Патент на изобретение №2363983
|
||||||||||||||||||||||||||
(54) СИСТЕМЫ И СПОСОБЫ ДЛЯ ПОИСКА С ИСПОЛЬЗОВАНИЕМ ЗАПРОСОВ, НАПИСАННЫХ НА ЯЗЫКЕ И/ИЛИ НАБОРЕ СИМВОЛОВ, ОТЛИЧНОМ ОТ ТАКОВОГО, ДЛЯ ЦЕЛЕВЫХ СТРАНИЦ
(57) Реферат:
Изобретение относится к поиску и выборке информации. Техническим результатом является обеспечение возможности выполнения поиска с использованием запросов, написанных в наборе символов или языке, который отличается от набора символов или языка документов, которые необходимо найти, и получения релевантных результатов поиска. Для этого принимают последовательность неоднозначных компонентов информации от пользователя и переводят в одну или более соответствующие последовательности менее неоднозначных компонентов информации. Эти последовательности менее неоднозначной информации предоставляются как входные данные в поисковую машину. Результаты поиска получаются от поисковой машины и представляются пользователю. Перевод между этими наборами символов и/или языками может быть выполнен посредством исследования использования терминов в выровненном тексте. Вероятности могут быть ассоциативно связаны с каждым возможным переводом. К этим вероятностям могут быть сделаны уточнения посредством исследования взаимодействий пользователя с результатами поиска. 7 н. и 38 з.п. ф-лы, 16 ил.
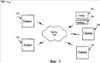
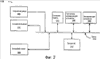
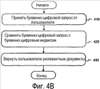
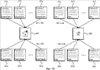
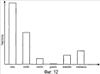
Перекрестная ссылка на родственные заявки Эта заявка является частичным продолжением Патентной заявки США серийный номер 09/748,431, озаглавленной «METHODS AND APPARATUS FOR PROVIDING SEARCH RESULTS IN RESPONSE TO AN AMBIGUOUS SEARCH QUERY» (Способы и устройство для предоставления результатов поиска в ответ на неоднозначный поисковый запрос), зарегистрированной 26 декабря 2000 г., которая притязает на приоритет по 35 U.S.C. §119(e), Предварительной патентной заявки США серийный номер 60/216,530, озаглавленной «DATA ENTRY AND SEARCH FOR HANDHELD DEVICES» (Ввод и поиск данных для карманных компьютеров), зарегистрированной 6 июля 2000 г., обе настоящим полностью включены в данный документ посредством ссылки. 1. Область техники, к которой относится изобретение Настоящее изобретение в целом относится к поиску и выборке информации. Более конкретно, раскрываются системы и способы для выполнения поиска с использованием запросов, которые написаны в наборе символов или языке, который отличается от набора символов или языка, по меньшей мере, некоторых документов, которые необходимо найти. 2. Уровень техники Большинство поисковых машин функционируют при допущении, что конечный пользователь вводит поисковые запросы, используя что-то наподобие стандартной клавиатуры, где ввод буквенно-цифровых последовательностей не является трудным. Поскольку маленькие устройства становятся более распространенными, это допущение не всегда обосновано. Например, пользователи могут запрашивать поисковые машины, используя радиотелефон, который поддерживает стандарт WAP (протокол приложений для беспроводной связи). Устройства, например радиотелефоны, обычно имеют интерфейс ввода данных, в котором конкретное воздействие пользователем (например, нажатие клавиши) может соответствовать более чем одному буквенно-цифровому символу. Подробное описание архитектуры WAP доступно на («WAP 100 Спецификация архитектуры протокола приложений для беспроводной связи»). В обычном случае пользователь WAP перемещается к странице поискового запроса, представляемого с помощью формы, в которую они вводят свой поисковый запрос. С обычными способами пользователю может потребоваться нажать множество клавиш, чтобы выбрать конкретную букву. На стандартной клавишной панели телефона, например, пользователь выбрал бы букву «b» посредством нажатия клавиши «2» дважды или выбрал бы букву «s» посредством нажатия клавиши «4» четыре раза. Соответственно, чтобы ввести запрос для «ben smith» пользователю обычно было бы необходимо ввести следующую последовательность нажатий клавиш: 223366077776444844, которая отображается в буквы следующим образом: 22 33 66 0 7777 6 444 8 44 После того как пользователь ввел свой поисковый запрос, поисковая машина принимает слово или слова от пользователя и обрабатывает почти таким же способом, как если бы она приняла запрос от веб-обозревателя настольной системы, в котором пользователь использует стандартную клавиатуру. Как можно увидеть из предшествующего примера, эта форма ввода данных неэффективна в том, что она требует восемнадцать нажатий клавиш, чтобы ввести девять буквенно-цифровых символов (включая пробел), соответствующих «ben smith». Схожие трудности могут возникать при вводе с клавиатуры запросов, используя клавиатуры с нецелевым языком. Например, текст на японском языке может выражаться, используя множество различных наборов символов, включая хирагану, катакану и кандзи, ни один из которых не вводится легко, используя обычную клавиатуру ASCII (Американский стандартный код для обмена информацией), основанную на латинском алфавите. В подобной ситуации пользователь часто воспользуется текстовым процессором, например Ichitaro, изготовленным JustSystem Corp., город Токушима, Япония, который может преобразовывать текст, написанный на ромадзи (фонетическое отображение японского языка латинским алфавитом), в катакану, хирагану и кандзи. Используя текстовый процессор, пользователь может печатать запрос в ромадзи и затем вырезать и вставить переведенный текст из экрана текстового процессора в поисковое окно в веб-обозревателе. Недостатком данного подхода является то, что он может быть относительно медленным и утомительным и требует от пользователя иметь доступ к копии текстового процессора, что может быть невыполнимым вследствие стоимости и/или ограничений памяти. Следовательно, остается потребность в способах и устройстве для предоставления релевантных результатов поиска в ответ на неоднозначный поисковый запрос. Раскрытие изобретения Способы и устройство в соответствии с настоящим изобретением, как реализуются и в общих чертах описываются в данном документе, обеспечивают релевантные результаты поиска в ответ на неоднозначный поисковый запрос. В соответствии с изобретением такой способ включает в себя приём последовательности неоднозначных компонентов информации от пользователя. Способ получает информацию отображения, которая отображает неоднозначные компоненты информации в менее неоднозначные компоненты информации. Эта информация отображения используется для перевода последовательности неоднозначных компонентов информации в одну или более соответствующие последовательности менее неоднозначных компонентов информации. Одна или более этих последовательностей менее неоднозначной информации предоставляются как входные данные в поисковую машину. Результаты поиска получаются от поисковой машины и представляются пользователю. Кроме этого, раскрываются системы и способы для выполнения поисков с использованием запросов, которые выражаются в наборах символов или языках, которые отличаются от набора символов или языка, по меньшей мере, некоторых документов, которые необходимо найти. Варианты осуществления настоящего изобретения позволяют пользователям печатать запросы, используя стандартные устройства ввода (например, клавиатуры ASCII), переводить им запросы в релевантные формы на сервере (например, перевести запрос, написанный на ромадзи, в катакану, хирагану и/или кандзи) и принимать результаты поиска на основе преобразованных форм. Следует принимать во внимание, что настоящее изобретение может быть реализовано многочисленными способами, включая, например, процесс, устройство, систему, механизм, способ или машинно-читаемый носитель, например, машинно-читаемый носитель информации, несущую или вычислительную сеть, в которой программные команды передаются по оптическим или электронными линиям связи. Некоторые изобретательские варианты осуществления описываются ниже. В одном из вариантов осуществления описывается способ для автоматического перевода терминов запроса из одного языка и/или набора символов в другой. Первое множество текста привязки, содержащего данный термин запроса, идентифицируется как множество документов (например, веб-страниц), на которые указывает текст привязки. Затем идентифицируется второе множество текста привязи, написанное во втором формате и указывающее на то же множество документов. Второе множество текста привязки затем анализируется, чтобы получить вероятность того, что представление данного термина запроса в первом формате соответствует представлению данного термина запроса во втором формате. В другом варианте осуществления создается вероятностный словарь, который отображает термины, написанные в первом формате (например, языке и/или наборе символов), во второй формат (например, другой язык и/или набор символов). Вероятностный словарь используется для перевода запроса, написанного в первом формате, во второй формат. Переведенный запрос затем используется для выполнения поиска, результаты которого возвращаются пользователю. В некоторых вариантах осуществления пользовательское взаимодействие с результатами поиска может отслеживаться и использоваться для обновления вероятностей в вероятностном словаре. Также в некоторых вариантах осуществления сам запрос мог бы быть расширен до поиска, чтобы включать в себя альтернативный язык и/или отображения набора символов. В еще одном варианте осуществления описывается способ для создания вероятностного словаря. Вероятностный словарь может использоваться для перевода терминов в первом формате во второй формат. Словарь создается предпочтительно почленно посредством идентификации текста привязки или других данных, содержащих термин. Затем данные, которые выровнены с текстом привязки или другими данными, анализируются для определения вероятности, с которой данный термин в первом формате отображается в один или более терминов во втором формате. В еще одном варианте осуществления предоставленный на первом языке или наборе символов запрос переводится на второй язык или набор символов посредством сравнения текста привязки, который содержит один или более терминов запроса и написан на первом языке или наборе символов, с текстом привязки, который соответствует первому тексту привязки и написан на втором языке или наборе символов. В другом варианте осуществления предоставляется компьютерный программный продукт для перевода термина, написанного в первом формате, во второй формат. Компьютерный программный продукт работает, чтобы заставить компьютерную систему идентифицировать выровненный текст привязки и определить вероятность того, что представление данного термина в первом формате соответствует одному или более терминов во втором формате. В другом варианте осуществления предоставляется способ для выполнения поисков, используя потенциально неоднозначные запросы. Когда пользователь вводит запрос в первом формате, он переводится в группу из одного или более вариантов, написанных во втором формате. Затем выполняется поиск, используя переведенные варианты, и ответная информация возвращается пользователю. Например, первый формат мог бы содержать последовательность цифр, введенных с использованием клавишной панели телефона, и второй формат мог бы содержать буквенно-цифровой текст (например, английский, ромадзи, ромадза, пиньинь (система транслитерации китайских иероглифов буквами английского алфавита) или т.п.). В некоторых вариантах осуществления выбирается группа из одного или более вариантов посредством отбрасывания переведенных вариантов, которые не появляются в предопределенном лексиконе и/или которые содержат предопределенные маловероятные сочетания символов. В некоторых вариантах осуществления используется вероятностный словарь, чтобы дополнительно перевести группу из одного или более вариантов в третий формат, до того как выполнится поиск. Например, вероятностный словарь может использоваться для перевода группы одного или более вариантов из ромадзи, ромадза или пиньинь в кандзи, катакану, хирагану, хангыль, хандза или традиционные китайские символы, а затем может быть выполнен поиск с использованием переведенных вариантов. Эти и другие признаки и преимущества настоящего изобретения будут представлены более обстоятельно в последующем подробном описании и сопроводительных рисунках, которые иллюстрируют принципы изобретения с целью примера. Краткое описание чертежей Сопроводительные чертежи, которые содержатся и составляют часть данного подробного описания, иллюстрируют варианты осуществления изобретения и вместе с описанием служат, чтобы объяснить преимущества и принципы изобретения. На чертежах: Фиг. 1 иллюстрирует блок-схему системы, в которой могут быть реализованы способы и устройство, в соответствии с настоящим изобретением; Фиг. 2 иллюстрирует блок-схему клиентского устройства в соответствии с изобретением; Фиг. 3 иллюстрирует диаграмму, изображающую три документа; Фиг. 4А иллюстрирует стандартный буквенно-цифровой индекс; Фиг. 4B иллюстрирует блок-схему алгоритма для предоставления результатов поиска в ответ на стандартный буквенно-цифровой поисковый запрос; Фиг. 5А иллюстрирует блок-схему алгоритма в соответствии с изобретением для предоставления результатов поиска в ответ на неоднозначный поисковый запрос; Фиг. 5B иллюстрирует диаграмму для отображения буквенно-цифровой информации в цифровую информацию; Фиг. 6 иллюстрирует другую блок-схему алгоритма в соответствии с изобретением, для предоставления результатов поиска в ответ на неоднозначный поисковый запрос; Фиг. 7 иллюстрирует способ для выполнения поиска в соответствии с вариантами осуществления настоящего изобретения; Фиг. 8 иллюстрирует вероятностный словарь переводов набора символов; Фиг. 9 иллюстрирует использование параллельного текста привязки для построения вероятностного словаря; Фиг. 10 иллюстрирует коллекцию документов, связанных с использованием текста привязки; Фиг. 11А и 11В иллюстрируют вычисление возможных переводов на основе текста привязки, показанного на фиг. 10; Фиг. 12 показывает распределение вероятности, ассоциативно связанной с пояснительным переводом слова. ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ Сейчас будет сделана подробная ссылка на варианты осуществления настоящего изобретения, как проиллюстрировано на сопроводительных чертежах. Одни и те же номера ссылок могут использоваться на чертежах и в последующем описании, чтобы ссылаться на те же или подобные части. Последующее описание представляется для предоставления возможности любому специалисту в данной области техники сделать и использовать основу изобретения для работы. Описания отдельных вариантов осуществления и приложений предоставляются только в качестве примеров, и различные модификации будут очевидны специалистам в данной области техники. Например, хотя многие из примеров описываются в контексте веб-страниц Интернета, следует понимать, что варианты осуществления настоящего изобретения могут использоваться для поиска других типов документов и/или информации, например книг, газет, журналов и т.п. Аналогично, хотя многие из примеров описывают перевод текста на японском языке из ромадзи в катакану, хирагану и/или кандзи ради иллюстрации, специалисты в данной области техники примут во внимание, что системы и способы настоящего изобретения могут применяться к любому подходящему переводу. Например, без ограничений варианты осуществления настоящего изобретения могли бы использоваться для поиска текста, написанного, например, в традиционных китайских символах или корейском хангыле или хандза, на основе запросов, принятых в каком-нибудь другом формате (например, пиньин или ромадза). Общие принципы, описанные в этом документе, могут применяться к другим вариантам осуществления и приложениям без отклонения от сущности и объема изобретения. Таким образом, настоящему изобретению нужно согласовываться с самым широким объемом, охватывающим многочисленные альтернативы, модификации и эквиваленты в соответствии с принципами и признаками, раскрытыми в этом документе. С целью ясности подробности, относящиеся к техническому материалу, который известен в областях, относящихся к изобретению, не описаны подробно с тем, чтобы излишне не затруднять понимание настоящего изобретения. А. Обзор Способы и устройство в соответствии с изобретением позволяют пользователю представить неоднозначный поисковый запрос и принять результаты поиска с потенциально устраненной неоднозначностью. В одном из вариантов осуществления последовательность цифр, принятая от пользователя стандартной клавишной панели телефона, переводится в множество потенциально соответствующих буквенно-цифровых последовательностей. Эти потенциально соответствующие буквенно-цифровые последовательности предоставляются как входные данные в обычную поисковую машину, используя булево выражение «OR» (ИЛИ). Этим способом поисковая машина используется, чтобы помочь ограничить результаты поиска до тех, в которых пользователь, вероятно, был заинтересован. B. Архитектура Фиг. 1 иллюстрирует систему 100, в которой могут реализовываться способы и устройство в соответствии с настоящим изобретением. Система 100 может включать в себя множество клиентских устройств 110, соединенных с множеством серверов 120 и 130 через сеть 140. Сеть 140 может включать в себя локальную сеть (LAN), глобальную сеть (WAN), телефонную сеть, например коммутируемую телефонную сеть общего пользования (PSTN), корпоративную сеть, Интернет либо сочетания сетей. Два клиентских устройства 110 и три сервера 120 и 130 проиллюстрированы подключенными к сети 140 для упрощения. На практике может быть больше либо меньше клиентских устройств и серверов. Также в некоторых случаях клиентское устройство может выполнять функции сервера, а сервер может выполнять функции клиентского устройства. Клиентские устройства 110 могут включать в себя устройства, например мэйнфреймы, мини-компьютеры, персональные компьютеры, портативные компьютеры, персональные цифровые помощники или т.п., допускающие подключение к сети 140. Клиентские устройства 110 могут передавать данные по сети 140 или принимать данные от сети 140 посредством проводного, беспроводного или оптического соединения. Фиг. 2 иллюстрирует примерное клиентское устройство 110 в соответствии с настоящим изобретением. Клиентское устройство 110 может включать в себя шину 210, процессор 220, основную память 230, постоянное запоминающее устройство 240 (ROM), запоминающее устройство 250, устройство 260 ввода, устройство 270 вывода и интерфейс 280 связи. Шина 210 может включать в себя одну или более стандартных шин, которые допускают обмен информацией между компонентами клиентского устройства 110. Процессор 220 может включать в себя любой тип обычного процессора или микропроцессора, который интерпретирует и исполняет команды. Основная память 230 может включать в себя оперативное запоминающее устройство (RAM) или другой тип динамического запоминающего устройства, которое хранит информацию и команды для исполнения процессором 220. ROM 240 может включать в себя обычное устройство ROM или другой тип статического запоминающего устройства, которое хранит статическую информацию и команды для пользования процессором 220. Запоминающее устройство 250 может включать в себя магнитный и/или оптический носитель информации и его соответствующий привод. Устройство 260 ввода может включать в себя один или более стандартных механизмов, которые позволяют пользователю вводить информацию в клиентское устройство 110, например клавиатуру, мышь, перо, механизмы распознавания голоса и/или биометрические и т.д. Устройство 270 вывода может включать в себя один или более стандартных механизмов, которые выводят информацию пользователю, включая дисплей, принтер, динамик и т.д. Интерфейс 280 связи может включать в себя любой механизм, подобный приемопередатчику, который дает возможность клиентскому устройству 110 обмениваться информацией с другими устройствами и/или системами. Например, интерфейс 280 связи может включать в себя механизмы для обмена информацией с другим устройством или системой через сеть, например сеть 140. Как будет подробно описано ниже, клиентские устройства 110 в соответствии с настоящим изобретением выполняют определенные связанные с поиском операции. Клиентские устройства 110 могут выполнять эти операции в ответ на исполняемые процессором 220 программные команды, содержащиеся на машинно-читаемом носителе, например, памяти 230. Машинно-читаемый носитель может быть определен как одно или более запоминающих устройств и/или несущих волн. Программные команды могут считываться в память 230 из другого машинно-читаемого носителя, например запоминающего устройства 250, или из другого устройства через интерфейс 280 связи. Программные команды, содержащиеся в памяти 230, заставляют процессор 220 выполнять относящиеся к поиску действия, описанные ниже. В качестве альтернативы может использоваться аппаратно реализованная схема вместо или в сочетании с программными командами, чтобы реализовывать процессы в соответствии с настоящим изобретением. Таким образом, настоящее изобретение не ограничивается каким-либо особым сочетанием аппаратно реализованной схемы и программного обеспечения. Серверы 120 и 130 могут включать в себя один или более типов вычислительных систем, например мэйнфрейм, мини-компьютер или персональный компьютер, допускающих соединение с сетью 140, чтобы предоставить возможность серверам 120 и 130 обмениваться информацией с клиентским устройством 110. В альтернативных реализациях серверы 120 и 130 могут включать в себя механизмы для прямого соединения с одним или более клиентскими устройствами 110. Серверы 120 и 130 могут передавать данные по сети 140 или принимать данные от сети 140 посредством проводного, беспроводного или оптического соединения. Серверы могут быть сконфигурированы способом, схожим с описанным выше в отношении к фиг. 2 для клиентского устройства 110. В реализации в соответствии с настоящим изобретением сервер 120 может включать в себя поисковую машину 125, используемую клиентскими устройствами 110. Серверы 130 могут хранить документы (или веб-страницы), доступные посредством клиентских устройств 110. С. Архитектурный процесс Фиг. 3 иллюстрирует диаграмму, изображающую три документа, которые могут храниться, например, в одном из серверов 130. Первый документ (Документ 1) содержит два элемента – «car repair» (ремонт машины) и «car rental» (прокат машины) и нумеруется «3» внизу. Второй документ (Документ 2) содержит элемент «video rental» (прокат видео). Третий документ (Документ 3) содержит три элемента – «wine» (вино), «champagne» (шампанское) и «bar items» (предметы бара) и включает в себя связь (или ссылку) на Документ 2. Для пояснительной простоты документы, показанные на фиг. 3, содержат только буквенно-цифровые последовательности информации (например, «car» (машина), «repair» (ремонт), «wine» (вино) и т.д.). Специалисты в данной области техники признают, тем не менее, что в других ситуациях документы могли бы содержать другие типы информации, например фонетическую или аудиовизуальную информацию. Фиг. 4А иллюстрирует стандартный буквенно-цифровой индекс на основе документов, показанных на фиг. 3. Первый столбец индекса содержит список буквенно-цифровых терминов и второй столбец содержит список документов, соответствующих этим терминам. Некоторые термины, например буквенно-цифровой термин «3», соответствуют только (например, появляются в) одному документу – в этом случае Документу 1. Другие термины, например «rental» (прокат), соответствуют множеству документов – в данном случае Документам 1 и 2. Фиг. 4B иллюстрирует, как обычная поисковая машина, например поисковая машина 125, использовала бы индекс, проиллюстрированный на фиг 4а, чтобы предоставить результаты поиска в ответ на буквенно-цифровой поисковый запрос. Буквенно-цифровой поисковый запрос может быть сформирован с использованием любой традиционной методики. С целью иллюстрации фиг. 4b изображает два буквенно-цифровых запроса: «car» (машина) и «wine» (вино). При традиционном походе поисковая машина 125 принимает буквенно-цифровой запрос, например «car» (этап 410), и использует буквенно-цифровой индекс для определения, какие документы соответствуют тому запросу (этап 420). В этом примере обычная поисковая машина 125 использовала бы индекс, проиллюстрированный на фиг. 4А, чтобы определить, что «car» соответствует Документу 1, и вернула бы Документ 1 (или ссылку на него) пользователю в качестве результата поиска. Подобным образом обычная поисковая машина определила бы, что «wine» соответствует Документу 3 и вернула бы Документ 3 (или ссылку на него) пользователю (этап 430). Фиг. 5А иллюстрирует блок-схему алгоритма в соответствии с изобретением, предпочтительной методики для предоставления результатов поиска в ответ на цифровой поисковый запрос на основе документов и индекса, показанных на фиг. 3 и 4а соответственно. Для облегчения пояснения фиг. 5А описывает особую методику для обработки цифрового запроса на основе отображения стандартной телефонной трубки; но специалисты в данной области техники признают, что могут использоваться другие методики в соответствии с изобретением. На этапе 510 последовательность «227» (состоящая из цифровых компонентов «2», «2» и «7») принимается от пользователя. На этапе 520 получается информация о том, как цифровые компоненты отображаются в буквы. Допуская, что пользователь ввел информацию со стандартной клавишной панели телефона, эта информация отображения показывается на фиг. 5B. Как показано на фиг. 5B, буквы «a», «b» и «c» каждая отображаются в цифру «1», буквы «p», «q», «r» и «s» каждая отображаются в цифру «7» и так далее. На этапе 530, используя информацию отображения, последовательность «227» переводится в ее возможные буквенно-цифровые эквиваленты. На основе информации, показанной на фиг. 5B, существует 36 возможных сочетаний букв, которые соответствуют последовательности «227», включая следующие: aap, bap, cap, abp, bbp, На этапе 540 эти буквенно-цифровые эквиваленты предоставляются в качестве входных данных обычной поисковой машине, например, как описаны в отношении фиг. 4А и 4B, используя логическую операцию «OR». Например, поисковый запрос, предоставленный поисковой машине, мог быть «aap OR bap OR cap OR abp На этапе 550 результаты поиска получаются от поисковой машины. Поскольку термины, например «aap» и «abp» не встречаются в индексе поисковой машины, они эффективно игнорируются. Действительно, единственными терминами, содержащимися в индексе, показанном на фиг. 4B, являются «car» и «bar» и поэтому возвращенными результатами поиска являются только те, которые соответствуют Документам 1 и 3. На этапе 560 эти результаты поиска представляются пользователю. Результаты поиска могут представляться в том же порядке, что и предоставленном поисковой машиной, либо могут быть переупорядочены на основе соображений, таких как язык пользователя. Допуская, что пользователь был заинтересован только в документах, содержащих термин «bar», пользователь примет нежелательный результат (Документ 3) в дополнение к желательному результату (Документ 1). Это может быть приемлемой издержкой, однако с выгодой для пользователя, которому необходимо нажать только три клавиши, чтобы сформулировать поисковый запрос. Фиг. 6 иллюстрирует другую блок-схему алгоритма в соответствии с изобретением, предпочтительной методики для предоставления результатов поиска в ответ на цифровой поисковый запрос, на основе документов и индекса, показанных на фиг. 3 и 4А соответственно. Эта блок-схема алгоритма демонстрирует, как увеличение размера принятой последовательности может помочь ограничить результаты поиска до желаемых пользователем. Для облегчения пояснения фиг. 6 снова описывает особую методику для обработки цифрового запроса на основе отображения стандартной телефонной трубки; но специалисты в данной области техники признают, что могут использоваться другие методики в соответствии с изобретением. На этапе 610 последовательность «227 48367» (состоящая из цифровых компонентов «2», «2», «7», «4», «8», «3», «6», «7») принимается от пользователя. Для пояснения последовательность «227» будет называться «цифровым словом», а вся последовательность «227 48367» будет называться «цифровой фразой». Возможные буквенно-цифровые эквиваленты цифрового слова будут называться «буквенными словами», а возможные буквенно-цифровые эквиваленты цифровой фразы буду называться «буквенными фразами». На этапе 620 получается информация о том, как цифровые компоненты отображаются в буквы. Допуская, что та же информация отображения используется, как показано на фиг. 5B, на этапе 630 цифровая фраза «227 48367» переводится в потенциально соответствующие буквенные фразы. На основе информации, показанной на фиг. 5B, 5С существует 11664 возможных буквенных фраз, которые соответствуют последовательности «227 48367». На этапе 640 эти буквенные фразы предоставляются в качестве входных данных обычной поисковой машине, например, как описано в отношении фиг. 4А и 4B, используя логическую операцию «OR». Например, поисковый запрос, предоставленный поисковой машине, мог бы быть «”`aap gtdmp` OR `aap htdmp` На этапе 650 результаты поиска получаются от поисковой машины. Так как многие поисковые машины спроектированы для ранжирования высоко тех документов, которые содержат точно искомую фразу, Документ 3 был бы, вероятно, наивысшим ранжированным результатом поиска (то есть потому, что он содержит точную фразу «bar items»). Никакой другой документ в примере не содержит одну из остальных буквенных фраз, сформированных на этапе 620. Более того, многие поисковые машины понижают вес (либо исключают) результатов поиска, которые содержат отдельные части фразы, но не всю фразу. Например, Документ 1 был бы понижен в весе или исключен, так как он содержит буквенное слово «car», которое соответствует первой части буквенной фразы, но он не содержит какое-нибудь буквенное слово, которое соответствует второй части буквенной фразы. Наконец, буквенные фразы, такие как «aap htdmp», эффективно игнорируются, поскольку они не содержат буквенных слов, которые встречаются в индексе поисковой машины. На этапе 660 результаты поиска представляются пользователю. В показанном примере первый результат, показанный пользователю, был бы Документ 3, который, вероятно, является наиболее релевантным запросу пользователя. Документ 1 может быть исключен совсем, так как он не содержит одну из возможных буквенных фраз. Таким образом, пользователь обеспечивается наиболее релевантными результатами поиска. Несмотря на то, что приведенные выше описания по отношению к фиг. 5 и 6 сделаны в отношении к приёму цифровой информации и отображению ее в буквенно-цифровую информацию, специалисты в данной области техники признают, что другие реализации возможны в соответствии с изобретением. Например, вместо приёма последовательности цифр, соответствующих клавишам, нажатым пользователем, принятая последовательность может состоять из первых букв, соответствующих клавишам, нажатым пользователем. Другими словами, вместо приёма «227» принятой последовательностью может быть «аар». В соответствии с изобретением эквивалентные буквенные последовательности, сформированные на этапах 530 или 630, могут тогда быть другими буквенными последовательностями (например «bar»), которые соответствуют «аар». Безусловно, принятая последовательность может содержать фонетический, аудиовизуальный или любой другой тип компонентов информации. Невзирая на форму, в которой принимается последовательность, обычно предпочитается, что принятую последовательность необходимо перевести в последовательность, которая соответствует формату, в котором информация хранится в индексе поисковой машины. Например, если индекс поисковой машины хранится в буквенно-цифровом формате, принятую последовательность следует перевести в буквенно-цифровые последовательности. Более того, обычно предпочитается, чтобы методика отображения, которая используется для перевода принятой последовательности компонентов информации, была той же методикой, что применяется на пользовательском устройстве для отображения пользовательского ввода в информацию, сформированную устройством. Однако могут быть случаи, где предпочтительно использовать другую методику отображения, нежели используется для ввода пользователя. Варианты осуществления настоящего изобретения также могут дать пользователям возможность выполнять поиски, введенные с использованием клавиатур с нецелевым языком. Например, веб-страница, содержащая текст на японском языке, может быть написана на кандзи, тогда как пользователь, пытающийся искать эту страницу, может иметь доступ только к стандартной клавиатуре ASCII (либо трубке) на основе латинского алфавита. Фиг. 7 иллюстрирует способ для выполнения подобного поиска. Как показано на фиг. 7, пользователь печатает запрос, используя стандартное устройство ввода (например, клавиатуру ASCII, телефонную трубку и т.д.), и отправляет запрос поисковой машине. Запрос может быть написан в наборе символов (например, ромадзи), который отличается от набора символов, в котором написаны некоторые из ответных документов (например, кандзи). Поисковая машина принимает запрос (этап 702), переводит его в релевантную форму(ы) (этап 704) и выполняет поиск документов, являющихся ответными на переведенный запрос, используя, например, традиционные методики поиска (этап 706). Поисковая машина затем возвращает список ответных документов (и/или копии самих документов) пользователю (этап 708). Например, результаты могут быть возвращены пользователю способом, похожим на описанный выше применительно к фиг. 6. Как показано на фиг. 7, пользовательский запрос переводится предпочтительно на сервере поисковой машины в противоположность клиенту, соответственно, освобождая пользователя от необходимости приобретать специализированное программное обеспечение для выполнения перевода. Однако будет принято во внимание, что в других вариантах осуществления часть или весь перевод мог бы выполняться на клиенте. Кроме того, в некоторых вариантах осуществления запрос может вводиться с использованием устройства, такого как клавишная панель телефона. В таких вариантах осуществления исходный цифровой запрос может сначала быть преобразован в буквенно-цифровую форму (например, ромадзи), используя методики отображения, описанные выше применительно к фиг. 5 и 6, включая, например, применение лексикона и/или вероятностных методик для отбрасывания маловероятных отображений (например, отображений, которые включают в себя сочетания букв, которые не встречаются в ромадзи). Как только буквенно-цифровой перевод запроса получен, могут выполняться остальные этапы, показанные на фиг. 7 (то есть 704, 706 и 708). Перевод запроса из одного набора символов или языка в другой (то есть этап 704 на фиг. 7) может выполняться различными путями. Одной из методик является использование обычного статического словаря значений слов или переводов, чтобы отобразить каждый термин в запросе в соответствующий термин в целевом языке или наборе символов. Однако проблема с этим подходом в том, что он будет часто выдавать неточные результаты, так как слова часто являются неоднозначными и запросы часто будут слишком короткими, чтобы обеспечить адекватные контекстные ключи для разрешения этой двусмысленности. Например, слово «bank» (банк) может относиться к речному берегу, финансовому учреждению или маневру самолета, соответственно, теоретически затрудняя безошибочный перевод. Кроме того, если словарь относительно небольшой и/или часто обновляется, он может не содержать элементы для всех терминов, с которыми может столкнуться поисковая машина, например редко используемые слова, жаргон, идиомы, имена собственные и т.п. Варианты осуществления настоящего изобретения могут использоваться для преодоления или улучшения части или всех этих проблем посредством использования вероятностного словаря для перевода терминов запроса из одного языка или набора символов (например, ASCII) в другой (например, кандзи). В предпочтительном варианте осуществления вероятностный словарь отображает одно множество терминов в другое множество терминов и ассоциативно связывает вероятность с каждым из отображений. Для удобства «термин» или «маркер» будет относиться к словам, фразам и/или (в большинстве случаев) последовательностям из одного или более символов, которые могут включать пробелы. Фиг. 8 показывает пример вероятностного словаря 800, такого как описан выше. Пример вероятностного словаря 800, показанный на фиг. 8, отображает слова, написанные на ромадзи (представление на латинском алфавите японского языка), в слова, написанные на кандзи (нелатинский, основанный на идеограммах набор японских символов). Чтобы облегчить объяснение, фиг. 8 изображает термины ромадзи как « Словарь 800 содержит элементы 808, 810, 812, 814 для различных терминов 802 ромадзи. Словарь также содержит возможные представления 804 каждого из этих терминов в кандзи вместе с соответствующей вероятностью 806, что каждое такое представление является правильным. Например, термин «bank» ромадзи может отображаться в термин кандзи, означающий «steep slope» (крутой откос) с вероятностью 0,3, в термин, означающий «financial institution», с вероятностью 0,4 и в термин, означающий «airplane maneuver», с вероятностью 0,2. С вероятностью 0,1 термин может отображаться в «other» (другое), что является просто общим способом предоставления возможности каждому термину отображаться в термины, которых может не быть в словаре. Следует принять во внимание, что пример, показанный на фиг. 8, создан для иллюстрации, что данный термин (например, слово «bank») в первом наборе символов или языке может отображаться в более чем один термин в другом наборе символов или языке. Специалисты в данной области техники, тем не менее, примут во внимание, что тогда, как ради ясности, отдельный пример на фиг. 8 иллюстрирует этот принцип, используя английские слова и значения, фактическое представление ромадзи слова «bank», например, может не быть неоднозначным таким же образом, как его английский эквивалент (например, может не быть неоднозначности в ромадзи между словом для финансового учреждения и словом для маневра самолета). Также следует принять во внимание, что для того, чтобы облегчить понимание, показанный на фиг. 8 словарь упрощен в других отношениях в той же степени. Например, реальный вероятностный словарь мог бы содержать гораздо больше возможных отображений для каждого термина или мог бы содержать только отображения, которые превышают предопределенный порог вероятности. Предпочтительные варианты осуществления настоящего изобретения используют такой вероятностный словарь для перевода запросов, выраженных на одном языке и/или наборе символов, в другой язык и/или набор символов, тем самым предоставляя пользователям возможность найти документы, написанные в другом наборе символов и/или языке, чем их исходный запрос. Например, если пользователь вводит запрос для «cars» (машины) на ромадзи, вероятностный словарь может использоваться для отображения термина ромадзи для «cars», например, в термин кандзи для «cars». Таким образом, пользователи могут искать документы, относящиеся к их запросам, даже если набор символов запросов (например, ромадзи) и набор символов совпадающих документов (например, кандзи) не являются одинаковыми. Подчеркиваем, что в этом конкретном примере реальный язык запроса не меняется (и ромадзи, и кандзи используются для выражения японского языка), только кодировка символов. В качестве еще одного примера термин «tired» (уставший) в английском ASCII может отображаться в термин «müde» (уставший) на немецком языке, используя кодировку символов Latin 1, так как символа умляут не существует в ASCII. Подчеркнем, что в этом примере словарь обеспечивает и перевод в другой язык (английский в немецкий), и перевод в другую кодировку символов (ASCII в Latin 1). В предпочтительных вариантах осуществления словарь отображения, описанный выше, строится автоматическим способом, используя информацию, доступную во всемирной сети совместно со статистическими методиками. Предпочтительные варианты осуществления используют параллельные, выровненные двуязычные своды, например текст привязки, написанный на различных языках и/или наборах символов, чтобы достичь точных переводов. Используя эти данные, предпочтительные варианты осуществления могут создавать словарь из возможных отображений слов. Это может быть сделано, например, путем простого подсчета количества раз, сколько маркер на языке Si (язык оригинала) встречается за то же время, что и маркер Tj (целевой язык) в выровненных текстовых парах (например, привязках, предложениях и т.д.). Будет принято во внимание, однако, что могла бы использоваться любая подходящая методика. В отсутствие достаточно больших и правильно выровненных множеств данных этот способ может порождать неоднозначные отображения многие-ко-многим. Так, например, можно только определить, что S1 мог бы отображаться в T2, T3, T7 и T8 с некоторой вероятностью. Однако это приемлемо и, как описывается более подробно ниже, в некоторых вариантах осуществления могут быть сделаны дополнительные усовершенствования для увеличения соответствующего правдоподобия каждого из отображений, например, посредством исследования предыдущих запросов пользователя, пользовательского выбора элементов на странице результатов и/или тому подобного. Фиг. 9 иллюстрирует использование параллельного текста привязки для построения вероятностного словаря. Текст привязки содержит текст, ассоциативно связанный с гиперссылкой между двумя веб-страницами (или местоположениями внутри данной веб-страницы). Например, в языке гипертекстовой разметки (HTML) команда «casa с вероятностью 0,5 house big big grande grande casa casa Представим, что теперь пользователь запрашивает поисковую машину с термином «casa». На этом этапе поисковая машина может вернуть страницы, которые содержат термин «casa», и также смешать N результатов, которые содержат только термин «house», и М результатов, которые содержат только термин «big». На практике N и M могут быть скорректированы, чтобы брать в расчет лежащие в основе вероятности отображений, так что относительно маловероятные отображения будут возникать в меньших отображаемых результатах. Если были обнаружены пользователи, на десять раз больше «щелкнувшие» на результаты, содержащие только термин «house», чем они щелкнули на результаты, содержащие только термин «big», вероятности отображения могли, например, быть скорректированы следующим образом: house house big big grande grande casa casa Отметим, что фактические количества могли зависеть от множества других факторов, например количество пользователей, чьи нажатия принимались в расчет, количество нажатий на страницы, содержащие оба термина, размещение результатов, содержащих данные термины, среди множества результатов и/или т.п. Также следует принимать во внимание, что скорректированные вероятности, данные в этом примере (то есть 0,1 и 0,9), предназначены для пояснительных целей. Специалист в данной области техники примет во внимание, что фактическое взвешивание, установленное на ответную реакцию пользователя, например ту, что описана выше, могло быть реализовано любым подходящим способом. Также отметим, что вышеупомянутый пример упрощен для облегчения объяснения использования ответной реакции пользователя. Например, в некоторых системах можно будет использовать информацию, полученную от других переводов, чтобы содействовать выполнению данного перевода. Например, в примере, который только что был представлен, даже если термин «house» возникает только в тексте привязки, который говорит «big house», все еще возможно определить, что «house» более уместно отображается в «casa», чем в «grande». Например, если уже определено, что «big» отображается в «grande» с очень высокой вероятностью и на достаточно большом множестве данных (и если допускалось, что текст привязки редко состоит из списка синонимов), то отображению house-to-casa могло быть всё же отдано предпочтение выше отображения house-to-grande, даже если привязки, содержащие «house» или «casa», были неубедительными. Точность перевода и/или пригодность результатов поиска также может быть улучшена посредством анализа истории сеанса пользовательских запросов. Например, во многих случаях система узнает (например, через cookie-файлы или информацию, сохраненную в учётной записи пользователя на сервере) предыдущие запросы, которые ввел пользователь. Эта предыстория может использоваться для ранжирования возможных значений (смыслов) запросов от этого пользователя, соответственно потенциально устраняя неоднозначность «bank» для относящихся к рыбной ловле запросов от относящихся к пилотированию. Таким образом, этот процесс может использоваться для сужения множества возможных переводов. В некоторых вариантах осуществления система может предложить их посредством отображения их применительно к сообщению, например «Did you mean to search for X» (Вы намеревались искать Х) в интерфейсе пользователя (где «Х» относится к прогнозируемому предпочтению перевода), наряду также с потенциальным отображением на первой странице результатов небольшого количества результатов от каждой из возможных переформулировок. Когда пользователь либо выбирает один из вариантов, предложенных посредством показа «did you mean D. Заключение Как подробно описано выше, способы и системы в соответствии с изобретением могут использоваться для предоставления результатов поиска в ответ на неоднозначные поисковые запросы и/или для перевода терминов в другой набор символов и/или языки. Описано многообразие методик и систем перевода и поиска. Тем не менее, будет принято во внимание, что предшествующее описание представлено для целей объяснения и что многие модификации и изменения возможны в свете вышеприведенных идей или посредством применения на практике изобретения. Например, хотя вышеупомянутое описание основывается на архитектуре «клиент-сервер», специалисты в данной области техники признают, что архитектура равноправных систем может использоваться в соответствии с изобретением. Кроме того, хотя описанная реализация включает в себя программное обеспечение, изобретение может быть реализовано как сочетание аппаратного обеспечения и программного обеспечения или исключительно аппаратного обеспечения. Кроме того, хотя особенности настоящего изобретения описываются как хранящиеся в памяти, специалист в данной области техники примет во внимание, что эти особенности также могут храниться на других типах машинно-читаемых носителей, например внешних запоминающих устройствах наподобие жестких дисков, дискет или компакт-дисков, несущих волнах от Интернета или других формах ОЗУ или ПЗУ. Объем изобретения, в силу вышесказанного, определяется формулой изобретения и ее эквивалентами.
Формула изобретения
1. Способ автоматического перевода терминов запроса из одного языка и/или набора символов в другой, содержащий этапы, на которых идентифицируют первое множество текста привязки, написанного в первом формате и содержащего данный термин; 2. Способ по п.1, в котором первый формат содержит первый набор символов, а второй формат содержит второй набор символов. 3. Способ по п.1, в котором первый формат содержит первый язык, а второй формат содержит второй язык. 4. Способ по п.1, в котором анализ второго множества текста привязки включает в себя идентификацию термина, который появляется наиболее часто во втором множестве текста привязки, и обозначение наиболее часто появляющегося термина как представления данного термина во втором формате. 5. Способ по п.1, в котором анализ второго множества текста привязки содержит этап, на котором вычисляют вероятность того, что данный термин соответствует термину во втором множестве текста привязки. 6. Способ по п.5, в котором вероятность получается с использованием, по меньшей мере, одного из байесовских методов, сглаживания гистограммы, сглаживания функции влияния и оценок сокращения. 7. Способ по п.5, в котором вероятность того, что данный термин соответствует термину во втором множестве текста привязки, получается путем деления количества вхождений термина во втором множестве текста привязки на общее количество вхождений всех терминов во втором множестве текста привязки. 8. Способ по п.1, в котором анализ второго множества текста привязки содержит этап, на котором вычисляют вероятность того, что данный термин соответствует каждому термину во втором множестве текста привязки. 9. Способ по п.1, в котором анализ второго множества текста привязки содержит этап, на котором идентифицируют термин, который появляется наиболее часто во втором множестве текста привязки. 10. Способ по п.2, в котором первый формат выбирается из группы, состоящей из ромадзи, ромадза и пиньинь, и в котором второй набор символов выбирается из группы, состоящей из кандзи, катакана, хирагана, хангыль, хандза и традиционных китайских символов. 11. Способ по п.1, в котором документы содержат веб-страницы. 12. Способ по п.1, дополнительно содержащий этапы, на которых получают запрос, написанный в первом формате и содержащий данный термин; переводят запрос во второй формат, по меньшей мере, частично на основе упомянутого этапа анализа; ищут в базе данных информацию, написанную во втором формате, которая соответствует переведенному запросу. 13. Способ по п.12, в котором этапы выполняются в перечисленном порядке. 14. Способ поиска информации в одном формате с использованием запросов, записанных в другом формате, содержащий этапы, на которых получают запрос от пользователя, написанный в первом формате; переводят запрос во второй формат, используя вероятностный словарь, при этом вероятностный словарь отображает термины из первого формата во второй формат; ищут в базе данных информацию, которая соответствует переведенному запросу; и возвращают пользователю результаты поиска, написанные во втором формате. 15. Способ по п.14, дополнительно содержащий этапы, на которых получают от пользователя варианты выбора результатов поиска; используют упомянутые варианты выбора результатов поиска для модифицирования вероятностного словаря отображений терминов. 16. Способ по п.15, в котором модификация содержит корректировку, по меньшей мере, одной вероятности, ассоциативно связанной, по меньшей мере, с одним отображением в вероятностном словаре. 17. Способ по п.14, в котором этап перевода запроса во второй формат включает в себя расширение запроса. 18. Способ по п.17, в котором расширенный запрос включает в себя альтернативные кодировки терминов запроса. 19. Способ по п.17, в котором расширенный запрос включает в себя альтернативные языковые переводы терминов запроса. 20. Способ по п.17, в котором расширенный запрос включает в себя альтернативные кодировки и альтернативные языковые переводы терминов запроса. 21. Способ по п.18, в котором расширенный запрос включает в себя синонимы альтернативных кодировок терминов запроса. 22. Способ для создания вероятностного словаря, причем упомянутый вероятностный словарь отображает термины в первом формате в термины во втором формате, упомянутый способ содержит этапы, на которых для данного термина идентифицируют первое множество данных в первом формате, которое содержит термин; идентифицируют второе множество данных во втором формате, которое выровнено с первым множеством данных; и анализируют второе множество данных, чтобы определить одну или более вероятностей, с которыми данный термин отображается в один или более терминов во втором множестве данных. 23. Способ по п.22, дополнительно содержащий этап, на котором добавляют данный термин в словарь вместе с одной или более вероятностями, с которыми данный термин отображается в один или более терминов во втором множестве данных. 24. Способ по п.23, дополнительно содержащий этап, на котором повторяют для каждого термина, который нужно добавить в словарь, упомянутые этапы идентификации первого множества данных, идентификации второго множества данных и анализа второго множества данных. 25. Способ по п.22, в котором первое множество данных содержит первое множество текста привязки, указывающего на множество из одной или более веб-страниц, и в котором второе множество данных содержит второе множество текста привязки, указывающего на то же множество из одной или более веб-страниц. 26. Способ по п.22, в котором первое множество данных содержит множество текста, написанного на первом языке, и в котором второе множество данных содержит то же множество текста, написанного на втором языке. 27. Способ по п.22, в котором вероятность, с которой данный термин отображается в термин во втором множестве данных, вычисляется посредством деления количества вхождений термина во втором множестве данных на общее количество терминов во втором множестве данных. 28. Способ по п.22, дополнительно содержащий этап, на котором модифицируют вероятность, с которой данный термин отображается в термин во втором множестве данных, по меньшей мере, частично на основе анализа пользовательского выбора результатов поиска. 29. Способ по п.22, дополнительно содержащий этап, на котором модифицируют вероятность, с которой данный термин отображается в термин во втором множестве данных, по меньшей мере, частично на основе анализа предыдущих пользовательских запросов. 30. Машиночитаемый носитель, содержащий команды, которые, будучи исполненными вычислительной системой, работают, чтобы заставить вычислительную систему выполнить действия, содержащие идентификацию первого множества текста привязки, написанного в первом формате и содержащего данный термин; идентификацию множества веб-страниц, на которые указывает первое множество текста привязки; идентификацию второго множества текста привязки, написанного во втором формате и указывающего на идентифицированное множество веб-страниц; определение вероятности того, что представление данного термина в первом формате соответствует представлению данного термина во втором формате. 31. Машиночитаемый носитель по п.30, дополнительно включающий в себя команды, которые, будучи исполненными вычислительной системой, работают, чтобы заставить вычислительную систему выполнить действия, содержащие модификацию вероятности того, что представление данного термина в первом формате соответствует представлению данного термина во втором формате, по меньшей мере, частично на основе анализа пользовательского выбора результатов поиска. 32. Машиночитаемый носитель по п.30, дополнительно включающий в себя команды, которые, будучи исполненными вычислительной системой, работают, чтобы заставить вычислительную систему выполнить действия, содержащие модификацию вероятности того, что представление данного термина в первом формате соответствует представлению данного термина во втором формате, по меньшей мере, частично на основе анализа предыдущих пользовательских запросов. 33. Машиночитаемый носитель по п.30, в котором вероятность определяется с использованием, по меньшей мере, частично одного из байесовских методов, сглаживания гистограммы, сглаживания функции влияния и оценок сокращения. 34. Способ перевода представленного на первом языке или наборе символов запроса на второй язык или набор символов, содержащий этапы, на которых идентифицируют первую часть текста, написанную в первом формате; идентифицируют вторую часть текста, написанную во втором формате, вторую часть текста, выравниваемую с первой частью текста; создают словарь переводов между терминами в первой части текста и терминами во второй части текста посредством сравнения вхождения терминов в первой части текста с вхождением терминов во второй части текста. 35. Способ по п.34, в котором словарь переводов включает в себя одну или более вероятностей, ассоциативно связанных с переводами. 36. Способ по п.34, в котором первый формат содержит первый набор символов, а второй формат содержит второй набор символов. 37. Способ по п.34, в котором первый формат содержит первый язык, а второй формат содержит второй язык. 38. Способ по п.34, в котором первая часть текста содержит текст привязки, и вторая часть текста содержит текст привязки. 39. Способ для выполнения поисков с использованием потенциально неоднозначных запросов, содержащий этапы, на которых принимают запрос, содержащий, по меньшей мере, один термин запроса, написанный в первом формате; переводят термин запроса во множество вариантов, написанных во втором формате; и используют один или более вариантов для поиска информации, написанной во втором формате, которая является ответной на запрос. 40. Способ по п.39, в котором первый формат содержит последовательность цифр, введенных с клавишной панели телефона; и в котором второй формат содержит буквенно-цифровой текст. 41. Способ по п.39, дополнительно содержащий этап, на котором получают один или более вариантов посредством отбрасывания вариантов в множестве вариантов, которые не являются частью предопределенного лексикона. 42. Способ по п.39, дополнительно содержащий этап, на котором получают один или более вариантов посредством отбрасывания вариантов в множестве вариантов, которые содержат предопределенные маловероятные сочетания символов. 43. Способ по п.39, в котором первый формат содержит буквенно-цифровой текст, написанный в наборе символов, выбранном из группы, состоящей из ромадзи, ромадза и пиньинь, и в котором второй формат содержит буквенно-цифровой текст, написанный в наборе символов, выбранном из группы, состоящей из кандзи, катакана, хирагана, хангыль, хандза и традиционных китайских символов. 44. Способ для выполнения поисков с использованием потенциально неоднозначных запросов, содержащий этапы, на которых принимают цифровой запрос, введенный с клавишной панели телефона; переводят цифровой запрос в группу потенциальных буквенно-цифровых переводов в первом формате; отбрасывают потенциальные переводы, которые определяются как включающие предопределенные маловероятные сочетания символов; переводят оставшиеся буквенно-цифровые переводы из первого формата во второй формат, используя вероятностный словарь; и выполняют поиск, используя буквенно-цифровые переводы во втором формате. 45. Способ по п.44, в котором первый формат содержит текст, написанный в наборе символов, выбранном из группы, состоящей из ромадзи, ромадза и пиньинь, и в котором второй формат содержит текст, написанный в наборе символов, выбранном из группы, состоящей из кандзи, катакана, хирагана, хангыль, хандза и традиционных китайских символов.
РИСУНКИ
|
||||||||||||||||||||||||||
 595
595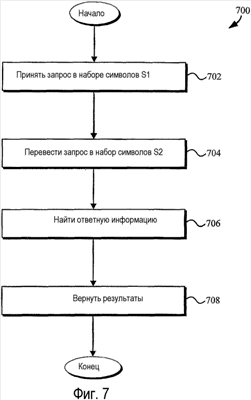
 b
b bar
bar