Патент на изобретение №2294012
|
||||||||||||||||||||||||||
(54) СТРУКТУРА ДАННЫХ И СПОСОБЫ ПРЕОБРАЗОВАНИЯ ПОТОКА БИТОВ В ЭЛЕКТРОННЫЙ ДОКУМЕНТ И ФОРМИРОВАНИЯ ПОТОКА БИТОВ ИЗ ЭЛЕКТРОННОГО ДОКУМЕНТА НА ЕЕ ОСНОВЕ
(57) Реферат:
Изобретение относится к синтаксическому анализу потока битов, содержащего данные, которые имеют структуру и содержимое, соответствующие некоторому формату, и предназначен для формирования древовидного представления упомянутого потока. Технический результат – повышение помехозащищенности. Предлагаемая схема, получаемая из XML, которая позволяет описывать формат кодирования в обобщенном виде. Такая схема используется для выполнения синтаксического анализа потока битов для получения документа, который представляет поток битов, который является экземпляром упомянутой схемы, или для формирования потока битов из документа, представляющего поток битов. 7 н.п. ф-лы, 3 ил.
(56) (продолжение): CLASS=”b560m”2000, p.76-87, ISSN:0163-5808. RU 2072562 C1, 27.01.1997. US 6108449 A, 22.08.2000.
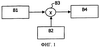
Настоящее изобретение относится к способу преобразования в электронный документ потока битов, содержащего данные, которые имеют структуру и содержимое, соответствующие некоторому формату, причем упомянутый способ предназначен для формирования древовидного представления упомянутого потока. Изобретение также относится к способу формирования потока битов согласно некоторому формату из документа, который представляет собой древовидное представление упомянутого потока битов и который содержит данные, в особенности импортируемые данные, посредством использования некоторого режима импорта. Изобретение также относится к структуре данных, образующей схему для преобразования потока битов в электронный документ и определяющей один или несколько типов данных, которые могут иметь один или несколько аспектов, и содержащей множество элементов, для которых она описывает имя, тип данных, расположение с перекрытием, порядок и предварительно определенное или случайное количество появлений, причем появление элемента является обязательным или факультативным. Изобретение также относится к компьютерным программам для осуществления таких способов, к обрабатывающему блоку, содержащему средство памяти для хранения упомянутых структуры данных и компьютерных программ, а также к системе передачи, содержащей, по меньшей мере, объект источника и объект адресата, причем упомянутый объект источника содержит упомянутый обрабатывающий блок. Изобретение может применяться в области редактирования, изменения и объединения содержимого. Примером применения изобретения является адаптация содержимого, подлежащего передаче адресату как функции профиля пользователя (экран, вычислительная производительность, объем памяти, канал связи, используемый для передачи и т.д.). Такая адаптация позволяет избежать бесполезных передач данных, которые получатель не сможет использовать, и, таким образом, сэкономить на полосе пропускания. В этом отношении в заявке на патент Франции №0101530, поданной 05.02.2001 г. Конинклийке Филипс Электронике Н.В., уже описан способ генерации файла с некоторыми характеристическими свойствами из основного документа, написанного на языке разметки и описывающего основной последовательный файл, причем упомянутый способ содержит этап преобразования для генерации преобразованного документа посредством применения к основному документу предварительно определенного преобразования, которое является функцией упомянутых характеристических свойств, причем файл с упомянутыми характеристическими свойствами генерируется из преобразованного документа. Этот способ включает в себя выполнение необходимых преобразований основного документа, в котором очевидна структура последовательного файла. Это позволяет исключить необходимость декодирования основного последовательного файла для его повторного кодирования иным образом. Однако этот способ генерации файла подразумевает генерацию основного документа, который описывает основной последовательный файл, а затем генерацию другого файла из преобразованного документа. Задачей настоящего изобретения является создание автоматически выполняемого обобщенного способа выполнения таких операций. В соответствии с изобретением указанный результат достигается посредством структуры данных, которая образует схему для преобразования потока битов в электронный документ на языке разметки или наоборот, определяет один или более типов данных, которые могут иметь один или более аспектов, причем аспект соответствует ограничению, наложенному на набор значений типа данных и содержит множество элементов, для которых она описывает имя, тип данных, расположение с перекрытием, порядок и предварительно определенное или случайное количество появлений, причем появление элемента является обязательным или факультативным, а также определяет один или более типов данных, которые соответствуют двоичным словам предварительно определенной длины или длин и которые имеют, по меньшей мере, аспект, относящийся к упомянутой длине. Упомянутая структура данных отличается тем, что она определяет одну или