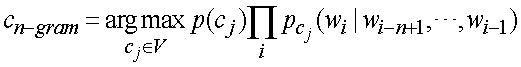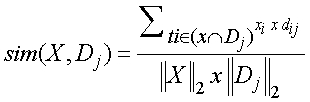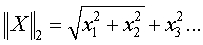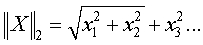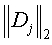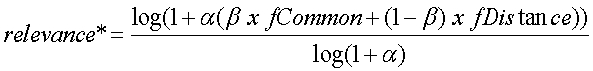Патент на изобретение №2375747
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(54) ПРОВЕРКА РЕЛЕВАНТНОСТИ МЕЖДУ КЛЮЧЕВЫМИ СЛОВАМИ И СОДЕРЖАНИЕМ ВЕБ-САЙТА
(57) Реферат:
Связанные заявки Настоящая патентная заявка связана со следующими патентными заявками, каждая из которых переуступлена правообладателю этой заявки и тем самым включается сюда по ссылке: Патентная заявка США Патентная заявка США Патентная заявка США Область техники Системы и способы изобретения принадлежат к информационному анализу данных. Уровень техники Ключевое слово или ключевая фраза – это слово или набор терминов, переданных пользователем веб-сети поисковому серверу при поиске связанной веб-страницы/сайта во всемирной паутине (WWW). Поисковые серверы определяют релевантность веб-сайта, основываясь на ключевых словах и ключевых фразах, которые появляются на странице/сайте. Поскольку существенный процент трафика веб-сайта является результатом использования поисковых серверов, промоутеры веб-сайтов знают, что надлежащий выбор ключевых слов(а) жизненно важен для увеличения трафика сайта для получения желательного освещения сайта. Методы идентификации ключевых слов, релевантных веб-сайту, для оптимизации результата поискового сервера включают, например, оценку человеком содержания веб-сайта и стремление идентифицировать релевантное ключевое слово(а). Эта оценка может включить использование инструмента определения популярности ключевого слова. Такие инструменты определяют, сколько людей передали конкретное ключевое слово или фразу, включающую ключевое слово, поисковому серверу. Ключевые слова, релевантные веб-сайту и определенные, как наиболее часто использованные для создания запросов на поиск, обычно выбираются для оптимизации результата поискового сервера относительно веб-сайта. Может показаться, что самый простой способ проверять ключевое слово(а) в отношении к веб-сайту (то есть содержанию веб-сайта) состоит в том, чтобы использовать обычный подход к поиску, который измеряет подобие только между ключевым(и) словом(ами) и веб-сайтом, без любых дополнительных сравнений точки ввода данных. Однако этот метод существенно ограничен. Даже при том, что ключевое слово может быть связано с веб-сайтом, сам сайт может не включать пороговые критерии (например, прямое соответствие, число появлений и т.д.), поддержку желательных ключевых слов, вызывая отклонение потенциально ценного термина предложений. Например, рассмотрим, что корпорация интерактивного магазина с соответствующим веб-сайтом предлагает цену на фразе «интерактивный магазин». Если используется обычный подход к поиску и на веб-сайте найдено относительно малое число появлений ключевого слова «магазин» и не одного появления ключевого слова «интерактивный», потенциально ценная ключевая фраза «интерактивный магазин» может быть по ошибке дисквалифицирована как термин предложения цены. Другой обычный метод заключается в классификации термина/фразы предоставленного предложения цены и веб-сайта для получения двух векторов категорий вероятности, которые потом объединяются в конечный релевантный контекст. Проблема с этим обычным методом состоит в том, что он не оценивает термин/фразу непосредственно по отношению к его веб-сайту, что может быть существенно проблематичным. Например, если рекламодатель предлагает цену по термину «итальянские ботинки» и его веб-сайт продает ботинки, но НЕ итальянские ботинки, обычный метод классификации укажет для рекламодателя, что фраза предложения цены «итальянские ботинки» не релевантна веб-сайту. Ввиду вышеизложенного, системы и способы лучшей идентификации ключевых слов, релевантных содержанию веб-сайта, приветствовались бы промоутерами веб-сайта. Это позволило бы промоутерам предлагать цену по терминам более вероятным для использования конечным пользователем. В идеале эти системы и способы должны быть независимы от требования оценки человеком содержания веб-сайта для идентификации релевантных ключевых слов для оптимизации поискового сервера и предложения цены по ключевым словам. Сущность изобретения Краткое описание чертежей В чертежах крайняя левая цифра ссылочной позиции компонента идентифицирует конкретный чертеж, на котором компонент появляется в первый раз. Фиг.1 – примерная система для проверки релевантности между содержанием веб-сайта и терминами. Фиг.2 – примерная процедура для проверки релевантности между содержанием веб-сайта и терминами. Фиг.3 – примерная процедура для проверки релевантности между содержанием веб-сайта и терминами. В частности, Фиг.3 является продолжением примерных операций из фиг.2. Фиг.4 – пример подходящей компьютерной среды, на которой описанные ниже системы, устройство и способы для проверки релевантности между терминами и содержанием веб-сайта могут быть полностью или частично осуществлены. ПОДРОБНОЕ ОПИСАНИЕ Краткий обзор Следующие системы и способы проверяют релевантность между терминами и содержанием веб-сайта для учета ограничений обычных методов квалификации термина. С этой целью системы и способы объединяют множество измерений подобия посредством моделей обучаемого классификатора для получения единственного значения достоверности, указывающего, релевантен(тны) ли термин(ы) предложения цены содержанию конкретного веб-сайта. Более подробно, и в этом осуществлении, множество измерений подобия включают оценки подобия содержания, категории и подобия имени собственного. Оценки подобия содержания включают прямое и расширенное подобие содержания. Прямое подобие содержания определяется с помощью оценки векторных моделей термина(ов) предложения цены и содержаний сайта для представленного веб-сайта. Расширенное подобие определяется с помощью оценки подобия между векторными моделями расширенных терминов и содержанием сайта. Расширенные термины анализируются из поискового сервера ввиду высокой частоты появления терминов в архивных запросах и определяются как семантически и/или контекстуально подобные термину(ам) предложения цены. Категории подобия определяются с помощью применения обучаемой модели категоризации подобия (классификатора) к расширенным терминам и содержанию веб-сайта для определения взаимосвязанности категорий между этими вводами. Подобие имени собственного определяется с помощью