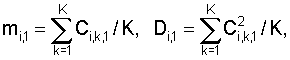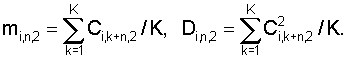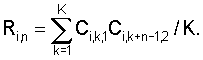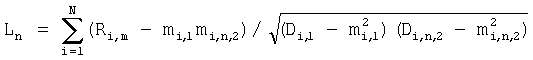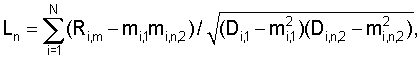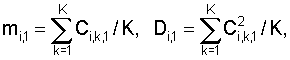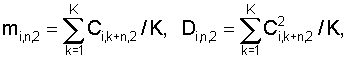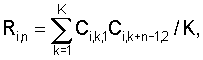Патент на изобретение №2295163
|
||||||||||||||||||||||||||
(54) СПОСОБ РАСПОЗНАВАНИЯ МУЗЫКАЛЬНЫХ ПРОИЗВЕДЕНИЙ И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ
(57) Реферат:
Изобретение относится к области информационных технологий – обработки аудио сигналов, в частности к способу распознавания музыкальных произведений и устройству для его осуществления. Технический результат состоит в быстрой и надежной идентификации музыкального произведения на основе обработки записи его фрагмента, за счет определения размера и качества полученной записи музыкального фрагмента, оригинального алгоритма поиска музыкального произведения, соответствующего записанному музыкальному фрагменту, при котором вычисляют множество величин Ln и определяют меру соответствия L музыкального произведения записанному музыкальному фрагменту как максимальное значение среди величин Ln, осуществляют поиск музыкального произведения из базы данных в Q этапов, при этом на каждом этапе выбирают множество музыкальных произведений с наибольшими мерами соответствия, по завершении последнего этапа поиска в качестве произведения, которому соответствует записанный фрагмент, выбирают музыкальное произведение, для которого получена максимальная мера соответствия, вычисляют меру надежности распознавания музыкального фрагмента r и сравнивают ее с порогом, если вычисленное значение меры надежности распознавания музыкального фрагмента превышает заданный порог, то записанное музыкальное произведение считают распознанным. 2 н. и 5 з.п. ф-лы, 7 ил.
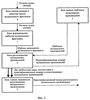
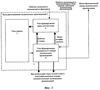
Изобретение относится к области информационных технологий – обработки аудиосигналов, в частности к способу распознавания музыкальных произведений и устройству для его осуществления. В современных системах обработки информации возникает необходимость автоматического распознавания музыкального произведения на основе анализа его фрагмента, который может быть искажен и зашумлен. В качестве примера можно привести задачу распознавания мелодии, записанной через микрофон мобильного телефона или портативного компьютера. Успешное решение такой задачи расширяет возможности операторов мобильной связи и поставщиков Интернет услуг по созданию средств быстрого поиска музыкальных произведений в удаленных базах данных большого размера. Для реализации системы распознавания необходимо решить две зависимые задачи. Во-первых, требуется найти параметры, которые позволили бы однозначно охарактеризовать музыкальное произведение или его фрагмент. Во-вторых, необходимо создать способ быстрого и надежного сравнения указанных параметров. Известен способ, предложенный в патенте US № 5918223 “Method and Article of Manufacture for Content-Based Analysis, Storage, Retrieval, and Segmentation of Audio Information”, G 06 F 17/30, в котором для формирования параметров, характеризующих музыкальное произведение, запись отсчетов аудиосигнала разбивают на блоки равной длительности. Для каждого блока находят громкость, основной тон, яркость, которая рассчитывается как взвешенная сумма модулей спектральных составляющих, оценку ширины полосы частот, параметр, характеризующий насыщенность низкими тонами, а также значения частотно-преобразованных кепстральных коэффициентов (в иностранной литературе они известны как “мел”-масштабированные кепстральные коэффициенты). На основе полученных временных последовательностей рассчитанных параметров вычисляют их производные. Находят средние значения и среднеквадратические отклонения найденных параметров и их производных. В результате средние и среднеквадратические значения образуют вектор, характеризующий музыкальное произведение. Для оценки соответствия одного музыкального произведения другому предлагается использовать евклидово расстояние между соответствующими векторами. Такой способ применим только в случае, когда распознаваемый музыкальный фрагмент является записью целого музыкального произведения. В противном случае может возникнуть ошибка распознавания, вызванная тем, что значения описанных параметров, вычисленные по целому произведению и его фрагменту, могут существенно отличаться. Для решения данной проблемы в патенте предлагается разбить музыкальное произведение большей длительности на несколько блоков, длительность которых равна длительности меньшего фрагмента. Затем вычислить все указанные выше характеристики для всех фрагментов и использовать их далее для сравнения. Такой подход имеет основной недостаток, заключенный в том, что длина записи распознаваемого фрагмента может быть не известна заранее, что не позволит рассчитать большое число необходимых характеристик для музыкальных произведений на этапе формирования базы данных. Следовательно, потребуется производить достаточно сложные вычисления в процессе поиска, что может существенно снизить его скорость. В опубликованных международных заявках WO 02/073520 А1 “A method and System for Acoustic Fingerprinting”, G 06 K 9/00, WO 2005/0322318 A2 “A method and System for Generating Acoustic Fingerprinting”, G 06 F, предлагаются способы идентификации аудиофайлов. В данных способах музыкальное произведение, записанное в аудиофайле, предлагается характеризовать вектором усредненных акустических характеристик, рассчитанных для нескольких фрагментов. В качестве таких характеристик используются значения среднего числа пересечений нулевого уровня аудиосигналом в каждом фрагменте, отношения среднего значения модуля отсчетов к среднему значению их среднеквадратических отклонений, средние значений изменений мощности сигнала, средние значения разности мощностей определенных спектральных компонент, число ударов в секунду, а также средние значения коэффициентов, полученных путем вейвлет преобразования в базисе Хаара. В указанных способах алгоритмы распознавания музыкальных произведений основаны на сравнении векторов перечисленных акустических характеристик. В частности, в международной заявке WO 02/073520 алгоритм определения соответствия двух музыкальных произведений заключается в вычислении взвешенной суммы модулей разности соответствующих элементов векторов и сравнении полученного значения с заданным порогом. Следует сказать, что предложенный способ более применим для систем, где требуется распознавание целых музыкальных произведений или музыкальных фрагментов достаточно большой длительности (при реализации в патентах предлагается использовать фрагменты длительностью несколько секунд). Только в этом случае можно утверждать, что усредненные акустические характеристики, полученные по фрагменту и целому одного и того же музыкального произведения достаточно близки. Кроме того, в описанных решениях не предложен способ оценки надежности распознавания музыкального произведения. Известны также способы распознавания музыкальных произведений, изложенные в опубликованных международных заявках WO 03/091990 “Robust and Invariant Audio Pattern Matching”, G 10 L 21/00 и WO 02/11123 “System and Methods for Recognizing Sound and Music Signals in High Noise and Distortion”, G 10 L 17/00. Основное отличие предложенных здесь решений от упомянутых выше заключается в том, что для описания музыкального произведения используются локальные характеристики, т.е. набор параметров, рассчитанных в характерных частотно-временных областях аудиосигнала. В частности, согласно международной заявке WO 03/091990 для получения параметров, описывающих музыкальное произведение или его фрагмент, строится его спектрограмма. На ней выделяются характерные локальные области, содержащие несколько пиков. Взаимное частотно-временное расположение пиков внутри области используется для ее характеристики. Алгоритм определения меры соответствия между двумя музыкальными произведениями состоит в вычислении числа областей с совпадающими или близкими характеристиками. В практических приложениях запись распознаваемого музыкального произведения может осуществляться при наличии нелинейных искажений, что может приводить к искажению существующих и появлению новых пиков на спектрограмме. Поэтому возникает снижение эффективности предложенного способа при наличии нелинейных искажений распознаваемого фрагмента. Наиболее близкими к заявляемому изобретению являются способ распознавания музыкальных произведений и устройство для его осуществления, предложенные в статье Jaap Haitsma and Ton Kalker. “A Highly Robust Audio Fingerprinting System”. Proceedings of ISMIR 2002, Paris, France, October 2002. В этой статье музыкальное произведение предлагается характеризовать временной последовательностью векторов, описывающей изменение акустических характеристик аудиосигнала. Процедура получения такой последовательности состоит из следующих основных этапов: – получают запись музыкального фрагмента, представленного в виде последовательности отсчетов аудиосигнала с заданной частотой дискретизации, – разбивают запись музыкального фрагмента на перекрывающиеся блоки данных заданной длины, – для каждого блока данных вычисляют коэффициенты, определяющие его акустические свойства, для чего: – выполняют спектральное взвешивание отсчетов блока данных, используя при этом оконную функцию, – осуществляют быстрое преобразование Фурье взвешенных отсчетов блока данных, получая спектральные составляющие блока данных, – вычисляют квадраты абсолютных значений спектральных составляющих блока данных, – выбирают диапазон частот для коэффициентов, определяющих акустические свойства блока данных, – разбивают выбранный частотный диапазон на интервалы в соответствии с логарифмической шкалой или шкалой Барк, – усредняют квадраты абсолютных значений спектральных составляющих блока данных на каждом интервале, – вычисляют коэффициенты F(n, m) по следующей формуле
где Е(n,m) – величина усредненных квадратов абсолютных значений спектральных составляющих на m-м интервале блока данных с номером n. Таким образом, получается последовательность векторов с бинарными элементами. Осуществляют процедуру распознавания путем сравнения шаблона записанного музыкального фрагмента и шаблонов музыкальных произведений, хранящихся в базе данных. В качестве меры различия шаблона записанного фрагмента и равной его длине части шаблона музыкального произведения из базы данных предлагается использовать значение среднего числа соответствующих не совпавших коэффициентов F(n, m). Для ускорения поиска предлагается сформировать кандидатский набор музыкальных произведений и производить вычисление мер различия только для шаблонов из этого набора. Формирование кандидатского набора осуществляется путем выбора в шаблоне записанного музыкального произведения одного из векторов и поиска музыкальных произведений, шаблон которых содержит такой же вектор. Эти музыкальные произведения и образуют кандидатский набор. Далее осуществляют процедуру проверки надежности распознавания музыкального фрагмента, которая основана на предположении, что шаблон записанного фрагмента содержит не искаженный вектор, положение которого известно. Это предположение в действительности не всегда верно, что может приводить к ошибкам формирования кандидатского набора. Осуществляют способ-прототип на устройстве, структурная схема которого для лучшего понимания выполнена функционально в укрупненном виде в соответствии с описанным алгоритмом на фиг.1. Устройство-прототип (фиг.1) содержит блок формирования шаблона музыкального фрагмента 1, блок распознавания музыкальных произведений 2 и базу данных шаблонов музыкальных произведений 3, при этом вход блока формирования шаблона музыкального фрагмента 1 является входом устройства, выход блока формирования шаблона музыкального фрагмента соединен с первым входом блока распознавания музыкальных произведений 2, второй вход и первый выход которого соединены соответственно со входом и выходом базы данных шаблонов музыкальных произведений, второй выход блока распознавания музыкальных произведений является выходом устройства. Работает устройство-прототип (фиг.1) следующим образом. Получают запись музыкального фрагмента, представленного в виде последовательности отсчетов аудиосигнала с заданной частотой дискретизации. Отсчеты аудиосигнала поступают на вход блока формирования шаблона музыкального фрагмента 1. В блоке 1 соответственно описанному в статье алгоритму разбивают запись музыкального фрагмента на перекрывающиеся блоки данных заданной длины, для каждого блока данных вычисляют коэффициенты, определяющие его акустические свойства, для чего выполняют спектральное взвешивание отсчетов блока данных, используя при этом оконную функцию, осуществляют быстрое преобразование Фурье взвешенных отсчетов блока данных, получая спектральные составляющие блока данных, вычисляют квадраты абсолютных значений спектральных составляющих блока данных, выбирают диапазон частот для коэффициентов, определяющих акустические свойства блока данных, разбивают выбранный частотный диапазон на интервалы в соответствии с логарифмической шкалой или шкалой Барк, усредняют квадраты абсолютных значений спектральных составляющих блока данных на каждом интервале, вычисляют коэффициенты F(n, m) по следующей формуле
где Е(n,m) – величина усредненных квадратов абсолютных значений спектральных составляющих на m-м интервале блока данных с номером n. Таким образом, получается последовательность векторов с бинарными элементами. Совокупность вычисленных коэффициентов для всех блоков данных музыкального фрагмента образует шаблон записанного музыкального фрагмента, который поступает на первый вход блока распознавания музыкальных произведений 2. Как и в большинстве известных работ, посвященных проблеме распознавания музыкальных произведений, в прототипе предлагается строить процедуру распознавания на основе сравнения шаблона записанного музыкального фрагмента и шаблонов музыкальных произведений, хранящихся в базе данных. В качестве меры различия шаблона записанного фрагмента и равной его длине части шаблона музыкального произведения из базы данных предлагается использовать значение среднего числа соответствующих не совпавших коэффициентов F(n, m). Для ускорения поиска предлагается сформировать кандидатский набор музыкальных произведений и производить вычисление мер различия только для шаблонов из этого набора. Формирование кандидатского набора осуществляется путем выбора в шаблоне записанного музыкального произведения одного из векторов и поиска музыкальных произведений, предварительно записанных, в базе данных шаблонов музыкальных произведений 3, шаблон которых содержит такой же вектор. Эти музыкальные произведения и образуют кандидатский набор. Одним из основных недостатков изложенного в прототипе способа является отсутствие процедур, позволяющих оценивать надежность распознавания музыкального фрагмента. Кроме того, описанная в прототипе процедура распознавания основана на предположении, что шаблон записанного фрагмента содержит не искаженный вектор, положение которого известно. Это предположение в действительности не всегда верно, что приводит к ошибкам формирования кандидатского набора. Задача, на решение которой направлено заявляемое изобретение, – это быстрая и надежная идентификация музыкального произведения на основе обработки записи его фрагмента. Задача решается тем, что в способ распознавания музыкальных произведений, заключающийся в том, что: получают запись музыкального фрагмента, представленного в виде последовательности отсчетов аудиосигнала с заданной частотой дискретизации, формируют шаблон музыкального произведения, разбивают запись музыкального фрагмента на блоки данных заданной длины, для каждого блока данных вычисляют коэффициенты, определяющие его акустические свойства, совокупность вычисленных коэффициентов для всех блоков данных музыкального фрагмента образует шаблон записанного музыкального фрагмента, осуществляют поиск музыкального произведения, соответствующего записанному музыкальному фрагменту путем сравнения сформированного шаблона записанного музыкального фрагмента и шаблонов музыкальных произведений, находящихся в базе данных, по завершении поиска выбирают музыкальное произведение, которому соответствует записанный фрагмент, согласно изобретению вводят следующую последовательность действий: определяют размер и качество полученной записи музыкального фрагмента, если размер и качество полученной записи музыкального фрагмента удовлетворяют заданным критериям размера и качества полученной записи музыкального фрагмента, то формируют шаблон записанного музыкального фрагмента, используя полученную последовательность отсчетов музыкального фрагмента, для чего осуществляют фильтрацию записи музыкального фрагмента, на блоки заданной длины разбивают отфильтрованную запись музыкального фрагмента, при поиске музыкального произведения, соответствующего записанному музыкальному фрагменту, для каждого шаблона музыкального произведения из базы данных вычисляют множество величин Ln по формуле
где N – выбранное число коэффициентов, описывающих акустические свойства блока данных, n=1…|K1-K2|+1, K1 и K2 – число блоков данных, использованных при формировании шаблона музыкального произведения в базе данных и шаблона записанного музыкального фрагмента, величины mi,1, Di,1 соответствуют шаблону, полученному с использованием меньшего числа блоков данных, и вычисляют по формулам
где Ci,k,1 – значение i-го коэффициента в k-м блоке шаблона, полученного с использованием меньшего числа блоков данных, K=min(K1, K2), величины mi,n,2, Di,n,2 соответствуют шаблону, полученному с использованием большего числа блоков данных, и вычисляются по формулам
где Ci,k,2 – значение i-го коэффициента в k-м блоке шаблона, полученного с использованием большего числа блоков данных, а коэффициент Ri,n вычисляется по формуле
Если число блоков данных, использованных при формировании шаблона музыкального произведения в базе данных и шаблона записанного музыкального фрагмента, совпадает, то величины mi,1, Di,1 вычисляют для шаблона записанного музыкального фрагмента, а величины mi,n,2, Di,n,2 вычисляют для шаблона музыкального произведения из базы данных или наоборот; определяют меру соответствия L музыкального произведения записанному музыкальному фрагменту как максимальное значение среди величин Ln; осуществляют поиск музыкального произведения из базы данных в Q этапов, где Q на каждом этапе выбирают множество из Еq по завершении последнего этапа поиска в качестве произведения, которому соответствует записанный фрагмент, выбирают музыкальное произведение, для которого получена максимальная мера соответствия; вычисляют меру надежности распознавания музыкального фрагмента r и сравнивают ее с заданным порогом, если вычисленное значение меры надежности распознавания превышает заданный порог, то записанное музыкальное произведение считают распознанным. При этом, например, в качестве размера полученной записи музыкального фрагмента используют временную длительность последовательности отсчетов аудиосигнала. Качество полученной записи музыкального фрагмента, например, определяют путем сравнения мощности записанного музыкального фрагмента с заданными, по меньшей мере, двумя порогами, определяющими диапазон допустимых значений. В качестве коэффициентов, определяющих акустические свойства блока данных, например, используют кепстральные коэффициенты или коэффициенты линейного предсказания, или значение средней мощности, или среднее число переходов через ноль, или любые их сочетания. Коэффициенты, определяющие акустические свойства блока данных, например, вычисляют, для чего: выполняют спектральное взвешивание отсчетов блока данных, используя при этом оконную функцию, осуществляют быстрое преобразование Фурье взвешенных отсчетов блока данных, получая спектральные составляющие блока данных, вычисляют абсолютные значения спектральных составляющих блока данных и вычисляют их логарифмы, выбирают диапазон частот для коэффициентов, определяющих акустические свойства блока данных, разбивают выбранный частотный диапазон на интервалы в соответствии с логарифмической шкалой или шкалой Барк, усредняют логарифмы абсолютных значений спектральных составляющих блока данных на каждом интервале, осуществляют дискретное косинусное преобразование полученных усредненных логарифмов абсолютных значений спектральных составляющих блока данных. Меру надежности распознавания музыкального фрагмента r, например, вычисляют по формуле: r=|L1-L2|/(L1+L2), где L1 и L2 – два максимальных значения мер соответствия, полученные на последнем этапе поиска. Задача решается также тем, что в устройство распознавания музыкальных произведений, содержащее блок формирования шаблона музыкального фрагмента, блок распознавания музыкальных произведений и базу данных шаблонов музыкальных произведений, при этом выход блока формирования шаблона музыкального фрагмента соединен с первым входом блока распознавания музыкальных произведений, первый выход и второй вход которого соединены соответственно со входом и выходом базы данных шаблонов музыкальных произведений, согласно изобретению введены: блок оценки размера и качества записи музыкального фрагмента, блок оценки надежности распознавания музыкального произведения, при этом вход блока оценки размера и качества записи музыкального фрагмента является входом устройства – входом отсчетов аудиосигнала, выход блока оценки размера и качества записи музыкального фрагмента соединен со входом блока формирования шаблона музыкального фрагмента, первый и второй входы блока оценки надежности распознавания музыкального произведения соединены соответственно со вторым и третьим выходами блока распознавания музыкальных произведений, формирующего на этих выходах две наибольшие меры соответствия и идентификационные номера соответствующих распознанных музыкальных произведений, выход блока оценки надежности распознавания музыкального произведения является выходом устройства, формирующего на выходе идентификационный номер распознанного музыкального произведения. Заявляемый способ по сравнению с известными техническими решениями в данной области техники позволяет быстрее и надежнее идентифицировать музыкальное произведение на основе обработки записи его фрагмента. Это достигается за счет определения размера и качества полученной записи музыкального фрагмента, оригинального алгоритма поиска музыкального произведения, соответствующего записанному музыкальному фрагменту, при котором вычисляют множество величин Ln и определяют меру соответствия L музыкального произведения записанному музыкальному фрагменту как максимальное значение среди величин Ln, осуществляют поиск музыкального произведения из базы данных в Q этапов, при этом на каждом этапе выбирают множество музыкальных произведений с наибольшими мерами соответствия, по завершении последнего этапа поиска в качестве произведения, которому соответствует записанный фрагмент, выбирают музыкальное произведение, для которого получена максимальная мера соответствия, вычисляют меру надежности распознавания музыкального фрагмента r и сравнивают ее с порогом, если вычисленное значение меры надежности распознавания музыкального фрагмента превышает заданный порог, то записанное музыкальное произведение считают распознанным. Технический эффект, заключающийся в быстрой и надежной идентификации музыкального произведения на основе обработки записи его фрагмента, достигается также заявляемым устройством. Для этого в устройство распознавания музыкальных произведений дополнительно введены блок оценки размера и качества записи музыкального фрагмента и блок оценки надежности распознавания музыкального произведения, а также, соответственно, новые связи между блоками. Кроме того, работа блока формирования шаблона музыкального фрагмента и блока распознавания музыкальных произведений построена по другим (отличным от прототипа) алгоритмам, которые в совокупности с новыми (введенными в устройство) блоками обеспечивают получение лучшего технического эффекта. Далее описание изобретения поясняется примерами выполнения и чертежами. На фиг.1 выполнена структурная схема устройства-прототипа. На фиг.2 – структурная схема заявляемого устройства распознавания музыкальных произведений. Фиг.3 иллюстрирует алгоритм работы блока оценки размера и качества записи музыкального фрагмента 4 для заявляемого устройства. Фиг.4 – алгоритм работы блока формирования шаблона 1. На фиг.5 выполнена структурная схема блока распознавания музыкальных произведений 2 для заявляемого устройства, приведена как пример выполнения. Фиг.6 иллюстрирует алгоритм работы узла формирования меры соответствия 6. Фиг.7 – алгоритм работы узла формирования кандидатского набора музыкальных произведений 8. Устройство распознавания музыкальных произведений (фиг.2) содержит блок оценки размера и качества записи музыкального фрагмента 4, блок формирования шаблона музыкального фрагмента 1, блок распознавания музыкальных произведений 2, базу данных шаблонов музыкальных произведений 3 и блок оценки надежности распознавания музыкального произведения 5, при этом вход блока оценки размера и качества записи музыкального фрагмента является входом устройства, выход блока оценки размера и качества записи музыкального фрагмента 4 соединен со входом блока формирования шаблона музыкального фрагмента 1, выход которого соединен с первым входом блока распознавания музыкальных произведений, первый выход и второй вход которого соединены соответственно со входом и выходом базы данных шаблонов музыкальных произведений, второй и третий выходы блока распознавания музыкальных произведений 2 соединены соответственно с первым и вторым входами блока оценки надежности распознавания музыкального произведения 5, выход которого является выходом устройства. Блок распознавания музыкальных произведений 2 (фиг.5) содержит узел формирования меры соответствия 6, узел памяти 7, хранящий меры соответствия и идентификационные номера музыкальных произведений из кандидатского набора, и узел формирования кандидатского набора музыкальных произведений 8, при этом первый вход узла формирования меры соответствия 6 является первым входом блока распознавания музыкальных произведений 2, выход узла формирования меры соответствия 6 соединен со входом узла памяти 7, выход которого соединен с первым входом узла формирования кандидатского набора музыкальных произведений 8, первый выход которого является первым выходом блока распознавания музыкальных произведений 2, второй вход узла формирования кандидатского набора музыкальных произведений 8 является вторым входом блока распознавания музыкальных произведений 2, второй и третий выходы узла формирования кандидатского набора музыкальных произведений 8 соединены соответственно со вторым и третьим входами узла формирования меры соответствия 6, четвертый и пятый выходы узла формирования кандидатского набора музыкальных произведений 8 являются соответственно вторым и третьим выходами блока распознавания музыкальных произведений 2. Осуществляют заявляемый способ распознавания музыкальных произведений в следующей последовательности. 1. Получают запись музыкального фрагмента, представленного в виде последовательности отсчетов аудиосигнала с заданной частотой дискретизации. 2. Определяют размер и качество полученной записи музыкального фрагмента. При этом, например, в качестве размера полученной записи музыкального фрагмента используют временную длительность последовательности отсчетов аудиосигнала, а качество полученной записи музыкального фрагмента определяют путем сравнения мощности записанного музыкального фрагмента с заданными, по меньшей мере, двумя порогами, определяющими диапазон допустимых значений. 3. Если размер и качество полученной записи музыкального фрагмента удовлетворяют заданным критериям размера и качества полученной записи музыкального фрагмента, то формируют шаблон записанного музыкального фрагмента, используя полученную последовательность отсчетов музыкального фрагмента, для чего: 3.1. Осуществляют фильтрацию записи музыкального фрагмента, 3.2. Разбивают отфильтрованную запись музыкального фрагмента на блоки данных заданной длины, 3.3. Для каждого блока данных вычисляют коэффициенты, определяющие его акустические свойства. При этом в качестве коэффициентов, определяющих акустические свойства блока данных, например, используют кепстральные коэффициенты или коэффициенты линейного предсказания, или значение средней мощности, или среднее число переходов через ноль, или любые их сочетания. Или коэффициенты, определяющие акустические свойства блока данных, вычисляют, для чего: – выполняют спектральное взвешивание отсчетов блока данных, используя при этом оконную функцию, – осуществляют быстрое преобразование Фурье взвешенных отсчетов блока данных, получая спектральные составляющие блока данных, – вычисляют абсолютные значения спектральных составляющих блока данных и вычисляют их логарифмы, – выбирают диапазон частот для коэффициентов, определяющих акустические свойства блока данных, – разбивают выбранный частотный диапазон на интервалы в соответствии с логарифмической шкалой или шкалой Барк, – усредняют логарифмы абсолютных значений спектральных составляющих блока данных на каждом интервале, – осуществляют дискретное косинусное преобразование полученных усредненных логарифмов абсолютных значений спектральных составляющих блока данных. 3.4. Совокупность вычисленных коэффициентов для всех блоков данных музыкального фрагмента образует шаблон записанного музыкального фрагмента. 4. Осуществляют поиск музыкального произведения, соответствующего записанному музыкальному фрагменту путем сравнения сформированного шаблона записанного музыкального фрагмента и шаблонов музыкальных произведений, находящихся в базе данных, для чего: 4.1. Для каждого шаблона музыкального произведения из базы данных вычисляют множество величин Ln по формуле
где N – выбранное число коэффициентов, описывающих акустические свойства блока данных, n=1…|K1-K2|+1, K1 и K2 – число блоков данных, использованных при формировании шаблона музыкального произведения в базе данных и шаблона записанного музыкального фрагмента, величины mi,1, Di,1 соответствуют шаблону, полученному с использованием меньшего числа блоков данных и вычисляются по формулам
где Сi,k,1 – значение i-го коэффициента в k-м блоке шаблона, полученного с использованием меньшего числа блоков данных, K=min(K1, K2), величины mi,n,2, Di,n,2 соответствуют шаблону, полученному с использованием большего числа блоков данных и вычисляются по формулам
где Ci,k,2 – значение i-го коэффициента в k-м блоке шаблона, полученного с использованием большего числа блоков данных, а коэффициент Ri,n вычисляется по формуле
Если число блоков данных, использованных при формировании шаблона музыкального произведения в базе данных и шаблона записанного музыкального фрагмента, совпадают, то величины mi,1, Di,1 вычисляют для шаблона записанного музыкального фрагмента, а величины mi,n,2, Di,n,2 вычисляют для шаблона музыкального произведения из базы данных или наоборот. 4.2. Определяют меру соответствия L музыкального произведения записанному музыкальному фрагменту как максимальное значение среди величин Ln. 5. Осуществляют поиск музыкального произведения из базы данных в Q этапов, где Q 5.1. На каждом этапе выбирают множество из Еq 5.2. По завершении последнего этапа поиска в качестве произведения, которому соответствует записанный фрагмент, выбирают музыкальное произведение, для которого получена максимальная мера соответствия. 6. Вычисляют меру надежности распознавания музыкального фрагмента r и сравнивают ее с заданным порогом, если вычисленное значение меры надежности распознавания музыкального фрагмента r превышает заданный порог, то записанное музыкальное произведение считают распознанным. Меру надежности распознавания музыкального фрагмента r, например, вычисляют по формуле: r=|L1-L2|/(L1+L2), где L1 и L2 – два максимальных значения мер соответствия, полученных на последнем этапе поиска. Для лучшего понимания рассмотрим реализацию заявляемого способа распознавания музыкальных произведений на устройстве, структурная схема которого выполнена на фиг.2, а также последовательно рассмотрим работу блоков, входящих в структурную схему устройства, их алгоритмы иллюстрируют фиг.3-7. Предположим, что получена запись музыкального фрагмента в виде последовательности отсчетов аудиосигнала с заданной частотой дискретизации. Например, при реализации заявляемого способа фрагменты распознаваемых музыкальных произведений записывались через микрофон мобильного телефона с частотой дискретизации 8 кГц. Перед началом процедуры распознавания осуществляется предварительная оценка качества музыкального фрагмента в блоке 4. Цель этой процедуры состоит в повышении надежности распознавания в целом за счет отказа от обработки заведомо плохо записанных музыкальных фрагментов. Для предварительной оценки качества записи можно использовать, например, длительность и среднюю мощность аудиосигнала. Пример процедуры, использующей эти параметры, представлен на фиг.3, где предлагается считать качество записи неудовлетворительным, если длительность фрагмента меньше заданной величины Т, а также если средняя мощность аудиосигнала меньше порога Hmin или превышает порог Нmax. Если качество полученной записи признано удовлетворительным, то отсчеты аудиосигнала поступают в блок формирования шаблона музыкального фрагмента 1. Алгоритм работы этого блока представлен на фиг.4. Согласно приведенному алгоритму на начальном этапе формирования шаблона осуществляется предварительная фильтрация полученного аудиосигнала с целью частичного подавления низких частот, что позволяет добиться более равномерного спектра сигнала. Для этой цели обычно используют простой цифровой фильтр высоких частот первого порядка, системная функция которого имеет вид [L.Rabiner, В.-Н.Juang “Fundamentals of Speech Recognition”. – Prentice Hall, New Jersey, 1993, 507 р.] H(z)=1-az-1, 0.9 Далее осуществляют разбиение профильтрованной последовательности отсчетов аудиосигнала на блоки равного размера, которые в общем случае могут перекрываться или, наоборот, отстоять на определенном расстоянии. Обычно в системах распознавания музыкальных произведений используют перекрывающиеся блоки достаточно большего размера. Так, например, в прототипе предлагается использовать блоки размера 2048 отсчетов с коэффициентом перекрытия 31/32. В отличие от общепринятого способа реализации разбиения на блоки в заявляемом способе рекомендуется использовать неперекрывающиеся блоки небольшого размера. Например, с успехом могут быть использованы блоки размером 128 отсчетов, взятые с интервалом 1024 отсчета. С одной стороны, такой подход позволяет существенно снизить объем вычислений, необходимых при формировании шаблонов и их сравнении, а с другой стороны, в сочетании с заявляемым способом сравнения шаблонов музыкальных произведений позволяет обеспечить достаточно высокую надежность распознавания. Для каждого блока вычисляют набор коэффициентов, определяющих его акустические свойства. В качестве таких коэффициентов, например, могут быть использованы кепстральные коэффициенты или коэффициенты линейного предсказания [L.Rabiner, В.-Н.Juang “Fundamentals of Speech Recognition”, Prentice Hall, New Jersey, 1993, 507 p.], или значение средней мощности, или среднее число переходов через ноль, или любые их сочетания. При реализации заявляемого способа для описания акустических характеристик блоков данных предлагается использовать частотно-преобразованные кепстральные коэффициенты [В.Logan, “Mel frequency cepstral coefficients for music modeling,” in Proc. International Symposium on Music Information Retrieval, Plymouth, MA, October 2000]. Порядок их вычисления также приведен на фиг.4 и состоит из следующих этапов: – Осуществляют спектральное взвешивание отсчетов сигнала x(l) в каждом блоке. Для этого находят произведение отсчетов сигнала и значений оконной функции w(l) y(l)=w(l)x(l) В качестве w(l) можно выбрать, например, функцию Хэмминга [С.Л.Марпл-мл. Цифровой спектральный анализ и его приложения. М.: Мир, 1990] w(l)=0.54+0.46cos(2 где Т – число отсчетов в блоке. – Вычисляют быстрое преобразование Фурье взвешенных отсчетов y(j) аудиосигнала в каждом блоке. – Вычисляют логарифмы абсолютных значений спектральных составляющих. – Выбирают частотный диапазон для анализа. Например, при частоте дискретизации 8 кГц интервал анализа может быть выбран от 300 Гц до 4 кГц. – Выбранный частотный диапазон разбивают на J интервалов неодинакового размера в соответствии со шкалой “мел” или Барк [L.Rabiner, B.-H.Juang “Fundamentals of Speech Recognition”, Prentice Hall, New Jersey, 1993, 507 p.]. Обычно оказывается достаточным разбить на 8-16 интервалов. – Внутри каждого частотного интервала вычисляется среднее значение логарифма модуля спектрального отсчета. – Осуществляют дискретное косинусное преобразование от вычисленных средних значений [Н.Ахмед, К.Р.Рао “Ортогональные преобразования при обработке цифровых сигналов”, М.: Связь, 1980, 248 с.]. Полученные в результате дискретного косинусного преобразования коэффициенты образуют вектор значений, характеризующий акустические свойства блока данных. Совокупность вычисленных коэффициентов (векторов), полученных для различных блоков данных музыкального фрагмента, образует его шаблон. Шаблон записанного музыкального фрагмента с выхода блока 1 поступает на первый вход блока распознавания музыкальных произведений 2, который включает следующие составные элементы (см. фиг.5): узел формирования меры соответствия 6, узел памяти 7 и узел формирования кандидатского набора музыкальных произведений 8. В узле формирования меры соответствия 6 осуществляют сравнение шаблона записанного музыкального фрагмента, поступающего на первый вход этого узла, и шаблона музыкального произведения, поступающего на его второй вход вместе с его идентификационным номером. Результатом сравнения является вычисленная мера соответствия, которая с выхода узла 6 поступает на вход узла памяти 7. Процедура вычисления меры соответствия показана на фиг.6. Она состоит из следующих этапов. Определяют, какой из сравниваемых шаблонов имеет меньший размер, т.е. получен на основе обработки меньшего числа блоков данных. Для него находят среднее значение и среднее значение квадрата коэффициентов по формулам
где Сi,k,1 – значение i-го коэффициента в k-м блоке шаблона, полученного с использованием меньшего числа блоков данных; K=min(K1, K2), K1 и K2 – число блоков данных, использованных при формировании шаблона в базе данных и шаблона записанного музыкального фрагмента. Затем для шаблона большего размера в скользящем окне размера K вычисляют среднее значение и среднее значение квадратов коэффициентов шаблона большего размера, т.е. для всех n=1…|K1-K2|+1 находят
Кроме того, в скользящем окне вычисляют
После этого находят множество величин
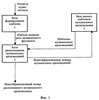
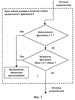
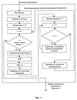
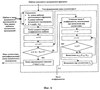
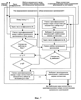
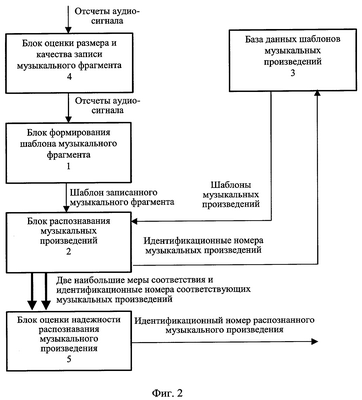
и находят максимальное из них L=max(L1,…,Ln). Это значение используют как меру соответствия распознаваемого фрагмента и музыкального произведения из базы данных. Основной задачей узла формирования кандидатского набора музыкальных произведений 8 (фиг.5) является планирование многоэтапной процедуры поиска, которое заключается в формировании кандидатского набора музыкальных произведений и определении параметров сравнения на каждом этапе. Процедуру формирования кандидатского набора иллюстрирует фиг.7. Узел памяти 7 (фиг.5) хранит значения мер соответствия для музыкальных произведений кандидатского набора. Работает блок распознавания музыкальных произведений 2 следующим образом (см. фиг.5-7). Предположим, что шаблон музыкального фрагмента сформирован и поступил на первый вход узла формирования меры соответствия 6. На первом этапе распознавания в узле формирования кандидатского набора музыкальных произведений в кандидатский набор включаются все произведения, хранящиеся в базе данных (E1 равно числу всех произведений в базе). Для ускорения процедуры распознавания выбирают число М1 коэффициентов, которое должно быть использовано при сравнении шаблонов на первом этапе, причем 1 где Z число вычисленных коэффициентов, акустические свойства блока данных. Например, вначале сравнение может осуществляться только по первым 4-6 коэффициентам (из сформированных 8-12). Это число коэффициентов поступает с третьего выхода узла 8 на третий вход узла формирования меры соответствия 6. Далее производится вычисление мер соответствия для всех произведений в базе данных шаблонов музыкальных произведений 3 в следующей последовательности. Узел 8 выбирает очередной идентификационный номер из кандидатского набора и с первого выхода подает содержащий его запрос на вход базы данных шаблонов музыкальных произведений 3. На второй вход узла 8 поступает шаблон соответствующего музыкального произведения (с выхода базы данных шаблонов музыкальных произведений 3), который вместе с идентификационным номером поступает со второго выхода этого узла на второй вход узла 6. В узле 6 вычисляют меры соответствия между этим музыкальным произведением и записанным (распознаваемым) музыкальным фрагментом. Полученная мера соответствия и идентификационный номер музыкального произведения поступают с выхода узла 6 на вход узла памяти 7. Описанную процедуру повторяют до тех пор, пока не будут получены меры соответствия для всех произведений из кандидатского набора. На этом первый этап процедуры распознавания завершается. Второй этап начинается с того, что меры соответствия и идентификационные номера с выхода узла памяти 7 поступают на первый вход узла 8. Далее формируется кандидатский набор, содержащий Е2 В блоке оценки надежности распознавания музыкального произведения 5 вычисляют меру надежности распознавания музыкального фрагмента r и сравнивают ее с заданным порогом h. Если вычисленное значение меры надежности распознавания музыкального фрагмента r превышает этот порог, то записанный музыкальный фрагмент считают распознанным. При этом считают, что распознано музыкальное произведение, для которого мера соответствия максимальна. Меру надежности распознавания r, например, вычисляют по формуле: r=|Lmax1-Lmax2|/(Lmax1+Lmax2). Значение порога h получено и оптимизировано по результатам проведения испытаний предлагаемого способа. Таким образом, на выходе блок 5 формирует идентификационный номер надежно распознанного музыкального произведения. Поэтому заявляемый способ и устройство для его осуществления по сравнению с известными техническими решениями в данной области техники позволяют быстрее и надежнее идентифицировать музыкальное произведение на основе обработки записи его фрагмента.
Формула изобретения
1. Способ распознавания музыкальных произведений, заключающийся в том, что получают запись музыкального фрагмента, представленного в виде последовательности отсчетов аудиосигнала с заданной частотой дискретизации, формируют шаблон музыкального произведения, разбивают запись музыкального фрагмента на блоки данных заданной длины, для каждого блока данных вычисляют коэффициенты, определяющие его акустические свойства, совокупность вычисленных коэффициентов для всех блоков данных музыкального фрагмента образует шаблон записанного музыкального фрагмента, осуществляют поиск музыкального произведения, соответствующего записанному музыкальному фрагменту путем сравнения сформированного шаблона записанного музыкального фрагмента и шаблонов музыкальных произведений, находящихся в базе данных, по завершении поиска выбирают музыкальное произведение, которому соответствует записанный фрагмент, отличающийся тем, что определяют размер и качество полученной записи музыкального фрагмента, если размер и качество полученной записи музыкального фрагмента удовлетворяют заданным критериям размера и качества полученной записи музыкального фрагмента, то формируют шаблон записанного музыкального фрагмента, используя полученную последовательность отсчетов музыкального фрагмента, для чего осуществляют фильтрацию записи музыкального фрагмента, на блоки заданной длины разбивают отфильтрованную запись музыкального фрагмента, при поиске музыкального произведения, соответствующего записанному музыкальному фрагменту, для каждого шаблона музыкального произведения из базы данных вычисляют множество величин Ln по формуле
где N – выбранное число коэффициентов, описывающих акустические свойства блока данных; n=1…|K1-K2|+1, K1 и K2 – число блоков данных, использованных при формировании шаблона музыкального произведения в базе данных и шаблона записанного музыкального фрагмента; величины mi,1, Di,1, соответствуют шаблону, полученному с использованием меньшего числа блоков данных, и вычисляют по формулам
где Сi,k,1 – значение i-го коэффициента в k-м блоке шаблона, полученного с использованием меньшего числа блоков данных, K=min(K1, K2); величины mi,n,2, Di,n,2 соответствуют шаблону, полученному с использованием большего числа блоков данных, и вычисляются по формулам
где Ci,k,2 – значение i-го коэффициента в k-м блоке шаблона, полученного с использованием большего числа блоков данных; коэффициент Ri,n вычисляют по формуле
если число блоков данных, использованных при формировании шаблона музыкального произведения в базе данных и шаблона записанного музыкального фрагмента совпадают, то величины mi,1, Di,1 вычисляют для шаблона записанного музыкального фрагмента, а величины mi,n,2, Di,n,2 вычисляют для шаблона музыкального произведения из базы данных или наоборот; определяют меру соответствия L музыкального произведения записанному музыкальному фрагменту, как максимальное значение среди величин Ln; осуществляют поиск музыкального произведения из базы данных в Q этапов, где Q 2. Способ по п.1, отличающийся тем, что в качестве размера полученной записи музыкального фрагмента используют временную длительность последовательности отсчетов аудиосигнала. 3. Способ по п.1, отличающийся тем, что качество полученной записи музыкального фрагмента определяют путем сравнения мощности записанного музыкального фрагмента с заданными, по меньшей мере, двумя порогами, определяющими диапазон допустимых значений. 4. Способ по п.1, отличающийся тем, что в качестве коэффициентов, определяющих акустические свойства блока данных, используют кепстральные коэффициенты, или коэффициенты линейного предсказания, или значение средней мощности, или среднее число переходов через ноль, или любые их сочетания. 5. Способ по п.1, отличающийся тем, что коэффициенты, определяющие акустические свойства блока данных, вычисляют, для чего выполняют спектральное взвешивание отсчетов блока данных, используя при этом оконную функцию, осуществляют быстрое преобразование Фурье взвешенных отсчетов блока данных, получая спектральные составляющие блока данных, вычисляют абсолютные значения спектральных составляющих блока данных и вычисляют их логарифмы, выбирают диапазон частот для коэффициентов, определяющих акустические свойства блока данных, разбивают выбранный частотный диапазон на интервалы в соответствии с логарифмической шкалой или шкалой Барк, усредняют логарифмы абсолютных значений спектральных составляющих блока данных на каждом интервале, осуществляют дискретное косинусное преобразование полученных усредненных логарифмов абсолютных значений спектральных составляющих блока данных. 6. Способ по п.1, отличающийся тем, что меру надежности распознавания музыкального фрагмента r вычисляют по формуле r=|L1-L2|/(L1+L2), где L1 и L2 – два максимальных значения мер соответствия, полученных на последнем этапе поиска. 7. Устройство распознавания музыкальных произведений, содержащее блок формирования шаблона музыкального фрагмента, блок распознавания музыкальных произведений и базу данных шаблонов музыкальных произведений, при этом выход блока формирования шаблона музыкального фрагмента соединен с первым входом блока распознавания музыкальных произведений, первый выход и второй вход которого соединены соответственно со входом и выходом базы данных шаблонов музыкальных произведений, отличающееся тем, что введены блок оценки размера и качества записи музыкального фрагмента и блок оценки надежности распознавания музыкального произведения, при этом вход блока оценки размера и качества записи музыкального фрагмента является входом устройства – входом отсчетов аудиосигнала, выход блока оценки размера и качества записи музыкального фрагмента соединен со входом блока формирования шаблона музыкального фрагмента, первый и второй входы блока оценки надежности распознавания музыкального произведения соединены соответственно со вторым и третьим выходами блока распознавания музыкальных произведений, формирующего на этих выходах две наибольшие меры соответствия и идентификационные номера соответствующих распознанных музыкальных произведений, выход блока оценки надежности распознавания музыкального произведения является выходом устройства, формирующего на выходе идентификационный номер распознанного музыкального произведения.
РИСУНКИ
|
||||||||||||||||||||||||||
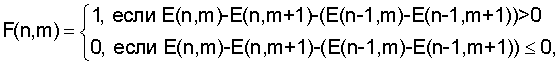
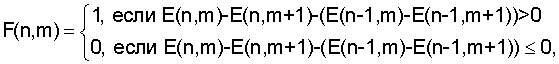
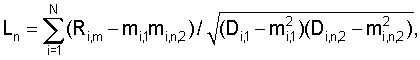
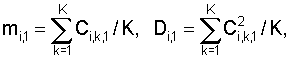
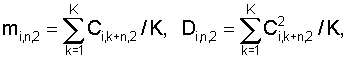
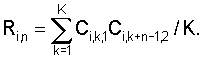
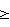 1, при этом
1, при этом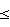 Q – номер этапа, причем на каждом этапе, кроме первого, Еq<Еq-1, при этом для вычисления мер соответствия используют Мq вычисленных коэффициентов, описывающих акустические свойства блока данных, где 1
Q – номер этапа, причем на каждом этапе, кроме первого, Еq<Еq-1, при этом для вычисления мер соответствия используют Мq вычисленных коэффициентов, описывающих акустические свойства блока данных, где 1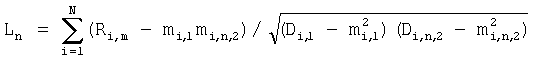
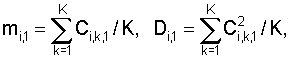
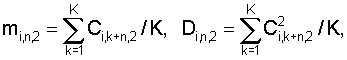
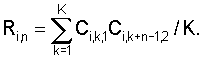
 [(l-[T-1]/2)/(T-1)]), 0
[(l-[T-1]/2)/(T-1)]), 0