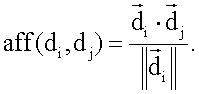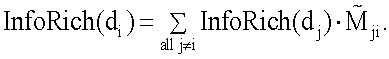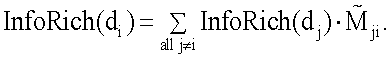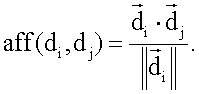Патент на изобретение №2383922
|
||||||||||||||||||||||||||
(54) СПОСОБ И СИСТЕМА ДЛЯ РАНЖИРОВАНИЯ ДОКУМЕНТОВ РЕЗУЛЬТАТА ПОИСКА ДЛЯ ПОВЫШЕНИЯ УРОВНЯ РАЗНООБРАЗИЯ И ИНФОРМАЦИОННОЙ НАСЫЩЕННОСТИ
(57) Реферат:
Изобретение относится к средствам ранжирования документов в результате поиска. Техническим результатом является повышение достоверности результатов ранжирования. Система ранжирования определяет информационную насыщенность каждого документа в результате поиска. Система ранжирования группирует документы результата поиска на основании их связанности в том смысле, что они посвящены схожим темам. Система ранжирования ранжирует документы, чтобы гарантировать, что документы наивысшего ранжирования могут включать в себя, по меньшей мере, один документ, охватывающий каждую тему, т.е. один документ из каждой группы. Система ранжирования выбирает документ из каждой группы, который имеет наивысшую информационную насыщенность среди документов в группе. Когда документы представлены пользователю в порядке ранжирования, пользователь с большой степенью вероятности находит на первой странице результата поиска документы, охватывающие различные темы, а не только одну популярную тему. 5 н. и 5 з.п. ф-лы, 5 ил.
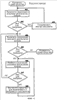
Область техники, к которой относится изобретение Описанная технология относится, в целом, к ранжированию документов результата поиска, идентифицированных запросом поиска, поданным службе поисковой машины. Предшествующий уровень техники Многие службы поисковой машины, например Google и Overture, обеспечивают поиск информации, доступной через Интернет. Эти службы поисковой машины позволяют пользователям осуществлять поиск для отображения страниц, например Web-страниц, которые могут представлять интерес для пользователей. После того как пользователь подает запрос поиска, включающий в себя критерии поиска, служба поисковой машины идентифицирует Web-страницы, которые могут относиться к этим критериям поиска. Чтобы быстро идентифицировать нужные Web-страницы, службы поисковой машины могут поддерживать отображение ключевых слов в Web-странице. Это отображение можно генерировать путем «ползания» по Web (т.е. Всемирной Паутине) для извлечения ключевых слов каждой Web-страницы. Для ползания по Web служба поисковой машины может использовать список корневых Web-страниц, чтобы идентифицировать все Web-страницы, доступные через эти корневые Web-страницы. Ключевые слова любой конкретной Web-страницы можно извлечь с использованием различных общеизвестных методов извлечения информации, например, идентифицируя слова в заголовке, слова, обеспеченные в метаданных Web-страницы, выделенные слова и т.д. Служба поисковой машины может вычислять балл релевантности, который указывает степень релевантности каждой Web-страницы запросу поиска на основании близости каждого совпадения, популярности Web-страницы (например, PageRank Google) и т.д. Затем служба поисковой машины отображает пользователю ссылки на эти Web-страницы в порядке их релевантности. Поисковые машины могут, в более общем случае, обеспечивать поиск информации в любом собрании документов. Например, собрания документов могут включать в себя все патенты США, все решения федеральных судов, все архивные документы компании и т.п. Web-страницы наивысшего ранжирования результата поиска, обеспеченные основывающейся на Web службой поисковой машины, могут все относиться к одной и той же популярной теме. Например, если пользователь подает запрос поиска с критерием поиска «Спилберг», то Web-страницы наивысшего ранжирования результата поиска, скорее всего, будут относиться к Стивену Спилбергу. Если же пользователю не нужен Стивен Спилберг, а ему нужно найти главную страницу профессора математики, который носит ту же фамилию, то ранжирование Web-страниц ничего не даст пользователю. Хотя главная страница профессора может быть включена в результат поиска, пользователю может понадобиться просмотреть несколько страниц ссылок на Web-страницы результата поиска, чтобы найти ссылку на главную страницу профессора. В общем случае, пользователям может быть трудно найти нужный документ, если он не идентифицирован на первой странице результата поиска. Кроме того, пользователи могут огорчиться, если им придется просматривать много страниц результата поиска, чтобы найти нужный документ. Желательно иметь метод ранжирования документов, который обеспечивал бы большее разнообразие тем в документах наивысшего ранжирования, и также желательно, чтобы каждый из таких