более переменных, составляемых путем доступа к данным, причем она содержит одно или несколько условных ветвлений для описания различных структур или возможного содержимого как функции значения упомянутых одной или более переменных, и, факультативно, имеет, по меньшей мере, один из следующих характеристических признаков: упомянутая структура данных определяет тип данных, который соответствует двоичным сегментам неопределенной длины и который имеет, по меньшей мере, аспект, указывающий, должны ли двоичные сегменты быть преобразованы и введены в электронный документ или двоичные сегменты должны содержаться в двоичном файле, и указатели на двоичный файл должны быть введены в электронный документ, и аспект, относящийся к флагу останова двоичного сегмента, причем структура данных определяет аспект, относящийся к заполняющим битам, содержащимся в упомянутых двоичных словах предварительно определенной длины или длин. Кроме того, в соответствии с изобретением способ преобразования потока битов в электронный документ на языке разметки, содержащего данные со структурой и содержимым согласно некоторому формату, и электронный документ является древовидным представлением упомянутого потока битов, содержит этапы считывания структуры данных, поиска в упомянутом потоке битов данных, которые соответствуют элементам, содержащимся в упомянутой структуре данных, формирования экземпляра упомянутой структуры данных, который содержит данные, найденные в упомянутом потоке битов, и который составляет упомянутое древовидное представление. Кроме того, в соответствии с изобретением способ формирования потока битов согласно некоторому формату из электронного документа на языке разметки, представляющему собой древовидное представление потока битов и содержащему данные, импортируемые посредством использования преобразования данных, чтобы ввести данные в электронный документ, или посредством использования указателей на двоичный файл, содержащий данные, содержит этапы считывания упомянутого документа, параллельного считывания структуры данных, которая обобщенным образом описывает упомянутый формат, кодирования упомянутых данных как функции определяемого типа, составления потока битов из кодированных данных. Изобретение также относится к компьютерным программам, содержащим команды и обеспечивающим при загрузке в процессор выполнение процессором способа преобразования потока битов в электронный документ на языке разметки и способа формирования потока битов согласно некоторому формату из электронного документа на языке разметки. Кроме того, в соответствии с изобретением обрабатывающий блок содержит средство памяти для хранения структуры данных и средство памяти для хранения программы, которая содержит команды для осуществления способа синтаксического анализа потока битов, основанного на упомянутой структуре данных, для формирования документа на языке разметки, который представляет упомянутый поток битов, который является экземпляром упомянутой структуры данных, и/или программы, которая содержит команды для осуществления способа формирования потока битов, основанного на упомянутой структуре данных и на документе, представляющем упомянутый поток битов, который является экземпляром упомянутой структуры данных. Изобретение также относится к системе передачи, содержащей, по меньшей мере, объект источника и, по меньшей мере, объект адресата, причем объект источника содержит заявленный обрабатывающий блок. Изобретение поясняется ниже со ссылками на чертежи, на которых показано следующее: фиг.1 – блок-схема, иллюстрирующая выполнение синтаксического анализа в способе преобразования потока битов в электронный документ согласно изобретению, фиг.2 – блок-схема, иллюстрирующая способ создания потока битов согласно изобретению и фиг.3 – пример системы передачи согласно изобретению. На фиг.1 представлена блок-схема, объясняющая основной режим способа преобразования потока битов в электронный документ. Блок В1 представляет поток битов в соответствии с предварительно определенным форматом. Блок В2 представляет схему, которая в обобщенном виде описывает упомянутый предварительно определенный формат. Блок В3 представляет синтаксический анализатор, который позволяет выполнять синтаксический анализ потока В1 битов для создания документа В4, который представляет собой древовидное представление потока В1 битов и экземпляр схемы В2. Схема В2 описывает синтаксис потока битов. В особенности, она определяет тип данных, которые могут иметь место в потоке битов, и метод, которым они должны быть включены в документ. Древовидное представление В4 создается в зависимости от анализа потока В1 битов. На фиг.2 представлена блок-схема, объясняющая принцип действия способа формирования потока битов согласно изобретению. Блок В’2 представляет схему, которая описывает формат кодирования в обобщенном виде. Блок В’4 представляет документ, который представляет собой экземпляр схемы В’2. Блок В’3 представляет генератор потока битов, который позволяет выполнять параллельное считывание документа В’4 и схемы В’2 для создания потока В’1 битов. Предпочтительно, схемы В2 и