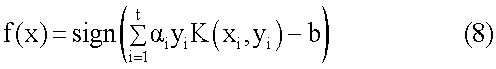Патент на изобретение №2387004
|
||||||||||||||||||||||||||
(54) СПОСОБ И СИСТЕМА ДЛЯ ВЫЧИСЛЕНИЯ ЗНАЧЕНИЯ ВАЖНОСТИ БЛОКА В ДИСПЛЕЙНОЙ СТРАНИЦЕ
(57) Реферат:
Изобретение относится к идентификации важности информационных областей дисплейной страницы для главной темы дисплейной страницы. Изобретение позволяет повысить релевантность результатов поиска поисковому запросу. Для каждого блока в обучающей Web-странице генерируют вектор признаков, который представляет этот блок. Получают от человека значение важности каждого блока для главной темы его Web-страницы. Находят функцию важности, представляющую собой отображение из вектора признаков на значение важности. Применяют найденную функцию важности к векторам признаков блоков Web-страницы для получения значения относительно важности каждого блока для главной темы Web-страницы. Затем применяют функцию важности к блокам Web-страницы результатов поиска. Устанавливают релевантность Web-страницы запросу на поиск в зависимости от значения важности ее блоков. 6 н. и 25 з.п. ф-лы, 8 ил.
Область техники Описанная технология относится в целом к идентификации блока в пределах дисплейной страницы, который представляет главную тему дисплейной страницы. Предшествующий уровень техники Многие услуги машин поиска, например от фирм Google и Overture, предусматривают поиск информации, которая доступна через Интернет. Эти услуги машины поиска позволяют пользователям искать дисплейные страницы (страницы отображения), такие как Web-страницы, которые могут быть интересными пользователям. После того как пользователь вводит запрос на поиск, который включает в себя термины поиска, служба машины поиска идентифицирует Web-страницы, которые могут быть связаны с этими терминами поиска. Чтобы быстро идентифицировать связанные Web-страницы, услуги машины поиска могут поддерживать отображение ключевых слов в Web-страницы. Это отображение может быть сгенерировано посредством “кроулинга” (автоматического выбора документов по ссылкам) в сети (то есть Всемирной паутине) для идентификации ключевых слов каждой Web-страницы. Чтобы осуществить кроулинг в сети, служба машины поиска может использовать список корневых Web-страниц для идентификации всех Web-страниц, которые доступны через эти корневые Web-страницы. Ключевые слова любой конкретной Web-страницы могут быть идентифицированы, используя различные хорошо известные способы извлечения информации, такие как идентификация слов заголовка, слов в метаданных Web-страницы, слов, которые подсвечены, и т.д. Служба машины поиска затем ранжирует Web-страницы результата поиска, на основании степени близости каждого соответствия, популярности Web-страницы (например, PageRank для Google) и т.д. Служба машины поиска может также генерировать оценку релевантности, чтобы указать, насколько релевантной информация Web-страницы может быть к запросу поиска. Служба машины поиска затем отображает пользователю ссылки на такие Web-страницы в том порядке, который основан на их ранжировании. Имеют ли Web-страницы результата поиска интерес для пользователя, зависит в значительной степени от того как хорошо ключевые слова, идентифицированные службой машины поиска представляют главную тему Web-страницы. Поскольку Web-страница может содержать много различных типов информации, может быть трудно различить первичную (главную) тему Web-страницы. Например, много Web-страниц содержит рекламные объявления, которые не являются связанными с главной темой Web-страницы. Web-страница Web-сайта новостей может содержать статью, относящуюся к международному политическому событию, и может содержать “шумовую информацию”, например рекламу популярной диеты, область, связанную с уведомлениями о законности, и навигационную область. Традиционно очень трудно для службы машины поиска идентифицировать то, какая информация на Web-странице является шумовой информацией и какая информация касается главной темы Web-страницы. В результате служба машины поиска может выбирать ключевые слова на основании шумовой информации вместо главной темы Web-страницы. Например, служба машины поиска может отображать Web-страницу, которая содержит рекламу диеты, по ключевому слову “diet” (конференция, диета), даже при том, что главная тема Web-страницы касается международного политического события. Когда пользователь затем вводит запрос на поиск, который включает в себя термин поиска “diet”, служба машины поиска может возвращать Web-страницу, которая содержит рекламу диеты, которая вряд ли будет интересна пользователю. Было бы желательно иметь