Патент на изобретение №2378692
|
||||||||||||||||||||||||||
(54) ПЕРЕЧНИ И ПРИЗНАКИ ИСТОЧНИКОВ/АДРЕСАТОВ ДЛЯ ПРЕДОТВРАЩЕНИЯ НЕЖЕЛАТЕЛЬНЫХ ПОЧТОВЫХ СООБЩЕНИЙ
(57) Реферат:
Область техники, к которой относится изобретение Настоящее изобретение в целом относится к системам и способам идентификации как законной, или допустимой (например, полезная или хорошая почта), так и нежелательной почты и более конкретно относится к обработке электронных сообщений, предназначенной для выделения (или извлечения) данных, чтобы содействовать предотвращению нежелательной рассылаемой информации, или спама. Предшествующий уровень техники Появление глобальных сетей связи, таких как Интернет, предоставило коммерческие возможности для достижения огромного количества потенциальных клиентов. Электронная передача сообщений, и конкретно электронная почта (“email”), становится все более и более распространяющейся в качестве средства для распространения пользователям сети нежелательных рекламных объявлений и продвижений продаж товаров (обозначаемых также как “спам”). По оценке компании Radicati Group. Inc., занимающейся консультированием и исследованиями возможностей рынка, на август 2002 г. два биллиона ненужных сообщений электронной почты (сообщений e-mail) посылались каждый день – это количество, как ожидается, должно утраиваться каждые два года. Отдельные личности и организации (например, предприятия, правительственные учреждения) становятся все более и более обеспокоенными и зачастую оскорбленными ненужными сообщениями. Как таковой, спам является в настоящее время или вскоре станет главной угрозой доверию (надежности) вычислительной технике. Основным способом, используемым, чтобы препятствовать спаму, является применение систем/методик фильтрации. Один испытанный способ фильтрации основан на подходе машинного обучения – фильтры, использующие машинное обучение, назначают входящему сообщению вероятность, что сообщение является спамом. В данном подходе признаки обычно выделяют из двух классов образцовых сообщений (например, сообщений спама и не спама) и применяют (само)обучающийся фильтр, чтобы различать в вероятностном смысле два класса. Поскольку многие признаки сообщения относятся к содержимому (например, слова и фразы в предмете и/или теле сообщения), то такие типы фильтров обычно называют как “фильтры на основе содержимого”. Под натиском подобных способов фильтрации спама многие пользователи сети, рассылающие спам, стали думать о способах маскировки своей идентификационной информации, чтобы избегать и/или обходить фильтры спама. Таким образом, обычные и адаптивные фильтры «на основе содержимого» могут стать неэффективными в распознавании и блокировании замаскированных сообщений спама. Краткое описание сущности изобретения Ниже представлено упрощенное краткое описание сущности изобретения для того, чтобы представить основное понимание некоторых аспектов изобретения. Данное краткое описание сущности изобретения не является исчерпывающим обзором изобретения. Оно не предназначено для идентификации ключевых/критических элементов настоящего изобретения или очерчивания объема изобретения. Его единственная цель состоит в том, чтобы представить некоторые концепции изобретения в упрощенной форме в качестве вводной части к более подробному описанию, которое представлено далее. Наиболее вероятными путями установления контакта с рассылающими спам пользователями являются вложенные ссылки или внедрение адресов электронной почты некоторого вида. Например, “щелкните здесь, чтобы узнать больше Относительно информации, извлекаемой из почтового адреса типа “from”, почтового адреса reply-to, вложенных адресов mailto:, внешних ссылок и ссылок на внешние изображения, по меньшей мере часть такой информации может быть использована для системы машинного обучения в качестве признака, с которым ассоциируют вес или вероятность; или информация может быть добавлена к перечню. Например, можно сохранять перечни IP-адресов или адресов, от которых посылают только спам, или только хорошую почту, или хорошую более чем на 90% почту и т.д.. Факт, что конкретная ссылка или адрес находятся в таком перечне, может быть использован либо в качестве признака для системы машинного обучения, либо в качестве части любой другой системы фильтрации спама, или в обоих вариантах. Кроме того, извлеченные признаки могут быть классифицированы по типу (разбиты на категории), могут быть взвешенными в соответствии со степенью бесполезности и могут быть обозначены либо как положительный (например, более вероятно, что не спам), либо отрицательный (например, более вероятно, что является спамом) признаки. Признаки могут быть использованы также, чтобы создать перечни, такие как перечни нерассылающих спам и перечни рассылающих спам пользователей, например. Для решения вышеупомянутых и связанных задач некоторые иллюстративные аспекты настоящего изобретения описаны в настоящем документе в связи с нижеследующим описанием и прилагаемыми чертежами. Эти аспекты показывают, однако, лишь несколько из различных способов, которыми принципы изобретения могут быть применены, и настоящее изобретение подразумевает включение всех таких аспектов и их эквивалентов. Другие преимущества и новые признаки изобретения могут стать очевидными из нижеследующего подробного описания изобретения при рассмотрении вместе с чертежами. Краткое описание чертежей Фиг.1 – укрупненная блок-схема системы, содействующей предотвращению спама в соответствии с аспектом настоящего изобретения. Фиг.2 – блок-схема системы, содействующей предотвращению спам посредством извлечения одного или нескольких признаков из входящих сообщений в соответствии с аспектом настоящего изобретения. Фиг.3 – схематическое представление множества признаков, которые могут быть извлечены из IP-адреса в соответствии с аспектом настоящего изобретения. Фиг.4 – схематическое представление множества признаков, которые могут быть извлечены из ПДИМ (FQDN) в соответствии с аспектом настоящего изобретения. Фиг.5 – схематическое представление множества признаков, которые могут быть извлечены из адреса электронной почты в соответствии с аспектом настоящего изобретения. Фиг.7 – схема последовательности операций примерного способа в связи с обучающимися фильтрами в соответствии с аспектом настоящего изобретения. Фиг.8 – схема последовательности операций примерного способа в связи с использованием обученного фильтра в соответствии с аспектом настоящего изобретения. Фиг.9 – схема последовательности операций примерного способа в связи с созданием перечней в соответствии с аспектом настоящего изобретения. Фиг.10 – схема последовательности операций примерного способа в связи с использованием перечней для обучения фильтров в соответствии с аспектом настоящего изобретения. Фиг.11 – схема последовательности операций способа, упомянутого в способах по меньшей мере на фиг.7 и 8 в соответствии с аспектом настоящего изобретения. Фиг.12 – схема последовательности операций способа, который содействует различению между законным и поддельным IP-адресами “received-from” в соответствии с аспектом настоящего изобретения. Фиг.13 – схема последовательности операций способа, который включает систему родительского контроля в формирование и/или извлечение признаков из входящих сообщений в соответствии с аспектом настоящего изобретения. Фиг.14 – схема последовательности операций способа, который содействует созданию наборов признаков, подлежащих использованию в системе машинного обучения в соответствии с аспектом настоящего изобретения. Фиг.15 – примерная среда для осуществления различных аспектов настоящего изобретения. Подробное описание изобретения Настоящее изобретение ниже описано со ссылкой на чертежи, на которых используют сходные ссылочные позиции, чтобы обращаться к подобным элементам по всему документу. В нижеследующем описании для целей объяснения сформулированы многочисленные конкретные подробности для того, чтобы обеспечить полное понимание настоящего изобретения. Однако очевидно, что настоящее изобретение может быть осуществлено на практике без этих конкретных подробностей. В других отдельных примерах хорошо известные структуры и устройства показаны в виде блок-схем, чтобы облегчить описание настоящего изобретения. Как использовано в данной заявке, термины “компонент” и “система” предназначены, чтобы обозначать относящийся к компьютеру элемент либо аппаратных средств, комбинации аппаратных средств и программного обеспечения, программного обеспечения, либо программного обеспечения на стадии исполнения. Например, компонент может быть, но не ограничен ими: процессом, исполняющимся на процессоре, процессором, объектом, исполняемым файлом, потоком (под-процессом) управления, программой и/или компьютером. В качестве иллюстрации, как исполняющееся на сервере приложение, так и сервер могут быть компонентами. Один или несколько компонентов могут постоянно находиться внутри процесса и/или потока управления, и компонент может находиться на одном компьютере и/или быть распределенным между двумя или несколькими компьютерами. Предмет изобретения может включать в себя различные схемы и/или способы логического