В’2, используемые для одного формата кодирования, идентичны. Документ В’4 считывается схемой В’2 с целью определения типа данных, которые содержатся в документе В’4. Для значения, считанного из документа В’4, соответствующий тип данных, обнаруживаемых в схеме В’2, определяет режим кодирования, который должен использоваться для кодирования упомянутого значения. В целом, конечно, не является необходимым предоставление полной детализации структуры формата кодирования в схеме. Степень детализации зависит от рассматриваемого применения. Для применения, описанного в заявке на патент Франции №0101530, упомянутого в вводной части настоящей заявки (способ генерации файла – например файла JPEG2000 – характеристические свойства которого адаптированы к профилю получателя), некоторые сегменты маркеров JPEG2000 должны быть даны подробно, параметр за параметром, чтобы можно было выполнить восстановление упомянутых параметров и модифицирование их. Другие сегменты маркеров обрабатываются как блоки, так как нет необходимости иметь доступ к параметрам, которые они содержат. С физической точки зрения XML-документ содержит, в особенности, элементы, которые могут быть проанализированы и могут содержать текст, т.е. последовательность знаков, принадлежащих предварительно определенному набору знаков, и которые представляют тег или текстовые данные. С точки зрения логики XML-документ содержит один или несколько элементов, границы которого отмечаются флагом начала и флагом останова. Элементы могут быть включены в другие элементы (что образует расположение с перекрытием). Каждый элемент идентифицируется именем, которое указывается в его флаге начала и в его флаге останова. Элемент может иметь значение. Значение элемента размещается между его флагом начала и его флагом останова. В примере, который описывается ниже, данные выбираются для размещения непосредственно в элементах XML-документа, чтобы упростить реализацию (т.е. данные, содержащиеся в XML-документе, составляют значения элементов XML). Схема XML представляет собой язык описания схемы, который позволяет осуществлять определение содержимого и структуры XML-документа: в частности, схема XML позволяет описывать элементы и для каждого элемента имя, тип данных, расположение с перекрытием, порядок и количество появлений. Порядок и количество появлений может быть предварительно определено или быть неопределенным. Появление элемента может быть обязательным или дополнительным. Схема определяет класс XML-документов. Экземпляром схемы XML является XML-документ, который действителен в отношении упомянутой схемы. В нижеследующем описании, чтобы дать конкретный пример осуществления изобретения, рассматриваются потоки битов формата JPEG2000. Это уже не является ограничивающим, и ясно, что изобретение может быть применено к другим форматам. Для некоторых форматов может быть необходимым добавить другие типы данных к тем, которые здесь описаны. В Приложении А приведен пример схемы, которая описывает формат кодирования JPEG2000. В этой схеме используются простые типы данных, которые являются обобщенными и которые определены в Приложении В, и простые типы данных, полученные из этих обобщенных типов, которые определены в Приложении С. В Приложении D приведен пример XML-документа, который является экземпляром схемы, приведенной в Приложении А, и который представляет поток битов JPEG2000. В Приложениях А, В и С и в нижеследующем описании буквы Согласно изобретению схема В2 (которая считается идентичной схеме В’2 в нижеследующем описании) определяет тип всех данных, которые могут содержаться в потоке согласно формату JPEG2000. Некоторые типы данных уже существуют в языке описания схемы XML и могут быть непосредственно использованы. Другие должны быть модифицированы. Другие должны быть добавлены. Поток данных согласно формату JPEG2000 более конкретно содержит следующие типы данных: 1) двоичные сегменты неопределенных длин, содержимое которых может быть импортировано в XML-документ посредством использования первого или второго режима импорта, описанного ниже, 2) двоичные слова различных длин, которые могут содержать биты заполнения, которые не являются старшими, 3) маркеры, значение которых определяется в шестнадцатеричном коде в стандарте JPEG2000 и которые импортируются в шестнадцатеричном коде в XML-документ. Этот импорт в шестнадцатеричном коде составляет третий режим импорта. Первый режим импорта содержит преобразование двоичных данных в знаки, которые принадлежат предварительно определенному набору знаков, используемому XML. С этой целью предпочтительно используется способ кодирования, известный под названием Во втором режиме импорта вместо преобразования двоичных данных в знаки для вставки их непосредственно в XML-документ, в XML-документ вводятся указатели на область двоичного файла, содержащую упомянутые двоичные данные. XML-документ тогда становится зависимым от упомянутого двоичного файла. В языке описания схемы XML определяется тип данных в качестве триплета, который содержит: – набор значений, называемый пространством значений, – набор лексических представлений, называемый лексическим