документов наивысшего ранжирования был очень насыщен информационным контентом (информационно значимым содержимым), относящимся к этой теме. Сущность изобретения Система ранжирует документы результатов поиска на основании информационной насыщенности и разнообразия тем. Система ранжирования группирует документы результата поиска на основании их связанности, в том смысле, что они посвящены схожим темам. Система ранжирования ранжирует документы, чтобы гарантировать, что документы наивысшего ранжирования включают в себя, по меньшей мере, один документ, охватывающий каждую тему. Затем система ранжирования выбирает документ из каждой группы, который имеет наивысшую информационную насыщенность из документов в группе, как один из документов наивысшего ранжирования. Перечень чертежей Фиг.1 – схема, иллюстрирующая граф сродства в одном варианте осуществления. Фиг.2 – блок-схема, иллюстрирующая компоненты системы ранжирования в одном варианте осуществления. Фиг.3 – логическая блок-схема, иллюстрирующая общую работу системы ранжирования в одном варианте осуществления. Фиг.4 – логическая блок-схема, иллюстрирующая работу компонента построения графа сродства в одном варианте осуществления. Фиг.5 – логическая блок-схема, иллюстрирующая работу компонента ранжирования документов в одном варианте осуществления. Подробное описание Предусмотрены способ и система для ранжирования документов результатов поиска на основании информационной насыщенности и разнообразия тем. В одном варианте осуществления система ранжирования определяет информационную насыщенность каждого документа в результате поиска. Информационная насыщенность – это мера того, сколько документ содержит информации, относящейся к его темам. Документ (например, Web-страница) с высокой информационной насыщенностью, скорее всего, будет содержать информацию, которая поглощает информацию документов, связанных с той же темой, но имеющих более низкую информационную насыщенность. Система ранжирования группирует документы результата поиска на основании их связанности в том смысле, что они посвящены схожим темам. Система ранжирования ранжирует документы, чтобы гарантировать, что документы наивысшего ранжирования могут включать в себя, по меньшей мере, один документ, охватывающий каждую тему, т.е. документ из каждой группы. Система ранжирования выбирает документ из каждой группы, который имеет наивысшую информационную насыщенность документов в группе. Когда документы представлены пользователю в порядке ранжирования, пользователь, вероятно, найдет на первой странице результата поиска документы, которые охватывают различные темы, а не только одну популярную тему. Например, если запрос поиска включает в себя критерий поиска «Спилберг», то один документ на первой странице результата поиска может относиться к Стивену Спилбергу, а другой документ на первой странице может относиться к профессору Спилбергу. Таким образом, пользователю с большей вероятностью будут представлены документы, охватывающие разнообразные темы, на первой странице результата поиска, и он, вероятно, не будет разочарован, если интересующая его тема не является наиболее популярной темой, относящейся к запросу поиска. Кроме того, поскольку система ранжирования ранжирует документы с более высокой информационной насыщенностью выше, чем документы с более низкой информационной насыщенностью, пользователю с большей вероятностью удастся найти нужную информацию в документе, представленном на первой странице результата поиска. В одном варианте осуществления система ранжирования вычисляет информационную насыщенность документов результата поиска на основании графа сродства. Сродство – это мера того, до какой степени информация одного документа поглощена информацией другого документа. Например, документ, поверхностно описывающий один из фильмов Спилберга, может иметь высокое сродство к документу, который подробно описывает все фильмы Спилберга. Напротив, документ, подробно описывающий все фильмы Спилберга, может иметь сравнительно низкое сродство к документу, который поверхностно описывает один из фильмов Спилберга. Документы, относящиеся к очень разным темам, не будут иметь никакого сродства друг к другу. Коллекция отношений сродства каждого документа ко всем остальным документам представляет собой граф сродства. Документ, к которому имеют высокое сродство многие другие элементы, скорее всего, будет иметь высокую информационную насыщенность, поскольку его информация поглощает информацию многих других документов. Кроме того, если эти другие документы с высоким сродством сами тоже имеют сравнительно высокую информационную насыщенность, то информационная насыщенность документа еще