способ вычисления важности различных информационных областей Web-страницы для главной темы Web-страницы. Сущность изобретения Система важности идентифицирует важность информационных областей дисплейной страницы. Система важности идентифицирует информационные области или блоки Web-страницы, которые представляют области Web-страницы, которые, как кажется, относятся к аналогичной теме. После идентификации блоков Web-страницы система важности обеспечивает характеристики или признаки блока для функции важности, которая генерирует индикацию относительно важности этого блока к его Web-странице. Система важности может изучать функцию важности, генерируя модель на основании особенностей (признаков) блоков и указанного пользователем значений важности этих блоков. Краткое описание чертежей Фиг.1 – изображает блок-схему, которая иллюстрирует компоненты системы важности в одном варианте осуществления. Фиг.2 – изображает схему последовательности операций, которая иллюстрирует обработку компонента генерирования функции важности системы важности в одном варианте осуществления. Фиг.3 – изображает схему последовательности операций, которая иллюстрирует обработку компонента вектора признаков системы важности в одном варианте осуществления. Фиг.4 – изображает схему последовательности операций, которая иллюстрирует обработку компонента вычисления важности блока в системе важности в одном варианте осуществления. Фиг.5 – изображает схему последовательности операций, которая иллюстрирует обработку компонента результата поиска по порядку, который использует изученную функцию важности в одном варианте осуществления. Фиг.6 – изображает схему последовательности операций, которая иллюстрирует обработку компонента результата расширенного поиска, который использует изученную функцию важности в одном варианте осуществления. Фиг.7 – изображает схему последовательности операций, которая иллюстрирует обработку компонента извлечения Web-страницы, который использует изученную функцию важности в одном варианте осуществления. Фиг.8 – изображает схему последовательности операций, которая иллюстрирует обработку компонента классификации Web-страницы, который использует изученную функцию важности в одном варианте осуществления. Подробное описание Обеспечиваются способ и система для идентификации важности информационных областей дисплейной страницы. В одном варианте осуществления система важности идентифицирует информационные области или блоки Web-страницы. Блок Web-страницы представляет собой область Web-страницы, которая, как кажется, относится к аналогичной теме. Например, статья новостей в Web-странице может представлять один блок, а реклама диеты Web-страницы может представлять другой блок. После идентификации блоков Web-страницы система важности подает характеристики или признаки блока к функции важности, которая генерирует индикацию (индикационную информацию) важности этого блока для его Web-страницы. Система важности “изучает” функцию важности посредством генерирования модели на основании признаков блоков и указанного пользователем значения важности таких блоков. Чтобы изучить функцию важности, система важности запрашивает пользователей обеспечить индикацию важности блоков в Web-страницах в совокупности (коллекции) Web-страниц. Например, один пользователь может идентифицировать некоторый блок как имеющий первичную важность для Web-страницы, а другой пользователь может идентифицировать тот же самый блок как имеющий вторичную важность для Web-страницы. Система важности также идентифицирует вектор признаков для каждого блока, который может представлять пространственные признаки и признаки контента (содержимого) блока. Например, пространственным признаком может быть размер блока или местоположение блока, а признаком контента может быть число ссылок в пределах блока или число слов в пределах блока. Система важности затем изучает функцию важности на основании указанной пользователем (информации о) важности и векторах признаков блоков, которая получает на входе вектор признаков блока и выдает важность (значение важности) блока. Система важности может пытаться изучать функцию, которая минимизирует квадрат разности между указанным пользователем значением важности блоков и значением важности, вычисленным функцией важности. Таким образом, система важности может идентифицировать блок Web-страницы, который может быть связан с главной (первичной) темой Web-страницы, на основании признаков блоков, которые, как полагает пользователь, являются важными. Функция важности, однажды изученная, может использоваться