Патент на изобретение №2341907
|
||||||||||||||||||||||||||
(54) СПОСОБ МИКШИРОВАНИЯ РЕЧЕВЫХ СИГНАЛОВ АБОНЕНТОВ ПРИ ПРОВЕДЕНИИ VoIP-КОНФЕРЕНЦИЙ
(57) Реферат:
Изобретение относится конференц-системам построенным на базе технологии передачи речи по сетям с пакетной коммутацией (VoIP). Способ заключается в том, что на VoIP сервере декодируют получаемый по сети передачи данных кодированный речевой сигнал каждого абонента, измеряют уровень громкости речевого сигнала каждого абонента, суммируют речевые сигналы, уровень громкости которых превышает заранее заданный уровень, кодируют и передают полученную сумму каждому абоненту, при передаче полученной суммы абоненту, уровень громкости речевого сигнала которого превышает заранее заданный уровень, из нее вычитают сигнал текущего абонента. Технический результат заключается в исключении возможности усиления акустического эха в конференц-системе и снижении затрат на системные ресурсы. 10 з.п. ф-лы, 3 ил.
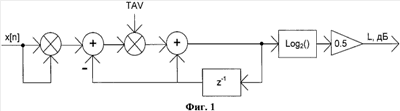
Область техники, к которой относится изобретение. Изобретение относится конференц-системам, построенным на базе технологии передачи речи по сетям с пакетной коммутацией (VoIP), и, в частности, к способу микширования речевых сигналов абонентов на сервере конференц-системы. Уровень техники В настоящее время разработано множество конференц-систем, построенных на базе технологии передачи речи по сетям с пакетной коммутацией (VoIP), обеспечивающих соединение множества абонентов. Так, например, авторское свидетельство №1527719 А1, опубл. 07.12.1989, раскрывает устройство для передачи речевых сигналов в системах с импульсно-кодовой модуляцией, содержащее систему синхронизации, сумматор абонентских блоков, которые в свою очередь содержат приемопередатчики, обнаружитель сигналов, мультиплексор и другие блоки. Причем обнаружитель определяет наличие или отсутствие речевого сигнала по его цифровому потоку в каждом канале, и при отсутствии речевого сигнала от местного абонента его не суммируют с сигналом, поступившим из линии от другого абонента. Другое авторское свидетельство №1789055 A3, опубл. 15.01.1993, раскрывает устройство цифровой распределительной конференц-связи, содержащее: передающие узлы, связанные кольцевой линией связи, каждый из которых содержит блок формирования кадра, блок приема данных, ЦАП, АЦП, и два коммутатора. Причем блок формирования кадра осуществляет суммирование сигналов всех участников конференц-связи, а блок приема данных для снижения уровня собственных шумов вычитает собственный сигнал говорящего абонента из суммы сигналов всех участников конференц-связи. Заявка США №2005094580 А1, МПК H04L 12/16, опубл. 05.05.2005, раскрывает систему управления многоточечной звуковой конференцией в сети пакетной коммутации, которая содержит: многоточечный блок управления, расположенный в пределах первой оконечной точки и предназначенный для установления соединений звуковой связи между указанной первой оконечной точкой и каждой из множества других оконечных точек, которые участвуют в многоточечной звуковой конференции. Смешивание акустических сигналов осуществляют от упомянутой первой оконечной точки и от упомянутого множества других оконечных точек, а компенсацию эха для акустических сигналов от упомянутой первой оконечной точки осуществляют в многоточечном блоке управления с компенсатором эха, посредством адаптивного фильтра. Причем управление операцией адаптивной фильтрации осуществляют в ответ на определение, сделанное контроллером и основанное на характеристиках указанных акустических сигналов, таких как: возникновение одновременного разговора, состояние тишины или речи. Также известна система для звукового группового вещания, раскрытая в Европейском патенте №1708471 А1, опубл. 04.10.2006, включающая: множество оконечных точек конференц-связи, с активными и пассивными участниками для связи с сервером. Сервер создает смешанный звуковой поток от полученных звуковых пакетов активных оконечных точек и осуществляет групповое вещание смешанного аудио ко всем оконечным точкам конференц-связи. Оконечные точки определяют, включает ли полученное смешанное аудио какое-нибудь самообразующееся аудио, сравнивая полученный пакет с типовым пакетом самообразующегося аудио, сохраненным до передачи к серверу, если имеет место совпадение, оконечная точка удаляет самообразующееся аудио от смешанного аудио и осуществляет аудио конференцию. Недостаток известных систем заключается в том, что при подключении к конференц-серверу абонентов с оконечными устройствами с заметным уровнем акустического эха (некачественный телефонный аппарат) возможны следующие ухудшения качества работы конференц-сервера: – значительное повышение уровня эхо сигнала (при суммировании сигнала от всех абонентов при условии одинаковой сетевой задержки), – появление многократного эхосигнала (при различных сетевых задержках), – переход в состояние автогенерации конференц-сервера (в случае большого количества абонентов с большим уровнем акустического эха с одинаковыми и малыми сетевыми задержками), – повышение уровня эхосигнала на элементах автоматической регулировки коэффициента усиления. В корейской заявке №20010035317, опубликованной 07.05.2001, раскрыта VoIP конферец-система, частично решающая указанные выше недостатки путем синхронизации голоса и потока, а также путем использования технологии буферизации голоса. В патенте США №6327276 В1, опубл. 