оценки термина(ов) предложения цены и содержанием веб-сайта в виде базы данных имен собственных. Эти множественные измерения подобия объединяются с использованием объединенной модели классификатора релевантности, которая обучается для генерации единого значения достоверности релевантности из этих оценок ввиду порога принятия отклонения. Значение достоверности обеспечивает объективное измерение релевантности термина(ов) предложения цены веб-сайту ввиду этого множества различных измерений подобия. Эти и другие аспекты систем и способов для проверки релевантности между терминами и содержанием веб-сайта описаны ниже более подробно. Примерная система для редакционной проверки На чертежах, где одинаковые ссылочные позиции относятся к одинаковым элементам, системы и способы для проверки релевантности между терминами и содержанием веб-сайта описаны и показаны как осуществляемые в подходящей компьютерной среде редакционной проверки. Хотя это и не требуется, изобретение описано в общем контексте компьютерно-выполнимых команд (программных модулей), исполняемых персональным компьютером. Программные модули, в общем случае, включают подпрограммы, программы, объекты, компоненты, структуры данных и т.д., которые выполняют конкретные задачи или реализуют некоторые абстрактные типы данных. В то время как системы и способы описаны в предшествующем контексте, действия и операции, описанные в дальнейшем, могут также быть осуществлены с помощью аппаратных средств. Пример предложенного термина поиска В ответ на получение ввода 120 предложения цены от конечного пользователя модуль 102 предложенного термина поиска генерирует список 126 предложенных терминов поиска для расширения термина(ов) 122 с помощью семантических и/или контекстуально связанных терминов. Множество смыслов или контекстов термина 122 может обеспечивать дополнительное значение термина, как описано ниже. Таблица показывает примерный список 126 предложенных терминов для терминов, связанных с термином 122 «mail» («почта»). Термины, связанные с термином 122, показаны в этом примере в столбце 1 «Предложенный термин(ы)».
Ссылаясь на таблицу, заметим, что для каждого предложенного термина (столбец 1), список 126 предложенных терминов поиска также включает соответствующее значение измерения подобия (см. столбец 2) для указания взаимосвязанности между предложенным термином(ами) и термином(ами) 122 и соответствующей частоты оценки использования (см. столбец 3) для обеспечения индикации того, как часто предложенный термин(ы) столбца 1 был представлен поисковому серверу 106. В этом примере каждое значение подобия столбца 2 обеспечивает меру подобия или оценку между соответствующим предложенным термином (столбец 1) и термином(ами) 122 предложения цены, которым является «mail» в этом примере. Каждое значение частоты или оценки, указывает то количество раз, которое предложенный термин использовался конкретным поисковым сервером 106 в запросе поиска конечного пользователя. Для представления конечному пользователю список 126 предложенных терминов сортируется как функция целей бизнеса, например предложенный(ые) термин(ы), подобие, и/или оценки частоты. Любой данный термин 122 (например, mail, и т.д.) может иметь более чем один контекст, в пределах которого может использоваться термин предложения цены. Для учета этого модуля 110 предложения термина поиска разделяет предложенный термин(ы) по контексту. Например, в таблице 1 термин 122 «mail» имеет два контекста: (1) традиционная почта и (2) электронная почта. Заметим, что соответствующий (выделенный или независимый) список предложенных терминов показан для каждого из этих двух контекстов термина предложения цены. Предложенный термин списка 126 предложенных терминов может быть больше чем синонимы термина 122. Например, согласно таблице, предложенный термин «usps» является акронимом для организации, которая обрабатывает почту, не синонимом для термина «mail» предложения цены. Однако «usps» также является термином, контекстуально весьма связанным с термином «mail» предложения цены, и таким образом, показан в списке 126 предложенных терминов. В одном осуществлении, модуль 110 предложения термина поиска 110 определяет отношение между связанным термином R (например, «usps») и целевым термином T (например, «mail») как функцию следующего ассоциативного правила: itr(T) Для генерации списка 126 предложенных терминов поиска модуль 110 предложения термина поиска посылает выбранные одни из архивных запросов, полученные из журнала 130 регистрации запросов 130, на поисковый сервер 106. Выбранные одни из архивных запросов для представления поисковому серверу 105 идентифицируются модулем 126 предложения термина поиска как имеющий существенно высокую частоту появления (FOO) по сравнению с другими одними из архивных запросов терминов, полученных из журнала 130 регистрации запросов. В этом осуществлении, используется конфигурированное пороговое значение для определения, имеет ли архивный запрос относительно высокую или низкую частоту появления. Например, термины архивных запросов, которые появляются, по меньшей мере, пороговое количество раз, оцениваются как имеющие высокую частоту появления. Аналогично, термины архивных запросов, которые появляются менее чем пороговое число раз, оцениваются как имеющие низкую частоту появления. Для целей иллюстрации, такое пороговое значение показано как соответствующая часть «других данных» 132. Термины запросов с высокой и низкой FOO показаны как часть «запросов высокой/низкой FOO» «других данных» 132. Модуль 110 предложения термина поиска извлекает набор признаков или описаний фрагментов из выбранных одних из возвращенных результатов поиска (например, одного или более результатов поиска высокого ранга) для каждого термина запроса. Модуль 110 предложения термина поиска выполняет операции предварительной обработки текста над извлеченными данными для генерации индивидуальных лексем термина. Для уменьшения размерности лексем модуль 110 предложения термина поиска удаляет любые стоп-слова (например, Вес для j-го вектора i-го термина рассчитывается следующим образом:
где TFij представляет частоту термина (число появлений термина j в i-ой записи), N – общее количество терминов запроса и DFj – число записей, которые содержат термин j. Модуль 110 предложения термина поиска использует эти соответствующие веса для группы подобных терминов группы и контекста из STS векторов 134 для генерации кластеров 136 терминов. С этой целью и в этом осуществлении, учитывая векторное представление каждого термина, используется функция косинуса для измерения подобия между парой терминов (напоминаем, что термины были нормализованы):
