Патент на изобретение №2295154
|
||||||||||||||||||||||||||
(54) СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТОВОЙ ИНФОРМАЦИИ ИЗ ГРАФИЧЕСКОГО ФАЙЛА С ИСПОЛЬЗОВАНИЕМ СЛОВАРЕЙ И ДОПОЛНИТЕЛЬНЫХ ДАННЫХ
(57) Реферат:
Изобретение относиться к области техники распознавания текстовой информации из графического файла. Технический результат изобретения заключается в повышении точности распознавания текста и повышении помехозащищенности распознавания текста. Технический результат достигается за счет того, что предварительно задают порядок обращения к дополнительной информации, назначают оценку качества для каждого вида дополнительной информации, строят различные варианты разбиения изображения выделенных строк на фрагменты, для каждого фрагмента строки строят граф линейного деления, распознают изображения графических элементов, используя классификатор, и каждому варианту распознавания присваивают оценку, выполняют переход от вариантов распознавания графем к вариантам символов алфавита, для каждой цепочки, соединяющей начальную и конечную вершины, строят цепочки, соответствующие всем вариантам распознавания графем и вариантам переходов от распознанных графем к символам алфавита, ранжируют полученные варианты в порядке уменьшения оценки качества распознавания, обрабатывают полученные варианты с привлечением информации о расположении заглавных и строчных букв, если имеются более одного варианта символа по результатам распознавания графического элемента, их обрабатывают с последовательным привлечением дополнительной информации, и/или при необходимости одновременным привлечением всех видов дополнительной информации, каждому полученному варианту назначают оценку качества, варианты символов, имеющие оценку ниже предварительно заданной, отбрасывают, полученные варианты сортируют, используя попарное сравнение, производят дополнительную коррекцию распознавания пробелов, ошибочно распознанных на предыдущих этапах. 8 з.п. ф-лы, 2 ил.
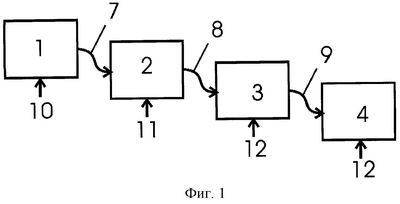
Изобретение относится к распознаванию образов из графического изображения, и в частности к распознаванию текста на изображении документа в электронном виде. Известны способы предварительной обработки графических изображений, состоящие в разбиении изображения на области, предположительно составляющие абзацы, строки, слова, отдельные символы. Изобретение относится к обработке изображений символов, распознаванию групп символов, слов, групп слов и т.д. с использованием дополнительной информации. Используемые термины. Вариант распознавания – одна из нескольких версий результатов интерпретации графем и составления слова. Одна из нескольких версий линейного деления фрагмента изображения на слова, символы. Результат распознавания фрагментов (дуг) графа линейного деления (далее ГЛД) и интерпретации графем. Трансляция – переход от графического изображения символа (графемы) к символу. Фрагмент текста – объект, для уровня которого осуществляется большая часть обработки: построение вариантов в соответствии с шаблонами, их оценка и выбор лучшего варианта. Дифференциальный компаратор – механизм оценки вариантов распознавания фрагментов. Представляет собой множество правил, осуществляющих как попарное сравнение вариантов, так и интегральную оценку. В качестве дополнительной информации могут использоваться словари нескольких разновидностей, правила языка документа, тематика (литературный текст, научная статья, заполняемая форма бланка и др.). Привлечение дополнительной информации позволяет повысить правильность распознавания в следующих случаях: – выбрать наиболее правильный из нескольких вариантов линейного деления фрагмента строки на символы, – выбрать наиболее правильный вариант распознавания изображения символа (графемы) несколькими классификаторами, – выбрать наиболее правильные из нескольких букв или лигатур, которые может обозначать выбранная графема, – проанализировать большой участок распознанного текста (например, строку) и, по возможности, скорректировать результаты распознавания (например, поменять запятую на точку, если она стоит в конце предложения или объединить два французских слова «d’» и «Alembert» в одно). Известен способ распознавания символов текста с использованием дополнительной информации. Патент RU №2234734 раскрывает способ обработки изображения символов и фрагмента текста, включающий несколько последовательных этапов. Выполняют сбор дополнительной информации (в основном пространственно-параметрической), которая