04.12.2001, раскрыта другая система конференц-связи со множеством клиентов в сети связи LAN/WAN, включающая: множество клиентов, соединенных с упомянутой сетью для того, чтобы передавать/получать сигналы к/от упомянутой сети; и сервер, связанный с упомянутой сетью, чтобы получать множество сигналов, переданных от упомянутого множества клиентов в упомянутой сети, и смешивая упомянутое множество сигналов, создавая единственный сигнал группового вещания и передавая сигнал группового вещания каждому из упомянутого множества клиентов, причем упомянутое множество сигналов включает пакеты данных определенной продолжительности, а сервер включает: буферный джиттер регистр для того, чтобы синхронизировать пакеты данных, полученные от упомянутого множества клиентов, регулируемый контроллер усиления/уменьшения для регулировки усиления/уменьшения, по крайней мере, одного синхронизированного пакета данных, и смеситель для смешивания упомянутых синхронизированных и отрегулированных пакетов данных упомянутого множества сигналов, чтобы создать единственный сигнал группового вещания для передачи к каждому упомянутому множеству клиентов сети. Причем для снижения эффекта эха система содержит устройство вычитания, которое вычитает от сигнала группового вещания собственный сигнал клиента. Также следует отметить, что система осуществляет вышеуказанное усиление индивидуальных сигналов на основе информации от энергетических детекторов таким образом, чтобы минимизировать изменение сигнальных уровней между различными дикторами, и регулирует усиление так, чтобы помеха от дикторов, которые не говорят, была подавлена. Однако такие системы не позволяет полностью решить проблему эхосигнала, используя при этом громадные вычислительные ресурсы, что в свою очередь увеличивает стоимость такой системы. Применение эхоподавителей, рассчитанных на подавление акустического эха, для каждого абонента конференции также вызовет грандиозные потребности в вычислительных ресурсах из-за больших переменных задержек, возникающих при передаче через пакетную сеть, и потерь пакетов в сети. Основными особенностями работы любой конференции является: – каждый абонент при подключении к конференции большую часть времени слушает других абонентов, – все абоненты при конференц-связи одновременно не говорят. Учитывая особенность активности абонента при конференц-связи нужно производить микширование сигнала только при наличии в сигнале речевой активности абонента. Для определения речевой активности в сигнале разработан и стандартизован ряд детекторов речевой активности (VAD – voice activity detector) (см., например, международную заявку №2002/060166, опубл. 01.08.2002). Использование VAD не решает проблему исключения из процесса микширования акустического эхосигнала. VAD разработан для определения активности речи в широком диапазоне уровней громкости и выделения вокализованных фрагментов на уровне фоновых шумов. По этой причине, если уровень эхосигнала достаточно высок (около -30 дБ), VAD выдает признак наличия активности речевого сигнала. Поэтому VAD позволяет исключить из процесса микширования только фоновые шумы и акустический речевой эхосигнал, низкий по уровню громкости. Поэтому задачей настоящего изобретения является разработка комплекса мер по исключению возможности усиления акустического эха в конференц-системе и снижению затрат на системные ресурсы. Сущность изобретения Поставленная задача решается с помощью способа микширования речевых сигналов абонентов при проведении VoIP-конференций, заключающегося в том, что на VoIP сервере декодируют получаемый по сети передачи данных кодированный речевой сигнал каждого абонента, измеряют уровень громкости речевого сигнала каждого абонента, суммируют речевые сигналы, уровень громкости которых превышает заранее заданный уровень и VAD выдает признак вокализованности данного фрагмента, полученную сумму передают на кодирование для отправки каждому абоненту, причем если уровень громкости речевого сигнала абонента превышает заранее заданный уровень (сигнал был микширован), то из нее вычитают сигнал текущего абонента, полученный сигнал кодируют и передают абоненту. При этом задают пороговый уровень сигнала приблизительно равным -30 дБ. В одном из вариантов осуществления изобретения