Таким образом, расстояние (мера сходства) между двумя терминами (измерение подобия) определяется как: dist(qj, qk) = 1-sim(qj, qk) Такие измерения подобия предложенного термина поиска (STS) показаны как соответствующая часть «других данных» 132. Примеры таких значений подобия показаны выше в примерном списке 126 предложенных терминов таблицы. Модуль 110 предложения термина поиска использует рассчитанное(ые) измерение(я) подобия термина для терминов кластера/группы в STS-векторах 134 для основанной на термине архивного запроса с высокой FOO части кластера(ов) 136 термина. Более подробно, и в этом осуществлении, модуль 110 предложения термина поиска использует известный алгоритм кластеризации на основе плотности (DBSCAN) для генерации кластера(ов) 136 этих терминов. DBSCAN использует два параметра: Eps и MinPts. Eps представляет собой максимальное расстояние между точками в кластерах 136 терминов. Точка является вектором признаков термина. В многомерном пространстве векторы эквивалентны точкам. MinPts представляет минимальное число точек в кластере 136 терминов. Для генерации кластера 136, DBSCAN начинает с произвольной точки p и отыскивает все точки, доступные по плотности из p по отношению к Eps и MinPts. Если p является основной точкой, эта операция выдает кластер 136 терминов по отношению к Eps и MinPts. Если p является граничной точкой, никакие точки не являются доступными по плотности из p, и DBSCAN переходит к следующей точке. Модуль 110 предложения термина поиска после этого сравнивает термин(ы) 122 с соответствующим(и) термином(ами) в кластере 136 терминов. Так как кластеры терминов включают в себя признаки, которые семантически и/или контекстуально связаны друг с другом, термин(ы) 122 оценивается(ются) в виде множества связанных контекстов или «смыслов» для расширения термина(ов) 122, и таким образом обеспечение генерации списка 126 предложенных терминов поиска. В одном осуществлении, если модуль 110 предложения термина поиска решает, что термин(ы) 122 отличается(ются) от термина(ов) не более чем из одного кластера 136, модуль 110 предложения термина поиска генерирует список 126 предложенных терминов из единственного кластера 136. В этом осуществлении соответствие может быть точным соответствием или соответствием с небольшим числом вариаций типа сингулярных/множественных форм, орфографических ошибок, знаков препинания, и т.д. Сформированный список терминов упорядочивается в соответствии с некоторыми критериями, которые, например, могли быть линейной комбинацией FOO и подобия между термином(ами) 122 и предложенными терминами, как: Score( qi ) = где Если модуль 110 предложенных терминов поиска решает, что термин(ы) 122 совпадает с термином(ами) в множестве кластеров 136 терминов, модуль 110 предложения термина поиска генерирует список 126 предложенных терминов из терминов множества кластеров терминов. Предложенные термины из каждого кластера упорядочиваются с использованием того же самого метода, что и описанный выше. Примерная система и способ для модуля 110 предложения термина поиска для генерации списка 126 предложенных терминов поиска описаны в патентной заявке США Примерная проверка релевантности Prop_Sim(term, page) = 1 – если term содержит имя собственное P, и page содержит соответствующее имя собственное Q. 0 – term содержит имя собственное P, и page содержит только несоответствующее имя(ена) собственное Q. 0,5 – Иначе. Имя собственное является согласованным с самим собой и с его предками. Например, географическое местоположение нижнего уровня является согласованным с географическим местоположением высокого уровня, которое содержит его, например Милан является согласованным с Италией. Примерное автономное обучение классификатора подобия Модуль 112 проверки релевантности обучает классификатор 142 подобия как Модуль 112 проверки релевантности применяет простую предварительную обработку текста для генерации лингвистических лексем (то есть, размечает индивидуальные термины) из извлеченных признаков/данных. Чтобы уменьшать размерность лексем, модуль 112 проверки релевантности удаляет любые слова останова и удаляет общие суффиксы для нормализации терминов, например, используя известный алгоритм морфологического поиска Портера. Модуль 112 проверки релевантности упорядочивает результирующие извлеченные признаки в один или более векторов терминов проверки релевантности (RV) (то есть, RV-векторы 134). Также, каждая Web-страница представлена как вектор признаков, элементом которого является слово с его взвешиванием xi=
где d представляет собой оригинал документа, t представляет термин, fx,t представляет частоту термина t в x,idft представляет инвертированную частоту документа термина t, dlbx представляет число уникальных терминов в x, avefx представляет среднее число частот терминов в x, и avedlb представляет среднее число dlbx в совокупности. Операции выбора признаков модуля 112 проверки релевантности дополнительно уменьшает признаки RV-векторов 134 (слишком много признаков может ухудшить производительность и точность системы классификации). В этом осуществлении, способ выбора информационного выигрыша (IG) используется для выбора признака. Информационный выигрыш термина измеряет число битов информации, полученной для предсказания категории присутствием или отсутствием термина в документе следующим образом:
где t представляет термин, c представляет категорию, и m представляет общее количество категорий. Также могут использоваться другие способы выбора признаков, типа взаимной информации (МИ), частоты документа (DF) и линейный дискриминантный анализ (LDA). В этом осуществлении, операции обучения классификатора модуля 112 проверки релевантности используют статистическую модель n-граммы, основанной на упрощенном байесовом классификаторе (n-грамма), хотя могут использоваться другие типы классификаторов. В частности, отличный от упрощенного байесова классификатора статистическая модель n-граммы не предполагает независимости от потока слов. Это предлагает независимость марковской n-граммы, то есть одно слово зависит от предыдущих n-1 слов согласно:
Прямая оценка этой вероятности из совокупности обучения задается наблюдаемой частотой:
Большинство из
где
является игнорируемой условной вероятностью и
