Патент на изобретение №2348990
|
||||||||||||||||||||||||||
(54) УСТРОЙСТВО И СПОСОБ КОРРЕКЦИИ НА ОСНОВЕ АУДИОГРАММЫ
(57) Реферат:
Предложено устройство и способ коррекции выходного звука на основе аудиограммы. Аудиограмма создается на основе алгоритма случайного прослеживания Бекеши, в котором частоты источника звука изменяются случайным образом. 2 н. и 7 з.п. ф-лы, 1 табл., 6 ил.
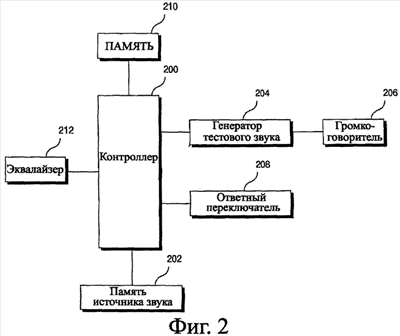
Область техники Настоящее изобретение относится к устройству и способу коррекции на основе аудиограммы, а конкретнее к устройству и способу коррекции на основе аудиограммы, в которых аудиограмма тестируется в персональной частотной полосе с помощью самокалибровки и алгоритма случайного прослеживания Бекеши, а корректировка выполняется на основе протестированной аудиограммы для получения оптимального звука и оптимальной функции защиты органов слуха. Уровень техники Статистически предполагается, что от 0,1% до 0,2% населения соответствует полной потере слуха, не дающей возможности слышать, от 1% до 2% населения соответствует средней и сильной потере слуха, а от 10% до 15% соответствует умеренной потере слуха. Люди, соответствующие умеренному диапазону потери слуха, имеют трудности при прослушивании звука от 20 дБ до 40 дБ, но могут беседовать с другими людьми рядом с ними без затруднения. Поэтому большинство людей, соответствующих диапазону умеренной потери слуха, редко обращаются в больницу, потому что они не понимают серьезности своей потери слуха. Однако если люди, соответствующие диапазону умеренной потери слуха, непрерывно используют аудиоплейер с чрезмерно большой громкостью, их потеря слуха может стать средней потерей слуха. В наихудшем случае их потеря слуха может стать сильной потерей слуха или полной потерей слуха. В современном обществе многие люди используют аудиоплейеры, такие как ТВ, АМ-ЧМ радио, CD плейер, МР3 плейер, аудиокассета, ПК (персональный компьютер) и плейер для изучения иностранных языков. Аудиоплейеры, продаваемые в настоящее время на рынке, имеют функцию усиления громкости, достаточную, чтобы вызвать потерю слуха. Поскольку большинство пользователей аудиоплейеров стремятся слушать музыку с большой громкостью, их потеря слуха становится серьезной и может привести к умеренной потере слуха. В частности, поскольку люди, которые очень любят музыку, стремятся слушать музыку с большой громкостью, потеря слуха для этих людей более серьезна, т.к. может вызвать среднюю потерю слуха или полную потерю слуха. Существующий аудиоплейер вызвал более серьезную потерю слуха, потому что он воспроизводит звук, не обращая внимания на индивидуальную аудиограмму. Слуховые клетки спирального канала улитки имеют частотные полосы и уровень, которые определяются. Аудиограмма представляет собой распределение восприятия по частоте слуховых клеток, которое получается тестированием слуха. Люди имеют уникальную аудиограмму подобно отпечатку пальца или структуре ДНК. Такая аудиограмма может изменяться из-за старения или чрезмерно большой громкости. Например, предположим, что некто слушал звук с частотой 1 кГц при интенсивности 80 дБ над уровнем слышимости или больше в течение нескольких часов, его конкретная слуховая клетка, которая имеет дело со звуком в 1 кГц, подвергается чрезмерному звуку, тем самым вызывая внезапную потерю слуха. Предположим, что некто, любящий острый и возбуждающий звук, неоднократно слушает звук частоты 10 кГц с большой громкостью, это может вызвать функциональную потерю слуха для частотной полосы 10 кГц. При этом фиг.1 иллюстрирует результат управления громкостью существующего аудиоплейера. На фиг.1 показаны первая группа 100 и вторая группа 102. Первая группа 100 имеет порог 0 дБ над слуховым порогом (дБСП) (dBHL) вблизи 1 кГц в наружной группе волосковых клеток, тогда как вторая группа 102 имеет порог 30 дБСП. Поскольку существующий аудиоплейер линейно управляет звуком, вероятно, что первая группа 100 может быть повреждена. Иными словами, если громкость устанавливается на 90 дБСП, вторая группа может почувствовать меньшее утомление, потому что она подвергается воздействию 60 дБСП. Но первая группа 100 может быть повреждена из-за искажения громкости и усталости, потому что она подвергается чрезмерному воздействию 90 дБСП. Чтобы избежать потери слуховых клеток, которую может вызвать линейное управление громкостью, можно выполнять коррекцию для обеспечения индивидуального управления громкостью по частотной полосе. Как правило, коррекция позволяет пользователю слушать музыку с желательным тембром. Например, некто, любящий ясный и элегантный звук, может увеличить громкость высокочастотного диапазона эквалайзера, чтобы слушать желательный звук. Некто, любящий величественный и мощный звук, может увеличить громкость низкочастотного диапазона эквалайзера, чтобы слушать желательный звук. Помимо получения желательного для пользователя звукового тембра эквалайзер используется для такого медицинского лечения как акустическое средство и искусственный улиточный (ушной) канал. В случае пациентов с потерей слуха, которые нуждаются в акустическом средстве или искусственном улиточном канале, эквалайзер должен, в принципе, управляться в зависимости от их аудиограммы после тестирования из потерь по частоте. Это потому что слух становится хуже, если пациенту с потерей слуха, не имеющему больших потерь слуха для частотной полосы 10 кГц, звук подается через акустическое средство и искусственный улиточный канал, которые не выполняют коррекцию (именуемую в акустике «подгонкой») для частотной полосы 10 кГц. Однако если предполагается обеспечить аудиоплейер на основе аудиограммы пользователя с помощью эквалайзера, то трудно обеспечить такой