декодер, который может декодировать только формат 7.1, декодирует CHSET1 и CHSET2 и игнорирует все другие наборы каналов…. Кроме того, кодирование с потерями плюс основное кодирование без потерь не ограничено форматом 5.1. Существующие воплощения поддерживают формат до 6.1, используя кодирование с потерями (основной поток + XCh) и кодирование без потерь, и могут поддерживать в общем случае m.n каналов, организованных в любом количестве наборов каналов. Кодирование с потерями будет использовать обратно совместимый основной поток формата 5.1, а все другие каналы, которые кодируются с помощью кодека с потерями, войдут в расширение XXCh. Это обеспечивает кодирование совсем без потерь со значительной гибкостью проектирования, чтобы сохранить обратную совместимость с существующими декодерами при поддержке дополнительных каналов. Хотя показаны и описаны некоторые иллюстративные варианты осуществления изобретения, специалистами могут быть предложены многочисленные разновидности и дополнительные варианты осуществления. Такие разновидности и дополнительные варианты осуществления предполагаются, и они могут быть выполнены без отклонения от сущности и объема изобретения, как определено в прилагаемой формуле изобретения.
Формула изобретения
1. Способ кодирования без потерь многоканального аудиосигнала, содержащий этапы, на которых: 2. Способ по п.1, в котором длительность сегментов определяют с помощью этапов, на которых: 3. Способ по п.2, в котором длительность сегмента первоначально устанавливают на минимальную длительность и увеличивают при каждой итерации разделения. 4. Способ по п.3, в котором длительность сегмента первоначально устанавливают как степень числа два и удваивают при каждой итерации разделения. 5. Способ по п.3, в котором если кодированная полезная нагрузка по всем каналам для любого сегмента превышает максимальный размер, то итерацию разделения прерывают. 6. Способ по п.2, в котором набор параметров кодирования включает в себя выбор энтропийного кодера и его параметров. 7. Способ по п.6, в котором энтропийный кодер и его параметры выбирают для минимизации кодированной полезной нагрузки для данного сегмента в данном канале. 8. Способ по п.2, дополнительно содержащий этапы, на которых: 9. Способ по п.2, в котором определенный набор параметров кодирования является или отличающимся для каждого канала, или глобальным для всех каналов, на основе того, который из них формирует меньшую кодированную полезную нагрузку, включающую в себя и заголовок, и аудиоданные для кадра. 10. Способ по п.1, в котором длительность сегмента определяют для минимизации кодированной полезной нагрузки каждого кадра. 11. Способ по п.1, в котором длительность сегмента определяют частично путем выбора набора параметров кодирования, включающих в себя один из множества энтропийных кодеров и его параметры кодирования для каждого сегмента. 12. Способ по п.11, в котором длительность сегмента определяют частично путем выбора отличающегося набора параметров кодирования для каждого канала или глобального набора параметров кодирования для указанного множества каналов. 13. Способ по п.11, в котором наборы параметров кодирования вычисляют для различных длительностей сегмента, и выбирают длительность, которая соответствует набору, имеющему наименьшую кодированную полезную нагрузку, которая соответствует ограничению на максимальный размер сегмента. 14. Способ по п.1, дополнительно содержащий генерацию декоррелированного канала для пар каналов для формирования, по меньшей мере, одного триплета из основного, коррелированного и декоррелированного каналов, причем длительность сегмента определяют частично путем выбора или пары каналов из основного и коррелированного каналов, или пары из основного и декоррелированного каналов для каждого указанного триплета для энтропийного кодирования. 15. Способ по п.14, в котором пары каналов выбирают путем определения, какой из декоррелированного или коррелированного каналов вносит меньше битов в кодированную полезную нагрузку. 16. Способ по п.14, в котором два наиболее коррелированных канала формируют пары, начиная с первой и далее, пока каналы не исчерпаны, если нечетный канал остается, то он формирует основной канал. 17. Способ по п.16, в котором в каждой паре канал, имеющий меньшую оценку автокорреляции при нулевой задержке, является основным каналом. 