продолжают суммировать речевые сигналы, уровень громкости которых превышает заранее заданный уровень в течение 100 мс, после того как уровень громкости этих сигналов упал ниже заранее заданного значения. Еще в одном варианте осуществления изобретения декодирование и кодирование осуществляется, по меньшей мере, одним из следующих кодеков: G.711, G.723 и G.729, при этом набор кодеков может быть расширен. Еще в одном варианте осуществления изобретения перед суммированием регулируют уровни громкости речевых сигналов, уровень громкости которых превышает заранее заданный уровень. При этом регулировку осуществляют только на вокализованных участках. Еще в одном варианте осуществления изобретения, в случае если уровень громкости речевых сигналов всех абонентов ниже заранее заданного уровня, генерируют и передают каждому абоненту сигнал комфортного шума. Еще в одном из вариантов осуществления изобретения ограничивается количество абонентов, сигнал которых используется при микшировании. Если количество абонентов с сигналом выше порогового значения больше заданного ограничения, то при микшировании используется сигнал от абонентов с самым высоким уровнем громкости, причем количество одновременно микшируемых абонентов ограниченно заданным числом. Еще в одном из вариантов осуществления изобретения при ограниченном количестве микшируемых абонентов при снижении уровня громкости сигнала абонента, который был в предыдущем периоде замикширован, микширование сигнала от этого абонента продолжается еще не менее 100 мс. Еще в одном варианте осуществления изобретения все действия способа осуществляют над порциями сигнала, длина которых равна 10 мс. Краткое описание чертежей Фиг.1. Блок-схема измерителя RMS речевого сигнала. Фиг.2. Алгоритм обработки входящих пакетов от абонентов. Фиг.3. Алгоритм микширования. Подробное описание изобретения Конференц-система согласно настоящему изобретению включает конференц-сервер VoIP и, по меньшей мере, два терминала абонента, соединенные между собой сетью передачи данных. Настоящее изобретение далее будет рассматриваться на примере функционирования DSP-части (цифровой процессор сигналов) конференц-сервера VoIP, с момента получения пакета кодированного речевого сигнала из буфера удаления джиттера. Выборка пакетов кодированного речевого сигнала из буфера деджиттерера производится с периодом поступления пакетов от абонента через сеть передачи данных, для этого для каждого абонента создается таймер с периодом сработки, равным периоду потока пакетов реального времени этого абонента из сети. Этот период рассчитывается исходя из длины фрейма кодека (например, G.711 – 1 мс, G.729 – 20 мс, G.723.1 – 30 мс) и количество фреймов в пакете. По каждой сработке таймера из буфера удаления джиттера вынимается один пакет. Если очередного пакета в буфере нет (по причине потерь пакетов в сети), то в этом случае создается пакет с нулевой длиной, что является признаком необходимости активизации алгоритма маскирования потерь (PLC) декодера. Тем самым на выходе декодера будет обеспечен непрерывный поток отсчетов речевого сигнала абонента размерностью 16 бит с частотой дискретизации 8 кГц. Полученный из буфера деджиттерера пакет помещается в буфер FIFO, создаваемый отдельно для каждого абонента. С поступлением каждого пакета в буфер FIFO ядру конференц-сервера выдается уведомление о приходе нового пакета. Эти уведомления запускают механизм микширования, который будет описан ниже. Конференц-сервер должен поддерживать работу с различными кодеками. Длины фреймов различных кодеков различаются. Поэтому необходимо выбрать порцию сигнала, кратную длительности фреймов всех кодеков, на основе которой будет производиться микширование сигналов от всех абонентов. Известно, что период стационарности речевого сигнала составляет 10-30 мс. Исходя из этого факта, разработаны все модельные кодеки речи (в том числе G.729, G.723.1). Поэтому логичным выбором длительности порции сигнала для микширования является 10 мс. При работе с кодеком G.711 возможны потенциальные трудности при использовании периода микширования, равного 10 мс, так как длительность фрейма у этого кодека составляет 1 мс. Исходя из реальностей использования кодека G.711 в сетях с коммутацией пакета ясно, что использовать этот кодек при размерах пакета меньше 10 мс не эффективно из-за наличия больших накладных расходов, связанных с добавлением к каждому пакету речевого сигнала дополнительной служебной информации: IP, UDP, RTP заголовки. Тем самым общепринятым минимальным размером пакета G.711 кодека является длина в 10 мс. Кроме того, для обеспечения корректности работы конференц-сервера, в случае если абонент все же будет использовать длину пакета кодека G.711 меньше 10 мс, такие соединения будут разрываться. Декодер каждого абонента имеет функцию short* PutBatch(Q), при помощи которой