пространством, – набор аспектов, причем аспект соответствует ограничению, наложенному на пространство значений. Для осуществления изобретения кодирование данных, которые записаны в потоке битов, должно быть однозначным и неявным. Непосредственно используются некоторые типы данных, которые ранее имели место в схеме XML и являются однозначными и неявными: это в случае, например, типов данных Согласно изобретению также используется тип данных 1) К нему добавляется аспект, относящийся к флагу останова, названный 2) Новое возможное значение добавляется к аспекту Этот модифицированный тип данных называется Этот модифицированный тип данных, который является обобщенным типом, затем используется для получения других типов конкретных данных, которые могут быть найдены в потоке битов XML. Например, как указано в Приложении В, тип Хотя ссылка делается на Приложение А, считается, что другие элементы имеют тип, получаемый из Изобретение также предусматривает добавление нового типа данных, предназначенного для использования для двоичных слов с предварительно определенной длиной. Этот новый тип данных называется Как указано в Приложении В, этот новый тип данных, который является обобщенным типом данных, затем используется для получения конкретных типов данных, которые можно найти в потоке JPEG2000. Например, тип данных, названный <11b>, который получается из обобщенного типа данных И тип данных, названный <5b3p>, который также получен из обобщенного типа данных Co ссылкой на Приложение А устанавливается, что используется тип данных <11b>, например, для элемента, названного
и что тип данных <5b3p> используется, например, для элемента, называемого
С точки зрения структуры в изобретении используются следующие инструментальные средства, которые уже существуют в схеме XML: – простые и комплексные типы данных – элементы – групповые модели – соединители Синтаксический анализатор В3 считывает поток В1 битов со схемой В2 для создания древовидного представления В4 потока В1 битов. Это древовидное представление В4 является экземпляром потока В2. Оно создается рекурсивно посредством интерпретации соединителей, найденных в схеме. Более конкретно, соединитель когда синтаксический анализатор находит соединитель
Согласно этому определению элемент Соединитель Элемент, обнаруженный в потоке битов, не соответствует элементу, поиск которого осуществляется, когда схема определяет фиксированное значение для этого элемента или для элемента из подэлементов, которые он содержит, и когда это значение не соответствует тому значению, которое обнаруживается в потоке битов. Например, когда синтаксический анализатор пытается реализовать элемент Соединитель Согласно этому определению элемент Хотя в Приложении А не приведен никакой пример, также может быть использован соединитель Использование переменной позволяет, например, определить количество элементов посредством параметра вместо определения его постоянным значением. Когда значение параметра дается в начале потока битов и информирует о структуре или содержании остальной части потока битов, то значение переменной определяется посредством использования синтаксиса языка Xpath. Например, в формате JPEG2000 количество компонентов Изобретение также предусматривает добавление новой групповой модели В качестве примера, формат JPEG2000 обеспечивает то, что присутствие некоторых элементов или что тип данных зависит от значения параметра, который указывается в начале потока битов. Это, в особенности, проявляется в элементе В элементе Когда синтаксический анализатор считывает поток битов, он последовательно создает XML-дерево. Когда он встречает переменную в схеме, например в атрибуте Необходимо отметить, что язык XML позволяет определять свои собственные расширения. Первый вариант выполнения изобретения, таким образом, содержит добавление новых инструментов, предлагаемых изобретением в качестве расширений для существующего языка описания схемы XML. Другой вариант выполнения изобретения содержит полное переопределение нового языка, который применяет инструменты схемы XML и добавляет к нему новые инструменты, предлагаемые изобретением. На фиг.3 показан пример системы передачи в соответствии с изобретением. Система передачи, показанная на фиг.3, содержит сервер SV и множество клиентов СТ. Сервер SV и клиенты СТ связаны со Всемирной паутиной Интернета. Сервер SV содержит средство MEM памяти и обрабатывающее средство PROC. Средство памяти содержит, в особенности, схему В2, первый поток В1 битов и компьютерную программу PG1 для осуществления способа синтаксического анализа согласно изобретению для получения первого документа В4, который представляет первый поток В1 битов и который представляет собой экземпляр схемы В2. Средство MEM памяти также предпочтительно содержит компьютерную программу PG2 для осуществления способа создания второго потока В’1 битов из документа В’4, представляющего его, и из схемы В2. В качестве примера документ В’4 получается в результате применения преобразования к документу В4, причем это преобразование зависит от профиля клиента, который ранее запросил передачу потока битов.