18. Способ по п.17, в котором декоррелированный канал генерируют путем умножения основного канала на коэффициент декорреляции и вычитания результата из коррелированного канала. 19. Способ кодирования без потерь данных ИКМ аудиосигнала, содержащий этапы, на которых: 20. Способ по п.19, в котором два наиболее коррелированных канала формируют пары, начиная с первой и далее, пока каналы не будут исчерпаны, если нечетный канал остается, то он формирует основной канал. 21. Способ по п.20, в котором в каждой паре канал, имеющий меньшую оценку автокорреляции при нулевой задержке, является основным каналом. 22. Способ по п.21, в котором декоррелированный канал генерируют с помощью умножения основного канала на коэффициент декорреляции и вычитания результата из коррелированного канала. 23. Способ кодирования без потерь данных ИКМ аудиосигнала, содержащий этапы, на которых: 24. Способ по п.23, в котором предопределенную длительность сегмента определяют частично путем выбора одного из множества энтропийных кодеров и его параметров кодирования. 25. Способ по п.23, в котором каждому каналу назначают набор параметров кодирования, включающий в себя выбранный энтропийный кодер и его параметры, при этом длительность сегмента определяют частично путем выбора или отличающегося набора параметров кодирования для каждого канала, или глобального набора параметров кодирования для упомянутого множества каналов. 26. Способ по п.23, в котором предопределенная длительность является одинаковой для каждого сегмента в кадре. 27. Способ по п.23, в котором предопределенная длительность определяется для каждого кадра и изменяется по последовательности кадров. 28. Многоканальный аудиокодер для кодирования цифрового аудиосигнала, дискретизированного с известной частотой дискретизации и имеющего ширину полосы аудиосигнала и разделенного на последовательность кадров, содержащий: 29. Многоканальный аудиокодер по п.28, в котором основной кодер содержит N-полосный блок фильтров анализа, который отбрасывает верхние N/2 подполос, и основной кодер подполос, который кодирует только нижние N/2 подполос, и основной декодер содержит основной декодер подполос, который декодирует кодированный основной битовый поток в выборки для нижних N/2 подполос, и N-полосный блок фильтров синтеза, который берет выборки для нижних N/2 подполос, обнуляет не переданные выборки подполос для верхних N/2 подполос и синтезирует восстановленный аудиосигнал, дискретизированный с известной частотой дискретизации. 30. Многоканальный аудиокодер по п.28, в котором кодер без потерь определяет длительность сегмента посредством: 31. Многоканальный аудиокодер по п.30, в котором кодер без потерь генерирует декоррелированный канал для пар каналов для формирования триплета из основного, коррелированного и декоррелированного каналов, выбирает или пару из основного и коррелированного каналов или пару из основного и декоррелированного каналов и выполняет энтропийное кодирование каналов в выбранных парах каналов. 32. Многоканальный аудиокодер по п.28, в котором цифровой аудиосигнал содержит множество аудиоканалов, упорядоченных, по меньшей мере, в первый и второй наборы каналов, первый набор каналов кодируется с помощью основного кодера и кодера без потерь, а второй набор кодируется только с помощью упомянутого кодера без потерь. 33. Многоканальный аудиокодер по п.32, в котором в кодере без потерь упомянутый первый набор каналов включает в себя структуру каналов формата 5.1. 34. Многоканальный аудиокодер по п.33, в котором основной кодер имеет максимальную битовую скорость для кодирования основного сигнала. 35. Многоканальный аудиокодер по п.32, в котором основной кодер извлекает и кодирует основной сигнал с частотой дискретизации, равной половине предопределенной частоты дискретизации. 36. Способ декодирования битового потока переменной битовой скорости (VBR) без потерь многоканального аудиосигнала, содержащий этапы, на которых: 37. Способ по п.36, в котором количество сегментов и выборок на сегмент изменяется от кадра к кадру для минимизации нагрузки переменной длины каждого кадра, подлежащего ограничениям. 38. Способ по п.37, в котором каждый сегмент в одном упомянутом кадре имеет одинаковое количество выборок. 39. Способ по п.38, в котором каждый упомянутый кадр включает в себя минимальное количество сегментов, которое удовлетворяет ограничениям. 