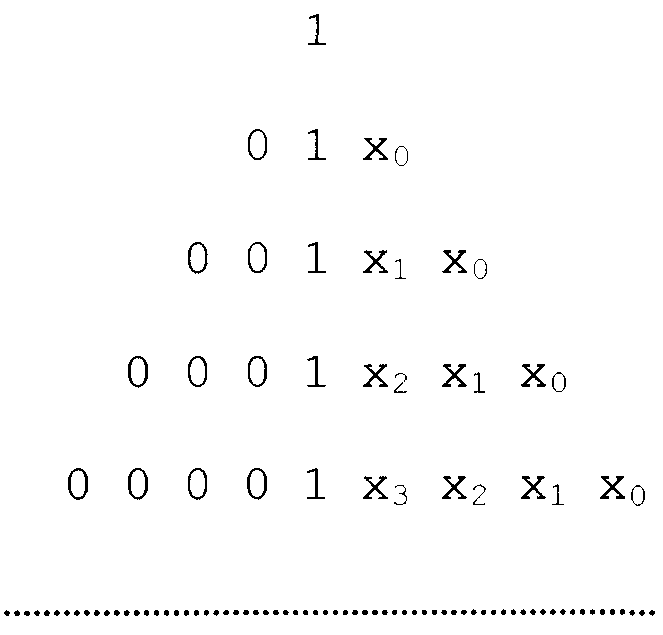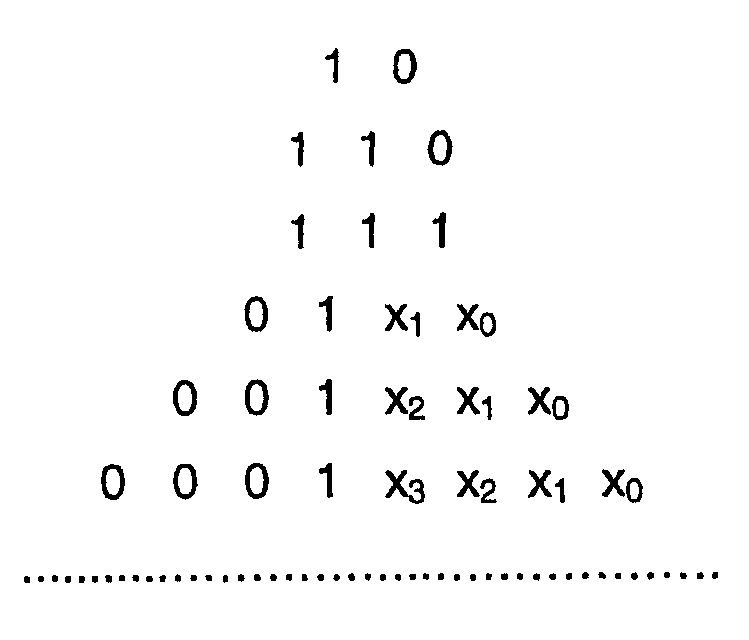Патент на изобретение №2335845
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(54) КОДИРОВАНИЕ КОЭФФИЦИЕНТОВ ПРЕОБРАЗОВАНИЯ В КОДЕРАХ И/ИЛИ ДЕКОДЕРАХ ИЗОБРАЖЕНИЯ/ВИДЕОСИГНАЛА
(57) Реферат:
Изобретение относится к способу кодирования набора символов данных, содержащего нулевые символы данных и ненулевые символы данных, при котором назначают кодовое слово для представления ненулевого символа данных и связанного с ним числа предшествующих или последующих нулевых символов данных посредством операции отображения. Согласно изобретению операцию отображения, посредством которой кодовое слово назначают ненулевому символу данных и связанному с ним числу предшествующих или последующих символов данных, адаптируют в зависимости от максимально возможного числа нулевых символов данных в наборе символов данных. Описываются также соответствующий способ декодирования, кодирующее и декодирующее устройства. Технический результат – снижение объема передаваемой информации при сохранении приемлемого качества изображения. 8 н. и 36 з.п. ф-лы, 7 ил. 7 табл.
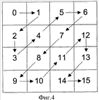
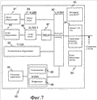
Область техники Изобретение относится к способу, кодеру, декодеру и устройству для кодирования цифрового видеосигнала. Более конкретно изобретение относится к кодированию коэффициентов преобразования, вырабатываемых в результате кодирования на основе поблочного преобразования в кодере/декодере видеосигнала/изображения, при использовании кодирования кодом переменной длины (VLC). Уровень техники Цифровые видеопоследовательности, подобные обычным движущимся изображениям, записанным на пленку, содержат последовательность неподвижных изображений, при этом иллюзия движения создается отображением этих изображений одно за другим с относительно большой скоростью, обычно 15-30 кадров в секунду. Из-за относительно быстрой скорости отображения изображения в следующих друг за другом кадрах имеют тенденцию быть почти подобными, а следовательно, содержат значительный объем избыточной информации. К примеру, типичная сцена может содержать некоторые стационарные элементы, такие как фоновое окружение, и некоторые подвижные области, которые могут принимать множество различных форм, например лицо диктора последних известий, трафик движения и т.д. Альтернативно может перемещаться, например, сама камера, записывающая сцену, и в этом случае все элементы изображения имеют один и тот же вид движения. Во многих случаях это означает, что общее изменение между одним видеокадром и следующим за ним достаточно мало. Каждый кадр несжатой цифровой видеопоследовательности содержит массив пикселов изображения. Например, в обычно используемом цифровом видеоформате, известном как квартетный общий формат обмена (QCIF), кадр содержит массив из 176×144 пикселов, и в этом случае каждый кадр имеет 25344 пиксела. В свою очередь каждый пиксел представляется определенным числом битов, которые несут информацию о яркостной и/или цветовой компоненте области изображения, соответствующей этому пикселу. Обычно для представления компоненты яркости и цветности изображения используется так называемая цветовая модель YUV. Яркостная, или Y, компонента представляет интенсивность (яркость) изображения, тогда как цветовая компонента изображения представляется двумя цветоразностными компонентами, обозначаемыми U и V. Цветовые модели, основанные на яркостном/цветностном представлении содержания, изображения, обеспечивает определенные преимущества по сравнению с цветовыми моделями, которые основаны на представлении, включающем в себя основные цвета (т.е. красный, зеленый и синий, RGB). Зрительная система человека более чувствительна к изменениям интенсивности, чем к цветовым изменениям, и цветовые модели YUV используют это свойство за счет применения более низкого пространственного разрешения для цветоразностных компонент (U, V), чем для яркостной компоненты (Y). Тем самым объем информации, необходимой для кодирования цветовой информации в изображении, можно снизить при приемлемом снижении качества изображения. Более низкое пространственное разрешение цветоразностных компонент обычно достигается путем подквантования. Как правило, каждый кадр видеопоследовательности разделяется на так называемые «макроблоки», которые содержат яркостную (Y) информацию и связанную с ней цветоразностную (U, V) информацию, которая пространственно подквантуется. Фиг.3 иллюстрирует способ, которым могут формироваться макроблоки. Фиг.3 показывает кадр видеопоследовательности, представленный с помощью цветовой модели YUV, причем каждая компонента имеет одно и то же пространственное разрешение. Макроблоки формируются путем представления области 16×16 пикселов в исходном изображении как четыре блока яркостной информации, причем каждый яркостный блок содержит массив 8×8 яркостных (Y) значений и две пространственно соответствующих цветоразностных компоненты (U и V), которые подквантуются с коэффициентом два в направлениях х и y, чтобы получить соответствующие массивы 8×8 цветоразностных (U, V) значений. Согласно некоторым рекомендациям видеокодирования, таким как Рекомендация H.26L Международного союза электросвязи (ITU-T), размер блоков, используемых в макроблоках, может быть иным, нежели 8×8, например, 4×8 или 4×4 (см. объединенную модель (JM) 2.0 рабочего проекта №2, Doc. JVT-B118, Joint Video Team (JVT) of ISO/IEC MPEG и ITU-T VCEG Pattaya, 2nd JVT Meeting, Geneva, CH, Jan. 29 – Feb. 1, 2002, Section 3.2). Изображение QCIF содержит 11×9 макроблоков. Если яркостные блоки и цветоразностные блоки представляются с разрешением 8 битов (т.е. числами в диапазоне от 0 до 255), общее число битов, требуемых на макроблок, равно (16×16×8)+2×(8×8×8)=3072 битов. Число битов, необходимых для представления видеокадра в формате QCIF, составляет, таким образом, 99×3072=304128 битов. Это означает, что объем данных, требуемых для передачи/записи/отображения несжатой видеопоследовательности в формате QCIF, представленной с помощью цветовой модели YUV, при скорости 30 кадров в секунду составляет более чем 9 Мбит/сек (миллионов битов в секунду). Это чрезвычайно высокая скорость передачи данных, не подходящая для использования в приложениях видеозаписи, передачи и отображения вследствие очень больших требуемых емкости хранения, пропускной способности канала и производительности аппаратного обеспечения. Если видеоданные подлежат передаче в реальном времени по сети с фиксированными линиями, такой как цифровая сеть с предоставлением комплексных услуг (ISDN) или традиционная телефонная сеть общего пользования (PSTN), доступная полоса частот для передачи данных составляет обычно около 64 кбит/сек. В мобильной видеотелефонии, где передача имеет место по меньшей мере частично по линии радиосвязи, доступная полоса частот может снижаться до 20 кбит/сек. Это означает, что должно достигаться значительное снижение в объеме информации, используемой для представления видеоданных, чтобы обеспечить передачу цифровой видеопоследовательности по сетям связи с малой шириной полосы. По этой причине разработаны методы видеосжатия, которые снижают объем передаваемой информации при сохранении приемлемого качества изображения. Способы видеосжатия базируются на снижении избыточных и бесполезных для восприятия частей в видеопоследовательностях. Избыточность в видеопоследовательностях может подразделяться на пространственную, временную и спектральную избыточность. «Пространственная избыточность» представляет собой выражение, используемое для описания взаимосвязи (подобия) между соседними пикселами в кадре. Выражение «временная избыточность» выражает тот факт, что объекты, появляющиеся в одном кадре последовательности, вероятно, появятся в последующих кадрах, тогда как «спектральная избыточность» относится к корреляции между различными цветовыми компонентами одного и того же изображения. Достаточно эффективное сжатие нельзя обычно получить в заданной последовательности изображений простым снижением разных видов избыточности. Таким образом, большинство нынешних видеокодеров также снижают качество тех частей видеопоследовательности, которые практически наименее важны. Вдобавок избыточность сжатого видеобитового потока сама по себе снижается посредством эффективного кодирования без потерь. В общем случае это достигается с помощью метода, известного как энтропийное кодирование. Часто имеется значительная величина пространственной избыточности между пикселами, которые составляют каждый кадр цифровой видеопоследовательности. Иными словами, значение любого пиксела в кадре последовательности практически то же самое, что и значение других пикселов в его непосредственной близости. Как правило, системы видеокодирования снижают пространственную избыточность с помощью метода, известного как «кодирование с поблочным преобразованием», в котором математическое преобразование, такое как двумерное дискретное косинусное преобразование (ДКП), применяется к блокам пикселов изображения. Оно преобразует данные изображения из представления, содержащего значения пикселов, к виду, содержащему набор значений коэффициентов, представляющих компоненты пространственных частот, значительно снижая пространственную избыточность и тем самым вырабатывая более компактное представление данных изображения. Кадры видеопоследовательности, которые сжимаются с помощью кодирования с поблочным преобразованием без ссылки на какой-либо иной кадр в этой последовательности, обозначаются как ВНУТРИ-кодированные, или I-кадры. В дополнение к этому и если возможно, блоки ВНУТРИ-кодированных кадров предсказываются из ранее кодированных блоков внутри того же самого кадра. Этот метод, известный как ВНУТРИ-предсказание, приводит к дополнительному сокращению объема данных, требуемых для представления ВНУТРИ-кодированного кадра. В общем случае системы видеокодирования не только снижают пространственную избыточность в отдельных кадрах видеопоследовательности, но также используют метод, известный как «предсказание с компенсацией движения», чтобы снизить временную избыточность в последовательности. С помощью предсказания с компенсацией движения содержание изображения некоторых (часто многих) кадров в цифровой видеопоследовательности «предсказывается» из одного или более других кадров в последовательности, известных как «опорные» кадры. Предсказание содержания изображения достигается путем отслеживания движения объектов или областей изображения между кадром, подлежащим кодированию (сжатию), и опорным(и) кадром(ами) с помощью «векторов движения». В общем случае опорный(ые) кадр(ы) могут предшествовать кадру, подлежащему кодированию, или следовать за ним в видеопоследовательности. Как и в случае ВНУТРИ-кодирования, предсказание с компенсацией движения в видеокадре обычно выполняется на основе макроблоков. Кадры видеопоследовательности, которые сжимаются с помощью предсказания с компенсацией движения, называются в общем случае МЕЖ-кодированными или Р-кадрами. Одно лишь предсказание с компенсацией движения редко обеспечивает достаточно точное представление содержания изображения видеокадра и потому, как правило, необходимо предусмотреть так называемый кадр «ошибки предсказания» (РЕ) с каждым МЕЖ-кодированным кадром. Кадр ошибки предсказания представляет разность между декодированной версией МЕЖ-кодированного кадра и содержанием изображения кадра, подлежащего кодированию. Более конкретно кадр ошибки предсказания содержит значения, которые представляют разность между значениями пикселов в кадре, подлежащем кодированию, и соответствующими реконструированными значениями пикселов, сформированными на основе предсказанной версии