ядро конференц-связи получает адрес массива, в котором хранится 10 мс звукового сигнала абонента. Так как можно декодировать принятый фрейм целиком, то в составе каждого декодера присутствует буфер длиною больше или равный 10 мс в зависимости от длительности кодированного фрейма. При вызове функции декодера PutBatch(Q) происходит декодирование необходимого количества фреймов из пакетов, хранящихся во входном буфере FIFO, для заполнения внутреннего буфера и на выход выдается указатель на адрес начала очередного звукового массива. Алгоритм обработки исходящего сигнала от абонента представлен на фиг.2, окончательный алгоритм микширования представлен на фиг.3. Алгоритм микширования работает следующим образом: 1. Инициация работы ядра конференц-сервера производится уведомлением о поступлении нового пакета в буфер FIFO любого из абонентов. 2. По каждому уведомлению происходит сбор с декодеров каждого абонента звуковых массивов длительностью 10 мс, которые суммируются во внутреннем буфере ядра конференц-сервера. 3. Если в очереди пакетов запрашиваемого абонента нет следующего пакета и в буфере декодера абонента не набралось еще 10 мс массива, то работа ядра конференц-сервера приостанавливается до следующего уведомления о приходе нового пакета. Причем по приходу очередного уведомления сбор данных начинается с абонента, на котором в прошлый раз произошла приостановка работы. 4. После того как ядро конференц-сервера получило 10 мс массив от последнего абонента, у кодеров каждого абонента вызывается функция void GetBatch(short* BatchBuffer, short* DecoderBuffer). Первый параметр функции GetBatch указывает на начало буфера, в котором производилось суммирование звуковых массивов всех абонентов, второй параметр указывает на начало звукового массива, который был выдан декодером этого же абонента ядру конференц-сервера. При вызове данной функции во внутренний буфер кодера копируется массив сумм звуковых сигналов всех абонентов. Затем из сигнала в буфере кодера производится вычитание сигнала текущего абонента для исключения эффекта локального эха. После того как во внутреннем буфере кодера наберется массив, необходимый для кодирования одного фрейма, производится кодирование сигнала, заполнение выходного пакета для отправки абоненту и очистка внутреннего буфера. После заполнения пакета необходимым количеством фреймов производится отправка пакета абоненту. 5. После выдаче кодеру последнего абонента массива микшированного сигнала производится переход на начальный этап работы. Приведенный выше алгоритм позволяет организовывать конференц-связь любого количества абонентов с различными наборами поддерживаемых кодеков. Причем качество связи для каждого абонента определяется качеством обработки речи кодека, используемым данным абонентом. Со стороны абонента подключение к конференц-серверу ничем не отличается от соединения с любым другим абонентом VoIP сети, то есть при подключении абонента к конференц-серверу создается два RTP потока – входящий и исходящий. Если не принимать никаких дополнительных мер, то при использовании алгоритма, приведенного выше, и подключении к конференц-серверу абонентов с оконечными устройствами с заметным уровнем акустического эха (не качественный телефонный аппарат) возможны ухудшения качества работы конференц-сервера (линейное эхо, возникающее на гибридах в телефонных сетях, не учитывается, так как это эхо должно быть подавлено на шлюзах в пакетную сеть). Эхосигнал отличается от речи абонента только по уровню громкости. Примерное значение уровня эхосигнала даже у плохого телефонного аппарата составляет около -30 дБ. Поэтому для исключения из процесса микширования сигнал, содержащего только акустический эхосигнал, необходимо кроме использования VAD производить измерение уровня громкости сигнала. Если уровень сигнала ниже -30 дБ, то такой сигнал не используется при микшировании. При измерении громкости сигнала производится измерение его среднеквадратического значения (RMS – root-mean-square) при помощи схемы, представленной на фиг.1. В представленном измерителе RMS TAV – определяет интегрирующие свойства измерителя (чем больше TAV, тем короче период интегрирования). Переход в логарифмическую шкалу отражает особенность слухового аппарата человека воспринимать громкость звуков, а использование логарифма по основанию 2 определяется простотой целочисленного представления алгоритма вычисления логарифма. Умножение на коэффициент 0,5 соответствует извлечению квадратного корня в линейной шкале. Обычной ситуацией при проведении конференц-связи является, когда один абонент говорит, а все остальные слушают. В редких случаях несколько абонентов говорят одновременно. Если одновременно говорит больше трех абонентов, то воспринимать информацию становится практически невозможно. Поэтому можно ограничиться максимум тремя-пятью абонентами, сигнал