Есть несколько алгоритмов для вычисления игнорируемой условной вероятности. В этом осуществлении «абсолютное сглаживание» используется следующим образом:
где
и является числом слов, которые возникают точно
В этом осуществлении n=3, и классификатор n-граммы называется 3-граммовым классификатором. Экспертная комбинация измерений подобия Измерения 140 RV-подобия обрабатываются как вектор признаков для ввода 120 предложения цены (то есть пара <термин, страница>). Для целей иллюстрации и обсуждения, измерения RV-подобия (SM) как вектора(ов) признаков показаны как вектор(ы) 140 признаков RVSM. Мы имеем следующие вычисления ввода 120 предложения цены и измерения 140 RV-подобия: Модуль 112 проверки релевантности применяет вектор(ы) 140 признаков RVSM из <термин, запрос> к объединенному классификатору 144 релевантности для отображения множества значений 140 RV-подобия ввиду порога релевантности отклонения/приема для вычисления соответствующих весов типа RV-подобия (то есть содержание, расширенное, категория и надлежащие типы измерения подобия) и конечного значения 138 достоверности. Классификация терминов с низким значением FOO В этом осуществлении для классификации кластера 136 терминов неизвестного класса, модуль 114 классификации использует алгоритм классификатора k – ближайшего соседа для ранжирования соседей кластера неизвестного класса среди векторов терминов, и использует метки класса для k наиболее подобных соседей для предсказания класса термина неизвестного класса. Классы этих соседей взвешиваются с использованием подобия каждого соседа элементу X, где подобие измерено евклидовым расстоянием или значением косинуса между двумя векторами документа. Подобие косинуса выражается следующим образом:
где X – испытываемый документ, представленный как вектор; Dj является j-ым обучающим документом; ti – слово, совместно используемое в X и Dj; xi – вес термина ti в X; dij – вес термина ti в документе Dj; В другом осуществлении для генерации обучаемого классификатора STS используются различные статистические классификации и методы машинного обучения (например, включая регрессивные модели, байесовы классификаторы, деревья решения, нейронные сети, и машины с поддержкой векторов), отличные от метода классификации ближайшего соседа. Модуль 114 классификации передает термины запроса с низкой частотой появления (FOO) (см. части терминов запросов с высокой/низкой частотой «других данных» 132) один за другим поисковому серверу 106. В ответ на получение соответствующего результата поиска для каждого запроса, переданного поисковому серверу, и с использованием уже описанных способов, модуль 114 классификации выделяет признаки, такие как отрывки описания из каждой из найденных веб-страниц, идентифицированной в результатах поиска. В этом осуществлении, признаки извлекаются из первой по рангу веб-страницы. Эти выделенные признаки представлены в соответствующей части «других данных» 132. В другом осуществлении, признаки выделяются из множества веб-страниц верхнего ранга. Для каждой найденной и проанализированной веб-страницы модуль 114 классификации сохраняет следующую информацию в соответствующей записи извлеченных признаков: описание отрывка, поисковый запрос, использованный для получения найденной веб-страницы, и универсальный идентификатор ресурса (URI) найденной веб-страницы. Затем, модуль 114 классификации маркирует, уменьшает размерность и нормализует извлеченные признаки 138, полученные из терминов запроса с низкой FOO для генерации другого набора векторов терминов (то есть векторов STS 134). Классификация 114 кластеризует термин(ы) в векторах STS 134 в соответствующий набор кластеров 136 терминов, которые являются кластерами, основанными на терминах запросов с низкой FOO. Эта операция кластеризации выполняется с использованием обученного классификатора 148 STS, который, как описано выше, был сформирован из терминов запросов с высокой FOO. Модуль 114 классификации оценивает термин(ы) ввиду этих кластеров терминов для идентификации и возврата списка 126 предложенных терминов, включающего эти другие термины, конечному пользователю. Примерная процедура сравнения терминов
где fCommon представляет число общих терминов, и fDistance представляет число раз, когда термины 122 предложения цены были обменены на термины запроса 152. Примерная процедура Фиг.2 иллюстрирует примерную процедуру 200 для проверки релевантности содержания веб-сайта терминам. Для целей обсуждения, операции процедуры описываются для компонентов, представленных на фиг.1. (Все ссылочные позиции начинаются с номера чертежа, на котором компонент представлен в первый раз). В блоке 202, модуль 110 предложения термина поиска генерирует первый набор кластеров 136 терминов из результатов поиска поискового сервера 106. Для целей обсуждения, такие результаты поиска показываются как соответствующая часть «других данных» 132. Чтобы получить результаты поиска, модуль 110 предложения терминов поиска передает архивные запросы с высокой частотой появления, полученные из журнала 130 регистрации запросов. Кластеры 136 терминов включают описания отрывков, соответствующие запросы на поиск, и веб-страницы, определенные модулем 110 предложения терминов поиска как семантически и/или контекстуально связанные с переданными архивными запросами с высокой частотой появления. В блоке 208, если модуль 112 проверки релевантности решает, что значение 138 достоверности приемлемо (не слишком низко ввиду порога принятия/отклонения), процедура переходит к блоку 302 фиг.3, как обозначено постраничной ссылкой «A». Примерная операционная среда Фиг.4 иллюстрирует пример подходящей компьютерной среды 400, на которой система 100 по фиг.1 и методология по фиг.2 и 3 для проверки релевантности между терминами и содержанием веб-сайта могут быть полностью или частично осуществлены. Примерная компьютерная среда 400 является только одним примером подходящей компьютерной среды и не предусматривает каких-либо ограничений относительно объема использования или функциональных возможностей систем и способов, описанных здесь. Компьютерная среда 400 не должна интерпретироваться как имеющая какую-либо зависимость или требование, касающиеся любого одного или комбинации компонентов, проиллюстрированных в компьютерной среде 400. Способы и системы, описанные здесь, могут быть реализованы с множеством других универсальных или специализированных компьютерных системных сред или конфигураций. Примеры известных компьютерных систем, сред и/или конфигураций, которые