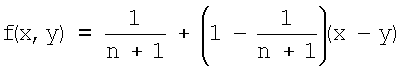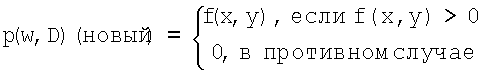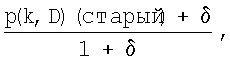Патент на изобретение №2331159
|
||||||||||||||||||||||||||||||||||||||||
(54) СПОСОБ МАРШРУТИЗАЦИИ СООБЩЕНИЙ ОТ УЗЛА ИСТОЧНИКА К УЗЛУ НАЗНАЧЕНИЯ В ДИНАМИЧЕСКОЙ СЕТИ
(57) Реферат:
Изобретение относится к области связи. Описывается способ обновления таблиц маршрутизации во временных сетях, таких как сети, включающие в себя мобильные узлы, связывающиеся через беспроводные соединения. Способ использует для обновления таблиц маршрутизации при утрате или обнаружении соседних узлов стохастическую и эмпирическую информацию. Техническим результатом является усовершенствование способа маршрутизации в динамических сетях. 9 з.п. ф-лы, 1 табл.
Область техники, к которой относится изобретение Данное изобретение относится к проблеме маршрутизации во временных сетях (ad-hoc networks, далее обозначаемые как AHN). Такие сети могут состоять из мобильных узлов, связывающихся путем беспроводных соединений. Уровень техники Связь в AHN может производиться непосредственно между двумя мобильными узлами, если они работают во взаимно допустимых диапазонах. Более часто встречается случай использования маршрутизации с множественными интервалами связи, при которых узлы, находящиеся между узлом S источника и узлом D назначения, служат в качестве маршрутизаторов, передающих данные от источника к узлу назначения через множество интервалов связи. Это технически вызывает поиск таких путей с множественными интервалами связи, т.к. топология AHN постоянно изменяется из-за перемещения узлов. В общем случае, таким образом, между узлами в AHN необходима маршрутизация сообщений. Следует отметить, что маршрутизация от мобильного узла к шлюзовому узлу G (который обычно неподвижен) также представляет существенный интерес. В этом случае шлюзовой узел предоставляет доступ мобильной AHN к фиксированной сети. Маршрутизация узел-шлюз может в общем случае включать случай множественных интервалов связи, при которой (вновь) промежуточные мобильные узлы служат в качестве маршрутизаторов для передачи данных к шлюзу или от шлюза. Фраза «маршрутизация с множественными интервалами связи» может использоваться применительно к любому из двух случаев (мобильный Проблема состоит в нахождении хороших маршрутов между парой взаимодействующих узлов в AHN. Для «хороших» маршрутов существует множество критериев. Маршрут должен быть осуществимым (т.е. не должен основываться на устаревшей информации о топологии, которая использует более не существующие связи). Маршрут также должен быть как можно короче, чтобы минимизировать использование диапазона частот для передачи; он также должен проходить вне перегруженных областей, так как это приводит к нежелательной задержке при передаче данных. В зависимости от обстоятельств и использования могут быть другие критерии для качества маршрута. Настоящее изобретение полезно для любых критериев качества, когда они могут быть измерены в процессе передачи данных по маршруту. Все упомянутые выше критерии (существование, длина и задержка на маршруте) являются измеряемыми. Нахождение хорошего пути уже является разрешимой задачей для статических сетей. Когда топология сети зависит от времени, возникают совершенно новые задачи. Для реалистического и практического диапазона подвижности узлов и диапазона беспроводной связи топология сети AHN может изменяться быстрее, чем позволяют традиционные методы, используемые для статических сетей. Следовательно, необходимо разработать новые способы поиска путей (маршрутизации) в динамических сетях. Маршрутизация в AHN интенсивно изучалась в течение последних 10-15 лет. Количество предлагавшихся протоколов маршрутизации очень велико, и не имеет смысла перечислять здесь их все. Ниже приведены некоторые обзоры специальных протоколов: S.Ramanathan и М.Steensrup, “A survey of routing techniques for mobile communications networks” (Обзор методов маршрутизации для мобильных сетей связи), Mobile Networks and Applications, vol.1 no.2, p.89, 1996. J.Broch, D.A.Maltz, D.B.Johnson, Y.-C.Hu и J.Jetcheva, “A performance comparison of multy-hop wireless ad hoc network network routing protocols” (Сравнение показателей протоколов маршрутизации беспроводных временных сетей с множественными интервалами связи), Proc.MobiCom Е.М.Royer и С.-К.Toh “A review of current routing protocols for ad hoc mobile wireless networks” (Обзор современных протоколов маршрутизации для временных мобильных беспроводных сетей), IEEE Personal Communications, April 1999, р.46. Электронный обзор Christian Tscudin из университета Uppsala приведен на сайте: Имеется также рабочая группа комитета по инженерным вопросам Internet (IETF), специализирующаяся на специальных мобильных сетях, или MANET. См.: Далее, для маршрутизации в фиксированных (но динамических) сетях в многочисленных исследовательских статьях была предложена стохастическая маршрутизация. Одна из статей, описывающая специальную схему стохастической маршрутизации для специальных сетей: Р.Gupta и P.R.Kumar, “A system and traffic dependent adaptive routing algorithm for ad hoc networks” (Система и адаптивный алгоритм, зависящий от трафика, для временных сетей), Proceedings of the IEEE Conference on Decision and Control, pp.2375-2380, San