вывода в связи с формированием обучающих данных для машинно-обучаемой фильтрации спам. Используемый в настоящем документе термин “логический вывод” в целом обозначает способ рассуждения о состоянии или умозаключения о состоянии системы, среды и/или пользователя, исходя из набора наблюдений, зафиксированных посредством событий и/или данных. Логический вывод может быть использован для того, чтобы идентифицировать конкретный контекст или действие, или может формировать распределение вероятностей по состояниям, например. Логический вывод может быть вероятностным, то есть вычисление распределения вероятностей по представляющим интерес состояниям, осуществляемое на основании рассмотрения данных и событий. Логический вывод может также ссылаться на способы, используемые для создания событий более высокого уровня из набора событий и/или данных. Такой логический вывод имеет результатом создание новых событий или действий из набора наблюдаемых событий и/или сохраненных данных о событиях, являются ли события или не являются коррелированными по временной близости, и поступают ли события и данные из одного или из нескольких источников событий и данных. Должен быть оценен факт, что хотя термин «сообщение» широко используют по всему описанию, этот термин не ограничен электронной почтой как таковой, но может быть соответственно приспособлен, чтобы включать в себя электронную передачу сообщений в любой форме, которую можно рассылать (распространять) по любой подходящей архитектуре связи. Например, приложения конференц-связи, которые содействуют конференции между двумя или несколькими людьми (например, программы интерактивного обмена текстовыми сообщениями (чат) и программы передачи мгновенных сообщений) также могут использовать преимущества фильтрации, раскрытые в настоящем документе, поскольку нежелательный текст может с помощью электронных средств вставлен в промежутки между нормальными сообщениями при обмене текстовыми сообщениями по мере того, как пользователи обмениваются сообщениями и/или вставлен в качестве начального сообщения, заключительного сообщения или всех из вышеуказанных. В данной конкретной заявке фильтр может быть обучен для автоматического фильтрования конкретного содержимого сообщения (текста и изображений) для того, чтобы фиксировать (собирать) и помечать как спам нежелательное содержимое (например, передачи рекламы, продвижения товаров или объявления). В объекте изобретения термин “получатель” обозначает адресата элемента входящего сообщения или почты. Термин “пользователь” может обозначать получателя или отправителя в зависимости от контекста. Например, “пользователь” может относиться к пользователю электронной почты, который посылает спам, и/или “пользователь” может относиться к получателю электронной почты, который принимает спам, в зависимости от контекста и применения термина. Адрес (IP) по протоколу Интернет является 32-битовым числом, обычно представляющим машину в сети интернет. Данные числа используют при обмене сообщениями между двумя машинами. Они обычно представлены в форме(ате) “xxx.xxx.xxx.xxx”, причем значение каждого xxx находится между 0 и 255. К сожалению, IP-адреса трудны для запоминания. Вследствие этого были созданы соглашения “имя домена” и “имя главной машины” (“имя хоста”). “Имя домена” является именем группы машин в сети интернет (возможно, одиночной машины), и обычно имеет формат “x.com”, или “y.edu”, или “courts.wa.gov”. Полное доменное имя машины (ПДИМ, FQDN) означает конкретную машину в сети интернет, например, “b.x.com” или “c.y.edu” или “www.courts.wa.gov”; доменной частью имени являются “x.com” или “y.edu” или “courts.wa.gox” соответственно. Части “b”, “c” и “www” соответственно называют частью ПДИМ, относящейся к имени хоста (главной машины). В общем случае IP-адрес может использоваться в любой ситуации, в которой может быть использовано имя домена (например, “DN/IP” указывает, что существуют обе возможности). В общем случае может использоваться также IP-адрес в любой ситуации, в которой может быть использован ПДИМ (например, “FQDN/IP”, указывает, что существуют обе возможности). Адрес электронной почты состоит из пользовательского имени и имени домена или IP-адреса (DN/IP), например, “a@x.com
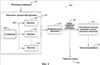
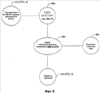
Обращаясь теперь к фиг.1, на ней проиллюстрированы основная блок-схема извлечения признаков и обучающая система 100 в соответствии с аспектом настоящего изобретения. Извлечение признаков и обучающая система 100 включают в себя обработку входящих сообщений 110 для того, чтобы извлечь данные или признаки из сообщений. Такие признаки могут быть извлечены по меньшей мере из части информации об источнике и/или адресате, поставляемой в сообщении и/или его разновидностях. В частности, одно или несколько входящих сообщений 110 могут быть приняты системой 100 посредством компонента 120 приема сообщений. Компонент 120 приема сообщений может быть размещен на сервере электронной почты или сервере сообщений, например, чтобы получать входящие сообщения 110. Хотя некоторые сообщения (например, по меньшей мере одно) могут быть уязвимы для существующего фильтра (например, фильтров спама, ненужной почты, родительского контроля) и таким образом направлены в папки для мусорной корзины или ненужной почты, по меньшей мере часть данных об источнике и/или адресата может быть извлечена и раскрыта для использования в связи с системой машинного обучения или с наполнением перечня признаков. Компонент 130 извлечения признаков может выполнять любое подходящее количество обработок, чтобы извлечь различные наборы признаков из сообщения 110 для последующего использования в системах машинного обучения. В дополнение, или в качестве альтернативы, наборы признаков могут быть использованы для наполнения перечней для других способов обучения фильтра. Имена ПДИМ, такие как a.x.com, например, могут быть преобразованы в номера (числа), обычно обозначаемые как IP-адрес. IP-адрес обычно рассматривают в формате с разделением десятичной точкой, включающим четыре блока номеров. Каждый блок отделен точкой или десятичной точкой, и каждый блок номеров может иметь значения (быть в диапазоне) от 0 до 255, причем каждое изменение номера соответствует различному имени в сети интернет. Например, a.x.com можно преобразовать в 123.124.125.126, тогда как 121.124.125.126 может представлять qrstuv.com. Поскольку номера не так легко распознаваемы или незабываемы как слова, то к IP-адресам обычно обращаются по их соответствующим именам ПДИМ. Тот же IP-адрес в точечном десятичном формате может быть выражен также в дополнительных форматах, которые будут обсуждены ниже. В соответствии с одним аспектом предмета изобретения компонент 130 извлечения признаков может сосредоточиться на IP-адрес(ах) “received-from”, включенных в сообщение 110. IP-адрес “received-from” (принято от) основан, по меньшей мере частично, на IP информации “received-from”. Обычно почту, посылаемую по Интернет, транспортируют от сервера к серверу, вовлекая одновременно только два сервера (например, отправителя и получателя). Хотя в более редких случаях клиент может осуществлять посылку непосредственно на сервер. В некоторых случаях может быть вовлечено значительно большее количество серверов, поскольку почту или сообщения посылают от одного сервера на другой вследствие присутствия, например, межсетевых защит, или брандмауэров. В частности, некоторые серверы могут быть размещены во внутренней части брандмауэра и таким образом могут взаимодействовать только с назначенными серверами на другой стороне брандмауэра. Это вызывает увеличение количества пересылок (или “прыжков”), которые сообщение делает, чтобы добраться от отправителя к получателю. Строки, содержащие IP-адреса “received-from”, облегчают отслеживание маршрута сообщения для того, чтобы установить, откуда сообщение прибыло. По мере перемещения сообщения 110 от сервера к серверу каждый сервер, с которым осуществляют контакт, добавляет к началу идентификационную информацию IP-адреса, от которого принято сообщение, к полю “received-from” (то есть к полю “Received:” (принято)) этого сообщения, а также имя предполагаемого ПДИМ (для) сервера, с которым (он) общается. Данное имя ПДИМ принимающему серверу сообщает сервер-отправитель посредством команды HELO протокола SMTP и таким образом оно не может быть доверительным (надежным), если сервер-отправитель находится вне предприятия. Например, сообщение может иметь пять строк “received from” с 5 IP-адресами и добавленными к началу именами ПДИМ, таким образом указывая, что оно прошло через шесть различных серверов (то есть пересылалось 5 раз), со строками в порядке, обратном тому, в котором они были добавлены к началу (то есть самая последняя является первой). Однако каждый сервер имеет возможность изменить любые нижележащие (добавленные к началу ранее) строки. Это может быть, в частности, трудным особенно тогда, когда сообщение перемещалось между множеством серверов. Поскольку каждый промежуточный сервер способен к изменению любых записанных ранее (ниже) строк “received-from”, то рассылающие спам пользователи