выше. В одном варианте осуществления система ранжирования способствует обеспечению разнообразия документов высокого ранжирования результата поиска также с использованием графа сродства. Система ранжирования может иметь начальный балл ранжирования документов на основании традиционного метода ранжирования (например, релевантности), метода информационной насыщенности или некоторого другого метода ранжирования. Система ранжирования первоначально выбирает документ с наивысшим начальным баллом ранжирования в качестве документа с наивысшим окончательным баллом ранжирования. Затем система ранжирования понижает балл ранжирования каждого документа, который имеет высокое сродство к выбранному документу. Система ранжирования понижает балл ранжирования, поскольку контент этих документов, скорее всего, поглощается выбранным документом и будет представлять избыточную информацию. Затем система ранжирования выбирает тот документ из оставшихся документов, который имеет следующий наивысший балл ранжирования. Система ранжирования понижает балл ранжирования каждого документа, который имеет высокое сродство ко вновь выбранному документу. Система ранжирования повторяет этот процесс, пока нужное количество документов не будет иметь окончательный балл ранжирования, все документы не будут иметь окончательный балл ранжирования или не будет выполнено некоторое другое условие окончания. В одном варианте осуществления разнообразие представляет собой количество тем в собрании документов, и информационная насыщенность документа в собрании указывает степень информативности документа по отношению ко всему собранию. Специалисту в данной области очевидно, что документы результатов поиска можно ранжировать на основании одной только информационной насыщенности или одного только разнообразия, а не комбинации информационной насыщенности и разнообразия. Служба поисковой машины может использовать одну только информационную насыщенность, например, идентифицируя группы документов, относящихся к сходным темам, и определяя информационную насыщенность каждого документа в этой группе. Затем служба поисковой машины может факторизовать определенную информационную насыщенность в ранжирование документов, так что документы с наивысшей информационной насыщенностью своей группы, скорее всего, будут ранжированы выше, чем другие документы в своей группе. Служба поисковой машины может использовать одно только разнообразие, например, идентифицируя группы документов, относящихся к сходным темам, и гарантируя, что, по меньшей мере, один документ из каждой группы высоко ранжируется в результатах поиска независимо от его информационной насыщенности. Например, служба поисковой машины может выбрать для отображения на первой странице результата поиска документ из каждой группы с наивысшей релевантностью группы. Граф сродства представляет документы как вершины и значения сродства как весовые коэффициенты ориентированных ребер между вершинами. Система ранжирования представляет граф сродства квадратной матрицей, которая отображает каждый документ во все остальные документы в собрании документов. Система ранжирования задает значение элементов матрицы равным сродству соответствующих документов. Если M – матрица, то Mij представляет сродство документа i к документу j. Система ранжирования вычисляет сродство документов, представляя каждый документ как вектор. Вектор представляет информационное наполнение документа. Например, каждый вектор может содержать 25 наиболее важных ключевых слов документа. Система ранжирования может вычислять сродство следующим образом:
где
где Система ранжирования вычисляет информационную насыщенность для каждого документа, применяя к графу сродства алгоритм анализа ребер. Система ранжирования нормирует матрицу сродства, в результате чего значения в каждой строке становятся равными не более 1. Нормированная матрица сродства выражается следующим образом:
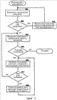
где
где
где
где c – коэффициент демпфирования и n – количество документов в собрании. Уравнение (6) можно представить в матричном виде следующим образом:
где
В каждой итерации информация может перетекать согласно одному из следующих правил. 1. С вероятностью c (т.е. равной коэффициенту демпфирования) информация будет перетекать в один из документов в 2. С вероятностью 1-c информация будет случайным образом перетекать в любые документы в собрании. Из вышеописанного процесса можно вывести цепь Маркова, где состояния заданы документами и матрица переходов (или перетока) задана как