могут быть подходящими для использования, включают, но не ограничены этим, персональные компьютеры, серверные компьютеры, многопроцессорные системы, системы на основе микропроцессора, сетевые PC, мини-компьютеры, универсальные компьютеры, распределенные компьютерные среды, которые включают любую из вышеупомянутых систем или устройств, и так далее. Компактные или сокращенные версии структуры могут также быть осуществлены на клиентах с ограниченными ресурсами, типа карманных компьютеров или других компьютерных устройств. Изобретение может быть реализовано в распределенной компьютерной среде, где задачи выполняются удаленными устройствами обработки, которые связаны посредством коммуникационной сети. В распределенной компьютерной среде программные модули могут быть расположены как в локальных, так и в удаленных запоминающих устройствах памяти. Согласно фиг.4 примерная система для проверки релевантности между терминами и содержанием веб-сайта включает в себя универсальное компьютерное устройство в форме компьютера 410. Следующие описанные аспекты компьютера 410 являются примерными реализациями сервера 102 (фиг.1) клиентского компьютерного устройства PSS и/или клиентского компьютерного устройства 106. Компоненты компьютера 410 могут включать, но не ограничены этим, процессорный модуль(и) 420, системную память 430 и системную шину 421, которая присоединяет различные системные компоненты, включая системную память, к процессорному модулю 420. Системная шина 421 может быть любой из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, использующую любую из разнообразия шинных архитектур. В качестве примера, а не ограничения, такая архитектура может включать шину архитектуры промышленного стандарта (ISA), шину микроканальной архитектуры (MCA), усовершенствованную ISA (EISA) шину, локальную шину ассоциации по стандартам в области видеоэлектроники (VESA) и Стандартную PCI шину, также известную как шина Mezzanine. Компьютер 410 обычно включает разнообразные машиночитаемые носители. Машиночитаемые носители могут быть любыми доступными носителями, к которым может обращаться компьютер 410, и включают энергозависимые и энергонезависимые носители, сменные и несменные носители. В качестве примера, но не ограничения, машиночитаемые носители могут включать компьютерные носители данных и среду передачи. Компьютерные носители данных включают энергозависимые и энергонезависимые, сменные и несменные носители, осуществленные любым способом или технологией для хранения информации, такой как читаемые компьютером команды, структуры данных, программные модули или другие данные. Компьютерные носители данных включают, но не ограничены этим, оперативную память, постоянную память, электронно-перепрограммируемую постоянную память, флэш-память или другую технологию памяти, CD-ROM, цифровые универсальные диски (DVD) или другую оптическую память на диске, магнитные кассеты, магнитную ленту, магнитную память на диске или другие магнитные запоминающие устройства, или любой другой носитель информации, который может использоваться для хранения желательной информации и к которой может обращаться компьютер 410. Среда передачи обычно воплощает читаемые компьютером команды, структуры данных, программные модули или другие данные в модулируемом сигнале данных типа несущего колебания или другого транспортного механизма и включают любые среды доставки информации. Термин «модулированный сигнал данных» означает сигнал, который имеет одну или более из его набора характеристик установленной или измененной таким способом, чтобы закодировать информацию в сигнале. В качестве примера, но не ограничения среды передачи включают проводные среды передачи типа проводной сети или непосредственного прямого подключения, и беспроводные среды передачи типа акустических, радиочастотных, инфракрасных и других беспроводных сред передачи. Комбинации любого из вышеупомянутых должны также быть включены в объем машиночитаемых носителей. Системная память 430 включает компьютерные носители данных в форме энергозависимой и/или энергонезависимой памяти типа постоянного запоминающего устройства 431 (ROM) и оперативной памяти 432 (RAM). Базовая система 433 ввода-вывода (BIOS), содержащая основные подпрограммы, которые помогают передавать информацию между элементами в компьютере 410, например во время запуска, обычно сохраняется в ROM 431. Оперативная память 432 обычно содержит данные и/или программные модули, которые являются немедленно доступными для процессорного модуля 420 и/или могут быть обработаны процессорным модулем 420. В качестве примера, но не ограничения, фиг.4 иллюстрирует операционную систему 434, прикладные программы 435, другие программные модули 436 и программные данные 437. В одном осуществлении, прикладные программы 435 включают в себя программные модули 108 по фиг.1. В том же самом сценарии, программные данные 437 включают программные данные 128 по фиг.1. Компьютер 410 может также включать другие сменные/несменные, энергозависимые/энергонезависимые компьютерные носители данных. Только в качестве примера, фиг.4 иллюстрирует дисковод 441 жестких дисков, который читает или пишет на несменные, энергонезависимые магнитные носители, дисковод 451 магнитных дисков, который читает или пишет на сменный, энергонезависимый магнитный диск 452, и дисковод 455 оптических дисков, который читает или пишет на сменный, энергонезависимый оптический диск 456 типа CD-ROM или другой оптический носитель. Другие сменные/несменные, энергозависимые/энергонезависимые компьютерные носители данных, которые могут использоваться в примерной среде, включают, но не ограничены этим, кассеты магнитной ленты, платы флэш-памяти, цифровые универсальные диски, цифровую видеоленту, оперативную твердотельную память, твердотельную ROM и т.