могут добавить к началу ложные IP-адреса к строкам “received-from” сообщения, чтобы маскировать IP-информацию “received-from” или отправителя сообщения-спама. Например, сообщение спам может первоначально появляться, как будто оно было послано от доверительного domain.com, таким образом искажая для получателя истинный источник сообщения. Для программного обеспечения спама важно легко идентифицировать IP-адрес, внешний для предприятия, с которого посылают серверу внутри предприятия. Поскольку этот IP-адрес записан сервером-получателем, внутренним для предприятия, то ему можно доверять как корректному IP-адресу. Все другие IP-адреса вне предприятия не могут быть доверительными, так как они были записаны серверами, находящимися вне предприятия, и таким образом возможно изменены. Может быть много IP-адресов серверов-отправителей, включенных в маршрут к предприятию получателя, но поскольку только один может быть доверительным, то обозначим этот единственный заслуживающий доверия как IP-адрес “отправителя”. Один способ найти IP-адрес такого отправителя для программного обеспечения, предназначенного для фильтрации спама, состоит в том, чтобы узнать конфигурации серверов электронной почты на предприятии. В общем, если известно, какие машины передают к каким другим машинам в каких ситуациях, то можно определить IP-адрес отправителя. Однако может быть не удобно описать конфигурацию сервера, особенно для программного обеспечения фильтрации спама, которое установлено на клиентах электронной почты. Альтернативный подход включает в себя использование почтовых записей ОПК (обмен почтовой корреспонденцией, ОПК, MX) для обнаружения истинного источника сообщения. ОПК записывает для каждого имени домена перечень имен ПДИМ получателей электронной почты для данного домена. Можно прослеживать в обратном порядке перечень “received from”, пока не будет найден IP-адрес, который соответствует ПДИМ, соответствующему элементу в записи ОПК для домена. IP-адрес адресует, что “received from” данной машины является IP-адресом отправителя. Представим, что 1.2.3.101 является единственной записью ОПК для x.com. Тогда, найдя строку, с “received from”, соответствующим 1.2.3.101, можно узнать, что следующая строка соответствует серверу входящей электронной почты для x.com, и таким образом IP-адрес в этой строке соответствует IP-адресу, который посылал на x.com. Таблица ниже изображает примерный анализ определения истинного источника сообщения, как обсуждено выше:
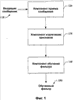
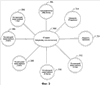
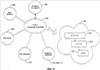
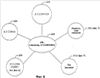
В настоящее время нет принятого стандарта для спецификации серверов исходящей электронной почты, и данная эвристика может потерпеть неудачу, если, например, IP-адреса, внутренние для предприятия, являются отличными от внешних для предприятия, или если предприятие посылает косвенно электронную почту от одной машины, входящей в перечень записи ОПК, на другую машину, входящую в перечень записи ОПК. Дополнительно, в специальном случае, когда обнаруживают, что IP отправителя, как определено выше, является внутренним для предприятия, как может случаться, если одна машина, находящаяся в записи ОПК, осуществляет посылку на другую, находящуюся в записи ОПК, обработку продолжают, как выше указано. В дополнение, некоторые IP-адреса могут быть выявлены как внутренние (поскольку они имеют форму 10.x.y.z или 172.16.y.z до 172.31.y.z или 192.168.0.z до 192.168.255.z, форма, используемая только для внутренних IP-адресов); любой адрес, являющийся внутренним для предприятия, может быть доверительным. В заключение если строка “received from” имеет форму “Received from a.x.com [1.2.3.100]” и просмотр IP-адреса a.x.com вырабатывает 1.2.3.100 или обратный поиск IP-адреса 1.2.3.100 вырабатывает a.x.com и если x.com является данным предприятием, то следующая строка может также быть доверительной. Используя эти замечания, обычно возможно найти IP-адрес отправителя. Примерный псевдокод является нижеследующим: bool fFoundHostInMX; if (внешний IP-адрес записи ОПК совпадает со внутренним IP-адресом записей ОПК) { fFoundHostInMX – FALSE; # его стоит искать } else { fFoundHostInMX = TRUE; # его не стоит искать, считаем (претендуем), что его уже нашли } для каждой строки received from, имеющей форму Received from a.b.c [i.j.k.l] { если i.j.k.l в записях MXдомена получателя { fFoundHostInMX – TRUE; продолжить; } если не fFoundHostInMX { # Еще не разобрали запись ОПК, должно быть внутренним продолжить; } если i.j.k.l в форме 10.x.y.z или 172.16.y.z до 172.31.y.z или 192.168.0.z до 192.168.255.z { # Должно быть внутренним продолжить; } если просмотр DNS для a.b.c вырабатывает i.j.k.l и d.b.c является доменом получателя { # Должно быть внутренним продолжить; } Вывести предполагаемый ПДИМ отправителя a.b.c и действительный IP-адрес отправителя i.j.k.k } Если пришли сюда, то Ошибка: нет возможности идентифицировать предполагаемый ПДИМ отправителя и действительный IP-адрес отправителя. Многое может быть сделано с IP-адресом отправителя, как с другими признаками источника и адресата. Во-первых, они могут быть добавлены к перечню постоянно плохих отправителей, в некоторых вариантах известного в качестве Черного Списка. Черные Списки могут быть использованы впоследствии для фильтрования, блокирования или переадресации ненадежных сообщений к соответствующей папке или местоположению, на котором они могут быть дополнительно исследованы. Другие типы перечней также могут быть сформированы и реализованы в качестве фильтров как в архитектуре (на основе) клиента, так и архитектуре (на основе) сервера. В архитектуре клиента пользователь может информировать клиентское программное обеспечение электронной почты о том, от кого он должен принимать электронную почту (например, перечни адресов электронной почты (список рассылки), отдельные личности, и т.д.). Перечень записей, соответствующих доверительным адресам электронной почты, может быть сформирован пользователем либо вручную, либо автоматически. Соответственно, представим себе, что отправитель, имеющий адрес электронной почты В качестве альтернативы к наполнению перечней признаков доверительных или плохих источников признаки источника отправителя (например, IP-адрес, предполагаемый адрес “From” (от)) могут быть извлечены в качестве одного или нескольких признаков и использоваться позднее в связи со способами машинного обучения для того, чтобы сформировать и/или обучить фильтр. Любая комбинация признаков, как описано выше, может быть извлечена из каждого входящего сообщения 110. Сообщения могут быть выбраны случайно, автоматически и/или вручную для того, чтобы участвовать в извлечении признаков, хотя обычно все сообщения могут быть использованы. Извлеченные наборы признаков впоследствии применяют к компоненту 140 обучения фильтра, такому как системы машинного обучения или любая другая система, которая создает и/или обучает фильтры 150, такие как фильтры спама. Что касается фиг.2, то на ней проиллюстрирована система 200 извлечения признаков, которая содействует раскрытию или нормализации одного или нескольких признаков входящего сообщения 210 в соответствии с одним аспектом настоящего изобретения. В конечном счете фильтр(ы) может быть создан на основании, по меньшей мере частично, одного или нескольких нормализованных признаках. Система 200 содержит компонент 220 экстрактора признака, который принимает входящее сообщение 210 либо непосредственно, как показано, либо косвенно в качестве получателя сообщения (фиг.1), например. Входящие сообщения, выбранные для извлечения признаков, или участвующие в извлечении признаков, в соответствии с пользовательскими предпочтениями могут быть подвергнуты системе 200. В качестве альтернативы, по существу, все входящие сообщения могут быть доступны для извлечения признаков и участвовать в извлечении признаков. Извлечение признаков включает в себя извлечение (вытягивание) одного или нескольких признаков 230 (упомянутых также как FEATURE1 232, FEATURE2 234, и FEATUREM 236, причем М является целым числом, большим или равным единице), ассоциированных с информацией об источнике и/или адресате из сообщения 210. Информация об источнике может относиться к элементам, указывающим отправителя сообщения, а также серверные доменные имена (доменов сервера) и относящуюся к идентификации информацию, которая указывает, откуда прибыло сообщение. Информация адресата может относиться к элементам сообщения, указывающим, кому или где получатель может послать свой ответ на сообщение. Информация об источнике и адресате может быть найдена в заголовке сообщения, а также в теле сообщения либо как видимая, либо как невидимая (например, вложенная как текст или в изображении) для получателя сообщения. На фиг.3 изображено примерное разбиение (разложение) IP-адреса 300 в соответствии с аспектом настоящего изобретения. IP-адрес 300 является 32-битовым по длине и состоящим из блоков (например, сетевыми блоками), если выражен в точечном десятичном формате (например, 4 блока до 3 цифр каждый, в котором каждый блок отделен точками и в котором