где В одном варианте осуществления система ранжирования вычисляет ранг сродства, комбинируя информационную насыщенность со штрафом за схожесть, благодаря чему множественные документы, посвященные одной и той же теме, не ранжируются настолько высоко, чтобы исключать документы, посвященные другим темам. Использование штрафа за схожесть приводит к повышению разнообразия тем среди наиболее высоко ранжированных документов. Система ранжирования может использовать итерационный жадный алгоритм для вычисления штрафов за схожесть, когда начальный ранг сродства документа задан равным его информационной насыщенности. В каждой итерации алгоритм выбирает документ со следующим наивысшим рангом сродства и понижает ранг сродства документов, посвященных одной и той же теме, на величину штрафа за схожесть. Таким образом, после выбора документа все остальные документы, посвященные той же теме, будут иметь пониженный ранг сродства для повышения вероятности того, что документы наивысшего ранжирования представляют разнообразные темы. Система ранжирования может понижать ранг сродства документов следующим образом:
где В одном варианте осуществления система ранжирования может комбинировать ранжирование по сродству с ранжированием на текстовой основе (например, традиционную релевантность) для генерации общего ранжирования. Ранжирования можно комбинировать на основании баллов или на основании рангов. При комбинированном исчислении баллов балл на текстовой основе комбинируется с рангом сродства для обеспечения общего балла, представляющего окончательный балл документа. Комбинированное исчисление баллов может быть основано на линейной комбинации балла на текстовой основе и ранга сродства. Поскольку баллы могут отличаться по порядку величины, система ранжирования нормирует баллы. Комбинированное исчисление баллов можно представить следующим образом:
где
При комбинированном ранжировании, ранжирование на текстовой основе комбинируется с ранжированием по сродству для обеспечения окончательного ранжирования документов. Комбинированное ранжирование может быть основано на линейной комбинации ранжирования на текстовой основе и ранжирования по сродству. Комбинированное ранжирование можно представить следующим образом:
где На фиг. 1 изображена схема, иллюстрирующая граф сродства в одном варианте осуществления. Граф сродства 100 включает в себя вершины 111-115, вершины 121-124 и вершину 131, каждая из которых представляет документ. Ориентированные ребра между вершинами указывают сродство одной вершины к другой. Например, вершина 111 имеет сродство к вершине 115, но вершина 115 не имеет сродства (или имеет сродство ниже порогового уровня) к вершине 111. В этом примере, группа 110 вершин содержит вершины 111-115, которые относятся к одной и той же теме, поскольку существует много ребер между вершинами в этой группе вершин. Аналогично, группа 120 вершин содержит вершины 121-124, относящиеся к одной и той же теме. Группа 130 вершин имеет только одну вершину, поскольку эта вершина не имеет сродства ни к одной другой вершине и ни одна вершина не имеет сродства с ней. Вершина 115, вероятно, будет иметь наивысшую информационную насыщенность из всех вершин в группе 110 вершин, и вершина 124, вероятно, будет иметь наивысшую информационную насыщенность из всех вершин в группе 120 вершин, поскольку каждая вершина имеет наибольшее количество вершин, которые имеют сродство к ней. На фиг.2 изображена блок-схема, иллюстрирующая компоненты системы ранжирования в одном варианте осуществления. Система ранжирования 200 включает в себя хранилища 201-204 данных и компоненты 211-216. Хранилище 201 документов содержит собрание документов и может представлять все Web-страницы, доступные через Интернет. Компонент 211 генерации графа сродства генерирует граф сродства на основании документов хранилища документов. Компонент генерации графа сродства сохраняет отношения сродства в хранилище 202 графа сродства. Компонент 212 вычисления информационной насыщенности вводит граф сродства из хранилища графа сродства и вычисляет балл информационного богатства для каждого документа. Компонент сохраняет вычисленные баллы информационной насыщенности в хранилище 203 информационной насыщенности. В одном варианте осуществления компонент генерации графа сродства и компонент вычисления информационной насыщенности могут действовать автономно для генерации графа сродства и баллов информационной насыщенности до проведения поиска. Компонент 213 проведения поиска принимает запрос поиска от пользователя и идентифицирует результаты поиска из документов в хранилище документов. Компонент проведения поиска сохраняет результат поиска в хранилище 204 результатов поиска совместно с указанием релевантности каждого документа результата поиска запросу поиска. Компонент 214 вычисления штрафа за