Diego, Dec. 1997. Стохастическая маршрутизация является формой многопутевой маршрутизации. При многопутевой маршрутизации узлы сохраняют таблицы маршрутизации (routing tables, далее обозначаемые RT) с множественным выбором пути для каждого возможного пункта назначения. Для динамических сетей выгодно сохранять множественные пути, так как это позволяет производить быструю смену пути в случае невозможности использования первого выбранного пути. Стохастическая маршрутизация влечет за собой сохранение информации о множественных путях, а также то, что выбор между множеством путей будет осуществляться вероятностным, а не детерминированным путем. Таким образом, стохастическая маршрутизация обязательно включает в себя следующие элементы: каждый узел S, рассматриваемый как источник данных, сохраняет RT для каждого возможного узла D назначения. Каждая такая RT имеет запись для каждого соседнего узла k узла S, содержащая вероятность p(k,D). Таким образом, когда бы не пересылались данные из S в D, соседний узел k будет выбираться с вероятностью p(k,D). Большинство специальных протоколов пытается перед передачей данных определить полный путь от первого узла S до второго узла D. Имеется две обширные категории протоколов, выполняющих такие действия. Активные протоколы: Эти протоколы пытаются найти полное решение для маршрутизации для всей сети в любое время. В этом смысле они сходны с теми подходами, которые используются для маршрутизации в статических сетях – хотя они конечно адаптированы для лучшей работы с AHN динамической природы. Эти протоколы также известны как «управляемые таблицами», так как они пытаются поддерживать информацию, относящуюся к полному комплекту таблиц маршрутизации для всех пар S-D. Реактивные протоколы: Эти протоколы пытаются найти пути из S в D, когда узлу S источника требуется передать данные в узел D назначения. Они также называются «инициируемыми источниками» или «протоколами по требованию». Недавняя оценка двух наиболее известных протоколов проведена в: С.Е.Perkins, E.M.Royer и М.К.Marina “Performance comparison of two on-demand routing protocols for ad-hoc networks” (Сравнение свойств двух протоколов маршрутизации «по требованию» для временных сетей), IEEE Personal Communications, February 2001, р.16. Имеются схемы временной маршрутизации, которые не требуют нахождения полного пути перед передачей данных. Такие схемы используют один или оба из описанных ниже механизмов: Иерархические протоколы: сеть разбивается на кластеры. Маршрутизация в пределах кластера производится любым из упомянутых выше методов. Однако прокладка маршрута к узлу, находящемуся вне кластера узла S, выполняется путем передачи данных к указанному шлюзовому узлу. (Здесь шлюзовой узел относится к другому кластеру, а не к фиксированной сети, и шлюзовые узлы также являются мобильными узлами). Затем данные передаются от кластера к кластеру через шлюзовые узлы, которые должен решить задачу маршрутизации между кластерами, пока не будет достигнут кластер, в котором находится узел D. Затем данные передаются в D с использованием межкпастерового протокола. Такая иерархическая маршрутизация имитирует маршрутизацию, применяемую в статическом Интернете. Протоколы, основанные на положении: Если узлу S известно его собственное географическое положение, а также положение узла D, то узел S может отправлять данные в направлении узла D, не зная полного пути к узлу D. Задачей является поддержание информации о расположении узлов назначения, которые являются мобильными, в актуальном состоянии. Если узел назначения является фиксированным шлюзовым узлом G (предоставляющим доступ к фиксированной сети), то решение указанной задачи является тривиальным, и требуется только оснастить каждый мобильный узел средствами позиционирования. По-видимому, не существует единственного лучшего решения проблем маршрутизации с множественными интервалами связи в специальных сетях. Такие сети могут существенно различаться по мобильности узлов и по конфигурации и объему межузлового трафика. Каждый отдельный тип схемы маршрутизации имеет свои слабые места, как описано ниже. Активные протоколы: Такие протоколы явно лучше работают, когда топология сети меняется медленно. По тем же признакам, когда сеть является слишком динамичной (например, из-за большой подвижности узлов), эти протоколы переполняют сеть дополнительными сообщениями, стремясь сохранить полный набор таблиц маршрутизации, обновляемых, несмотря на слишком большие изменения сети во времени. То есть эти протоколы не могут работать при слишком больших изменениях сети во времени, обычно из-за слишком большой подвижности узлов и/или слишком большого размера сети. Короче говоря, принципиальной проблемой с активными протоколами являются большие потери, связанные с маршрутизацией в динамических сетях. Реактивные протоколы: Эти протоколы ищут пути только тогда, когда они необходимы, сокращая таким образом потери на маршрутизацию по сравнению с активными протоколами. Таким образом, их потери растут с ростом сетевого трафика, а не с изменяемостью сети. Такие схемы могут хорошо работать в высокодинамичных сетях, если величина трафика не слишком высока. Поэтому они являются предпочтительными при использовании активных протоколов. Реактивные протоколы работают