становится доступной на каждом этапе, и для последующего ее использования при повторном анализе того же фрагмента. Указанный способ использует лишь ограниченное число видов дополнительной информации. Способ не использует информацию из дополнительных источников, информацию, основанную на особенностях языка, некоторую другую внешнюю информацию. Не учитывают последовательность обращения к разным видам информации. Технический результат состоит в повышении точности распознавания текста, повышении помехозащищенности распознавания текста. Приведенный способ, так же как и другие известные способы, не позволяет достичь необходимого уровня точности распознавания. Заявленный технический результат достигают за счет использования правил языка и дополнительных правил. Заявляемый способ заключается в том, что после выполнения операций разбиения изображения, предположительно содержащего текст, на фрагменты, предположительно содержащие символы, выполняют распознавание символов. В результате распознавания получают один или более вариантов символов для каждой графемы. После этого объединяют символы в группы, предположительно составляющие слова. Рассматривают все возможные слова, полученные как комбинации всех возможных вариантов разбиения изображения на символы и вариантов распознавания составляющих фрагментов. Группы символов анализируют, в том числе вместе с одним или несколькими соседними группами с одной или с двух сторон. К словам применяют дополнительную информацию нескольких типов последовательно из нескольких источников, в объеме, необходимом для точного распознавания слова, соизмеряя достигаемый уровень надежности распознавания и объем используемых вычислительных ресурсов. Последовательность анализа следующая. Предварительно задают перечень и очередность привлечения дополнительной информации. Перечень дополнительной информации и последовательность обращения следующая: 1. Информация о точках деления строки на символы. 2. Качество распознавания графического элемента. 3. Словарь. 4. Словарь возможных частей слов, например, триграмм. 5. Правила, обусловленные используемыми типовыми шаблонами данных. 6. Правила, обусловленные местонахождением слова в пределах стоки и/или абзаца. 7. Правила, обусловленные особенностями языка документа. 8. Правила, обусловленные типом документа. 9. Дополнительные правила для обработки редко встречающихся случаев. Возможно использование не всех, а только части перечисленных видов дополнительной информации. Также предварительно назначают оценку качества для каждого вида дополнительной информации. Определяют все возможные варианты разбиения фрагментов изображения, предположительно являющихся строками текста на фрагменты, предположительно относящихся к изображениям отдельных слов, по надежно распознанным пробелам. Для каждого фрагмента строки, предположительно являющегося словом, строят граф линейного деления (ГЛД), описывающий варианты разбиения фрагмента на графические элементы, относящиеся к изображениям символов (графем). Распознают изображения графических элементов, используя по крайней мере один классификатор, и каждому варианту распознавания графического элемента (графемы) присваивают оценку. Осуществляют переход от вариантов распознавания графем, составляющих слово, к символам алфавита, используя варианты с наибольшими значениями оценок распознавания символов. Среди всех цепочек ГЛД, ведущих из начальной вершины в финальную, выбирают (отмечают) одну или более цепочек распознаваемых символов, соответствующих выбранным вариантам распознавания графических элементов (графем). Все полученные варианты группы символов подразделяют на четыре разновидности по следующим признакам: – все символы являются заглавными буквами, – все символы являются строчными буквами, – первый символ является заглавной буквой, остальные – строчные, – вариант, выбранный исходя из оценки выполненных переходов от распознанной графемы к символам с использованием первого вида дополнительной информации. Если имеются более одного варианта символа по результатам распознавания графического элемента, их обрабатывают с последовательным привлечением последующих видов дополнительной информации, согласно заранее заданного порядка. Проводят дополнительную коррекцию распознавания пробелов, ошибочно распознанных на предыдущих шагах. В случае необходимости добавляют новые правила и ограничения для типов данных, причем типы данных подразделяют на простые и составные, причем