схожесть вычисляет штраф за схожесть для применения к рангу сродства на основании информации хранилища результатов поиска, хранилища графа сродства и хранилища информационной насыщенности. Компонент 215 вычисления ранга сродства генерирует ранг сродства для каждого документа в результате поиска. Компонент вычисления ранга сродства факторизуется в информационной насыщенности документа, хранилище графа сродства и результате поиска. Компонент 216 вычисления окончательного балла комбинирует ранг сродства и балл релевантности для вычисления окончательного балла. Вычислительное устройство, на котором реализована система ранжирования, включает в себя центральный процессор, память, устройства ввода (например, клавиатуру и указательные устройства, устройства вывода (например, устройства отображения) и устройства хранения данных (например, дисководы). Память и устройства хранения данных являются машиночитаемыми носителями, которые могут содержать команды, реализующие систему ранжирования. Кроме того, структуры данных или структуры сообщений могут храниться или передаваться через среду передачи, например сигнал на линии связи. Можно использовать различные линии связи, например Интернет, локальную сеть, глобальную сеть или двухточечное коммутируемое соединение. Система ранжирования может быть реализована в различных операционных средах. Различные общеизвестные вычислительные системы, среды и конфигурации, которые могут быть пригодны для использования, включают в себя персональные компьютеры, компьютеры-серверы, карманные или портативные устройства, многопроцессорные системы, системы на основе микропроцессора, программируемую бытовую электронику, сетевые ПК, миникомпьютеры, универсальные компьютеры, распределенные вычислительные среды, которые включают в себя любые из вышеупомянутых систем или устройств, и т.п. Система ранжирования может быть описана в общем контексте машиноисполняемых команд, например программных модулей, выполняющихся на одном или нескольких компьютерах или других устройствах. В общем случае, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.п., которые выполняют определенные задачи или реализуют определенные абстрактные типы данных. Обычно, функциональные возможности программных модулей могут объединяться или распределяться в зависимости от варианта осуществления. На фиг. 3 изображена логическая блок-схема, иллюстрирующая общую работу системы ранжирования в одном варианте осуществления. Системе ранжирования передается собрание документов, которое может представлять собой результат поиска. На этапе 301 компонент строит граф сродства для собрания документов. Компонент может строить граф сродства, охватывающий все документы в совокупности документов (например, все Web-страницы) в автономном режиме или охватывающий только документы собрания в режиме реального времени. На этапе 302 компонент вычисляет информационную насыщенность каждого документа собрания. На этапе 303 компонент ранжирует документы собрания, после чего завершает работу. На фиг.4 изображена логическая блок-схема работы компонента построения графа сродства в одном варианте осуществления. Компоненту передается собрание документов, и он строит граф сродства для этих документов. На этапе 401-403 компонент выполняет цикл, генерируя вектор документа для каждого документа в собрании документов. На этапе 401 компонент выделяет следующий документ в собрании. На этапе 402 принятия решения, если все документы в собрании уже выделены, то компонент переходит к этапу 404, иначе компонент переходит к этапу 403. На этапе 403 компонент генерирует вектор документа для выделенного документа, после чего возвращается к этапу 401 для выделения следующего документа в собрании. На этапах 404-408 компонент вычисляет сродство для каждой пары документов в собрании. На этапе 404 компонент выделяет следующий документ в собрании, начиная с первого документа. На этапе 405 принятия решения, если все документы уже выделены, то компонент возвращает граф сродства, иначе компонент переходит к этапу 406. На этапах 406-408 компонент выполняет цикл, выбирая каждый документ собрания. На этапе 406 компонент выбирает следующий документ в собрании, начиная с первого документа. На этапе 407 принятия решения, если все документы в собрании уже выбраны, то компонент возвращается к этапу 404 для выделения следующего документа в собрании, иначе компонент переходит к этапу 408. На этапе 408 компонент вычисляет сродство выделенного документа к выбранному документу согласно Уравнению (1), после чего возвращается к этапу 406 для выбора следующего документа в собрании. На фиг. 5 изображена логическая блок-схема, иллюстрирующая работу