Патент на изобретение №2352979
|
||||||||||||||||||||||||||
(54) СИНХРОННОЕ ПОНИМАНИЕ СЕМАНТИЧЕСКИХ ОБЪЕКТОВ ДЛЯ ВЫСОКОИНТЕРАКТИВНОГО ИНТЕРФЕЙСА
(57) Реферат:
Изобретение относится к доступу к информации в компьютерной системе с использованием распознавания и понимания. Изобретение обеспечивает осуществление распознавания ввода пользователя до завершения ввода пользователя, то есть на пользовательском, а не на системном этапе, что позволяет отойти от поочередного характера разговорного диалога с компьютером. Изобретение обеспечивает режим речевого ввода, который динамически сообщает частичные семантические анализы в то время, как восприятие аудиосигнала все еще продолжается. Семантические анализы можно оценивать по исходу, немедленно сообщаемому пользователю. 5 н. и 19 з.п. ф-лы, 7 ил.
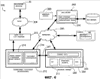
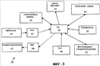
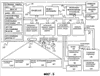
Предпосылки изобретения Настоящее изобретение относится к доступу и представлению информации в компьютерной системе. В частности, настоящее изобретение относится к доступу к информации с использованием распознавания и понимания. В последнее время появилась технология, позволяющая пользователю обращаться к информации в компьютерной системе посредством речевых команд. Получив команду пользователя, компьютерная система осуществляет распознавание речи на устройстве пользовательского ввода и далее обрабатывает вводимые данные, чтобы выявить намерение пользователя в отношении действия, которое должна выполнить компьютерная система. В некоторых случаях ввод, обеспечиваемый пользователем, является неполным или неопределенным, из-за чего компьютерной системе требуется запрашивать у пользователя дополнительную информацию посредством визуальных или звуковых приглашений. Таким образом, между пользователем и компьютерной системой может установиться диалог, в котором стороны по очереди задают вопросы, получают ответы и/или подтверждения, пока не будет выяснено намерение пользователя и не будет выполнено действие. В других случаях создание такого диалога является предпочтительным режимом для взаимодействия с компьютерной системой. Для облегчения речи как жизнеспособной модальности ввода/вывода для современной конструкции пользовательского интерфейса был внедрен формат SALT (Speech Application Language Tags) [тэги языка речевого приложения]. Конструктивной задачей SALT является упрощение обычных речевых заданий для программы и в то же время обеспечение расширенных возможностей с непосредственной реализацией. SALT разработан для многих приложений. Таковым является, например, чисто речевое телефонное приложение, взаимодействующее с пользователями исключительно посредством разговорного диалога. SALT включает в себя входной и выходной речевые объекты («слушать» ( Однако в разговоре между людьми обычно не существует переключаемого, упорядоченного диалога между участниками. Напротив, разговоры могут включать в себя квитирования, подтверждения, вопросы со стороны одного участника и т.д., тогда как другой предоставляет информацию, которая может существенно влиять, незначительно влиять или совсем не влиять на способ, которым говорящий предоставляет информацию. Людям, ведущим разговор, нравится такая естественная форма общения. Аналогично, в телефонных системах применяется полнодуплексная технология, позволяющая вести такие разговоры. Напротив, в диалоговых интерфейсах применяется режим работы с жестким переключением между пользователем и компьютерной системой, в результате чего компьютерной системе приходится ожидать окончания диалога с пользователем прежде, чем начать обработку и выполнить следующее действие. Хотя простая обратная связь, например визуальные указания наподобие увеличивающегося количества точек на экране компьютера, может давать пользователю некоторую уверенность в том, что компьютерная система, по меньшей мере, что-то обрабатывает, пока пользователь не закончит свой этап, и компьютерная система не ответит, степень понимания компьютерной системы неизвестна. Соответственно, требуется усовершенствовать компьютерные системы, основанные на распознавании и понимании. Такие усовершенствования обеспечивают систему или способ доступа к информации, которые были бы проще в использовании благодаря большей естественности для пользователя. Сущность изобретения Способ и система обеспечивают режим речевого ввода, который динамически сообщает частичные результаты семантического анализа в то время, как восприятие аудиосигнала все еще продолжается. Результаты семантического анализа можно оценивать по исходу, немедленно сообщаемому пользователю. Конечный эффект состоит в том, что задания, традиционно выполняемые на системном этапе, теперь выполняются во время пользовательского этапа, что представляет собой значительный отход от поочередного характера разговорного диалога. В целом, один аспект настоящего изобретения включает в себя компьютерно-реализуемый способ взаимодействия с компьютерной системой. Способ включает в себя получение вводимых данных от пользователя и восприятие вводимых данных для обработки. Затем при вводе, последовательно или параллельно, осуществляется распознавание для получения семантической информации, относящейся к первой части ввода, и вывод семантического объекта. Семантический объект включает в себя данные в формате, подлежащем обработке компьютерным приложением, т.е. в соответствии с распознанным вводом (например, текста, зашифрованного текста, сжатого текста и т.д.), а также семантическую информацию для первой части. Согласно указанному выше, операции распознавания и вывода семантического объекта осуществляются в то время, когда продолжается восприятие последующих частей ввода. Этот способ можно реализовать для распознавания звукового ввода, например речи, а также для незвукового ввода, например визуального ввода или рукописного ввода. Вышеозначенный способ можно реализовать посредством компьютерно-считываемого носителя, который содержит команды, считываемые вычислительным устройством, реализация которых приводит к тому, что вычислительное устройство обрабатывает информацию и осуществляет способ. Согласно другому варианту осуществления компьютерно-считываемый носитель может включать в себя команды для установления языковой модели для осуществления распознавания и понимания. Языковая модель предназначена для обеспечения данных в формате, соответствующем распознанному вводу, и для обеспечения семантической информации для полученного ввода. Краткое описание чертежей Фиг.1 – блок-схема системы представления данных. Фиг.2 – схематический вид операционной среды вычислительного устройства. Фиг.3 – блок-схема вычислительного устройства, изображенного на фиг.2. Фиг.4 – схематический вид телефона. Фиг.5 – блок-схема компьютера общего назначения. Фиг.6 – блок-схема архитектуры системы клиент-сервер. Фиг.7 – блок-схема модуля распознавания и понимания речи. Подробное описание иллюстративных вариантов осуществления изобретения На фиг.1 показана блок-схема системы 10 представления данных для представления данных на основании голосового ввода. Система 10 содержит модуль 12 речевого интерфейса, модуль 14 распознавания и понимания речи и модуль 16 представления (воспроизведения) данных. Пользователь обеспечивает ввод данных в виде голосового запроса на модуль 12 речевого интерфейса. Модуль 12 речевого интерфейса собирает речевую информацию от пользователя и выдает сигнал, указывающий это. После того, как модуль 12 речевого интерфейса примет входную речь, модуль 14 распознавания и понимания речи распознает речь с использованием распознавателя речи, а также осуществляет понимание речи, при котором согласно одному аспекту настоящего изобретения обеспечивают частичные семантические анализы полученных к этому времени введенных данных, в то время, как все еще продолжается восприятие аудиосигнала речевого ввода. Частичные результаты семантического анализа, которые обычно включают в себя текст для полученного ввода (или другие данные, указывающие текст ввода), а также выявленную семантическую информацию, поступают на модуль 16 приложения, который может принимать многообразные формы. Например, в одном варианте осуществления модуль приложения может представлять собой электронную записную книжку и использоваться для отправки, получения сообщений электронной почты и ответа на них, организации встреч и т.п. Таким образом, пользователь может выдавать звуковые (слышимые) команды для выполнения этих задач. Тем не менее, важнее то, что модуль 16 приложения может обеспечивать интерактивную обратную связь и/или выполнять действия над информацией частичных результатов семантического анализа по мере их поступления, тем самым обеспечивая пользователя высокоинтерактивным интерфейсом для модуля 16 приложения. Например, при работе в чисто голосовом режиме выходные данные 20 могут содержать слышимые утверждения, обращенные к пользователю, хотя, конечно, возможно выполнение других задач, относящихся к приложению. Частичные результаты семантического анализа или семантические объекты можно использовать для выполнения диалоговой логики в приложении. Например, диалоговая логика может представлять пользователю опцию или совокупность, или список опций на основании одного или более семантических объектов. Это позволяет системе 10 немедленно сообщать исходы, основанные на частичном фрагменте речи, а именно до окончания пользовательского этапа. Другими словами, благодаря использованию связи по обратному каналу для сообщения и выполнения задания, обычно связанного с системным этапом, определение пользовательского и системного этапов размывается. В большинстве исследований традиционного диалога, особенно основанных на диалогах между людьми, часто рассматривается связь по обратному каналу как ненавязчивую обратную связь, которая переносит только простые сигналы, например, положительного, отрицательного или нейтрального квитирования (подтверждения). Однако обратная связь, обеспеченная выходом 20, может потенциально нести больше информации, тем самым являясь несколько более навязчивой по отношению к продолжающемуся пользовательскому фрагменту речи, которая может понуждать или не понуждать пользователя пояснять намерения или директивы пользователя. Тем не менее, этот подход обеспечивает более реалистический человеческий диалог между пользователем и системой 10, что во многих случаях не будет считаться докучливым, но, напротив, более удобным для пользователя, и устанавливать нужную пользователю степень конфиденциальности. В этой связи следует заметить, что настоящее изобретение не ограничивается исключительно голосовой операционной средой, но, напротив, может включать в себя другие формы обратной связи с пользователем на основании обработки частичных семантических анализов или объектов. Например, в рассмотренном выше применении, где модуль 16 приложения выполняет задания электронной почты, выходной сигнал 20 может включать в себя визуальную обратную связь, например активацию модуля электронной почты только на основании выражения, например, «Отправить электронную почту» в непрерванной команде от пользователя, содержащей «Отправить электронную почту Бобу», причем обработка выражения «Бобу» может принудить модуль приложения обратиться к дополнительной информации в хранилище данных 18 и представить список людей, носящих имя «Боб». Просматривая список, пользователь легко идентифицирует нужного получателя как «Боб Грин», которого затем можно выбрать, поскольку система получила бы другой семантический объект для частичного фрагмента речи «Боб Грин», который, будучи получен приложением и обработан, приводит к выбору «Боб Грин». Согласно указанному выше, модуль 16 приложения может принимать многочисленные формы, в которых могут иметь преимущество аспекты настоящего изобретения, дополнительно рассмотренные ниже. Без ограничения, модуль 16 приложения может также быть модулем диктовки для обеспечения текстового вывода произносимого ввода пользователя. Однако благодаря также обработке семантической информации для частичного ввода или выражений ввода можно получить более точную транскрипцию. Хотя описанное выше в отношении ввода от пользователя, содержащего голосовые команды, аспекты настоящего изобретения можно также применять к другим формам ввода, например рукописному вводу, ДТМЧН (двухтональному многочастотному набору), жестам или визуальным указаниям. Ввиду широкой применимости обработки частичных семантических выражений или объектов может быть полезно описать в общих чертах вычислительные устройства, которые могут функционировать в вышеописанной системе 10. Специалистам в данной области известно, что компоненты системы 10 могут размещаться в одном компьютере или распределяться по распределенной вычислительной среде, в которой используются сетевые соединения и протоколы. На фиг.2 представлена иллюстративная форма мобильного устройства, например устройства управления данными (электронная записная книжка ЭЗК, персональный цифровой ассистент-ПЦА и др.), обозначенная позицией 30. Однако предполагается, что настоящее изобретение можно также осуществлять на практике с использованием других вычислительных устройств, рассмотренных ниже. Например, не пользовать преимущества настоящего изобретения могут также телефоны и/или устройства управления данными. Такие устройства будут более полезны, чем существующие портативные персональные устройства управления информацией или другие портативные электронные устройства. В иллюстративной форме мобильного устройства 30 управления данными, показанном на фиг.2, мобильное устройство 30 содержит корпус 32 и имеет пользовательский интерфейс, включающий в себя дисплей 34, в котором используется сенсорный экран в сочетании с пером 33. Перо 33 используется для нажима на дисплей 34 или касания его в указанных координатах для выбора поля, избирательного перемещения начального положения курсора или иного обеспечения командной информации, например, посредством жестов или рукописного ввода. Альтернативно или дополнительно, в состав устройства 30 может входить одна или несколько кнопок 35 для навигации. Кроме того, можно предусмотреть другие механизмы ввода, например вращающиеся колесики, ролики и т.п. Однако следует заметить, что изобретение не призвано ограничиваться этими формами механизмов ввода. Например, другая форма ввода может включать в себя визуальный ввод, например, посредством компьютерного визуального восприятия. На фиг.3 изображена блок-схема, на которой показаны функциональные компоненты мобильного устройства 30. Центральный процессор (ЦП) 50 реализует функции управления программного обеспечения. ЦП 50 подключен к дисплею 34, чтобы текст и графические иконки, генерируемые в соответствии с управляющим программным обеспечением, появлялись на экране 34. Громкоговоритель 43 обычно подключен к ЦП 50 через цифроаналоговый преобразователь 59 для обеспечения слышимого выходного сигнала. Данные, загружаемые или вводимые пользователем в мобильное устройство 30, сохраняются в энергонезависимом запоминающем устройстве 54 произвольного доступа для чтения/записи, двусторонне подключенном к ЦП 50. Память произвольного доступа (ЗУПД) 54 обеспечивает временное хранение команд, выполняемых ЦП 50, и хранение временных данных, например значений регистров. Значения по умолчанию для опций настройки и других переменных хранятся в постоянной памяти (ПЗУ) 58. ПЗУ 58 также может использоваться для хранения программного обеспечения операционной системы для устройства, которая управляет основными функциями мобильного устройства 30 и другими функциями ядра операционной системы (например, загрузкой компонентов программного обеспечения в ЗУПД 54). ЗУПД 54 также используется в качестве хранилища для кода наподобие жесткого диска на ПК, который применяется для хранения прикладных программ. Заметим, что хотя для хранения кода используется энергонезависимая память, его альтернативно можно хранить в энергозависимой памяти, которая не используется для выполнения кода. Мобильное устройство может передавать/принимать беспроводные сигналы через беспроводной приемопередатчик 52, подключенный к ЦП 50. Необязательный интерфейс 60 связи может также быть предусмотрен для загрузки данных, по желанию, непосредственно от компьютера (например, настольного компьютера) или из проводной сети. Соответственно, интерфейс 60 может содержать различные формы устройств связи, например устройство инфракрасной связи, модем, сетевую карту и т.п. Мобильное устройство 30 включает в себя микрофон 29 и аналого-цифровой преобразователь (АЦП) 37 и необязательную программу распознавания (речи, ДТМЧН, рукописного ввода, жестов или компьютерного визуального восприятия), хранящуюся в памяти 54. Например, в ответ на звуковую информацию, инструкции или команды от пользователя устройства 30, микрофон 29 выдает речевые сигналы, которые оцифровываются АЦП 37. Программа распознавания речи может осуществлять функции нормализации и/или извлечения признаков на оцифрованных речевых сигналах для получения промежуточных результатов распознавания речи. Используя беспроводной приемопередатчик 52 или интерфейс связи 60, речевые данные можно передавать на удаленный сервер 204 распознавания, рассмотренный ниже и проиллюстрированный в архитектуре, показанной на фиг.6. Затем результаты распознавания могут возвращаться на мобильное устройство 30 для представления (например, визуального и/или звукового) на нем и для возможной передачи на веб-сервер 202 (фиг.6), причем веб-сервер 202 и мобильное устройство 30 соотносятся как сервер и клиент соответственно. Аналогичную обработку можно использовать для других форм ввода. Например, рукописный ввод можно оцифровывать с предварительной обработкой на устройстве 30 и без нее. Как и речевые данные, эту форму ввода можно передавать на сервер 204 распознавания для распознавания, причем результаты распознавания возвращаются на устройство 30 и/или веб-сервер 202. Данные ДЧМТН, данные жеста и визуальные данные можно обрабатывать аналогичным образом. В зависимости от формы ввода (вводимого сигнала), устройство 30 (и другие формы клиентов, рассмотренные ниже) будут включать в себя необходимое оборудование, например камеру для визуального ввода. На фиг.4 показан схематичный вид иллюстративного варианта осуществления портативного телефона 80. Телефон 80 включает в себя дисплей 82 и клавиатуру 84. В целом, блок-схема, показанная на фиг.3, применима к телефону, показанному на фиг.4, хотя может потребоваться дополнительная схема, необходимая для осуществления других функций. Например, для варианта осуществления, показанного на фиг.3, может потребоваться приемопередатчик, действующий как телефон; однако такая схема не относится к настоящему изобретению. Нужно также понимать, что помимо вышеописанных портативных или мобильных вычислительных устройств, настоящее изобретение можно использовать со многими другими вычислительными устройствами, например настольным компьютером общего назначения. Например, настоящее изобретение позволит пользователю с ограниченными физическими возможностями вводить текст в компьютер или другое вычислительное устройство, когда другие традиционные устройства ввода, например полную буквенно-цифровую клавиатуру, слишком трудно применять. Изобретение также применимо ко многим другим вычислительным системам, средам или конфигурациям общего или специального назначения. Примеры общеизвестных вычислительных систем, сред и/или конфигураций, которые могут быть пригодны для использования в соответствии с изобретением, включают в себя, но не исключительно, обычные телефоны (без экрана), персональные компьютеры, компьютеры-серверы, карманные или портативные компьютеры, планшетные компьютеры, многопроцессорные системы, системы на основе микропроцессора, телевизионные приставки, программируемая бытовая электроника, сетевые ПК, миникомпьютеры, универсальные компьютеры, распределенные вычислительные среды, которые включают в себя любые из вышеперечисленных систем или устройств и т.п. Ниже приведено краткое описание компьютера 120 общего назначения, показанного на фиг.5. Однако компьютер 120 является всего лишь примером подходящего вычислительного устройства и не призван как-либо ограничивать объем использования или функциональные возможности изобретения. Также, компьютер 120 не следует рассматривать как имеющий какую-либо зависимость или требование в отношении к любому из проиллюстрированных здесь компонентов или их комбинации. Изобретение можно описать в общем контексте компьютерно-выполняемых команд, например программных модулей, выполняемых компьютером. В целом, программные модули включают в себя процедуры, программы, объекты, компоненты, структуры данных и т.п., которые выполняют конкретные задания или реализуют определенные абстрактные типы данных. Изобретение также можно применять на практике в распределенных вычислительных средах, где задания выполняются удаленными обрабатывающими устройствами, связанными посредством сети связи. В распределенной вычислительной среде программные модули могут размещаться как на локальных, так и на удаленных компьютерных носителях данных, включая запоминающие устройства. Задания, выполняемые программами и модулями, описаны ниже со ссылками на чертежи. Специалисты в данной области могут реализовать описание и чертежи в виде команд, выполняемых процессором, которые могут быть записаны на компьютерно-считываемых носителях любого типа. Согласно фиг.5 компоненты компьютера 120 могут включать в себя, но не исключительно, процессор 140, системную память 150 и системную шину 141, которая соединяет различные компоненты системы, включая системную память, к процессору 140. Системная шина 141 может относиться к любому из нескольких типов шинных структур, включая шину памяти или контроллер памяти, периферийную шину и локальную шину, с использованием разнообразных шинных архитектур. В порядке примера, но не ограничения, такие архитектуры включают в себя шину архитектуры промышленного стандарта (ISA), шину микроканальной архитектуры (MCA), шину расширенного стандарта ISA (EISA), локальную шину Ассоциации по стандартам в области видеоэлектроники (VESA) и шину подключений периферийных компонентов (PCI), также именуемую шиной «Mezzanine» (расширения). Компьютер 120 обычно содержит разнообразные компьютерно-считываемые носители. Компьютерно-считываемые носители могут представлять собой любые имеющиеся носители, к которым может осуществлять доступ компьютер 120, и включают в себя энергозависимые и энергонезависимые носители, сменные и стационарные носители. В порядке примера, но не ограничения, компьютерно-считываемый носитель может представлять собой компьютерный носитель данных или среду передачи данных. Компьютерные носители данных включают в себя энергозависимые и энергонезависимые, сменные и стационарные носители, реализованные посредством любого способа или технологии для хранения информации, например компьютерно-считываемых команд, структур данных, программных модулей или других данных. Компьютерные носители данных включают в себя, но не исключительно, ОЗУ, ПЗУ, ЭСППЗУ, флэш-память или другую технологию памяти, CD-ROM, цифровые универсальные диски (DVD) или иные оптические дисковые носители данных, магнитные кассеты, магнитную ленту, магнитные дисковые носители данных или иные магнитные запоминающие устройства или любой другой носитель, который можно использовать для хранения полезной информации и к которому компьютер 120 может осуществлять доступ. Среды передачи данных обычно воплощают компьютерно-считываемые команды, структуры данных, программные модули или другие данные в виде модулированного сигнала данных, например несущей волны или иного транспортного механизма. Среды передачи данных также включают в себя любые среды доставки информации. Термин «модулированный сигнал данных» означает сигнал, одна или несколько характеристик которого изменяется так, чтобы кодировать информацию в сигнале. В порядке примера, но не ограничения, среды передачи данных содержат проводные среды, например проводную сеть или прямое проводное соединение, и беспроводные среды, например акустические, РЧ, инфракрасные и другие беспроводные среды. В число компьютерно-считываемых сред входят также комбинации любых из вышеперечисленных позиций. Системная память 150 содержит компьютерные носители данных в виде энергозависимой и/или энергонезависимой памяти, например постоянной памяти (ПЗУ) 151 и оперативной памяти (ОЗУ) 152. Базовая система ввода/вывода (BIOS) 153, содержащая основные процедуры, которые помогают переносить информацию между элементами компьютера 120, например при запуске, хранится в ПЗУ 151. ОЗУ 152 обычно содержит данные и/или программные модули, которые непосредственно доступны процессору 140 и/или в данный момент обрабатываются им. В порядке примера, но не ограничения, на фиг.5 показаны операционная система 154, прикладные программы 155, другие программные модули 156 и программные данные 157. Компьютер 120 может также включать в себя другие сменные/стационарные, энергозависимые/энергонезависимые компьютерные носители данных. В качестве примера на фиг.5 показан жесткий диск 161, который производит считывание со стационарного энергонезависимого магнитного носителя и запись на него, привод 171 магнитного диска, который производит считывание со сменного энергонезависимого магнитного диска 172 и запись на него, и привод 175 оптического диска, который производит считывание со сменного энергонезависимого оптического диска 176, например CD-ROM или другого оптического носителя, и запись на него. Другие сменные/стационарные, энергозависимые/ энергонезависимые компьютерные носители данных, которые можно использовать в иллюстративной операционной среде, включают в себя, но не исключительно, кассеты с магнитной лентой, карты флэш-памяти, цифровые универсальные диски, ленту для цифрового видео, полупроводниковое ОЗУ, полупроводниковое ПЗУ и т.д. Жесткий диск 161 обычно подключен к системной шине 141 посредством интерфейса стационарной памяти, например интерфейса 160, а привод 171 магнитного диска и привод 175 оптического диска обычно подключены к системной шине 141 посредством интерфейса сменной памяти, например интерфейса 170. Приводы и соответствующие компьютерные носители данных, описанные выше и показанные на фиг.5, обеспечивают хранение компьютерно-считываемых команд, структур данных, программных модулей и других данных для компьютера 120. Например, на фиг.5 показано, что на жестком диске 161 хранятся операционная система 164, прикладные программы 165, другие программные модули 166 и программные данные 167. Заметим, что эти компоненты могут быть идентичны операционной системе 154, прикладным программам 155, другим программным модулям 156 и программным данным 157 или отличны от них. Операционная система 164, прикладные программы 165, другие программные модули 166 и программные данные 167 обозначены здесь другими позициями, чтобы показать, что они, как минимум, представляют собой разные копии. Пользователь может вводить команды и информацию в компьютер 120 посредством устройства ввода, например клавиатуры 182, микрофона 183, и указательного устройства 181, например мыши, шарового манипулятора или сенсорной панели. Другие устройства ввода (не показаны) могут включать в себя джойстик, игровую панель, спутниковую антенну, сканер и т.п. Эти и другие устройства ввода часто подключают к процессору 140 через интерфейс 180 пользовательского ввода, который подключен к системной шине, но можно подключать посредством других структур интерфейса и шины, например параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 184 или устройство отображения другого типа также подключен к системной шине 141 через интерфейс, например видеоинтерфейс 185. Помимо монитора, компьютеры могут содержать другие периферийные устройства вывода, например громкоговорители 187 и принтер 186, которые могут быть подключены через периферийный интерфейс 188 вывода. Компьютер 120 может работать в сетевой среде с использованием логических соединений с одним или несколькими удаленными компьютерами, например удаленным компьютером 194. В качестве удаленного компьютера 194 может выступать персональный компьютер, портативное устройство, сервер, маршрутизатор, сетевой ПК, равноправное устройство или другой общий сетевой узел, который обычно содержит многие или все элементы, описанные выше применительно к компьютеру 120. Логические соединения, указанные на фиг.5, включают в себя локальную сеть (ЛС) 191 и глобальную сеть (ГС) 193, но также могут включать в себя другие сети. Такие сетевые среды обычно используются в офисных, производственных компьютерных сетях, интрасетях и в Интернете. При использовании в сетевой среде ЛС компьютер 120 подключен к ЛС 191 через сетевой интерфейс или адаптер 190. При использовании в сетевой среде ГС компьютер 120 обычно содержит модем 192 или другие средства установления соединений по ГС 193, например Интернет. Модем 192, который может быть внутренним или внешним, может быть подключен к системной шине 141 через интерфейс 180 пользовательского ввода или другой соответствующий механизм. В сетевой среде программные модули, указанные в отношении компьютера 120, или часть из них могут храниться в удаленном запоминающем устройстве. В качестве примера, но не ограничения, на фиг.5 показано, что удаленные прикладные программы 195 размещены в запоминающем устройстве 194. Очевидно, что показанные сетевые соединения являются иллюстративными, и что можно использовать другие средства установления линии(й) связи между компьютерами. На фиг.6 показана архитектура 200 для распознавания и представления данных на сетевой основе, которая является одним иллюстративным вариантом осуществления настоящего изобретения. В целом, к информации, хранящейся на веб-сервере 202, можно осуществлять доступ через клиента 100, например мобильное устройство 30 или компьютер 120 (который здесь представляет другие формы вычислительных устройств, имеющих экран дисплея, микрофон, камеру, сенсорную панель и т.д., необходимые в зависимости от типа ввода), или через телефон 80, в котором информация запрашивается голосом или посредством тонов, генерируемых телефоном 80 при нажатии клавиш, причем информация поступает от веб-сервера 202 обратно к пользователю только в звуковом виде. Согласно этому варианту осуществления, архитектура 200 универсальна в том смысле, что всякий раз при получении информации через клиент 100 или телефон 80 с использованием распознавания речи один сервер 204 распознавания может поддерживать любой режим работы. Кроме того, архитектура 200 действует с использованием расширения общеизвестных языков разметки (например, HTML, XHTML, cHTML, XML, WML и т.п.). Таким образом, к информации, хранящейся на веб-сервере 202, можно также осуществлять доступ с использованием общеизвестных способов ГИП (графического интерфейса пользователя), имеющихся в этих языках разметки. Использование расширения общеизвестных языков разметки позволяет упростить работу авторской системы на веб-сервере 202 и легко модифицировать существующие в настоящее время унаследованные приложения также для включения распознавания голоса. В общем случае, клиент 100 выполняет страницы HTML, сценарии и т.п., обозначенные общей позицией 206, предоставленные веб-сервером 202, с использованием обозревателя (браузера). Когда требуется распознавание голоса, например речевые данные, которые могут быть оцифрованными аудиосигналами или речевыми признаками, причем аудиосигналы предварительно обработаны клиентом 100 согласно рассмотренному выше, поступают на сервер 204 распознавания с указанием грамматической или языковой модели 220, используемой при распознавании речи, которая может быть обеспечиваться клиентом 100. Альтернативно, языковую модель может содержать речевой сервер 204. Реализация сервера 204 распознавания может принимать многочисленные формы, одна из которых проиллюстрирована, но в общем случае содержит распознаватель 211. Результаты распознавания поступают обратно на клиент 100 для локального представления, по желанию или необходимости. При желании, для передачи на клиент 100 произносимого текста можно использовать модуль 222 преобразования текст-в-речь. После компиляции информации посредством распознавания и любого графического интерфейса пользователя, если таковой используется, клиент 100 отправляет эту информацию на веб-сервер 202 для дальнейшей обработки и приема дополнительных страниц HTML/сценариев, при необходимости. Согласно фиг.6, клиент 100, веб-сервер 202 и сервер 204 распознавания связаны друг с другом и раздельно адресуемы через сеть 205, в данном случае глобальную сеть, например, Интернет. Поэтому эти устройства не обязаны физически располагаться рядом друг с другом. В частности, веб-сервер 202 не обязательно включает в себя сервер 204 распознавания. Таким образом, авторская система на веб-сервере 202 может сосредоточиться на приложении, для которого она предназначена, и авторам не нужно вникать в детали работы сервера 204 распознавания. Напротив, сервер 204 распознавания может быть независимым устройством, подключенным к сети 205 и таким образом иметь возможность обновления или усовершенствования, не влекущего необходимость в дополнительных изменениях на веб-сервере 202. Веб-сервер 202 может также включать в себя механизм авторской системы, способный динамически генерировать разметки и сценарии клиентской стороны. Согласно другому варианту осуществления, веб-сервер 202, сервер 204 распознавания и клиент 100 могут быть объединены в зависимости от возможностей реализующих машин. Например, если клиент 100 содержит компьютер общего назначения, например персональный компьютер, то клиент может включать в себя сервер 204 распознавания. Аналогично, при желании, веб-сервер 202 и сервер 204 распознавания можно включить в состав одной машины. Доступ к веб-серверу 202 через телефон 80 включает в себя подключение телефона 80 к проводной или беспроводной телефонной сети 208, которая, в свою очередь, подключает телефон 80 к шлюзу 210 третьей стороны. Шлюз 210 подключает телефон 80 к телефонному голосовому обозревателю (браузеру) 212. Телефонный голосовой обозреватель 212 содержит медиа-сервер 214, который обеспечивает телефонный интерфейс и голосовой обозреватель (браузер) 216. Как и клиент 100, телефонный голосовой обозреватель 212 принимает от веб-сервера 202 страницы HTML/сценарии и т.п. Согласно одному варианту осуществления, страницы HTML/сценарии сходны со страницами HTML/сценариями, поступающими на клиент 100. Таким образом, веб-серверу 202 не нужно по отдельности поддерживать клиент 100 и телефон 80 и даже не нужно по отдельности поддерживать стандартные клиенты ГИП. Напротив, можно использовать общий язык разметки. Кроме того, аналогично клиенту 100, распознавание голоса из слышимых сигналов, передаваемых телефоном 80, поступает от голосового обозревателя 216 на сервер 204 распознавания либо по сети 205, либо по выделенной линии 207, например, с использованием TCP/IP. Веб-сервер 202, сервер 204 распознавания и телефонный голосовой обозреватель 212 можно реализовать в любой подходящей вычислительной среде, например настольном компьютере общего пользования, показанном на фиг.5. Описав различные среды и архитектуры, действующие в системе 10, обратимся к более подробному описанию различных компонентов и функций системы 10. На фиг.7 показана блок-схема модуля 14 распознавания и понимания речи. Входная речь, принятая от модуля 12 речевого интерфейса, поступает на модуль 14 распознавания и понимания речи. Модуль 14 распознавания и понимания речи содержит машину (механизма) 310 распознавания, с которой связана языковая модель 310. Машина 306 распознавания использует языковую модель 310 для идентификации возможных поверхностных семантических структур для представления каждого из выражений, образующих ввод, обеспечивая частичные семантические анализы или объекты по мере поступления ввода. В отличие от систем, ожидающих, пока пользователь закончит фрагмент речи, а затем обрабатывающих полностью полученный ввод, модуль 14 непрерывно выдает семантические объекты, базируясь только на том, что получено на данный момент. Машина 306 распознавания обеспечивает, по меньшей мере, один выходной поверхностный семантический объект на основании частичного фрагмента речи. В некоторых вариантах осуществления машина 306 распознавания способна обеспечивать несколько альтернативных поверхностных семантических объектов для каждой альтернативной структуры. Хотя согласно фиг.7 предусмотрен речевой ввод, настоящее изобретение можно использовать применительно к распознаванию рукописного ввода, распознаванию жестов или графическим интерфейсам пользователя (предусматривающим взаимодействие с пользователем посредством клавиатуры или другого устройства ввода). В этих других вариантах осуществления распознаватель 306 речи заменен соответствующей машиной распознавания, известной из уровня техники. Для графических интерфейсов пользователя, грамматика (имеющая языковую модель) связана с пользовательским вводом, например, через окно ввода. Соответственно, ввод пользователя обрабатывается соответствующим образом без значительной модификации в зависимости от способа ввода. Используя, например, SALT объект SALT «listen» можно использовать для выполнения как распознавания речи, так и заданий понимания. Дело в том, что конструкция соответствует точке зрения и формулировке, согласно которым понимание речи рассматривается как задача распознавания образов наподобие распознавания речи. И там, и там нужно найти образ из совокупности возможных исходов, которые наилучшим образом совпадают с данным речевым сигналом. Для распознавания речи искомый образ представляет собой строку слов, а для понимания – дерево семантических объектов. Традиционное задание распознавания речи инструктирует процесс поиска с помощью языковой модели при составлении правдоподобных (вероятных) строк слов. Аналогичным образом, задание понимания речи может управлять той же машиной поиска для составления подходящих деревьев семантических объектов с помощью семантической модели. Наподобие языковой модели, которая часто предусматривает лексикон и правила составления сегментов выражения из элементов лексикона, семантическая модель предусматривает словарь всех семантических объектов и правила их составления. В то время, как исходом распознавания является строка текста, результатом понимания является дерево семантических объектов. Хотя для возвращения структурированного исхода поиска можно расширить N-грамму (группу из N последовательных элементов), наиболее типичные приложения понимания речи базируются на вероятностной контекстно-свободной грамматике (PCFG), где разработчики могут задавать правила составления семантических объектов без массивных обучающих данных, аннотированных банком дерева. Один способ задания таких правил состоит в связывании каждого правила PCFG с директивами создания для каждой поисковой машины относительно того, как преобразовывать дерево частичных анализов PCFG в дерево семантических объектов. Ниже приведен пример, записанный в формате программного интерфейса речевых приложений Microsoft (SAPI) (который также является примером речевого API, который можно использовать в настоящем изобретении).
Сегмент грамматики содержит три правила. В первом пре-терминале, названном Составление семантических объектов также может быть динамическим процессом, например, при планировании новой встречи. Например, когда пользователь заканчивает задавать свойства встречи, например дату, время, продолжительность и участников, создается семантический объект NewMeeting. Для вставки в семантический объект NewMeeting других семантических объектов в качестве составляющих, можно использовать шаблоны. Тот же принцип можно также применять к другим правилам, которые здесь не показаны. Например, фрагмент речи «запланировать встречу с Ли Денгом и Алексом Акеро на первое января в течение одного часа» даст следующий семантический объект: В реальных приложениях усовершенствование покрытия PCFG является серьезной задачей. Поэтому желательно иметь возможность использовать N-грамму для моделирования, помимо прочего, функциональных выражений, которые не несут существенной семантической информации, но обычно имеют значительные вариации в синтаксической структуре (например, «Могу ли я С другой стороны, семантическая языковая модель нацелена на использование декодера или распознавателя для поиска семантической структуры, которая обычно лучше воспринимается PCFG. Поэтому, вместо внедрения фрагментов в N-грамму, используется PCFG, чтобы вместить N-грамму благодаря созданию особого пре-терминала PCFG, который соответствует нужной N-грамме. В формате грамматики SAPI Microsoft, ее можно обозначить с использованием пре-терминала тэгом LCFG где LCFG и RCFG обозначают левый и правый контексты внедренной N-граммы соответственно. Процесс поиска обрабатывает тэг
где
Дополнительные детали, касающиеся семантической языковой модели, описаны в статье К. Ванга (K. Wang) «Семантическое моделирование для диалоговых систем в структуре распознавания образов» ( Еще один аспект настоящего изобретения включает в себя новое использование объекта «listen» SALT. SALT обеспечивает набор элементов XML, с которыми связаны атрибуты, а также свойства, события и методы объектов DOM (Document Object Model), которые можно использовать в сочетании с исходным документом разметки для применения речевого интерфейса к исходной странице. В общем случае главные элементы включают в себя: Объекты «listen» и «dtmf» также содержит средства управления грамматики и связывания: Элемент «listen» может включать в себя атрибут В первом режиме, Во втором режиме работы, Третий режим работы распознавателя речи это «multiple mode» («многократный режим»). Этот режим работы используется для сценария Однако этот режим работы в качестве другого аспекта настоящего изобретения может предоставлять машинам поиска средство демонстрации пользователям возможностей более интенсивного взаимодействия, позволяя им сообщать (выдавать отчет) сразу же по достижении лингвистического «ориентира» молчания. В этом режиме можно непосредственно использовать общеизвестные алгоритмы поиска, основанные на синхронном декодировании. Один такой алгоритм описан в статье Х. Нея и С. Ортманса (H. Ney, S. Ortmanns) «Динамическое программирование поиска для непрерывного распознавания речи» ( Этот режим работы можно лучше понять, сравнив его с мультимодальным сценарием. В мультимодальном сценарии пользователь указывает поле, например, помещая и удерживая перо в поле ввода во время произнесения. Хотя пользователь может ткнуть в общее поле и произнести законченную фразу, чтобы заполнить многие поля в одной фразе, тем не менее, интерфейс «ткни и говори» предусматривает использование глаз и рук пользователя, что неприемлемо во многих ситуациях. Кроме того, хотя «ткни и говори» отличается богатой обратной связью, которая отображает громкость и индикатор выполнения обработки разговорного языка на более низком уровне, эти обратные связи обеспечивают очень примитивные подходы к качеству обработки разговорного языка в отношении скорости и точности. Это потенциально более проблематично для более длинных фраз, в которых ошибки могут распространяться в более широких пределах, что в конце концов затрудняет даже проверку и корректировку исходов распознавания и понимания. Поскольку исследования практичности говорят о том, что длинные фразы являются фактором принципиального различия, который демонстрирует большую полезность речи по сравнению с расширением или альтернативой клавиатуры, для успешного использования речи в качестве жизнеспособной модальности абсолютно необходим удовлетворительный опыт использования ПИ. Синхронное понимание семантических объектов путем сообщения частичных семантических анализов или объектов по мере их появления эффективно для развития восприятия человека и компьютера как тесно сотрудничающих партнеров, стремящихся к общей цели. В одном варианте осуществления для этого используется «многократный» режим элемента value= targetElement= value= targetElement= Множественные грамматики образуют пространство параллельного поиска для распознавания с нулевым переходом, возвращающим цикл к точке ввода. В этом режиме SALT позволяет объекту listen инициировать событие сразу же по выходу из грамматики. Событие ответвляет параллельный процесс, чтобы последовательно вызвать директивы связывания, пока продолжаются сбор и распознавание аудиоданных на более низком уровне, тем самым создавая для пользователя эффект, что соответствующие поля формы заполняются во время произнесения речевой команды, для приложения, которое имеет визуальное представление полей. Для пользовательского интерфейса приложений, не предусматривающих использование зрения, могут быть желательны сопровождающие речевые выходные сигналы. В этом случае объекты «prompt» SALT можно использовать, чтобы давать промежуточные обратные связи. Например, следующий объект «prompt» SALT можно использовать, чтобы синтезировать ответ на основании динамического содержимого в поле даты, и синтез речи можно запускать с помощью следующих дополнительных директив «bind» SALT:
в день
value= targetElement= targetMethod=
Конечный эффект состоит в том, что пользователь чувствует, что он говорит другой стороне, которая не только записывает, но и повторяет услышанное, как в «Запланировать встречу (новая встреча) на два часа (начинается в два часа дня) в следующий вторник (в день 10/29/02) в течение двух часов (продолжительность: два часа)», где выражения, обеспеченные в пояснениях, представляют звуковые и/или визуальные приглашения (которые также можно синхронизировать) обратно пользователю. Заметим, что SALT позволяет разработчикам присоединять специализированные обработчики событий распознавания, которые выполняют усложненные вычисления помимо простых присвоений, например, с помощью директив «bind» SALT. В вышеприведенном примере нормализация даты может осуществляться в семантической грамматике, которая, однако, не может облегчить усовершенствованное разрешение ссылок (например, «Запланировать встречу с Ли Денгом и его начальником»). В этих случаях алгоритмы можно реализовать как объекты сценария, доступные соответствующим обработчикам событий, чтобы осуществлять доступ к сохраненным данным с целью уточнения неопределенных ссылок. Такие алгоритмы описаны в статье К. Ванга (K. Wang) «Диалоговая система на плановой основе с вероятностными интерфейсами» ( Заметим, что хотя для объекта «listen» существовал множественный режим работы, в современных реализациях этот режим обеспечивает только текст для принятого ввода, например в сценарии диктования. Однако в этом аспекте настоящего изобретения частичные результаты по мере поступления ввода представляют собой не только текст, но также включают в себя соответствующую семантическую информацию, относящуюся к тексту, и, таким образом, выход содержит частичные семантические анализы или объекты, которые можно использовать согласно описанному выше для предоставления пользователю более качественной обратной связи, что компьютер правильно понял то, что получил. В зависимости от сложности приложения, принимающего частичные семантические анализы или объекты, система может предоставлять обратно пользователю подтверждения, альтернативы, исправления и пояснения на основании принятых частичных семантических анализов. Хотя известно, что мультимодальные приложения включают в себя множественные грамматики, позволяя пользователю свободно говорить и таким образом обеспечивая возможность предоставлять информацию, которая не была указана, возможно, лучше использовать элемент «listen» в многократном режиме работы, поскольку это предоставляет пользователю более высокое указание понимания. Только в голосовом приложении генерируется естественная форма диалога, тогда как в случае использования визуальных представлений, приложение может начинать обработку (осуществление действий, отображение внутренних результатов или опций, например, с помощью всплывающих окон) на основании только частичных семантических анализов того, что пользователь до сих пор предоставил, и в то время, как пользователь продолжает говорить. Хотя настоящее изобретение описано применительно к частичным вариантам осуществления, специалисты в данной области могут предложить изменения, касающиеся формы и деталей, не выходя за пределы сущности и объема изобретения.
Формула изобретения
1. Реализуемый компьютером способ взаимодействия с компьютерной системой, содержащий этапы, на которых принимают ввод от пользователя и воспринимают ввод для обработки и осуществляют распознавание относительно ввода для получения семантической информации, относящейся к первой части ввода, и выводят семантический объект, используя языковую модель, содержащую комбинацию языковой модели N-граммы и контекстно-свободной грамматики, и содержащий данные в формате, подлежащем обработке компьютерным приложением и соответствующем распознанному вводу, и семантическую информацию для первой части, причем операцию распознавания и вывод семантического объекта осуществляют в то время, как продолжается восприятие последующих частей ввода, при этом языковая модель хранит информацию, относящуюся к словам, и семантическую информацию, которая должна быть распознана. 2. Реализуемый компьютером способ по п.1, отличающийся тем, что дополнительно содержит этап, на котором 3. Реализуемый компьютером способ по п.2, отличающийся тем, что ввод является голосовым или слышимым вводом. 4. Реализуемый компьютером способ по п.3, отличающийся тем, что при установлении языковой модели определяют множественные грамматики, подлежащие использованию для распознавания. 5. Реализуемый компьютером способ по п.4, отличающийся тем, что при установлении языковой модели используют интерфейсы прикладного программирования для задания множественных грамматик, подлежащих использованию для распознавания. 6. Реализуемый компьютером способ по п.5, отличающийся тем, что при установлении языковой модели используют тэги языка речевого приложения (SALT). 7. Реализуемый компьютером способ по п.6, отличающийся тем, что при обработке ввода реализуют объект «listen» SALT в «многократном» режиме. 8. Реализуемый компьютером способ по п.1 или 2, отличающийся тем, что при выводе семантического объекта выводят данные в текстовом виде. 9. Реализуемый компьютером способ по п.8, отличающийся тем, что при приеме и восприятии ввода принимают и воспринимают звуковой ввод от пользователя. 10. Реализуемый компьютером способ по п.9, отличающийся тем, что при приеме и восприятии ввода принимают и воспринимают речевой ввод от пользователя. 11. Реализуемый компьютером способ по п.1 или 2, отличающийся тем, что при приеме и восприятии ввода принимают и воспринимают рукописный ввод от пользователя. 12. Реализуемый компьютером способ по п.1 или 2, отличающийся тем, что при приеме и восприятии ввода принимают и воспринимают визуальный ввод от пользователя. 13. Реализуемый компьютером способ по п.1 или 2, отличающийся тем, что дополнительно содержит этап, на котором представляют информацию пользователю в то время, как пользователь обеспечивает ввод, причем информация является функцией принятого семантического объекта. 14. Реализуемый компьютером способ по п.13, отличающийся тем, что при представлении информации подтверждают то, что было принято, представляя информацию как функцию семантической информации для семантического объекта. 15. Реализуемый компьютером способ по п.14, отличающийся тем, что при представлении информации представляют информацию как функцию данных в соответствии с распознанным вводом. 16. Реализуемый компьютером способ по п.15, отличающийся тем, что при представлении информации пользователю представляют опцию как функцию данных в соответствии с распознанным вводом. 17. Реализуемый компьютером способ по п.16, отличающийся тем, что при представлении информации пользователю представляют совокупность опций как функцию данных в соответствии с распознанным вводом. 18. Реализуемый компьютером способ по п.13, отличающийся тем, что при представлении информации пользователю представляют слышимое приглашение. 19. Реализуемый компьютером способ по п.18, отличающийся тем, что при представлении информации пользователю представляют визуальные указания. 20. Реализуемый компьютером способ по п.19, отличающийся тем, что при представлении информации пользователю представляют синхронизированные слышимые и визуальные указания. 21. Считываемый компьютером носитель, содержащий команды, считываемые компьютером, реализация которых приводит к тому, что компьютер осуществляет любой из способов по предыдущим пунктам способа. 22. Система, имеющая считываемый компьютером носитель, адаптированный к осуществлению любого из способов по предыдущим пунктам способа. 23. Считываемый компьютером носитель, содержащий команды, считываемые вычислительным устройством, содержащие 24. Считываемый компьютером носитель, содержащий команды, считываемые вычислительным устройством, содержащие
РИСУНКИ
|
||||||||||||||||||||||||||
 595
595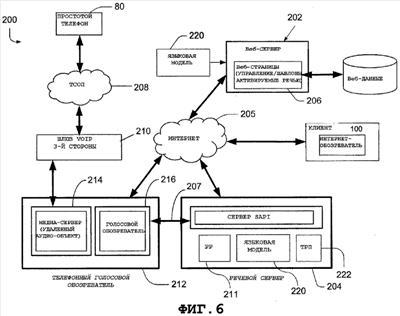
 listen
listen ) и «приглашать» (
) и «приглашать» (
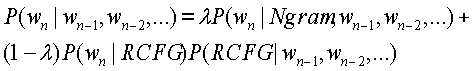
 – вес интерполяции N-граммы, и P(RCFG|wn-1,
– вес интерполяции N-граммы, и P(RCFG|wn-1,