Формула изобретения
1. Структура (В2) данных, которая образует схему для преобразования потока (В1) битов в электронный документ (В4) на языке разметки или наоборот, упомянутая структура данных определяет один или более типов данных, которые могут иметь один или более аспектов, причем аспект соответствует ограничению, наложенному на набор значений типа данных, и содержит множество элементов, для которых она описывает имя, тип данных, расположение с перекрытием, порядок и предварительно определенное или случайное количество появлений, причем появление элемента является обязательным или факультативным, упомянутая схема определяет один или более типов данных, которые соответствуют двоичным словам предварительно определенной длины или длин и которые имеют, по меньшей мере, аспект, относящийся к упомянутой длине, отличающаяся тем, что упомянутая структура данных определяет одну или более переменных, составляемых путем доступа к данным, причем она содержит одно или несколько условных ветвлений для описания различных структур или возможного содержимого как функции значения упомянутых одной или более переменных, и факультативно имеет, по меньшей мере, один из следующих характеристических признаков: упомянутая структура данных определяет тип данных, который соответствует двоичным сегментам неопределенной длины и который имеет, по меньшей мере, аспект, указывающий, должны ли двоичные сегменты быть преобразованы и введены в электронный документ или двоичные сегменты должны содержаться в двоичном файле и указатели на двоичный файл должны быть введены в электронный документ, и аспект, относящийся к флагу останова двоичного сегмента, причем структура данных определяет аспект, относящийся к заполняющим битам, содержащимся в упомянутых двоичных словах предварительно определенной длины или длин. 2. Способ преобразования потока (В1) битов в электронный документ (В4) на языке разметки, причем поток битов содержит данные, которые имеют структуру и содержимое согласно некоторому формату, причем электронный документ является древовидным представлением упомянутого потока битов, причем упомянутый способ содержит этапы A) считывания структуры (В2) данных по п.1, B) поиска в упомянутом потоке битов данных, которые соответствуют элементам, содержащимся в упомянутой структуре данных, C) формирования экземпляра упомянутой структуры данных, который содержит данные, найденные в упомянутом потоке битов, и который составляет упомянутое древовидное представление. 3. Компьютерная программа (PG1), содержащая команды, которая при загрузке в процессор (SV) обеспечивает выполнение процессором способа преобразования по п.2. 4. Способ формирования потока (В1) битов согласно некоторому формату из электронного документа (В4′) на языке разметки, который представляет собой древовидное представление упомянутого потока битов и который содержит данные, в особенности данные, импортируемые посредством использования преобразования данных таким образом, чтобы ввести данные в электронный документ, или посредством использования указателей на двоичный файл, который содержит данные, причем способ содержит этапы A) считывания упомянутого документа, B) параллельного считывания структуры данных (В2) по п.1, которая обобщенным образом описывает упомянутый формат, C) кодирования упомянутых данных как функции определяемого типа, D) составления потока (В1) битов из кодированных данных. 5. Компьютерная программа (PG1), содержащая команды, которая при загрузке в процессор (SV) обеспечивает выполнение процессором способа формирования потока битов по п.4. 6. Обрабатывающий блок (SV), который содержит средство памяти (MEM) для хранения структуры данных (В2) по п.1 и средство памяти (MEM) для хранения программы (PG1), которая содержит команды для осуществления способа синтаксического анализа потока (В1) битов, основанного на упомянутой структуре данных, для формирования документа (В4) на языке разметки, который представляет упомянутый поток битов, который является экземпляром упомянутой структуры данных, и/или программы (PG2), которая содержит команды для осуществления способа формирования потока (В1) битов, основанного на упомянутой структуре (В2) данных и на документе (В4′), представляющем упомянутый поток битов, который является экземпляром упомянутой структуры данных. 7. Система передачи, содержащая, по меньшей мере, объект источника и, по меньшей мере, объект адресата, причем упомянутый объект источника содержит обрабатывающий блок (SV) по п.6.
РИСУНКИ
|
||||||||||||||||||||||||||

 type=”jp2:11b”/>
type=”jp2:11b”/>