40. Способ по п.36, в котором упомянутые коэффициенты декомпрессии содержат коэффициенты предсказания, причем упомянутая декомпрессия включает в себя выполнение инверсного предсказания над сжатыми аудиосигналами. 41. Способ декодирования битового потока без потерь, содержащий этапы, на которых: 42. Способ декодирования битового потока без потерь, содержащий этапы, на которых: 43. Способ по п.42, в котором флаг попарной декорреляции каналов указывает, была ли закодирована первая пара каналов, включающая в себя основной и коррелированный канал, или вторая пара каналов, включающая в себя основной и декоррелированный канал, для триплета, включающего в себя основной, коррелированный и декоррелированный каналы, при этом упомянутый способ дополнительно содержит этапы, на которых: 44. Машиночитаемый носитель, содержащий сохраненный на нем кодированный битовый поток, выполненный с возможностью декодирования с помощью способа декодирования по п.36, причем битовый поток разделен на последовательность кадров кодированных без потерь аудиоданных, при этом каждый упомянутый кадр подразделен на множество сегментов, длительность сегмента выбрана для минимизации кодированной полезной нагрузки аудиоданных в кадре, при условии ограничения, что каждый сегмент должен полностью декодироваться и иметь полезную нагрузку кодированного сегмента меньше, чем максимальное число байтов. 45. Машиночитаемый носитель по п.44, в котором каждый сегмент энтропийно кодирован, упомянутый битовый поток включает в себя информацию заголовка сегмента, включающую в себя флаг энтропийного кода, который указывает конкретный энтропийный код и параметр кодирования для этого энтропийного кода. 46. Машиночитаемый носитель по п.45, в котором информация заголовка сегмента также включает в себя флаг одинаковых параметров для всех каналов, который указывает, отличаются ли энтропийный код и параметры кодирования для каждого канала или они одинаковы для всех каналов. 47. Машиночитаемый носитель по п.45, в котором каждый сегмент аудиоданных включает в себя для каждой пары аудиоканалов или пару из основного и коррелированного каналов, или пару из основного и декоррелированного каналов, причем упомянутый битовый поток содержит информацию заголовка набора каналов, включающую в себя флаг попарной декорреляции каналов, который указывает, какая пара включена в состав, исходный порядок каналов и квантованные коэффициенты декорреляции канала для генерации коррелированного канала, если включен в состав декоррелированный канал. 48. Способ декодирования битового потока переменной битовой скорости (VBR) без потерь многоканального аудиосигнала, содержащий этапы, на которых: 49. Способ декодирования битового потока переменной битовой скорости (VBR) без потерь многоканального аудиосигнала, содержащий этапы: 50. Способ по п.49, в котором флаг попарной декорреляции каналов указывает, была ли закодирована первая пара каналов, включающая в себя основной и коррелированный канал, или вторая пара каналов, включающая в себя основной и декоррелированный канал, для триплета, включающего в себя основной, коррелированный и декоррелированный каналы, при этом упомянутый способ дополнительно содержит этапы, на которых: 51. Способ по п.50, в котором первый набор каналов включает в себя 5.1 многоканальный аудиосигнал, а второй набор каналов включает в себя, по меньшей мере, один дополнительный аудиоканал. 52. Способ по п.50, в котором множество упомянутых сегментов являются независимо декодируемыми. 53. Способ по п.52, в котором каждый упомянутый сегмент является независимо декодируемым. 54. Способ декодирования битового потока переменной битовой скорости (VBR) без потерь многоканального аудиосигнала, содержащий этапы: 55. Способ по п.54, в котором заголовки сегментов и энтропийно кодированные сжатые многоканальные аудиосигналы для всех из упомянутых наборов каналов распаковываются, и все из сжатых многоканальных аудиосигналов декодируются для реконструкции без потерь ИКМ аудиосигнала для полного многоканального аудиосигнала. 56. Способ по п.54, в котором заголовки сегментов и энтропийно кодированные сжатые многоканальные аудиосигналы для менее чем всех из упомянутых наборов каналов распаковываются, и соответствующие сжатые аудиосигналы декодируются для реконструкции без потерь ИКМ аудиосигнала для частичного многоканального аудиосигнала.