неудовлетворительно, когда требуемая скорость нахождения пути превышает возможную скорость нахождения пути. Это происходит из-за высокого трафика (увеличивает требуемую скорость нахождения пути), высокой скорости в сети (увеличивает требуемую скорость нахождения пути и одновременно уменьшает возможную скорость нахождения пути) или большого размера сети (уменьшает возможную скорость нахождения пути). Реактивные протоколы особенно уязвимы с точки зрения последнего фактора: если сеть становится слишком большой, время, требуемое для нахождения путей по требованию, может превысить время, в течение которого путь существует, при этом маршрутизация становится невозможной. Конечно, не существует схемы маршрутизации в сетях AHN, которая может применяться в произвольной большой сети. Однако необходимость нахождения полного пути в реальном времени является существенным ограничением для обоих этих классов протоколов – активных и реактивных. Иерархические протоколы: В этих схемах исключается необходимость в определении полного пути перед передачей данных. Однако они сталкиваются с проблемами, аналогичными проблемам, возникающим в активных схемах, т.е. они не могут работать в слишком больших сетях и/или в слишком динамичных сетях. Причина заключается в том, что они должны неоднократно решать проблему сетевого масштаба: выбор того, как объединить узлы в иерархические кластеры и как проложить путь между кластерами. Для некоторых мобильных конфигураций (например, когда узлы естественно стремятся перемещаться в кластерах), решения для этой глобальной проблемы не будут изменяться слишком быстро. Однако для AHN в общем случае с очень подвижными узлами, двигающимися некоррелированным образом, иерархическая схема будет подвергаться неприемлемым нагрузкам, особенно если сеть велика. Протоколы, основанные на положении: Эти протоколы в основном избегают проблем перегрузок указанного выше типа, так как для передачи данных им требуется только знать местоположение. Однако, они имеют два недостатка. Во-первых, может оказаться сложным получить достаточно полную информацию о расположении узлов назначения. Для узла источника отсутствует необходимость точного знания расположения узла D, и поэтому такие схемы могут работать при частично устаревшей информации. Более того, регулярная связь с узлом D служит для обновления мест расположения. Следовательно, проблема возникает только при связи на нерегулярной основе (во времени) с рядом различных узлов, которые удалены географически. Вторая проблема схем, основанных на расположении, заключается в том, что они естественным образом зависят от «наведения» данных на узел D. То есть в качестве следующего интервала связи выбирается ближайший к узлу D. Проблема возникает, когда данные получаются узлом, который не может достичь узла D непосредственно, а также другого узла, который находится ближе него к узлу D. Такой узел представляет собой «тупик» для этого типа схем маршрутизации, которые поэтому должны быть дополнены некоторым механизмом для прокладки маршрута в обход тупиков. Тупики наиболее возможны для AHN с низкой и/или очень неравномерной плотностью узлов. В конце (как указано выше) отметим, что прокладка маршрута к фиксированному шлюзовому узлу имеет только вторую из двух проблем, так как расположение шлюзового узла G всегда известно. Раскрытие изобретения Задача, на решение которой направлено настоящее изобретение, состоит в создании способа, который устраняет недостатки, описанные выше. В соответствии с изобретением поставленная задача решается посредством способа маршрутизации сообщений от узла источника к узлу назначения в динамической сети, причем указанный узел источника содержит таблицу маршрутизации, каждая строка которой представляет собой возможный узел назначения для информационного сообщения, передаваемого от узла источника, и каждая строка в таблице маршрутизации включает в себя одно значение вероятности для каждого узла, соседнего с узлом-источником, причем указанный способ включает в себя обновление значения вероятности с качественными измерениями, проводимыми каждый раз при передаче сообщения от узла источника к узлу назначения, маршрутизацию заранее определенного процента сообщений путем выбора соседнего узла с наибольшим значением вероятности в строке таблицы маршрутизации для узла назначения, и маршрутизацию других сообщений путем распределения сообщений между соседними узлами в соответствии со значениями вероятности, имеющимися в той же строке таблицы маршрутизации. Однако испрашиваемый объем защиты настоящего изобретения определяется формулой изобретения, включающей в себя несколько предпочтительных вариантов осуществления изобретения. Осуществление изобретения Как упоминалось ранее, в общем случае настоящее изобретение предназначено для маршрутизации сообщений между узлами в сети AHN. Настоящее изобретение относится именно к этой проблеме маршрутизации, точнее, к маршрутизации с множественными интервалами связи в сетях AHN. Как упоминалось ранее, для маршрутизации в фиксированных (но динамических) сетях во многих научных статьях была предложена стохастическая маршрутизация, а в работе Gupta и др. была предложена форма стохастической маршрутизации для AHN. В настоящем изобретении предложена стохастическая маршрутизация