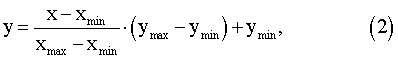Патент на изобретение №2294024
|
||||||||||||||||||||||||||
(54) СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ КЛЮЧЕВЫХ СЛОВ В СЛИТНОЙ РЕЧИ
(57) Реферат:
Изобретение относится к системам обработки информации и управления, а именно к способам построения систем распознавания речи. Достигаемый технический результат – обеспечение возможности распознавания ключевых слов в потоке слитной речи и повышение быстродействия системы. Согласно способу поток слитной речи сегментируют, выделенные отдельные слова подают поочередно на двухуровневую обработку речевого сигнала. Выбирают на первом уровне наиболее вероятные кандидаты эталонов для анализируемого слова, выбирают на втором уровне наиболее вероятную альтернативу из отобранных кандидатов. Выполняют анализ результатов распознавания речевого сигнала с принятием решения. Анализ и обработка речевого сигнала проводятся в частотно-временной области, представленной с помощью вейвлет-преобразования. 2 з.п. ф-лы, 2 ил.
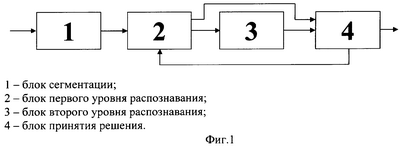
Изобретение относится к системам обработки информации и управления, а именно к способам построения систем распознавания речи. Известен способ проведения двухуровневой обработки речевого сигнала для точного определения границ слова [1]. Способ предполагает сравнивать с анализируемым речевым сигналом эталоны для всех слов словаря системы, ввиду этого способ обладает недостаточным быстродействием. Известен способ обработки речевого сигнала с использованием блока первого уровня, построенного с применением метода динамического программирования, и блока второго уровня, построенного на основе методов фонемного анализа [2]. Недостатками данного способа является то, что возникновение ошибки блока первого уровня приводит к ошибке всей системы в целом. Способ использует ресурсоемкие, сложные алгоритмы распознавания, что снижает его быстродействие. В качестве прототипа авторами принят способ дикторонезависимого распознавания изолированных речевых команд [3], содержащий двухуровневую обработку речевого сигнала, с отбором на первом уровне наиболее вероятных кандидатов эталонов для анализируемого слова, выбором на втором уровне наиболее вероятной альтернативы из отобранных кандидатов и анализом результатов распознавания речевого сигнала блоком принятием решения. Блок первого уровня проводит целословный анализ, измеряя расстояние от анализируемого речевого сигнала до эталонов с применением нелинейных функций. Недостатками способа, выбранного в качестве прототипа, являются его неприменимость для распознавания ключевых слов или команд в потоке слитной речи. Применение нелинейных функций при вычислении расстояний между анализируемым словом и эталонами в блоке первого уровня значительно снижает быстродействие способа. Перед заявленным изобретением поставлена задача сделать возможным распознавание ключевых слов в потоке слитной речи, а также повысить быстродействие системы. Указанная задача решается за счет того, что применяют блок сегментации, осуществляющий выделение слов из потока слитной речи и подающий поочередно выделенные слова на вход двухуровневой обработки речевого сигнала, с отбором на первом уровне наиболее вероятных кандидатов эталонов для анализируемого слова, выбором на втором уровне наиболее вероятной альтернативы из отобранных кандидатов и анализом результатов распознавания речевого сигнала блоком принятием решения. В блоке выделения наиболее вероятных кандидатов проводят целословный анализ, измеряя расстояние между анализируемым словом и эталонами с применением линейных функций. Блок принятия решения формирует три вида решения, отбор ключевого слова, переспрос блоку первого уровня на расширение числа кандидатов и отсев анализируемого слова. Анализ и обработку речевого сигнала в блоках сегментации, первого и второго уровней проводят в частотно-временной области, представленной с помощью вейвлет-преобразования [4]. Благодаря этому получен технический результат, а именно возникла возможность распознавания ключевых слов в слитной речи, и повышено быстродействие системы распознавания. Заявляемый способ дикторонезависимого распознавания ключевых слов в слитной речи поясняется чертежами, где на фиг.1 схематически изображены основные блоки способа дикторонезависимого распознавания ключевых слов в слитной речи; на фиг.2 приведена схема блока сегментации. Способ дикторонезависимого распознавания ключевых слов в слитной речи содержит сегментацию слов из речевого потока и двухуровневую обработку выделенных слов с отбором на первом уровне наиболее вероятных кандидатов слов для анализируемого сигнала, выбором на втором уровне наиболее вероятной альтернативы из отобранных кандидатов и принятием решения либо о распознанном ключевом слове, либо о переспросе блока первого уровня, либо об отсеве анализируемого слова. Блок 1 сегментации (фиг.1) производит анализ слитной речи на наличие в анализируемый момент времени сигнала-паузы либо сигнала-слова и в результате выделяет множество изолированных слов. Блок 2 первого уровня распознавания (фиг.1) выделяет множество наиболее вероятных кандидатов, наиболее близких к распознаваемому слову. Число кандидатов во множестве, как правило, меньше общего количества слов в словаре. Блок 3 второго уровня распознавания (фиг.1) производит анализ речевого сигнала, с помощью которого определяет наиболее вероятное слово из выбранного множества кандидатов с помощью статистического метода. Результаты распознавания речевого сигнала на первом и втором уровнях анализируют блоком 4 принятия решения (фиг.1), и, в зависимости от уровня соответствия результатов требованиям, формируют сигнал либо о распознанном ключевом слове, либо о переспросе блока первого уровня, либо об отсеве анализируемого слова. На этапе сегментации проводится анализ и обработка речевого потока. На первом уровне блок 5 вейвлет-преобразования (фиг.2) представляет речевой поток слитной речи в частотно-временной области. Сущность вейвлет-преобразования поясняет формула:
где C(a,b) – вейвлет-коэффициенты; S(t) – речевой сигнал; а – коэффициент масштабирования;
t – время. В процессе анализа блок 6 вычисляет энергетические и блок 7 (фиг.2) – статистические характеристики речевого сигнала. На основе сравнения вычисленных характеристик с пороговыми значениями в блоке 8 (фиг.2) принимается решение об отнесении анализируемого сигнала в данный момент времени к сигналу-паузе или к сигналу-слову. В конечном счете, на основании данных блока 8, блок 9 (фиг.2) формирует множество отдельных слов, которые содержались в речевом потоке. На первом уровне распознавания проводят отбор наиболее вероятных кандидатов с применением целословного анализа. Применение линейных функций (например, функции линейного контрастирования) для измерения расстояний между анализируемым словом и эталонами при проведении целословного анализа (использование признаков, характеризующих все слово в целом) позволяет снизить время сравнения с эталонами слов в блоке 2 (фиг.1) первого уровня, так как применение нелинейных функций вычислительно сложнее. Линейное контрастирование поясняется формулой:
где у – нормированное значение коэффициента; х – реальное значение коэффициента вейвлет-преобразования; xmax – максимальное значение коэффициента вейвлет-преобразования; хmin – минимальное значение коэффициента вейвлет-преобразования; уmax – максимальное значение нормированных коэффициентов; уmin – минимальное значение нормированных коэффициентов. С помощью блока 2 (фиг.1) первого уровня измеряют расстояние от анализируемого речевого сигнала до эталонов и величину порога решающего правила для отбора наиболее вероятных кандидатов определяют как постоянную величину, что снижает время работы блока. Таким образом, решающее правило для определения подмножества слов-претендентов в блоке 1 первого уровня определяется формулой:
где Rk – расстояние от анализируемого речевого сигнала до эталона, соответствующего k-му слову заданного словаря; Rnop – постоянное пороговое расстояние. На втором уровне (блок 3 фиг.1) осуществляют сравнение статистических характеристик анализируемого слова с характеристиками кандидатов эталонов, выбранных на первом уровне. Результаты сравнения анализируют на третьем уровне (блок 4 фиг.1) и формируют решение либо о распознанном ключевом слове, либо о переспросе блока 2 первого уровня, либо об отсеве анализируемого слова. Переспрос блока 2 заключается в команде на увеличение Rnop (формула 3) и проведение повторного отбора кандидатов уже с увеличенным значением Rnop (формула 3). Таким образом, применение блока сегментации позволяет распознавать ключевые слова в слитной речи, а также применение линейных функций на первом уровне распознавания при проведении целословного анализа позволяет увеличить быстродействие системы. Список литературы 1. Патент США №4881266, МПК G 10 L 5/06, 1989. 2. Патент США №5315689, МПК G 10 L 5/06, 1995. 3. Патент РФ №2103753, МПК G 10 L 5/06, опубликован 27.01.1998. 4. Дьяконов В.П. Вейвлеты. От теории к практике. – Москва: СОЛОН-Р, 2002.
Формула изобретения
1. Способ дикторонезависимого распознавания ключевых слов в слитной речи, содержащий двухуровневую обработку речевого сигнала с отбором на первом уровне наиболее вероятных кандидатов эталонов для анализируемого слова, выбором на втором уровне наиболее вероятной альтернативы из отобранных кандидатов и анализ результатов распознавания речевого сигнала с принятием решения, отличающийся тем, что поток слитной речи сегментируют и выделенные отдельные слова подают поочередно на двухуровневую обработку речевого сигнала, при этом анализ и обработка речевого сигнала при сегментации и двухуровневой обработке проводится в частотно-временной области, представленной с помощью вейвлет-преобразования. 2. Способ по п.1, отличающийся тем, что в при выделении наиболее вероятных кандидатов с применением целословного анализа измеряют расстояние от анализируемого слова до эталонов с применением линейных функций. 3. Способ по п.1, отличающийся тем, что при принятии решения формируют три вида решения: либо о распознанном ключевом слове, либо о переспросе блоку первого уровня на расширение числа кандидатов, либо об отсеве анализируемого слова.
РИСУНКИ
MM4A – Досрочное прекращение действия патента СССР или патента Российской Федерации на изобретение из-за неуплаты в установленный срок пошлины за поддержание патента в силе
Дата прекращения действия патента: 19.04.2007
Извещение опубликовано: 20.07.2008 БИ: 20/2008
|
||||||||||||||||||||||||||
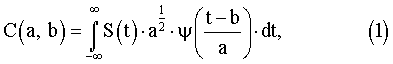
 (х) – вейвлет-функция;
(х) – вейвлет-функция;