аудиоплейер согласно способу коррекции на основе аудиограммы в существующем способе тестирования аудиограмм. В известном из уровня техники способе тестирования аудиограмм конкретная частотная полоса выбирается путем тестирования в шести частотных диапазонах 250 Гц, 500 Гц, 1000 Гц, 2000 Гц, 4000 Гц и 8000 Гц. Затем интенсивность тестового звука управляется вручную, чтобы определить порог слышимости в конкретной частотной полосе. Далее таким же образом выбирается другая частотная полоса, чтобы определить порог слышимости. Иными словами, в известном из уровня техники способе тестирования аудиограммы, поскольку шаг выбора частоты тестера, шаг предложения тестового звука и шаг определения порога слышимости в зависимости от отклика тестового звука тестируемого лица выполняются раздельно, требуется максимальное время в 50 минут для определения порога слышимости в шести вышеуказанных частотных полосах. Поэтому, если известный из уровня техники способ тестирования аудиограммы применяется в аудиоплейере, то пользователю трудно выбрать частоту аудиоплейера, принять тестовый звук и определить порог слышимости. В частности, время, требуемое для тестирования порога слышимости, становится длиннее, если частотная полоса подразделяется. Поэтому трудно обеспечить аудиоплейер, в котором коррекция выполняется на основе известного из уровня техники способа тестирования аудиограммы. Далее, если тестовый звук обеспечивается путем управления только интенсивностью в состоянии, в котором выбирается конкретная частота, может в сильной степени случиться тестовая ошибка из-за адаптации и выборочного внимания пользователя, за счет чего трудно точно протестировать аудиограмму. Краткое описание чертежей Сопровождающие чертежи, которые введены для обеспечения дальнейшего понимания изобретения и включены в него и составляют часть данного описания, иллюстрируют варианты осуществления изобретения вместе с описанием, служащим для пояснения принципов изобретения. На чертежах: фиг.1 иллюстрирует результат управления громкостью известного из уровня техники аудиоплейера; фиг.2 иллюстрирует устройство коррекции на основе аудиограммы согласно предпочтительному варианту осуществления настоящего изобретения; фиг.3 иллюстрирует модуль контроллера согласно предпочтительному варианту осуществления настоящего изобретения; фиг.4 иллюстрирует стандарт для нахождения окончательного порога слышимости согласно предпочтительному варианту осуществления настоящего изобретения; фиг.5 иллюстрирует результат управления громкостью аудиоплейера, в котором выполняется коррекция на основе аудиограммы согласно предпочтительному варианту осуществления настоящего изобретения; и фиг.6 представляет собой блок-схему алгоритма, иллюстрирующую коррекцию на основе аудиограммы согласно предпочтительному варианту осуществления настоящего изобретения. Подробное описание изобретения Технические проблемы Соответственно настоящее изобретение направлено на устройство и способ коррекции на основе аудиограммы, которые практически устраняют одну или несколько проблем вследствие ограничений и недостатков уровня техники. Цель настоящего изобретения состоит в обеспечении устройства и способа коррекции на основе аудиограммы, в которых оптимальный звук и оптимальная функция защиты слуха могут быть предоставлены пользователю при минимизации времени тестирования аудиограммы. Другая цель настоящего изобретения состоит в обеспечении устройства и способа коррекции на основе аудиограммы, в которых время, требуемое для тестирования аудиограммы, можно минимизировать в случае, когда частотная полоса подразделена. Еще одна цель настоящего изобретения состоит в обеспечении устройства и способа коррекции на основе аудиограммы, в которых оптимальный тестовый начальный звук можно установить автоматически без ручной манипуляции пользователя при выборе тестового звука, чтобы снизить время, требуемое для тестирования аудиограммы. Еще одна цель настоящего изобретения состоит в обеспечении устройства и способа коррекции на основе аудиограммы, в которых порог слышимости по частотной полосе определяется для управления громкостью, чтобы ясный звук можно было получать на низкой мощности. Еще одна цель настоящего изобретения состоит в обеспечении устройства и способа коррекции на основе аудиограммы, в которых шаг разрешения пользователю выбирать частоту опускается, чтобы не вызывать адаптации слуха или избирательного внимания, посредством чего обеспечивается точное тестирование аудиограммы. Технические решения Чтобы достичь этих и иных преимуществ и в соответствии с назначением настоящего изобретения, как оно осуществлено и широко описано, в способе коррекции на основе аудиограммы с помощью устройства коррекции, включающего в себя память источника звука, откалиброванную с постоянным шагом в дБСП и хранящую данные источника звука, имеющие множество частотных полос для одного дБСП, звуковую микросхему, контроллер, вызывающий данные источника звука, громкоговоритель и эквалайзер, содержатся шаги, на которых: а) выдают эталонный звук с эталонными частотой и интенсивностью, чтобы приблизительно наметить порог слышимости; б) находят начальный звук, соответствующий намеченному значению порога слышимости, при вызове звука с интенсивностью, отличной от прежнего звука, в памяти источника звука в зависимости от того, принят ли ответный сигнал от пользователя на эталонный звук; в) выдают первый тестовый звук, интенсивность которого выставляется на значение, установленное перед начальным звуком, и имеющий эталонную частоту; г) вызывают тестовый звук с интенсивностью и частотой, отличными от интенсивности и частоты прежнего звука, в памяти источника звука в зависимости от