Патент на изобретение №2296376
|
||||||||||||||||||||||||||
(54) СПОСОБ РАСПОЗНАВАНИЯ СЛОВ РЕЧИ
(57) Реферат:
Изобретение относится к области анализа и распознавания речевых сигналов. Техническим результатом является повышение точности распознавания слов речи, достигаемый тем, что в процессе обучения системы распознаванию формируются эталонные биспектральные признаки фонем – положения максимумов модуля биспектра (ММБ) звукового сигнала и амплитуды ММБ звукового сигнала, а также эталонные признаки слов, представляющие собой совокупности усредненных временных отрезков от начала слова до начала и окончания всех фонем и пауз в слове, а в процессе распознавания речевой сигнал, соответствующий интервалу слова, разбивается на сегменты, в которых формируются биспектральные признаки – положения ММБ звукового сигнала и амплитуды ММБ звукового сигнала, сравниваемые с эталонными биспектральными признаками фонем в соответствии с первым и вторым критериями принятия решения. Из принятых в процессе сравнения решений о распознанных фонемах на всех сегментах формируются две последовательности решений о распознанных фонемах, из которых выделяются наиболее часто встречающиеся решения (буквенные коды фонем), формирующие набор буквенных кодов фонем распознаваемого слова. При сравнении набора буквенных кодов фонем распознаваемого слова с наборами буквенных кодов фонем всех слов словаря с учетом эталонных признаков слов формируется массив значений показателей распознавания, равных количеству совпадающих буквенных кодов фонем и кодов пауз и решение о распознавании слова принимается в пользу того слова словаря, при сравнении с которым получен максимальный показатель распознавания. 8 ил.
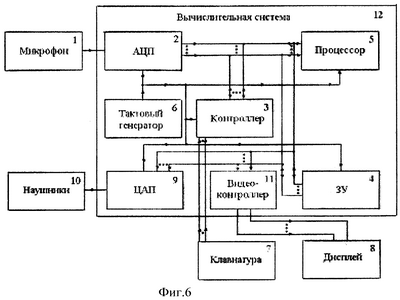
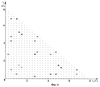
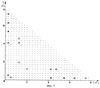
Изобретение относится к области анализа и распознавания речевых сигналов и касается способа распознавания слов речи. Известен способ распознавания слов речи [Патент ЕВП №420825, кл. G 10 L 5/06, опубликован в 1991 г.], основанный на определении и хранении для каждого слова в словаре фонетической модели, составленной из последовательности фонетических символов, соответствующих фонемам слова, определении и хранении характерных параметров (признаков), показывающих энергию и спектральный состав фонем, выборке звуковых сигналов, соответствующих каждому слову, произнесенному диктором, сравнении значений признаков для всех моделей словаря и выборке посредством алгоритма динамического программирования небольшого количества моделей – кандидатов. Известен также способ распознавания слов речи [Патент RU №2047912 кл. G 10 L 5/06, 7/06, опубликован в 1995 г.], основанный на предыскажении речевого сигнала во временной области при дифференцировании со сглаживанием, последовательной сегментации, кодировании сегментов, вычислении энергетического спектра, измерении формантных частот, классификации артикуляторных событий и состояний, формировании и сортировке эталонов слов, вычислении расстояний между эталоном и реализацией неизвестного слова, принятии решений о распознавании или отказе в распознавании. Недостатком данных способов является то, что используемое в них для формирования признаков фонем представление речевых сигналов в спектральной области с последующим выделением контура особенностей спектра (оценкой спектральной плотности мощности в различных частотных полосах, нахождением максимумов энергии спектра (измерением формантных частот)) не всегда обеспечивает высокую точность распознавания фонем, и, как следствие, слов речи, составленных из данных фонем. Наиболее близким к предлагаемому способу является способ распознавания слов речи, принятый за прототип, реализованный в системе распознавания речи в реальном времени на базе средств вычислительной техники [Патент US №4852170 кл. 381/41, опубликован в 1989 г.], базирующийся на представлении слов в виде последовательностей характерных сегментов, в целом соответствующих фонемам речи. Каждый сегмент описывается ограниченным набором признаков, а каждое слово описывается последовательностью таких сегментов. Для выделения признаков речевой сигнал, соответствующий сегменту (фонеме) речи, преобразуется в аналого-цифровом преобразователе (АЦП) в цифровые последовательности кодов, подвергаемые в анализаторе спектра спектральному анализу с помощью использования алгоритма быстрого преобразования Фурье (БПФ). В блоке обработки данных и управления формируются признаки – положения формантных частот и соотношения между ними, динамика изменения энергии спектра в специально подобранных частотных полосах. Процедура распознавания слов в данном способе основана на автоматической сегментации сигналов, соответствующих словам, на сегменты, соответствующие фонемам, формировании признаков сегментов слова, сравнении сформированных признаков сегментов слова с признаками эталонов фонем, либо классов фонем, хранящихся в памяти блока обработки данных и управления, в результате чего последовательно осуществляется отнесение распознаваемого сегмента к классу фонем, а затем идентифицируется конкретная фонема. Фонемы, полученные в результате распознавания сегментов слов речи, объединяются в последовательность фонем, которая с помощью алгоритма синтаксического и фонетического разбора фонем преобразуется в орфографически правильные слова речи. Недостатком данного способа является невысокая точность распознавания слов речи. Это обусловлено тем, что при распознавании слов в данном способе необходимо осуществлять автоматическую сегментацию распознаваемого слова на сегменты, соответствующие фонемам речи. Признаки фонем либо классов фонем, используемые для определения границ сегментов в словах, а также для последующего распознавания фонем, обладают недостаточной информативностью и формализованностью, как, например, “низкий” или “высокий” уровень амплитуды, “молчание”, что ведет к ошибкам в определении границ сегментов (фонем) и к формированию недостаточно достоверных эталонов фонем. Также при распознавании фонем используются признаки, полученные, исходя из описания изобретения, на основе анализа целого ряда речевых сигналов дикторов, включая мужчин, женщин и детей, однако являющие собой идеализированный случай, не всегда наблюдаемый при анализе реальных речевых сигналов. Таким образом, использование приведенных выше признаков фонем не обеспечивает высокую точность распознавания слов речи. Задачей изобретения является повышение точности распознавания слов речи. С целью решения задачи повышения точности распознавания слов речи в предлагаемом способе последовательно осуществляются два процесса: процесс обучения системы распознаванию и процесс распознавания слов речи, причем особенностью предлагаемого способа в процессе обучения является применение принципиально нового подхода к формированию эталонных признаков фонем речи, основанного на преобразовании речевых сигналов в биспектральную область, позволяющую извлекать дополнительную, существенно новую информацию из распознаваемых сигналов. Наряду с эталонными признаками фонем в процессе обучения системы распознаванию формируются эталонные признаки слов, представляющие собой усредненные длительности фонем и пауз в слове. Особенностью предлагаемого способа в процессе распознавания слов является то, что интервалы, соответствующие выделенным на фоне шума словам, разбиваются на сегменты стандартной длительности, меньшей длительности фонем, в каждом из сегментов формируются биспектральные признаки, которые сравниваются с эталонными признаками фонем с целью принятия решения о распознанной фонеме на каждом сегменте слова. Применение нового подхода, основанного на сравнении между собой решений (буквенных кодов распознанных фонем) на соседних сегментах слова в сформированных последовательностях решений о распознанных фонемах, позволяет сформировать набор буквенных кодов фонем распознаваемого слова, при этом исключается необходимость автоматического выделения границ фонем в словах. При сравнении сформированного набора буквенных кодов фонем распознаваемого слова с наборами буквенных кодов фонем слов словаря, используя эталонные признаки слов, формируется массив значений показателей распознавания, равных количеству совпадающих буквенных кодов и кодов пауз распознаваемого слова со словами из словаря. Решение о распознанном слове принимается в пользу того слова словаря, при сравнении с которым получен максимальный показатель распознавания. Вышеуказанные существенные признаки предлагаемого способа, связанные с совместным применением новых подходов в процессе обучения и в процессе распознавания, обеспечивают повышение точности распознавания слов речи. Задача изобретения достигается тем, что в способе распознавания слов речи последовательно осуществляются два процесса: процесс обучения системы распознаванию и процесс распознавания слов речи, причем в процессе обучения системы распознаванию осуществляется прием звуковых колебаний, соответствующих произнесенным словам речи (каждое произносится несколько раз) из определенного словаря (ограниченного набора слов), их преобразование в электрические сигналы в микрофоне, аналого-цифровое преобразование электрических сигналов в цифровые последовательности кодов, хранящиеся в запоминающем устройстве (ЗУ) вычислительной системы и преобразуемые к виду графических функций во времени, при анализе которых на дисплее оператор устанавливает границы фонем и пауз в составе слов речи, одновременно прослушивая в наушниках звуковые сигналы, соответствующие выделенным фонемам и паузам в словах. Оператор вводит набор буквенных кодов фонем и кодов пауз слов и номера дискретных временных отсчетов начала и окончания всех фонем и пауз в составе слов. После окончания произнесения, приема, накопления и разметки всех слов заданного словаря, участвующих в обучении системы распознаванию, формируются эталоны фонем. В вычислительной системе (см. фиг.6) по интервалам внутри выделенных границ фонем осуществляется обработка соответствующих цифровых последовательностей кодов, заключающаяся в формировании биспектральных признаков фонем – положений максимумов модуля биспектра и амплитуд максимумов модуля биспектра. Формирование биспектральных признаков основано на преобразовании цифровых последовательностей кодов в область биспектра, который, благодаря своим свойствам, обеспечивает более полное выделение информации из сигнала, что дает повышение точности при распознавании фонем и слов речи, составленных из данных фонем. Накапливая сформированные биспектральные признаки для одинаковых по буквенному коду фонем из разных слов, формируются эталоны фонем (совокупные матрицы биспектральных признаков). В вычислительной системе формируются эталонные признаки слов, представляющие собой совокупности усредненных значений временных отрезков от начала и окончания каждой из фонем и пауз, входящих в состав каждого из слов словаря. Так как каждое слово словаря произносится несколько раз, то усреднение значений эталонных признаков слов осуществляется при анализе одинаковых слов. В ЗУ вычислительной системы хранятся наборы буквенных кодов фонем, соответствующие каждому слову из заданного словаря, а также эталоны фонем и эталоны слов. В процессе распознавания слов речи осуществляется прием звуковых колебаний, соответствующих вновь произнесенным словам речи из того же словаря, на котором проводилось обучение системы распознаванию, их преобразование в электрические сигналы в микрофоне, аналого-цифровое преобразование электрических сигналов в цифровые последовательности кодов (ЦПК), хранящиеся в ЗУ вычислительной системы. При анализе ЦПК, соответствующих произнесенным словам речи, осуществляется выделение границ (начала и окончания) слов речи на фоне шума, а также пауз в составе слов речи. В рамках выделенных границ осуществляется разбивка выделенных интервалов слов речи на сегменты стандартной длительности, меньшей длительности фонем, причем начало каждого последующего сегмента расположено ранее окончания предыдущего сегмента. Длительность сегмента составляет 640 дискретных временных отсчетов, что соответствует временному интервалу 40 мс при частоте дискретизации 16 кГц. В каждом из сегментов слова формируются биспектральные признаки – положения ММБ и амплитуды ММБ, характеризующие речевой сигнал в сегменте. Сформированные биспектральные признаки сегментов слова сравниваются с эталонными биспектральными признаками фонем, полученными в процессе обучения системы распознаванию, с целью принятия решений о распознанной фонеме на каждом сегменте слова. Из полученных на каждом из сегментов слова решений о распознанных фонемах формируются две последовательности решений (в соответствии с первым и вторым критериями принятия решения, основанными соответственно на сравнении положений ММБ и амплитуд ММБ сегментов слова и эталонов фонем). При сравнении между собой буквенных кодов решений о распознанных фонемах на соседних сегментах слова в двух последовательностях решений выделяются наиболее часто встречающиеся решения, формирующие набор (цепочку) буквенных кодов фонем распознаваемого слова. Полученный набор сравнивается с наборами буквенных кодов фонем всех слов словаря с учетом эталонных признаков слов словаря, полученных в процессе обучения системы распознаванию. В результате сравнения формируется массив значений показателей распознавания, равных количеству совпадающих буквенных фонем и кодов пауз распознаваемого слова и каждого из слов словаря. То слово словаря, при сравнении с набором буквенных кодов фонем которого достигнут максимум числа совпадений буквенных кодов фонем и кодов пауз распознаваемого слова, считается распознанным. Изобретение поясняется чертежами, где на фиг.1 – 3 показаны примеры графических изображений массивов значений модулей биспектра фонем 3, А, X, из слова “ЗАХВАТ”. Массивы значений модуля биспектра в указанных примерах вычислены по предлагаемому способу, где оси х и у являются осями частот f1, f2, соответствующими исследуемому диапазону речи (0-8 кГц). На фиг.4 и 5 показаны эталоны фонем “А” и “З”, сформированные по предлагаемому способу и представляющие собой совокупные матрицы положений максимумов модуля биспектра с рассчитанными средними значениями амплитуд максимумов модуля биспектра в частотной плоскости f1, f2. На фиг.6 представлена функциональная схема устройства для реализации способа. Схема включает следующие элементы: 1. Микрофон – осуществляет прием звуковых колебаний, соответствующих словам речи, и преобразование их в электрические сигналы. 2. Аналого-цифровой преобразователь (АЦП) – преобразует электрические сигналы в цифровые последовательности кодов. 3. Контроллер – осуществляет управление информацией в вычислительной системе. 4. Запоминающее устройство (ЗУ) – накапливает и сохраняет информацию в виде цифровых последовательностей кодов, соответствующих словам, информацию о наборах буквенных кодов фонем и кодов пауз, соответствующих каждому слову из заданного словаря, эталоны фонем и эталоны слов, а также оперативную информацию, получаемую в процессе обучения системы распознаванию и в процессе распознавания слов речи. 5. Процессор – производит по программе необходимые преобразования и вычисления. 6. Тактовый генератор – производит синхронизацию работы АЦП, процессора, контроллера, ЗУ, цифроаналогового преобразователя (ЦАП). 7. Клавиатура – предназначена для ввода оператором информации по анализируемым и распознаваемым фонемам из слов речи. 8. Дисплей – производит отображение информации о фонемах и распознаваемых словах для оператора. 9. Цифроаналоговый преобразователь (ЦАП) – осуществляет преобразование цифровых последовательностей кодов, соответствующих фонемам речи, в электрические сигналы. 10. Наушники – преобразуют электрические сигналы в звуковые сигналы. 11. Видеоконтроллер – преобразует информацию в видеосигнал для отображения на дисплее. 12. Вычислительная система – включает в свой состав блоки 2, 3, 4, 5, 6, 9, 11, осуществляющие: прием и преобразование речевых сигналов, формирование биспектральных признаков фонем и признаков слов, формирование эталонов фонем и слов, хранение информации о фонемах и словах, передачу информации в другие блоки устройства, распознавание слов речи. На фиг.7 представлена рабочая схема процессов обучения системы распознаванию и распознавания слов речи. Внутри каждого из элементов схемы на фиг.7 приведены операции, выполняемые элементами функциональной схемы устройства для реализации способа, приведенного на фиг.6, и подробно раскрыты этапы процесса обучения системы распознаванию и процесса распознавания слов речи. На фиг.8 представлены результаты поэтапного распознавания слова “ЗАХВАТ”, осуществляемого в соответствии с предлагаемым способом. Предлагаемый способ осуществляется устойством в соответствии с фиг.6. В процессе обучения системы распознаванию производится прием звуковых колебаний, соответствующих произносимым диктором словам речи (каждое произносится несколько раз) из определенного словаря (ограниченного набора слов), их преобразование в электрические сигналы, осуществляемое микрофоном 1, затем электрические сигналы поступают в аналого-цифровой преобразователь (АЦП) 2, где осуществляется их преобразование в цифровые последовательности кодов, которые при управлении контроллера 3 вычислительной системы 12 передаются в запоминающее устройство (ЗУ) 4 для хранения и использования при последующей обработке в процессоре 5. Синхронизация работы АЦП 2, контроллера 3, ЗУ 4, цифроаналогового преобразователя (ЦАП) 9 и процессора 5 осуществляется тактовым генератором 6. Для обучения системы распознаванию слов речи создаются эталоны фонем, из которых состоят слова, с этой целью цифровые последовательности кодов, соответствующие произнесенным диктором словам, передаются из ЗУ 4 в процессор 5, где с помощью программы осуществляется их преобразование к виду графических функций во времени (фиг.7, поз.”а”), передаваемых через видеоконтроллер 11 на дисплей 8. Оператор, анализируя графическую функцию во времени, представленную на экране дисплея 8, соответствующую произнесенному слову, осуществляет ручную разметку, заключающуюся в установке границ всех фонем и пауз в слове путем перемещения с помощью клавиатуры 7 временных меток, ограничивающих на экране дисплея 8 определенный интервал слова. С целью уточнения установленных границ фонем и пауз в слове оператор одновременно прослушивает с помощью наушников 10 звуковой сигнал, соответствующий каждой из выделенных при видеоанализе фонем и пауз слова. Звуковые сигналы, соответствующие произнесенному слову, формируются путем передачи цифровой последовательности кодов из процессора 5 в ЦАП 9, где осуществляется преобразование цифровой последовательности кодов в электрические сигналы, преобразуемые в наушниках 10 в звуковые сигналы. Оператор вводит с помощью клавиатуры 7 набор буквенных кодов фонем и кодов пауз слова и номера дискретных временных отсчетов начала и окончания всех фонем и пауз в составе слова. Эта информация предается через контроллер 3 и накапливается в ЗУ 4. После окончания произнесения, приема, накопления и разметки всех слов заданного словаря, участвующих в обучении системы распознаванию, формируются эталоны фонем. Для формирования эталонов фонем процессором 5 по каждой фонеме на основании ее буквенного кода и номеров дискретных временных отсчетов, соответствующих выделенным интервалам фонемы, производится извлечение из ЗУ 4 цифровых последовательностей кодов, соответствующих реализациям данной фонемы во всех словах, произнесенных при обучении системы распознаванию. Далее в процессоре 5 с помощью алгоритма БПФ для цифровой последовательности кодов, соответствующей каждой реализации одной и той же фонемы из разных слов, вычисляется массив значений модуля спектра звукового сигнала |F(jf)|, где f – частота, соответствующая речевому диапазону 0-8 кГц, |S(f1, f2)|=|F[-j(f1+f2)]|·|F(jf1)|·|F(jf2)|, где f1, f2 – частоты, соответствующие исследуемому диапазону речевого сигнала (0-8 кГц с шагом дискретизации 125 Гц), причем в качестве значений модулей спектра звукового сигнала |F[-j(f1+f2)]|, |F(jf1)|, |F(jf2)| используются значения из ранее вычисленного массива значений модуля спектра звукового сигнала. В результате преобразования звуковых сигналов в биспектральную область, характеризующую взаимодействия между значениями компонентов Фурье на разных частотах в диапазоне речи, формируется массив значений модуля биспектра звукового сигнала. Биспектральная область графически изображается в трехмерном пространстве с взаимно перпендикулярными осями координат, причем осям абсцисс (х) и ординат (у) соответствуют оси частот f1 и f2, а по вертикальной оси апликат (z) в виде точек, соединенных между собой линиями, изображаются вычисленные значения модуля биспектра звукового сигнала, соответствующие дискретным точкам плоскости f1, f2. На фиг.1 – 3 показаны примеры графических изображений массивов значений модуля биспектра фонем З, А, X, из слова “ЗАХВАТ”, вычисленных по предлагаемому способу. Трехмерная система координат, используемая в приведенных графических примерах, полностью эквивалентна общепринятой системе координат. Каждая из фонем в приведенных примерах характеризуется индивидуальным расположением областей наличия значений максимумов модуля биспектра высокой интенсивности, в частности, как видно из фиг.1, фиг.2, фиг.3, для фонемы А характерно наличие значений максимумов модуля биспектра высокой интенсивности в области низких частот до 2 кГц, а для фонем З, Х – как в области низких частот, так и в области высоких частот, выше 4 кГц. Эти свойства используются в предлагаемом способе при распознавании фонем. В полученном массиве значений модуля биспектра звукового сигнала выделяются максимумы, затем определяются их положения в частотной плоскости f1, f2, и фиксируются амплитуды выделенных максимумов. Для одинаковых по буквенному коду фонем в процессоре 5 производится накопление биспектральных признаков – положений максимумов модуля биспектра (ММБ) и амплитуд ММБ в виде совокупной матрицы положений ММБ с рассчитанными средними значениями амплитуд ММБ в частотной плоскости f1, f2 (фиг.7, поз.”б”), эталоны фонем накапливаются и хранятся в ЗУ 4. На фиг.4 и 5 в частотной плоскости f1, f2 показаны эталоны фонем “А” и “З” в виде совокупных матриц положений ММБ с рассчитанными средними значениями амплитуд ММБ. Точками в частотной плоскости f1, f2 показаны положения вычисленных по формуле (1) значений модуля биспектра, совокупность которых образует массив значений модуля биспектра. Цифры в частотной плоскости f1, f2 являются средними значениями амплитуд максимумов модуля биспектра, а координаты f1, f2 цифровых значений являются положениями максимумов модуля биспектра, выделенных в массиве значений модуля биспектра. Анализ приведенных эталонов фонем показывает различие положений ММБ, а также различие значений амплитуд ММБ, которые для эталона фонемы “А” изменяются в диапазоне от 44 единиц в области частот выше 4 кГц до 76 единиц (максимальное значение) в области частот до 3 кГц, а для эталона фонемы “З” максимальные значения амплитуд ММБ изменяются в диапазоне от 5 единиц в области частот выше 4 кГц до 94-97 единиц (максимальные значения) в областях выше и ниже 4 кГц. Эти свойства являются основой для надежного разграничения эталонов фонем, что способствует повышению точности распознавания фонем и состоящих из них слов. Для формирования эталонов слов в процессоре 5 по каждому из слов словаря вычисляются усредненные значения начала и окончания всех фонем и пауз, полученных при анализе одинаковых слов (фиг.7, поз.”в”). Эта информация хранится в ЗУ 4. В процессе распознавания слов речи осуществляется прием звуковых колебаний, соответствующих вновь произнесенным тем же диктором словам из того же словаря, на котором проводилось обучение системы распознаванию, их преобразование в электрические сигналы, осуществляемое микрофоном 1, преобразование электрических сигналов в цифровые последовательности кодов (ЦПК) в аналого-цифровом преобразователе (АЦП) 2, передача ЦПК при управлении контроллера 3 вычислительной системы 12 в запоминающее устройство (ЗУ) 4 для хранения и последующей обработки в процессоре 5. В процессоре 5 ЦПК, соответствующие произнесенным словам и паузам до и после них, анализируются с целью выделения слов речи на фоне шума, а также выделения возможных пауз в составе слов (фиг.7, поз.”г”). Определение уровня шума до начала слова осуществляется путем расчета значений максимального разброса между экстремумами (МРЭ) сигнала на каждом из десяти, как минимум, начальных интервалов ЦПК (длительностью 128 отсчетов каждый) и расчета среднего значения МРЭ по десяти, как минимум, интервалам ЦПК. Определение начала слова производится при превышении порогового уровня шума значением МРЭ, полученным на каждом из десяти, как минимум, последующих смежных интервалов ЦПК (каждый длительностью 128 отсчетов), в противном случае производится переход к аналогичному анализу на десяти последующих интервалах, сдвинутых относительно предыдущих на один интервал длительностью 128 отсчетов. Пауза в составе слова фиксируется в случае, если значение МРЭ на отдельном интервале (длительностью 128 отсчетов) от начала слова и не более, чем на двадцати последующих за ним интервалах, ниже порогового значения уровня шума. Окончание слова фиксируется в случае, если более чем на двадцати последовательных интервалах значения МРЭ ниже порогового уровня шума. В процессоре 5 проводится разбивка выделенных интервалов слов на сегменты стандартной длительности (640 временных дискретных отсчетов, соответствующих интервалу времени 40 мс при частоте дискретизации 16 кГц), меньшей длительности фонем, причем начало каждого последующего сегмента расположено ранее окончания предыдущего сегмента (фиг.7, поз.”д”). На каждом из сегментов, следующих от зафиксированного начала слова, производятся следующие операции: вычисление массива значений модуля спектра звукового сигнала, вычисление массива значений модуля биспектра звукового сигнала, выделение ММБ, фиксация амплитуд ММБ и определение положений выделенных ММБ в частотной плоскости f1, f2 (фиг.7, поз.”е”). Далее в процессоре 5 производится сравнение биспектральных признаков – положений ММБ и амплитуд ММБ распознаваемого сегмента с биспектральными признаками – положениями ММБ и амплитудами ММБ каждого из эталонов фонем (фиг.7, поз.”ж”). Решение о распознавании фонемы (об отнесении распознаваемого сегмента к конкретному типу фонемы) принимается отдельно по первому критерию принятия решения, основанному на сравнении биспектральных признаков – положений ММБ, и по второму критерию принятия решения, основанному на сравнении биспектральных признаков – амплитуд ММБ (причем сравниваются только те амплитуды ММБ, которые соответствуют совпадающим по положению максимумам модуля биспектра распознаваемого сегмента и каждого из эталонов фонем): 1) первый критерий принятия решения – по отношению числа совпадающих по положению ММБ распознаваемого сегмента с ММБ каждого из эталонов фонем и общим числом ММБ каждого из эталонов фонем. Распознаваемый сегмент относится к тем двум типам фонем, при сравнении с эталонами которых получены максимальные значения этого отношения, из всех эталонов фонем, 2) второй критерий принятия решения – по отношению между числом совпадающих по положению ММБ распознаваемого сегмента с ММБ каждого из эталонов фонем и суммой разностей амплитуд совпадающих по положению ММБ распознаваемого сегмента и ММБ каждого из эталонов фонем. Распознаваемый сегмент относится к тем двум типам фонем, при сравнении с эталонами которых получены максимальные значения этого отношения, из всех эталонов фонем. Аналогичные описанным выше операции производятся в процессоре 5 по всем последовательным сегментам от начала до окончания слова, исключая паузы в слове. Сегменты имеют стандартную длительность 5 по 128 отсчетов, сдвиг между последовательно распознаваемыми сегментами равен 128 отсчетов. Таким образом, в результате распознавания фонем слова (отнесения распознаваемых сегментов слова к конкретному типу фонемы) формируются две (соответственно по первому и второму критериям принятия решения) последовательности решений (буквенных кодов фонем), к которым относятся распознаваемые сегменты слова (фиг.7, поз.”з”). В каждой из двух последовательностей решений по каждому сегменту слова имеется два решения (два буквенных кода фонем), имеющие наивысшие значения по первому и второму критериям среди всех эталонов фонем. Наличие двух решений в каждом сегменте последовательностей обеспечивает большую надежность при последующем выделении устойчивого набора буквенных кодов фонем распознаваемого слова. В сформированных последовательностях решений, полученных по всем сегментам распознаваемого слова, проводится сравнение между собой полученных буквенных кодов решений о распознанных фонемах на соседних сегментах слова для выделения из последовательностей решений устойчивого набора (цепочки) буквенных кодов фонем распознаваемого слова (фиг.7, поз.”и”). Сравнение буквенных кодов решений осуществляется следующим образом: полученные последовательности решений разбиваются на последовательные интервалы анализа, каждый из которых включает десять решений, полученных при применении признаков – положений ММБ и десять решений, полученных при применении признаков – амплитуд ММБ. В каждом из интервалов процессором 5 выбирается наиболее часто встречающийся буквенный код решения. Буквенный код решения, число появлении которого в рассматриваемом интервале в любой из последовательности решений выше или равно пороговому значению, записывается в результирующий набор буквенных кодов фонем распознаваемого слова. В сформированном наборе буквенных кодов фонем распознаваемого слова (фиг.7, поз.”к”) при наличии одинаковых по буквенному коду решений на смежных интервалах анализа производится их исключение в пользу решения, наиболее раннего от начала слова. Полученный набор буквенных кодов фонем распознаваемого слова сравнивается с наборами буквенных кодов фонем слов словаря (фиг.7, поз.”л”). В процессе сравнения, осуществляемого в процессоре 5, используется извлеченная из ЗУ 4 информация об эталонных признаках слов словаря, представляющих собой совокупности усредненных значений временных отрезков от начала слова до начала и окончания каждой из фонем и пауз, входящих в состав каждого из слов словаря. Каждый буквенный код фонемы и код паузы из набора буквенных кодов фонем каждого из слов словаря сравнивается с буквенным кодом фонемы и кодом паузы из набора буквенных кодов фонем распознаваемого слова, при этом сравниваются только те буквенные коды фонем и коды пауз, которые имеют одинаковое местоположение (в пределах порогового допуска (0,8÷1,2)) во временной области от начала слов (для этого используются эталонные длительности всех фонем и пауз от начала каждого из слов словаря, полученные в процессе обучения системы распознаванию). В случае совпадения буквенного кода фонемы или кода паузы распознаваемого слова с буквенным кодом фонемы или кодом паузы слова из словаря происходит накопление показателя распознавания для данного слова словаря. Формируется массив значений показателей распознавания, равных числу совпадающих буквенных кодов фонем и кодов пауз распознаваемого слова с каждым из слов словаря (фиг.7, поз.”м”). То слово из словаря, при сравнении с которым получен наибольший показатель распознавания, считается распознанным (фиг.7, поз.”н”). На фиг.8 представлены результаты поэтапного распознавания слова “ЗАХВАТ”, осуществляемого в соответствии с предлагаемым способом. На фиг.8 показаны: слово “ЗАХВАТ”, предъявленное к распознаванию, две последовательности решений о распознанных фонемах слова: первая последовательность решений о распознанных фонемах по положениям ММБ, вторая последовательность решений о распознанных фонемах по амплитудам ММБ. В каждой последовательности решений имеется две строки букв. Каждая пара вертикально расположенных букв в любой из последовательностей решений является двумя решениями о распознанных фонемах на одном сегменте слова, получившими два максимальных значения (верхняя буква – наивысшее значение, нижняя буква – следующее за ним меньшее значение) по первому критерию принятия решения (для первой последовательности решений) и по второму критерию принятия решения (для второй последовательности решений) при сравнении соответственно положений ММБ и амплитуд ММБ сегмента слова с положениями ММБ и амплитудами ММБ всех эталонов фонем. Слева направо в последовательностях решений представлены решения на всех сегментах от начала до окончания распознаваемого слова, границы которого выделены треугольниками. Точками до и после последовательностей решений показаны интервалы шума. Точками внутри последовательностей решений показаны сегменты, соответствующие зафиксированной паузе в слове. Ниже на фиг.8 представлен набор буквенных кодов фонем распознаваемого слова, который получен при сравнении между собой решений о распознанных фонемах на соседних сегментах слова, объединенных в последовательные интервалы в двух сформированных последовательностях решений, и выделении наиболее часто встречающихся решений. При сравнении данного набора с наборами буквенных кодов фонем каждого слова словаря с учетом эталонных признаков слов сформирован массив значений показателей распознавания, равных количеству совпадающих буквенных кодов фонем и кодов пауз распознаваемого слова и каждого слова словаря. В сформированном массиве выбран максимальный показатель распознавания, который равен максимальному числу совпадающих буквенных кодов фонем и кодов пауз слова из словаря и распознаваемого слова. В приведенном примере при сравнении набора буквенных кодов фонем распознаваемого слова с набором буквенных кодов фонем слова “ЗАХВАТ” из заданного словаря получен максимальный показатель распознавания Пр=6, что означает совпадение 5-ти буквенных кодов фонем З, А, X, В, А и кода паузы “.”, и дает основание для выбора данного слова словаря (“ЗАХВАТ”) в качестве распознанного слова. Распознанное слово и соответствующий ему максимальный показатель распознавания Пр приведены на фиг.8.
Формула изобретения
Способ распознавания слов речи, заключающийся в приеме звуковых колебаний, соответствующих словам речи, их преобразовании в электрические сигналы в микрофоне, в преобразовании электрических сигналов в цифровые последовательности кодов в аналого-цифровом преобразователе (АЦП), отличающийся тем, что в процессе обучения системы распознаванию цифровые последовательности кодов (ЦПК), полученные при аналого-цифровом преобразовании электрических сигналов, передают в соответствии с тактовыми импульсами, поступающими из тактового генератора, для хранения в запоминающее устройство (ЗУ) вычислительной системы, ЦПК из ЗУ передают в процессор, в процессоре преобразовывают цифровые последовательности кодов, соответствующие словам речи, в графические функции во времени, после чего передают графические функции во времени в видеоконтроллер для преобразования в видеосигнал и отображения на дисплее, из процессора ЦПК, соответствующие словам речи, передают в цифроаналоговый преобразователь (ЦАП), где ЦПК преобразовывают в электрические сигналы, в наушниках электрические сигналы преобразовывают в звуковые сигналы, оператор производит аудио и видео анализ графических функций во времени на дисплее и звуковых сигналов в наушниках с целью ручного выделения границ фонем и пауз в словах, ввод с помощью клавиатуры набора буквенных кодов фонем слов, кодов пауз слов и номеров дискретных отсчетов начала и окончания всех фонем и пауз в словах и передачу этой