для улучшения точности широкого диапазона прикладных программ, чьи результаты зависят от различенных тем Web-страниц. Служба машины поиска может использовать функцию важности для вычисления релевантности Web-страниц результата поиска к запросу на поиск. После того как результат поиска получен, служба машины поиска может использовать функцию важности для идентификации наиболее важного блока каждой Web-страницы и вычисления релевантности наиболее важного блока (или группы блоков важности) к запросу на поиск. Поскольку эта релевантность основана на информации наиболее важного блока Web-страницы, это может быть более точной мерой релевантности, чем релевантность, которая основана на полной информации Web-страницы, которая может включать в себя шумовую информацию. Служба машины поиска может также использовать функцию важности для идентификации Web-страницы, которые относятся к некоторой Web-странице. Служба машины поиска может использовать функцию важности для идентификации наиболее важного блока этой Web-страницы и затем сформулировать запрос на поиск на основании текста идентифицированного блока. Служба машины поиска может выполнять поиск, используя этот сформулированный запрос на поиск для идентификации Web-страниц, которые относятся к этой некоторой Web-странице. Служба машины поиска может также использовать функцию важности, чтобы классифицировать Web-страницы. Например, Web-страницы могут быть классифицированы на основании их главной темы. Служба машины поиска может использовать функцию важности для идентификации наиболее важного блока Web-страницы и затем классифицировать Web-страницу на основании текста идентифицированного блока. Web-браузер может также использовать функцию важности для идентификации частей Web-страницы, которая должна быть отображена, когда полное содержимое Web-страницы не может уместиться на устройстве отображения. Например, устройства, такие как сотовые телефоны или персональные цифровые помощники, могут иметь очень маленькие дисплеи, на которых большинство Web-страниц не может быть приемлемым образом отображено из-за объема, размера и сложности информации Web-страницы. Web-страница приемлемым образом не отображается, когда содержимое настолько мало, что оно не может быть эффективно просмотрено человеком. Когда такое устройство используется для просмотра Web-страницы, функция важности может использоваться для идентификации наиболее важного блока Web-страницы и отображать только этот идентифицированный блок на маленьком дисплее. Альтернативно, Web-браузер может перекомпоновывать блоки Web-страницы, высвечивать блоки Web-страницы, удалять блоки Web-страницы и т.д. на основании важности блоков как указано функцией важности. Система важности может идентифицировать информационные области Web-страницы, используя различные способы сегментации, такие как алгоритм сегментации, на основании объектной модели документа (“на основании ОМД”), алгоритм сегментации, на основании расположения, алгоритм сегментации, на основании зрительного восприятия и т.д. Алгоритм сегментации на основании ОМД может использовать HTML-иерархию Web-страницы для идентификации ее различных блоков. Алгоритм сегментации, на основании расположения, пытается идентифицировать области Web-страницы, которые могут рассматриваться как единый блок, на основании физических характеристик областей. Алгоритм сегментации на основании зрительного восприятия описан в заявке на патент США 10/628766, “Vision-based Document Segmentation”, поданной 28 июля 2003, который тем самым включен по ссылке. Этот алгоритм сегментации на основании зрительного восприятия идентифицирует блоки на основании связности информационного содержимого каждого блока. Например, реклама для диеты может представлять единый блок, потому что его содержимое посвящено одной теме и таким образом имеет высокую связность. Область дисплейной страницы, которая включает в себя много различных тем, может быть разделена на много различных блоков. Система важности может использовать различные способы для изучения функции важности из векторов признаков, представляющих блоки и указанную пользователем важность блоков. Например, как более подробно описано ниже, система важности может изучать функцию важности, используя нейронную сеть или машину опорных векторов. Кроме того, система важности может использовать различные пространственные признаки и признаки содержимого блока в представлении вектора признаков этого блока. Например, пространственные признаки могут включать в себя центральное расположение блока и размеры блока, которые называют “абсолютными пространственными признаками”. Эти абсолютные пространственные признаки могут быть нормализованы на основании размера Web-страницы, которые называют “относительными пространственными признаками”, или нормализованы на основании размера окна, которые называют “пространственными признаками окна”. Признаки содержимого могут относиться к изображениям блока (например, количество и размер изображений), связям блока (например, число ссылок и число слов в каждой ссылке), тексту блока (например, количество слов в блоке), взаимодействию пользователя блока (например, количество и размер полей ввода) и форме блока (например, количество и размер). Различные признаки содержимого также могут быть нормализованы. Например, количество ссылок блока может быть нормализовано общим количеством ссылок на Web-странице, или число слов текста в блоке может быть нормализовано общим количеством слов в тексте всех блоков Web-страницы. В одном варианте осуществления система важности может позволить пользователям определять важность (значение важности) блоков, используя дискретные или непрерывные значения. Более высокие значения могут представлять большую важность блока для Web-страницы. При использовании дискретных значений 1-4 значение 1 может представляет шумовую информацию, такую как рекламу, уведомления авторского права, художественное оформление и т.д. Значение 2 может представлять полезную информацию, которая не особенно релевантна главной теме страницы, такую как навигационная информация, информация каталога и т.д. Значение 3 может представлять информацию, которая является релевантной главной теме страницы, но не имеет заметной важности, такую как связанные темы, индексы тем и т.д. Значение 4 может указывать наиболее заметную часть Web-страниц, такую как заголовок, главное содержимое и т.д. Фиг.1 представляет блок-схему, которая иллюстрирует компоненты системы важности в одном варианте осуществления. Система важности может включать в себя компоненты 101-105 и хранилища 111-114 данных. Компоненты могут включать в себя компонент 101 идентификации блоков, компонент 102 сбора указанной пользователем важности, компонент 103 генерации функции важности, компонент 104 применения функции важности и компонент 105 генерации вектора признаков. Хранилища данных могут включать в себя хранилище 111 Web-страниц, хранилище 112 блоков, хранилище 113 указанной пользователем важности и хранилище 114 функции важности. Хранилище Web-страниц может содержать коллекцию (совокупность) Web-страниц для использования при генерировании или изучении функции важности. Компонент идентификации блоков идентифицирует блоки каждой Web-страницы из хранилища Web-страниц и сохраняет идентификационную информацию каждого блока в хранилище блоков. Компонент сбора указанной пользователем важности отображает каждую Web-страницу в хранилище Web-страницы пользователю, высвечивая каждый из блоков Web-страницы, запрашивает пользователя задать важность каждого блока и сохраняет спецификации важности в хранилище указанной пользователем важности. Компонент генерации функции важности использует компонент генерации вектора признаков, чтобы сгенерировать вектор признаков для каждого блока в хранилище блоков. При генерации функции важности затем изучают функцию важности для моделирования векторов признаков блоков и заданной пользователем важности блоков. Хранилище функции важности может содержать информацию, такую как коэффициенты и параметры, определяющие изученную функцию важности, которые рассчитаны компонентом генерации функции важности. Компонент применения функции важности просматривает блок Web-страницы, вызывает компонент генерации вектора признаков для генерации вектора признаков для блока и применяет функцию важности к сгенерированному вектору признаков, чтобы сгенерировать индикацию важности блока. Вычислительное устройство, на котором может быть осуществлена система важности, может включать в себя центральный блок обработки, память, устройства ввода данных (например, клавиатуру и устройства управления позицией), устройства вывода (например, устройства отображения) и устройства хранения (например, дисковые накопители). Устройства памяти и хранения являются считываемыми компьютером средствами, которые могут содержать команды, которые реализуют систему важности. Кроме того, структуры данных и структуры сообщений могут быть сохранены или переданы через среду передачи данных, такие как сигнал в линии связи. Могут использоваться различные линии связи, такие как Интернет, локальная сеть, глобальная сеть или двухточечное