того, принят ли ответный сигнал от пользователя на тестовый звук; д) сохраняют принятые данные об ответном сигнале от пользователя на тестовый звук; е) повторяют шаги г)-д); ж) находят порог слышимости для ранее установленной частотной полосы с помощью принятых данных об ответном сигнале; и з) выполняют коррекцию в зависимости от найденного порога слышимости по частоте, при этом контроллер вызывает источник звука при случайном изменении частоты в зависимости от заранее заданного алгоритма случайного прослеживания Бекеши. В другом объекте настоящего изобретения устройство коррекции на основе аудиограммы включает в себя память источника звука, откалиброванную с постоянным шагом в дБСП и хранящую данные источника звука, имеющие множество частотных полос для одного дБСП; контроллер, вызывающий источник звука, чтобы приблизительно наметить порог слышимости пользователя и источник звука из памяти источника звука в процессе тестирования аудиограммы, при этом источник звука имеет интенсивность и (или) частоту, управляемые в зависимости от того, принимается ли ответный сигнал от пользователя, сохраняющий принятые данные об ответном сигнале от пользователя, чтобы найти порог слышимости пользователя по частотной полосе, выполняющий коррекцию в зависимости от найденного порога слышимости; звуковую микросхему, выходной уровень которой управляется с постоянным шагом программой управления выходным уровнем, принимающую сигнал изменения выходного уровня от контроллера, чтобы изменить выходной уровень; и эквалайзер, корректируемый контроллером, причем контроллер вызывает источник звука при случайном изменении частоты в зависимости от заранее заданного алгоритма случайного прослеживания Бекеши. Существующие преимущества Устройство и способ коррекции на основе аудиограммы согласно настоящему изобретению имеют следующие преимущества. Поскольку используются как звуковая микросхема с выходной интенсивностью, управляемой с заранее заданным шагом, так и файл источника звука на основе кривой равной громкости ISO226:2003, аудиограмму можно тестировать точно, а время, требуемое для установки первого тестового звука, можно снизить. Далее, поскольку частотная полоса изменяется случайным образом в процессе тестирования аудиограммы, можно устранить адаптацию или выборочное внимание для конкретной частотной полосы, чтобы найти точный порог слышимости. Далее, поскольку обеспечивается аудиоплейер, в котором выполняется коррекция на основе точного и оперативного порога слышимости, пользователю можно предоставить оптимальный звук и оптимальную функцию защиты слуха. Наконец, поскольку порог слышимости определяется по частотной полосе для управления громкостью, чистый звук можно получить на низкой мощности. Наилучший режим осуществления изобретения Теперь будут сделаны подробные ссылки на предпочтительные варианты осуществления настоящего изобретения, примеры которых иллюстрируются на сопровождающих чертежах. Фиг.2 иллюстрирует устройство коррекции на основе аудиограммы согласно предпочтительному варианту осуществления настоящего изобретения. Как показано на фиг.2, устройство коррекции на основе аудиограммы включает в себя контроллер 200, память 202 источника звука, генератор 204 тестового звука, громкоговоритель 206, ответный переключатель 208, память 210 и эквалайзер 212. Контроллер 200 принимает начальный сигнал для тестирования аудиограммы пользователя и вызывает заранее заданный эталонный звук из памяти 202 источника звука для выдачи эталонного звука на выход через генератор 204 тестового звука и громкоговоритель 206. В качестве контроллера 200 можно использовать микропроцессор. Контроллер 200 вызывает источник звука с отличными дБСП интенсивности из памяти 202 источника звука в зависимости от того, принимается ли ответный сигнал от ответного переключателя 208 в процессе тестирования аудиограммы. Затем контроллер 200 обрабатывает принятый ответный сигнал, чтобы найти порог слышимости пользователя. В частности, контроллер 200 случайным образом изменяет частоту источника звука в зависимости от алгоритма случайного прослеживания Бекеши, чтобы найти порог слышимости. Шаг нахождения порога слышимости будет подробнее описан позже. Память 202 источника звука хранит источник звука, подаваемый пользователю. В настоящем изобретении тестовый звук, откалиброванный с шагом 2,5 дБСП, хранится в памяти 202 источника звука по частотной полосе. Генератор 204 тестового звука соответствует звуковой микросхеме и декодирует источник звука, вызванный из памяти 202 источника звука, чтобы выдавать тестовый звук через громкоговоритель. Память 202 источника звука и генератор 204 тестового звука согласно настоящему изобретению сконструированы для обеспечения самокалибровки, в которой оптимальный тестовый начальный звук можно выбрать в процессе тестирования аудиограммы. После этого будут более подробно описаны самокалибровка и алгоритм случайного прослеживания Бекеши согласно настоящему изобретению. Самокалибровка Как правило, в звуковой микросхеме, которая использует аудиокодек АС97 (который является стандартизованной звуковой микросхемой, встроенной в главную плату ПК в виде перевернутого кристалла на плате) или аудиокодек, подобный аудиокодеку АС97, если используется контроллер на управляющей плате ПК, невозможно высококачественно управлять выходной интенсивностью звуковой микросхемы. Поэтому настоящее изобретение предназначено для управления выходной интенсивностью звуковой микросхемы с шагом 10 дБ на основе алгоритма управления выходом АС97 в прикладной программе контроллера 200. Кроме того, соотношение между выходным уровнем и выходным звуковым давлением установлено таким, как показано в нижеследующей таблице 1.