компонента ранжирования документов в одном варианте осуществления. Компоненту передается собрание документов, для которого сгенерирован граф сродства и вычислена информационная насыщенность каждого документа. На этапах 501-503 компонент выполняет цикл, инициализируя ранг сродства каждого документа в собрании его информационной насыщенностью. На этапе 501, компонент выделяет следующий документ в собрании. На этапе 502 принятия решения, если все документы уже выделены, то компонент переходит к этапу 504, иначе компонент переходит к этапу 503. На этапе 503 компонент задает ранг сродства выделенного документа равным информационной насыщенности выделенного документа, после чего возвращается к этапу 501 для выделения следующего документа в собрании. На этапах 504-508 компонент выполняет цикл, идентифицируя пары документов и регулируя ранги сродства посредством штрафа за схожесть. На этапе 504 компонент выделяет следующий документ с наивысшим рангом сродства. На этапе 505 принятия решения, если достигнуто условие окончания, то компонент возвращает ранжированные документы, иначе компонент переходит к этапу 506. На этапах 506-508 компонент выбирает документы и регулирует ранги сродства посредством штрафа за схожесть. На этапе 506 компонент выбирает следующий документ, который имеет сродство к выделенному документу, указанное ненулевым значением в графе сродства для сродства выбранного документа к выделенному документу. На этапе 507 принятия решения, если все эти документы уже выбраны, то компонент возвращается к этапу 504 для выделения следующего документа с наивысшим рангом сродства. На этапе 508 компонент регулирует ранг сродства для выбранного документа посредством штрафа за схожесть согласно Уравнению (10). Затем компонент возвращается к этапу 506 для выбора следующего документа со сродством к выделенному документу. Специалисту в данной области очевидно, что, хотя конкретные варианты осуществления системы ранжирования были описаны здесь в целях иллюстрации, допустимы различные модификации, не выходящие за рамки сущности и объема изобретения. В одном варианте осуществления, система ранжирования может вычислять сродство и информационную насыщенность на блоковой основе, а не на документной основе. Блок представляет собой информацию Web-страницы, которая, в целом, связана с одной темой. Ранжирование Web-страницы может осуществляться частично на основании важности блока для его Web-страницы. Важность блоков описана в патентной заявке США
Формула изобретения
1. Реализуемый в компьютерной системе способ упорядочения документов результата поиска, содержащий этапы, на которых получают запрос поиска, осуществляют поиск документов, которые удовлетворяют запросу поиска, обозначают в качестве результата поиска некоторые из упомянутых документов, которые удовлетворяют запросу поиска, формируют граф сродства, показывающий сродство между парами документов результата поиска, при этом сродство между парой документов указывает, до какой степени информация одного документа поглощена информацией другого документа, и определяют информационную насыщенность для каждого документа результата поиска на основании сродства, которое другие документы результата поиска имеют к данному документу, при этом информационная насыщенность документа представляет собой меру того, сколько содержит документ информации, относящейся к его теме, для каждого документа результата поиска инициализируют ранг сродства на основании информационной насыщенности этого документа, идентифицируют группы документов результата поиска, которые посвящены схожим темам, на основе анализа ребер графа сродства, для каждой из упомянутых групп, для каждого документа в группе, начиная с документа с наивысшим рангом сродства, итеративно выбирают документы, которые имеют сродство с данным документом, и понижают ранги сродства выбранных документов, причем чем больше выбранный документ схож с упомянутым документом, тем больше понижается его ранг сродства, и ранжируют документы результата поиска на основе, по меньшей мере частично, их рангов сродства. 2. Способ по п.1, в котором для каждого документа вычисляют релевантность для этого документа на основании ранга сродства этого документа и релевантности на основе поиска для данного документа. 3. Способ по п.1, в котором при понижении рангов сродства применяют штраф за схожесть. 