для сетей AHN. Оно включает в себя использование самих пакетов данных в качестве средства для обновления таблиц маршрутизации (RT) с новым сочетанием стохастической и детерминистической маршрутизации для данных. Настоящее изобретение также включает в себя новый способ обновления RT в случае установления нового соединения. Для каждой схемы стохастической маршрутизации требуется метод для обновления значений вероятностей в RT (также называемых «весами»). По изобретению каждый раз при посылке сообщения из узла S в узел D будет измеряться качество выбираемого пути. Мерой качества может служить количество интервалов связи, временная задержка или другие критерии, или их комбинация. Предлагаемый способ может использоваться для любой такой меры качества, если она измеряема. Мера качества пути наряду с выбираемым путем затем присоединяются к пакету данных. Эта информация представляет собой небольшие дополнения, включаемые при отправке данных. Затем происходит обновление RT следующим образом. Если соединения в сети симметричны, то сообщение может обновлять RT, относящиеся к узлу S, в каждом узле N, имеющемся на пути, т.к. вследствие симметричности качество пути S Если соединения не симметричны, то сообщения приходят в узел D с информацией о качестве пути S Измеренное качество пути может быть обозначено
для того случая, когда узел k был использован в пути. Оставшиеся вхождения j для узла назначения D корректируются таким образом, чтобы сумма вероятностей была равна единице:
Это дает общий метод для обновления весов в RT. Специальный метод для определения обновленного веса В соответствии с предпочтительным вариантом осуществления изобретения, каждое сообщение используется в качестве источника информации для обновления стохастических RT. Следовательно, этот метод естественным образом регулирует скорость обновления в соответствии со скоростью трафика: при высоком трафике RT часто обновляются, а следовательно, с высокой вероятностью остаются достоверными. В настоящем изобретении также предлагается другой механизм обновления, который не зависит от скорости трафика, а включается при изменении топологии сети. Таким образом, этот второй механизм поддерживает RT обновленными даже при низких скоростях трафика, играя меньшую роль при высоких скоростях трафика. Второй механизм обновления инициируется любым узлом j, когда этот узел обнаруживает изменение в наборе соседних узлов NS(j). Что является набором соседних узлов для узла, использующего беспроводную связь, определяется алгоритмом, который регулирует уровень мощности для поддержания возможности связи, пытаясь поддерживать уровень помех между различными соединениями на как можно более низком уровне. Имеется ряд таких алгоритмов для использования в сетях AHN. Настоящее изобретение не определяет такие алгоритмы. Определяется правило реагирования на изменения в NS. Здесь имеются два возможных случая: (а) потеря соседнего узла и (b) появление соседнего узла. а) Потеря соседнего узла. Предположим, что узел j потерял соединение с соседним узлом k. В этом случае возникают две задачи, которые требуется решить: (i) RT для всех узлов назначения D должны быть настроены таким образом, чтобы отразить удаление соседа k. (ii) Узел j должен построить набор весов (т.е. новую строку в своей RT), определяющий, как проложить маршрут к k, т.к. он более не является соседним узлом в пределах одного интервала связи. (i) Для каждого узла назначения D веса для оставшихся соседних узлов NS для j должны быть настроены так, чтобы их сумма равнялась единице. В настоящем изобретении предлагается настраивать эти веса таким образом, чтобы они сохраняли тот же относительный вес, который они имели до потери соседнего узла k. Это правило мотивируется тем фактом, что потеря соседнего узла k не дает никакой новой информации об относительном качестве оставшихся путей к узлу D. (ii) Узел j должен выждать (регулируемый) временной интервал b) Появление нового соседнего узла: Предположим, что узел j получил новый соседний узел w. Теперь требуется решить только одну задачу, т.к. аналог (ii) – нахождение потерянного соседнего узла – здесь не требуется. Тогда задачей является настройка RT в j для всех возможных узлов назначения D (отличных от w), при условии, что j получил новый соседний узел. Желательно использовать информацию о маршрутах, хранящуюся в RT в j, а также использовать информацию о маршрутах, хранящуюся в RT в w. Это делается следующим образом. Целью является извлечение информации о достижении узла назначения D из узлов j и w. Первым этапом является оценка качества информации, содержащейся в j и w соответственно. Количественно узел j вычисляет оценку качества маршрутизации RQR(D,j) для каждого узла назначения D в своей RT: RQR(D,j)=p(max,D)-p(min,D), где p(max,D) – максимальный вес в текущем списке для узла назначения D, и p(min,D) – минимальный вес. Вычисленный таким образом, RQR имеет минимальное значение нуль (ничего не известно о маршруте к D), а максимальное значение единица (в каждом случае только одно, лучший путь к D имеет какой-нибудь вес). Узел j также запрашивает RQR(D,w) для каждого узла назначения D из узла w. Теперь узел j присвоит больший или меньший вес для использования w в качестве пути к D в соответствии с относительными значениями двух RQR. Если j до обнаружения w имеет n соседей, то после обнаружения он имеет n+1 соседей, таким образом, средний вес для узла w будет 1/(n+1). Узел j будет отклоняться от этого среднего значения, если два RQR (для j и для w) достаточно отличаются, как указано ниже. Пусть x=RQR(D,w) y=RQR(D,j)