(Эталонный тон = относительная интенсивность при 1 кГц, 0 дБ) После этого подготавливается список файлов колебаний, который калибруется с шагом 2,5 дБСП по стандарту дБСП на основе кривой равной слышимости ISO226:2003. Как описано выше, тестовый звук, откалиброванный с шагом 2,5 дБСП, хранится в памяти 202 источника звука. В это время тестовый звук предпочтительно хранится в виде файла колебания. Например, обеспечивается память 202 источника звука с каталогами файлов от 50 дБСП до 0 дБСП с шагом 2,5 дБСП. Тестовый звук, разделенный на источники звука по частотной полосе (к примеру, 6, 11, 17 и 34 полосы), используемые при тестировании аудиограммы, хранится в каждом из каталогов файлов колебаний. Выражение «дБСП» (дБ над слуховым порогом) означает, что уровень звукового давления в дБ (УЗД дБ) (dB SPL), т.е. физический стандарт звука преобразуется в психологический акустический стандарт. В настоящем изобретении данные источника звука калибруются на основе кривой равной громкости ISO226:2003, окончательно пересмотренного в августе 2003. После того, как управляется выходная интенсивность звуковой микросхемы и файл колебания, подготовленный на основе кривой равной громкости ISO226, сохраняется как описано выше, выполняется самокалибровка, чтобы найти оптимальный тестовый начальный звук, чтобы приблизительно наметить пороги слышимости слева и справа. В случае самокалибровки первоначальный уровень выходной интенсивности АС97 составляет 100 (на основе максимального значения выходного уровня 10000, см. табл.1). На данном этапе файл колебания, первым вызываемый из памяти 202 источника звука контроллером 2000, является файлом 1 кГц, 50 дБСП (эталонный звук). При тестировании аудиограммы согласно настоящему изобретению, если пользователь не слышит эталонный звук, предлагается тестовый звук более интенсивный, нежели прежний тестовый звук, на 10 дБСП. Для этого контроллер 200 изменяет уровень выходной интенсивности АС97 со 100 (64 дБСП) до 10000 (104 дБСП). В этом случае выдается тестовый звук более интенсивный, нежели первый тестовый звук, на 40 дБ. Затем контроллер 200 вызывает файл колебания 1 кГц 20 дБСП. Если выходной уровень изменяется со 100 на 10000, как указано выше для выхода файла 20 дБСП, пользователю выдается звук с интенсивностью на 60 дБ, интенсивнее на 10 дБСП, чем эталонный звук. Если пользователь не отвечает на звук 60 дБСП, контроллер 200 выводит источник звука 30 дБСП в состоянии, где выходной уровень поддерживается на 10000, так что пользователь может слышать звук 70 дБСП. Если пользователь не распознает этот звук, контроллер 200 выдает пользователю звук с увеличением интенсивности звука на 10 дБСП. Контроллер 200 определяет звук, соответствующий первому ответному сигналу от пользователя, в качестве начального звука и сохраняет этот начальный звука в памяти 210. Между тем, если пользователь выдает ответный сигнал на звук 1 кГц 50 дБСП, выводимый на первом выходном уровне 100, контроллер 200 вызывает источник звука 40 дБСП (частота 1 кГц) из памяти 202 источника звука без изменения выходного уровня. Если ответный сигнал на источник звука 40 дБСП не принимается, контроллер 200 определяет этот источник звука в качестве начального звука. В отличие от этого, если ответный сигнал на источник звука 40 дБСП принимается, контроллер 200 выводит источник звука 30 дБСП (частота 1 кГц) без изменения выходного уровня. Контроллер 200 повторяет шаг нахождения начального звука или шаг понижения интенсивности тестового звука. Как описано выше, контроллер 200 выполняет самокалибровку, которая находит начальный звук, путем различного выведения тестового звука с шагом 10 дБСП в зависимости от того, распознает ли пользователь тестовый звук. Поэтому шаг нахождения начального звука можно укоротить. Иными словами, в известном из уровня техники способе тестирования аудиограммы принципиально требуется неудобное ручное манипулирование тестером для нахождения начального звука. Однако в настоящем изобретении выходная интенсивность звуковой микросхемы управляется с шагом 10 дБ, и оптимальный начальный звук можно легко найти путем изменения выходного уровня контроллера 200. Поэтому в настоящем изобретении время тестирования аудиограммы заметно снижено. Хотя описано, что в качестве звуковой микросхемы используется АС97, а в качестве файла источника звука используется файл колебания, настоящее изобретение не ограничивается таким случаем. Алгоритм случайного прослеживания Бекеши В настоящем изобретении после того, как выполнена самокалибровка, при тестировании аудиограммы используется алгоритм случайного прослеживания Бекеши. Алгоритм случайного прослеживания Бекеши при тестировании аудиограммы состоит в получении чистого тона и тестовой аудиограммы в зависимости от того, отвечает ли тестируемое лицо на этот чистый тон. Однако, как описано выше, в известном из уровня техники способе тестирования аудиограммы (способ Бекеши) управляется только интенсивность тестового звука и эта управляемая интенсивность тестового звука подается тестируемому лицу в состоянии, когда тестер ранее установлен в частотной полосе. Если порог слышимости, наконец, находится в соответствующей частотной полосе, устанавливается следующая частотная полоса. При этом повторяются одни и те же шаги. В этом случае тестирование