4. Способ по п.1, в котором сродство определяют как 5. Способ по п.1, в котором информационную насыщенность определяют как 6. Машиночитаемый носитель, содержащий команды, предписывающие компьютерной системе ранжировать документы результата поиска способом, содержащим этапы, на которых получают запрос поиска, осуществляют поиск документов, которые удовлетворяют запросу поиска, обозначают в качестве результата поиска некоторые из упомянутых документов, которые удовлетворяют запросу поиска, формируют граф сродства, показывающий сродство между парами документов результата поиска, при этом сродство между парой документов указывает, до какой степени информация одного документа поглощена информацией другого документа, и определяют информационную насыщенность для каждого документа результата поиска на основании сродства, которое другие документы результата поиска имеют к данному документу, при этом информационная насыщенность документа представляет собой меру того, сколько содержит документ информации, относящейся к его теме, для каждого документа результата поиска инициализируют ранг сродства на основании информационной насыщенности этого документа, идентифицируют группы документов результата поиска, которые посвящены схожим темам, на основе анализа ребер графа сродства, для каждой из упомянутых групп, для каждого документа в группе, начиная с документа с наивысшим рангом сродства, итеративно выбирают документы, которые имеют сродство с данным документом, и понижают ранги сродства выбранных документов, причем чем больше выбранный документ схож с упомянутым документом, тем больше понижается его ранг сродства, и ранжируют документы результата поиска на основе, по меньшей мере частично, их рангов сродства. 7. Машиночитаемый носитель по п.6, в котором информационная насыщенность определена как 8. Машиночитаемый носитель по п.6, в котором сродство определено как 9. Машиночитаемый носитель по п.6, в котором для каждого документа вычисляется релевантность для этого документа на основании ранга сродства этого документа и релевантности на основе поиска для данного документа. 10. Компьютерная система для ранжирования документов результата поиска, содержащая средство для получения запроса поиска, средство для поиска документов, которые удовлетворяют запросу поиска, средство для обозначения в качестве результата поиска некоторых из упомянутых документов, которые удовлетворяют запросу поиска, средство для формирования графа сродства, показывающего сродство между парами документов результата поиска, при этом сродство между парой документов указывает, до какой степени информация одного документа поглощена информацией другого документа, и для определения информационной насыщенности для каждого документа результата поиска на основании сродства, которое другие документы результата поиска имеют к данному документу, при этом информационная насыщенность документа представляет собой меру того, сколько содержит документ информации, относящейся к его теме, средство для инициализации, для каждого документа результата поиска, ранга сродства на основании информационной насыщенности этого документа, средство для идентификации групп документов результата поиска, которые посвящены схожим темам, на основе анализа ребер графа сродства, средство для каждой из упомянутых групп, для каждого документа в группе, начиная с документа с наивысшим рангом сродства, итеративного выбора документов, которые имеют сродство с данным документом, и понижения рангов сродства выбранных документов, причем чем больше выбранный документ схож с упомянутым документом, тем больше понижается его ранг сродства, и средство для ранжирования документов результата поиска на основе, по меньшей мере частично, их рангов сродства.
РИСУНКИ
|
||||||||||||||||||||||||||
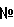 595
595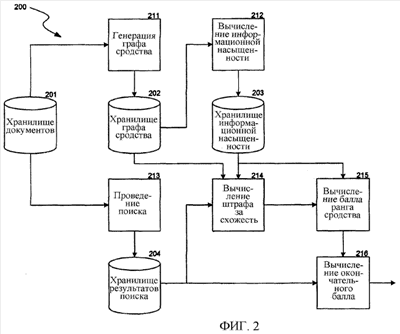
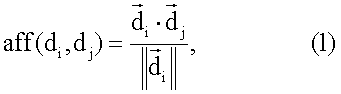
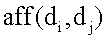 – сродство документа
– сродство документа 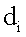 к документу
к документу 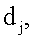
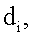
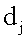 представляет вектор документа
представляет вектор документа 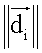 представляет длину вектора
представляет длину вектора 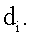 Уравнение (1) задает сродство как длину проекции
Уравнение (1) задает сродство как длину проекции 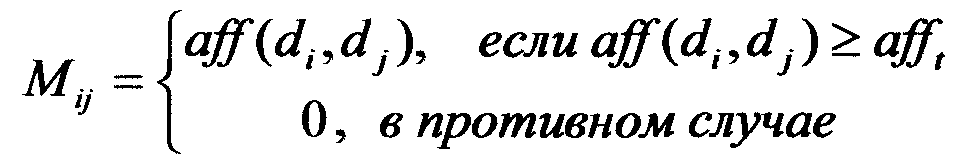
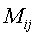 – элемент матрицы, и
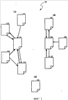
– элемент матрицы, и 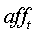 – пороговое значение сродства. Группа вершин со многими ребрами между ними может представлять одну тему, поскольку многие документы в группе имеют сродство друг к другу, превышающее пороговое сродство. Напротив, вершины без связей между ними представляют документы, посвященные разным темам.
