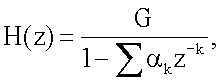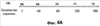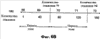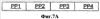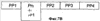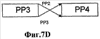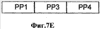Патент на изобретение №2371784
|
||||||||||||||||||||||||||
(54) ИЗМЕНЕНИЕ МАСШТАБА ВРЕМЕНИ КАДРОВ В ВОКОДЕРЕ ПОСРЕДСТВОМ ИЗМЕНЕНИЯ ОСТАТКА
(57) Реферат:
Изобретение относится к передаче речи, в частности, к способу изменения масштаба времени вокодерных кадров в вокодере. Технический результат – повышение точности кодирования речевых данных. Изобретение содержит вокодер, имеющий, по меньшей мере, один вход и, по меньшей мере, один выход, кодер, содержащий фильтр, имеющий, по меньшей мере, один вход, функционально связанный с входом вокодера, и, по меньшей мере, один выход, декодер, содержащий синтезатор, имеющий, по меньшей мере, один вход, функционально связанный с, по меньшей мере, одним выходом кодера, и, по меньшей мере, один выход, функционально связанный с, по меньшей мере, одним выходом вокодера, при этом кодер содержит память и кодер выполнен с возможностью выполнения команд, сохраненных в памяти, содержащих классификацию речевых сегментов и кодирование речевых сегментов, и декодер содержит память, и декодер выполнен с возможностью выполнения команд, сохраненных в памяти, содержащих изменение масштаба времени остаточного речевого сигнала к расширенному или сжатому виду остаточного речевого сигнала. 4 н. и 41 з.п. ф-лы, 17 ил.
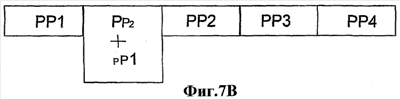
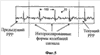
Заявление на приоритет Эта заявка заявляет приоритет по предварительной заявке Область техники Настоящее изобретение относится в целом к способу изменения масштаба времени (расширения или сжатия) вокодерных кадров в вокодере. Изменение масштаба времени имеет ряд применений в сетях с переключением пакетов, где пакеты вокодера могут поступать асинхронно. Пока может выполняться изменение масштаба времени в вокодере или вне вокодера, выполняя его в вокодере, предоставляется ряд преимуществ, таких как лучшее качество кадров, подвергшихся изменению масштаба времени, и уменьшение вычислительной нагрузки. Способы, представленные в документах, могут применяться в любом вокодере, который использует похожие методы, о которых идет речь в этой заявке на патент для вокодерных голосовых данных. Уровень техники Настоящее изобретение содержит устройство и способ для изменения масштаба времени речевых кадров посредством манипуляции речевым сигналом. В одном варианте осуществления настоящий способ и устройство используются в, но не ограничивая, Четвертом Генерирующем Вокодере (4ГВ) (4GV). Описанные варианты осуществления содержат способы и устройства для расширения/сжатия различных типов речевых сегментов. Сущность изобретения В связи с вышеизложенным описанные признаки настоящего изобретения в целом относятся к одной или более улучшенным системам, способам и/или устройствам для передачи речи. В одном варианте осуществления настоящее изобретение содержит способ передачи речи, содержащий этапы на которых классифицируют речевые сегменты, кодируют речевые сегменты, используя линейное предсказание с кодовым возбуждением, и изменяют масштаб времени остаточного речевого сигнала к расширенному или сжатому виду остаточного речевого сигнала. В другом варианте осуществления способ передачи речи дополнительно содержит отправку речевого сигнала через кодирующий фильтр с линейным предсказанием, посредством чего фильтруя кратковременные корреляции в речевом сигнале и выдавая коэффициенты кодирования с линейным предсказанием и остаточный сигнал. В другом варианте осуществления кодирование является кодированием с линейным предсказанием с кодовым возбуждением и этап изменения масштаба времени содержит оценку задержки тона, разделение речевого кадра на периоды тона, при этом границы периодов тона определяются с использованием задержки тона в различных точках речевого кадра, совмещение периодов тона, если сжимается остаточный речевой сигнал, и добавление периодов тона, если расширяется остаточный речевой сигнал. В другом варианте осуществления кодирование является кодированием периода тона образца и этап изменения масштаба времени содержит оценку по меньшей мере одного периода тона, интерполяцию по меньшей мере одного периода тона, добавление по меньшей мере одного периода тона, когда расширяют остаточный речевой сигнал, и выделение по меньшей мере одного периода тона, когда сжимают остаточный речевой сигнал. В другом варианте осуществления кодированием является кодирование с линейным предсказанием с шумовым возбуждением и этап изменения масштаба времени содержит применение возможных различных коэффициентов усилений к различным частям речевого сегмента до его синтеза. В другом варианте осуществления настоящее изобретение содержит вокодер, имеющий по меньшей мере один вход и по меньшей мере один выход, кодер включает в себя фильтр, имеющий по меньшей мере один вход, функционально связанный с входом вокодера, и по меньшей мере один выход, декодер, включающий в себя синтезатор, имеющий по меньшей мере один вход, функционально связанный с по меньшей мере одним выходом упомянутого кодера, и по меньшей мере один выход, функционально связанный с по меньшей мере одним выходом упомянутого вокодера. В другом варианте осуществления кодер содержит память, при этом кодер выполнен с возможностью исполнения команд, сохраненных в памяти, содержащих классификацию речевых сегментов по 1/8 кадра, период тона образца, линейное предсказание с кодовым возбуждением или линейное предсказание с шумовым возбуждением. В другом варианте осуществления декодер содержит память и декодер выполнен с возможностью исполнения команд, сохраненных в памяти, содержащих изменение масштаба времени остаточного сигнала к расширенному или сжатому виду остаточного сигнала. Кроме того, объем применения настоящего изобретения станет очевидным из последующего подробного описания, формулы и чертежей. Однако будет понятно, что подробное описание и конкретные примеры, несмотря на то, что показывают предпочтительные варианты осуществления изобретения, даются только для иллюстрации, поскольку различные изменения и модификации в сущности и объеме изобретения станут очевидными для специалиста в уровне техники. Краткое описание чертежей Настоящее изобретение станет более понятным из подробного описания, данного здесь ниже, приложенной формулы и сопровождающих чертежей, на которых: Фиг.1 – блок-схема Кодирующего вокодера с Линейным Предсказанием (КЛП) (LPC); Фиг.2а – речевой сигнал, содержащий вокализированную речь. Фиг.2в – речевой сигнал, содержащий невокализированную речь. Фиг.2с – речевой сигнал, содержащий изменяющуюся речь. Фиг.3 – блок-схема, показывающая Фильтрацию с LPC речи, следующей за Кодированием Остатка. Фиг.4а – кривая Первоначальной Речи. Фиг.4в – кривая Остаточного Речевого Сигнала после Фильтрации c LPC. Фиг.5 показывает генерацию форм колебаний сигнала, используя Интерполяцию между Предыдущим и Текущим Периодами Тона Образца. Фиг.6а показывает определение Задержек Тона при помощи Интерполяции. Фиг.6в показывает идентификацию периодов тона. Фиг.7а представляет первоначальный речевой сигнал в форме периодов тона. Фиг.7в представляет расширенный речевой сигнал, используя совмещение-добавление. Фиг.7с представляет речевой сигнал, сжатый, используя совмещение-добавление. Фиг.7d представляет, как используется взвешивание для сжатия остаточного сигнала. Фиг.7е представляет речевой сигнал, сжатый без использования совмещения-добавления. Фиг.7f представляет, как используется взвешивание для расширения остаточного сигнала; и Фиг.8 содержит два выражения, используемые в способе добавления-совмещения. Подробное раскрытие Слово «иллюстративный» используется здесь для обозначения «служащий в качестве примера, образца или иллюстрации». Любой вариант осуществления, описанный здесь как «иллюстративный», необязательно интерпретируется как предпочтительный или преимущественный над другими вариантами осуществления. Признаки использования изменения масштаба времени в вокодере Человеческие голоса состоят из двух компонентов. Один компонент содержит основные гармоники, которые являются чувствительными к тону, и другой является фиксированными гармониками, которые не являются чувствительными к тону. Воспринимаемый тон звука является частотой, воспринимаемой ухом, т.е. для большинства конкретных целей тон является частотой. Компоненты гармоники добавляют отличительные характеристики к персональному голосу. Они изменяют также голосовые связки и физическую форму вокального тракта и называются формантами. Человеческий голос может представляться цифровым сигналом s(n) 10. Представление s(n) 10 является цифровым речевым сигналом, полученным во время обычного разговора, включающего в себя различные голосовые звуки и периоды молчания. Речевой сигнал s(n) 10 предпочтительно разделяется на кадры 20. В одном варианте осуществления s(n) 10 квантуется по 8 кГц. Текущие схемы кодирования сжимают цифровой речевой сигнал 10 в сигнал с низкой битовой скоростью посредством удаления всех естественных избыточностей (т.е. коррелированные элементы), присущих речи. Речь обычно представляет собой временные избыточности, получающиеся из механического действия губ и языка, и долговременные избыточности, получающиеся из вибрации голосовых связок. Кодирование с линейным предсказанием (КЛП) (LPC) фильтрует речевой сигнал 10 посредством удаления избыточностей, создавая остаточный речевой сигнал 30. Он затем моделирует итоговый остаточный сигнал 30 в качестве белого шума Гаусса. Эталонное значение формы колебания речевого сигнала может прогнозироваться посредством взвешивания суммы числа предыдущих эталонов 40, каждый из которых умножается на коэффициент 50 линейного предсказания. Поэтому кодеры с линейным предсказанием обеспечивают уменьшенную битовую скорость посредством передачи коэффициентов 50 фильтра и квантованного шума вместо речевого сигнала 10 полного диапазона. Остаточный сигнал 30 кодируется посредством выделения периода 100 образца из текущего кадра 20 остаточного сигнала 30. Блок-схему в одном варианте осуществления вокодера 70 LPC, используемого настоящим способом, и устройство, можно увидеть на Фиг.1. Функция LPC предназначена для минимизации суммы квадрата разности между первоначальным речевым сигналом и оцененным речевым сигналом за определенный промежуток времени. Это может создавать уникальный набор коэффициентов 50 средства предсказания, которые обычно оценивают каждый кадр 20. Кадр 20 обычно равен 20 мс. Функция передачи цифрового фильтра 75 с временным изменением выражается:
где коэффициенты 50 средства предсказания представляются как ak и коэффициент усиления как G. Сумма вычисляется от k=1 до k=p. Если используется способ LPC-10, тогда p=10. Это означает, что только первые 10 коэффициентов передаются на синтезатор 80 LPC. Два наиболее обычно используемых способа для вычисления коэффициентов являются, но не ограничивая, ковариационным способом и автокорреляционным способом. Говорить с разной скоростью является общим для разных говорящих. Время сжатия является одним способом уменьшения эффекта изменения скорости для индивидуальных говорящих. Временные разницы между двумя образцами речи могут быть уменьшены посредством изменения масштаба временной оси одного с тем, чтобы достигнуть максимального совпадения с другим. Этот метод временного сжатия известен как изменение масштаба времени. Кроме того, изменение масштаба времени сжимает или расширяет голосовые сигналы без изменения их тона. Обычно вокодеры создают кадры 20 с продолжительностью 20 мсек, включая в себя 160 эталонов 90 с предпочтительной скоростью 8 кГц. Сжатый вид изменения масштаба времени этого кадра 20 имеет продолжительность менее, чем 20 мсек, в то время как расширенный вид изменения масштаба времени имеет продолжительность более, чем 20 мсек. Изменение масштаба времени голосовых данных имеет значительные преимущества, когда отправляют голосовые данные через сети с переключением пакетов, которые представляют флуктуации времени задержки в передаче голосовых пакетов. В таких сетях изменение масштаба времени может использоваться для уменьшения эффектов такой флуктуации временной задержки и создания «синхронно» просматриваемого голосового потока. Варианты осуществления изобретения относятся к устройству и способу изменения масштаба времени кадров 20 в вокодере 70 посредством манипулирования речевым остатком 30. В одном варианте осуществления настоящий способ и устройство используются в 4GV. Описанные варианты осуществления содержат способы и устройства или системы для расширения/сжатия различных типов 4GV речевых сегментов 110, кодированных с помощью Периода Тона Образца (ПТО) (PPP), кодирования с Линейным Предсказанием С Кодовым Возбуждением (ЛПВК) (CELP) или (Линейным Предсказанием С Шумовым Возбужденнием (ЛПВШ) (NELP). Термином «вокодер» 70 обычно называется устройство, которое сжимает вокализированную речь посредством извлечения параметров на основе модели генерации человеческой речи. Вокодеры 70 включают в себя кодер 204 и декодер 206. Кодер 204 анализирует входящую речь и извлекает релевантные параметры. В одном варианте осуществления кодер содержит фильтр 75. Декодер 206 синтезирует речь, используя параметры, которые он принимает от кодера 204 по каналу 208 передачи. В одном варианте осуществления декодер содержит синтезатор 80. Речевой сигнал 10 часто разделяют на кадры 20 данных и блок обрабатывается вокодером 70. Специалисту в уровне техники будет понятно, что человеческая речь может классифицироваться различными путями. Тремя обычными классификациями речи являются вокализированные, невокализированные звуки и неустойчивая речь. Фиг.2а показывает вокализированный речевой сигнал s(n) 402. Фиг.2а показывает измеряемое общее свойство вокализированной речи, известное как период 100 тона. Фиг.2в – невокализированный речевой сигнал s(n) 404. Невокализированный речевой сигнал 404 напоминает цветной шум. Фиг.2с показывает неустойчивый речевой сигнал s(n) 406 (т.е. речь, которая является ни вокализированой, ни невокализированой). Пример неустойчивой речи 406, показанный на Фиг.2с, может представлять переход s(n) между невокализированной речью и вокализированной речью. Эти три классификации не все включают в себя. Есть много различных классификаций речи, которые могут использоваться в соответствии со способами, описанными здесь, для достижения сопоставимых результатов. 4GV Вокодер Использует 4 Разных Типа Кадра Четвертый генерирующий вокодер (4ГВ) (4GV) 70, используемый в одном из вариантов осуществления изобретения, обеспечивает эффективные признаки для использования в беспроводных сетях. Некоторые из этих признаков включают в себя способность в соотношении качества в сравнении с битовой скоростью, более гибкое кодирование речевых сигналов несмотря на увеличенную скорость пакетных ошибок (СПО) (PER), лучшее маскирование стираний и т.д. 4GV вокодер 70 может использовать любые четыре разных кодера 204 и декодера 206. Разные кодеры 204 и декодеры 206 работают в соответствии с разными схемами кодирования. Некоторые кодеры 204 более эффективны в частях кодирования речевого сигнала s(n) 10, представляя определенные свойства. Поэтому в одном варианте осуществления режимы кодеров 204 и декодеров 206 могут выбираться на основе классификации текущего кадра 20. 4GV кодер 204 кодирует каждый фрейм 20 голосовых данных в одном из четырех различных типов кадров 20: Интерполяция Формы Колебания Сигнала Периода Тона Образца (ИФКСПТО) (PPPWI), Линейное предсказание с кодовым возбуждением (ЛПВК) (CELP), Линейное предсказание с шумовым возбуждением (ЛПВШ) (NELP) или кадр 1/8 скорости молчания. CELP используется для кодирования речи с малой периодичностью или речи, которая включает в себя изменение от одного периодического сегмента 110 к другому. Так режим CELP обычно выбирается для кодирования кадров, проклассифицированных как неустойчивая речь. Так как такие сегменты 110 не могут быть точно восстановлены только из одного периода тона образца, CELP кодирует характеристики завершенного речевого сегмента 110. Режим CELP вызывает модель линейного предсказания голосового тракта с квантованным видом остаточного сигнала 30 линейного предсказания. Из всех кодеров 204 и декодеров 206, описанных здесь, CELP обычно создает более точное речевое восстановление, но требует высокой битовой скорости. Режим периода тона образца (ПТО) (PPP) может выбираться для кодовых фреймов 20, проклассифицированных как вокализированная речь. Вокализированная речь содержит медленно изменяющиеся во времени периодические компоненты, которые используются режимом PPP. Режим PPP кодирует поднабор периодов 100 тона в каждом кадре 20. Остальные периоды 100 речевого сигнала 10 восстанавливаются посредством интерполяции между этими периодами 100 образца. При использовании периодичности вокализированной речи PPP способен достигать битовой скорости ниже, чем CELP, и еще воспроизводить речевой сигнал 10 в перцепционно точной манере. PPPWI используется для кодирования речевых данных, которые являются периодичными по природе. Такая речь характеризуется различными периодами 100 тона, схожими с периодом тона «образца» (ПТО) (PPP). Этот PPP является только голосовой информацией, которая необходима кодеру 204 для кодирования. Декодер может использовать этот PPP для восстановления других периодов 100 тона в речевом сегменте 110. Кодер 204 с «Линейным Предсказанием С Шумовым Возбуждением» (ЛПВШ) (NELP) выбирается для кодовых фреймов 20, проклассифицированных как невокализированная речь. Кодирование NELP работает эффективно в терминах восстановления сигнала, где речевой сигнал 10 имеет малую или не малую структуру тона. Более конкретно, NELP используется для кодирования речи, которая имеет характер подобный шуму, такой как невокализированная речь или фон. NELP использует фильтрованные сигналы псевдослучайного шума в модели невокализированной речи. Шумовой характер таких речевых сегментов 110 может восстанавливаться посредством генерирования случайных сигналов в декодере 206 и применения к ним назначенных коэффициентов усилений. NELP использует наипростейшую модель для кодирования речи и поэтому достигает низкую битовую скорость. Кадры 1/8 скорости используются для кодирования молчания, например периодов, когда пользователь не разговаривает. Все из четырех схем кодирования речевых сигналов, описанных выше, совместно используют начальную процедуру фильтрации LPC, как показано на Фиг.3. После классификации речи по четырем категориям речевой сигнал 10 отправляется через кодирующий фильтр 80 с линейным предсказанием (КЛП) (LPC), который фильтрует кратковременные корреляции в речи, используя линейное предсказание. Выходные сигналы этого блока являются коэффициентами 50 LPC и «остаточным» сигналом 30, который в основном является начальным речевым сигналом 10 с кратковременными корреляциями, удаленными из него. Затем остаточный сигнал 30 кодируется, используя конкретные способы, используемые способами кодирования речевого сигнала, выбранными для кадра 20. Фиг.4а-4в показывают пример начального речевого сигнала 10 и остаточного сигнала 30 после блока 80 LPC. Можно видеть, что остаточный сигнал 30 показывает периоды 100 тона более отчетливо, чем начальная речь 10. Понятно, таким образом, что остаточный сигнал 30 может использоваться для определения периода 100 тона речевого сигнала более точно, чем начальный сигнал 10 (который также содержит кратковременные корреляции). Изменение масштаба остаточного времени Как установлено выше, изменение масштаба времени может использоваться для расширения или сжатия речевого сигнала 10. Хотя ряд способов может использоваться для достижения этого, многие из них основываются на добавлении или удалении периодов 100 тона из сигнала 10. Добавление или удаление периодов 100 тона могут выполняться в декодере 206 после приема остаточного сигнала 30, но до синтеза сигнала 30. Для речевых данных, которые кодируются с помощью CELP или PPP (не NELP), сигнал включает в себя ряд периодов 100 тонов. Таким образом, наименьший блок, который может добавляться или удаляться из речевого сигнала 10, является периодом 100 тона, т.к. любой блок меньший, чем этот, будет приводить к фазовому разрыву в представлении заметного речевого артефакта. Так одним шагом в способах изменения масштаба времени, применяемых для речи CELP или PPP, является оценка периода 100 тона. Такой период 100 тона уже известен для декодера 206 для речевых кадров 20 CELP/PPP. В случае PPP и CELP информация тона вычисляется кодером 204 с помощью автокорреляционных способов и передается на декодер 206. Таким образом, декодер 206 имеет точные знания о периоде 100 тона. Это создает простоту применения способа изменения масштаба времени настоящего изобретения в декодере 206. Кроме того, как установлено выше, проще изменить масштаб времени сигнала 10 до синтеза сигнала 10. Если такие способы изменения масштаба времени были применены после декодирования сигнала 10, необходимо будет оценить период 100 тона сигнала 10. Это требует не только дополнительного вычисления, но также оценки периода 100 тона могут не быть точными, т.к. остаточный сигнал 30 также содержит информацию 170 LPC. С другой стороны, если дополнительные оценки периода 100 тона тоже не являются комплексными, тогда выполнение изменения масштаба времени после декодирования не требует изменений в декодере 206 и поэтому может выполняться только один раз для всех вокодеров 80. Другая причина выполнения изменения масштаба времени в декодере 206 до синтеза сигнала, используя кодирующий синтез LPC, заключается в том, что сжатие/расширение может применяться к остаточному сигналу 30. Это позволяет синтезу кодирования с линейным предсказанием (LPC) применяться для остаточного сигнала 30, подвергшегося изменению масштаба времени. Коэффициенты 50 LPC играют роль в том, как речевые звуки и применение синтеза после изменения масштаба гарантируют, что поддерживается корректная информация 170 LPC в сигнале 10. Если, с одной стороны, изменение масштаба времени выполняется после декодирования остаточного сигнала 30, синтез LPC уже выполнен до изменения масштаба времени. Таким образом, процедура изменения масштаба может изменять информацию 170 LPC сигнала 10, особенно, если предсказание периода 100 тона после декодирования не было очень точным. В одном варианте осуществления этапы, выполняемые способами изменения масштаба времени, описанные в настоящей заявке, сохраняются в качестве команд, расположенных в программном обеспечении или встроенной программе 81, расположенной в памяти 82. На Фиг.1 память показывается расположенной в декодере 206. Память 82 может также располагаться вне декодера 206. Кодер 204 (такой как один из 4GV) может классифицировать речевые кадры 20 как PPP (периодичные), CELP (слабо периодичные) или NELP (шумовые) в зависимости от того, представляют ли кадры 20 вокализированную, невокализированную или неустойчивую речь. Используя информацию о типе речевого кадра, декодер 206 может изменять масштаб времени разных типов кадров 20, используя различные способы. Например, речевой кадр 20 NELP не имеет понятия о периодах тона и его остаточный сигнал 30 генерируется в декодере 206, используя «случайную» информацию. Таким образом, оценка периода 100 тона CELP/PPP не применяется к NELP и в целом кадры 20 NELP могут изменять масштаб времени (расширяться/сжиматься) на менее, чем период 100 тона. Такая информация не является пригодной, если изменение масштаба времени выполняется после декодирования остаточного сигнала 30 в декодере 206. В целом изменение масштаба времени кадров 20, подобных NELP, после декодирования приводит к артефактам. Изменение масштаба времени кадров 20 NELP в декодере 206, с другой стороны, создает более лучшее качество. Таким образом, есть два преимущества выполнения изменения масштаба времени в декодере 206 (т.е. до синтеза остаточного сигнала 30) против пост-декодера (т.е. после синтеза остаточного сигнала 30): (i) уменьшение дополнительных расчетов (например, избежание поиска периода 100 тона) и (ii) улучшенное качество изменения масштаба времени вследствие а) знания типа кадра 20, b) выполнения синтеза LPC сигнала, подвергшегося изменению масштаба времени, и с) более точная оценка/знание периода тона. Способы изменения масштаба времени остатка Последующее описание вариантов осуществления, в которых настоящие способ и устройство изменяют масштаб времени речевого остатка 30 в декодерах PPP, CELP и NELP. Следующие два этапа выполняются в каждом декодере 206: (i) изменение масштаба времени остаточного сигнала 30 к расширенному или сжатому виду; и (ii) отправка остатка 30, подвергшегося изменению масштаба времени, через фильтр 80 LPC. Кроме того, этап (i) по-разному выполняется для речевых сегментов 110 PPP, CELP и NELP. Варианты осуществления будут описаны ниже. Изменение Масштаба Времени Остаточного сигнала, когда речевой сегмент является PPP Как установлено выше, когда речевой сегмент 110 является PPP, наименьшим блоком, который может добавляться или удаляться из сигнала, является период 100 тона. До того, как сигнал 10 может декодироваться (и восстановлен остаток 30) из периода 100 тона образца, декодер 206 интерполирует сигнал 10 из предыдущего периода 100 тона образца (который сохраняется) в период 100 тона образца в текущем кадре 20, добавляя недостающие периоды 100 тона в процесс. Этот процесс показан на Фиг.5. Такая интерполяция придает простоту в изменении масштаба времени посредством создания менее или более интерполированных периодов 100 тона. Это будет приводить к сжатию или расширению остаточных сигналов 30, которые затем отправляются через синтез LPC. Изменение Масштаба Времени Остаточного Сигнала, когда речевой сегмент 110 является CELP Как установлено ранее, когда речевой сегмент 110 является PPP, наименьшим блоком, который может добавляться или удаляться из сигнала, является период 100 тона. С другой стороны, в случае CELP, изменение масштаба времени также не является непосредственным для PPP. Для изменения масштаба времени остатка 30 декодер 206 использует информацию о задержке 180 тона, содержащейся в кодированном кадре 20. Эта задержка 180 тона действительно является задержкой 180 тона в конце кадра 20. Следует отметить, что даже в периодическом кадре 20, задержка 180 тона может немного изменяться. Задержки 180 тона в любой точке в кадре могут оцениваться интерполяцией между задержкой 180 тона в конце последнего кадра 20 и в конце текущего кадра 20. Это показано на Фиг.6. Как только известны задержки 180 тона во всех точках кадра 20, кадр может разделяться на периоды 100 тона. Границы периодов 100 тона определяются, используя задержки 100 тона в различных точках в кадре 20. Фиг.6а показывает пример того, как разделяют кадр 20 на его периоды 100 тона. Например, количество эталонов 70 имеет задержку 70 тона, равную приблизительно 70, и количество эталонов 142 имеет задержку 190 приблизительно 72. Таким образом, периоды 100 тона получаются из числа эталонов [1-70] и из числа эталонов [71-142]. См. Фиг.6в. Один кадр 20 разделен на периоды 100 тона, эти периоды 100 тона могут затем совмещаться-добавляться для увеличения/уменьшения размера остатка 30. См. Фиг.7в-7f. В синтезе совмещения и добавления, измененный сигнал получается посредством удаления сегментов 110 из входного сигнала 10, перемещения их вдоль временной оси и выполнения взвешенного совмещенного суммирования для создания синтезированного сигнала 150. В одном варианте осуществления сегмент 110 может равняться периоду 100 тона. Способ совмещения-добавления заменяет два различных речевых сегмента 110 на один речевой сегмент 110 посредством «объединения» сегментов 110 речи. Объединение речи выполняется способом сохранения, на сколько возможно, большего качества речи. Качество защиты речи и минимизации представления артефактов в речи выполняется посредством тщательного выбора сегментов 110 для объединения. (Артефакты являются нежелательными объектами подобно щелчку, хлопку и т.д.). Выбор речевых сегментов 110 базируется на «сходстве» сегментов. Близость «сходства» речевых сегментов 110, лучшее результирующее речевое качество и низкая вероятность представления речевого артефакта, когда два сегмента 110 речи совмещаются для уменьшения/увеличения размера речевого остатка 30. Правилом полезности для определения, должны ли периоды тона совмещаться-добавляться, является, если схожи задержки тона двух (как например, если задержки тона различаются менее чем 15 эталонам, которые соответствуют около 1,8 мсек). Фиг.7с показывает, как используется совмещение-добавление для сжатия остатка 30. Первым этапом способа совмещения/добавления является сегментирование входных эталонных последовательностей s(n) 10 на их периоды тона, как объяснено выше. На Фиг.7а показан начальный речевой сигнал 10, включающий 4 периода 100 (ПТ) (PP) тона. Следующий этап включает в себя удаление периодов 100 тона сигнала 10, показанных на Фиг.7а, и замену этих периодов 100 тона на объединенные периоды 100 тона. Например на Фиг.7с, периоды PP2 и PP3 тона удаляются и затем заменяются одним периодом 100 тона, в котором PP2 и PP3 совмещаются-суммируются. Более конкретно, на Фиг.7с, периоды 100 PP2 и PP3 тона совмещаются-добавляются таким образом, что доля второго периода 100 (PP2) тона уменьшается и что PP3 увеличивается. Способ добавления-совмещения создает один речевой сегмент 110 из двух разных речевых сегментов 110. В одном варианте осуществления добавление-совмещение выполняется, используя взвешенные эталоны. Это показывается выражениями а) и b), показанными на Фиг.8. Взвешивание используется для обеспечения сглаживания перехода между первым эталоном PMC (ИКМ) (Импульсно-Кодовой Модуляции) Сегмента1 (110) и последним эталоном PMC Сегмента2 (110). Фиг.7d является другой графической иллюстрацией совмещенных-добавленных PP2 и PP3. Плавное микширование улучшает качество времени сигнала 10, сжатого этим способом, по сравнению с простым удалением одного сегмента 110 и соединения оставшихся соседних сегментов 110 (как показано на Фиг.7е). В случае, когда период 100 тона изменяется, способ совмещения-добавления может объединять два периода 110 тона неравной длины. В этом случае лучшее объединение может достигаться посредством выравнивания пиков двух периодов 100 тона до их совмещения-добавления. Расширенный/сжатый остаток затем отправляется через синтез LPC. Речевое расширение Простым подходом в расширении речи является выполнение множества повторений одинаковых эталонов PMC. Однако повторение одинаковых эталонов PMC более чем один раз может создать области с ровными тонами, которые являются артефактами, которые легко определяются людьми (например, речь может звучать немного роботизировано). Для сохранения качества речи может использоваться способ добавления-совмещения. Фиг.7в показывает, как этот речевой сигнал 10 может расширяться, используя способ совмещения-добавления настоящего изобретения. На Фиг.7в добавляется дополнительный период 100 тона, созданный из периодов 100 PP1 и PP2 тона. В дополнительном периоде 100 тона периоды 100 PP2 и PP1 тона совмещаются-добавляются таким образом, что доля второго периода 100 (PP2) тона уменьшается и что PP1 увеличивается. Фиг.7f является другой графической иллюстрацией совмещенных добавленных PP2 и PP3. Изменение Масштаба Времени Остаточного Сигнала, когда речевой сегмент является NELP Для речевых сегментов NELP кодер кодирует информацию LPC, а также коэффициенты усиления для различных частей речевого сегмента 110. Необходимо кодировать любую другую информацию, т.к. речь по природе очень подобна шуму. В одном варианте осуществления коэффициенты усиления кодируются в наборе из 16 эталонов PMC. Так, например, кадр из 160 эталонов может представляться 10 кодированными значениями коэффициента усиления, один для каждых 16 эталонов речи. Декодер 206 генерирует остаточный сигнал 30 посредством генерирования случайных значений и затем применяя к ним соответствующие коэффициенты усиления. В этом случае здесь не может быть понятия период 100 тона и по существу расширение/сжатие не может выполняться, не имея неравномерности периода 100 тона. Для расширения или сжатия NEL сегмента, декодер 206 генерирует количество сегментов (110) больше или меньше, чем 160, в зависимости от того, расширяется или сужается сегмент 110. 10 декодированных коэффициентов усиления затем применяются к эталонам для генерирования расширенного или сжатого остатка 30. Так как эти 10 декодированных коэффициентов усиления соответствуют начальным 160 эталонам, они прямо не применяются для расширения/сжатия эталонов. Различные способы могут использоваться для применения этих коэффициентов усиления. Некоторые из этих способов описываются ниже. Если количество генерируемых эталонов меньше, чем 160, тогда нет необходимости в применении всех 10 коэффициентов усиления. Например, если количество эталонов равно 144, могут применяться первые 9 коэффициентов усилений. В этом примере первый коэффициент усиления применяется к первым 16 эталонам, эталоны 1-16, второй коэффициент усиления применяется к следующим 16 эталонам, эталоны 17-32, и т.д. Аналогично, если эталонов больше, чем 160, тогда 10-й коэффициент усиления может применяться более чем один раз. Например, если количество эталонов равно 192, 10-й коэффициент усиления может применяться к эталонам 145-160, 161-176 и 177-192. Альтернативно, эталоны могут разделяться на 10 наборов из одинакового количества, каждый набор имеет одинаковое количество эталонов, и 10 коэффициентов усиления могут применяться к 10 наборам. Например, если количество эталонов равно 140, 10 коэффициентов усилений могут применяться к наборам из 14 эталонов в каждом. В этом примере первый коэффициент усиления применяется к первым 14 эталонам, эталоны 1-14, второй коэффициент усиления применяется к следующим 14 эталонам, эталоны 14-28, и т.д. Если количество эталонов полностью не делится на 10, тогда 10-й коэффициент усиления может применяться к оставшимся эталонам, полученным после разделения на 10. Например, если количество эталонов равно 145, 10 коэффициентов усиления может применяться к наборам из 14 эталонов в каждом. Дополнительно, 10-й коэффициент усиления применяется к эталонам 141-145. После изменения масштаба времени расширенный/сжатый остаток 30 отправляется через синтез LPC, где используются любые перечисленные выше способы кодирования. Специалисту в уровне техники будет понятно, что информация и сигналы могут представляться, используя любой из множества различных технологий и методов. Например, данные, инструкции, команды, информация, сигналы, биты, символы и чипы, которые могут ссылаться по упомянутому выше описанию, могут представляться напряжениями, токами, электромагнитными волнами, магнитными полями или частицами, оптическими полями или частицами или любой их комбинацией. Специалисту в уровне техники будет очевидно, что различные иллюстративные логические блоки, модули, схемы и этапы алгоритма, описанные в связке с вариантами осуществления, описанными здесь, могут выполняться в качестве электронной аппаратуры, компьютерного программного обеспечения или их комбинации. Для ясности иллюстрации этой равноценности аппаратуры и программного обеспечения различные иллюстративные компоненты, блоки, модули, схемы и этапы описаны выше в терминах их функциональности. Любая такая функциональность выполняется аппаратно или программно в зависимости от конкретного применения и ограничений конструкции, заданных на всю систему. Специалист может выполнить описанную функциональность различными способами для каждого конкретного применения, но такие решения выполнения не следует интерпретировать как отход от объема настоящего изобретения. Различные иллюстративные логические блоки, модули и схемы, описанные в связке с вариантами осуществления, описанными здесь, могут воплощаться или выполняться в процессоре общего назначения, Процессоре Цифровых Сигналов (ПЦС) (DSP), Специализированной Интегральной схеме (СИС) (ASIC), Программируемой Пользователем Вентильной Матрице (ППВМ) (FPGA) или других программно-логических устройствах, логическом элементе на дискретных компонентах или транзисторной логике, дискретных аппаратных компонентах или любой их комбинации, предназначенной для выполнения функций, описанных здесь. Процессором общего назначения может быть микропроцессор, но в альтернативе, процессором может быть любой обычный процессор, контроллер, микроконтроллер или конечный автомат. Процессор может также выполняться как комбинация вычислительных устройств, например комбинация DSP и микропроцессора, множество микропроцессоров, один или более микропроцессоров в связке с ядром DSP или любая другая такая конфигурация. Этапы способа или алгоритма, описанные в связке с вариантами осуществления, описанными здесь, могут выполняться прямо в аппаратуре, в программном модуле, выполняемом процессором, или в комбинации этих двух. Программный модуль может располагаться в Оперативной памяти (RAM), флэш-памяти, Постоянной Памяти (ROM), Электрически Программируемой ROM (EPROM), Электрически Стираемой Программируемой ROM (EEPROM), регистрах, жестком диске, сменном диске, CD-ROM или любой другой форме запоминающего носителя, известного из уровня техники. Иллюстративный носитель подключается к процессору так, чтобы процессор мог считывать информацию с и записывать информацию на запоминающий носитель. В альтернативе запоминающий носитель может встраиваться в процессор. Процессор и запоминающий носитель могут располагаться в ASIC. ASIC может располагаться в пользовательском терминале. В альтернативе, процессор и запоминающий носитель могут располагаться как дискретные компоненты в пользовательском терминале. Предыдущее описание раскрытых вариантов осуществления приспособлено для создания или использования настоящего изобретения любым специалистом в уровне технике. Различные модификации этих вариантов осуществления будут без труда очевидны специалисту в уровне техники и общие принципы, определенные здесь, могут применяться для других вариантов осуществления без отхода от сущности или объема изобретения. Таким образом, настоящее изобретение не подлежит ограничению вариантами осуществления, показанными здесь, но подлежит согласованию с широким объемом, согласующимся с принципами и новыми признаками, описанными здесь.
Формула изобретения
1. Способ передачи речи, содержащий этапы, на которых: 2. Способ передачи речи по п.1, в котором упомянутый этап кодирования речевых сегментов содержит использование периодов тона образца, линейное предсказание с кодовым возбуждением, линейное предсказание с шумовым возбуждением или 1/8 кадрового кодирования. 3. Способ передачи по речи п.1, дополнительно содержащий этапы, на которых: 4. Способ передачи речи по п.1, в котором упомянутый этап классифицирования речевых сегментов содержит классификацию речевых кадров на периодические, слабопериодические или шумовые в зависимости от того, представляют ли кадры вокализированную, невокализированную или неустойчивую речь. 5. Способ передачи речи по п.1, в котором упомянутое кодирование является кодированием с линейным предсказанием с кодовым возбуждением. 6. Способ передачи речи по п.1, в котором упомянутое кодирование является кодированием периода тона образца. 7. Способ передачи речи по п.1, в котором упомянутое кодирование является кодированием с линейным предсказанием с шумовым возбуждением. 8. Способ по п.5, в котором упомянутый этап изменения масштаба времени содержит 9. Способ по п.5, в котором этап изменения масштаба времени содержит: 10. Способ по п.6, в котором упомянутый этап изменения масштаба времени содержит этапы, на которых: 11. Способ по п.7, в котором упомянутый этап кодирования содержит кодирование информации кодирования с линейным предсказанием в качестве коэффициентов усиления разных частей речевого сегмента. 12. Способ по п.9, в котором упомянутый этап совмещения упомянутых периодов тона, если уменьшается упомянутый речевой остаточной сигнал, содержит: 13. Способ по п.9, в котором упомянутый этап оценки задержки тона содержит интерполяцию между задержкой тона конца последнего кадра и конца текущего кадра. 14. Способ по п.9, в котором упомянутый этап добавления упомянутых периодов тона содержит объединение речевых сегментов. 15. Способ по п.9, в котором упомянутый этап добавления упомянутых периодов тона, если увеличивается упомянутый остаточный речевой сигнал, содержит добавление дополнительного периода тона, созданного из первого сегмента периода тона и второго сегмента периода тона. 16. Способ по п.11, в котором упомянутые коэффициенты усиления кодируются для наборов речевых эталонов. 17. Способ по п.12, в котором упомянутый этап объединения упомянутых удаленных сегментов содержит увеличение доли первого сегмента периода тона и уменьшение доли второго сегмента периода тона. 18. Способ по п.14, дополнительно содержащий этап выбора схожих речевых сегментов, при этом объединяют упомянутые схожие речевые сегменты. 19. Способ по п.14, дополнительно содержащий этап корреляции речевых сегментов, посредством чего выбирают схожие речевые сегменты. 20. Способ по п.15, в котором упомянутый этап добавления дополнительного периода тона, созданного из первого сегмента периода тона и второго сегмента периода тона, содержит сложение упомянутого первого и упомянутого второго сегментов периода тона таким образом, что увеличивается доля упомянутого первого сегмента периода тона и уменьшается доля упомянутого второго сегмента периода тона. 21. Способ по п.16, дополнительно содержащий этап генерирования остаточного сигнала посредством генерирования случайных значений и последующего применения упомянутых коэффициентов усиления к упомянутым случайным значениям. 22. Способ по п.16, дополнительно содержащий этап представления упомянутой информации кодирования с линейным предсказанием в качестве 10 кодированных значений коэффициентов усиления, при этом каждое кодированное значение коэффициента усиления представляет 16 эталонов речи. 23. Вокодер, имеющий по меньшей мере один вход и по меньшей мере один выход, содержащий: 24. Вокодер по п.23, в котором упомянутый кодер содержит память и упомянутый кодер выполнен с возможностью выполнения программных команд, сохраненных в упомянутой памяти, содержащих классификацию речевых сегментов по 1/8 кадра, периоды тона образца, линейное предсказание с кодовым возбуждением или линейное предсказание с шумовым возбуждением. 25. Вокодер по п.24, в котором упомянутый фильтр является кодирующим фильтром с линейным предсказанием, который выполнен с возможностью: 26. Вокодер по п.24, в котором, упомянутый кодер содержит: 27. Вокодер по п.24, в котором упомянутый кодер содержит: 28. Вокодер по п.24, в котором упомянутый кодер содержит: 29. Вокодер по п.26, в котором упомянутая программная команда изменения масштаба времени содержит 30. Вокодер по п.26, в котором упомянутая программная команда изменения масштаба времени содержит 31. Вокодер по п.27, в котором упомянутая программная команда изменения масштаба времени содержит 32. Вокодер по п.28, в котором упомянутое кодирование упомянутых речевых сегментов, используя программную команду кодирования с линейным предсказанием с шумовым возбуждением, содержит кодирование информации кодирования с линейным предсказанием в качестве коэффициентов усиления различных частей речевых сегментов. 33. Вокодер по п.30, в котором упомянутое совмещение упомянутых периодов тона, если уменьшается упомянутый речевой остаточный сигнал, содержит 34. Вокодер по п.30, в котором упомянутая команда оценки задержки тона содержит интерполяцию между задержкой тона конца последнего кадра и конца текущего кадра. 35. Вокодер по п.30, в котором упомянутая команда суммирования упомянутых периодов тона содержит объединение речевых сегментов. 36. Вокодер по п.30, в котором упомянутая команда добавления упомянутых периодов тона, если увеличивается упомянутый речевой остаточный сигнал, содержит добавление дополнительного периода тона, созданного из первого сегмента периода тона и второго сегмента периода тона. 37. Вокодер по п.32, в котором упомянутые коэффициенты усиления кодируются для наборов речевых эталонов. 38. Вокодер по п.33, в котором упомянутая команда объединения упомянутых удаленных сегментов содержит увеличение доли первого сегмента периода тона и уменьшение доли второго сегмента периода тона. 39. Вокодер по п.35, дополнительно содержащий этап выбора схожих речевых сегментов, при этом объединяются упомянутые схожие речевые сегменты. 40. Вокодер по п.35, в котором упомянутая команда изменения масштаба времени дополнительно содержит корреляцию речевых сегментов, посредством чего выбираются схожие речевые сегменты. 41. Вокодер по п.36, в котором упомянутая команда дополнения дополнительного периода тона, созданного из первого сегмента периода тона и второго сегмента периода тона, содержит добавление упомянутого первого и второго сегментов периода тона таким образом, что увеличивается упомянутая доля первого сегмента периода тона и уменьшается доля второго сегмента периода тона. 42. Вокодер по п.37, в котором упомянутая команда изменения масштаба времени дополнительно содержит генерирование остаточного сигнала посредством генерирования случайных значений с последующим применением упомянутых коэффициентов усиления к упомянутым случайным значениям. 43. Вокодер по п.37, в котором упомянутая команда изменения масштаба времени дополнительно содержит представление упомянутой информации кодирования с линейным предсказанием в качестве 10 кодированных значений коэффициента усиления, при этом каждое кодированное значение коэффициента усиления представляет 16 эталонов речи. 44. Вокодер, содержащий: 45. Считываемый процессором носитель для передачи речи, содержащий команды для
РИСУНКИ
|
||||||||||||||||||||||||||
 595
595