составные типы образуют как соединение двух или более простых или как любую комбинацию простых и сложных типов. Ограничения (правила) включают использование, в том числе одного или более типов шаблонов. Описание процесса распознавания текста с использованием дополнительной информации. Обработку с использованием дополнительной информации можно условно представить как троекратную обработку одного фрагмента текста. С помощью средства распознавания символов разбивают графические изображения строк текста на фрагменты и обрабатывают их по очереди слева направо. Для каждого фрагмента строки строят символьный граф линейного деления (ГЛД), описывающий варианты разбиения фрагмента на графемы, а изображения графем распознают с применением классификаторов по крайней мере двух разных типов. Далее выполняют первую обработку ГЛД с использованием дополнительной информации. Первая обработка состоит в следующем: 1. На ГЛД выбирают цепочки дуг, ведущие из начальной вершины в финальную, а в каждой из дуг выбирают один из вариантов ее распознавания (букву). С помощью дополнительной информации строят несколько цепочек дуг в порядке убывания суммарного качества распознавания. 2. Полученные цепочки дуг обрабатывают с привлечением шаблонов, описывающих разновидности слов, которые могут встречаться в тексте. Поскольку одна графема может обозначать несколько букв, вариант слова может содержать несколько вариантов некоторых букв. Шаблоны в некоторой степени уменьшают число возможных вариантов (например, шаблон слова оставляет только варианты с буквами языка, а шаблон числа – с цифрами), но не полностью. 3. Все порожденные варианты оценивают по суммарному значению показателя качества, а некоторое количество лучших по качеству вариантов сортируют дифференциально на основе попарного сравнения. 4. Из отсортированного списка выбирают несколько лучших вариантов, которые передают на вторую обработку. В качестве источников для оценки и сравнения вариантов привлекают: – Качество распознавания графем каждого варианта (качество пути), – Соответствие грамматике одного из шаблонов (качество шаблона). Чем более жесткая грамматика и чем выше частота применения шаблона, тем большее ему отдают предпочтение. – Результаты проверки по словарю. Оценка словарного слова возрастает с увеличением длины слова и зависит от стиля и сложности слова. – Геометрическую информацию. Соседние буквы в слове должны располагаться друг относительно друга заданным образом и быть согласованы по высоте. – Информацию о точках линейного деления. Определенные пары букв могут касаться друг друга. – Правила, написанные для обработки некоторых частных случаев. При первой обработке еще нет информации о тексте справа от обрабатываемого фрагмента (правого фрагмента) и может быть недостаточно статистики для вычисления точной высоты строки. Однако при первой обработке есть дополнительная информация в виде ГЛД и изображения графем, которые уничтожаются после обработки фрагмента и недоступны при второй обработке. Поэтому при первой обработке не выбирают окончательный вариант (зачастую остаются неоднозначности типа «строчная-заглавная» в буквах и «буква-цифра» в идентификаторах). Вторая обработка. После того, как обработаны все фрагменты одной строки, начинают выполнять вторую обработку. На этом этапе собрана уже вся статистика о высоте букв, поэтому выдвигают окончательные гипотезы и делают окончательные заключения о высоте строки. Одновременно окончательно выбирают расположение заглавных букв и оценивают надежность вариантов трансляций. Фрагменты строки обрабатывают в порядке от последнего к первому. Все варианты символов при второй обработке разделяют на четыре группы: – все заглавные, – все строчные, – первая заглавная и – с расположением строчных и заглавных символов, выбранным исходя из оценок имеющихся трансляций. Если остались неоднозначные трансляции, их также конкретизируют по следующему общему правилу: оставляют только трансляции, обеспечивающие максимально возможную оценку. Снятие неоднозначностей производят последовательно следующими способами: 1. По геометрическим характеристикам. 2. По соотношению высоты строчных и заглавных символов, записанному в шаблоне. 3. С учетом вариантов трансляций фрагмента слева. 4. По правилам, которые минимизируют число переключений с букв на цифры в буквенно-цифровых словах. 