аудиограммы занимает много времени и происходит адаптация и избирательное внимание в тестовой частотной полосе, так что надежный результат тестирования не получается. В частности, когда тестируются аудиограммы слева и справа в 34 полосах на основе известного из уровня техники алгоритма прослеживания Бекеши, расходуется время, занимающее три часа. В настоящем изобретении контроллер 200 предоставляет тестовый звук путем различной установки частотной полосы на основе заранее заданного алгоритма в процессе тестирования аудиограммы без манипуляций пользователя. Затем используется алгоритм случайного прослеживания Бекеши для нахождения порога слышимости в конкретной частотной полосе в зависимости от того, принимает ли пользователь тестовый звук. Подробнее, как описано выше, если тестовый начальный звук, найденный путем самокалибровки, сохраняется в памяти 210, контроллер 200 вызывает звук (первый тестовый звук) 1 кГц из памяти 202 источника звука и подает этот звук пользователю. В этом случае звук сопровождается интенсивностью выше, нежели интенсивность прежнего начального звука, на заранее заданное значение от 0 дБСП до 15 дБСП. Предпочтительно для точного тестирования аудиограммы используется значение 15 дБСП. Например, если первый тестовый звук подается с интенсивностью выше, нежели интенсивность начального звука, на 15 дБСП, контроллер 200 выводит тестовый звук (второй тестовый звук) меньше или больше, чем первый тестовый звук, на 5 дБСП в зависимости от отклика тестируемого лица. При этом контроллер 200 вызывает второй тестовый звук частотной полосы из памяти 202 источника звука, причем частотная полоса отличается от 1 кГц, который является частотной полосой первого тестового звука. После этого повторяется шаг изменения интенсивности источника звука тестового звука на 5 дБСП в зависимости от отклика пользователя. Если для заранее заданной частотной полосы находят порог слышимости при нарастании звука и порог слышимости при убывании звука, контроллер 200 находит точку, соответствующую 2,5 дБСП от порога слышимости при нарастании звука и порога слышимости при убывании звука как порог слышимости в этой частотной полосе. Если порог слышимости определен, как указано выше, контроллер 200 управляет выходом эквалайзера 212, чтобы воспроизводить звук на основе аудиограммы пользователя. При этом, хотя и не показано, устройство коррекции согласно настоящему изобретению может быть снабжено пользовательской интерфейсной частью, которая может выбирать число частотных полос для нахождения порога слышимости. Поэтому пользователь может выбирать число частотных полос, подлежащих тестированию, и контроллер 200 может находить порог слышимости в зависимости от выбранной частотной полосы. Как описано выше, поскольку контроллер 200 по настоящему изобретению случайным образом изменяет частотную полосу каждого тестового звука и вызывает измененную частотную полосу из памяти 202 источника звука, пользовательских манипуляций для изменения частоты не требуется. Кроме того, возможно избежать искажения аудиограммы вследствие адаптации и избирательного внимания тестируемого лица в известном из уровня техники алгоритме прослеживания Бекеши, в котором аудиограмма тестируется путем изменения только интенсивности звука в одной частотной полосе. Фиг.3 иллюстрирует модуль контроллера согласно предпочтительному варианту осуществления настоящего изобретения. Как показано на фиг.3, контроллер 200 по настоящему изобретению включает в себя модуль 300 вызова источника звука, модуль 302 управления выходным уровнем, модуль 304 приема ответного сигнала, модуль 306 нахождения порога слышимости и модуль 308 вычисления коррекции. Модуль 200 вызова источника звука выводит эталонный звук (к примеру, 1 кГц 50 дБСП) и тестовый звук, установленный ранее в зависимости от отклика пользователя из памяти 202 источника звука, если в нем принимается начальный сигнал тестирования аудиограммы пользователя. В частности, модуль 300 вызова источника звука выводит источник звука с интенсивностью, отличной от интенсивности прежнего тестового звука, в зависимости от отклика пользователя на тестовый звук на шаге нахождения порога слышимости и вызывает тестовый звук частотной полосы из памяти 202 источника звука, причем эта частотная полоса отличается от прежней частотной полосы, поданной пользователю. Модуль 202 управления выходным уровнем управляет выходным уровнем звуковой микросхемы в процессе самокалибровки. В настоящем изобретении для предоставления тестового звука без искажения на основе кривой равной громкости ISO226:2003, данные источника звука сохраняются с шагом 2,5 дБСП с помощью файла колебания 50 дБСП в качестве максимального значения. Как описано выше, источник звука эталонного звука 1 кГц 50 дБСП (на основе максимального выходного уровня 10000) вызывается с помощью первого выходного уровня 100 в случае самокалибровки. Однако если ответный сигнал от пользователя на эталонный звук не принят, требуется звук интенсивнее на 10 дБСП, чем прежний звук. Поскольку файл источника звука 60 дБСП не существует, модуль 202 управления выходным уровнем управляет выходным уровнем на 10000, чтобы обеспечить такой тестовый звук. Модуль 200 вызова источника звука вызывает источник звука 1 кГц 20 дБСП, чтобы предоставить пользователю