соединение модемной связи. Фиг.1 иллюстрирует пример подходящей рабочей среды, в которой может быть осуществлена система важности. Рабочая среда представляет только один пример подходящей среды и не предназначена для какого-либо ограничения контекста использования или функциональных возможностей системы важности. Другие известные вычислительные системы, среды и конфигурации, которые могут быть подходящими для использования, включают в себя персональные компьютеры, компьютеры-серверы, карманные или портативные устройства, мультипроцессорные системы, основанные на микропроцессорах системы, программируемую бытовую электронику, сетевые ПК, миникомпьютеры, универсальные компьютеры, распределенные вычислительные среды, которые включают в себя любую из вышеупомянутых систем или устройств, и т.п. Система важности может быть описана в общем контексте выполняемых компьютером команд, таких как программные модули, выполняемые одним или более компьютерами или другими устройствами. Обычно программные модули включают в себя подпрограммы, программы, объекты, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют конкретные абстрактные типы данных. Как правило, функциональные возможности программных модулей могут быть объединены или распределены, как требуется в различных вариантах осуществления. В одном варианте осуществления система важности изучает функцию важности блока посредством минимизации целевой функции по методу наименьших квадратов на основании указанной пользователем важности блоков коллекции Web-страниц. Каждый блок может быть представлен вектором признаков и парой (x, y) важности, где x – вектор признаков блока, и y – его важность. Набор вектора признаков и пар важности коллекции Web-страниц называют обучающим набором T. Система важности пытается изучить функцию f важности, которая минимизирует следующую целевую функцию:
Целевая функция может быть решена, используя способы классификации, такие как машины опорных векторов, если y является дискретной, и способы регрессии, такие как нейронной сети, если y является непрерывной. Когда важность представлена непрерывными вещественными числами, система важности может применить изучение с помощью нейронной сети для изучения оптимальной f*, которая задается посредством минимизации следующей целевой функции:
где m – число блоков в обучающем наборе. Это представляет проблему многомерной непараметрической регрессии, так как не имеется никакого априорного знания относительно формы истинной функции регрессии, которая оценивается. Модель нейронной сети имеет три главных компонента: архитектура, функция стоимости и алгоритм поиска. Архитектура определяет функциональную форму, связывающую входы с выходами (в терминах топологии сети – связность блоков и функцию активации). Поиск в пространстве весов для набора весов, который минимизирует целевую функцию, является процессом обучения. В одном варианте осуществления система важности использует сеть с радиально-симметричной базисной функцией (“RBF”) и стандартный градиентный спуск в качестве методики поиска. Система важности конструирует RBF-сеть с тремя уровнями, имеющими различные роли. Входной уровень включает в себя исходные узлы (то есть воспринимающие блоки), которые соединяют сеть с ее окружением (то есть пространством признаков низкого уровня). Скрытый уровень применяет нелинейное преобразование из пространства входа к скрытому пространству. Обычно скрытое пространство имеет высокую размерность. Скрытый уровень имеет RBF-нейроны, которые вычисляют входные значения скрытого уровня посредством комбинирования взвешенных входных значений и отклонений. Выходной уровень является линейным и выдает важность блока при заданном низкоуровневом блочном представлении, подаваемом на входной уровень. Функция, изученная RBF-сетями, может быть представлена следующим образом:
где i – блок в обучающем наборе, h – число нейронов скрытого уровня,
где ci является центром для Gi и
где f= [f1, f2, RBF-нейронная сеть аппроксимирует оптимальную функцию регрессии из пространства признаков в важность блока. Система важности может автономно обучать RBF-нейронную сеть обучающими выборками {xi,yi} (i = 1,.., m) обучающего набора T. Для нового блока, ранее необработанного, система важности может вычислять ее важность, используя функцию f регрессии при заданном векторе признаков блока. Когда важность представлена дискретными числами, система важности применяет машину опорных векторов для изучения функции важности. Машина опорных векторов пытается минимизировать структурный риск вместо эмпирического риска. Машина опорных векторов может использовать двоичную классификацию, такую что обучающий набор определен следующим образом:
где D – обучающий набор, t – номер обучающих выборок, и yi Система важности пытается выбрать среди бесконечного числа линейных классификаторов, которые отделяют данные, один с минимальной ошибкой обобщения. Гиперплоскость с этим свойством является тем, что оставляет максимальный запас между двумя классами. Функция важности может быть представлена следующим образом:
где
где K – функция ядра. Некоторые типичные функции ядра включают в себя полиномиальное ядро, RBF-ядро Гаусса и сигмоидальное ядро. Для проблемы классификации по многим классам система важности может применять схему “один против всех”. Фиг.2 изображает последовательность операций, которая иллюстрирует обработку компонента генерации функции важности системы важности в одном варианте осуществления. На этапе 201 компонент извлекает коллекцию Web-страниц из хранилища Web-страниц. На этапе 202 этот компонент идентифицирует блоки в извлеченных Web-страницах и сохраняет индикации блоков в хранилище блоков. На этапе 203 компонент собирает указанные пользователем данные важности для блоков. Компонент может отображать каждую Web-страницу наряду с индикацией блоков Web-страниц и запрашивать пользователя оценить важность каждого блока для Web-страницы. Компонент сохраняет указанную пользователем важность в заданном пользователем хранилище важности. На этапе 204 компонент генерирует вектор признаков для каждого блока и может сохранять векторы признака в хранилище блоков. На этапе 205 компонент изучает функцию важности, используя нейронную сеть или методику машины опорных векторов, как описано выше. Фиг.3 изображает последовательность операций, которая иллюстрирует обработку компонента генерации вектора признаков системы важности в одном варианте осуществления. Компонент просматривает индикацию о Web-странице наряду с индикацией блока Web-страницы, чья важность должна быть вычислена. На этапе 301 компонент идентифицирует абсолютные пространственные признаки блока. На этапе 302 компонент вычисляет признаки пространственного окна блока. Компонент может вычислять признаки пространственного окна, например центр блока для y-координаты, согласно следующему выражению:
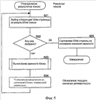
Фиг.4 изображает последовательность операций, которая иллюстрирует обработку компонента вычисления важности блока для системы важности в одном варианте осуществления. Компонент просматривает индикацию о Web-странице и вычисляет важность каждого блока Web-страницы, применяя изученную функцию важности. На этапе 401 компонент идентифицирует блоки просмотренной Web-страницы. На этапах 402-406 циклически вычисляет важность каждого блока просмотренной Web-страницы. На этапе 402 компонент выбирает следующий блок просмотренной Web-страницы. На этапе 403 принятия решения, если все блоки просмотренной Web-страницы уже были выбраны, то компонент возвращает важность каждого блока, иначе компонент продолжает работу на этапе 404. На этапе 404 компонент вызывает компонент генерации вектора признаков для генерации вектора признаков для выбранного блока. На этапе 405 компонент применяет изученную функцию важности к сгенерированному вектору признаков для вычисления важности выбранного блока. На этапе 406 компонент сохраняет вычисленную важность и затем переходит в цикле к блоку 402, чтобы выбрать следующий блок просмотренной Web-страницы. Фиг.5-8 иллюстрируют использование изученной функции важности в различных применениях. Фиг.5 изображает последовательность операций, которая иллюстрирует обработку компонента результата поиска по порядку, который использует изученную функцию важности в одном варианте осуществления. Компонент просматривает результат поиска Web-страниц и возвращает результат поиска, переупорядоченный на основании важности блока, как вычислено изученной функцией важности. На этапе 501 компонент выбирает следующую Web-страницу результата поиска. На этапе 502 принятия решения, если все Web-страницы результата поиска уже были выбраны, то компонент продолжает выполнение на этапе 505, иначе компонент продолжает работу в соответствии с этапом 503. На этапе 503 компонент вызывает компонент вычисления важности блока для вычисления важности каждого блока выбранной Web-страницы. На этапе 504 компонент устанавливает релевантность Web-страницы на основании блока с наивысшей важностью. Компонент может вычислять релевантность на основании того, как хорошо текст наиболее важного блока (или блоков) соответствует запросу