5. Если ни один из предыдущих способов не дает результата, вариант трансляции выбирают из нескольких имеющихся случайным образом. После снятия неоднозначностей варианты повторно оценивают и дифференциально сортируют. В оценках и при сортировке учитывают слова как слева, так и справа от обрабатываемого слова. Для слова, расположенного в правой крайней позиции, генерируют несколько вариантов фрагментов слов справа, соответствующих разным гипотезам о высоте строки. Для каждого слова оценки и сортировку производят с несколькими фрагментами справа и оставляют несколько лучших вариантов, которые будут служить фрагментами справа для следующего по порядку слова. Третья обработка. После того, как выбраны варианты для всей строки, производят их коррекцию. Поскольку на этом этапе имеется целая распознанная строка, при коррекции привлекают “синтаксическую” информацию: о начале или конце предложения, о строчных или заглавных буквах следующего или предыдущего слова и т.д. На этапе коррекции производят уточнение расположения пробелов на основе анализа на одинаковую ширину пробелов и распределения ширины просветов, присоединение ошибочно отделенных пунктуаторов (знаков препинания и др.) и единиц в числах, исправление ошибок типа замены точки на запятую, исправление слов Построение путей на ГЛД. Построение путей на ГЛД выполняют одним из следующих способов. Первый способ строит лучший по качеству путь. Он использует обычный алгоритм построения лучшего пути для ориентированного ациклического графа. Второй способ («генератор») предполагает перебор всех путей на ГЛД, начиная от лучшего и далее в порядке ухудшения качества. Необходимость в отдельном способе для построения первого (наилучшего) пути объясняется тем, что, с одной стороны, первый способ строит его намного быстрее, чем второй («генератор»), а, с другой стороны, тем что часто первый (наилучший) путь оказывается очевидно наиболее пригодным. Оба способа учитывают множество графем, которые допустимы в цепочках дуг ГЛД. Кроме того, второй способ («генератор») может строить лишь цепочки дуг, определяющиеся допустимыми триграммами или, например, проверкой по словарю, что позволяет увеличить глубину перебора за счет раннего отсечения заведомо неправильных путей. Варианты результатов распознавания и способ их конкретизации. Основным результатом применения дополнительной информации являются варианты слова. Поскольку трансляция графемы в букву неоднозначна, для каждой графемы сохраняют набор вариантов буквы. По мере привлечения дополнительной информации (словарь, геометрия строки, фрагмент слева и справа) число вариантов постепенно уменьшается. При первой обработке уменьшение числа вариантов достигают применением шаблонов с учетом грамматики и словаря. Дальнейшее ограничение числа подходящих вариантов получают при второй обработке. Распознавание схожих графем. Существуют пары очень схожих графем: “r”-“г”, “п”-“n”, “6”-“б” и т.п. Для их распознавания выполняют дополнительную трансляцию. Каждую графему из пары схожих транслируют в буквы, соответствующие обеим графемам пары, но часть трансляций помечают как дополнительные. Например, графемы “г” и “r” имеют следующие трансляции: “г” “г” “г” “r” “r” “r” Если словарь или грамматика не дают оснований для однозначного выбора трансляции, выбирают основную трансляцию. Обобщенные графемы. Для распознавания разделившихся символов используются парные подстановки в ГЛД. Вводят обобщенные графемы «||» и «|||» для двух- и трехэлементных графем. Эти графемы транслируют во все двух- или трехэлементные буквы, но все эти трансляции считают дополнительными. Окончательный выбор трансляций осуществляют с привлечением дополнительной информации. Назначение оценок качества распознавания при использовании дополнительной информации. Используют интегральные и дифференциальные оценки. Интегральная оценка состоит из базовой оценки качества по цепочке дуг ГЛД, качества шаблона и дополнительного качества. Дифференциальную оценку используют при парном сравнении. Базовая оценка качества пути. Базовая оценка качества пути определяется как сумма оценок качества распознавания графем для всех графем по цепочке дуг. Качество с учетом шаблонов. Качество по шаблонам состоит из двух компонент. Одна компонента оценивает соответствие варианта грамматике шаблона. Другая компонента оценивает наличие слова в словаре. Дополнительное качество. Дополнительное качество начисляют по дополнительному списку правил. Основные источники дополнительных поправок – геометрические параметры, плохие с точки зрения соответствия графеме или фрагменту слева от обрабатываемого слова, строчные-заглавные буквы, соответствие языку во фрагменте слева и справа. КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКОГО МАТЕРИАЛА. Фиг.1 показывает основные этапы (шаги) распознавания символов, фрагментов строки, строк с использованием дополнительной информации и средств сравнения. Фиг.2 показывает этап выбора окончательного варианта распознанной строки символов. ОПИСАНИЕ ПОЗИЦИЙ НА ФИГУРАХ. 1 – операция (этап) построения путей (цепочек) на ГЛД по множеству (группе) графем. 2 – операция (этап) построения вариантов группы символов в соответствии с шаблонами. 3 – операция (этап) суммарной оценки полученных вариантов. 4 – операция (этап) дифференциальной сортировки вариантов. 5 – операция (этап) окончательного разрешения неоднозначности трансляций. 6 – операция (этап) выбора цепочки лучших вариантов для строки. 7 – пути (цепочки) на ГЛД. 8 – варианты. 9 – сортированный список вариантов. 10 – правила языка документа. 11 – шаблоны. 12 – средство сравнения. 13 – список вариантов. ОПИСАНИЕ ПРИНЦИПА РАБОТЫ. Сущность заявляемого способа представлена на фиг.1, 2. После выполнения операций разбивки изображения, предположительно содержащего текст, на фрагменты, предположительно содержащие символы, выполняют распознавание символов для всех вариантов разбивки на фрагменты. В результате распознавания получают один или более вариантов символов для каждого изображения символа (графемы). После этого объединяют символы в группы, предположительно составляющие слова. Сущность заявляемого способа заключается в том, что рассматривают все возможные слова, полученные как комбинации всех возможных вариантов разбиения изображения и распознавания составляющих изображений символов. Группы символов анализируют, в том числе вместе с одним или несколькими соседними группами с одной или с двух сторон. К словам применяют дополнительную информацию нескольких разновидностей последовательно из нескольких источников, в объеме, необходимом для точного распознавания слова. Выполняют анализ, включающий по крайней мере следующие этапы. Предварительно задают перечень и очередность привлечения дополнительной информации. Перечень дополнительной информации и последовательность обращения выбирают из следующего списка. 1. Информация о точках деления строки на символы. 2. Качество распознавания графического элемента. 3. Словарь полных слов. 4. Словарь возможных частей слов, например, триграмм. 5. Правила, обусловленные используемыми типовыми форматами данных. 6. Правила, обусловленные местонахождением в пределах стоки и/или абзаца. 7. Правила, обусловленные особенностями языка документа. 8. Правила, обусловленные типом документа. 9. Дополнительные правила для обработки редко встречающихся случаев. Если использование части перечисленных видов дополнительной информации, дает достаточно надежный и достоверный результат, дальнейшую (следующую по списку) информацию не привлекают. Также предварительно назначают оценку качества для каждого вида дополнительной информации. Определяют все возможные варианты разбиения областей изображения, предположительно являющихся строками текста на фрагменты, предположительно относящихся к изображениям отдельных слов, по надежно распознанным пробелам. Для каждого фрагмента строки строят ГЛД, описывающий варианты разбиения фрагмента на графические элементы, относящиеся к графемам. Распознают полученные изображения графических элементов, используя один или более классификатор, и каждому варианту распознавания графического элемента (графемы) присваивают оценку. Осуществляют переход от вариантов распознавания графем к символам алфавита. Выполняют следующую по крайней мере трехшаговую процедуру. Первый шаг. Для всех цепочек ГЛД, ведущих из начальной вершины в финальную, строят одну или более цепочек распознаваемых символов, соответствующих вариантам распознавания графических элементов (графем) и вариантам переходов от распознанных графем к символам алфавита. Ранжируют полученные варианты в порядке уменьшения оценки качества распознавания. Второй шаг. Все полученные варианты группы символов обрабатывают с учетом правил о возможном расположении строчных и заглавных символов (букв). Указанные правила подразделяют на четыре разновидности по следующим признакам: – все символы являются заглавными буквами, – все символы являются строчными буквами, – первый символ является заглавной буквой, остальные – строчные, – вариант, выбранный исходя из оценки выполненных