рассматриваемого кадра. Следовательно, кадр ошибки предсказания имеет характеристики, аналогичные неподвижному изображению, и для снижения его пространственной избыточности, а значит, и объема данных (числа битов), требуемых для его представления, может применяться кодирование с поблочным преобразованием. Работа системы видеокодирования более подробно описана ниже со ссылками на фиг. 1 и 2. На фиг. 1 показана условная схема базового видеокодера, который использует комбинацию ВНУТРИ- и МЕЖ-кодирования для формирования сжатого (кодированного) потока видеобитов. Соответствующий декодер показан на фиг. 2 и описан ниже. Видеокодер 100 содержит вход 101 для приема цифрового видеосигнала от камеры или другого видеоисточника (не показано). Он также содержит блок 104 преобразования, который предназначен для выполнения поблочного дискретного косинусного преобразования (ДКП), квантователь 106, обратный квантователь 108, блок 110 обратного преобразования, предназначенный для выполнения обратного поблочного дискретного косинусного преобразования (ОДКП), объединители 112 и 116 и кадровую память 120. Кодер также содержит блок 130 оценки движения, кодер 140 поля движения и предсказатель 150 скомпенсированного движения. Переключатели 102 и 114 управляются совместно блоком 160 управления для переключения кодера между режимом ВНУТРИ-видеокодирования и режимом МЕЖ-видеокодирования. Кодер 100 содержит также видеомультиплексирующий кодер 170, который формирует единый битовый поток из различных типов информации, выработанной кодером 100, для дальнейшей передачи к удаленному приемному терминалу или, например, для сохранения на носителе данных большой емкости, таком как жесткий диск компьютера (не показан). Кодер 100 работает следующим образом. Каждый кадр несжатого видеосигнала, подаваемый из источника видеосигнала на вход 101, принимается и обрабатывается макроблок за макроблоком, предпочтительно в порядке растрового сканирования. Когда начинается кодирование новой видеопоследовательности, первый подлежащий кодированию кадр кодируется как ВНУТРИ-кодированный кадр. Вслед за этим кодер программируется для кодирования каждого кадра в МЕЖ-кодированном формате, если только не будет удовлетворено одно из следующих условий: 1) принимается решение, что текущий макроблок кодируемого кадра настолько отличается от значений пикселов в опорном кадре, использованном для его предсказания, что вырабатывается информация чрезмерной ошибки предсказания, и в этом случае текущий макроблок кодируется в формате ВНУТРИ-кодирования; 2) истекает заранее заданный интервал повторения ВНУТРИ-кодированных кадров; или 3) принимается обратная связь от принимающего терминала, указывающая на запрос кадра, подлежащего представлению во ВНУТРИ-кодированном формате. Появление условия 1) обнаруживается путем контроля выхода объединителя 116. Объединитель 116 формирует разность между текущим макроблоком кодируемого кадра и его предсказанием, выработанным в блоке 150 предсказания скомпенсированного движения. Если мера этой разности (к примеру, сумма абсолютных разностей значений пикселов) превосходит заранее заданный порог, объединитель 116 информирует об этом блоки 160 управления по управляющей линии 119 и блок 160 управления воздействует на переключатели 102 и 114 по управляющей линии 113, чтобы переключить кодер 100 в режим ВНУТРИ-кодирования. При этом кадр, который в противном случае кодируется в формате МЕЖ-кодирования, может содержать ВНУТРИ-кодированные макроблоки. Появление условия 2) контролируется посредством таймера или счетчика кадров, реализованного в блоке 160 управления, так что если таймер заканчивает счет либо счетчик кадров достигает заранее заданного числа кадров, блок 160 управления воздействует на переключатели 102 и 114 по управляющей линии 113, чтобы переключить кодер в режим ВНУТРИ-кодирования. Условие 3) запускается, если блок 160 управления принимает, например, от принимающего терминала по управляющей линии 121 сигнал обратной связи, указывающий, что принимающим терминалом затребовано ВНУТРИ-кадровое обновление. Такое условие может возникнуть, к примеру, если предыдущий переданный кадр сильно искажен помехами в процессе его передачи, что делает невозможным его декодирование в приемнике. В этой ситуации принимающий декодер выдает запрос на следующий кадр, подлежащий кодированию в ВНУТРИ-кодированном формате, тем самым вновь запуская кодирующую последовательность. Ниже описана работа кодера 100 в режиме ВНУТРИ-кодирования. В режиме ВНУТРИ-кодирования блок 160 управления воздействует на переключатель 102 для приема входного видеосигнала из входной линии 118. Входной видеосигнал принимается макроблок за макроблоком от входа 101 по входной линии 118. По мере их приема эти блоки яркостных и цветоразностных значений, которые составляют макроблок, проходят к блоку 104 преобразования ДКП, который выполняет двумерное дискретное косинусное преобразование над каждым блоком значений, вырабатывая двумерный массив коэффициентов ДКП для каждого блока. Блок 104 преобразования ДКП вырабатывает массив значений коэффициентов для каждого блока, причем число значений коэффициентов зависит от свойств блоков, которые составляют макроблок. К примеру, если основной размер блока, используемого в макроблоке, составляет 4×4, блок 104 преобразования ДКП вырабатывает массив 4×4 коэффициентов ДКП для каждого блока. Если размер блока составляет 8×8, вырабатывается массив коэффициентов ДКП 8×8. Коэффициенты ДКП для каждого блока подаются на квантователь 106, где они квантуются с использованием параметра квантования ПК. Выбор параметра ПК квантования управляется блоком 160 управления по управляющей линии 115. Квантование вносит потерю информации, т.к. коэффициенты квантования имеют более низкую численную точность, чем коэффициенты, первоначально сформированные блоком 104 преобразования ДКП. Это обеспечивает дополнительный механизм, посредством которого можно снизить объем данных, требуемых для представления каждого изображения в видеопоследовательности. Однако в отличие от преобразования ДКП которое по существу не вносит потерь, потеря информации, вносимая квантованием, вызывает необратимое ухудшение качества изображения. Чем больше степень квантования, примененного к коэффициентам ДКП, тем больше потери качества изображения. Квантованные коэффициенты ДКП для каждого блока с квантователя 106 подаются на видеомультиплексирующий кодер 170, как указано линией 125 на фиг. 1. Видеомультиплексирующий кодер 170 упорядочивает квантованные коэффициенты преобразования для каждого блока с помощью процедуры зигзагообразного сканирования. Эта операция преобразует двумерный массив квантованных коэффициентов преобразования в одномерный массив. Обычные порядки зигзагообразного сканирования, такие как для массива 4×4, показанного на фиг. 4, упорядочивают коэффициенты примерно в возрастающем порядке пространственных частот. Это также имеет тенденцию к упорядочению коэффициентов согласно их значениям, так что коэффициенты, расположенные раньше в одномерном массиве, с большей вероятностью имеют большие абсолютные значения, чем коэффициенты, расположенные позже в массиве. Это имеет место потому, что более низкие пространственные частоты имеют тенденцию к более высоким амплитудам в блоках изображений. Следовательно, последние значения в одномерном массиве квантованных коэффициентов преобразования обычно равны нулям. Как правило, видеомультиплексирующий кодер 170 представляет каждый ненулевой квантованный коэффициент в одномерном массиве двумя значениями, именуемыми «уровень» и «пробег». «Уровень» представляет собой величину квантованного коэффициента, а «пробег» представляет собой число следующих друг за другом нулевых коэффициентов, предшествующих рассматриваемому коэффициенту. Значения уровня и пробега для данного коэффициента упорядочиваются так, что значение уровня предшествует связанному с ним значению пробега. Значение уровня, равное нулю, используется для указания того, что в блоке больше нет ненулевых значений коэффициентов. Это значение 0-уровня именуется символом (ЕОВ) (Конец-Блока). Альтернативно каждый квантованный коэффициент с ненулевым значением в одномерном массиве может быть представлен тремя значениями (пробег, уровень, последний). Значения «уровня» и «пробега» такие же, как в предыдущей схеме, тогда как «последний» обозначает, имеются ли какие-либо другие коэффициенты с ненулевыми величинами в одномерном массиве, следующими за текущим коэффициентом. Следовательно, нет необходимости в отдельном символе EOB. Значения пробега и уровня (и последнего, если приемлемо) затем сжимаются с помощью энтропийного кодирования. Энтропийное кодирование представляет собой операцию без потерь, которая использует тот факт, что символы в подлежащем кодированию наборе данных в общем случае имеют различные вероятности появления. Поэтому вместо использования фиксированного числа битов для представления каждого символа назначается переменное число битов так, что символы, которые более вероятны для появления, представляются кодовыми словами с меньшим числом битов. По этой причине энтропийное кодирование часто называется кодированием переменной длины (VLC). Поскольку некоторые значения уровней и пробегов более вероятны, чем прочие значения, методы энтропийного кодирования могут эффективно использоваться для снижения числа битов, требуемых для представления значений пробега и уровня. После того как значения пробега и уровня энтропийно закодированы, видеомультиплексирующий кодер 170 далее объединяет их с управляющей информацией, также энтропийно кодированной с помощью способа кодирования переменной длины, подходящего для вида рассматриваемой информации, чтобы сформировать сжатый поток битов закодированной информации 135 изображения. Этот поток битов, включающий в себя кодовые слова переменной длины, представляющие пары (пробег, уровень), передается из кодера. Хотя энтропийное кодирование описано в связи с операциями, выполняемыми видеомультиплексирующим кодером 170, следует отметить, что в альтернативных реализациях может предусматриваться отдельный блок энтропийного кодирования. В кодере 100 формируется также локально декодированная версия макроблока. Это делается путем пропускания квантованных коэффициентов преобразования для каждого блока, выданных квантователем 106, через обратный квантователь 108 и применения обратного преобразования ДКП в блоке 110 обратного преобразования. Таким образом, реконструированный массив значений пикселов формируется для каждого блока в макроблоке. Результирующие декодированные данные изображения вводятся в объединитель 112. В режиме ВНУТРИ-кодирования переключатель 114 устанавливается так, что ввод данных на объединитель 112 через переключатель 114 равен нулю. При этом операция, выполняемая объединителем 112, эквивалентна пропусканию декодированных данных изображения неизменными. После того как последующие макроблоки текущего кадра приняты и подвергнуты ранее описанным шагам кодирования и локального декодирования в блоках 104, 106, 108, 110 и 112, декодированная версия ВНУТРИ-кодированного кадра встраивается в кадровую память 120. Когда последний макроблок текущего кадра ВНУТРИ-кодирован и вслед за этим декодирован, кадровая память 120 содержит полностью декодированный кадр, доступный для использования в качестве опорного кадра предсказания при кодировании принятого следующим видеокадра во ВНУТРИ-кодированном формате. Ниже описана работа кодера 100 в режиме МЕЖ-кодирования. В режиме МЕЖ-кодирования блок 160 управления воздействует на переключатель 102 для приема его входных данных из линии 117, которые содержат выходные данные объединителя 116. Когда объединитель 116 принимает блоки яркостных и цветоразностных значений, которые составляют макроблок, он формирует соответствующие блоки информации ошибки предсказания. Информация ошибки предсказания представляет разность между рассматриваемым блоком и его предсказанием, выработанным блоком 150 предсказания скомпенсированного движения. Более конкретно информация ошибки предсказания для каждого блока в макроблоке содержит двумерный массив значений, каждое из которых представляет разность между значением пиксела в блоке кодируемой яркостной и цветоразностной информации и декодированным значением пиксела, полученным путем формирования предсказания скомпенсированного движения для блока согласно процедуре, описанной ниже. Таким образом, в ситуации, когда каждый макроблок содержит, например, набор блоков 4×4, содержащих яркостные и цветоразностные значения, информация ошибки предсказания для каждого блока в макроблоке аналогичным образом содержит массив 4×4 значений ошибки предсказания. Информация ошибки предсказания для каждого блока в макроблоке поступает в блок 104 преобразования ДКП, который выполняет двумерное дискретное косинусное преобразование над каждым блоком значений ошибки предсказания, чтобы выработать двумерный массив коэффициентов преобразования ДКП для каждого блока. Блок 104 преобразования ДКП вырабатывает массив значений коэффициентов для каждого блока ошибки предсказания, причем число значений коэффициентов зависит от свойств блоков, которые составляют макроблок. К примеру, если основной размер блока, используемый в макроблоке, составляет 4×4, блок 104 преобразования ДКП вырабатывает массив 4×4 коэффициентов ДКП для каждого блока ошибки предсказания. Если размер блока равен 8×8, то вырабатывается массив 8×8 коэффициентов ДКП. Коэффициенты преобразования для каждого блока ошибки предсказания поступают в квантователь 106, где они квантуются с помощью параметра квантования ПК аналогично тому, как описано в связи с работой кодера в режиме ВНУТРИ-кодирования. Выбор параметра квантования ПК вновь управляется блоком 160 управления по управляющей линии 115. Квантованные коэффициенты ДКП, представляющие информацию ошибки предсказания для каждого блока в макроблоке, поступают из квантователя 106 на видеомультиплексирующий кодер 170, как указано линией 125 на фиг. 1. Как и в режиме ВНУТРИ-кодирования, видеомультиплексирующий кодер 170 упорядочивает коэффициенты преобразования для каждого блока ошибки предсказания с помощью ранее описанной процедуры зигзагообразного сканирования (см. фиг. 4), а затем представляет каждый квантованный коэффициент как значение уровня и пробега. Он также сжимает значения уровня и пробега с помощью энтропийного кодирования аналогично тому, как это описано выше в связи с режимом ВНУТРИ-кодирования. Видео мультиплексирующий кодер 170 также принимает информацию вектора движения (описанную ниже) из блока 140 кодирования поля движения по линии 126 и управляющую информацию из блока 160 управления. Он энтропийно кодирует информацию вектора движения и информацию управления и формирует единый поток 135 битов кодированной информации изображения, содержащий энтропийно кодированную информацию вектора движения, ошибки предсказания и управления. Квантованные коэффициенты ДКП, представляющие информацию ошибки предсказания для каждого блока в макроблоке, поступают также из квантователя 106 на обратный квантователь 108. Здесь они обратно квантуются и результирующие блоки обратно квантованных коэффициентов ДКП подаются на блок 110 обратного преобразования ДКП, где они подвергаются обратному преобразованию ДКП, чтобы выработать локально декодированные блоки значений ошибки предсказания. Локально декодированные блоки значений ошибки предсказания вводятся затем в объединитель 112. В режиме МЕЖ-кодирования переключатель 114 устанавливается так, что объединитель 112 также принимает предсказанные значения пикселов для каждого блока в макроблоке, выработанные блоком 150 предсказания скомпенсированного движения. Объединитель 112 объединяет каждый из локально декодированных блоков значений ошибки предсказания с соответствующим блоком предсказанных значений пикселов для формирования блоков реконструированного изображения и сохраняет их в кадровой памяти 120. Последующие макроблоки видеосигнала принимаются от источника видеосигнала и подвергаются ранее описанным шагам кодирования и декодирования в блоках 104, 106, 108, 110, 112, а декодированная версия кадра встраивается в кадровую память 120. Когда последний макроблок кадра обработан, кадровая память 120 содержит полностью декодированный кадр, доступный для использования в качестве опорного кадра предсказания при кодировании принимаемого затем видеокадра в МЕЖ-кодированном формате. Ниже описано формирование предсказания для макроблока текущего кадра. Любой кадр, закодированный в МЕЖ-кодированном формате, требует опорного кадра для предсказания с компенсацией движения. Это с неизбежностью означает, что при кодировании видеопоследовательности первый подлежащий кодированию кадр, будь то первый кадр в последовательности или какой-то иной кадр, должен кодироваться во ВНУТРИ-кодированном формате. Это, в свою очередь, означает, что когда видеокодер 100 переключается блоком 160 управления в режим МЕЖ-кодирования, полный опорный кадр, сформированный локальным декодированием ранее кодированного кадра, уже доступен в кадровой памяти 120 кодера. В общем случае опорный кадр формируется локальным декодированием либо ВНУТРИ-кодированного кадра, либо МЕЖ-кодированного кадра. Первый шаг при формировании предсказания для макроблока текущего кадра выполняется блоком 130 оценивания движения. Блок 130 оценивания движения принимает блоки яркостных и цветоразностных значений, которые составляют текущий макроблок подлежащего кодированию кадра, по линии 128. Он затем выполняет операцию согласования блоков, чтобы идентифицировать область в опорном кадре, которая в основном соответствует текущему макроблоку. Для того чтобы выполнить операцию согласования блоков, блок оценивания движения обращается к данным опорного кадра, хранящимся в кадровой памяти 120, по линии 127. Более конкретно блок 130 оценивания движения выполняет согласование блоков путем вычисления разностных значений (к примеру, сумм абсолютных разностей), представляющих разность значений пикселов между рассматриваемым макроблоком и кандидатами наиболее совпадающих областей пикселов из опорного кадра, хранящегося в кадровой памяти 120. Разностное значение вырабатывается для областей-кандидатов при всех возможных сдвигах в пределах заранее определенной области опорного кадра, и блок 130 оценивания движения находит наименьшее вычисленное разностное значение. Сдвиг между макроблоком в текущем кадре и блоком-кандидатом из значений пикселов в опорном кадре, который задает наименьшее разностное значение, определяет вектор движения для рассматриваемого макроблока. Когда блок 130 оценивания движения выработал вектор движения для макроблока, он выдает этот вектор движения в блок 140 кодирования поля движения. Блок 140 кодирования поля движения аппроксимирует вектор движения, принятый из блока 130 оценивания движения, с помощью модели движения, содержащей набор базисных функций и коэффициентов движения. Конкретнее блок 140 кодирования поля движения представляет вектор движения как набор значений коэффициентов движения, который при умножении на базисные функции формирует аппроксимацию вектора движения. Как правило, используется модель смещения, имеющая только два коэффициента движения и две базисных функции, но могут также использоваться модели движения большей сложности. Коэффициенты движения проходят из блока 140 кодирования поля движения в блок 150 предсказания скомпенсированного движения. Блок 150 предсказания скомпенсированного движения также принимает из кадровой памяти 120 наиболее совпадающую область-кандидат значений пикселов, идентифицированную блоком 130 оценивания движения. С помощью аппроксимированного представления вектора движения, выработанного блоком 140 кодирования поля движения, и значений пикселов наиболее совпадающей области-кандидата из опорного кадра блок 150 предсказания скомпенсированного движения вырабатывает массив предсказанных значений пикселов для каждого блока в макроблоке. Каждый блок предсказанных значений пикселов поступает на объединитель 116, где предсказанные значения пикселов вычитаются из действующих (входных) значений пикселов в соответствующем блоке текущего макроблока. Таким образом, получается набор блоков ошибок предсказания для макроблока. Ниже описана работа видеодекодера 200, показанного на фиг. 2. Декодер 200 содержит видеомультиплексирующий декодер 270, принимающий кодированный битовой поток 135 видеоданных от кодера 100 и демультиплексирующий его на составные части, обратный квантователь 210, обратный преобразователь 220 ДКП, блок 240 предсказания скомпенсированного движения, кадровую память 250, объединитель 230, блок 260 управления и выход 280. Блок 260 управления управляет работой декодера 200 в ответ на то, декодируется ли ВНУТРИ- или МЕЖ-кодированный кадр. Управляющий сигнал запуска ВНУТРИ-/МЕЖ-режима, обеспечивающий переключение декодера между режимами декодирования, извлекается, например, из информации типа изображения, связанной с каждым сжатым видеокадром, принятым от кодера. Управляющий сигнал запуска ВНУТРИ-/МЕЖ-режим выделяется из закодированного битового потока видеоданных посредством видеомультиплексирующего декодера 270 и поступает по управляющей линии 215 в блок 260 управления. Декодирование ВНУТРИ-кодированного кадра выполняется макроблок за макроблоком, причем каждый макроблок декодируется, по существу как только относящаяся к нему информация принимается в битовом потоке 135 видеоданных. Видеомультиплексирующий декодер 270 отделяет кодированную информацию для блоков в макроблоке от возможной управляющей информации, относящейся к рассматриваемому макроблоку. Кодированная информация для каждого блока во ВНУТРИ-кодированном макроблоке содержит кодовые слова переменной длины, представляющие энтропийно закодированные значения уровня и пробега для ненулевых квантованных коэффициентов ДКП в блоке. Видеомультиплексирующий декодер 270 декодирует кодовые слова переменной длины с помощью способа декодирования переменной длины, соответствующего способу кодирования, используемому в кодере 100, и благодаря этому восстанавливает значения уровня и пробега. Он затем восстанавливает массив значений квантованных коэффициентов преобразования для каждого блока в макроблоке и пропускает их на обратный квантователь 210. Любая управляющая информация, относящаяся к макроблоку, также декодируется в видеомультиплексирующем декодере с помощью подходящего способа декодирования и пропускается на блок 260 управления. В частности, информация, относящаяся к уровню квантования, применяемому к коэффициентам преобразования, выделяется из кодированного битового потока видеоданных мультиплексирующим декодером 270 и подается в блок 260 управления по управляющей линии 217. Блок управления, в свою очередь, пропускает эту информацию на обратный квантователь 210 по управляющей линии 218. Обратный квантователь 210 обратно квантует квантованные коэффициенты ДКП для каждого блока в макроблоке согласно управляющей информации и подает новые обратно квантованные коэффициенты ДКП на обратный преобразователь 220 ДКП. Обратный преобразователь 220 ДКП выполняет обратное преобразование ДКП над обратно квантованными коэффициентами ДКП для каждого блока в макроблоке, чтобы сформировать декодированный блок информации изображения, содержащей восстановленные значения пикселов. Восстановленные значения пикселов для каждого блока в макроблоке поступают через объединитель 230 на видеовыход 280 декодера, где, к примеру, они могут подаваться на отображающее устройство (не показано). Восстановленные значения пикселов для каждого блока в макроблоке также сохраняются в кадровой памяти 250. Поскольку предсказание с компенсацией движения не используется при кодировании/декодировании ВНУТРИ-кодированных макроблоков, блок 260 управления управляет объединителем 230 для пропускания каждого блока значений пикселов как такового на видеовыход 280 и кадровую память 250. Когда декодируются и сохраняются последующие макроблоки ВНУТРИ-кодированного кадра, декодированный кадр постепенно выстраивается в кадровой памяти 250 и тем самым становится доступным для использования в качестве опорного кадра для предсказания с компенсацией движения в связи с декодированием последующих принимаемых МЕЖ-кодированных кадров. МЕЖ-кодированные кадры декодируются макроблок за макроблоком, причем каждый МЕЖ-кодированный макроблок декодируется по существу, как только относящаяся к нему информация принимается в битовом потоке 135 видеоданных. Видеомультиплексирующий декодер 270 отделяет кодированную информацию ошибки предсказания для каждого блока в МЕЖ-кодированном макроблоке от кодированной информации вектора движения и возможной управляющей информации, относящейся к рассматриваемому макроблоку. Как пояснялось выше, кодированная информация ошибки предсказания для каждого блока в макроблоке содержит кодовые слова переменной длины, представляющие энтропийно кодированные значения уровня и пробега для ненулевых квантованных коэффициентов преобразования рассматриваемого блока ошибки предсказания. Видеомультиплексирующий декодер 270 декодирует кодовые слова переменной длины с помощью способа декодирования переменной длины, соответствующего способу кодирования, используемому в кодере 100, и благодаря этому восстанавливает значения уровня и пробега. Он затем восстанавливает массив значений квантованных коэффициентов преобразования для каждого блока ошибки предсказания и пропускает их на обратный квантователь 210. Управляющая информация, относящаяся к МЕЖ-кодированному макроблоку, также декодируется в видеомультиплексирующем декодере с помощью подходящего способа декодирования и подается на блок 260 управления. Информация, относящаяся к уровню квантования, применяемому к коэффициентам преобразования, выделяется из кодированного потока битов видео мультиплексирующим декодером 270 и подается в блок 260 управления по управляющей линии 217. Блок управления, в свою очередь, подает эту информацию на обратный квантователь 210 по управляющей линии 218. Обратный квантователь 210 обратно квантует квантованные коэффициенты ДКП, представляющие информацию ошибки предсказания для каждого блока в макроблоке согласно управляющей информации и подает новые обратно квантованные коэффициенты ДКП на обратный преобразователь 220 ДКП. Обратно квантованные коэффициенты ДКП, представляющие информацию ошибки предсказания для каждого блока, затем обратно преобразуются в обратном преобразователе 220, чтобы получить массив восстановленных значений ошибки предсказания для каждого блока в макроблоке. Кодированная информация вектора движения, связанная с макроблоком, выделяется из кодированного битового потока 135 видеоданных посредством видео мультиплексирующего декодера 270 и декодируется. Полученная таким образом декодированная информация вектора движения подается по управляющей линии 225 на блок 240 предсказания скомпенсированного движения, который восстанавливает вектор движения для макроблока с помощью той же самой модели движения, которая использовалась для кодирования МЕЖ-кодированного макроблока в кодере 100. Восстановленный вектор движения аппроксимирует вектор движения, первоначально найденный блоком 130 оценивания движения в кодере. Блок 240 предсказания скомпенсированного движения в декодере использует восстановленный вектор движения, чтобы идентифицировать местоположение области восстановленных пикселов в опорном кадре предсказания, хранящемся в кадровой памяти 250. Этот опорный кадр может быть, например, ранее декодированным МЕЖ-кодированным кадром или ранее декодированным ВНУТРИ-кодированным кадром. В любом случае область пикселов, указанная восстановленным вектором движения, используется для формирования предсказания для рассматриваемого блока. Более конкретно блок 240 предсказания скомпенсированного движения формирует массив значений пикселов для каждого блока в макроблоке путем копирования соответствующих значений пикселов из области пикселов, идентифицированной в опорном кадре. Предсказание, т.е. блоки значений пикселов, выделенных из опорного кадра, поступают из блока 240 предсказания скомпенсированного движения в объединитель 230, где они объединяются с декодированной информацией ошибки предсказания. На практике значения пикселов каждого предсказанного блока добавляются к соответствующим восстановленным значениям ошибки предсказания, выводимым обратным преобразователем 220 ДКП. Таким образом получается массив восстановленных значений пикселов для каждого блока в макроблоке. Восстановленные значения пикселов поступают на видеовыход 280 декодера, а также сохраняются в кадровой памяти 250. Когда декодируются и сохраняются последующие макроблоки МЕЖ-кодированного кадра, декодированный кадр постепенно формируется в кадровой памяти 250 и тем самым становится доступным для использования в качестве опорного кадра для предсказания с компенсацией движения других МЕЖ-кодированных кадров. Ниже более подробно описано энтропийное кодирование значений уровня и пробега, связанных с квантованными коэффициентами преобразования с помощью метода кодирования переменной длины (КПД). Как правило, пара пробег-уровень кодируется как единый символ. Это достигается путем определения соответствия между каждой возможной парой пробег-уровень и определенными кодовыми числами. Пример отображения пар пробег-уровень в кодовые числа в виде таблицы перекодировки иллюстрируется в Таблице 3. С помощью этих отображений в таблице перекодировки кодовое число назначается каждой паре (пробег, уровень) блока, и результирующие кодовые числа кодируются посредством кодирования VLC. Например, в объединенной модели (JM) 2.0 рабочего проекта № 2, Doc. JVT-B118, Joint Video Team (JVT) of ISO/IEC MPEG и ITU-T VCEG Pattaya, 2nd JVT Meeting, Geneva, CH, Jan. 29 – Feb. 1, 2002, (стандарт видео кодирования Н.26L) определяются две разных таблицы перекодировки, которые отображают пары (пробег, уровень) на кодовые числа. Выбор того, какую таблицу надлежит использовать, основывается на значении ПК и режиме кодирования блока. Более конкретно, если режим кодирования является ВНУТРИ-режимом и ПК меньше, чем 24, используется другая таблица, чем в противоположном случае. Объединенная модель JM 2.0 of JVT H.26L использует так называемую «универсальную» схему кодирования переменной длины, упоминаемую как UVLC. Соответственно видеокодер, реализованный согласно H. 26L JM 2.0, использует единый набор кодовых слов переменной длины для энтропийного кодирования всех информационных (синтаксических) элементов, подлежащих передаче в потоке битов от кодера. Хотя используемые кодовые слова одни и те же, заранее заданное число различных отображений символов данных в кодовые слова определяются для кодирования различных типов информации. Например, два отображения символов данных в кодовые слова предусматриваются для блоков, содержащих яркостную информацию, причем выбор отображения зависит от типа операции зигзагообразного сканирования (простое или двойное сканирование), используемой для упорядочения квантованных коэффициентов преобразования ДКП. Подробности схем простого и двойного зигзагообразного сканирования согласно H.26L см. рабочий проект № 2, Doc. JVT-B118, Joint Video Team (JVT) of ISO/IEC MPEG и ITU-T VCEG Pattaya, 2nd JVT Meeting, Geneva, CH, Jan. 29 – Feb. 1, 2002. Различные отображения, среди прочих, также предусматриваются для информации типа макроблока (тип_МБ) (MB_type) информации режима ВНУТРИ-предсказания (см. ниже таблицу 3). Кодовые слова UVLC, определенные в H.26L JM 2.0, могут записываться в следующем сжатом виде, показанном ниже в Таблице 1, где выражение xn может принимать либо значение 0, либо 1. Таблица 1: Схема для генерирования кодовых слов UVLC согласно H.26L JM 2.0
Таблица 2 представляет первые 16 кодовых слов, вырабатываемых согласно схеме, представленной в Таблице 1, тогда как Таблица 3 показывает некоторые из различных отображений символов данных в кодовые слова, предусмотренных согласно Н.26L. Полное описание этих отображений содержится в рабочем проекте № 2, Doc. JVT-B118, Joint Video Team (JVT) of ISO/IEC MPEG и ITU-T VCEG Pattaya, 2nd JVT Meeting, Geneva, CH, Jan. 29 – Feb. 1, 2002. Таблица 2
Принятая в Н.26L универсальная схема кодирования переменной длины обеспечивает несколько технических преимуществ. В частности, использование единого набора кодовых слов VLC, который может составляться согласно простому правилу, такому как представлено в Таблице 1, позволяет создавать кодовые слова бит за битом. Это устраняет необходимость в хранении таблицы кодовых слов в кодере и декодере и тем самым снижает требования к памяти как кодера, так и декодера. Следует, разумеется, отметить, что в альтернативных реализациях таблицы кодовых слов могут вырабатываться и сохраняться в кодере и декодере. Различные отображения символов данных в кодовые слова обеспечивают по меньшей мере ограниченную адаптацию схемы кодирования UVLC к различным статистическим свойствам разных типов связанных с изображением данным и управляющей информации, которые кодируются энтропийно. Различные отображения символов данных в кодовые слова могут сохраняться в кодере и декодере, и тем самым нет необходимости передавать информацию отображения в потоке битов от кодера к декодеру. Это помогает поддерживать стойкость к ошибкам. Схема энтропийного кодирования UVLC, однако, имеет некоторые недостатки. В частности, фиксированные кодовые слова и ограниченная степень адаптивности, обеспечиваемая различными отображениями символов данных в кодовые слова, неминуемо приводят к менее чем оптимальному сжатию данных. Это имеет место из-за того, что при кодировании изображений частота появления (т.е. вероятность) различных коэффициентов преобразования, а следовательно, вероятность различных пар (пробег, уровень) изменяется в зависимости от содержания изображения и типа кодируемого изображения. Таким образом, если используется единый набор кодовых слов переменной длины и только одно отображение символов данных, подлежащих кодированию/декодированию и предусматривается VLC, то в общем случае эффективность оптимального кодирования не может быть достигнута. По этой причине предложены модификации основной схемы кодирования UVLC. Более конкретно, предложено включить более одного набора кодовых слов VLC. Одно такое предложение сделано Gisle Bjontegaard в Q.15/SG16 “Use of Adaptive Switching Between Two VLCs for INTRA Luma Coefficients” [«Использование адаптивного переключения между двумя VLC для ВНУТРИ-кодированных яркостных коэффициентов»], Doc. Q15-K-30, август 2000. Это предложение предлагало использовать второй набор кодовых слов VLC для энтропийного кодирования некоторых типов информации. Согласно документу Q15-К-30 предложенный второй набор кодовых слов VLC, называемый VLC2, составляется согласно схеме, показанной в Таблице 4. Он используется, в частности, для кодирования значений пробега и уровня, связанных с квантованными коэффициентами преобразования ВНУТРИ-кодированных яркостных блоков 4×4 пиксела, сканируемых с помощью схемы двойного сканирования зигзагом, определенной согласно Н.26L. Таблица 5 показывает в явной форме первые 16 кодовых слов VLC2.
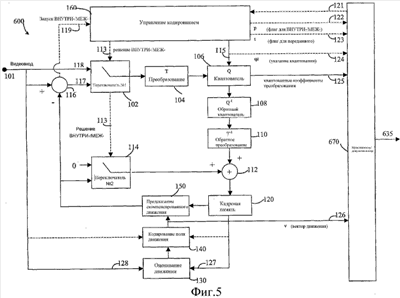
Как можно видеть при сравнении Таблиц 4 и 5 с Таблицами 1 и 2 соответственно, самое короткое кодовое слово VLC2 имеет два бита в противоположность одному биту, назначенному для самого короткого кодового слова в исходном наборе кодовых слов UVLC. В связи с общим требованием возможности декодирования, что никакое кодовое слово VLC не может быть префиксом никакого другого, это изменение имеет значительное влияние на структуру других кодовых слов VLC2. В частности, назначение двух битов для самого короткого кодового слова обеспечивает представление кодовых слов, имеющих более высокие индексы, меньшим числом битов. Например, из Таблицы 2 можно видеть, что кодовое слово UVLC с индексом 7 имеет 7 битов, тогда как кодовое слово VLC2 с индексом 7 имеет только 6 битов. Обнаружено также, что имеется сильная взаимосвязь между числом ненулевых коэффициентов в блоке и возможными в этом же самом блоке парами (пробег, уровень). Отметим, что число ненулевых коэффициентов в блоке связано с размером блока преобразования, например 16 для преобразования 4×4. Аналогично значение пробега ограничено размером блока преобразования, например, 15 для преобразования 4×4. Когда число ненулевых коэффициентов велико, скажем, близко к общему размеру массива, обнаружено, что пары (пробег, уровень) с малой величиной пробега и высокой величиной уровня имеют более высокую вероятность. К примеру, для преобразования 4×4 с 15 ненулевыми коэффициентами пробег может принимать лишь значения в диапазоне [0, 1]. На основании этих наблюдений в работе Karczewicz, “VLC Coefficients Coding for High Bit-Rate” [Коэффициенты кодирования VLC для высокой битовой скорости»], Doc. JVT-B072, 2nd JVT Meeting, Geneva, CH, Jan. 29 – Feb. 1, 2002, предложен способ кодирования переменной длины, в котором предусмотрена отдельная таблица перекодировки, соответствующая различным числам ненулевых квантованных коэффициентов преобразования. Согласно этому предложению для каждой из этих таблиц назначаются кодовые слова и отображения между парами (пробег, уровень) и кодовыми словами, чтобы обеспечить оптимальное сжатие данных, когда оно применяется к набору пар (пробег, уровень), выделенных из массива значений квантованных коэффициентов преобразования, имеющего конкретное число ненулевых коэффициентов. Информация об изменении статистических свойств пар (пробег, уровень) по отношению к числу ненулевых квантованных коэффициентов преобразования получается эмпирически, например, путем кодирования заранее нескольких тестовых («тренировочных») изображений или видеопоследовательностей. Кодовые слова КПД и отображения между этими кодовыми словами могут затем назначаться и сохраняться в кодере как одна или более таблиц перекодировки. Особенности алгоритма, предложенного Karczewicz, заключаются в следующем. После того как блок пикселов изображения или значений ошибки предсказания закодирован с преобразованием в виде двумерного массива значений коэффициентов преобразования и каждое из значений коэффициентов проквантовано, определяют число значений квантованных коэффициентов массива. Этому числу назначается значение, называемое Nc, которое используется для сигнализации в явном виде о числе значений ненулевых коэффициентов в массиве. Таким образом, символ EOB (к примеру, значение уровня, равное нулю) более не требуется. Затем каждая пара (пробег, уровень) в рассматриваемом блоке отображается на кодовые слова с помощью таблицы перекодировки, которая определяет отображения между парами (пробег, уровень) и кодовыми словами, причем эта таблица перекодировки выбирается в зависимости от значения Nc. Оба ранее описанных способа кодирования VLC, в которых кодовые слова выбираются посредством основанного на контексте переключения между более чем одним набором кодовых слов, обеспечивают улучшение в эффективности сжатия данных по сравнению со способами, в которых используется единственный набор кодовых слов VLC. Однако во многих применениях сжатия данных и особенно в применениях, относящихся к видеокодированию, имеется постоянная потребность в улучшении эффективности сжатия данных. Таким образом, налицо значительный интерес к разработке новых способов кодирования переменной длины, которые обеспечивают улучшенную возможность приспособления к типу и статистическим свойствам подлежащих кодированию символов данных при поддержании низкой вычислительной сложности, низких требований к памяти и хорошей стойкости к ошибкам. Именно в этом контексте и разработан способ согласно настоящему изобретению. Сущность изобретения Изобретение относится в целом к кодированию переменной длины символов данных, представленных парами (пробег, уровень). Оно включает в себя использование по меньшей мере двух отображений между символами данных и кодовыми словами VLC и определяет правила переключения между этими отображениями, которые учитывают статистические свойства символов данных, подлежащих кодированию переменной длины. Таким образом, получается улучшенная эффективность сжатия данных по сравнению со способами кодирования VLC, которые используют фиксированные отображения между символами данных и кодовыми словами. Эти правила переключения разработаны так, чтобы поток битов, содержащий кодовые слова VLC, сформированные способом согласно изобретению, могли декодироваться не требуя какой-либо информации, относящейся к выбору отображения и подлежащей включению в поток битов. Иными словами, нет необходимости обеспечивать точное указание отображения, использованного для генерирования каждого кодового слова в потоке битов. Это свойство усиливает эффективность сжатия данных. В частности, настоящее изобретение предлагает новые способы для кодирования квантованных коэффициентов преобразования, чтобы улучшить эффективность кодирования. Более конкретно, особой задачей изобретения является обеспечение новых и более эффективных схем для кодирования пар (пробег, уровень), представляющих ненулевые квантованные коэффициенты преобразования. Подобно способу, предложенному в документе Karczewicz, “VLC Coefficients Coding for High Bit-Rate” [Коэффициенты кодирования КПД для высокой битовой скорости»], Doc. JVT-B072, 2nd JVT Meeting, Geneva, CH, Jan. 29 – Feb. 1, 2002, настоящее изобретение основано на наблюдении того, что число ненулевых коэффициентов в блоке коэффициентов преобразования, а также значение пробега связаны с размером блока преобразования. Это наблюдение и дальнейший анализ кодеров, работающих с изображениями реального мира, привел изобретателей настоящего изобретения к обнаружению корреляции между числом ненулевых коэффициентов в блоке и значениями пробега в рассматриваемом блоке. В частности, было обнаружено, что по мере того, как из блока кодируется все больше и больше пар (пробег, уровень), возможное число комбинаций пробег-уровень начинает уменьшаться. Именно обнаружение последнего факта привело к настоящему изобретению. Таким образом, способ кодирования VLC согласно изобретению учитывает тот факт, что по мере того как следующие друг за другом пары (пробег, уровень) назначаются кодовым словам, возможный диапазон, связанный со следующей подлежащей кодированию парой (пробег, уровень), становится все более ограниченным. Тот факт, что возможные значения для пробега меняются при каждом кодировании пары (пробег, уровень), может преимущественно использоваться во время назначения индекса пар (пробег, уровень) кодовым числам. Более конкретно, согласно варианту выполнения изобретения, по меньшей мере два набора отображений предусматриваются для связывания пар (пробег, уровень) с кодовыми числами. Каждая пара (пробег, уровень) сначала отображается на кодовое число с помощью таблицы отображений, выбранной из одного из по меньшей мере двух наборов отображений, реагирующих на значение макс_пробег, которое определяет максимальное значение пробега, которое может быть принято. Макс_пробег инициализируется с учетом числа ненулевых коэффициентов в блоке и обновляется после кодирования каждой пары (пробег, уровень). Нижеследующий пример иллюстрирует этот пункт. Предположим, что блок квантованных коэффициентов преобразования имеет 5 ненулевых коэффициентов с парами (пробег, уровень) (2, 1), (3, 2), (4, 3), (2, 3) и (1, 2). Следует отметить, что обычно значения пробега и уровня для данного коэффициента упорядочиваются так, что значение уровня предшествуют связанному с ним значению пробега. Следовательно, в парах (пробег, уровень), представленных выше, значениями уровня являются первые числа в каждой паре (2, 3, 4, 2, 1), а значения пробега являются последними числами каждой пары (1, 2, 3, 3, 2). В начале процесса кодирования, поскольку имеется 5 ненулевых коэффициентов, а может быть самое большее 16 таких коэффициентов, пробег может принимать значение максимум 11. Отмечая это максимально возможное значение пробега как макс_пробег, можно видеть, что после кодирования первой пары, т.е. (2, 1), макс_пробег уменьшится, он станет в точности равен 10, что находится обновлением предыдущего значения макс_пробег путем вычитания текущего значения пробега. В частности, макс_пробег обновляется по уравнению: макс_пробег=макс_пробег-пробег, где макс_пробег инициализируется посредством 16-Nc в начале кодирования этого блока. Согласно первому аспекту изобретения предлагается способ кодирования набора символов данных, содержащего нулевые символы данных и ненулевые символы данных, содержащий назначение кодового слова для представления ненулевого символа данных и связанного с ним числа предшествующих или последующих нулевых символов данных посредством операции отображения. Согласно этому способу операция отображения, посредством которой кодовое слово назначается ненулевому символу данных и связанному с ним числу предшествующих или последующих символов данных, зависит от максимально возможного числа нулевых символов данных в наборе символов данных. Согласно второму аспекту изобретения предлагается способ декодирования набора кодовых слов, представляющих набор символов данных, причем набор символов данных содержит нулевые символы данных и ненулевые символы данных, содержащий прием указания числа ненулевых символов данных в упомянутом наборе символов данных, прием кодового слова, представляющего ненулевой символ данных и связанное с ним число предшествующих или последующих нулевых символов данных и декодирование этого кодового слова, чтобы восстановить ненулевой символ данных и связанное с ним число предшествующих или последующих нулевых символов данных, путем выполнения операции обратного отображения. Согласно этому способу операция обратного отображения, посредством которой ненулевой символ данных и связанное с ним число предшествующих и последующих нулевых символов данных декодируются из упомянутого кодового слова, зависит от максимально возможного числа нулевых символов данных в упомянутом наборе символов данных. Согласно третьему аспекту изобретения предлагается кодер для кодирования набора символов данных, содержащего нулевые символы данных и ненулевые символы данных, содержащий средство для назначения кодового слова для представления ненулевого символа данных и связанного с ним числа предшествующих или последующих нулевых символов данных путем выполнения операции отображения. Согласно изобретению предусмотренное в кодере средство для назначения кодового слова выполнено с возможностью адаптировать операцию отображения, посредством которой назначается кодовое слово, в зависимости от максимально возможного числа нулевых символов данных в упомянутом наборе символов данных. Согласно четвертому аспекту изобретения, предлагается декодер для декодирования набора кодовых слов, представляющих набор символов данных, причем упомянутый набор символов данных содержит нулевые символы данных и ненулевые символы данных, содержащий средство для приема указания числа ненулевых символов данных в упомянутом наборе символов данных, средство для приема кодового слова, представляющего ненулевой символ данных и связанное с ним число предшествующих или последующих нулевых символов данных, и средство для декодирования кодового слова, чтобы восстановить ненулевой символ данных и связанное с ним число предшествующих или последующих нулевых символов данных, путем выполнения операции обратного отображения. Согласно изобретению средство для декодирования кодового слова выполнено с возможностью адаптировать операцию обратного отображения, посредством которой декодируются ненулевой символ данных и связанное с ним число предшествующих и последующих нулевых символов данных, в зависимости от максимально возможного числа нулевых символов в упомянутом наборе символов данных. Согласно пятому аспекту изобретения предлагается мультимедийный терминал, содержащий кодер по третьему аспекту изобретения. Согласно шестому аспекту изобретения предлагается мультимедийный терминал, содержащий декодер по четвертому аспекту изобретения. Предпочтительно мультимедийный терминал по пятому и/или шестому аспектам изобретения представляет собой мобильный мультимедийный терминал, выполненный с возможностью осуществлять связь с сетью мобильной связи посредством радиосоединения. Краткое описание чертежей Ниже описаны варианты выполнения изобретения посредством примера со ссылкой на сопровождающие чертежи, на которых: Фиг.1 – блок-схема базового видеокодера согласно уровню техники; Фиг.2 – блок-схема базового видеодекодера согласно уровню техники и соответствующего кодеру, показанному на фиг. 1; Фиг.3 – иллюстрация формирования макроблока согласно уровню техники; Фиг.4 – иллюстрация примерного порядка зигзагообразного сканирования; Фиг.5 – блок-схема видеокодера согласно варианту выполнения изобретения; Фиг. 6 – блок-схема видеодекодера согласно варианту выполнения изобретения и соответствующего кодеру, показанному на фиг. 5; и Фиг. 7 – блок-схема мультимедийного терминала связи, в котором может быть реализован способ согласно изобретению. Подробное описание изобретения В нижеследующем подробном описании представлены примерные варианты выполнения изобретения. Они относятся к кодированию переменной длины пар (пробег, уровень), представляющих ненулевые коэффициенты преобразования, полученные в результате поблочного кодирования преобразования в видеокодере, а также их последующему декодированию в соответствующем видеодекодере. Однако специалистам должно быть понятно, что способ согласно изобретению можно применять в общем к кодированию КПД символов данных, которые представлены как пары (пробег, уровень), или к любому эквивалентному представлению подлежащего кодированию набора символов данных. На Фиг. 5 представлена блок-схема видео кодера 600, в котором может быть применен способ кодирования КПД согласно изобретению. Структура видеокодера, показанного на фиг. 5, практически идентична структуре существующего видеокодера, показанного на фиг. 1, с соответствующими модификациями тех частей кодера, которые выполняют операции кодирования переменной длины. Все части видеокодера, которые воплощают функции и могут работать аналогично тому, как это делается в ранее описанном существующем видеокодере, обозначены теми же самыми ссылочными позициями. В этом описании предполагается, что все операции кодирования переменной длины выполняются в видеомультиплексирующем кодере 670. Однако понятно, что в альтернативных вариантах выполнения изобретения могут быть предусмотрены отдельные блок или блоки кодирования переменной длины. Следует также отметить, что способ по изобретению может применяться к определенным символам данных, вырабатываемых видеокодером (например, пары (пробег, уровень), связанные с ненулевыми коэффициентами преобразования), а для кодирования других символов данных можно использовать иные способы кодирования VLC. Ниже подробно описана работа видеокодера 600. При кодировании кадра цифрового видеосигнала кодер 600 работает аналогично ранее описанному в связи с фиг. 1, чтобы генерировать ВНУТРИ-кодированные и МЕЖ-кодированные сжатые видеокадры. Как описано выше, в режиме ВНУТРИ-кодирования к каждому блоку данных изображения (значений пикселов) применяется дискретное косинусное преобразование (ДКП), чтобы получить соответствующий двумерный массив значений коэффициентов преобразования. Операция ДКП выполняется в блоке 104 преобразования, и полученные таким образом коэффициенты поступают в квантователь 106, где они квантуются. В режиме ВНУТРИ-кодирования преобразование ДКП, выполненное в блоке 104, применяется к блокам значений ошибки предсказания. Коэффициенты преобразования, полученные в результате этой операции, также поступают в квантователь 106, где они также квантуются. Следует отметить, что МЕЖ-кодированные кадры могут содержать ВНУТРИ-кодированные блоки изображения, и далее что в некоторых ситуациях кодирование преобразования не применяется к конкретным блокам изображения. К примеру, если в режиме ВНУТРИ-кодирования используется ВНУТРИ-предсказание, некоторые блоки изображения предсказываются в кодере из одного или более ранее кодированных блоков изображения. В этом случае кодер снабжает декодер указанием предыдущих блоков, подлежащих использованию в предсказании, и не выдает данных коэффициентов преобразования. Далее, в режиме МЕЖ-кодирования разность между предсказанием для некоторого блока и данными изображения самого этого блока может быть настолько малой, что предпочтительно в терминах отношения сжатия данных не передавать никакой информации ошибки предсказания. Соответственно способ кодирования КПД согласно изобретению применяется к тем блокам изображения, которые подвергаются кодированию преобразования и последующему квантованию коэффициентов преобразования. Согласно изобретению, когда видеомультиплексирующий кодер 670 принимает блок (двумерный массив) квантованных коэффициентов преобразования, он находит число Nc ненулевых коэффициентов в массиве, и указание этого числа передается на декодер в потоке 635 битов. В предпочтительном варианте выполнения изобретения число Nc кодируется кодом переменной длины перед передачей. В альтернативных вариантах выполнения оно может передаваться как таковое либо можно использовать иной способ кодирования. Видеомультиплексирующий кодер 670 затем представляет ненулевые коэффициенты как пары (пробег, уровень). Более конкретно, двумерный массив квантованных коэффициентов преобразования сначала сканируется с использованием заранее определенного порядка сканирования, такого как показанный на фиг. 4, чтобы получить упорядоченный одномерный массив. Каждое значение ненулевого коэффициента в упорядоченном одномерном массиве представляется затем значением пробега и значением уровня, где значение уровня представляет значение коэффициента, а значение пробега представляет число следующих друг за другом нулевых коэффициентов, предшествующих этому ненулевому коэффициенту. Видеомультиплексирующий кодер 670 затем применяет кодирование переменной длины к значениям пробега и уровня так, что каждой паре (пробег, уровень) назначается единственное кодовое слово VLC. Согласно предпочтительному варианту выполнения изобретения пары (пробег, уровень) кодируются путем выбора отличающегося отображения пар (пробег, уровень) в кодовые числа с учетом максимально возможного пробега (обозначенного макс_пробег) перед кодированием символа. При кодировании первой пары (пробег, уровень) в блоке квантованных коэффициентов преобразования макс_пробег устанавливается равным максимально возможному числу ненулевых коэффициентов, которые могут быть представлены в блоке, минус ранее найденное значение Nc. Таким образом, для блока 4×4 макс_пробег инициализируется как:
Нижеследующий примерный псевдокод представляет процедуру для назначения кодового слова паре (пробег, уровень) согласно изобретению:
где ПУ_индекс отображает целочисленные части значений пробег-уровень на различные кодовые числа в зависимости от значения макс_пробег. Он инициализируется после выполнения моделирования с использованием тестового материала. Наконец Индекс_ПУ кодируется одним из кодовых слов VLC, перечисленных в Таблице 2 или Таблице 5. Более конкретно, функция отображения ПУ_индекс формируется эмпирически из одной или более тестовых последовательностей видеоданных путем анализа вероятности появления различных пар (пробег, уровень) для каждого возможного значения макс_пробег. Кодовые числа (т.е. значения Индекс_ПУ), выработанные применением процедуры отображения, используются затем для выбора кодовых слов, представляющих пары (пробег, уровень), из таблицы кодовых слов. Предпочтительные варианты выполнения изобретения используют либо таблицу, показанную выше в Таблице 2, либо ту, что показана в Таблице 5. Таблицы 6 и 7 представляют примерные отображения пар (пробег, уровень) для кодирования чисел согласно значению макс_пробег. В обеих таблицах строки соответствуют значениям уровня, а столбцы соответствуют значениям пробега, тогда как записи в каждой ячейке указывают кодовое число кодового слова VLC для этой конкретной пары пробег-уровень (т.е. комбинации значений пробег и уровень). Наиболее вероятной паре назначается кодовое число 1, второй наиболее вероятной паре – кодовое число 2, и т.д. И Таблица 6, и Таблица 7 перечисляют 15 наиболее вероятных пар. Таблица 6 иллюстрирует случай, когда макс_пробег равен 8, тогда как Таблица 7 показывает ситуацию, когда макс_пробег равен 3.
Таблица 7
Выбрав с помощью описанной выше процедуры отображения кодовое слово VLC для представления конкретной пары (пробег, уровень), видеомультиплексирующий кодер 670 передает это кодовое слово в декодер в потоке 635 битов. Если имеется больше пар (пробег, уровень), подлежащих кодированию для текущего блока, он затем обновляет макс_пробег для использования в связи с кодированием следующей пары (пробег, уровень) путем вычитания текущего значения пробега, т.е. макс_пробег=макс_пробег-пробег. Процедура кодирования продолжается до тех пор, пока все пары (пробег, уровень) для данного блока не будут представлены как кодовые слова, после чего видеомультиплексирующий кодер 670 принимает следующий блок квантованных коэффициентов преобразования для кодирования и повторяет этот процесс кодирования для следующего блока. Ниже описана работа видеодекодера 700 согласно изобретению со ссылкой на фиг. 6. Структура видеодекодера, проиллюстрированная на фиг. 6, практически идентична структуре существующего видеодекодера, показанного на фиг. 2, с соответствующими модификациями тех частей декодера, которые выполняют операции декодирования переменной длины. Все части видеодекодера, которые реализуют функции и могут работать аналогично тому, как это делается в ранее описанном существующем видеодекодере, обозначены теми же самыми ссылочными позициями. В этом описании предполагается, что все операции декодирования переменной длины выполняются в видеомультиплексирующем декодере 770. Однако ясно, что в альтернативных вариантах выполнения изобретения могут быть предусмотрены отдельные блок или блоки декодирования переменной длины. Ниже подробно описана работа видеодекодера. Предполагается, что видеодекодер по фиг. 6 соответствует кодеру, описанному в связи с фиг. 5, и поэтому может принимать и декодировать поток 635 битов, переданный кодером 600. В декодере поток битов принимается и разделяется на свои составные части видеомультиплексирующим декодером 770. Как пояснялось в связи с приведенным ранее описанием существующего уровня техники, сжатые видеоданные, выделенные из потока битов, обрабатываются макроблок за макроблоком. Согласно изобретению сжатые видеоданные для ВНУТРИ-кодированного макроблока содержат кодовые слова переменной длины, представляющие кодированные КПД пары (пробег, уровень) для каждого блока в макроблоке, вместе с указанием числа Nc ненулевых квантованных коэффициентов преобразования, представленных в каждом блоке, и кодированную управляющую информацию (например, относящуюся к параметру ПК квантования). Сжатые видеоданные для МЕЖ-кодированного макроблока содержат кодированную КПД информацию ошибки предсказания для каждого блока (содержащую кодированные пары (пробег, уровень) и указание числа Nc для каждого блока), информацию вектора движения и кодированную управляющую информацию. Значение Nc и кодированные КПД пары (пробег, уровень) для каждого блока во ВНУТРИ-кодированном макроблоке и для каждого блока данных ошибки предсказания, связанных с МЕЖ-кодированным макроблоком, обрабатываются одинаковым образом. Более конкретно, при декодировании кодированных КПД пар (пробег, уровень) для ВНУТРИ- и МЕЖ-кодированного блока изображения видеомультиплексирующий декодер 770 сначала находит число ненулевых квантованных коэффициентов преобразования в блоке. Как описано выше, информация, относящаяся к числу Nc ненулевых квантованных коэффициентов преобразования, вводится в поток 635 битов кодером 600. Видеомультиплексирующий декодер 770 декодера 700 выделяет эту информацию из принятого потока битов. Затем видеомультиплексирующий декодер 770 начинает декодировать кодированные КПД пары (пробег, уровень) для блока изображения. Согласно изобретению операция декодирования выполняется аналогично процедуре кодирования, выполняемой в кодере, и описана выше. Конкретнее при декодировании первого кодового слова переменной длины, связанного с конкретным блоком изображения, видеомультиплексирующий декодер 770 инициализирует значение макс_пробег путем установки его равным максимальному числу ненулевых коэффициентов, которые могут присутствовать в блоке, минус значение Nc, относящееся к рассматриваемому блоку, которое выделено из принятого потока битов. Он затем определяет кодовое число, соответствующее принятому кодовому слову, и в зависимости от значения макс_пробег выбирает таблицу отображения, относящуюся к кодовому числу для конкретной комбинации значений пробега и уровня, причем таблица отображения, используемая в декодере, соответствует такой же таблице, использованной для генерирования кодовых слов в кодере. Восстановив значения пробега и уровня, соответствующие первому ненулевому квантованному коэффициенту преобразования этого блока, видеомультиплексирующий декодер 770 обновляет значение макс_пробег путем вычитания только что найденного значения пробега и начинает декодирование следующего кодового слова для этого блока. Этот процесс продолжается до тех пор, пока все кодовые слова, представляющие конкретный блок изображения, не будут декодированы, после чего видеомультиплексирующий декодер 770 восстанавливает значения квантованных коэффициентов преобразования для блока из декодированных пар (пробег, уровень) и подает их на обратный квантователь 210. Остальные шаги процедуры видеодекодирования, посредством которых восстановленные значения пикселов формируются для каждого блока изображения, происходят, как описано в связи с существующим видеодекодером 200. Фиг. 7 представляет терминальное устройство, содержащее видеокодирующее и декодирующее оборудование, которое может быть адаптировано для работы в соответствии с настоящим изобретением. Точнее, этот чертеж иллюстрирует мультимедийный терминал 80, реализованный согласно рекомендациям Н.324 ITU-T. Этот терминал может рассматриваться как мультимедийное приемопередающее устройство. Он включает в себя элементы, которые получают, кодируют и мультиплексируют потоки данных для передачи по сети связи, а также элементы, которые принимают, демультиплексируют, декодируют и отображают принятое мультимедийное содержание. Рекомендации Н.324 ITU-T определяют всю работу терминала и ссылаются на другие рекомендации, которые управляют работой его разных составных частей. Этот вид мультимедийного терминала можно использовать в приложениях реального времени, таких как разговорная видеотелефония, или в приложениях не в реальном времени, таких как извлечение и/или формирование потоков видеоклипов, к примеру, из сервера мультимедийного содержания в интернете. В контексте настоящего изобретения понятно, что терминал Н.324, показанный на фиг. 7, является лишь одним из ряда альтернативных реализаций мультимедийного терминала, пригодных для применения способа, соответствующего изобретению. Следует отметить, что существует несколько альтернатив местоположения и реализации терминального оборудования. Как иллюстрируется на фиг. 7, мультимедийный терминал может располагаться в оборудовании связи, соединенном с телефонной сетью на фиксированных линиях, такой как аналоговая телефонная сеть общего пользования (PCTN). В этом случае мультимедийный терминал оснащен модемом 91, совместимым с рекомендациями V.8, V.34 и, дополнительно, V.8bis ITU-T. Альтернативно мультимедийный терминал может соединяться с внешним модемом. Модем обеспечивает преобразование мультиплексированных цифровых данных и управляющих сигналов, вырабатываемых мультимедийным терминалом, в аналоговую форму, пригодную для передачи по сети PSTN. Он далее позволяет мультимедийному терминалу принимать данные и управляющие сигналы в аналоговом виде из сети PSTN и преобразовывать их в поток цифровых данных, который можно демультиплексировать и обрабатывать подходящим образом с помощью терминала. Мультимедийный терминал Н.324 может быть также реализован таким образом, что он может подключаться непосредственно к цифровой сети с фиксированными линиями, такой как цифровая сеть с предоставлением комплексных услуг (ISDN). В этом случае модем 91 заменяется интерфейсом пользователь-сеть ISDN. На фиг. 7 этот интерфейс пользователь-сеть ISDN представлен альтернативным блоком 92. Мультимедийный терминал Н.324 может быть также адаптирован для использования в приложениях мобильной связи. При использовании с беспроводной линией связи модем 91 можно заменить любым подходящим беспроводным интерфейсом, как представлено альтернативным блоком 93 на фиг.7. К примеру, мультимедийный терминал Н.324/М может включать в себя радиоприемопередатчик, обеспечивающий подключение к нынешней мобильной телефонной сети GSM второго поколения или к предлагаемой сети UMTS (Универсальная мобильная телефонная система) третьего поколения. Следует отметить, что в мультимедийных терминалах, разработанных для двунаправленной связи, т.е. для передачи и приема видеоданных, предпочтительно обеспечивать как видеокодер, так и видеодекодер, реализованные согласно настоящему изобретению. Такая пара кодера и декодера часто реализуется как единый функциональный блок, называемый «кодек». Ниже подробно описан типичный мультимедийный терминал Н.324 со ссылкой на фиг. 7. Мультимедийный терминал 80 включает в себя множество элементов, упоминаемых как «терминальное оборудование». Это оборудование включает в себя видео-, аудио- и телематические устройства, обозначенные в общем ссылочными позициями 81, 82 и 83 соответственно. Видеооборудование 81 может включать в себя, к примеру, видеокамеру для получения видеоизображений, монитор для отображения принятого видеосодержания и дополнительное оборудование видеообработки. Аудиооборудование 82 обыкновенно включает в себя микрофон, например, для получения речевых сообщений, и громкоговоритель для воспроизведения принятого аудиосодержания. Аудиооборудование может также включать в себя дополнительные блоки аудиообработки. Телематическое оборудование 83 может включать в себя терминал данных, клавиатуру, электронную доску или приемопередатчик неподвижных изображений, такой как блок факсимильной связи. Видеооборудование 81 соединяется с видеокодеком 85. Видеокодек 85 содержит видеокодер и соответствующий видеодекодер, реализованные согласно изобретению. Такие кодер и декодер будут описаны ниже. Видеокодек 85 реагирует на кодированные полученные видеоданные в подходящем виде для дальнейшей передачи по линии связи и декодирования сжатого видеосодержания, принятого из сети связи. В примере, показанном на фиг.7, видеокодек реализован согласно рекомендациям Н.26L ITU-T с соответствующими модификациями для реализации способа адаптивного кодирования переменной длины согласно изобретению как в кодере, так и в декодере видеокодека. Терминальное аудиооборудование соединяется с аудиокодеком, обозначенном на фиг. 7 ссылочной позицией 86. Как и в случае видеокодека, аудиокодек содержит пару кодер/декодер. Она преобразует аудиоданные, полученные терминальным аудиооборудованием, в вид, пригодный для передачи по линии связи, и преобразует кодированные аудиоданные, принятые из сети, обратно к виду, пригодному для воспроизведения, например, в терминальном громкоговорителе. Выходной сигнал аудиокодека подается в блок 87 задержки. Он компенсирует задержки, вызванные процессом видеокодирования, и тем самым обеспечивает синхронизацию аудио и видеосодержания. Системный блок 84 управления мультимедийного терминала управляет сигнализацией окончание-сеть с помощью подходящего протокола управления (блок 88 сигнализации), чтобы установить общий режим работы между передающим и принимающим терминалом. Блок 88 сигнализации осуществляет обмен информацией о возможностях кодирования и декодирования передающего и принимающего терминалов и может использоваться для обеспечения различных режимов кодирования видеокодера. Системный блок 84 управления управляет также использованием шифрования данных. Информация, касающаяся типа подлежащего использованию шифрования при передаче данных, подается из блока 89 шифрования в мультиплексор/демультиплексор 90 (блок MUX/DMUX). Во время передачи данных от мультимедийного терминала блок 90 MUX/DMUX объединяет кодированные и синхронизированные видео и аудиопотоки с данными, поступающими от телематического оборудования 83, и возможными управляющими данными, чтобы сформировать единый поток битов. Информация, касающаяся типа шифрования данных (если она имеется), подлежащая применению к потоку битов, предоставляемая блоком 89 шифрования, используется для выбора режима шифрования. Соответственно, когда принимается мультиплексированный и, возможно, зашифрованный мультимедийный поток битов, блок 90 MUX/DMUX обеспечивает дешифрование потока битов, разделяя его на составляющие мультимедийные компоненты и пропуская эти компоненты на соответствующий кодек(и) и/или терминальное оборудование для декодирования и воспроизведения. Следует отметить, что функциональные элементы мультимедийного терминала – видеокодер, декодер и видеокодек согласно изобретению – могут быть реализованы как программное обеспечение или специализированное аппаратное обеспечение, либо комбинация обоих. Способы кодирования и декодирования переменной длины согласно изобретению специально приспособлены для реализации в виде компьютерной программы, содержащей машиночитаемые команды для выполнения функциональных этапов изобретения. Как таковые кодер и декодер переменной длины согласно изобретению могут быть реализованы как программные коды, хранящиеся на носителе данных и выполняемые в компьютере, таком как персональный настольный компьютер. Если мультимедийный терминал 80 является мобильным терминалом, т.е. если он снабжен радиоприемопередатчиком 92, специалисту понятно, что он может содержать дополнительные элементы. В одном варианте выполнения он содержит пользовательский интерфейс, имеющий дисплей и клавиатуру, которые обеспечивают работу мультимедийного терминала 80 для пользователя, центральный блок обработки, такой как микропроцессор, который управляет блоками, реагирующими на различные функции мультимедийного терминала, Оперативное запоминающее устройство ОЗУ (RAM), постоянное запоминающее устройство ПЗУ (ROM) и цифровую камеру. Микропроцессорные рабочие команды, т.е. программные коды, соответствующие основным функциям мультимедийного терминала 80, хранятся в ПЗУ и могут выполняться, как это требуется микропроцессору, например, под управлением пользователя. В соответствии с программным кодом микропроцессор использует радиоприемопередатчик 93 для установления соединения с сетью мобильной связи, позволяя мультимедийному терминалу передавать информацию в сеть мобильной связи и принимать информацию из сети мобильной связи по радиоканалу. Микропроцессор отслеживает состояние пользовательского интерфейса и управляет цифровой камерой. В ответ на команду пользователя микропроцессор выдает команду камере записывать цифровые изображения в ОЗУ. Когда изображение получено или, альтернативно, в процессе его получения, микропроцессор сегментирует это изображение на сегменты изображения (например, макроблоки) и использует кодер для выполнения кодирования со скомпенсированным движением этих сегментов для генерации последовательности сжатых изображений, как пояснено выше. Пользователь может выдать команду мультимедийному терминалу 80 отобразить полученные изображения на дисплее или послать последовательность сжатых изображений с помощью радиоприемопередатчика 93 к другому мультимедийному терминалу, видеотелефону, соединенному с сетью PSTN, или какому-то иному устройству связи. В предпочтительном варианте выполнения передача данных изображения начинается, как только кодируется первый сегмент, так что получатель может начать соответствующий процесс декодирования с минимальной задержкой. Хотя изобретение описано в контексте конкретных вариантов выполнения, специалистам понятно, что возможны модификации и различные изменения описанных вариантов. Так, хотя изобретение в частности показано и описано в отношении одного или более его предпочтительных вариантов выполнения, специалистам понятно, что в нем могут быть сделаны некоторые модификации или изменения без отклонения от объема и сущности изобретения, как оно изложено выше. Альтернативный вариант выполнения изобретения базируется на наблюдении того, что зигзагообразное сканирование коэффициентов имеет тенденцию к упорядочению коэффициентов согласно их значениям, так что коэффициенты, расположенные раньше в одномерном массиве, с большей вероятностью имеют более высокие абсолютные значения, нежели коэффициенты, расположенные позже в этом массиве. Поэтому следующие друг за другом значения уровня проявляют значительное сходство, т.е. в пределах данного блока коэффициентов преобразования уровень подлежащего кодированию коэффициента имеет в общем величину, практически одинаковую с уровнем предыдущего закодированного коэффициента. Этот альтернативный вариант выполнения использует это сходство путем кодирования пар (пробег, уровень) согласно следующему соотношению:
где предыдущ_уровень представляет собой ранее закодированное значение уровня в блоке. По сравнению с ранее описанными вариантами выполнения здесь имеется дополнительный параметр (а именно, предыдущ_уровень), который влияет на назначение индексных значений парам (пробег, уровень). Еще один вариант выполнения изобретения основывается на том факте, что следующие друг за другом значения уровня проявляют сильную взаимосвязь. Более конкретно ранее закодированные значения уровня могут быть использованы для назначения отличающейся кодовой книги VLC, чтобы кодировать текущий символ, в дополнение к используемой в назначении индексов. Нижеследующий примерный псевдокод обеспечивает процедуру для назначения кодовой книги VLC кодовому числу пары (пробег, уровень), найденному за счет использования одного из ранее описанных вариантов выполнения изобретения:
где предыдущ_уровень представляет собой ранее закодированное значение уровня в блоке, а Nc_отображ представляет собой массив, который отображает целочисленные значения на различные доступные коды VLC.
Формула изобретения
1. Способ кодирования набора символов данных, содержащего нулевые символы данных и ненулевые символы данных, отличающийся тем, что назначают кодовое слово для представления пары символов данных, представляющей собой комбинацию ненулевого символа данных и связанного с ним числа предшествующих или последующих нулевых символов данных, путем выполнения операции отображения, причем операцию отображения, посредством которой назначают кодовое слово, адаптируют в зависимости, по меньшей мере частично, от максимально возможного числа нулевых символов данных в упомянутом наборе символов данных, и обновляют максимально возможное число нулевых символов данных в упомянутом наборе символов данных в связи с назначением пары символов данных кодовому слову путем вычитания упомянутого связанного числа предшествующих или последующих нулевых символов данных из упомянутого максимально возможного числа нулевых символов данных, чтобы получить обновленное максимально возможное число нулевых символов данных, при этом операцию отображения, посредством которой следующее кодовое слово назначается паре символов данных, адаптируют в зависимости, по меньшей мере частично, от упомянутого обновленного максимально возможного числа нулевых символов данных. 2. Способ кодирования по п.1, отличающийся тем, что продолжают кодирование до тех пор, пока всем парам символов данных в упомянутом наборе символов данных не будет присвоено кодовое слово. 3. Способ кодирования по п.1 или 2, отличающийся тем, что максимально возможное число из числа нулевых символов данных в упомянутом наборе символов данных определяют путем вычитания числа ненулевых символов данных в упомянутом наборе символов данных из общего числа символов данных в упомянутом наборе. 4. Способ кодирования по п.1 или 2, отличающийся тем, что указание числа ненулевых символов данных в упомянутом наборе символов данных передают к соответствующему декодирующему устройству. 5. Способ кодирования по п.1 или 2, отличающийся тем, что упомянутую операцию отображения выполняют путем выбора конкретной таблицы отображения из набора таблиц отображения в зависимости, по меньшей мере частично, от упомянутого максимально возможного числа нулевых символов данных в упомянутом наборе символов данных, причем каждая таблица отображения из упомянутого набора определяет назначение символов данных кодовым словам. 6. Способ кодирования по п.5, отличающийся тем, что каждая из упомянутых таблиц отображения определяет назначение пар символов данных кодовым словам. 7. Способ кодирования по п.5, отличающийся тем, что каждая из упомянутых таблиц отображения определяет назначение пар символов данных кодовым числам, причем каждое кодовое число представляет кодовое слово в наборе кодовых слов и используется в качестве ссылки в этот набор кодовых слов, определяя при этом назначение пар символов данных кодовым словам. 8. Способ кодирования по п.1 или 2, отличающийся тем, что упомянутый набор символов данных представляет значения коэффициентов преобразования. 9. Способ кодирования по п.1 или 2, отличающийся тем, что значение предыдущего закодированного ненулевого символа данных используют для назначения кодовой книги из набора кодовых книг, содержащих кодовые слова, чтобы кодировать текущий ненулевой символ данных. 10. Способ кодирования по п.1 или 2, отличающийся тем, что его используют в видеокодере. 11. Способ декодирования набора кодовых слов, представляющих набор символов данных, причем упомянутый набор символов данных содержит нулевые символы данных и ненулевые символы данных, отличающийся тем, что принимают кодовое слово, представляющее пару символов данных, которая представляет собой комбинацию ненулевого символа данных и связанного с ним числа предшествующих или последующих нулевых символов данных; декодируют упомянутое кодовое слово, чтобы восстановить упомянутую пару символов данных, путем выполнения операции обратного отображения, при этом операцию обратного отображения, посредством которой декодируется пара символов данных, адаптируют в зависимости, по меньшей мере частично, от максимально возможного числа нулевых символов данных в упомянутом наборе символов данных; и обновляют упомянутое максимально возможное число нулевых символов данных в упомянутом наборе символов данных в связи с декодированием принятого кодового слова для восстановления пары символов данных, представленной упомянутым кодовым словом, путем вычитания упомянутого связанного числа предшествующих или последующих нулевых символов данных из упомянутого максимально возможного числа нулевых символов данных, чтобы получить обновленное максимально возможное число нулевых символов данных, при этом операцию обратного отображения, посредством которой следующее кодовое слово декодируется для восстановления пары символов данных, представленной упомянутым следующим кодовым словом, адаптируют в зависимости, по меньшей мере частично, от упомянутого обновленного максимально возможного числа нулевых символов данных. 12. Способ декодирования по п.11, отличающийся тем, что принимают указание числа ненулевых символов данных в упомянутом наборе символов данных. 13. Способ декодирования по п.11 или 12, отличающийся тем, что максимально возможное число нулевых символов данных в упомянутом наборе символов данных определяют путем вычитания числа ненулевых символов данных в упомянутом наборе символов данных из общего числа символов данных в упомянутом наборе. 14. Способ декодирования по п.12, отличающийся тем, что указание числа ненулевых символов данных в упомянутом наборе символов данных принимают из соответствующего кодирующего устройства. 15. Способ декодирования по п.11 или 12, отличающийся тем, что упомянутую операцию обратного отображения выполняют путем выбора конкретной таблицы обратного отображения из набора таблиц обратного отображения в зависимости, по меньшей мере частично, от упомянутого максимально возможного числа нулевых символов данных в упомянутом наборе символов данных, причем каждая таблица обратного отображения упомянутого набора определяет назначение кодовых слов символам данных. 16. Способ декодирования по п.15, отличающийся тем, что каждая из упомянутых таблиц обратного отображения определяет назначение кодовых слов парам символов данных. 17. Способ декодирования по п.15, отличающийся тем, что упомянутое принятое кодовое слово декодируют для восстановления кодового числа, причем упомянутое кодовое число используют в качестве ссылки в конкретную таблицу обратного отображения, выбранную в зависимости, по меньшей мере частично, от упомянутого максимально возможного числа нулевых символов данных в упомянутом наборе символов данных, при этом восстанавливают пару символов данных, представленную упомянутым кодовым словом. 18. Способ декодирования по п.11 или 12, отличающийся тем, что упомянутый набор символов данных представляет значения коэффициентов преобразования. 19. Способ декодирования по п.11 или 12, отличающийся тем, что значение предыдущего декодированного ненулевого символа данных используют для выбора кодовой книги из набора кодовых книг, содержащих кодовые слова, представляющие ненулевые символы данных, для декодирования текущего кодового слова. 20. Способ декодирования по п.11 или 12, отличающийся тем, что его используют в видеодекодере. 21. Кодер для кодирования набора символов данных, содержащего нулевые символы данных и ненулевые символы данных, отличающийся тем, что содержит: средство для назначения кодового слова для представления пары символов данных, которая представляет собой комбинацию ненулевого символа данных и связанного с ним числа предшествующих или последующих нулевых символов данных, путем выполнения операции отображения, при этом упомянутое средство для назначения кодового слова выполнено с возможностью адаптировать операцию отображения, посредством которой назначается кодовое слово, в зависимости, по меньшей мере частично, от максимально возможного числа нулевых символов данных в упомянутом наборе символов данных; и средство для обновления максимально возможного числа нулевых символов данных в упомянутом наборе символов данных в связи с назначением пары символов данных кодовому слову путем вычитания упомянутого связанного числа предшествующих или последующих нулевых символов данных из упомянутого максимально возможного числа нулевых символов данных, чтобы получить обновленное максимально возможное число нулевых символов данных, причем упомянутое средство для назначения кодового слова для представления пары символов данных выполнено с возможностью адаптировать операцию отображения, посредством которой следующее кодовое слово назначается паре символов данных, в зависимости, по меньшей мере, частично, от упомянутого обновленного максимально возможного числа нулевых символов данных. 22. Кодер по п.21, отличающийся тем, что он выполнен с возможностью продолжения кодирования до тех пор, пока всем парам символов данных в упомянутом наборе символов данных не будет присвоено кодовое слово. 23. Кодер по п.21 или 22, отличающийся тем, что он выполнен с возможностью определения максимально возможного числа из числа нулевых символов данных в упомянутом наборе символов данных путем вычитания числа ненулевых символов данных в упомянутом наборе символов данных из общего числа символов данных в упомянутом наборе. 24. Кодер по п.21 или 22, отличающийся тем, что он выполнен с возможностью передачи указания числа ненулевых символов данных в упомянутом наборе символов данных к соответствующему декодирующему устройству. 25. Кодер по п.21 или 22, отличающийся тем, что упомянутое средство для назначения кодового слова для представления пары символов данных выполнено с возможностью осуществления упомянутой операции отображения путем выбора конкретной таблицы отображения из набора таблиц отображения в зависимости, по меньшей мере частично, от упомянутого максимально возможного числа нулевых символов данных в упомянутом наборе символов данных, причем каждая таблица отображения упомянутого набора определяет назначение символов данных кодовым словам. 26. Кодер по п.25, отличающийся тем, что каждая из упомянутых таблиц отображения определяет назначение пар символов данных кодовым словам. 27. Кодер по п.25, отличающийся тем, что каждая из упомянутых таблиц отображения определяет назначение пар символов данных кодовым числам, причем каждое кодовое число представляет кодовое слово в наборе кодовых слов, при этом упомянутое средство для назначения кодового слова для представления пары символов данных выполнено с возможностью использования упомянутых кодовых чисел в качестве ссылок в набор кодовых слов, при этом определяется назначение пар символов данных кодовым словам. 28. Кодер по п.21 или 22, отличающийся тем, что упомянутый набор символов данных представляет значения коэффициентов преобразования. 29. Кодер по п.21 или 22, отличающийся тем, что значение предыдущего закодированного ненулевого символа данных используется для назначения кодовой книги из набора кодовых книг, содержащих кодовые слова, чтобы кодировать текущий ненулевой символ данных. 30. Видеокодер, содержащий кодер по любому из пп.21-29. 31. Декодер для декодирования набора кодовых слов, представляющих набор символов данных, причем упомянутый набор символов данных содержит нулевые символы данных и ненулевые символы данных, отличающийся тем, что содержит: средство для приема кодового слова, представляющего пару символов данных, представляющую собой комбинацию ненулевого символа данных и связанного с ним числа предшествующих или последующих нулевых символов данных; средство для декодирования принятого кодового слова, чтобы восстановить упомянутую пару символов данных, путем выполнения операции обратного отображения, при этом упомянутое средство для декодирования упомянутого кодового слова выполнено с возможностью адаптировать операцию обратного отображения, посредством которой декодируется пара символов данных, в зависимости, по меньшей мере частично, от максимально возможного числа нулевых символов в упомянутом наборе символов данных; и средство для обновления максимально возможного числа нулевых символов данных в упомянутом наборе символов данных в связи с декодированием принятого кодового слова для восстановления пары символов данных, представленной упомянутым кодовым словом, путем вычитания упомянутого связанного числа предшествующих или последующих нулевых символов данных из упомянутого максимально возможного числа нулевых символов данных, чтобы получить обновленное максимально возможное число нулевых символов данных, причем упомянутое средство для декодирования кодового слова выполнено с возможностью адаптировать операцию обратного отображения, посредством которой следующее кодовое слово декодируется для восстановления пары символов данных, представленной упомянутым следующим кодовым словом, в зависимости, по меньшей мере частично, от упомянутого обновленного максимально возможного числа нулевых символов данных. 32. Декодер по п.31, отличающийся тем, что он выполнен с возможностью приема указания числа ненулевых символов данных в упомянутом наборе символов данных. 33. Декодер по п.31 или 32, отличающийся тем, что он выполнен с возможностью определения максимально возможного числа нулевых символов данных в упомянутом наборе символов данных путем вычитания числа ненулевых символов данных в упомянутом наборе символов данных из общего числа символов данных в упомянутом наборе. 34. Декодер по п.32, отличающийся тем, что он содержит средство для приема упомянутого указания числа ненулевых символов данных в упомянутом наборе символов данных из соответствующего кодирующего устройства. 35. Декодер по п.31 или 32, отличающийся тем, что упомянутое средство для декодирования кодового слова выполнено с возможностью выполнения операции обратного отображения путем выбора конкретной таблицы обратного отображения из набора таблиц обратного отображения в зависимости, по меньшей мере частично, от упомянутого максимально возможного числа нулевых символов данных в упомянутом наборе символов данных, причем каждая таблица обратного отображения упомянутого набора определяет назначение кодовых слов символам данных. 36. Декодер по п.35, отличающийся тем, что каждая из упомянутых таблиц обратного отображения определяет назначение кодовых слов парам символов данных. 37. Декодер по п.35, отличающийся тем, что упомянутое средство для декодирования кодового слова выполнено с возможностью декодирования принятого кодового слова для восстановления кодового числа и для использования упомянутого кодового числа в качестве ссылки в конкретную таблицу обратного отображения, выбранную в зависимости, по меньшей мере частично, от упомянутого максимально возможного числа нулевых символов данных в упомянутом наборе символов данных, при этом восстанавливается пара символов данных, представленная упомянутым кодовым словом. 38. Декодер по п.31 или 32, отличающийся тем, что упомянутый набор символов данных представляет значения коэффициентов преобразования. 39. Декодер по п.31 или 32, отличающийся тем, что упомянутое средство для декодирования кодового слова выполнено с возможностью использования значения предыдущего декодированного ненулевого символа данных для выбора кодовой книги из набора кодовых книг, содержащих кодовые слова, представляющие ненулевые символы данных, для декодирования текущего кодового слова. 40. Видеодекодер, содержащий декодер по любому из пп.31-39. 41. Мультимедийный терминал, содержащий видеокодер по п.30. 42. Мультимедийный терминал, содержащий видеодекодер по п.40. 43. Мультимедийный терминал по п.41, отличающийся тем, что он содержит приемопередающее средство для передачи информации в сеть мобильной связи и приема информации из сети мобильной связи по радиоканалу. 44. Мультимедийный терминал по п.42, отличающийся тем, что он содержит приемопередающее средство для передачи информации в сеть мобильной связи и приема информации из сети мобильной связи по радиоканалу.
РИСУНКИ
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||