информации для хранения в ЗУ, в процессоре проводят обработку цифровых последовательностей кодов, соответствующих выделенным интервалам фонем, включающую вычисление массива значений модуля спектра звукового сигнала, определяемого по алгоритму быстрого преобразования Фурье, преобразующему цифровую последовательность кодов, соответствующую выделенному интервалу фонемы, в массив значений модуля спектра звукового сигнала |F(jf)|, где f – частота в речевом диапазоне, далее производят вычисление массива значений модуля биспектра звукового сигнала |S(f1, f2)| как произведения трех значений модуля спектра звукового сигнала по формуле |S(f1, f2)|=|F[-j(f1+f2)]|*|F(jf1)|*|F(jf2)|, где f1, f2 – частоты речевого диапазона, а в качестве значений модулей спектра звукового сигнала |F[-j(f1+f2)]|; |F(jf1)|, |F(jf2)| используют значения из ранее вычисленного массива значений модуля спектра звукового сигнала, при обработке массива значений модуля биспектра звукового сигнала выделяют максимумы модуля биспектра (ММБ) звукового сигнала, определяют положения ММБ в частотной плоскости f1, f2 и фиксируют амплитуды ММБ, затем операции вычисления массива значений модуля спектра звукового сигнала и вычисления массива значений модуля биспектра звукового сигнала, выделения ММБ, определения положений ММБ и фиксации амплитуд ММБ повторяют по всем одинаковым по буквенному коду фонемам из всех слов словаря, формируют эталонные биспектральные признаки фонем – положения ММБ и амплитуды ММБ, объединенные в единый эталон по каждой фонеме, представленный в виде совокупной матрицы положений ММБ с усредненными значениями амплитуд ММБ в частотной плоскости, в процессоре формируют эталоны слов, которые представляют собой совокупности усредненных значений временных отрезков от начала каждого слова до начала и окончания всех фонем и пауз в слове, полученные при анализе одинаковых слов словаря, в процессе распознавания слов осуществляют прием звуковых колебаний, соответствующих словам, преобразование звуковых колебаний в электрические сигналы в микрофоне, преобразование электрических сигналов в ЦПК в АЦП, передачу ЦПК при управлении контроллера вычислительной системы в ЗУ для хранения и обработки в процессоре, выделение в процессоре начала и окончания слов на фоне шума, а также пауз в словах и кодов пауз, в процессоре производят разбивку выделенных интервалов, соответствующих словам, на сегменты стандартной длительности, меньшей длительности фонем, причем начало каждого последующего сегмента расположено ранее окончания предыдущего сегмента, в процессоре на каждом из сегментов, следующих от зафиксированного начала слова, вычисляют массив значений модуля спектра звукового сигнала, вычисляют массив значений модуля биспектра звукового сигнала, выделяют максимумы модуля биспектра (ММБ), фиксируют амплитуды ММБ и определяют положения выделенных ММБ в частотной плоскости f1, f2, положения ММБ и амплитуды ММБ сегментов слова сравнивают соответственно с положениями ММБ и амплитудами ММБ каждого из эталонов фонем с целью принятия решения о распознанной фонеме, решение о распознанной фонеме на каждом сегменте слова принимают по двум критериям отдельно: по первому критерию принятия решения, основанному на сравнении биспектральных признаков – положений ММБ, и по второму критерию принятия решения, основанному на сравнении биспектральных признаков – амплитуд ММБ: первый критерий определяет максимум отношения числа совпадающих по положению ММБ распознаваемого сегмента слова с ММБ каждого из эталонов фонем к общему числу ММБ каждого из эталонов фонем, второй критерий определяет максимум отношения числа совпадающих по положению ММБ распознаваемого сегмента слова с ММБ каждого из эталонов фонем и суммой разностей амплитуд совпадающих по положению ММБ распознаваемого сегмента слова и ММБ каждого из эталонов фонем, в результате распознавания всех фонем слова формируют две последовательности решений, включающих по два буквенных кода решений о распознанных фонемах на каждом сегменте слова, имеющих наивысшие значения по первому и второму критериям, в процессоре путем сравнения между собой буквенных кодов решений на соседних сегментах, заключающегося в разбивке двух полученных последовательностей решений на интервалы стандартной длительности и выборе в них наиболее часто встречающегося буквенного кода решения, формируют набор буквенных кодов фонем распознаваемого слова, каждый буквенный код фонемы и код паузы из набора буквенных кодов фонем каждого из слов словаря, хранящихся в ЗУ, сравнивают в процессоре с буквенным кодом фонемы и кодом паузы из набора буквенных кодов фонем распознаваемого слова с учетом эталонных признаков слов, полученных в процессе обучения системы распознаванию, и по результатам сравнения формируют массив значений показателей распознавания, равных количеству совпадающих буквенных кодов фонем и кодов пауз распознаваемого слова со словами из словаря, решение о распознавании принимают в пользу того слова словаря, при сравнении с которым получают максимальный показатель распознавания.
РИСУНКИ
|
||||||||||||||||||||||||||