Патент на изобретение №2334269
|
||||||||||||||||||||||||||
(54) УСТРОЙСТВО И СПОСОБ ФОРМИРОВАНИЯ СЛОЖНЫХ СЛОВ
(57) Реферат:
Изобретение относится к области систем ввода текста. Предлагается устройство и способ для генерации многозначительных сложных слов. Интерфейс пользователя выполнен с возможностью приема входных данных, соответствующих одному или более сложным словам. Процессор выполнен с возможностью идентификации комбинаций слов из более коротких слов, которые могут быть объединены для формирования части или всего одного слова или более сложных слов. Дисплей выполнен с возможностью отображения комбинаций слов с учетом приоритета на основе одного или более критериев, таких как различие комбинаций слов, имеющих различные количества коротких слов. Технический результат заключается в улучшении систем ввода текста с лучшим прогнозированием слов. 2 н. и 8 з.п. ф-лы, 8 ил.
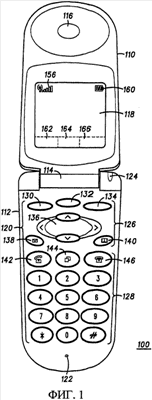
Область техники Настоящее изобретение относится к области систем ввода текста, которые обеспечивают удобные и правильные процессы для ввода символов и слов. А именно, настоящее изобретение относится к системе ввода текста, имеющей интеллектуальные способности для формирования сложных слов, что максимизирует точность ввода текста с предсказанием. Описание предшествующего уровня техники Разработчики портативных электронных устройств должны реализовать интерфейс пользователя, имеющий ограниченное количество клавиш. Таким разработчикам приходится бороться с дизайном интерфейсов пользователя для ввода текстовых данных, таких как латинские символы, фонетические символы, идеограммы и штрихи идеограмм. Портативные электронные устройства, например радиотелефон, как правило, имеют только двенадцать или около того клавиш для ввода чисел от «0» до «9» и символов «*» и «#». Разработка портативного электронного устройства, допускающего ввод пользователем многочисленных символов определенного языка с использованием ограниченного количества клавиш на стандартной клавишной панели, является очень перспективной. Существующие системы ввода текста с предсказанием решают множество проблем, связанных с вводом теста с использованием стандартной клавишной панели. Для ввода текста с предсказанием пользователь нажимает клавишу один раз для каждого символа, и система прогнозирует символ, который был введен пользователем. Ввод текста с предсказанием предпочтителен потому, что он требует в среднем меньше нажатий клавиши для ввода каждого символа. Тем не менее, существующие системы ввода текста с предсказанием не всегда правильно предсказывают задуманный пользователем текст. Таким образом, желательна улучшенная система ввода текста с лучшим прогнозированием символа и слова, особенно сложных слов. Краткое описание чертежей Фиг. 1 – вид в перспективе примерного портативного электронного устройства в соответствии с настоящим изобретением. Фиг. 2 – блок-схема примерных внутренних компонентов портативного электронного устройства по фиг. 1. Фиг. 3 – примерная диаграмма, иллюстрирующая работу процедуры прогнозирующих комбинаций, которая может быть выполнена внутренними компонентами по фиг. 2. Фиг. 4 – диаграмма псевдокода процедуры прогнозирующих комбинаций, которая может быть выполнена внутренними компонентами по фиг. 2. Фиг. 5 – диаграмма псевдокода процедуры перемещения, которая может быть вызвана процедурой прогнозирующих комбинаций по фиг. 4. Фиг. 6 – диаграмма псевдокода процедуры сравнивающих комбинаций, которая может быть выполнена внутренними компонентами по фиг. 2. Фиг. 7 – список слов, представляющий собой сравнение примерных комбинаций слов по фиг. 4. Фиг. 8 – таблица слов, представляющая собой другое сравнение примерных комбинаций слов по фиг. 4. Подробное описание предпочтительных реализаций Настоящее изобретение является интерфейсом пользователя для портативного электронного устройства, который обеспечивает ввод данных для фонетических символов, идеограмм и штрихов идеограмм и, тем самым, применим для любого языка, имеющего буквы, символы и/или слова. Предпочтительные реализации, представленные на чертежах и описанные в этом документе, ориентированы на радиотелефон для беспроводной передачи голосовых сигналов и/или сигналов данных и обеспечивают ввод данных для латинских символов, фонетических символов и идеограмм. Тем не менее, должно быть понятно, что настоящее изобретение может быть использовано в электронных устройствах любого типа, например, но без ограничения, в пейджерах, компьютерах, карманных калькуляторах, персональных цифровых помощниках и тому подобном. На фиг. 1 показано складное портативное электронное устройство 100, имеющее верхнюю секцию 110 и нижнюю секцию 112, подвижно соединенные в секции 114 соединения. Верхняя секция 110 содержит отверстие 116 динамика телефона и дисплей 118, нижняя секция 112 содержит интерфейс 120 пользователя, отверстие 122 микрофона и визуальный индикатор 124. Устройство 100 также содержит другие компоненты радиотелефона (показаны на фиг. 2), как будет описано ниже, например антенну, источник питания, внешние разъемы, дополнительные элементы управления и тому подобное. Интерфейс 120 пользователя в соответствии с настоящим изобретением включает в себя функциональные клавиши 126 и клавишную панель 128. Для устройства 100, показанного на фиг. 1, функциональные клавиши 126 расположены в верхней части нижней секции 112 и включают в себя клавиши 130, 132, 134 