Тогда новый вес, присвоенный узлу w в RT узла j для узла D, будет
Это правило дает средний вес для узла w, если его RQR для узла D (который показывает, как много узел w «знает» о маршруте к узлу D) является таким же, как RQR узла j для узла D. Однако, если узел w «знает» значительно больше, чем узел j [RQR(D,w)=1, RQR(D,j)=0], то новый вес узла w в таблице маршрутизации узла j будет 100%. Наконец, если RQR в узле w значительно меньше, чем в узле j, ему будет присвоен нулевой вес. Коротко говоря, это правило создано для оценки относительных «знаний» двух узлов, относящихся к маршрутизации к узлу D и для определения весов путей к узлу D от узла j через узел w соответственно. Оставшийся вес, таким образом, 1-p(w,D) (новый) распределяется пропорционально между оставшимися соседними узлами узла j с пропорциями, установленными до обнаружения узла w. При условии наличия таблицы с множественным взвешенным содержимым для каждого узла назначения, имеется выбор из трех возможностей для направления пакета к узлу назначения. Эти возможности могут быть названы «однородной», или u-маршрутизацией, «нормальной», или r-маршрутизацией и «скупой» или g-маршрутизацией. Однородная маршрутизация (u-маршрутизация) игнорирует веса в RT и выбирает следующий интервал связи с равной вероятностью среди соседних узлов. Однородная маршрутизация не является хорошим выбором для маршрутизации данных. Однако (как отмечено выше), пустые сообщения, ищущие утерянный соседний узел, маршрутизированы (на первом интервале связи) однородно. Более того, может оказаться преимущественным посылать небольшое количество пустых сообщений даже при отсутствии изменений в NS. Эти сообщения являются “шумом” в процессе маршрутизации. Их эффективность заключается в том, что они могут служить для обнаружения хороших путей, которые окажутся неиспользованными, если RT системы установили другой набор путей, которые ранее были лучшими, но перестали быть таковыми. Таким образом, шум при маршрутизации предотвращает «замораживание» системы на менее чем оптимальных путях. Для стохастических схем маршрутизации обычным является использование небольшого процента f u-маршрутизации пустых сообщений; в предлагаемой схеме такие сообщения также будут использоваться, причем f является настраиваемым параметром. Нормальная маршрутизация (r-маршрутизация) посылает данные с вероятностью, имеющейся в RT. Это стохастическая маршрутизация. Наконец, скупая маршрутизация (g-маршрутизация) всегда выбирает для следующего интервала связи значение с максимальным весом. Следовательно, этот метод является детерминистским. В исследованиях по стохастической маршрутизации в фиксированных сетях обычно используется большое количество пустых сообщений, служащих для сбора информации о путях. Такие пустые сообщения часто называются «агентами» или «муравьями», причем последнее название вызвано их природой, представляющей собой небольшие объекты, снующие в сети и оставляющие за собой «след», направляющий других муравьев. Чтобы последующие муравьи могли с пользой обучаться у предыдущих, важно, чтобы муравьи (пустые сообщения, исследующие сеть) направлялись с помощью r-маршрутизации. Т.е. они должны следовать вероятностями, установленными предыдущими опытами. С другой стороны, сообщения (в этих исследованиях) обычно маршрутизируются с использованием скупой маршрутизации: выбирается наилучший известный в данное время путь. Следовательно, в предыдущих исследованиях по стохастической маршрутизации в фиксированных сетях для пустых, исследовательских сообщений (муравьев) использовалась r-маршрутизация, а для данных g-маршрутизация. В настоящем изобретении муравьи и данные должны быть скомбинированы: каждый передаваемый в сети пакет используется для обновления RT, и имеется немного пустых сообщений, используемых исключительно для исследования сети. Другими словами, сообщения также действуют как муравьи. Однако, так как оба типа скомбинированы, они должны маршрутизироваться по одному правилу: g- или r-маршрутизация. В настоящем изобретении предлагается использовать смешение двух правил: h процентов сообщений должны маршрутизироваться с высоким приоритетом (скупая маршрутизация, наибольший вес) и (100-h) процентов сообщений должны маршрутизироваться со стандартной приоритетностью (нормальная маршрутизация в соответствии с весами в RT). h является настраиваемым параметром. Настоящее изобретение применяет смешение двух правил маршрутизации, чтобы использовать преимущества обоих: g-маршрутизация обычно дает наилучшие эксплуатационные показатели для любого сообщения; но r-маршрутизация необходима для поддержки процесса обучения сети, в который коллективно вносят свою долю все сообщения. Следовательно, выбрано смешение, пропорции которого должны определяться в соответствии с эксплуатационными показателями, достижимыми при данном наборе рабочих условий. Пример В Таблице, приведенной ниже, приведен пример таблицы маршрутизации (RT) для узла, который мы называем узлом S источника.
В этом примере узел S имеет пять соседей на одном интервале связи. Тогда RT имеет «индекс качества», который может интерпретироваться как вероятность использования для каждого соседа для каждого узла назначения. Например, если S собирается сделать посылку в узел назначения 1, в соответствии с RT лучшим выбором будет Сосед 2. Примечание: этот индекс качества не является оценкой качества маршрутизации RQR. Например, RQR для узла S и узла назначения 1 составляет 0,5-0,05=0,45, в то время как узел назначения 4 имеет низший RQR, равный нулю. «И т.д.» в данном примере означает, что в типовой специальной сети имеется более 4 узлов назначения. Таким образом, сеть, видимая из S, состоит из самого S (один узел), плюс соседи S (здесь еще 5 узлов), каждый из которых может иметь в RT свою строку. «Скупая маршрутизация» будет всегда выбирать соседа с наибольшим индексом качества. Т.е. при заданном узле назначения D просматривает соответствующую строку в RT и выбирает соседний узел с наибольшим индексом качества. Так как сумма индексов в каждой строке равна единице, они могут рассматриваться как вероятности. «Нормальная маршрутизация» при, например, заданном узле назначения D, просматривает соответствующую строку в RT и выбирает соседний узел на первом интервале связи с вероятностью, которая равна индексу для этого соседнего узла в строке. Т.е. если узел S использует нормальную маршрутизацию и собирается послать сообщение на узел назначения 1, для узла S необходим алгоритм (являющийся стандартным), который выбирает соседний узел 1 с вероятностью 0,1, соседний узел 2 с вероятностью 0,5 и т.д. Когда имеется множество возможных выборов для следующего интервала связи для каждого узла назначения, и вес, или вероятность для каждого, то мы говорим, что схема маршрутизации использует «стохастическую маршрутизацию». Большинство схем (но не все), использующих стохастическую маршрутизацию, будет использовать скупую маршрутизацию для сообщений и нормальную маршрутизацию для «исследовательских пакетов» и «муравьев». Первые переносят данные, хотя они используются только для исследования сети и сбора информации для обновления RT. Схема по изобретению использует пакеты данных для выполнения обеих задач. Указание того, как должны направляться новые пакеты данных, является новым: h процентов сообщений должны использовать скупую маршрутизацию, и (1-h) процентов сообщений – нормальную маршрутизацию. Таким образом, достигается как хорошая доставка, так и хорошее исследование сети, в то же время имеются малые потери, обусловленные использованием малого количества исключительно исследовательских пакетов. Если узел S потеряет соседа, он потеряет целый столбец в RT. Тогда узел S должен выполнить две задачи: (i) заново назначить веса в оставшихся столбцах в существующих строках, чтобы их сумма снова была равна единице. (ii) Добавить в таблицу новую строку, так как утраченный соседний узел становится новым узлом назначения. При отсутствии информации о том, каким образом найти этот утерянный соседний узел, узел S заполнит новую строку равными весами (как показано для узла назначения 4 в примере RT). Однако Способ по изобретению требует, чтобы S отправил пустые сообщения для поиска утерянного соседнего узла. Если узел S обнаруживает новый соседний узел (для этого имеются стандартные процедуры, не являющиеся частью настоящего изобретения), должен быть добавлен новый столбец (и, если новый соседний узел ранее был узлом назначения, удалить эту строку). Добавление нового столбца требует настройки каждой строки в RT. Кроме того, новый соседний узел (назовем его NN) нашел нового соседа S. Следовательно, оба узла должны обновить все строки в своих RT. Способ по изобретению предлагает новый и удачный метод получения информации от обоих узлов – нового соседнего узла NN и узла S – чтобы наилучшим образом использовать их совместную информацию о маршрутизации с использованием RQR. Все новые (и другие) возможности настоящего изобретения, описанные здесь, могут быть использованы в жестко соединенных сетях всегда, когда такие сети имеют удовлетворительные условия для динамической работы, такие как изменение схемы трафика, или изменение возможности подключения узлов или связей, так что предпочтительным является стохастическая маршрутизация. Имеется также важный случай, называемый «ячеистая (смешанная) сеть» (mesh network), которая является промежуточной между сетью с жесткими связями и специальными сетями. Смешанные сети используют маршрутизацию с множественными интервалами связи между беспроводными узлами, однако в общем случае узлы не являются мобильными. Вместо этого они зафиксированы в зданиях. Такие сети могут с преимуществом использовать алгоритмы, аналогичные используемым во временных сетях. Такие