от которых будет микшироваться. Выбор активных абонентов должен производиться на основании уровня громкости сигнала, наличия признака вокализованности фрагмента и истории сигнала каждого абонента. Количество активных абонентов не обязательно должно быть все время максимальным, количество может уменьшаться до 0. В случае если в текущий момент нет активных абонентов, то необходимо включать генератор комфортного шума (CNG – comfort noise generator), так как абсолютная тишина в телефонной трубке вызывает дискомфорт общения. Другим вариантом использования CNG может быть постоянное добавление комфортного шума даже в случае присутствия активных абонентов для исключения неприятных для абонентов переходов от микширования сигналов абонентов к полностью комфортному шуму. Кроме того, при выборе активных абонентов необходимо учитывать характер человеческой речи, заключающийся в низком уровне окончаний слов. Для этого если в процессе микширования было принято решение, что данный абонент в текущий момент является активным, то необходимо продолжать микширование сигнала от этого абонента в течение 100 мс после того, как уровень громкости сигнала упал ниже порога активности или стал ниже, чем у другого абонента. К конференц-серверу могут подключаться абоненты с различными оконечными устройствами от различных производителей с различными уровнями громкости сигнала от абонента, поэтому для повышения комфортности общения через конференц-сервер необходимо обеспечить примерно одинаковый уровень звукового сигнала от каждого абонента. Выравнивание уровня громкости сигнала от абонентов производится при помощи алгоритма автоматической регулировки усиления (АРУ). Основной особенностью алгоритма АРУ, используемого в конференц-сервере, является то, что регулировка коэффициента усиления сигнала должна производиться только на вокализованных участках. Регулировка коэффициента усиления только на вокализованных участках позволяет избежать резких повышений коэффициента усиления в паузах речи, тем самым исключается эффект «пульсирующего звука». Еще одной особенностью применяемого АРУ является достаточно высокий уровень сигнала, с которого начинается регулировка текущего коэффициента усиления для исключения значительного повышения акустического эхосигнала. Настоящее изобретение позволяет проводить конференц-связь пользователей с различными наборами поддерживаемых кодеков. Алгоритм обработки сигнала, поступающего от абонентов, алгоритм выбора активных абонентов позволяет исключить автогенерацию конференц-сервера в случае подключения большого количества абонентов с высоким уровнем акустического эха и повысить комфорт общения за счет исключения из процесса микширования фоновых шумов неактивных абонентов.
Формула изобретения
1. Способ микширования речевых сигналов абонентов при проведении VoIP-конференций, заключающийся в том, что на VoIP сервере декодируют получаемый по сети передачи данных кодированный речевой сигнал каждого абонента, измеряют уровень громкости речевого сигнала каждого абонента, суммируют речевые сигналы, уровень громкости которых превышает заранее заданный уровень, кодируют и передают полученную сумму каждому абоненту, при передаче полученной суммы абоненту, уровень громкости речевого сигнала которого превышает заранее заданный уровень, из нее вычитают сигнал текущего абонента. 2. Способ по п.1, отличающийся тем, что продолжают суммировать речевые сигналы, уровень громкости которых превышает заранее заданный уровень в течение не менее 100 мс, после того как уровень громкости этих сигналов упал ниже заранее заданного значения. 3. Способ по п.1, отличающийся тем, что задают уровень сигнала приблизительно равным -30 дБ. 4. Способ по п.1, отличающийся тем, что декодирование и кодирование осуществляется по меньшей мере одним из следующих кодеков: G.711, G.723 и G.729. 5. Способ по п.1, отличающийся тем, что перед суммированием регулируют уровни громкости речевых сигналов, уровень громкости которых превышает заранее заданный уровень. 6. Способ по п.5, отличающийся тем, что регулировку осуществляют только на вокализованных участках и нижний уровень начала регулировки коэффициента достаточно высок для исключения усиления эхосигнала. 7. Способ по п.1, отличающийся тем, что в случае, если уровень громкости речевых сигналов всех абонентов ниже заранее заданного уровня, генерируют и передают каждому абоненту сигнал комфортного шума. 8. Способ по п.7, отличающийся тем, что сигнал комфортного шума добавляется при микшировании сигналов от абонентов. 9. Способ по п.1, отличающийся тем, что все действия способа осуществляют над порциями сигнала. 10. Способ по п.9, отличающийся тем, что длина порции сигнала равна 10 мс. 11. Способ по п.2, отличающийся тем, что количество одновременно микшируемых абонентов ограничено.
РИСУНКИ
|
||||||||||||||||||||||||||