п. Дисковод 441 жестких дисков обычно подключается к системной шине 421 через интерфейс несменной памяти типа интерфейса 440 и дисковод 451 магнитных дисков, и дисковод 455 оптических дисков обычно подключаются к системной шине 421 посредством интерфейса сменной памяти типа интерфейса 450. Дисководы и связанные с ними компьютерные носители данных, обсужденные выше и проиллюстрированные на фиг.4, обеспечивают хранение читаемых компьютером команд, структур данных, программных модулей и других данных для компьютера 410. На фиг.4, например, дисковод 441 жестких дисков проиллюстрирован как хранилище операционной системы 444, прикладных программ 445, других программных модулей 446 и программных данных 447. Эти компоненты могут или быть теми же самыми или отличными от операционной системы 434, прикладных программ 435, других программных модулей 436 и программных данных 437. Операционная система 444, прикладные программы 445, другие программные модули 446 и программные данные 447 здесь обозначены другими номерами, чтобы проиллюстрировать то, что они являются, по меньшей мере, отличающимися копиями. Пользователь может ввести команды и информацию в компьютер 410 через устройства ввода данных типа клавиатуры 462 и координатно-указательного устройства 461, обычно называемого мышью, трекболом или сенсорной клавиатурой. Другие устройства ввода данных (не показанные здесь) могут включать микрофон, джойстик, игровую клавиатуру, спутниковую антенну, сканер или подобные им. Эти и другие устройства ввода данных часто подключаются к процессорному модулю 420 через интерфейс 460 пользовательского ввода, который соединен с системной шиной 421, но может быть связан другим интерфейсом и шинными структурами типа параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 491 или другой тип устройства отображения также связан с системной шиной 421 через интерфейс, типа видеоинтерфейса 490. В дополнение к монитору, компьютеры могут также включать другие периферийные устройства вывода типа динамиков 497 и принтера 496, которые могут быть связаны через внешний интерфейс 495 вывода. Компьютер 410 работает в сетевой среде, используя логические соединения с одним или более удаленными компьютерами типа удаленного компьютера 480. Удаленный компьютер 480 может быть персональным компьютером, сервером, маршрутизатором, сетевым PC, одноранговым устройством или другим обычным сетевым узлом, и соответственно функции его конкретного воплощения, может включать в себя многие или все элементы, описанные выше для компьютера 410, хотя на фиг.4 проиллюстрировано только запоминающее устройство памяти 481. Логические соединения, изображенные на фиг.4, включают локальную сеть 471 (LAN) и глобальную сеть (WAN) 473, но могут также включать другие сети. Такие сетевые среды являются обычными в офисах, компьютерных сетях масштаба предприятия, интранет и Интернет. При использовании в сетевой среде LAN компьютер 410 связан с LAN 471 через сетевой интерфейс или адаптер 470. При использовании в сетевой среде WAN компьютер 410 обычно содержит модем 472 или другие средства для установления связи по глобальной сети WAN 473, типа сети Интернет. Модем 472, который может быть внутренним или внешним, может быть связан с системной шиной 421 через интерфейс 460 пользовательского ввода или другой соответствующий механизм. В сетевой среде программные модули, изображенные для компьютера 410, или его частей, могут быть сохранены в удаленном запоминающем устройстве памяти. В качестве примера, но не ограничения, фиг.4 иллюстрирует удаленные прикладные программы 485 как постоянно находящиеся в устройстве памяти 481. Показанные сетевые соединения приведены в качестве примера и могут использоваться другие средства установления связи между компьютерами. Заключение Хотя системы и способы для проверки релевантности между терминами и содержанием веб-сайта описаны на языке, специфическом для структурных признаков и/или методологических операций или действий, понятно, что варианты осуществления, определенные в прилагаемой формуле изобретения, не обязательно ограничены конкретными признаками или описанными действиями. Соответственно, конкретные признаки и действия раскрыты как примерные формы реализации заявленного изобретения.
Формула изобретения
1. Способ проверки релевантности между терминами и содержанием веб-сайта, причем способ заключается в том, что: формулируют расширенный(ые) термин(ы), семантически и/или контекстуально связанный(ые) с термином(ами) предложения, которые извлечены из поисковой машины, принимая во внимание высокую частоту появления терминов архивных запросов; 2. Способ по п.1, в котором классификатор подобия основан на статистической основанной на n-грамме упрощенной байесовой модели (N-грамма), упрощенной байесовой модели (NB), машине с векторной поддержкой (SVM), ближайшем соседе (KNN), дереве решения, сообучении или увеличивающей модели классификации. 3. Способ по п.1, в котором формулировка расширенных терминов дополнительно содержит генерацию кластеров терминов из векторов терминов на основе вычисленного подобия термина, причем векторы терминов генерируются из архивных запросов, каждый архивный запрос имеет высокую частоту появления, и кластеры терминов включают в себя расширенные термины. 4. Способ по п.1, в котором генерация измерений подобия содержания дополнительно содержит генерацию соответствующих векторов терминов из термина(ов) предложений и содержания сайта и вычисление подобия между соответствующими векторами терминов для определения прямого подобия между термином(ами) предложения и содержанием сайта. 5. Способ по п.1, в котором генерация измерений расширенного подобия дополнительно содержит этапы: 6. Способ по п.1, в котором вычисление значения достоверности дополнительно содержит этапы: 7. Способ по п.1, дополнительно содержащий этапы: в ответ на получение запроса поиска определяют, релевантны ли термины запроса поиска термину(ам) предложения ввиду возможности того, что термины запроса поиска могут не точно соответствовать термину(ам) предложения; и 8. Способ по п.1, дополнительно содержащий этапы: 9. Способ по п.8, в котором определение измерений подобия имени собственного дополнительно включает этапы: 10. Способ по п.1, дополнительно содержащий этапы: 11. Способ по п.10, в котором идентификация дополнительно содержит этапы: 12. Машиночитаемый носитель информации, содержащий выполняемые компьютером команды для проверки релевантности между терминами и содержанием веб-сайта, при этом выполняемые компьютером команды содержат команды для: формулировки расширенного(ых) термина(ов), семантически и/или контекстуально связанного(ых) с термином(ами) предложения, которые извлечены из поисковой машины, принимая во внимание высокую частоту появления терминов архивных запросов; 13. Машиночитаемый носитель информации по п.12, в котором классификатор подобия основан на статистической основанной на n-грамме упрощенной байесовой модели (N-грамма), упрощенной байесовой модели (NB), машине с векторной поддержкой (SVM), ближайшем соседе (KNN), дереве решения, сообучении или увеличивающей модели классификации. 