переходов от распознанной графемы к символам, с использованием первого вида дополнительной информации. Если имеются более одного варианта символа по результатам распознавания графического элемента, их обрабатывают с последовательным привлечением последующих видов дополнительной информации, согласно заранее заданного порядка, и/или при необходимости одновременным привлечением всех видов дополнительной информации. Каждому полученному варианту назначают оценку качества. Варианты символов, имеющие оценку ниже предварительно заданной, отбрасывают. Полученные варианты сортируют, используя попарное сравнение. Третий шаг. Проводят дополнительную коррекцию распознавания пробелов, ошибочно распознанных на предыдущих шагах: – присоединение элементов, ошибочно отделенных на предыдущих шагах, – отделение элементов, ошибочно присоединенных на предыдущих шагах. Правила, обусловленные особенностями языка документа, могут включать, в том числе фонетические и/или лексические, и/или семантические правила. При повторной оценке и попарной сортировке для самого правого слова генерируют несколько вариантов слов справа, соответствующих разным гипотезам (например, о высоте строки), причем для каждого слова оценку и сортировку производят с несколькими контекстами справа и принимают несколько лучших вариантов, которые затем используют как дополнительную информацию для следующего по порядку (по расположению) слова. Если необходимо, добавляют новые правила и ограничения и/или редактируют имеющиеся. Средства для добавления новых правил и ограничений могут включать введение правил для типов данных, причем типы данных подразделяют на простые и составные, причем составные типы образуют как соединение двух или более простых или любые комбинации простых и сложных. Тип данных задают в виде по крайней мере следующих характеристик: – перечня символов, разрешенных для использования в словах и/или – дополнительного правила, ограничивающего перечень символов, и/или – перечня пунктуаторов, разрешенных для использования, и/или – грамматических правил для часто встречающихся слов, или фрагментов слов. Ограничения включают использование, в том числе одного или более из следующих типов шаблонов: – двуязычное слово, – двуязычное слово с цифрами, – словарный идентификатор, – аббревиатуру, – число, – римское число, – число с суффиксом (порядковое число), – число с префиксом, – слово, составленное из пунктуаторов, – слово + число, – слово с числом внутри, – слово со скобками, – телефонный номер, – имя файла вместе с полной информацией о местонахождении, – шаблон регулярных выражений, – вспомогательный шаблон. Более подробное описание некоторых из перечисленных разновидностей шаблонов, смысл которых не очевиден из наименования. Шаблон регулярных выражений. Способ описания слов, которые могут встретиться в тексте с помощью регулярных выражений. Регулярное выражение – сложный формализованный формат данных. Состоит из данных простого типа. Слово считается предпочтительным, если соответствует описанию, приведенному в регулярном выражении. Данные простого типа – набор слов, собранных в специальном словаре. Специальный словарь ограниченного объема показывает, какие слова более вероятны в тексте, а какие маловероятны. Слово считается предпочтительным, если оно есть в словаре. Регулярные выражения – это разновидность описания “предпочтительных” слов в формальном виде. Например, следующее регулярное выражение: (“кр”|”мон”)”ах” Такое регулярное выражение означает, что для того, чтобы слово считалось предпочтительным, в начале слова должно быть “кр” или “мон”, а затем должно следовать “ах”. То есть предпочтительными будут всего два слова “крах” и “монах”. (99999)|(999999) Такое регулярное выражение означает, что предпочтительным считают число, имеющее длину пять или шесть знаков. Другие примеры. s?t означает “sat” и “set”. s*d означает “sad” и “started”. w[io]n означает “win” и “won”. [r-t]ight означает “right” и “sight”. m[!a]st означает “mist” и “most”, но не “mast”. t[!a-m]ck означает “tock” и “tuck”, но не “tack” или “tick”. fe{2}d означает “feed”, но не “fed”. fe{1,}d означает “fed” и “feed”. 10{1,3} означает “10” и “100”, и “1000”. Вспомогательный шаблон. Шаблон, используемый, в том случае, когда не подходит ни один другой шаблон. Например, если в середине русского текста встречается слово “Юг12Хъ”, то все контекстные шаблоны не смогут идентифицировать это слово. В этом случае используют вспомогательный шаблон.