каждый блок из 3 цифр является произвольным числом в диапазоне между 0 и 255). Блоки назначены классам, таким как Class A (Класс A), Class B (Класс B) и Class C (Класс C). Каждый блок содержит установленное количество IP-адресов, причем количество IP-адресов в блоке изменяется в соответствии с классом. То есть в зависимости от класса (то есть A, B, или C) может быть большее или меньшее количество адресов, назначаемых на блок. Размер блока является обычно кратным 2, и набор IP-адресов в одном и том же блоке будет совместно использовать k первых двоичных цифр и различаться в 32-k (например, 32 минус k) последних двоичных цифрах. Таким образом, каждый блок может быть идентифицирован (ID 302 блока) в соответствии с его совместно используемыми первыми k битами. Чтобы определить ИД (ID) 302 блока, который ассоциирован с конкретным IP-адресом 300, пользователь может обращаться за справкой в каталог блоков, например, arin.net. Более того, ID 302 блока может быть извлечен и использован в качестве признака. В некоторых обстоятельствах, однако, ID 302 блока не может быть легко определен даже при обращении к arin.net, поскольку группы IP-адресов внутри блока могут быть проданы разделенными и перепроданы любое количество раз. В таких случаях пользователь или система извлечения могут делать одно или несколько предположений об идентификаторах ID 302 блоков для соответствующих IP-адресов. Например, пользователь может извлечь по меньшей мере первый 1 бит 304, по меньшей мере первые 2 бита 306, по меньшей мере первые 3 бита 308, по меньшей мере первые М битов 310 (то есть М является целым числом, большим или равным единице) и/или по меньшей мере до первых 31 бите 312 в качестве отдельных признаков для последующего использования системой машинного обучения и/или в качестве элементов в перечне(ях) признаков (например, в перечнях “хороших” признаков, в перечнях признаков спама, и т.д.). Практически, например, первый 1 бит IP-адреса может быть извлечен и использован в качестве признака для того, чтобы определить, указывает ли IP-адрес на рассылающего спам или на не рассылающего спам отправителя. Может быть осуществлено сравнение первого 1 бита из других IP-адресов, извлеченных из других сообщений, для того, чтобы содействовать определению по меньшей мере одного ID блока. ID, идентифицирующий по меньшей мере один блок, может затем помогать распознаванию, является ли сообщение посланным от рассылающего спам отправителя. Более того, IP-адреса, которые совместно используют первые М битов, могут сравниваться относительно других их извлеченных признаков для того, чтобы установить, являются ли IP-адреса от законных отправителей и/или являются ли соответствующие сообщения спамом. IP-адреса также могут быть упорядочены иерархически (314). То есть набор битов высокого порядка может быть назначен конкретной стране. Эта страна может назначать поднабор ПУИ (Поставщику услуг Интернет, ISP), и этот ПУИ затем может назначать поднабор для конкретной компании. Соответственно, различные уровни могут быть значащими для одного и того же IP-адреса. Например, факт, что IP-адрес исходит от блока, назначенного для Кореи, мог бы быть полезен в определении, ассоциирован ли IP-адрес с рассылающим спам отправителем. Если IP-адрес является частью блока, назначенного ПУИ со строгой политикой против рассылающих спам отправителей, то это также могло бы быть полезным в определении, что IP-адрес не ассоциирован с рассылающим спам отправителем. Следовательно, посредством использования каждого из первых 1-31 битов IP-адреса в комбинации с иерархической схемой 314 по меньшей мере поднабора IP-адресов пользователь может автоматически узнавать (изучать) информацию на различных уровнях, без знания, по существу, (в действительности) способа, которым IP-адрес был назначен (например, без знаний идентификаторов ID блоков). В дополнение к признакам, описанным выше, редкость 316 признака (например, присутствие признака не является достаточно общим) может быть определена выполнением соответствующих вычислений и/или использованием статистических данных, сравнивающих частоту или количество раз, которое признак появляется в выборке (из) входящих сообщений, например. Практически редким IP-адресом 300 может быть пример линии модемной связи, используемой для доставки электронной почты, которая является тактикой, обычно используемой рассылающими спам отправителями. Рассылающие спам отправители обычно имеют тенденцию изменять свою идентичность и/или местоположение. Таким образом, факт, что признак является общим (обычным) или редким, может быть полезной информацией. Следовательно, показанная редкость 316 может быть использована в качестве признака для системы машинного обучения и/или как часть по меньшей мере одного перечня (например, перечня редких признаков). На фиг.4 продемонстрировано примерное разбиение признаков для ПДИМ 400, как например, b.x.com. ПДИМ 400 может быть извлечен из поля HELO, например, (например, предполагаемый ПДИМ отправителя) и обычно включает имя 402 хоста (главной машины) и имя 404 домена. Имя 402 хоста ссылается на конкретный компьютер, которым является Некоторые признаки, как, например, информация “received-from” (принять от:), существуют первоначально в качестве IP-адресов. Таким образом, может быть полезно преобразовать ПДИМ 400 к IP-адресу 300, который может быть разбит на дополнительные признаки (как показано на фиг.3), поскольку относительно просто создать новые имена хостов и имена доменов, но относительно трудно получить новые IP-адреса. К сожалению, владельцы домена могут устанавливать для предположительно различных машин соотнесение их всех с одной и той же позицией (в имени). Например, владелец машины, названной “a.x.com”, может быть тем же, что и владелец “b.x.com”, который может быть тем же, что и владелец “x.com”. Таким образом, рассылающий спам мог бы легко направлять обычный фильтр по ложному пути поверки, что сообщение является от ПДИМ 400 “b.x.com”, а не от домена 404 “x.com”, таким образом позволяя сообщению обойти фильтр спама, хотя в действительности домен 404 В заключение редкость признака 316 или тип признака (см. фиг.3. выше) могут быть еще одним признаком, как описано выше согласно фиг.3. Например, признак, извлеченный из сообщения, такого как имя “B” 402 хоста из ПДИМ 400 “b.x.com”, может быть общим примером для типа признака: «порнографический материал». Следовательно, если этот признак извлечен из сообщения и затем найден в перечне признаков порнографического материала, то может быть сделано заключение, что более вероятно, что сообщение будет спамом, или неподходящим/несоответствующим для всех возрастов, или составляет содержимое для взрослых (например, характеристика «взрослые»), и подобное. Таким образом, каждый перечень может включать в себя более общие признаки такого конкретного типа. В качестве альтернативы соответствующий IP-адрес обыкновенно может быть найден в спам-сообщениях в целом и таким образом обозначен в качестве общего признака спама. Кроме того, признаки общности и/или редкости могут быть использованы в качестве отдельного признака для систем машинного обучения или других систем, основанных на правилах. На фиг.5 продемонстрировано примерное разбиение признаков адреса 500 электронной почты: a@b.x.com, который включает в себя ПДИМ 400, а также несколько дополнительных признаков, например, пользовательского имени 502. Адрес 500 электронной почты может быть извлечен из поля From, поля “cc” и поля “reply-to” сообщения, а также из любых ссылок “mailto:” в теле сообщения (например, ссылки “mailto:” являются ссылкой специального вида, которая при щелчке формирует отправку почты по конкретному адресу), и, если доступно, из команды MAIL FROM, используемой в протоколе SMTP. Адреса 500 электронной почты могут быть также вложенными как текст в тело сообщения. В некоторых случаях содержимое сообщения может предписывать получателю использовать функцию “reply all” (ответить всем) при ответе на сообщение. В таких случаях по адресам в поле “cc” и/или по меньшей мере части из них, включенных в поле”to” (“по”) (если перечислено более одного получателя), также нужно отвечать. Таким образом, каждый из этих адресов может быть извлечен в качестве одного или нескольких признаков для содействия идентификации рассылающего спам отправителя и предотвращения спама. Адрес 500 электронной почты”a@b.x.com По нескольким практическим причинам, таким как легкость использования, распознавания и запоминания, адреса электронной почты являются обычно изображенными (нотированными) предпочтительно с использованием имен ПДИМ, чем IP-адресов. В настоящем примере “a@b.x.com” содержит пользовательское имя “a” 502. Таким образом, “a” может быть извлечено в качестве одного признака. Аналогично, ПДИМ 504
Если суффиксы отделены, то ПДИМ 630 может быть анализирован далее, чтобы получить дополнительные признаки, как предварительно обсуждено выше согласно фиг.4. Кроме того, ПДИМ 630 также может быть преобразован в IP-адрес, как продемонстрировано на фиг.3 выше. Соответственно, различные признаки, относящиеся к IP-адресу, также могут быть использованы в качестве признаков.