выбора меню, клавиши 136 прокрутки (то есть вверх, вниз, влево и вправо), клавишу 138 вызова сообщений, клавишу 140 памяти, клавишу 142 ответа на вызов, клавишу 144 функции очистки и клавишу 146 прекращения вызова. Функциональные клавиши 126 в соответствии с настоящим изобретением не ограничиваются клавишами, приведенными для устройства 100, и могут включать другие запрограммированные или программируемые пользователем управляющие кнопки, такие как клавиши управления громкостью, клавиши записи голоса, элементы управления для настройки устройства и тому подобное. Клавишная панель 128 устройства 100 расположена в нижней части нижней секции и включает в себя 10 цифровых клавиш, а именно клавиши от «1» до «9» и «0», а также клавиши «*» и «#» (всего 12 клавиш). Как показано на фиг. 1, клавишная панель образует матрицу из четырех строк, в которой каждая строка содержит три клавиши, аналогично обыкновенной телефонной клавишной панели. Хотя это не показано на фиг. 1, клавишная панель 128 также может быть использована для ввода символов других типов, таких как латинские символы, фонетические символы, идеограммы и штрихи символов. Например, типичный набор клавиш клавишной панели может ассоциировать символы A, B, C и 2 с клавишей 2; D, E, F и 3 с клавишей 3; G, H, I и 4 с клавишей 4; J, K, L и 5 с клавишей 5; M, N, O и 6 с клавишей 6; P, Q, R, S и 7 с клавишей 7; T, U, V и 8 с клавишей 8 и W, X, Y, Z и 9 с клавишей 9. Таким образом, каждая клавиша может быть использована для ввода цифры или символа в зависимости от режима ввода устройства. Например, режим ввода устройства может быть определен с помощью выбора одной или более функциональных клавиш, например клавиш 130, 132, 134 выбора меню. Дисплей 118 устройства обеспечивает представление информации различных типов пользователю. Несколько индикаторов предусматриваются для общей работы устройства, например индикатор 156 силы сигнала и индикатор 160 мощности устройства 100. Другие индикаторы предусмотрены для работы клавиш 130, 132, 134 выбора меню из числа функциональных клавиш. Например, как показано устройством 100 на фиг. 1, имеются три клавиши 130, 132, 134 выбора меню в верхней части нижней секции 112. Также нижняя область дисплея 118 зарезервирована для от одного до трех индикаторов 162, 164, 166 выбора меню, которые соответствуют одной или более клавишам 130, 132, 134 выбора меню. На фиг. 2 показаны внутренние компоненты 200 портативного электронного устройства 100. Предпочтительная реализация включает в себя антенну 202, приемопередатчик 204, процессор 206, устройства 208, 210 вывода и устройства 212, 214 ввода. При приеме беспроводных сигналов внутренние компоненты 200 детектируют сигналы с помощью антенны 202 для получения детектированных голосовых сигналов и/или сигналов данных. Приемопередатчик 204, связанный с антенной 202, преобразует детектированные сигналы в узкополосные электрические сигналы и демодулирует узкополосные электрические сигналы для восстановления входящей информации, такой как голосовая информация и/или данные, переданной беспроводными сигналами. После приема входящей информации от приемопередатчика 204 процессор 206 форматирует входящую информацию для вывода устройствами 208, 210 вывода. Аналогичным образом, для передачи беспроводных сигналов процессор 206 форматирует исходящую информацию и передает ее приемопередатчику 204 для модуляции несущей и преобразования в модулированные сигналы. Приемопередатчик 204 передает модулированные сигналы антенне 202 для передачи удаленному приемопередатчику (не показан). Устройства ввода и вывода могут включать в себя множество устройств визуального отображения, аудиоустройств и устройств генерации движения. Устройства вывода могут включать в себя, но не ограничиваются нижеперечисленными, устройства 208 визуального отображения (например, жидкокристаллические дисплеи и светодиодные индикаторы), устройства 210 вывода аудио (например, динамики, сигнализаторы и устройства звуковой сигнализации), устройства генерации движения (например, механизмы генерации вибраций). Устройства ввода могут включать в себя, но не ограничиваются нижеперечисленными, механические устройства 212 ввода (например, клавиатуры, клавишные панели, кнопки выбора, сенсорные панели, емкостные датчики, сканеры движения и переключатели) и устройства 214 ввода аудио (например, микрофоны). Например, верхняя и/или нижняя секции 112, 114 устройства 100 могут содержать переключатель, который отвечает за перемещение секций по отношению друг к другу и в результате активирует одну или более функций устройства. Внутренние компоненты 200 портативного устройства 100 дополнительно включают в себя блок 216 памяти для хранения и извлечения данных. Процессор 206 может выполнять различные операции для хранения, манипулирования и извлечения информации в блоке 216 памяти. Например, процессор 206 может искать в памяти 216 ранее сохраненные данные с помощью ввода элементов поиска или символов от пользовательских устройств 212, 214. В процессе поиска процессор 206 сравнивает сохраненные данные с введенными элементами поиска или символами. Если одно или более совпадений найдено, совпавшие данные передаются устройствам 208, 210 вывода или дополнительно обрабатываются процессором 206. Для предпочтительных реализаций блок 216 памяти хранит базу данных или словарь 218 слов или символов, которые рассматриваются как завершенные слова или