Формула изобретения
1. Способ распознавания текстовой информации из графического файла, характеризующийся получением графического файла из устройства сканирования или иным путем, сегментацией изображения, распознаванием символов текста; отличающийся тем, что предварительно задают следующий порядок обращения к дополнительной информации, включающей следующие виды: информация о точках деления строки на символы, и/или качество распознавания графического элемента, и/или словарь, и/или словарь возможных частей слов, и/или правила, обусловленные используемыми типовыми шаблонами данных или регулярными выражениями и/или правила, обусловленные местонахождением слова в пределах строки и/или абзаца, и/или правила, обусловленные особенностями языка документа, и/или правила, обусловленные типом документа, и/или дополнительные правила для обработки редко встречающихся случаев; предварительно назначают оценку качества для каждого вида дополнительной информации; строят различные варианты разбиения изображения выделенных строк на фрагменты, предположительно содержащие изображения отдельных слов, по надежно распознанным пробелам; для каждого фрагмента строки строят граф линейного деления, описывающий варианты разбиения фрагмента на графические элементы, предположительно содержащие изображения символов; распознают изображения графических элементов, используя один или более классификатор, и каждому варианту распознавания графического элемента присваивают оценку; осуществляют переход от вариантов распознавания графем к вариантам символов алфавита; выполняют по крайней мере следующие шаги: первый шаг: для каждой цепочки, соединяющей начальную и конечную вершины, строят цепочки, соответствующие всем вариантам распознавания графем и вариантам переходов от распознанных графем к символам алфавита, ранжируют полученные варианты в порядке уменьшения оценки качества распознавания, второй шаг: все полученные варианты группы символов обрабатывают с привлечением информации о расположении заглавных и строчных букв, если имеются более одного варианта символа по результатам распознавания графического элемента, их обрабатывают с последовательным привлечением последующих видов дополнительной информации, согласно заранее заданного порядка, и/или при необходимости одновременным привлечением всех указанных видов дополнительной информации, каждому полученному варианту назначают оценку качества, варианты символов, имеющие оценку ниже предварительно заданной, отбрасывают, полученные варианты сортируют, используя попарное сравнение; третий шаг: производят дополнительную коррекцию распознавания пробелов, ошибочно распознанных на предыдущих этапах: присоединение элементов, ошибочно отделенных на предыдущих шагах, отделение элементов, ошибочно присоединенных на предыдущих шагах. 2. Способ по п.1, отличающийся тем, что правила, обусловленные особенностями языка документа, включают в том числе фонетические, и/или лексические, и/или семантические. 3. Способ по п.1, отличающийся тем, что на втором шаге информация о возможном расположении заглавных и строчных букв включает по крайней мере четыре разновидности по следующим признакам: все символы являются заглавными буквами, все символы являются строчными буквами, первый символ является заглавной буквой, остальные – строчные, вариант, выбранный, исходя из оценки выполненных переходов от распознанной графемы к символам с использованием первого вида дополнительной информации. 4. Способ по п.1, отличающийся тем, что используют словарь возможных фрагментов слов, существующих в естественном языке. 5. Способ по п.4, отличающийся тем, что каждая комбинация возможных фрагментов слов снабжена оценкой вероятности использования в тексте. 7. Способ по п.1, отличающийся тем, что содержит средство для добавления новых правил и ограничений, включающее введение правил для типов данных, которые подразделяют на простые и составные. 8. Способ по п.7, отличающийся тем, что составные типы данных образуют как соединение по крайней мере двух простых или как любая комбинация простых и составных типов данных. 9. Способ по п.7, в котором тип данных задают в виде по крайней мере следующих характеристик: перечня символов, разрешенных для использования в словах, и/или дополнительное правило, ограничивающее перечень символов, и/или перечень пунктуаторов, разрешенных для использования, и/или грамматические правила для часто встречающихся слов или фрагментов слов.
РИСУНКИ
|
||||||||||||||||||||||||||
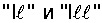 на римские “II” и “III”, соответственно.
на римские “II” и “III”, соответственно. “_Г”, основная,
“_Г”, основная,