14. Машиночитаемый носитель информации по п.12, в котором выполняемые компьютером команды для формулирования расширенных терминов дополнительно содержат команды для генерации кластеров терминов из векторов терминов на основе вычисленного подобия терминов, причем векторы терминов генерируются из архивных запросов, каждый архивный запрос имеет высокую частоту появления, и кластеры терминов содержат расширенные термины. 15. Машиночитаемый носитель информации по п.12, в котором выполняемые компьютером команды для генерации измерений подобия содержания дополнительно содержат команды для генерации соответствующих векторов терминов из термина(ов) предложений и содержания сайта и вычисления подобия между соответствующими векторами терминов для определения прямого подобия между термином(ами) предложения и содержанием сайта. 16. Машиночитаемый носитель информации по п.12, в котором выполняемые компьютером команды для генерации измерений расширенного подобия дополнительно содержат команды для: 17. Машиночитаемый носитель информации по п.12, в котором выполняемые компьютером команды для вычисления значения достоверности дополнительно содержат команды для: 18. Машиночитаемый носитель информации по п.12, в котором выполняемые компьютером команды дополнительно содержат команды для: определения в ответ на получение запроса поиска релевантны ли термины запроса поиска термину(ам) предложения, ввиду возможности того, что термины запроса поиска могут не точно соответствовать термину(ам) предложения; и 19. Машиночитаемый носитель информации по п.12, в котором выполняемые компьютером команды дополнительно содержат команды для: 20. Машиночитаемый носитель информации по п.19, в котором выполняемые компьютером команды для определения измерений подобия имени собственного дополнительно содержат команды для: 21. Машиночитаемый носитель информации по п.12, в котором выполняемые компьютером команды дополнительно содержат команды для: 22. Машиночитаемый носитель информации по п.21, в котором выполняемые компьютером команды идентификации дополнительно содержат команды для: 23. Компьютерное устройство для проверки релевантности между терминами и содержанием веб-сайта, причем компьютерное устройство содержит: формулировки расширенного(ых) термина(ов), семантически и/или контекстуально связанного(ых) с термином(ами) предложения; 24. Компьютерное устройство по п.23, в котором классификатор подобия основан на статистической основанной на n-грамме упрощенной байесовой модели (N-грамма), упрощенной байесовой модели (NB), машине с векторной поддержкой (SVM), ближайшем соседе (KNN), дереве решения, сообучении или увеличивающей модели классификации. 25. Компьютерное устройство по п.23, в котором выполняемые компьютером команды для формулирования расширенных терминов дополнительно содержат команды для генерации кластеров терминов из векторов терминов на основе вычисленного подобия терминов, причем векторы терминов генерируются из архивных запросов, каждый архивный запрос имеет высокую частоту появления, и кластеры терминов содержат расширенные термины. 26. Компьютерное устройство по п.23, в котором выполняемые компьютером команды для генерации измерений подобия содержания дополнительно содержат команды для генерации соответствующих векторов терминов из термина(ов) предложений и содержания сайта и вычисления подобия между соответствующими векторами терминов для определения прямого подобия между термином(ами) предложения и содержанием сайта. 27. Компьютерное устройство по п.23, в котором выполняемые компьютером команды для генерации измерений расширенного подобия дополнительно содержат команды для: 28. Компьютерное устройство по п.23, в котором выполняемые компьютером команды для вычисления значения достоверности дополнительно содержат команды для: 29. Компьютерное устройство по п.23, в котором выполняемые компьютером команды дополнительно содержат команды для: 30. Компьютерное устройство по п.29, в котором выполняемые компьютером команды для определения измерений подобия имени собственного дополнительно содержат команды для: 31. Компьютерное устройство по п.23, в котором выполняемые компьютером команды дополнительно содержат команды для: 32. Компьютерное устройство по п.31, в котором выполняемые компьютером команды идентификации дополнительно содержат команды для: 33. Компьютерное устройство для проверки релевантности между терминами и содержанием веб-сайта, при этом компьютерное устройство содержит: средство формулирования для идентификации расширенного(ых) термина(ов), семантически и/или контекстуально связанного(ых) с термином(ами) предложения, 34. Компьютерное устройство по п.33, в котором компьютерное средство формулирования дополнительно содержит средство генерации для создания кластеров терминов из векторов терминов на основе вычисленного подобия термина, причем вектора терминов генерируются из архивных запросов, каждый архивный запрос имеет высокую частоту появления, и кластеры терминов содержат расширенные термины. 35. Компьютерное устройство по п.33, в котором средство генерации дополнительно содержит средство создания для генерации соответствующих векторов терминов из термина(ов) предложения и содержания сайта и вычисления подобия между соответствующими векторами терминов для определения прямого подобия между термином(ами) предложения и содержанием сайта. 36. Компьютерное устройство по п.33, в котором средство генерации дополнительно содержит: 37. Компьютерное устройство по п.33, в котором средство вычисления дополнительно содержит: 38. Компьютерное устройство по п.33, дополнительно содержащее: 39. Компьютерное устройство по п.38, в котором средство определения для определения измерений подобия имени собственного дополнительно содержит в ответ на обнаружение имени собственного, содержащего, по меньшей мере, одно из термина(ов) предложения и содержания сайта, средство вычисления для вычисления оценки подобия имени собственного. 40. Компьютерное устройство по п.33, дополнительно содержащее: 41. Компьютерное устройство по п.40, в котором средство идентификации дополнительно содержит:
РИСУНКИ
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
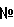 595
595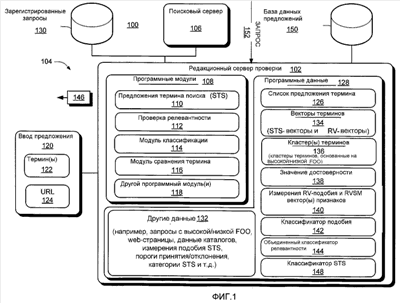

 itr(R), где «itr» представляет собой «заинтересованный в». То есть, если конечный пользователь (рекламодатель, промоутер веб-сайта и/или подобный им) заинтересован в R, то конечный пользователь будет, вероятно, также заинтересован в T.