РИСУНКИ
|
||||||||||||||||||||||||||
 595
595
 (n) из исходной выборки s(n). Результирующий остаточный сигнал e(n)=s(n)+
(n) из исходной выборки s(n). Результирующий остаточный сигнал e(n)=s(n)+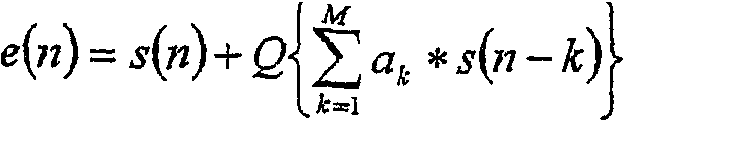
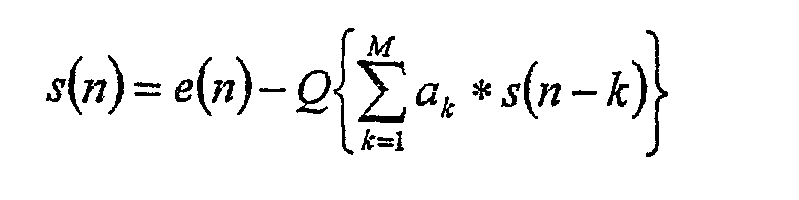
 1 (игнорируя числовые ошибки). Когда абсолютное значение RC – близко к 1, чувствительность линейного предсказания к ошибкам квантования, существующим в квантованных RC, становится высокой. Решение состоит в том, чтобы выполнять неоднородное квантование RC с более мелкими шагами квантования около единицы. Это достигается за два этапа:
1 (игнорируя числовые ошибки). Когда абсолютное значение RC – близко к 1, чувствительность линейного предсказания к ошибкам квантования, существующим в квантованных RC, становится высокой. Решение состоит в том, чтобы выполнять неоднородное квантование RC с более мелкими шагами квантования около единицы. Это достигается за два этапа: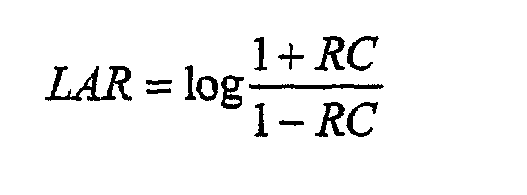
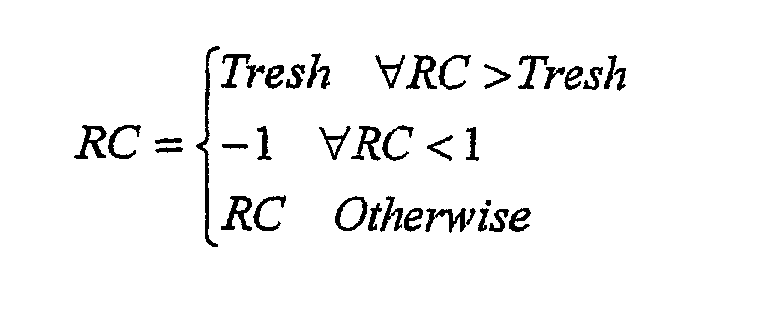

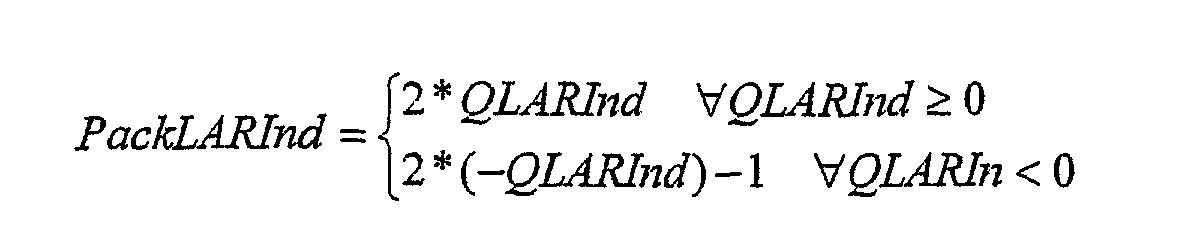