самостоятельные символы. Кроме того, по меньшей мере, некоторые из слов или символов в базе 218 данных могут объединяться для образования комбинаций слов, которые рассматриваются как завершенные слова или символы. Таким образом, слово или символ могут быть образованы или с помощью их поиска в базе данных 218, или с помощью объединения двух или более символов, то есть два или более коротких слов образуют более длинное слово. Процессор 206 может обращаться к базе 218 данных при прогнозировании слов или символов, которые хочет ввести пользователь, на основе входной информации, полученной интерфейсом 120 пользователя. Внутренние компоненты 200 портативного электронного устройства 100 могут дополнительно включать интерфейс 220 компонента и источник 222 питания. Аксессуары и дополнительные компоненты могут быть связаны с интерфейсом 220 компонента для обеспечения дополнительной функциональности и возможностей для устройства 100. Источник 222 питания, например батарея, обеспечивает питание для внутренних компонент 200 таким образом, что они могут функционировать корректным образом. На фиг. 3 приведена примерная диаграмма 300, иллюстрирующая работу процедуры 400 прогнозирующих комбинаций в соответствии с настоящим изобретением. Примерная древовидная диаграмма включает в себя множество узлов (например, узлов с 302 по 340), соединенных вершинами. Темные узлы, например узлы 308, 314, 322, 328, 336, 340, примерной древовидной диаграммы 300 обозначают окончания завершенных слов. Каждая вершина имеет вероятность или оценку, связанную с ней. Узел 302 в левой части диаграммы 300 обозначает первый узел дерева, и следуя вершинам дерева для продвижения по дереву, идентифицируются спрогнозированные комбинации. Примерная древовидная диаграмма иллюстрирует, как процедура 400 прогнозирующих комбинаций может произвести множество спрогнозированных комбинаций из некоторого набора входной информации в интерфейсе 120 пользователя. Например, как показано на фиг. 3, процедура 400 прогнозирующих комбинаций может сгенерировать следующие спрогнозированные комбинации из единственного набора входной информации: «ask» следует узлам 302, 304, 306 и 308; «aside» следует узлам 302, 304, 306, 310, 312 и 314; «park» следует узлам 302, 316, 318, 320 и 322; «parking» следует узлам 302, 316, 318, 320, 322, 324, 326 и 328; «ball» следует узлам 302, 330, 332, 334 и 336; и «ballet» следует узлам 302, 330, 332, 334, 336, 338 и 340. Примерная древовидная диаграмма, показанная на фиг. 3, представляет пример, в котором пользователь выбирает клавишу «7», за которой следует клавиша «2», как начальную часть входной информации. Как было описано выше, клавиша «7» может соответствовать символам «p», «q», «r», «s» или «7», а клавиша «2» может соответствовать символам «a», «b», «c» или «2». Процедура 400 прогнозирующих комбинаций может, например, идентифицировать шесть комбинаций, показанных на фиг. 3, то есть «ask», «aside», «park», «parking», «ball» и «ballet», на основе полученной входной информации. Следует отметить, что в этом примере только две из этих комбинаций, а именно «park» и «parking», действительно включают в себя символ, соответствующий клавише «7»; оставшиеся комбинации начинаются с символов, соответствующих клавише «2». Как представлено циклом 342, процедура 400 прогнозирующих комбинаций может попытаться идентифицировать комбинации, начинающиеся с первой клавиши, например клавиши «7», и также попытаться идентифицировать комбинации, начинающиеся с последующей клавиши, например клавиши «2». Таким образом, процедура 400 прогнозирующих комбинаций способна рассмотреть и идентифицировать комбинации слов, которые составляют часть входной информации, а также входную информацию во всей ее полноте. На фиг. 4 представлена диаграмма псевдокода процедуры 400 прогнозирующих комбинаций. В частности, детерминизм может быть максимизирован до вычислительной модели, например модели конечных автоматов, показанной на чертеже. Вычислительная модель является функцией, использующей переменные, и функции включают в себя, но не ограничиваются перечисленным, набор состояний, алфавит базы данных, переменную текущего состояния, набор терминальных состояний и функцию перехода. Набор состояний может включать в себя все потенциальные предсказания в форме путей и их соединений, таких как стартовая точка. Алфавит базы данных включает в себя все символы, имеющиеся в определенном языке или типе языков. Переменная текущего состояния включает в себя все новые состояния и все обновленные состояния набора состояний. Набор терминальных состояний является подмножеством набора состояний и включает в себя конечные точки путей. Функция перехода определяет, как процедура 400 прогнозирования переключается между последовательными состояниями, и предпочтительно является функцией набора состояний и алфавита базы данных. Процедура 400 прогнозирования включает в себя функцию безусловного перехода, которая обеспечивает продвижение вперед и условный перезапуск в каждой точке. Таким образом, процедура 400 прогнозирования позволяет создание сложных слов, то есть новые слова базируются на существующих в базе данных словах. Как только новые слова идентифицированы, они рассматриваются наряду с существующими словами для последующего анализа. Как показано на фиг. 4, процедура 400 прогнозирования инициирует поиск комбинации слов в строке 402, в которой словарная информация и заданный ввод используются процедурой. Как было описано выше, словарная информация может быть сохранена в базе 218 данных, и входная информация может быть получена как последовательность виртуальных ключей от интерфейса 120 пользователя. Процедура 400 прогнозирования может быть выполнена электронной схемой, которая содержит процессор, память и интерфейс пользователя, например процессор 206, устройства ввода 212 и блок 216 памяти, как показано на фиг. 2. Процедура 400 прогнозирования начинается с инициализации некоторых переменных в строках 404-414. Например, процессор 206 устанавливает переменные текущего состояния в корень словаря в строке 404, устанавливает переменные «обнуление времени» (TimesReset) и «оценка» (Score) в ноль в строках 406 и 408, устанавливает символьную строку символа в ноль, устанавливает строку символов в пустое значение в строке 410, обозначая, что текущий узел является первым узлом в строке 412, и устанавливает переменную i, равную ее начальному значению (в процессе подготовки последующего шага), которое может быть сохранено в блоке 216 памяти. Затем процедура 400 прогнозирования последовательно продвигается через входные состояния, как показано первой циклической функцией, на основе длины входной информации на строке 416 и этапов, выполняемых первым циклом, то есть строки 416-426. Например, как показано на фиг. 4, первый цикл выполняется для каждого символа полученной входной информации. Затем переменная «Разрешенные Переходы» (Allowed Transitions) устанавливается на разрешенное отображение текущей входной информации в строке 418. Например, для клавиш ввода данных, имеющих латинские символы, клавиша 2 может отображать A, B и C, а также цифру 2. Отображение может отличаться от языка к языку и от устройства к устройству, на основе количества отображаемых символов и количества входных возможностей, доступных пользовательскому интерфейсу. Гипотезы устанавливаются равными нулю для инициализации узлов назначения в строке 420. Все описанные выше переменные могут быть сохранены в блоке 216 процессором 206. В общем смысле состояние – это расположение в слове. Таким образом, корень словаря – это расположение в каждом слове такое, что ему следуют все символы в слове. Когда мы открываем переходы в каждой итерации (входного) цикла 416, мы передвигаем вперед этот указатель позиции. Следование переходу символа из одного состояния в другое означает продвижение от одной позиции к другой, если следующий символ соответствует одному из действий перехода. В первом цикле, представленном строкой 416, существует второй цикл, представленный строкой 422. Для этого второго цикла процедура 400 прогнозирования продвигается последовательно через все состояния, сохраненные в переменной «начальные Узлы» (startNodes), на основе длины этих состояний, как показано в строке 422, и этапы образуют второй цикл, то есть строки 424-434. Например, как показано на фиг. 4, второй цикл выполняется для каждого состояния, сохраненного в переменной startNodes. Затем выполняется процедура прогнозирования на основе определенных параметров. На фиг. 5 представлена диаграмма псевдокода для примерной функции 500 перехода, например функции перемещения, которая может быть вызвана строкой 424 (и как будет описано ниже в строке 434), процедуры прогнозирующих комбинаций по фиг. 4. Как представлено строкой 502, функция 500 перехода требует два параметра, а именно переменную currentState, то есть startNode, который доступен, и символ во входной информации, отображенной на входную информацию с соответствующим ключом, то есть allowedTransition, для установления переменной «Новые состояния» (New States). Таким образом, каждый раз, когда выполняется функция 500 перехода, множество новых элементов может быть добавлено в конец переменной «Текущее Состояние» (currentState). Функция 500 перехода также инициализирует переменную для слежения за новыми узлами в строке 504. Затем функция 500 перехода выполняет цикл для обработки новых узлов. В частности, функция 500 перехода выполняет цикл для каждого символа в переменной allowedTransitions в строке 508. Это не только временное местоположение, но и временный узел (который добавляется к новым узлам на этапе 516). Функция 500 перехода затем идентифицирует новый узел на основе вершины, достигаемой из startNode следованием границы текущего символа во входной информации в строке 508. Затем функция 500 перехода сохраняет значение переменной timeReset и подсчитывает значение оценок для startNode во временных расположениях в строках 510 и 512 для того, чтобы сохранить эти старые значения. Затем функция 500 перехода складывает старую символьную строку с границей в строке 514. Затем узел добавляется к результату в строке 516. Окончательно вновь обработанные узлы возвращаются к процедуре 400 прогнозирования в строке 518. Как показано на фиг. 4, процедура 400 прогнозирования определяет, должны ли быть включены в полное слово рассматриваемые вспомогательные состояния на этапе 426. Эта проверка выполняется для определения того, имеет ли смысл обнулить текущее начальное состояние. Например, процессор 206 может сравнить вспомогательные состояния переменной startNodes с базой 218 данных блока 216 памяти для определения того, возникают ли какие-либо совпадения. Если да, то процедура 400 прогнозирования также включает в себя не детерминистические гипотезы. Соответственно процедура 400 прогнозирования готовится перезапустить гипотезу с помощью установки текущего узла в корень словаря, и устанавливает значение временной строковой переменной в строке 429, и увеличивает значение переменной TimeReset для отслеживания количества раз, когда завершенное слово для определенного пути проанализировано для входной информации в строке 430. Процедура 400 прогнозирования затем оценивает полную часть перед перезапуском с помощью добавления ранга, связанного с узлом, для получения счета для текущей комбинации в строке 432. Различные способы добавления ранга могут быть применены к вспомогательным состояниям, такие как похожесть или повторяемость на основе частоты использования. В дополнение к добавлению ранга к определенному рассматриваемому вспомогательному состоянию процедура 300 прогнозирования также будет вычислять объединенную оценку для этого вспомогательного состояния с любым другим ранее идентифицированным вспомогательным состоянием, если такие есть, для рассматриваемой входной информации. Затем процедура 400 прогнозирования использует функцию перехода для определения повторно рассматриваемых состояний в свете только что найденного полного слова в строке 434. Затем процедура 400 прогнозирования сохраняет все сгенерированные гипотезы в строке 436, так что они могут быть использованы на последующих этапах. Затем цикл в строке 422 продолжается до тех пор, пока не будут рассмотрены все возможности. В противном случае, если завершенное слово не идентифицировано в строке 426, то процедура 400 прогнозирования переходит на следующий размер вспомогательного состояния, возвращаясь на строку 422 и определяя, включают ли эти вспомогательные состояния большего размера полное слово еще раз в строке 426. Окончательно новые переменные currentState компилируются в список переменных currentState для обработки на последующем этапе, как будет описано ниже. Процедура 400 прогнозирования продолжает идентифицировать и обрабатывать полные слова в цикле 426 до тех пор, пока существуют все возможные комбинации слов для каждого возможного пути через цикл 416 входной информации, которая пересматривается, и создается полный список переменных currentState. Процедура 400 прогнозирования оценивает все результаты после обработки всех виртуальных ключей в строках 438 и 440. Окончательно процедура 400 прогнозирования возвращает все накопленные символьные строки и завершается в строке 442. Следует отметить, что для другой реализации процедура 400 прогнозирования может ограничивать или еще каким-нибудь способом подстраивать количество гипотез, что делает возможным для последующих этапов предотвратить экспоненциальный рост количества гипотез. Такие ограничения или подстройки могут базироваться на возможностях по обработке устройства, используя эту процедуру 400 прогнозирования. Общее функционирование процедуры 400 может быть объяснено следующим образом. Определенное соответствие или известная комбинация находятся пересечением пути словаря через всю последовательность символов. Соответствие не выполняется для определенного соответствия, если не имеется перехода для соответствия. Другие соответствия могут быть успешными, потому что каждая клавиша может отображать несколько символов, например клавиша 2 отображает символы A, B, C и 2. Например, для введенной пользователем комбинации 2-2-7 “ca” является одной из совпавших комбинаций после обработки первых двух клавиш. Затем машина исследует третью клавишу, например 7, анализируя все переходы, отображенные на этот символ, такие как “p”, “q”, “r”, “s” и 7. В этом процессе машина может идентифицировать одно или более слов. Для приведенного выше примера машина может идентифицировать слова “car”, “cap” и “car”. Должно быть понятно, что последние символы не обязательно показывают последний символ в слове. С другой стороны, машина способна устранять некоторые комбинации на основе вероятности формирования известных операций. Например, вероятность нахождения соответствия для любого из слов, начинающихся со слова “car”, мала, так что машина может отбросить эту вероятность. На фиг. 6 приведена диаграмма псевдокода для процедуры 600 сравнения комбинаций. В частности, эта процедура 600 сравнения анализирует две или более переменных currentState из списка переменных currentState, созданного процедурой 400 прогнозирования, показанной на фиг. 4, и определяет приоритеты переменных currentState на основе одного или более критериев. Например, процедура 600 сравнения, показанная на фиг. 6, определяет приоритеты двух или более переменных currentState на основе количества слов, объединенных для образования каждой комбинации слова, или проверки того, завершена ли комбинация слов, и вычисления оценок, связанных с каждой комбинацией. Функция 600 сравнения включает в себя, но не ограничивается перечисленным, критерии, показанные на фиг. 6. Также, если используются множественные критерии, критерии сами могут быть распределены по приоритетам, так что вес некоторого критерия в финальном решении может быть больше, чем у другого критерия. На фиг. 6 процедура 600 сравнения начинается с идентификации двух переменных currentState, например состояния “a” и состояния “b” из списка переменных currentState. Процедура 600 сравнения определяет, имеют ли эти два состояния одинаковое количество TimesReset в строке 602. Другими словами, комбинация слова в состоянии “a” сравнивается с комбинацией слова в состоянии “b” для определения того, включают ли они одинаковое количество более коротких слов. Если два состояния имеют различное количество TimeReset, то процедура 600 сравнения определяет, какое состояние имеет меньшее количество TiemReset в строке 604, таким образом, получается меньшее количество коротких слов и большая вероятность того, что это является комбинацией, которую хотел ввести пользователь. Например, если количество коротких слов состояния “a” меньше, чем количество коротких слов в состоянии “b”, то процедура 600 сравнения определяет, что состояние “a” должно иметь более высокий приоритет по сравнению с состоянием “b” в строке 604. Таким образом, гипотеза “состояние ‘a’ лучше, чем состояние ‘b'” возвращает результат ИСТИНА, и процедура сравнения 600 завершается. С другой стороны, для этого примера, если количество коротких слов в состоянии “a” не меньше, чем количество коротких слов в состоянии “b” в строке 604, то процедура 600 сравнения определяет, что состояние “b” должно иметь более высокий приоритет, чем “a”. Другими словами, гипотеза “состояние ‘a’ лучше, чем состояние ‘b'” возвращает результат ЛОЖЬ, и процедура 600 сравнения останавливается. В строке 602, если два состояния имеют одинаковое количество TimesReset, то другой критерий должен быть использован для определения того, какое состояние должно иметь более высокий приоритет. В таком случае процедура 600 сравнения переходит на линию 606 для определения того, достигнут ли конец ввода, так как завершенные слова являются предпочтительными. Если да, то процедура 600 сравнения определяет, производят ли одинаковый результат два состояния при анализе на завершенность в строках 608-612. В частности, процедура 600 сравнения определяет, завершено ли состояние “a” в строке 608, результатом является ИСТИНА, если состояние “a” завершено, ЛОЖЬ, если “a” не завершено. Затем процедура 600 сравнения определяет, завершено ли состояние “b” в строке 610, результатом является ИСТИНА, если состояние “b” завершено, ЛОЖЬ, если “b” не завершено. Также в строке 610 процедура сравнения определяет, сгенерировали ли состояния “a” и “b” одинаковые результаты по полноте. Если состояние “a” есть комбинация слова в его полноте, и состояние “b” не является комбинацией слова в его полноте, или наоборот, то результат в определении полноты “a” является финальным результатом в строке 612; ИСТИНА, если состояние “a” завершенное, а состояние “b” незавершенное, ЛОЖЬ, если состояние “a” незавершенное, а состояние “b” завершенное. Процедура 600 сравнения определяет, какое состояние является комбинацией слова в его полноте, и, таким образом, более вероятно является комбинацией слова, которую хотел ввести пользователь. Затем процедура 600 сравнения завершается. С другой стороны, если оба состояния “a” и “b” являются комбинациями слова в его полноте или ни “a” ни “b” не являются комбинациями слова в его полноте, то должен применяться другой критерий для определения того, какое состояние должно иметь больший приоритет. Таким образом, процедура 600 переходит на строку 614 для определения того, какое состояние ассоциировано с более высокой оценкой. Для этого этапа может быть применен метод любого типа для начисления оценок, например, такой как вероятность встречи на основе исторической частоты. Если состояние “a” имеет более высокую оценку, чем “b”, то процедура 600 сравнения определяет, что состояние “a” должно иметь более высокий приоритет по сравнению с состоянием “b”. Если оценки для состояния “a” отличаются от оценок для состояния “b” на строке 614, то процедура 600 сравнения определяет, больше ли оценка у состояния “a”, чем у состояния “b”. Если гипотеза “состояние ‘a’ лучше, чем ‘b'” верна, то процедура 600 сравнения возвращает результат ИСТИНА. С другой стороны, если состояние “a” не имеет более высокой оценки по сравнению с “b”, то гипотеза “состояние ‘a’ лучше, чем ‘b'” возвращает ЛОЖЬ. Таким образом, выполнение процедуры 400 прекращается. Для предпочтительной реализации процедура 400 сравнения, как показано на фиг. 6 и описано выше, исполняется процессором 206 и использует блок памяти 216. Следует отметить, что последний критерий, рассматриваемый процедурой 600 сравнения, не может точно определить лучшее состояние, то есть состояние с более высоким приоритетом. Например, для примера, показанного на фиг. 6, оценка состояния “a” может быть равна оценке состояния “b” и, таким образом, состояние “a” и состояние “b” равны на основе всех критериев, рассматриваемых процедурой 400 сравнения. В этом случае может быть предопределено решение по умолчанию для того, чтобы завершить определение приоритетов. Например, как показано на фиг. 6, если оценка состояния “a” равна оценке состояния “b” в строке 614, то состояние по умолчанию “a” считается имеющим более высокий приоритет, чем состояние “b”, и гипотеза “состояние ‘a’ лучше, чем ‘b'” возвращает истину в строке 616. На фиг. 7 и 8 представлен список слов и таблица слов, представляющие сравнение примерных комбинаций слов. Список слов на фиг. 7 и таблица слов на фиг. 8 представлены здесь как примеры для дальнейшего описания возможностей компонент и процедур, показанных на фиг. 1-6 и описанных выше. Соответственно конкретные элементы, показанные на фиг. 7 и 8 и описанные ниже, не должны использоваться для ограничения пределов изобретения. На фиг. 7 представлена оценка полной символьной строки, которая может быть выполнена с использованием