– пороговое значение сродства. Группа вершин со многими ребрами между ними может представлять одну тему, поскольку многие документы в группе имеют сродство друг к другу, превышающее пороговое сродство. Напротив, вершины без связей между ними представляют документы, посвященные разным темам.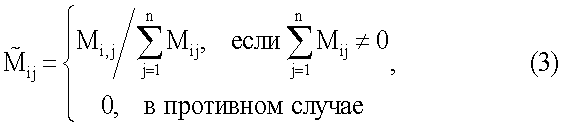
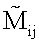 – элемент нормированной матрицы сродства. Система ранжирования вычисляет информационную насыщенность следующим образом:
– элемент нормированной матрицы сродства. Система ранжирования вычисляет информационную насыщенность следующим образом:
 – информационная насыщенность документа
– информационная насыщенность документа 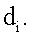 Таким образом, информационная насыщенность определяется рекурсивно. Уравнение 4 можно представить в матричном виде следующим образом:
Таким образом, информационная насыщенность определяется рекурсивно. Уравнение 4 можно представить в матричном виде следующим образом:
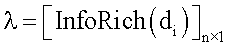 – собственный вектор нормированной матрицы сродства
– собственный вектор нормированной матрицы сродства 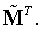 Поскольку нормированная матрица сродства
Поскольку нормированная матрица сродства 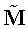 обычно является разреженной матрицей, в ней, возможно, появляются строки со всеми нулями, и это значит, что некоторые документы не имеют других документов со значительным сродством к ним. Для вычисления имеющего смысл собственного вектора система ранжирования использует коэффициент демпфирования (например, .85), который может быть ранжированием документа на основании популярности документа. Информационную насыщенность можно представить с использованием коэффициента демпфирования следующим образом:
обычно является разреженной матрицей, в ней, возможно, появляются строки со всеми нулями, и это значит, что некоторые документы не имеют других документов со значительным сродством к ним. Для вычисления имеющего смысл собственного вектора система ранжирования использует коэффициент демпфирования (например, .85), который может быть ранжированием документа на основании популярности документа. Информационную насыщенность можно представить с использованием коэффициента демпфирования следующим образом: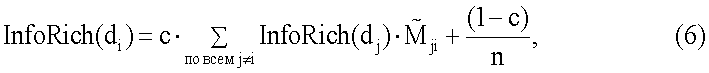
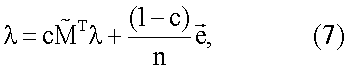
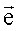 – единичный вектор, все компоненты которого равны 1. Вычисление информационной насыщенности можно представить моделью перетока и стока информации. В этой модели информация перетекает между вершинами при каждой итерации. Документ
– единичный вектор, все компоненты которого равны 1. Вычисление информационной насыщенности можно представить моделью перетока и стока информации. В этой модели информация перетекает между вершинами при каждой итерации. Документ 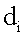 имеет множество документов
имеет множество документов 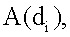 к которым он имеет сродство, что выражается следующим образом:
к которым он имеет сродство, что выражается следующим образом: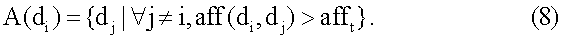
 пропорциональна
пропорциональна 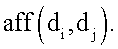
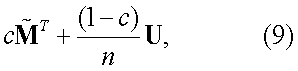
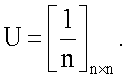 Стационарное распределение вероятности каждого состояния задается главным собственным вектором матрицы переходов.
Стационарное распределение вероятности каждого состояния задается главным собственным вектором матрицы переходов.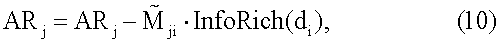
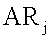 представляет ранг сродства документа j, и i – выбранный документ. Поскольку штраф за схожесть основан на матрице сродства, то чем больше документ схож с выбранным документом, тем больше штраф за схожесть.
представляет ранг сродства документа j, и i – выбранный документ. Поскольку штраф за схожесть основан на матрице сродства, то чем больше документ схож с выбранным документом, тем больше штраф за схожесть.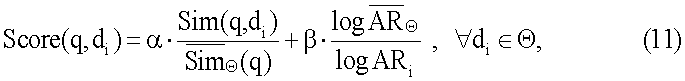
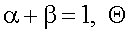 представляет результаты поиска по запросу поиска q,
представляет результаты поиска по запросу поиска q, 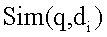 представляет схожесть документа
представляет схожесть документа 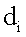 с запросом поиска q, и
с запросом поиска q, и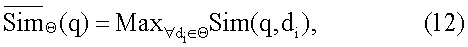
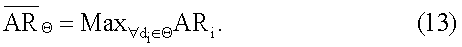
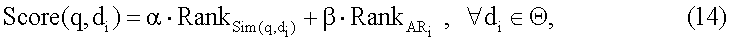
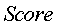 представляет окончательное ранжирование для документа
представляет окончательное ранжирование для документа 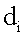 по запросу поиска q,
по запросу поиска q, 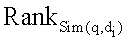 представляет ранжирование на текстовой основе, и
представляет ранжирование на текстовой основе, и 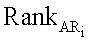 представляет ранжирование по сродству.
представляет ранжирование по сродству. 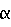 и
и  в обоих алгоритмах комбинирования являются регулируемыми параметрами. Когда
в обоих алгоритмах комбинирования являются регулируемыми параметрами. Когда