алгоритмы позволяют смешанным сетям разделяться с центральным управлением, даже позволяя узлам (например, в отдельных домах) входить или выходить из сети незапланированным образом. Таким образом, смешанные сети являются наиболее привлекательными, когда они поддерживают механизм самовосстановления, очень похожий на используемый в сетях AHN. Методы, описанные в данном изобретении, могут быть выгодно применены в смешанных сетях. Примерами компаний, предлагающих технологию смешанных сетей, являются MeshNetworks, SkyPilot, CoWave и Ember. Наиболее вероятно, что временная маршрутизация найдет наиболее широкое применение при использовании в комбинации с фиксированными сетями. Изолированные мобильные беспроводные сети вряд ли будут использоваться кроме специальных целей; однако беспроводная связь с множественными интервалами обещает стать полезным способом для расширения доступности и емкости фиксированных сетей с базовыми станциями. Таким образом, наиболее вероятное использование AHN будет включать в себя маршрутизацию от и к фиксированному узлу межсетевого интерфейса или базовой станции. В этом случае настоящее изобретение будет в этом случае полезным и почти наверняка будет в этом случае работать лучше, чем для «чистого» случая маршрутизации только между мобильными узлами в пределах AHN. Это происходит потому, что менее перспективным является прокладка маршрута к фиксированному узлу межсетевого интерфейса, чем к большому количеству мобильных абонентских номеров. Таким образом, фиксированная инфраструктура, расширенная на «границе» с помощью прокладки беспроводных маршрутов, которые в свою очередь используют стохастическую маршрутизацию, как описано здесь, является очень перспективным направлением для будущих телекоммуникационных систем. В таких ситуациях также многообещающим является маршрутизация, основанная на расположении. В случае, когда становится выгодной поддержка обеспечения информации о позиционировании в реальном времени, для дешевых мобильных компактных устройств, то такая информация должна для получения простейшей и наиболее надежной поддержки для маршрутизации с множественными интервалами связи в специальных сетях комбинироваться со стохастической маршрутизацией. Более точно, для достижения наиболее эффективной маршрутизации настоящее изобретение может быть скомбинировано с информацией о расположении.
Формула изобретения
1. Способ маршрутизации сообщений от узла (S) источника к узлу назначения в динамической сети, причем указанный узел источника содержит таблицу маршрутизации, каждая строка указанной таблицы маршрутизации представляет собой запись, относящуюся к возможному узлу (D) назначения для сообщений с данными, передаваемых от узла (S) источника, причем каждая строка указанной таблицы маршрутизации включает в себя по одному значению вероятности p(k,D) использования каждого узла (к), соседнего для узла (S) источника, для передачи информации от узла (S) источника к узлу (D) назначения, причем указанный способ включает в себя обновления значений вероятности в соответствии с измерениями качества выбираемого пути передачи сообщений, проводимыми всякий раз при посылке сообщения из узла (S) источника к узлу (D) назначения, отличающийся тем, что производят маршрутизацию заранее определенного процента сообщений путем выбора соседнего узла с наибольшим значением вероятности в строке для узла (D) назначения в таблице маршрутизации, а маршрутизация других сообщений выполняется среди соседних узлов в соответствии со значениями вероятности, приведенными в той же строке таблицы маршрутизации. 2. Способ по п.1, отличающийся тем, что значение вероятности использования конкретного узла (k), соседнего для узла (S) источника, для передачи информации от узла (S) источника к узлу (D) назначения, обновляют в соответствии со следующим выражением:
где 3. Способ по п.1 или 2, отличающийся тем, что меры качества выбираемого пути представлены интервалами связи и/или временными задержками. 4. Способ по п.1, отличающийся тем, что при обнаружении утраты соединения с соседним узлом для каждой строки таблицы маршрутизации узла удаляют значение вероятности для утраченного соседнего узла, а для остальных соседних узлов значения вероятностей регулируются таким образом, чтобы их сумма была равна единице, и создают новую строку таблицы маршрутизации для утраченного соседнего узла с назначением исходных равных значений вероятности для каждого из соответственно оставшихся соседних узлов, и настраивают значения вероятности в соответствии измерениями качества, выполненными сообщениями, посылаемыми из узла в направлении утраченного соседнего узла. 5. Способ по п.4, отличающийся тем, что значения вероятностей затем настраивают для восстановления относительных соотношений между оставшимися соседними узлами как до утраты соседнего узла. 6. Способ по п.4 или 5, отличающийся тем, что устанавливают период времени ожидания с момента обнаружения исчезновения соседнего узла до настройки существующих строк таблицы маршрутизации и создания новых строк таблицы маршрутизации. 7. Способ по п.6, отличающийся тем, что сообщения, выполняющие измерения качества путей и обновляющие таблицы маршрутизации, являются просто сообщениями с данными, а пустые сообщения специально передают после заранее определенных интервалов времени и в дальнейшем через равные интервалы времени исключительно для целей обнаружения утраченного соседнего узла. 8. Способ по п.1, отличающийся тем, что при обнаружении появления нового соседнего узла (j) для нового соседнего узла (j) и узла (S) источника вычисляют по одной оценке качества информации маршрутизации, содержащейся в таблице маршрутизации (RQR (D,J) и RQR (D,S)) для каждого возможного узла (D) назначения, и для всех возможных узлов (D) назначения вычисляют новое значение вероятности для нового соседнего узла (j) на основе оценки качества маршрутизации для соседнего узла (j) и узла (S) источника и связанных с ним соседних узлов. 9. Способ по п.8, отличающийся тем, что оценка качества маршрутизации равна максимальному значению вероятности минус минимальное значение вероятности. 10. Способ по п.9, отличающийся тем, что новое значение вероятности для нового соседнего узла (j) равно:
где х – оценка качества маршрутизации нового соседнего узла, y – оценка качества маршрутизации рассматриваемого узла, а n – количество соседних узлов перед получением нового соседнего узла.
|
||||||||||||||||||||||||||||||||||||||||
 мобильный и мобильный
мобильный и мобильный  98, Dallas, TX, USA, 1998.
98, Dallas, TX, USA, 1998. N то же, что и качество пути N
N то же, что и качество пути N . Пусть p(k,D) (старый) – вероятность в RT по направлению к узлу D через узел k перед обновлением. Тогда обновленное значение вычисляется по формуле
. Пусть p(k,D) (старый) – вероятность в RT по направлению к узлу D через узел k перед обновлением. Тогда обновленное значение вычисляется по формуле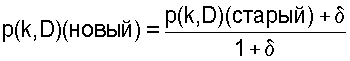
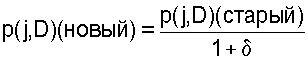
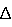 t (1) после обнаружения потери соседнего узла k. Если соединение с узлом k после этого времени не восстановится, и если узел j не пытается в течение этого времени посылать информацию к узлу k, то узел j должен выдать «пустое» сообщение, весь смысл которого заключается в получении информации для установления маршрута между j и k. RT в узле j для узла k исходно устанавливается с равными весами, когда все соседи узла j выбираются равновероятно для построения пути к узлу k. Следовательно, пустое сообщение, вырабатываемое узлом j, при поиске узла k выберет исходящих соседей j с равной вероятностью. Последующие узлы на пути будут иметь информацию о маршруте к k; здесь пустое сообщение выберет путь с наибольшим весом для следующего интервала связи на пути к k. Для симметричных связей для обновления RT (для узла j) может использоваться мера качества каждого узла по пути к узлу k (включая сам узел k). Как для симметричных, так и для асимметричных связей по достижении узла k пустое сообщение формирует высокоприоритетный маршрутизационный пакет, который возвращается в узел j с мерой качества и может быть использован для обновления RT в j для узла k. Если узел j не получил такого подтверждения, после (настраиваемого) интервала времени
t (1) после обнаружения потери соседнего узла k. Если соединение с узлом k после этого времени не восстановится, и если узел j не пытается в течение этого времени посылать информацию к узлу k, то узел j должен выдать «пустое» сообщение, весь смысл которого заключается в получении информации для установления маршрута между j и k. RT в узле j для узла k исходно устанавливается с равными весами, когда все соседи узла j выбираются равновероятно для построения пути к узлу k. Следовательно, пустое сообщение, вырабатываемое узлом j, при поиске узла k выберет исходящих соседей j с равной вероятностью. Последующие узлы на пути будут иметь информацию о маршруте к k; здесь пустое сообщение выберет путь с наибольшим весом для следующего интервала связи на пути к k. Для симметричных связей для обновления RT (для узла j) может использоваться мера качества каждого узла по пути к узлу k (включая сам узел k). Как для симметричных, так и для асимметричных связей по достижении узла k пустое сообщение формирует высокоприоритетный маршрутизационный пакет, который возвращается в узел j с мерой качества и может быть использован для обновления RT в j для узла k. Если узел j не получил такого подтверждения, после (настраиваемого) интервала времени