настоящего изобретения. Оценка полной символьной строки анализирует полностью виртуальную последовательность клавиш или символьную строку после выборки каждой клавиши интерфейса 120 пользователя. Оценка полной символьной строки разделяет символьную строку на возможные подстроки, которые соответствуют элементам в базе 218 данных, и устанавливает веса в соответствии с их вероятностью. На основе одного или более критериев комбинации строк распределяются по приоритетам. Например, комбинация строк, имеющая наименьшее количество завершенных сегментов и/или самую высокую комбинированную вероятность, может быть выбрана как лучший результат выбора. Для примера, показанного на фиг. 7, предполагается, что выборы клавиш были введены на интерфейсе 120 пользователя в определенном порядке, а именно 2-2-5-5-7-3-7-5, как представлено в верхней части 702-716 чертежа. Каждая из первой клавиши 702, второй клавиши 704 и шестой клавиши 712 представляют символы A, B, C и 2; каждая из третьей клавиши, четвертой клавиши и восьмой клавиши представляют символы J, K, L и 5; и каждая из пятой клавиши и седьмой клавиши представляют символы P, Q, R, S и 7. Четыре возможных комбинации слова также показаны на фиг. 7, а именно “callsask” 718, 720; “ballpark” 722, 724; “allpar” 728, 730 и “ballsask” 734, 736. Первая возможная комбинация слова включает в себя короткие слова “calls” 718 и “ask” 720, вторая возможная комбинация слова включает в себя короткие слова “ball” и “park” 724, третья возможная комбинация слова включает в себя короткие слова “all” 728 и “par” 730, и четвертая возможная комбинация слова включает в себя короткие слова “balls” 734 и “ark” 736. Настоящее изобретение может определить приоритеты этих возможных комбинаций слов с помощью выбора наиболее вероятного разделения, как показано в результирующей области 738. Если процедура 600 сравнения комбинаций по фиг. 6 используется для анализа этих возможных комбинаций слов, то переменные currentState, которые содержат комбинации слов, должны сравниваться по два одновременно, начиная с вершины списка. Так как более новые версии переменной currentState имеют более высокий приоритет по сравнению с более старыми переменными currentState, порядок списка не меняется, и процедура 600 сравнения продолжает двигаться по списку вниз. Если более старое значение переменной currentState имеет более высокий приоритет, чем более новая переменная currentState, то порядок этих двух состояний резервируется, и переменная currentState с наивысшим приоритетом продолжает двигаться вверх по списку до тех пор, пока она не будет сравнена с другой переменной currentState, имеющей еще более высокий приоритет. Затем операция возвращается в точку, где проанализированные переменные currentState встречаются с непроанализированными переменными currentState, и продолжает сравнивать состояния попарно. Эта операция продолжается до тех пор, пока весь лист не будет проанализирован и отсортирован. Например, процедура 600 сравнения может сравнить первую возможную комбинацию слов 718, 720 со второй возможной комбинацией слов 722, 724 и определить, что переменные TimesReset равны, и что целостность каждой переменной currentState равна. Тем не менее, вторая возможная комбинация слов 722, 724 может получить более высокий приоритет по сравнению с первой возможной комбинацией слов 718, 720 на основе вероятности появления, и, таким образом, порядок этих комбинаций может обратиться. Затем процедура сравнения комбинаций 600 может сравнить первую возможную комбинацию слов 718, 720 со второй возможной комбинацией слов 728, 730 и определить, что переменные TimesReset равны. Тем не менее, процедура 600 сравнения может рассмотреть переменную currentState первой возможной комбинации слов 718, 720 как комбинацию слов во всей ее полноте, но она может рассмотреть переменную currentState третьей возможной комбинации слов 728, 730 другим способом, так как переменная currentState включает в себя, по меньшей мере, один дополнительный символ, то есть символ “a” 726 и символ “b” 732. Таким образом, порядок первой возможной комбинации слов 718, 720 и третьей возможной комбинации слов 728, 730 не изменится. Затем третья возможная комбинация слов 728, 730 будет сравниваться с возможной комбинацией слов. Фиг. 8 показывает примерное определение порядка сортировки на основе орфографической структуры результата. Таблица слов на фиг. 8 содержит колонки возможных комбинаций 802 слов, образующие или сегментированные короткие слова 804, оценку 806 для соответствующей комбинации слов, ранг 808 для соответствующей комбинации слов, причину 810 расстановки приоритета для соответствующей комбинации слов и примерный словарь 812 для хранения коротких слов. Возможные комбинации слов 802 могут быть входной информацией, полученной от ввода 120 пользователя. Образующие слова и оценка могут быть определены процедурой прогнозирования, такой как процедура 400 прогнозирования, показанная на фиг. 4. Для одной реализации оценка для каждой комбинации слов определяется с помощью определения оценки для каждого более короткого слова из комбинации слов и объединения оценок всех более коротких слов комбинации слов. Оценка для каждого более короткого слова может быть определена с помощью вероятности или каким-либо другим способом оценки. Ранг или приоритет может быть определен процедурой сравнения, такой как процедура сравнения, показанная на фиг. 6. Примерный словарь может быть возможным эквивалентом базы 218 данных, сохраненной в блоке 216 памяти. Процедуры, описанные здесь, предпочтительно спроектированы для статических словарей, то есть баз данных с информацией, и их свойства, такие как частота, остаются неизменными, и подстройка для динамического обучения также может быть рассмотрена. В любое время может быть сделан выбор между двумя или более результатами, и процедуры могут разделить решения на несколько этапов. Во-первых, процедуры рассматривают, как хорошо подходит к соответствующему языку сгенерированное слово или последовательность. Если один из сравненных результатов лучше, чем другой, то лучший результат рассматривается как более предпочтительный. Во-вторых, если все сравненные величины оказываются равными в контексте соответствия тестам, они сортируются в соответствии с вычисленной частотой. Результаты разбиваются на составляющие их дополнения. Например, (фиг. 8) предположим, что пользователь желает напечатать сложное слово “ballgame” в интерфейсе 120 пользователя. После выбора всех восьми кнопок (2-2-5-5-4-2-6-3) существует 38, то есть 6561 возможных комбинаций. Характерные примеры включают в себя, но не ограничиваются перечисленным: “ballgame” 814, “aallgame” 816, “ballhcof” 818 и “callhand” 820. Первое слово “ballgame” 814 получает высокий приоритет или ранг, так как оно состоит из двух последовательных полных и часто используемых слов. Второе и третье слова “aallgame” 816 и “ballhcof” 818 с меньшей вероятностью являются предпочитаемыми пользователем, так как они имеют больший TimesReset, чем первое слово “ballgame” 814, то есть второе слово содержит три сегмента, и третье слово содержит четыре сегмента. Также ни второе, ни третье слово не являются полными, то есть комбинацией правильных слов. Подобно первому слову “ballgame” 814 четвертое слово “callhand” 820 также имеет более высокий приоритет или ранг 808 по сравнению со вторым и третьим словами 816, 818. Тем не менее, четвертое слово “callhand” 820 имеет более низкий приоритет или ранг 808 по сравнению с первым словом “ballgame”, так как оно получает меньшую оценку, чем первое слово, на основе вероятности появления. Хотя были описаны и проиллюстрированы предпочтительные варианты реализации изобретения, должно быть понятно, что изобретение не ограничивается этим. Многочисленные модификации, изменения, вариации, подстановки и эквиваленты могут быть разработаны специалистами в данной области техники без выхода за пределы объема настоящего изобретения, определяемого нижеследующей формулой.
Формула изобретения
1. Устройство беспроводной связи для выполнения полнотекстовой оценки сложных слов, содержащее интерфейс пользователя, выполненный с возможностью приема входных данных, соответствующих, по меньшей мере, одному сложному слову; процессор, связанный с интерфейсом пользователя, выполненный с возможностью идентификации комбинаций слов из более коротких слов, которые могут быть объединены для образования, по меньшей мере, части, по меньшей мере, одного сложного слова и определения приоритета, на основе, по меньшей мере, одного критерия, причем, по меньшей мере, один критерий содержит идентификацию конкретного полного количества коротких слов для каждой комбинации слов; и дисплей, связанный с процессором, выполненный с возможностью отображения комбинаций слов на основе приоритета. 2. Устройство по п.1, дополнительно содержащее базу данных, связанную с процессором, выполненную с возможностью хранения множества коротких слов, но не пренебрегающую, по меньшей мере, одним сложным словом. 3. Устройство по п.1, дополнительно содержащее приемопередатчик, связанный с процессором, выполненный с возможностью передачи сообщения, которое содержит, по меньшей мере, одно сложное слово, идентифицированное процессором. 4. Устройство по п.1, в котором в любой момент времени дисплей показывает одну из комбинаций слов, имеющую более высокий приоритет, и множество комбинаций слов в порядке приоритета. 5. Устройство по п.1, в котором, по меньшей мере, один критерий содержит комбинацию слов, имеющую более низкое общее количество коротких слов, которая имеет более высокий приоритет, чем комбинации слов, имеющие более высокое общее количество коротких слов. 6. Устройство по п.1, в котором, по меньшей мере, один критерий содержит результат проверки того, формирует ли комбинация слов, по меньшей мере, одно сложное слово в его полноте. 7. Устройство по п.1, в котором процессор оценивает каждую комбинацию слов на основе вероятности употребления. 8. Устройство по п.1, в котором оценка для конкретной комбинации слов соответствует объединенной оценке всех коротких слов определенной комбинации слов. 9. Устройство по п.1, в котором, по меньшей мере, один критерий представляет собой оценку комбинаций слов. 10. Способ для выполнения полнотекстовой оценки сложных слов, включающий в себя этапы, на которых получают входные данные, соответствующие, по меньшей мере, одному сложному слову; идентифицируют комбинации слов из более коротких слов, которые могут быть объединены для образования, по меньшей мере, части, по меньшей мере, одного сложного слова; и определяют приоритеты для комбинаций слов на основе, по меньшей мере, одного критерия, причем, по меньшей мере, один критерий содержит идентификацию конкретного полного количества коротких слов для каждой комбинации слов.
РИСУНКИ
|
||||||||||||||||||||||||||