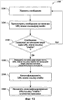
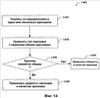
Различные методики в соответствии со связанным изобретением теперь будут описаны посредством последовательности действий. Должно быть понято и оценено, что настоящее изобретение не ограничено порядком действий, так что некоторые действия могут в соответствии с настоящим изобретением происходить в различной последовательности и/или одновременно с другими действиями из тех, которые показаны и описаны в настоящем документе. Например, специалисты в данной области техники поймут и оценят, что в качестве альтернативы методика могла бы быть представленной в виде последовательностей взаимосвязанных состояний или событий, таких как в диаграмме состояний. Более того, не все проиллюстрированные действия могут потребоваться, чтобы осуществить методику в соответствии с настоящим изобретением. Извлеченные (и/или нормализованные) признаки, а также классификация сообщения (например, спам или не спам) на этапе 730 могут быть добавлены к обучающему набору данных. На этапе 740 вышеупомянутые этапы (например, 710, 720, и 730) могут быть повторены для существенно всех других входящих сообщений до тех пор, пока они не будут соответственно обработаны. На этапе 750 признаки, которые, проявляются в качестве полезных или наиболее полезных признаков, могут быть выбраны из обучающего набора(ов). Такие выбранные признаки могут быть использованы для обучения фильтра, такого как машинно-обучаемого фильтра, например, посредством алгоритма машинного обучения, на этапе 760. После того как обучен, машинно-обучаемый фильтр может быть использован для того, чтобы содействовать обнаружению спама, как описано в соответствии с примерным способом 800 на фиг.8. Способ 800 имеет началом прием сообщения на этапе 810. На этапе 820 извлекают один или несколько признаков из сообщения, как описано ниже относительно фиг.11. На этапе 830 извлеченные признаки пропускают через фильтр, обученный системой машинного обучения, например. Следуя далее, от системы машинного обучения получают решение, такое как “спам”, “не спам”, или вероятность, что сообщение является спамом. Как только получено решение относительно содержимого сообщения, может быть предпринято соответствующее действие. Типы действий включают в себя, но не ограничены перечисляемым, удаление сообщения, перемещение сообщения в специальную папку, изолирование (предотвращение) сообщения и разрешение получателю осуществлять доступ к сообщению. В качестве альтернативы, действия на основе перечня могут быть выполнены с признаками, извлеченными из сообщений. Что касается фиг.9, то на ней проиллюстрирована схема последовательности операций примерного способа 900 для создания и наполнения перечней на основании, по меньшей мере частично, извлеченных признаков и их вхождения в принятые сообщения, классифицированные либо как спам, либо не спам (или вероятно или маловероятно являющимися спамом). Процесс 900 начинается с приема сообщения на этапе 910. Следуя далее, на этапе 920 извлекают некоторый признак, представляющий интерес, как, например, IP-адрес отправителя сообщения. В некоторый момент времени после того, как сообщение принято, сообщение может быть классифицировано как спам или не спам, например, посредством существующего фильтра. На этапе 930 признак может быть подсчитан с приращением в соответствии с классификацией сообщения (например, спам или не спам). Это может повторяться на этапе 940 до тех пор, пока, по существу, все сообщения не будут обработаны (например, на этапах 910, 920 и 930). После этого на этапе 950 могут быть созданы перечни признаков. Например, один перечень может быть создан для IP-адресов отправителей, которые являются на 90% “хорошими” (например, не спам в течение 90% времени или не спам для 90% входящих сообщений). Подобным образом другой перечень может быть создан для IP-адресов отправителей, которые являются на 90% “плохими” (передающими спам). Другие перечни для других признаков могут быть созданы подобным образом. Должно быть оценено, что эти перечни могут быть динамическими. То есть они могут быть обновлены по мере того, как обработаны дополнительные группы новых сообщений. Следовательно, возможно, что IP-адрес отправителя первоначально будет найден в перечне “хороших”; и затем в некоторый момент времени позднее будет найден в перечне “плохих”, поскольку обычно некоторые рассылающие спам отправители первоначально посылают “хорошую” электронную почту (например, чтобы получить “доверие” фильтров, а также получателей) и затем начинает посылать в основном только спам. Такие перечни могут быть использованы различными способами. Например, они могут быть использованы для того, чтобы формировать обучающие наборы для использования системой машинного обучения с целью обучить фильтры. Таковой изображен посредством примерной процедуры 1000, описанной затем на фиг.10. В соответствии с фиг.10 процедура 1000 может начинаться с приема сообщения на этапе 1010. Сообщение может быть классифицировано, например, как спам или не спам. На этапе 1020 признаки, включающие в себя, но не ограниченные им, IP-адрес отправителя, могут быть извлечены из сообщения. На этапе 1030 извлеченные признаки и классификацию сообщения добавляют к обучающему набору, который впоследствии используют, чтобы обучить систему машинного обучения. Следуя далее, на этапе 1040 специальный признак, соответствующий конкретному перечню, в котором находится IP-адрес отправителя, включают в обучающий набор. Например, если IP-адрес отправителя был в перечне “хорошие на 90%”, то признак, добавленный к обучающему набору, будет “перечень хороших на 90%”. На этапе 1050 предшествующие этапы (например, 1010, 1020, 1030, и 1040) могут быть повторены, чтобы обработать, по существу, все входящие сообщения. Поскольку некоторые признаки могут быть более полезными для целей обучения фильтра, чем остальные, наиболее полезный признак или признаки выбирают на этапе 1060 на основании частично на пользовательском предпочтении и применяют, чтобы обучить фильтр(ы), такие как фильтр спама, используя алгоритм машинного обучения. Более того, динамические перечни IP-адресов, например, могут быть созданы для сравнения с тестовыми (контрольными) сообщениями, новыми сообщениями и/или подозрительными сообщениями. Однако собственно IP-адреса не являются признаками в данном случае. Вместо этого признаком является качество IP-адреса. В качестве альтернативы или в дополнение, перечни могут быть использованы другими способами. На практике, например, перечень подозрительных IP-адресов может быть использован, чтобы пометить отправителя как “плохого”, и соответственно, обрабатывать их сообщения с подозрением. Если обратиться теперь к фиг.11, то на ней проиллюстрирована схема последовательности операций примерного способа 1100 извлечения признаков из сообщения в объединении со способами 700, 800, 900 и 1000, описанными выше согласно фиг.7-10 соответственно. Обработка по способу 1100 может начинаться с этапа 1110, на котором выделяют и нормализуют IP-адрес “received-from” или его части. Также на этапе 1110 IP-адрес может быть подвергнут поразрядной обработке (например, первый 1 бит, первые 2 бита, Дополнительно, на этапе 1120 содержимое строки “From:” может быть извлечено и/или нормализовано и впоследствии использовано в качестве признаков. На этапе 1130 содержимое команды “MAIL FROM SMTP” может быть подобным образом извлечено и/или нормализовано для использования в качестве признаков. Способ 1100 затем может переходить к поиску других возможных признаков, которые могут быть включены в сообщение. Например, он может дополнительно извлечь и нормализовать (если необходимо) содержимое в поле “reply-to” на этапе 1140. На этапе 1150 содержимое поля “cc” может быть дополнительно извлечено и/или нормализовано для использования в качестве по меньшей мере одного признака. На этапе 1160 подлежащие оплате номера телефонов могут дополнительно быть извлечены из тела сообщения и также назначены в качестве признаков. Нетелефонные номера могут быть полезны для идентификации рассылающих спам отправителей, поскольку междугородный код и/или первые три цифры телефонного номера могут быть использованы для соотнесения местоположения рассылающего спам отправителя. Если в сообщении присутствуют более одного подлежащего оплате номера телефона, то каждый номер может быть извлечен и использован в качестве отдельных признаков на этапе 1160. Обработка по способу 1100 может продолжать просмотр тела сообщения, чтобы отыскать другие адреса электронной почты, а также ключевые слова и/или фразы (например, предварительно выбранные или определенные), которые могут быть более вероятно найденными в сообщении спама, чем в законном сообщении и наоборот. Каждое слово или фраза могут быть извлечены и использованы в качестве признака либо для систем машинного обучения, либо в качестве элемента перечня, либо для