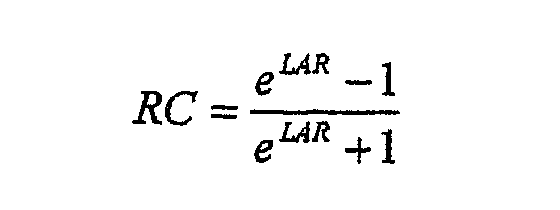
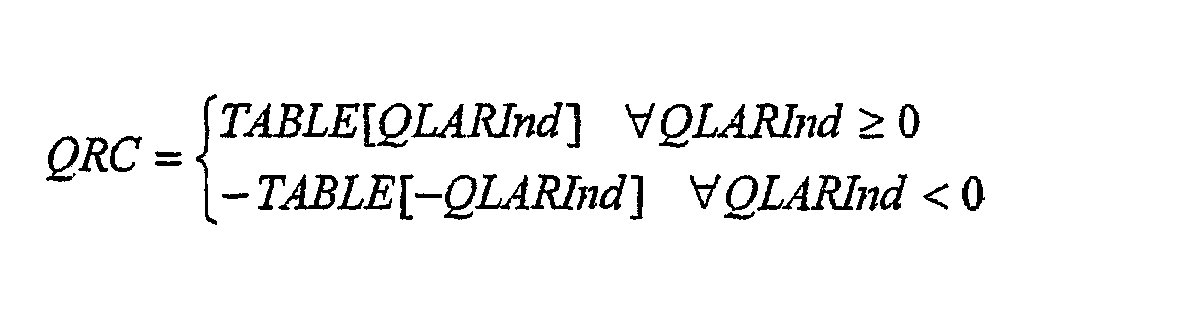
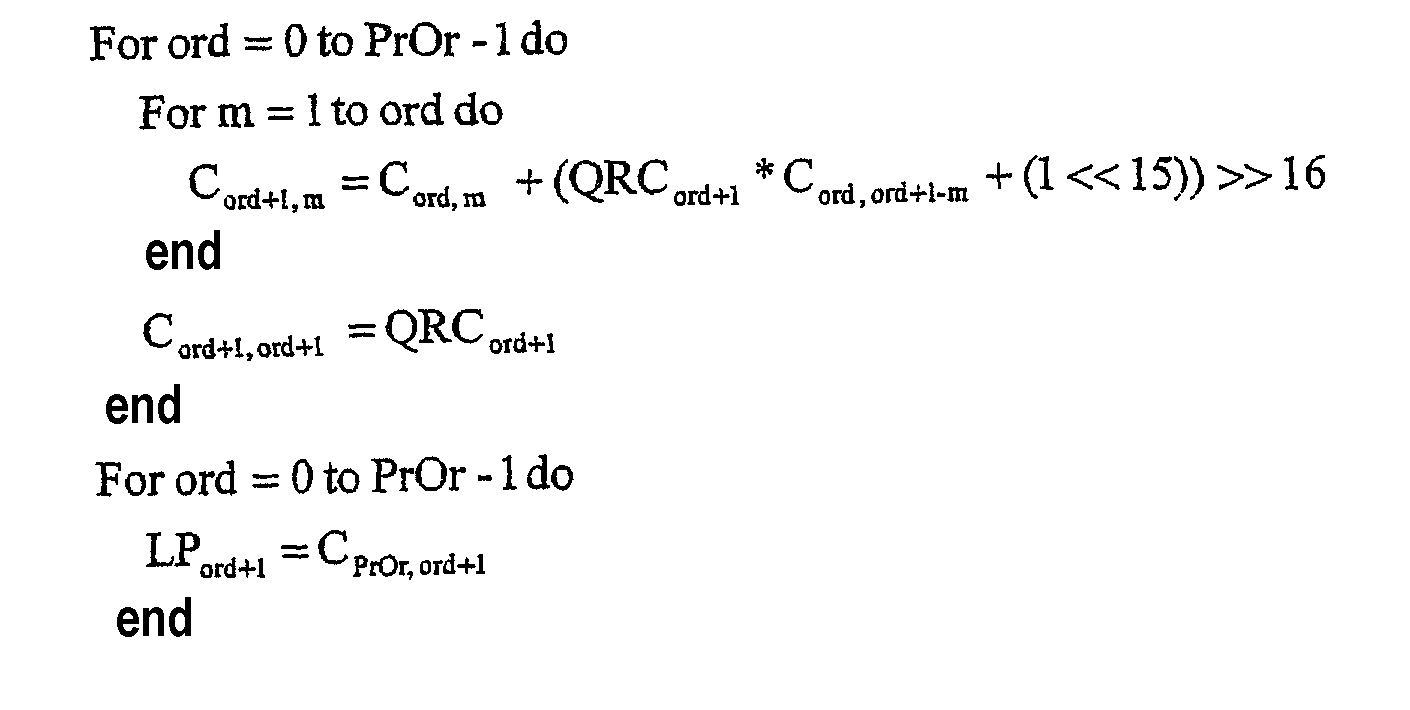
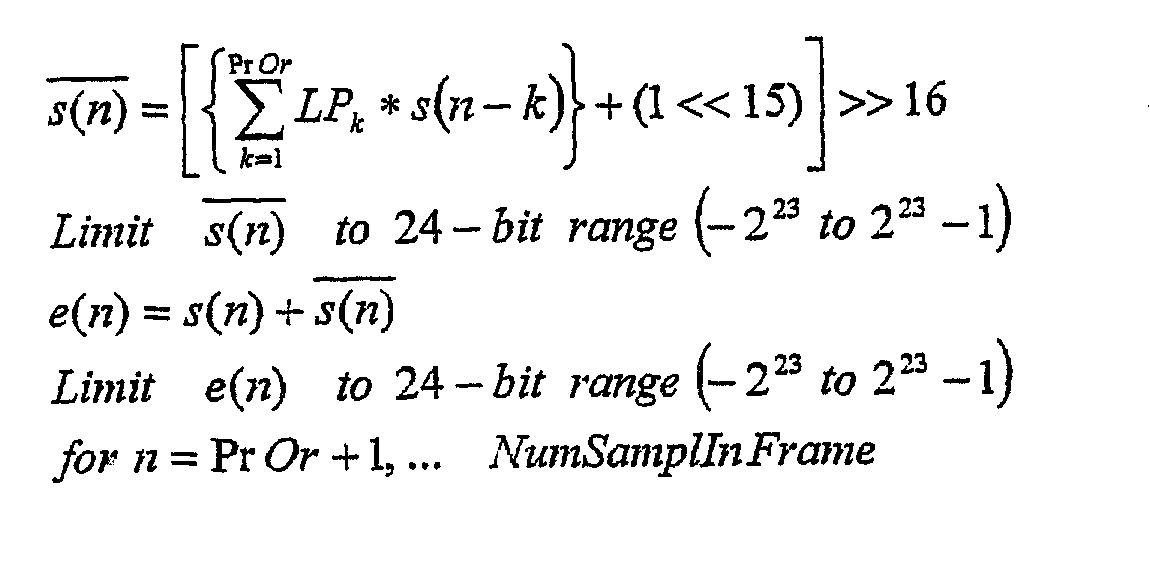
 PrOr [Ch]). Для каждого канала Ch с порядком предсказания PrOr [Ch] > 0, значение без знака PackLARInd [n] отображается на значения со знаком QLARInd [n] с использованием следующего отображения:
PrOr [Ch]). Для каждого канала Ch с порядком предсказания PrOr [Ch] > 0, значение без знака PackLARInd [n] отображается на значения со знаком QLARInd [n] с использованием следующего отображения: