Патент на изобретение №2351007
|
||||||||||||||||||||||||||
(54) СИСТЕМА И СПОСОБ ПОДДЕРЖКИ “НЕСОБСТВЕННОГО” XML В “СОБСТВЕННОМ” XML В ДОКУМЕНТЕ ТЕКСТОВОГО ПРОЦЕССОРА
(57) Реферат:
Изобретение относится к вычислительной технике. Техническим результатом является обеспечение возможности проверки правильности документа расширяемого языка разметки (XML), имеющего элементы, связанные с двумя или более схемами, причем элементы каждой схемы могут быть произвольно вложены в элементы другой схемы и каждый набор элементов остается правильным в пределах своей собственной схемы. Элементы второй схемы являются “прозрачными” по отношению к элементам первой схемы, когда текстовый процессор проверяет правильность элементов первой схемы. Элементы второй схемы проверяются на правильность отдельно, так что элементы первой схемы являются “прозрачными” для проверки правильности элементов, соответствующих второй схеме. 3 н. и 13 з.п. ф-лы, 6 ил.
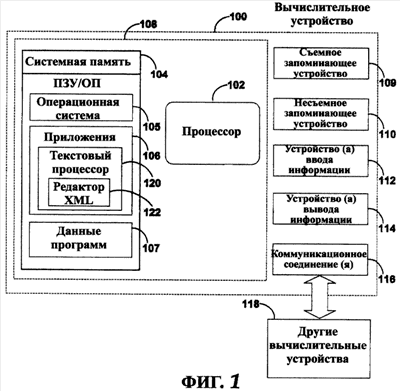
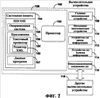
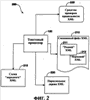
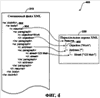
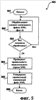
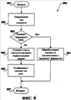
(56) (продолжение): ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ В последние годы языки разметки достигли широкой популярности. Один из видов языка разметки, расширяемый язык разметки (XML), является универсальным языком, который обеспечивает способ идентификации, обмена и обработки различных видов данных. Например, XML используется для создания документов, которые могут использоваться разнообразными прикладными программами. Элементы файла XML имеют связанное с ним пространство имен и схему. В XML пространство имен обычно используется для однозначного определения каждого документа XML. Каждый документ XML может использовать пространство имен для того, чтобы позволить процессам легко идентифицировать тип XML, связанного с документом. Уникальные пространства имен могут также помочь дифференцировать элементы разметки, которые исходят из различных источников и, случается, имеют то же самое имя. Схемы XML обеспечивают способ описания и проверки правильности (проверки на допустимость) данных в среде XML. Схема устанавливает, какие элементы и атрибуты используются для описания содержимого в документе XML, где разрешен каждый из элементов, и какие элементы могут появляться в пределах других элементов. Использование схем гарантирует, что файл структурирован одинаковым образом. Схемы могут создаваться пользователем и в общем случае поддерживаются с помощью соответствующего языка разметки, такого как XML. Используя редактор XML, который поддерживает схему, пользователь может воздействовать на файл XML и генерировать документы XML, которые придерживаются созданной пользователем схемы. Документы XML могут создаваться, придерживаясь одной или более схем. Однако обычные механизмы проверки правильности элементов в пределах документа XML по отношению к более чем одной схеме становятся неприемлемыми в некоторых ситуациях. Если элементы, связанные с первой схемой, вложены в элементы второй схемы, то любые “дочерние” элементы вложенных элементов не могут проверяться на правильность по отношению к первой схеме, если обе схемы не структурированы таким образом, чтобы учитывать друг друга. Другими словами, существующие механизмы проверки правильности могут проверять правильность по отношению к схеме только элемента и его “дочерних” элементов, но не его “внучатых” элементов непосредственно. Часто “родительский” элемент является единственным, кто может устанавливать правила для своих “дочерних” элементов. Если “дочерний” элемент находится в другой схеме, то схема “дочернего” элемента должна обращаться к “родительской” схеме, если существует необходимость вставить “внучатый” элемент в “родительскую” схему. На самом деле не существовало способа, чтобы “дочерняя” схема была “прозрачной” и позволяла “родительскому” элементу определять то, каким может быть “внучатый” элемент. До настоящего времени это ограничение создавало проблему для разработчиков инструментальных средств языка разметки. СУЩНОСТЬ ИЗОБРЕТЕНИЯ Настоящее изобретение направлено на предоставление возможности проверки правильности документа расширяемого языка разметки (XML), имеющего элементы, связанные с двумя или более схемами, где элементы каждой схемы могут быть произвольно вложены в элементы другой схемы, и каждый набор элементов остается правильным (достоверным) в пределах своей собственной схемы. Текстовый процессор имеет основную связанную с ним, или “родную” (собственную), схему, которая соответствует “родному” (собственному) XML. Документ, сгенерированный согласно “родному” XML, может включать в себя произвольные элементы, или “неродные” элементы XML, вложенные в элементы “родного” XML, и элементы “родного” XML, вложенные в элементы “неродного” XML. Элементы “неродного” XML игнорируются текстовым процессором при проверке правильности элементов “родного” XML смешанного файла XML. Элементы “неродного” XML проверяются на правильность отдельно, используя параллельное дерево XML, сгенерированное из элементов “неродного” XML в пределах смешанного файла XML, и обрабатывая элементы “родного” XML так, как будто они “прозрачны”. Настоящее изобретение позволяет внедрять элементы “неродного” XML, которые имеют их собственное соответствующее пространство имен, в элементы “родного” XML, которые имеют другое соотнесенное пространство имен. Раньше пользователи преобразовывали файлы XML в другие форматы для отображения или других функций. Предыдущие редакторы XML при проверке правильности не признавали (т.е. считали неправильными) элементы первого пространства имен, внедренные в элементы второго пространства имен (если обе связанные схемы явно не разрешали пространства имен друг друга в пределах себя). Настоящее изобретение обеспечивает, чтобы “родной” XML позволял внедрять другие элементы “неродного” XML в элементы “родного” XML в том же самом файле XML безотносительно к тому, позволяет ли какая-нибудь из схем XML явно наличие внедренных элементов. Удаление элементов “родного” XML из файла XML привело бы к тому, что документ, правильный по отношению к схеме “неродного” XML, имел только “неродной” XML. Соответственно удаление элементов “неродного” XML из файлов XML привело бы к тому, что документ, правильный по отношению к схеме “родного” XML, имеет только “родной” XML. Соответственно схема XML одного пространства имен “прозрачна” по отношению к схеме XML другого пространства имен, так что элементы, связанные с каждой схемой, могут проверяться на правильность индивидуально и отдельно. Для обеспечения “прозрачности” элементы “неродного” XML сохраняются в отдельном месте, названном “параллельное дерево XML”, когда документ создается из смешанного файла XML. Каждый узел дерева соответствует элементу пространства имен XML в смешанном файле XML. Узлы отображаются на местоположения соответствующих им элементов в пределах смешанного файла XML. Соответственно, когда файл XML сохраняется, он сохраняет элементы и “родного” XML, и “неродного” XML. Преимущество дерева XML состоит в том, что оно позволяет обрабатывать “неродной” XML отдельно от “родного” XML для целей проверки правильности по отношению к схеме “неродного” XML при сохранении местоположения “неродного” XML в пределах “родного” XML. То, что “родной” XML рассматривается как “прозрачный” по отношению к “неродному” XML, позволяет использовать и сохранять файл XML по-прежнему как единый файл. КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ Фиг. 1 – показывает примерное вычислительное устройство, которое может использоваться в одном примерном варианте осуществления настоящего изобретения. Фиг. 2 – структурная схема, показывающая примерную среду для применения настоящего изобретения. Фиг. 3 – показывает примерный смешанный файл XML в соответствии с настоящим изобретением. Фиг. 4 – показывает примерную структурную диаграмму связи между примерным смешанным файлом XML и примерным параллельным деревом XML в соответствии с настоящим изобретением. Фиг. 5 – логическая схема последовательности операций примерного процесса генерации смешанного документа XML в соответствии с настоящим изобретением. Фиг. 6 – логическая схема последовательности операций примерного процесса обработки элементов в пределах смешанного документа XML в соответствии с настоящим изобретением. ПОДРОБНОЕ ОПИСАНИЕ ПРЕДПОЧТИТЕЛЬНОГО ВАРИАНТА ОСУЩЕСТВЛЕНИЯ По всему описанию и формуле изобретения следующие термины имеют значения, явно указанные ниже, если контекст явно не диктует иное значение. Термины “язык разметки” или “ЯР” относятся к языку для специальных кодов в пределах документа, которые определяют, как части документа должны интерпретироваться приложением. В файле текстового процессора элементы разметки могут быть связаны с определенным форматированием, которое определяет, как содержимое элемента должно быть отображено или размещено. В других документах, таких как другие документы XML, разметка может быть направлена на описание данных, не обращаясь к рассмотрению отображения. Термины “родной” (собственный) расширяемый язык разметки” или “родной” (собственный) XML” относятся к элементам языка разметки, которые связаны с приложением текстового процессора, и к схеме, связанной с приложением текстового процессора. Термины “неродной” (несобственный) расширяемый язык разметки” или “неродной” (несобственный) XML” относятся к элементам языка разметки, которые создали пользователь или другое приложение, которые придерживаются схемы, отличающейся от схемы “родного” XML. Термин “элемент” относится к основному модулю документа XML. Элемент может содержать атрибуты, другие элементы, содержимое и другие стандартные блоки для создания документа XML. Термин “тэг” относится к команде, вставленной в документ, которая описывает элементы в пределах документа XML. Каждый элемент обычно имеет не более чем два тэга: начальный тэг и конечный тэг. Может существовать пустой элемент (без содержимого), в этом случае разрешается один тэг. Содержимое между тэгами считают “дочерними элементами” элемента (или “элементами-потомками”). Следовательно, другие элементы, внедренные в содержимое элемента, называют “дочерними элементами” или “дочерними вершинами” или элементом. Текст, внедренный непосредственно в содержимое элемента, считают “дочерними текстовыми узлами” элемента. Вместе “дочерние” элементы и текст в пределах элемента составляют “содержимое” этого элемента. Термин “атрибут” относится к дополнительному свойству, установленному равным определенному значению и связанному с элементом. Элементы могут иметь произвольное количество значений параметров атрибута, связанных с ними, включая отсутствие параметров. Атрибуты используются для связывания с элементом дополнительной информации, которую не включает в себя содержимое элемента. ИЛЛЮСТРАТИВНАЯ ОПЕРАЦИОННАЯ СРЕДА Обращаясь к фиг. 1, одна из примерных систем для осуществления изобретения включает в себя вычислительное устройство, такое как вычислительное устройство 100. В основной конфигурации вычислительное устройство 100 обычно включает в себя по меньшей мере один процессор 102 и системную память 104. В зависимости от точной конфигурации и типа вычислительного устройства системная память 104 может быть энергозависимой (такой как оперативная память (ОП)), энергонезависимой (такой как постоянное запоминающее устройство (ПЗУ), флэш-память и т.д.) или некоторой их комбинацией. Системная память 104 обычно включает в себя операционную систему 105, одно или более приложений 106 и может включать в себя данные 107 программ. В одном из вариантов осуществления приложение 106 может включать в себя приложение 120 текстового процессора, которое дополнительно включает в себя редактор 122 XML. Эта основная конфигурация показана на фиг. 1 компонентами в пределах пунктирной линии 108. Вычислительное устройство 100 может иметь дополнительные особенности или функциональные возможности. Например, вычислительное устройство 100 может также включать в себя дополнительные устройства хранения данных (съемные и/или несъемные), такие как, например, магнитные диски, оптические диски или лента. Такие дополнительные запоминающие устройства показаны на фиг. 1 в качестве съемного запоминающего устройства 109 и несъемного запоминающего устройства 110. Компьютерные носители данных могут включать в себя энергозависимые и энергонезависимые, съемные и несъемные носители, реализованные с помощью любого способа или технологии для хранения информации, такой как считываемые компьютером команды, структуры данных, модули программ или другие данные. Системная память 104, съемное запоминающее устройство 109 и несъемное запоминающее устройство 110 – все являются примерами компьютерных носителей данных. Компьютерные носители данных включают в себя ОП, ПЗУ, электрически стираемое программируемое постоянное запоминающее устройство (ЭСППЗУ), флэш-память или память другой технологии, компакт-диски (CD-ROM), цифровые универсальные диски (DVD) или другие оптические запоминающие устройства, магнитные кассеты, магнитную ленту, запоминающее устройство на магнитном диске или другие магнитные запоминающие устройства или любой другой носитель, который может использоваться для хранения требуемой информации и к которому может обращаться вычислительное устройство 100, но не ограничены ими. Любые такие компьютерные носители данных могут быть частью устройства 100. Вычислительное устройство 100 может также иметь устройство (а) 112 ввода данных, такие как клавиатура, мышь, перо, устройство ввода голосовых данных, сенсорное устройство ввода данных и т.д. Оно может также включать в себя устройство (а) 114 вывода, такие как дисплей, динамики, принтер и т.д. Эти устройства хорошо известны из предшествующего уровня развития техники и нет необходимости обсуждать их подробно. Вычислительное устройство 100 может также содержать коммуникационные подключения 116, которые позволяют устройству связываться с другими вычислительными устройствами 118, например, по сети. Коммуникационное подключение 116 является одним из примеров средств связи. Средства связи могут в типовом варианте воплощаться в виде считываемых компьютером команд, структур данных, модулей программ или других данных в модулируемом сигнале данных, таком как несущая, или могут использовать другой механизм транспортировки, и включают в себя любые средства доставки информации. Термин “модулированный сигнал данных” означает сигнал, который имеет одну или более из своих характеристик, которые устанавливаются или изменяются таким образом, чтобы кодировать информацию в сигнале. Для примера, а не в качестве ограничения, средства связи включают в себя проводные средства связи, такие как проводная сеть или прямое проводное подключение, и беспроводные средства связи, такие как акустические, радиочастотные (РЧ), инфракрасные и другие беспроводные средства связи. Считается, что термин “считываемый компьютером носитель” включает в себя и носитель данных, и средство связи. СТРУКТУРА ФАЙЛА ТЕКСТОВОГО ПРОЦЕССОРА Фиг. 2 изображает структурную схему, показывающую примерную среду для применения настоящего изобретения. Примерная среда, показанная на фиг. 2, является средой текстового процессора 200, который включает в себя текстовый процессор 120, смешанный файл 210 XML, схему 215 “неродного” XML, параллельное дерево 220 XML и средство 225 проверки правильности XML. Смешанный файл 210 XML включает в себя и “родной” XML 211, и “неродной” XML 212. В одном из вариантов осуществления текстовый процессор 120 имеет свое собственное пространство имен и набор схем, который определен для использования с документами, связанными с текстовым процессором 120. Набор тэгов и атрибутов, которые определяются схемой для текстового процессора 120, может определять формат документа до такой степени, что он упоминается, как его собственный язык разметки, “родной” XML. “Родной” XML поддерживается текстовым процессором 120 и может придерживаться правил других языков разметки при создании дополнительных собственных правил. “Родной” XML обеспечивает язык разметки, который включает в себя много информации отображения и который пользователь может использовать без необходимости тратить время на создание схемы, соответствующей отображаемой информации. “Родной” XML 211 и “неродной” XML 212 смешиваются в смешанном файле 210 XML. В соответствии с настоящим изобретением элементы “неродного” XML 212 могут быть вложены в элементы “родного” XML 211, и элементы “родного” XML 211 могут быть вложены в элементы “неродного” XML 212. Соответственно, когда текстовый процессор 120 внутренним образом проверяет правильность “родного” XML 211 смешанного файла 210 XML, процесс внутренней проверки правильности вступает в противоречие с элементами “неродного” XML 212. Примерный смешанный файл 210 XML описан ниже при обсуждении фиг. 2. Схема 215 “неродного” XML связана с элементами “неродного” XML 212. При проверке правильности элементы “неродного” XML 212 исследуются относительно того, соответствуют ли они схеме 215 “неродного” XML. Как предварительно описано выше, схема устанавливает, какие теги и атрибуты используются для описания содержимого документа XML, где разрешен каждый из тэгов, и какие теги могут оказаться внутри других тэгов, гарантируя, что документ структурирован одним и тем же образом. Соответственно “неродной” XML 212 является правильным, когда он структурирован так, как сформулировано в схеме 215 “неродного” XML. Проверка правильности “неродного” XML 212 описана дополнительно ниже при обсуждении фиг. 5. Перед проверкой правильности элементы “неродного” XML 212 сохраняются в параллельном дереве 220 XML. Параллельное дерево 220 XML описано ниже при обсуждении фиг. 4. Параллельное дерево 220 XML передают средству 225 проверки правильности XML для проверки правильности “неродного” XML 212. Средство 225 проверки правильности XML работает подобно другим доступным средствам проверки правильности для документов XML. Средство 225 проверки правильности XML оценивает XML, который находится в структуре схемы 215 “неродного” XML. В одном из вариантов осуществления большое количество средств проверки правильности может быть связано с текстовым процессором 120 для проверки правильности большого количества структур языка разметки. Фиг. 3 иллюстрирует примерный смешанный файл XML в соответствии с настоящим изобретением. Смешанный файл 210 XML включает в себя и элементы “родного” XML, и элементы “неродного” XML. Элемент на языке разметки обычно включает в себя открывающий тэг (обозначенный “<” и “>”), некоторое содержимое и закрывающий тэг (обозначенный ” “). Считается, что теги, связанные с “родным” XML, связаны с пространством имен текстового процессора. Напротив, теги, которые связаны с “неродным” XML, упоминаются как связанные с другим пространством имен, в этом примере с пространством имен “resume” (резюме). Элементы смешанного документа 210 XML могут дополнительно включать в себя содержимое. Например, элемент “Work” (работа) содержится в элементе “objective” (цель), и элемент “123 Main” (123 Главная) содержится в элементе “street” (улица). Элемент “address” (адрес) включает в себя элемент “street”. Эти элементы определяются согласно схеме “неродного” XML, соответствующей пространству имен “resume” (например, схема “resume”), которое было предварительно обеспечено пользователем или другим приложением. При исследовании смешанного файла 210 XML данный файл включает в себя элементы “неродного” XML, вложенные в элементы “родного” XML, и элементы “родного” XML, вложенные в элементы “неродного” XML. Соответственно, когда смешанный файл 210 XML внутренним образом проверяется на правильность текстовым процессором или передается в качестве дерева средству проверки правильности, приложение, проверяющее правильность смешанного файла 210 XML, вступает в противоречие с вложенными элементами, которые соответствуют двум различным схемам. В зависимости от правил, связанных с приложением, которое проверяет правильность, смешанный файл 210 XML может оказаться недопустимым, если схема “неродного” XML не разрешена для “родного” XML. Например, если бы смешанный файл 210 XML был полностью отправлен другому средству проверки правильности XML, то файл был бы вероятно определен как недопустимый. Схемы XML типично не позволяют, чтобы элементы одного пространства имен были вложены в элементы второго пространства имен. В одном из вариантов осуществления настоящее изобретение преодолевает это ограничение посредством схемы “родного” XML, связанной с текстовым процессором, который позволяет вкладывать произвольные элементы, связанные с другой схемой “неродного” XML. Примерный процесс получения правильного (допустимого) смешанного файла XML описан дополнительно при обсуждении, сопровождающем фиг. 5 и 6. Фиг. 4 показывает примерную структурную диаграмму связи между примерным смешанным файлом XML и примерным параллельным деревом XML в соответствии с настоящим изобретением. Параллельное дерево XML 220 генерируется, когда текстовый процессор 120 (показанный на фиг. 1 и 2) создает документ, внутренним образом проверяя правильность смешанного файла 210 XML. Внутренняя проверка правильности позволяет текстовому процессору 120 оценивать каждый элемент согласно его собственному набору правил. Когда элемент “неродного” XML вступает в противоречие, будучи вложенным в элемент “родного” XML, в пределах параллельного дерева XML 220 генерируется узел (например, 402), который соответствует этому элементу. Положение узла в параллельном дереве 220 XML определяется положением соответствующего элемента в смешанном документе 210 XML относительно других элементов. Соответственно каждый элемент “неродного” XML смешанного файла 210 XML представлен узлом (например, 402) параллельного дерева 220 XML. Прямые “родительско-дочерние” отношения устанавливаются между элементами XML, представленными в параллельном дереве 220 XML, некоторые из которых, возможно, первоначально не существовали в смешанном файле 210 XML из-за промежуточной разметки “родного” XML. Примерный процесс, связанный с генерацией узлов примерного дерева 220 “неродного” XML, описан ниже со ссылками на фиг. 6. Параллельное дерево 220 XML позволяет текстовому процессору 120 по существу игнорировать элементы “неродного” XML, когда он внутренним образом проверяет правильность смешанного файла 210 XML. Параллельное дерево 220 XML может в таком случае проверяться на правильность отдельно от смешанного файла 210 XML, как описано ниже со ссылками на фиг. 5. ОБРАБОТКА ЭЛЕМЕНТОВ СМЕШАННОГО ФАЙЛА XML Фиг. 5 – логическая схема последовательности операций примерного процесса генерации смешанного документа XML в соответствии с настоящим изобретением. Процесс 500 начинается на этапе 501, где смешанный файл XML был предварительно сгенерирован пользователем приложения текстового процессора, подобного текстовому процессору 120, показанному на фиг. 1. Обработка продолжается на этапе 502. На этапе 502 обрабатывается элемент смешанного файла XML. При обработке каждого элемента происходит определение, является ли элемент элементом “родного” XML или элементом “неродного” XML. Как обрабатывается каждый элемент, зависит от типа элемента. Когда элемент является элементом “неродного” XML, узел, соответствующий этому элементу, вставляется в параллельное дерево XML, как описано далее со ссылками на фиг. 6. Примерный процесс обработки каждого элемента описан далее со ссылками на фиг. 6. Как только элемент обработан, процесс происходит в соответствии с этапом 503 принятия решения. На этапе 503 принятия решения происходит определение, был ли обработан каждый из элементов, которые включает в себя смешанный файл XML. Каждый элемент был обработан, когда текстовый процессор достиг последнего закрывающего тэга смешанного файла XML при создании документа из смешанного файла XML. Если дальнейшие элементы еще не были обработаны, то обработка возвращается на этап 502, и начинают обрабатывать дальнейшие элементы. Если все элементы были обработаны, то обработка продолжается на этапе 504. На этапе 504 проверяется на правильность параллельное дерево XML. Параллельное дерево XML передается с помощью текстового процессора средству проверки правильности XML, которое подобно средству 225 проверки правильности XML, показанному на фиг. 2. Средство проверки правильности XML работает таким образом, что оно исследует параллельное дерево XML в соответствии со связанной схемой, которая подобна схеме 215 “неродного” XML, показанной на фиг. 2. Связанная схема устанавливает, какие теги и атрибуты используются для описания содержимого в результирующим документе XML, где разрешается каждый из тэгов и какие элементы могут появляться в других элементах. Параллельное дерево XML является правильным, когда оно придерживается связанной схемы. Как только параллельное дерево XML проверено на правильность, обработка продолжается на этапе 505. На этапе 505 текстовым процессором генерируется документ, соответствующий смешанному файлу XML. В одном из вариантов осуществления документ форматируется согласно схеме “родного” XML, обеспеченной текстовым процессором, и она отображает тэги, связанные с элементами “неродного” XML смешанного файла XML. Обработка продолжается на этапе 506, где процесс заканчивается. В одном из вариантов осуществления процесс 500 может изменяться в результате внутренней проверки правильности “родного” XML или проверки правильности “неродного” XML. Например, процесс может определить, что или “родной” XML, или “неродной” XML недопустимы. В результате процесс 500 может прерываться, может возвращаться сообщение об ошибках, может запускаться программа для оказания помощи в исправлении XML или могут активизироваться дополнительные операции. Фиг. 6 представляет логическую схему последовательности операций примерного процесса обработки элементов в пределах смешанного документа XML в соответствии с настоящим изобретением. Процесс 600 начинается на этапе 601, когда процесс 500, показанный на фиг. 5, переходит на этап 502. Обработка продолжается на этапе 602. На этапе 602 выполняют определение, соответствует ли обрабатываемый элемент элементу “родного” XML или элементу “неродного” XML. Тип элемента может быть определен, исследуя открывающий тэг каждого элемента. Открывающий тэг каждого элемента включает в себя ссылку на схему, которая соответствует этому элементу (см. фиг. 3). Каждая схема связана или с “родным” XML, или с “неродным” XML. Как только тип элемента определен, процесс переходит на этап 603 принятия решения. На этапе 603 принятия решения определяют, является ли элемент элементом “неродного” XML. Как указано выше, каждый элемент обрабатывается по-разному в зависимости от типа элемента. Если элемент не является элементом “неродного” XML, то обработка продолжается на этапе 604. На этапе 604 элемент обрабатывается в соответствии с “родным” (собственным) форматом текстового процессора (например, “родным” XML). В одном из вариантов осуществления текстовый процессор обеспечивает свою собственную внутреннюю проверку правильности элементов в пределах своего собственного формата. Другими словами, у процессора нет необходимости обращаться к средству проверки правильности XML для проверки правильности элементов, соответствующих его “родному” формату (например, “родному” XML). Распознавая элементы своего “родного” формата, как правильные или нет, текстовый процессор может создать документ, соответствующий этим элементам, пока процесс продолжается. Как только элемент “родного” XML обработан согласно “родному” XML, обработка продолжается на этапе 607, откуда процесс возвращается на этапе 503 на фиг. 5. Однако, если элемент является элементом “неродного” XML, то обработка продолжается в соответствии с этапом 605. На этапе 605 в параллельном дереве XML создается узел, который соответствует открывающему тэгу или атрибуту элемента “неродного” XML. Параллельное дерево XML исследуется на правильность с помощью средства проверки правильности XML. Средство проверки правильности XML определяет, придерживается ли параллельное дерево XML связанной схемы “неродного” XML. Генерируя и отдельно проверяя на правильность параллельное дерево XML, настоящее изобретение включает в себя функциональные возможности для проверки правильности смешанного документа XML, который имеет элементы, связанные с двумя или более схемами, причем элементы каждой схемы могут быть произвольно вложены друг в друга. Как только узел создан в параллельном дереве, обработка продолжается на этапе 606. На этапе 606 элемент “неродного” XML отображается на узел, созданный в параллельном дереве. В одном из вариантов осуществления метка-заполнитель связывается с каждым элементом в пределах смешанного файла XML. Метка-заполнитель определяет для каждого узла положение каждого элемента “неродного” XML в пределах смешанного файла XML. Отображение элементов “неродного” XML на соответствующие им узлы допускает, чтобы созданные и/или применяемые пользователем элементы устанавливались точно в пределах результирующего документа XML. Как только элемент “неродного” XML отображен на узел, обработка продолжается на этапе 506, откуда процесс возвращается к этапу 503 на фиг. 5. В одном из вариантов осуществления соответствующие разделы одного и того же смешанного файла XML могут включать в себя многочисленные схемы “неродного” XML. Генерируется параллельное дерево XML, причем каждому элементу, соответствующему каждой из схем “неродного” XML, соответствует узел. В таком случае, когда параллельное дерево XML проверяется на правильность, элементы “неродного” XML, соответствующие каждой схеме, проверяются на правильность, как будто каждый соответствующий раздел одного и того же смешанного файла XML является фактически отдельным файлом XML. Однако, если многочисленные схемы “неродного” XML ссылаются друг на друга, то это может привести к тому, что элементы будут смешиваться. Вышеприведенные описание, примеры и данные обеспечивают законченное описание изготовления и использования состава изобретения. Поскольку множество вариантов осуществления изобретения могут быть сделаны без отрыва от духа и формы изобретения, данное изобретение определяется прилагаемой формулой изобретения.
Формула изобретения
1. Способ поддержания проверки правильности документа на расширяемом языке разметки (XML), причем упомянутый XML-документ включает в себя неродной (несобственный) XML в пределах родного (собственного) XML, при этом способ содержит этапы: определяют, связан ли элемент в документе с одним из неродного XML и родного XML, генерируют параллельное дерево, которое включает в себя узлы, причем каждый узел соответствует элементу в XML-документе, ассоциированному с неродным XML, проверяют правильность элементов, связанных с родным XML в документе XML, в то же время игнорируя элементы, связанные с неродным XML, и проверяют правильность упомянутого параллельного дерева отдельно от XML-документа, так что элементы, ассоциированные с родным XML, являются “прозрачными” при проверке правильности неродного XML. 2. Способ по п.1, в котором способ дополнительно содержит установку соответствия между каждым узлом и соответствующим ему элементом в XML-документе, так что положение каждого элемента, связанного с неродным XML, сохраняется. 3. Способ по п.1, в котором способ дополнительно содержит генерацию документа на языке разметки, который соответствует проверенным на правильность элементам, ассоциированным с родным XML, и проверенным на правильность элементам, ассоциированным с неродным XML. 4. Способ по п.1, в котором этап проверки на правильность элементов, связанных с родным XML, выполняется с помощью текстового процессора внутренним образом. 5. Способ по п.4, в котором текстовый процессор определяет правильность элементов, ассоциированных с родным XML, так что документ XML формируют, когда текстовый процессор оценивает каждый элемент. 6. Способ по п.1, в котором этап проверки правильности параллельного дерева отдельно от документа XML включает в себя исследование параллельного дерева с помощью средства проверки правильности языка разметки согласно схеме неродного XML, которая соответствует элементам документа XML, которые связаны с неродным XML. 7. Способ по п.1, дополнительно содержащий обработку элементов, связанных с неродным XML, которые также ассоциированы с многочисленными различными схемами, в качестве отдельных файлов при проверке правильности. 8. Считываемый компьютером носитель, имеющий выполняемые компьютером компоненты для выполнения способа проверки правильности документа на расширяемом языке разметки (XML), содержащий: первый компонент для генерации документа на расширяемом языке разметки (XML), который включает в себя элементы, ассоциированные с неродным XML, вложенные в элементы, ассоциированные с родным XML текстового процессора, второй компонент для сохранения узлов в параллельном дереве, каждый узел которого ассоциирован с каждым элементом, ассоциированным с неродным XML, третий компонент для проверки правильности элементов, ассоциированных с родным XML в документе, созданном первым компонентом, в то время как элементы, ассоциированные с неродным XML, являются “прозрачными” при обработке правильности, и четвертый компонент для отдельной проверки правильности параллельного дерева, так что при обработке правильности элементы, ассоциированные с родным XML, являются “прозрачными”, в то время как проверяются на правильность элементы, ассоциированные с неродным XML. 9. Считываемый компьютером носитель по п.8, дополнительно содержащий пятый компонент для обеспечения схемы, которая ассоциирована с элементами неродного XML, причем элементы неродного XML проверяются на правильность по отношению к схеме, обеспечиваемой пятым компонентом. 10. Считываемый компьютером носитель по п.8, в котором второй компонент дополнительно конфигурируется таким образом, чтобы каждый узел ставился в соответствие соответствующему ему элементу неродного XML в пределах документа, созданного первым компонентом. 11. Считываемый компьютером носитель по п.8, в котором первый компонент дополнительно конфигурируется таким образом, что метка-заполнитель ассоциируется с каждым элементом неродного XML, когда соответствующий ему узел генерируется вторым компонентом. 12. Считываемый компьютером носитель по п.8, в котором первый компонент дополнительно включает в себя элементы, ассоциированные с родным XML, вложенные в элементы, ассоциированные с неродным XML. 13. Считываемый компьютером носитель, имеющий выполняемые компьютером команды для поддержания проверки правильности документа на расширяемом языке разметки (XML), который включает в себя неродной XML в пределах родного XML текстового процессора, содержащий команды для выполнения этапов: определяют, ассоциирован ли элемент в документе XML с одним из: первого пространства имен и второго пространства имен, причем первое пространство имен ассоциировано с родным XML, и второе пространство имен ассоциировано с неродным XML, генерируют параллельное дерево, которое включает в себя узлы, причем каждый узел соответствует элементу документа XML, ассоциированному со вторым пространством имен, устанавливают соответствие между каждым узлом и соответствующим ему элементом в XML-документе, так что положение каждого элемента, ассоциированного со вторым пространством имен, сохраняется, проверяют правильность каждого элемента XML документа, так что элементы, ассоциированные с первым пространством имен, являются “прозрачными”, когда проверяются на правильность элементы, ассоциированные со вторым пространством имен, и элементы, ассоциированные со вторым пространством имен, являются “прозрачными”, когда проверяются на правильность элементы, ассоциированные с первым пространством имен. 14. Считываемый компьютером носитель по п.13, в котором этап проверки правильности элементов, ассоциированных с первым пространством имен, выполняют с помощью текстового процессора внутренним образом. 15. Считываемый компьютером носитель по п.14, в котором текстовый процессор определяет правильность элементов, ассоциированных с первым пространством имен, так что документ XML сформирован, когда текстовый процессор оценит каждый элемент. 16. Считываемый компьютером носитель по п.13, в котором этап проверки правильности параллельного дерева отдельно от файла XML включает в себя исследование параллельного дерева с помощью средства проверки правильности XML согласно схеме неродного XML, которая соответствует элементам файла XML, которые ассоциированы со вторым пространством имен.
РИСУНКИ
|
||||||||||||||||||||||||||