обоих. Как раскрыто выше, сообщения, посылаемые по Интернет, могут быть посланы с сервера на сервер с помощью лишь двух вовлеченных серверов. Количество серверов, которые обмениваются сообщениями, возрастает в результате присутствия брандмауэров и связанных сетевых архитектур. По мере того как сообщение передают от сервера на сервер, каждый сервер добавляет свой IP-адрес к началу поля “received-from”. Каждый сервер также имеет возможность изменения любых, ранее добавленных к началу адресов “received-from”. Рассылающие спам отправители, к сожалению, могут воспользоваться преимуществом такой возможности и могут вводить поддельные адреса в поля “received-from”, чтобы маскировать свои местоположения и/или идентификационную информацию и вводить в заблуждение получателя относительно источника сообщения. На фиг.12 проиллюстрирована схема последовательности операций примерного способа 1200 различения между законными и поддельными (например, рассылающими спам) IP-адресами сервера, добавленными к началу в строке “received-from” входящего сообщения. Добавленные к началу адреса “received-from” могут быть рассмотрены в том порядке, в котором они были добавлены (например, первым является наиболее недавно добавленный). Таким образом, на этапе 1210 пользователь может осуществлять обратное прослеживание по цепочке IP-адресов серверов-отправителей, чтобы определить последний доверительный IP-адрес сервера. На этапе 1220 последний доверительный IP-адрес сервера (тот, который непосредственно вне предприятия) может быть извлечен в качестве признака, подлежащего использованию системой машинного обучения. Любой другой IP-адрес после последнего доверительного может рассматриваться сомнительным или ненадежным и может быть игнорирован, но может быть сравнен с перечнями (главным образом) “хороших” IP-адресов и (главным образом) “плохих” IP-адресов. На этапе 1230 предполагаемый ПДИМ отправителя также может быть извлечен, чтобы содействовать определению, является ли отправитель законным или рассылающим спам. Более конкретно, предполагаемый ПДИМ может быть разбит посредством расщепления (анализа) домена, чтобы выработать более одного частичного ПДИМ. Например, представим, что предполагаемым ПДИМ является a.b.c.x.com. Данный предполагаемый ПДИМ будет расщеплен следующим образом, чтобы выработать: b.c.x.com -> c.x.com -> x.com -> com. Таким образом, каждый частичный сегмент ПДИМ, а также полный ПДИМ могут быть использованы в качестве отдельного признака, чтобы помочь в определении поддельных и законных отправителей. На практике различные классификации могут указывать различные степени бесполезности. Например, сообщения, классифицированные как «ненавистная речь», могут показать, по существу, отсутствие степени бесполезности (например, поскольку они наиболее вероятно не спам). Напротив, сообщения, классифицированные как сексуальное содержимое/материал, могут отражать относительно более высокую степень бесполезности (например, ~90% уверенности, что сообщение является спамом). Системы машинного обучения могут создавать фильтры, которые дают отчет (объясняют) о степени бесполезности. Таким образом, фильтр может быть настроен и индивидуализирован для удовлетворения пользовательских предпочтений. Как уже обсуждено, несметное число признаков может быть извлечено из сообщения и использовано в качестве обучающих данных системой машинного обучения или в качестве элементов в перечне(ях), идентифицирующих хорошие и плохие признаки. Качества признаков, в дополнение к собственно признакам, могут быть полезны при выявлении и предотвращении спама. Например, представим, что одним признаком является адрес электронной почты отправителя. Адрес электронной почты может быть использован как один признак и частота, или количество появлений такого адреса электронной почты в новых входящих сообщениях может использоваться в качестве еще одного признака. Обработка 1400 может начинаться с извлечения одного или нескольких признаков из входящего сообщения и/или нормализации признака(ов) на этапе 1410. Затем признак может быть сравнен с одним или несколькими перечнями признаков, которые были ранее извлечены или рассмотрены во множестве предшествующих сообщений на этапе 1420. Обработка 1400 затем может определить, является ли настоящий признак общим. Общность признака может быть определена посредством вычисленной частоты появления признака в недавних и/или предыдущих входящих сообщениях. Если сообщение не является общим или недостаточно общим (например, будет не в состоянии удовлетворять пороговому значению общности) на этапе 1430, то его редкость может использоваться в качестве дополнительного признака на этапе 1440. Иначе общность признака также может использоваться в качестве признака также на этапе 1450. В соответствии с настоящим изобретением, как описано выше, нижеследующий псевдокод может быть использован для того, чтобы реализовать по меньшей мере один аспект изобретения. Имена переменных обозначены прописными буквами. Как дополнительное примечание, две функции, add-machine-features (добавить-машинные-признаки) и add-ip-features (добавить-IP-признаки), определены в конце псевдокода. Нотация, подобная “PREFIX-machine-MACHINE”, используется, чтобы указать строку, составленную из того, что находится в переменной PREFIX (ПРЕФИКС), объединенным со словом machine, объединенным с тем, что находится в переменной MACHINE. В заключение функция add-to-feature-list (добавить-к-перечню-признаков) записывает признак в перечень признаков, ассоциированных с текущим сообщением. Примерный псевдокод является нижеследующим: # для данного сообщения извлечь все признаки IPADDRESS:= последний внешний IP-адрес в перечне received-from; add-ipfeatures(received, IPADDRESS); SENDERS-ALLEGED-FQDN:= FQDN в последнем внешнем IP-адресе в перечне received-from; add-machine-features(sendersfqdn, SENDERS-ALLEGED-FQDN); для каждого адреса электронной почты типа TYPE из (from, CC, to, reply-to, embedded-mailto-link, embedded-address, и SMTP MAIL FROM) { для каждого адреса ADDRESS типа TYPE в сообщении { раскрыть ADDRESS, если необходимо; add-to-feature-list TYPE-ADDRESS; если ADDRESS в форме NAME@MACHINE, то { add-machine-features(TYPE, MACHINE); } иначе { # ADDRESS в форме NAME@IPADDRESS add-ip-features(TYPE, IPADDRESS); } } } для каждого url типа TYPE из (clickable-1inks, text-based-links, embedded-image-links) { { add-to-feature-list TYPE-class-PARENTCLASS; { } { } иначе { } } } function add-machine-features(PREFIX, MACHINE) { add-ip-features(PREFIX-ip, nslookup(MACHINE)); пока MACHINE не равно “” { add-to-feature-list PREFIX-machine-MACHINE; удалить, начиная с MACHINE # (т.е. a.x.com -> x.com, или x.com -> com); } } function add-ip-features(PREFIX, IPADDRESS) { add-to-feature-list PREFIX-ipaddress-IPADDPESS; найти сетевой блок СЕТЕВОЙ БЛОК из IPADDRESS; add-to-feature-list PREFIX-сетевой блок-СЕТЕВОЙ БЛОК; для N = 1 до 31 { MASKED = первые N битов из IPADDRESS; add-to-feature-list PREFIX-masked-N-MASKED; } } Для представления дополнительного контекста различных аспектов настоящего изобретения предназначены фиг.15 и нижеследующее описание, чтобы обеспечить краткое общее описание соответствующей среды 1510, в которой могут быть осуществлены различные аспекты настоящего изобретения. Тогда как изобретение описано в общем контексте машиноисполнимых инструкций, таких как программные модули, исполняемые одним или несколькими компьютерами, или другими устройствами, специалисты в данной области техники признают, что изобретение может быть также осуществлено в комбинации с другими программными модулями и/или как комбинация аппаратных средств и программного обеспечения. В целом, однако, программные модули включают в себя подпрограммы, программы, объекты, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или осуществляют конкретные типы данных. Операционная среда 1510 является лишь одним примером подходящей операционной среды и не предусматривает наложения какого-либо ограничения как на объем использования, так и на функциональные возможности изобретения. Другие хорошо известные вычислительные системы, среды и/или конфигурации, которые могут быть пригодными для использования вместе с изобретением, включают в себя, но не ограничены перечисляемым, персональные компьютеры, переносные или портативные устройства, многопроцессорные системы, микропроцессорные системы, программируемую бытовую электронику, сетевые ПК, мини-компьютеры, мейнфреймы (большие ЭВМ), распределенные вычислительные среды, которые включают в себя вышеупомянутые системы или устройства, и подобное. Со ссылкой на фиг.15, примерная среда 1510 для осуществления различных аспектов настоящего изобретения включает в себя компьютер 1512. Компьютер 1512 включает в себя блок 1514 обработки или процессор, системное запоминающее устройство 1516 и системную шину 1518. Системная шина 1518 связывает системные компоненты, включая, но не