тестовый звук 60 дБСП. Модуль 304 приема ответного сигнала принимает ответный сигнал от пользователя, распознавшего тестовый звук, который выводится через ответный переключатель 208. Затем модуль 304 приема ответного сигнала передает принятый ответный сигнал в модуль 300 вызова источника звука или модуль 302 управления выходным уровнем. Далее, если ответный сигнал от пользователя не принимается в заранее заданное время после того, как предоставлен тестовый звук, модуль 304 приема ответного сигнала выдает такой неответный сигнал в модуль 300 вызова источника звука или модуль 302 управления выходным уровнем. Модуль 300 вызова источника звука и модуль 302 управления выходным уровнем вызывают отличные данные источника звука или управляют выходным уровнем в зависимости от сигнала, переданного из модуля 304 приема ответного сигнала. Модуль 306 нахождения порога слышимости находит порог слышимости при нарастании звука и порог слышимости при убывании звука по частотной полосе в зависимости от отклика пользователя на тестовый звук, интенсивность которого управляется на 5 дБСП (частота изменяется случайным образом). Модуль 306 нахождения порога слышимости находит среднее значение между порогом слышимости при нарастании звука и порогом слышимости при убывании звука в качестве окончательного порога слышимости соответствующей частотной полосы. Фиг.4 иллюстрирует стандарт для нахождения окончательного порога слышимости согласно предпочтительному варианту осуществления настоящего изобретения. Как показано на фиг.4, модуль 406 нахождения порога слышимости может находить порог слышимости по частотной полосе в зависимости от шести стандартов. На фиг.4 вертикальная линия представляет шаг в 5 дБСП, горизонтальная линия представляет число тестовых звуков, 1 представляет ответ, а 0 представляет неответ. Подробнее, первый пример 400 представляет неответ (0), ответ (1) и неответ (0) по порядку. Если первый тестовый звук 30 дБСП предоставляется в частотной полосе 250 Гц, то первый пример 400 представляет неответ (0). Если тестовый звук интенсивнее, чем прежний тестовый звук, на 5 дБСП (35 дБСП), то первый пример 400 представляет ответ (1). Если тестовый звук ниже, чем прежний тестовый звук, на 5 дБСП (30 дБСП), то первый пример 400 представляет неответ (0). Модуль 306 нахождения порога слышимости сохраняет данные об ответном сигнале от пользователя в памяти 210 с каждой частотой и интенсивностью. В частотной полосе 250 Гц порог слышимости при убывании звука находится как 30 дБСП, порог слышимости при нарастании звука находится как 35 дБСП, а окончательный порог слышимости находится как 32,5 дБСП. Тестовые звуки 30 дБСП, 35 дБСП и 32,5 дБСП подаются пользователю случайным образом (не последовательно) во время тестирования аудиограммы в зависимости от алгоритма случайного прослеживания Бекеши. Второй пример 402 представляет ответ (1), неответ (0) и ответ (1) в конкретной частотной полосе. На данном этапе модуль 306 нахождения порога слышимости находит среднее значение среди тестовых звуков в случае ответа (1), неответа (0) и ответа (1) в качестве окончательного порога слышимости. Третий пример 404 представляет неответ (0), ответ (1) и ответ (1). В третьем примере пользователь, который не отвечает на первый тестовый звук, по меньшей мере дважды отвечает на тестовый звук с той же самой интенсивностью, что и первый тестовый звук. В этом случае модуль 306 нахождения порога слышимости находит тестовый звук с интенсивностью ниже, чем конечный тестовый звук, на 2,5 дБСП в качестве окончательного порога слышимости. В четвертом примере 406 пользователь нерегулярно представляет ответ (1) и неответ (0) на тестовый звук, равный по интенсивности первому тестовому звуку, не отвечая на первый тестовый звук. В этом случае модуль 306 нахождения порога слышимости находит конечный тестовый звук как порог слышимости при убывании звука и находит значение более интенсивное, чем порог слышимости при убывании звука, на 2,5 дБСП как окончательный порог слышимости. В пятом же примере 408 пользователь отвечает на первый тестовый звук, но по меньшей мере дважды не реагирует на следующий тестовый звук той же самой интенсивности, что и первый тестовый звук. В этом случае модуль 306 нахождения порога слышимости находит тестовый звук более интенсивный, чем конечный тестовый звук, на 2,5 дБСП как окончательный порог слышимости. Наконец, в шестом примере 410 пользователь отвечает на первый тестовый звук два раза из трех. В этом случае модуль 306 нахождения порога слышимости находит первый тестовый звук как порог слышимости при нарастании звука и находит тестовый звук с интенсивностью ниже, чем первый тестовый звук, на 2,5 дБСП как окончательный порог слышимости. Вышеупомянутые шесть стандартов нахождения включают в себя все возможные случаи, и тестирование аудиограммы, подвергнутое алгоритму случайного прослеживания Бекеши, пригодно в соответствии с этими стандартами. Если порог слышимости по частотной полосе находится модулем 306 нахождения порога слышимости, как описано выше, модуль 308 вычисления коррекции выполняет коррекцию на основе окончательного порога слышимости. Поскольку эквалайзер общеизвестен, его описание в настоящем изобретении будет опущено. Фиг.5 иллюстрирует результат управления громкостью аудиоплейера, в