на поиск, для которого был идентифицирован результат поиска. Компонент может также комбинировать эту релевантность с релевантностью каждой Web-страницы, которая была вычислена машиной поиска. Компонент затем переходит в цикле к блоку 501, чтобы выбрать следующую Web-страницу результата поиска. На этапе 505 компонент сортирует Web-страницы на основании установленной релевантности и затем возвращает переупорядоченные Web-страницы результата поиска. Фиг.6 изображает последовательность операций, которая иллюстрирует обработку компонента результата расширенного поиска, который использует изученную функцию важности в одном варианте осуществления. Компонент просматривает Web-страницу и идентифицирует Web-страницы, которые могут быть связаны с просмотренной Web-страницей. На этапе 601 компонент вызывает компонент вычисления важности блока для вычисления важности каждого блока просмотренной Web-страницы. На этапе 602 компонент выбирает блок просмотренной Web-страницы с наивысшей важностью. На этапе 603 компонент извлекает текст, связанный с выбранным блоком. На этапе 604 компонент формулирует запрос на поиск на основании извлеченного текста. На этапе 605 компонент выдает сформулированный запрос на поиск к службе машины поиска и в ответ извлекает результат поиска. Компонент затем возвращает результат поиска. Фиг.7 изображает последовательность операций, которая иллюстрирует обработку компонента Web-страницы отображения, который использует изученную функцию важности, в одном варианте осуществления. Этот компонент просматривает обнаружитель унифицированных ресурсов Web-страницы и отображает содержимое блока этой Web-страницы с наивысшей важностью в качестве содержимого самой Web-страницы. На этапе 701 компонент использует просмотренный обнаружитель унифицированных ресурсов, чтобы извлечь Web-страницу. На этапе 702 компонент вызывает функцию вычисления важности блока для вычисления важности каждого блока извлеченной Web-страницы. На этапе 703 компонент выбирает блок извлеченной Web-страницы с наивысшей важностью. На этапе 704 компонент отображает выбранный блок в качестве содержимого Web-страницы. Фиг.8 изображает последовательность операций, которая иллюстрирует обработку компонента классификации Web-страниц, который использует изученную функцию важности, в одном варианте осуществления. Компонент просматривает Web-страницу и классифицирует эту Web-страницу. На этапе 801 компонент вызывает функцию важности блока для вычисления важности каждого блока просмотренной Web-страницы. На этапе 802 компонент выбирает блок (или группу блоков) просмотренной Web-страницы с наивысшей важностью. На этапе 803 компонент извлекает текст выбранного блока с наивысшей важностью. На этапе 804 компонент генерирует классификацию на основании извлеченного текста. Классификация может также быть основана на ссылках в пределах выбранного блока. Компонент затем возвращает классификацию. Специалисту очевидно, что хотя конкретные варианты воплощения системы важности были описаны с целью иллюстрации, различные модификации могут быть сделаны без отрыва от объема и контекста изобретения. Принципы системы важности могут быть использованы для определения важности информационных областей в различных информационных источниках, отличных от Web-страниц. Эти информационные источники могут включать в себя документы, представленные с использованием HTML, XML или других языков разметки. Специалисту очевидно, что некоторые применения важности блока могут использовать функцию важности, которая “не изучена”. Например, разработчик может просто задать функцию важности, которая отражает их концепцию важности блока, и не полагаться на сбор эмпирических данных пользовательских оценок важности блока. Такая функция важности может оценивать важность блока на основании комбинации его размера и расположения. Соответственно, изобретение не ограничено ничем, кроме прилагаемой формулы изобретения.
Формула изобретения