ограничиваясь ими, системное запоминающее устройство 1516 с процессором 1514. Процессор 1514 может быть любым из различных доступных процессоров. Сдвоенные микропроцессоры и другая архитектура мультипроцессора также могут быть использованы в качестве процессора 1514. Системная шина 1518 может быть произвольного типа из нескольких типов шинной архитектур(ы), включая шину памяти или контроллер памяти, периферийную шину или внешнюю шину и/или локальную шину, использующую произвольную шинную архитектуру (организацию) из множества возможных шинных архитектур, включая, но не ограничиваясь, 11-битовую шину, промышленную стандартную архитектуру (ISA), микроканальную архитектуру (MСA), расширенную ISA (EISA), интеллектуальную электронику устройства (IDE), локальную шину VESA (VLB), межсоединение периферийных компонентов или системную шину PCI (PCI), универсальную последовательную шину (USB), ускоренный графический порт (AGP), шину стандарта PCMCIA (Международная ассоциация производителей плат памяти для персонального компьютера, PCMCIA) и интерфейс малых компьютерных систем (SCSI). Системное запоминающее устройство 1516 включает в себя энергозависимое запоминающее устройство 1520 и энергонезависимое запоминающее устройство 1522. Базовая система ввода-вывода (BIOS), содержащая основные программы для передачи информации между элементами компьютера 1512, например, в течение запуска, хранится в энергонезависимом запоминающем устройстве 1522. В качестве иллюстрации, а не ограничения, энергонезависимое запоминающее устройство 1522 может включать в себя постоянное запоминающее устройство (ПЗУ, ROM), программируемое ПЗУ (ППЗУ, PROM), электрически программируемое ПЗУ (ЭППЗУ, EPROM), электрически стираемое программируемое ПЗУ (ЭСППЗУ, EEPROM) или флэш-память. Энергозависимое запоминающее устройство 1520 включает в себя оперативное запоминающее устройство (ОЗУ, RAM), которое действует в качестве внешнего кэша. В качестве иллюстрации, а не ограничения, ОЗУ возможна во многих формах, таких как синхронное ОЗУ (СОЗУ, SRAM), динамическое ОЗУ (ДОЗУ, DRAM), синхронное ДОЗУ (СДОЗУ, SDRAM), SDRAM с двойной скоростью данных (ДСК СДОЗУ, DDR SDRAM), расширенное SDRAM (РСДОЗУ, ESDRAM), ДОЗУ с синхронной передачей данных (ДОЗУСПД, SLDRAM) и ОЗУ для шины прямого резидентного доступа (ОЗУПРД, DRRAM). Компьютер 1512 включает также сменные/несменные, энергозависимые/энергонезависимые носители запоминающих устройств. На фиг.15 проиллюстрировано, например, дисковое запоминающее устройство 1524. Дисковое запоминающее устройство 1524 включает в себя, но не ограничивается, устройства, подобные дисководу магнитного диска, дисководу гибкого диска, накопителю на магнитной ленте, устройства Jaz, дисководу для специальных zip-дисков или zip-дисководу, местное ЗУ LS-100, карту флэш-памяти, или закрепляемую память. В дополнение, дисковое запоминающее устройство 1524 может включать в себя носители информации отдельно или в комбинации с другими носителями информации, включая, но не ограничиваясь, накопитель на оптических дисках, такой как ПЗУ на компакт-дисках (CD-ROM), накопитель на компакт-дисках с однократной записью (CD-R Drive Диск CD-R), накопитель на перезаписываемых компакт-дисках (Диск CD-RW) или накопитель на цифровых универсальных дисках ПЗУ (DVD-ROM). Чтобы содействовать соединению дисковых запоминающих устройств 1524 с системной шиной 1518, обычно используют интерфейс сменных или несменных устройств, как, например, интерфейс 1526. Должно быть оценено, что на фиг.15 описано программное обеспечение, которое действует как посредник между пользователями и основными ресурсами компьютера, описанными в соответствующей операционной среде 1510. Такое программное обеспечение включает в себя операционную систему 1528. Операционная система 1528, которая может быть сохранена на дисковом запоминающем устройстве 1524, действует для того, чтобы управлять и распределить ресурсы вычислительной системы 1512. Системные приложения 1530 используют преимущество управления ресурсами посредством операционной системы 1528 через программные модули 1532 и программные данные 1534, сохраняемые либо на системном запоминающем устройстве 1516, либо на дисковом запоминающем устройстве 1524. Должно быть оценено, что настоящее изобретение может быть осуществлено с помощью различных операционных систем или комбинаций операционных систем. Пользователь вводит команды или информацию в компьютер 1512 посредством устройств(а) 1536 ввода данных. Устройства 1536 ввода данных включают в себя, но не ограничены перечисляемым, указывающее устройство, такое как мышь, шаровой указатель (трекбол), перо для ввода данных, сенсорную панель, клавиатуру, микрофон, джойстика, игровую панель, спутниковую антенны, сканер, плату селектора телевизионных каналов, цифровую камеру, цифровой видеокамеру, web-камеруи подобное. Эти и другие устройства ввода данных соединены с процессором 1514 системной шиной 1518 посредством интерфейсного порта(ов) 1538. Интерфейсный порт(ы) 1538 включает в себя, например, последовательный порт, параллельный порт, игровой порт, и универсальную последовательную шину (USB). Устройство(а) 1540 вывода данных использует некоторые из тех же типов портов, что и устройство(а) 1536 ввода данных. Таким образом, например, порт USB может использоваться для обеспечения ввода данных в компьютер 1512 и вывода информации из компьютера 1512 на устройство 1540 вывода данных. Адаптер 1542 вывода предусмотрен для иллюстрирования, что среди других устройств 1540 вывода присутствуют некоторые устройства 1540 вывода данных, подобные мониторам, динамикам и принтерам, которые требуют специальных адаптеров. Адаптеры 1542 вывода включают в себя, в качестве иллюстрации, а не ограничения, видеоплаты и звуковые платы, которые обеспечивают средство соединения между устройством 1540 вывода данных и системной шиной 1518. Следует отметить, что другие устройства и/или системы устройств предоставляют как возможности ввода данных, так и вывода данных, как, например, удаленный компьютер(ы) 1544. Компьютер 1512 может функционировать в сетевой среде, используя логические соединения с одним или несколькими удаленными компьютерами, таким как удаленный компьютер(ы) 1544. Удаленный компьютер(ы) 1544 может быть персональным компьютером, сервером, маршрутизатором, сетевым ПК, рабочей станцией, микропроцессорным устройством, одноранговым узлом или другим узлом сети общего пользования и т.п. и обычно включает в себя многие или все элементы из описанных выше элементов, относящихся к компьютеру 1512. Для целей краткости, вместе с удаленным компьютером(ами) 1544 проиллюстрировано только запоминающее устройство 1546. Удаленный компьютер(ы) 1544 логически соединен с компьютером 1512 через сетевой интерфейс 1548 и затем физически соединен через соединение 1550 связи. Сетевой интерфейс 1548 охватывает сети связи, такие как локальные сети (ЛС, LAN) и глобальные сети (ГС, WAN). Технические решения LAN включают в себя распределенный интерфейс передачи данных по волоконно-оптическим каналам (FDDI), распределенный проводной интерфейс передачи данных (CDDI), Ethernet/IEEE 1102.3, Token Ring/IEEE 1102.5 и подобное. Технические решения WAN включают в себя, но не ограничены, соединения «точка-точка», сети с коммутацией каналов, подобные цифровым сетям с интегрированными услугами (ISDN) и их разновидностей, сети с коммутацией пакетов, и цифровые абонентские линии (DSL). Соединение(я) 1550 связи относятся к аппаратному/программному обеспечению, используемому для соединения сетевого интерфейса 1548 с шиной 1518. Тогда как соединение 1550 связи показано для иллюстративной ясности внутри компьютера 1512, оно также может быть внешним для компьютера 1512. Аппаратное/программное обеспечение, необходимое для соединения сетевым интерфейсом 1548, включает, лишь для иллюстративных целей, внутренние и внешние технические средства, такие как модемы, включая телефонные модемы обычного класса, модемы кабельных линий и модемы цифровых абонентских линий (DSL), адаптеры ISDN и карты локальной сети Ethernet. То, что было описано выше, включает в себя примеры настоящего изобретения. Конечно, не является возможным описать каждую возможную комбинацию компонентов или методик с целями описания настоящего изобретения, но любому специалисту в данной области техники очевидно, что возможны многие дополнительные комбинации и изменения в форме настоящего изобретения. Соответственно, настоящее изобретение подразумевает охват всех таких изменений, модификаций и разновидностей, которые подпадают под рамки существа и объема прилагаемой формулы изобретения. Кроме того, по мере того, как термин “включает” используется как в подробном описании, так и в формуле изобретения, такой термин предназначен, чтобы быть включающим в смысле, подобном термину “содержащий”, поскольку “содержащий” при применении интерпретируют в качестве переходного слова в пункте формулы.