котором коррекция на основе аудиограммы выполняется согласно предпочтительному варианту осуществления настоящего изобретения. Результат управления громкостью по фиг.5 будет описан в сравнении с фиг.1. При управлении громкостью известного из уровня техники аудиоплейера, поскольку управление громкостью производится линейно, например громкость увеличивается до 90 дБСП во всех частотных полосах (см. фиг.1), могут происходить искажение звука и утомление в конкретной слуховой клетке (первая группа 100). Однако в настоящем изобретении, поскольку управление громкостью выполняется после коррекции, управление громкостью в диапазоне 75 дБСП можно выполнять соответственно в первой группе 100 и во второй группе 102. В этом случае группа клеток, чувствительных к интенсивности, защищается, тогда как в группу клеток, менее восприимчивых к интенсивности, может подаваться звук большей интенсивности, чтобы дать пользователю возможность прослушивать желательный звук. Фиг.6 представляет собой блок-схему алгоритма, иллюстрирующую коррекцию на основе аудиограммы согласно предпочтительному варианту осуществления настоящего изобретения. На фиг.6 контроллер 200 выводит эталонный звук 1 кГц 50 дБСП на шаге S600 и на шаге S602 определяет, принимается ли ответный сигнал от пользователя в ответ на эталонный звук. Если ответный сигнал принимается, контроллер 200 выводит звук с интенсивностью ниже, чем интенсивность эталонного сигнала, на 10 дБСП на шаге S604. Контроллер находит на шаге S606, принимается ли ответный сигнал от пользователя на звук 40 дБСП. Если ответный сигнал принимается, контроллер 200 повторяет шаг S604. Если же ответный сигнал не принимается, контроллер 200 находит в это время тестовый звук как начальный звук и сохраняет этот тестовый звук в памяти 210 на шаге S612. При этом на шаге 602, если ответный сигнал не принимается, контроллер 200 на шаге S608 выводит звук с интенсивностью более высокой, чем интенсивность эталонного сигнала, на 10 дБСП. Контроллер 200 находит на шаге S610, принимается ли ответный сигнал от пользователя на звук с интенсивностью более высокой, чем интенсивность эталонного сигнала, на 10 дБСП. Если ответный сигнал не принимается, контроллер 200 повторяет шаг S608. Если же ответный сигнал принимается, контроллер 200 находит звук в это время в качестве начального звука на шаге S612. Если начальный звук находится, как описано выше, контроллер 200 выводит первый тестовый звук с интенсивностью более высокой, чем интенсивность начального звука, на 15 дБСП на шаге S614 и находит на шаге S616, отвечает ли пользователь на первый тестовый звук. Если пользователь отвечает на первый тестовый звук, то на шаге S618 контроллер 200 определяет, все ли пороги слышимости полностью найдены на заранее заданной частотной полосе. Если пороги слышимости не найдены полностью, контроллер 200 предоставляет пользователю тестовый звук с интенсивностью ниже, чем интенсивность прежнего тестового звука, на 5 дБСП на шаге S620. Если при этом пользователь не реагирует на тестовый сигнал на шаге S616, контроллер 200 определяет на шаге S622, все ли пороги слышимости полностью найдены. Если пороги слышимости найдены не полностью, контроллер 200 на шаге S624 предоставляет пользователю тестовый звук с интенсивностью больше, чем интенсивность прежнего тестового звука, на 5 дБСП. Как описано выше, после того, как пользователю предоставлен тестовый сигнал, измененный с шагом 5 дБСП по сравнению с прежним тестовым звуком, повторяются шаги S618 и S620 или шаги S622 и S624 в зависимости от того, принят ли ответный сигнал от пользователя. Если все пороги слышимости полностью найдены на шагах S618 и S622, контроллер 200 на шаге S626 сохраняет порог слышимости по частотной полосе в памяти 210 и выполняет коррекцию в зависимости от порога слышимости, сохраненного в памяти 210. Как описано выше, устройство и способ коррекции на основе аудиограммы согласно настоящему изобретению имеют следующие преимущества. Поскольку используются как звуковая микросхема с выходной интенсивностью, управляемой с заранее заданным шагом, так и файл источника звука на основе кривой равной громкости ISO226:2003, аудиограмму можно тестировать точно, а время, требуемое для установки первого тестового звука, можно снизить. Далее, поскольку частотная полоса изменяется случайным образом в процессе тестирования аудиограммы, можно устранить адаптацию или выборочное внимание для конкретной частотной полосы, чтобы найти точный порог слышимости. Далее, поскольку обеспечивается аудиоплейер, в котором выполняется коррекция на основе точного и оперативного порога слышимости, пользователю можно предоставить оптимальный звук и оптимальную функцию защиты слуха. Наконец, поскольку порог слышимости определяется по частотной полосе для управления громкостью, чистый звук можно получить на низкой мощности. Хотя настоящее изобретение описано и проиллюстрировано здесь со ссылкой на предпочтительные варианты его осуществления, специалистам понятно, что различные модификации и варианты могут быть сделаны в нем без отхода от сущности и объема изобретения. Таким образом, подразумевается, что настоящее изобретение покрывает модификации и варианты данного изобретения, которые попадают в объем приложенной формулы изобретения и ее эквивалентов.
Формула изобретения
1. Способ коррекции на основе аудиограммы с помощью устройства коррекции, включающего в себя память источника звука, откалиброванную с постоянным шагом в дБСП и хранящую данные источника звука, имеющие множество частотных полос для одного дБСП, звуковую микросхему, контроллер, вызывающий данные источника звука, громкоговоритель и эквалайзер, содержащий шаги, на которых: а) выдают эталонный звук с эталонными частотой и интенсивностью, чтобы приблизительно наметить порог слышимости; б) находят начальный звук, соответствующий намеченному значению порога слышимости, при вызове звука с интенсивностью, отличной от прежнего звука, в памяти источника звука в зависимости от того, принят ли ответный сигнал от пользователя на эталонный звук; в) выдают первый тестовый звук, интенсивность которого выставляется на значение, установленное перед начальным звуком, и имеющий эталонную частоту; г) вызывают тестовый звук с интенсивностью и частотой, отличными от интенсивности и частоты прежнего звука, в памяти источника звука в зависимости от того, принят ли ответный сигнал от пользователя на тестовый звук; д) сохраняют принятые данные об ответном сигнале от пользователя на тестовый звук; е) повторяют шаги г)-д); ж) находят порог слышимости для ранее установленной частотной полосы с помощью принятых данных об ответном сигнале; и з) выполняют коррекцию в зависимости от найденного порога слышимости по частоте, при этом контроллер вызывает источник звука при случайном изменении частоты в зависимости от заранее заданного алгоритма случайного прослеживания Бекеши. 2. Способ коррекции на основе аудиограммы по п.1, в котором звуковая микросхема имеет максимальную выходную интенсивность и минимальную выходную интенсивность, которые разделяются с постоянным шагом посредством алгоритма управления выходной интенсивностью, причем выходная интенсивность изменяется на заранее заданный выходной уровень, и память источника звука сохраняет данные источника звука, откалиброванные с шагом 2,5 дБСП от 50 дБСП до 0 дБСП (от 50 дБСП до 0 дБСП означает, что интенсивность соответствующего дБСП слышна как конкретный выходной уровень). 3. Способ коррекции на основе аудиограммы по п.2, в котором шаг б) включает в себя шаги, на которых: и) выдают звук с интенсивностью больше интенсивности прежнего звука на 10 дБСП, если ответный сигнал от пользователя на эталонный звук принимается, и сохраняют звук соответствующей интенсивности, если ответный сигнал принимается (сохраненный звук соответствует начальному звуку); и к) выдают звук с интенсивностью ниже интенсивности прежнего звука на 10 дБСП, если ответный сигнал от пользователя не принимается, и сохраняют звук, соответствующий интенсивности, если ответный сигнал принят (сохраненный звук соответствует начальному звуку). 4. Способ коррекции на основе аудиограммы по п.3, в котором контроллер вызывает данные источника звука 1 кГц 50 дБСП из памяти источника звука для выдачи эталонного звука 1 кГц 50 дБСП пользователю на первом выходном уровне и управляют выходным уровнем на более высоком уровне для выдачи звука с интенсивностью больше звука 50 дБСП, если ответный сигнал от пользователя на эталонный сигнал не принимается на шаге и). 5. Способ коррекции на основе аудиограммы по п.1, в котором первый тестовый звук соответствует звуку с интенсивностью больше интенсивности начального звука на 15 дБСП, при этом тестовый звук, управляемый на шаге г), имеет разность интенсивности 5 дБСП от интенсивности прежнего тестового звука, и контроллер находит окончательный порог слышимости в диапазоне 2,5 дБСП между порогом слышимости при нарастании звука и порогом слышимости при убывании звука в конкретной частотной полосе в зависимости от того, принимается ли ответный сигнал от пользователя. 6. Способ коррекции на основе аудиограммы по п.1, содержащий далее шаг, на котором находят число частотных полос для нахождения порога слышимости в зависимости от входного сигнала пользователя, при этом контроллер вызывает данные источника звука и находит порог слышимости для соответствия числу найденных частотных полос. 7. Способ коррекции на основе аудиограммы по п.6, в котором число частотных полос соответствует любому числу из 6 полос, 11 полос, 17 полос и 34 полос. 8. Устройство коррекции на основе аудиограммы, содержащее: память источника звука, откалиброванную с постоянным шагом в дБСП и хранящую данные источника звука, имеющие множество частотных полос для одного дБСП; контроллер, вызывающий источник звука, чтобы приблизительно наметить порог слышимости пользователя и источник звука из памяти источника звука в процессе тестирования аудиограммы, при этом источник звука имеет интенсивность и (или) частоту, управляемые в зависимости от того, принимается ли ответный сигнал от пользователя, сохраняющий принятые данные об ответном сигнале от пользователя, чтобы найти порог слышимости пользователя по частотной полосе, выполняющий коррекцию в зависимости от найденного порога слышимости; звуковую микросхему, выходной уровень которой управляется с постоянным шагом программой управления выходным уровнем, принимающую сигнал изменения выходного уровня от контроллера, чтобы изменить выходной уровень; и эквалайзер, корректируемый контроллером, причем контроллер вызывает источник звука при случайном изменении частоты в зависимости от заранее заданного алгоритма случайного прослеживания Бекеши. 9. Устройство коррекции на основе аудиограммы по п.8, в котором память источника звука сохраняет множество данных источника звука с шагом 2,5 дБСП от 50 дБСП до 0 дБСП на основе кривой равной громкости ISO226:2003, и контроллер вызывает данные источника звука 1 кГц 50 дБСП из памяти источника звука для выдачи эталонного звука 1 кГц 50 дБСП пользователю на первом выходном уровне и управляют выходным уровнем на более высоком уровне, если тестовый звук, предоставленный пользователю на основе первого выходного уровня, должен быть больше, чем 50 дБСП.
РИСУНКИ
|
||||||||||||||||||||||||||