1. Способ идентификации значения важности блоков для главной темы Web-страницы, которая содержит эти блоки, реализуемый в компьютерной системе и содержащий этапы: 2. Способ по п.1, в котором вектор признаков включает в себя пространственные признаки. 3. Способ по п.1, в котором вектор признаков включает признаки содержимого. 4. Способ по п.3, в котором признаки содержимого включают в себя признаки изображения. 5. Способ по п.3, в котором признаки содержимого включают в себя признаки ссылки. 6. Способ по п.3, в котором признаки содержимого включают в себя признаки взаимодействия. 7. Способ по п.1, в котором вектор признаков включает в себя пространственные признаки и признаки содержимого. 8. Способ по п.1, в котором изучение функции включает в себя применение анализа регрессии на основе нейронной сети. 9. Способ по п.8, в котором нейронная сеть является нейронной сетью с радиально-симметричным базисом. 10. Способ по п.1, в котором функцию находят посредством выбора функции, которая имеет тенденцию минимизировать сумму квадратов разностей значения важности, вычисленного этой функцией, и собранного значения важности. 11. Способ по п.1, в котором нахождения функции включает в себя использование алгоритма машины опорных векторов. 12. Способ установления релевантности Web-страниц запросам на поиск, реализуемый в компьютерной системе и содержащий этапы: 13. Способ по п.12, в котором установка релевантности включает в себя корректировку предварительно вычисленной релевантности. 14. Способ по п.12, включающий в себя упорядочение Web-страниц на основании установленной релевантности. 15. Способ идентификации Web-страниц, относящихся к Web-странице, реализованный в компьютерной системе и содержащий этапы: 16. Способ по п.15, в котором функция важности находится на основании указанной пользователем важности для блоков коллекции Web-страниц. 17. Способ по п.15, в котором Web-страница является частью результата поиска. 18. Способ выбора части Web-страницы для отображения на устройстве отображения, реализуемый в компьютерной системе и содержащий этапы: 19. Способ по п.18, в котором устройство отображения не может приемлемым образом размещать представление полной Web-страницы. 20. Способ по п.18, в котором устройство отображения связано с сотовым телефоном. 21. Способ по п.18, в котором устройство отображения связано с персональным цифровым помощником. 22. Способ по п.18, в котором выбранный блок является единственным блоком, отображенным на устройстве отображения. 23. Способ по п.18, в котором поднабор идентифицированных блоков отображается на основании их важности. 24. Способ классификации Web-страниц, реализованный в компьютерной системе и содержащий этапы: 25. Способ по п.24, в котором генерирование классификации дополнительно основано на множестве блоков, которые имеют высокое значение важности. 26. Считываемый компьютером носитель, содержащий команды, которые при их выполнении на компьютере определяют важность блоков Web-страницы способом по п.1. 27. Считываемый компьютером носитель по п.26, в котором функция важности находится на основании указанной пользователем важности блоков в коллекции Web-страниц. 28. Считываемый компьютером носитель по п.27, в котором функция важности находится, используя нейронную сеть. 29. Считываемый компьютером носитель по п.27, в котором функция важности находится, используя машину опорных векторов. 30. Считываемый компьютером носитель по п.26, в котором вектор признаков включает в себя пространственные признаки. 31. Считываемый компьютером носитель по п.26, в котором вектор признаков включает в себя признаки содержимого.
РИСУНКИ
|
||||||||||||||||||||||||||
 595
595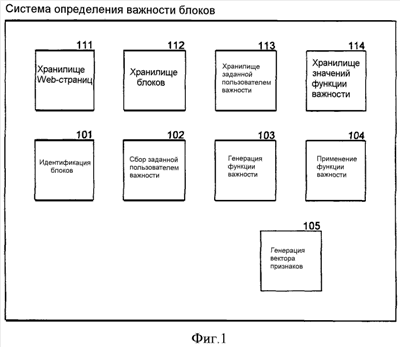
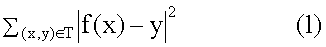
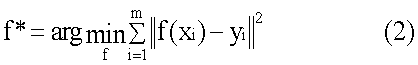
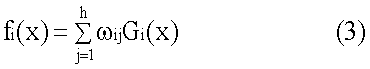
 ij
ij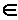 R являются весами, и Gi является радиально-симметричной функцией, определенной следующим образом:
R являются весами, и Gi является радиально-симметричной функцией, определенной следующим образом: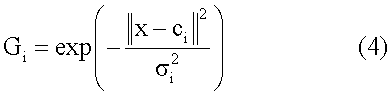
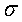 i является шириной базисной функции. K-мерное отображение может быть представлено следующим образом:
i является шириной базисной функции. K-мерное отображение может быть представлено следующим образом: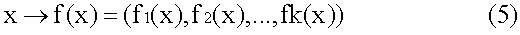
 , fk] – функция отображения.
, fk] – функция отображения.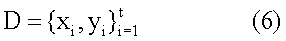
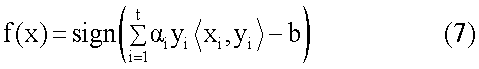
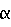 i, связанное с обучающей выборкой xi, выражает интенсивность (степень), с которой эта точка внедрена в конечную функцию, и b является пересечением, также известным как отклонение в обучении машины. Свойством этого представления является то, что часто только подмножество точек будет связано с ненулевым
i, связанное с обучающей выборкой xi, выражает интенсивность (степень), с которой эта точка внедрена в конечную функцию, и b является пересечением, также известным как отклонение в обучении машины. Свойством этого представления является то, что часто только подмножество точек будет связано с ненулевым