Формула изобретения
1. Компьютерно-реализованная система для извлечения данных в связи с обработкой спама, содержащая: 2. Система по п.1, отличающаяся тем, что дополнительно содержит компонент нормализации, который раскрывает набор признаков. 3. Система по п.1, отличающаяся тем, что фильтром является фильтр спама. 4. Система по п.1, отличающаяся тем, что фильтром является фильтр родительского контроля. 5. Система по п.1, отличающаяся тем, что дополнительно содержит компонент системы машинного обучения, который использует раскрытые признаки для того, чтобы изучить по меньшей мере одно из: спама и не спама. 7. Система по п.6, отличающаяся тем, что IP-адрес содержит идентификатор блока, причем идентификатор блока может быть извлечен в качестве по меньшей мере одного признака. 8. Система по п.7, отличающаяся тем, что идентификатор блока определяют, по меньшей мере частично, обращаясь к каталогу блоков. 9. Система по п.8, отличающаяся тем, что каталогом блоков является arin.net. 10. Система по п.7, отличающаяся тем, что идентификатор блока определяют, по меньшей мере частично, посредством угадывания, таким образом извлекая в качестве признаков любой один из по меньшей мере первого 1 бита, по меньшей мере первых 2 битов, по меньшей мере первых 3 битов, и вплоть до по меньшей мере первых 31 битов упомянутого IP-адреса. 11. Система по п.1, отличающаяся тем, что набор признаков содержит каждый из первого 1 вплоть до первых 31 битов IP-адреса. 14. Система по п.1, отличающаяся тем, что дополнительно содержит компонент, который использует по меньшей мере поднабор извлеченных признаков, чтобы заполнить по меньшей мере один перечень признаков. 15. Система по п.14, отличающаяся тем, что по меньшей мере один перечень признаков является любым одним из: перечня “хороших” пользователей, перечня рассылающих спам отправителей, перечня положительных признаков, указывающих законного отправителя, и перечня признаков, указывающих спам. 20. Система по п.1, отличающаяся тем, что набор признаков содержит по меньшей мере одно из: имени хоста и имени домена, извлеченных из адреса электронной почты. 23. Система по п.1, отличающаяся тем, что по меньшей мере часть набора извлеченных признаков нормализуют прежде, чем использовать в связи с системой машинного обучения. 24. Система по п.1, отличающаяся тем, что по меньшей мере часть набора извлеченных признаков нормализуют прежде, чем использовать для заполнения по меньшей мере одного перечня признаков. 26. Система по п.25, отличающаяся тем, что компонентом классификации является система родительского контроля. 28. Система по п.1, отличающаяся тем, что набор признаков содержит по меньшей мере один подлежащий оплате номер телефона, причем номер телефона содержит междугородный код, чтобы содействовать согласованию географического местоположения отправителя или контакта, ассоциированного с сообщением. 29. Выполняемый компьютером способ, который извлекает данные в связи с обработкой спама, заключающийся в том, что: 30. Способ по п.29, отличающийся тем, что набор признаков содержит по меньшей мере часть IP-адреса. 31. Способ по п.30, отличающийся тем, что извлечение по меньшей мере части IP-адреса содержит выполнение по меньшей мере одного из нижеследующих действий: 32. Способ по п.30, отличающийся тем, что по меньшей мере один извлеченный IP-адрес соответствует по меньшей мере одному серверу. 33. Способ по п.32, дополнительно заключающийся в том, что выделяют по меньшей мере один сервер в качестве дополнительного признака. 34. Способ по п.29, дополнительно заключающийся в том, что раскрывают по меньшей мере набор признаков, извлеченных из сообщения. 35. Способ по п.29, дополнительно заключающийся в том, что раскрывают по меньшей мере часть для по меньшей мере одного признака, извлеченного из сообщения. 36. Способ по п.35, отличающийся тем, что раскрытие IP-адреса “получено от:”, извлеченного из сообщения, содержит этап обратного прослеживания через множество адресов, добавленных к IP-адресу, для того, чтобы проверить идентификационные данные добавленных IP-адресов. 37. Способ по п.35, дополнительно заключающийся в том, что извлечение дополнительных признаков из адреса web-сайта содержит выполнение по меньшей мере одного из нижеследующих действий: 39. Способ по п.29, отличающийся тем, что по меньшей мере поднабор извлеченных признаков внедрен в тело сообщения в качестве одного из текста или изображений. 40. Способ по п.29, отличающийся тем, что набор признаков содержит имя хоста и имя домена. 41. Способ по п.29, дополнительно заключающийся в том, что классифицируют один или несколько извлеченных признаков и/или их части, чтобы указать любое одно из: “подходящее” или “неподходящее” содержимое, ассоциированное с сообщением, и используют такую классификацию в качестве дополнительного признака. 42. Способ по п.29, дополнительно заключающийся в том, что назначают тип признака соответствующим извлеченным признакам, чтобы уведомить пользователя о содержимом сообщения на основании, по меньшей мере частично, соответствующих извлеченных признаков и использования типа признака в качестве дополнительного признака. 43. Способ по п.42, дополнительно заключающийся в том, что определяют, что по меньшей мере одно из: тип признака и признака, являющегося любым одним из: “редкий” и “общий”, и используют редкость и общность признака в качестве дополнительного признака. 44. Способ по п.29, отличающийся тем, что набор признаков используют для содействия обучению фильтра посредством системы машинного обучения. 45. Способ по п.29, отличающийся тем, что фильтр является фильтром спама. 46. Способ по п.29, отличающийся тем, что фильтр является фильтром родительского контроля. 47. Способ по п.29, дополнительно заключающийся в том, что используют по меньшей мере набор признаков, извлеченных из сообщения, чтобы заполнить один или несколько перечней признаков. 48. Способ по п.47, отличающийся тем, что перечни признаков содержат по меньшей мере одно из: перечней “положительных” признаков, указывающих не рассылающих спам отправителей, и перечней “плохих” признаков, указывающих рассылающих спам отправителей. 49. Способ по п.29, отличающийся тем, что извлеченные признаки раскрывают по меньшей мере частично прежде, чем использовать в качестве признаков для системы машинного обучения. 50. Способ по п.29, отличающийся тем, что извлеченные признаки раскрывают по меньшей мере частично прежде, чем используют в качестве признаков для заполнения перечней признаков. 51. Система, реализуемая компьютером, которая извлекает данные в связи с обработкой спама, и которая содержит:
РИСУНКИ
|
||||||||||||||||||||||||||
 595
595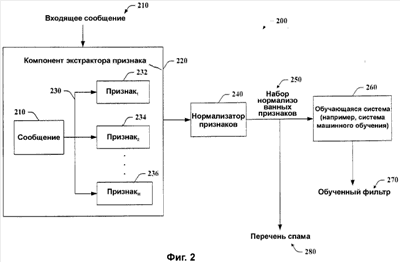
 , в котором “щелкните здесь” содержит ссылку к определенной web-странице, которую система машинного обучения может выявить и использовать в соответствии с одним аспектом настоящего изобретения. Подобным образом адрес, по которому нужно отвечать (например, обычно адрес “from” (“отправитель”), но иногда адрес “reply-to” (“ответить по”), если таковой есть), или любой вложенный mailto: ссылки (ссылки, которые позволяют послать сообщение электронной почты, щелкая по ссылке), или любые другие вложенные адреса электронной почты. Дополнительно, рассылающие спам пользователи обычно включают в сообщения изображения. Поскольку многократная отправка по электронной почте больших по размерам изображений является дорогой, то рассылающие спам пользователи обычно встраивают только специальную ссылку на изображение, которое побуждает загрузку изображения. Местоположения, на который указывают такие ссылки, также могут быть использованы в качестве признаков.
, в котором “щелкните здесь” содержит ссылку к определенной web-странице, которую система машинного обучения может выявить и использовать в соответствии с одним аспектом настоящего изобретения. Подобным образом адрес, по которому нужно отвечать (например, обычно адрес “from” (“отправитель”), но иногда адрес “reply-to” (“ответить по”), если таковой есть), или любой вложенный mailto: ссылки (ссылки, которые позволяют послать сообщение электронной почты, щелкая по ссылке), или любые другие вложенные адреса электронной почты. Дополнительно, рассылающие спам пользователи обычно включают в сообщения изображения. Поскольку многократная отправка по электронной почте больших по размерам изображений является дорогой, то рассылающие спам пользователи обычно встраивают только специальную ссылку на изображение, которое побуждает загрузку изображения. Местоположения, на который указывают такие ссылки, также могут быть использованы в качестве признаков. b@zyx.com
b@zyx.com и до первых 31 бите из IP-адреса в качестве отдельных признаков (см. фиг.3).
и до первых 31 бите из IP-адреса в качестве отдельных признаков (см. фиг.3).