itr(R), где «itr» представляет собой «заинтересованный в». То есть, если конечный пользователь (рекламодатель, промоутер веб-сайта и/или подобный им) заинтересован в R, то конечный пользователь будет, вероятно, также заинтересован в T. the
the ,
, 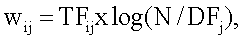
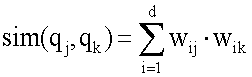
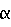 FOO(qi) +
FOO(qi) +  sim(qi, Q),
sim(qi, Q),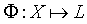 на данных каталога (см. «другие данные» 132), где X является вводом (строковый поток с масштабом от одного термина до содержаний нескольких веб-страниц), и L является выводом (вероятность по всем уровням top2 категорий). Таксономия категории имеет иерархическую структуру. В этом осуществлении мы используем категории 2-го уровня данных каталога LookSmart®, сумма этих категорий является некоторым числом (например, 74) для классификации. Модуль 112 проверки релевантности выполняет операции выделения признаков и выбора признаков на данных каталога. Более подробно, модуль 112 проверки релевантности выделяет отрывки описаний (извлеченные данные) из веб-страниц(ы), идентифицированной(ыми) данными каталога. Веб-страница(ы) извлекается(ются), например, модулем «червяка» веб-страниц, представленный с соответствующей частью «другого(их) программного(ых) модуля(ей)» 118. Каждый отрывок описаний для конкретной веб-страницы включает, например, один или более заголовков, метаданные, тело, привязку текста, размер шрифта, гиперсвязи, изображения, необработанный HTML (например, резюмирование и информация о компоновке страницы) и/или подобное этому.
на данных каталога (см. «другие данные» 132), где X является вводом (строковый поток с масштабом от одного термина до содержаний нескольких веб-страниц), и L является выводом (вероятность по всем уровням top2 категорий). Таксономия категории имеет иерархическую структуру. В этом осуществлении мы используем категории 2-го уровня данных каталога LookSmart®, сумма этих категорий является некоторым числом (например, 74) для классификации. Модуль 112 проверки релевантности выполняет операции выделения признаков и выбора признаков на данных каталога. Более подробно, модуль 112 проверки релевантности выделяет отрывки описаний (извлеченные данные) из веб-страниц(ы), идентифицированной(ыми) данными каталога. Веб-страница(ы) извлекается(ются), например, модулем «червяка» веб-страниц, представленный с соответствующей частью «другого(их) программного(ых) модуля(ей)» 118. Каждый отрывок описаний для конкретной веб-страницы включает, например, один или более заголовков, метаданные, тело, привязку текста, размер шрифта, гиперсвязи, изображения, необработанный HTML (например, резюмирование и информация о компоновке страницы) и/или подобное этому. xin>, взвешивание xij рассчитывается путем нормализации по длине log(tf).idf в форме:
xin>, взвешивание xij рассчитывается путем нормализации по длине log(tf).idf в форме: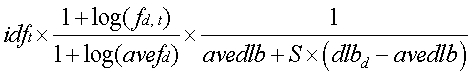
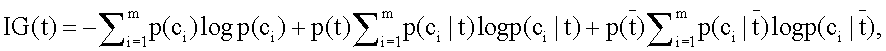
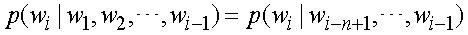
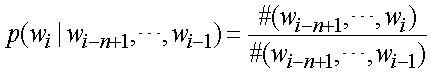
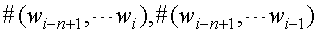 значений является нулевым в данных обучения. Поэтому предложена технология сглаживания для оценки нулевой вероятности для обработки любой разреженности данных. Модель n-граммы с выдержкой является одним из способов решения этой проблемы следующим образом:
значений является нулевым в данных обучения. Поэтому предложена технология сглаживания для оценки нулевой вероятности для обработки любой разреженности данных. Модель n-граммы с выдержкой является одним из способов решения этой проблемы следующим образом: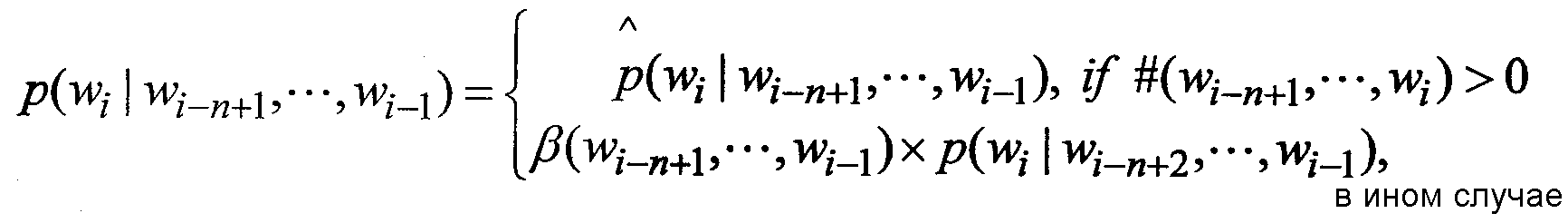
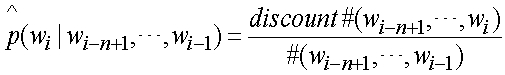
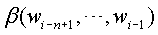 является фактором выдержки для сдвига n-граммы к (n-1)-грамме:
является фактором выдержки для сдвига n-граммы к (n-1)-грамме: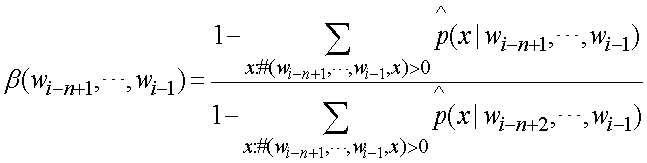
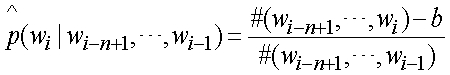
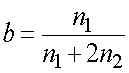
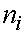
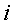 раз в данных обучения. Таким образом, мы можем изменить NB классификатор как классификатор n-граммы:
раз в данных обучения. Таким образом, мы можем изменить NB классификатор как классификатор n-граммы: