Патент на изобретение №2294011
|
||||||||||||||||||||||||||
(54) СПОСОБ И УСТРОЙСТВО ДЛЯ ОБЕСПЕЧЕНИЯ ИЕРАРХИЧЕСКОГО ИНДЕКСА СТРУКТУРЫ ДАННЫХ МОДЕЛИ ЯЗЫКА
(57) Реферат:
Изобретение относится к статистическим моделям языка, используемых в системах распознавания речи. Техническим результатом является уменьшение памяти, необходимой для хранения структуры данных модели языка. Индексы слов биграмм сохраняют в виде общей основы с характерным смещением. В одном варианте выполнения объем памяти, необходимый для последовательно хранения индексов слов биграмм, сравнивают с объемом памяти, необходимым для хранения индексов слов биграмм в виде общей основы с характерным смещением. Затем сохраняют индексы слов биграмм для минимизации размера файла данных модели языка. 7 н. и 13 з.п. ф-лы, 4 ил.
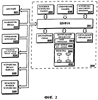
Область техники Данное изобретение относится в целом к области статистических моделей языка, используемым в системах распознавания речи (CSR), в частности касается способа и устройства для более эффективной организации таких моделей. Уровень техники Известные из уровня техники системы распознавания слитной речи работают посредством формирования ряда гипотез последовательности слов и вычисления вероятности каждой последовательности слов. Последовательности с низкой вероятностью отсекаются, в то время как последовательности с высокой вероятностью продолжаются. Когда декодирование речевого ввода завершается, то последовательность с наивысшей вероятностью принимается в качестве результата распознавания. Говоря обобщенно, используется отсчет на основе вероятности. Отсчет последовательностей является суммой акустического отсчета (суммы акустических логарифмов вероятности для всех минимальных единиц речи – звуков или слогов) и лингвистического отсчета (суммы лингвистических логарифмов вероятности для всех слов в речевом вводе). В системах распознавания слитной речи обычно используют статистическую n-граммную модель языка для разработки статистических данных. Такая модель вычисляет вероятность наблюдения n последовательных слов в заданной области, поскольку на практике можно предположить, что текущее слово зависит от n предшествующих ему слов. Униграммная модель вычисляет P(w), которая является вероятностью для каждого слова w. Биграммная модель использует униграммы и условную вероятность P(w2|w1), которая является вероятностью слова w2, при условии, что предшествующее слово является словом w1, для каждого слова w1 и w2. Триграммная модель использует униграммы, биграммы и условную вероятность P(w3|w2,w1), которая является вероятностью слова w3, при условии, что два предшествующих слова являются w1 и w2, для каждого слова w3, w2 и w1. Величины биграммных и триграммных вероятностей вычисляют во время обучения модели языка, что требует огромного количества текстовых данных, текстового корпуса. Вероятность можно точно оценивать, если последовательность слов появляется сравнительно часто в данных обучения. Такие вероятности являются условно существующими. Для n-граммных вероятностей, которые не существуют, используют возвратную формулу для приближения величины. Такие статистические модели языка являются особенно полезными для систем распознавания слитной речи с большим словарным запасом, которые распознают произвольную речь (задача речевого ввода). Например, теоретически для словаря, состоящего из 50000 слов, будет 50000 униграмм, миллиарды (500002) биграмм и более 100 триллионов (500003) триграмм. На практике числа значительно уменьшаются, поскольку биграммы и триграммы существуют только для пар слов и троек слов, которые появляются относительно часто. Например, в английском языке для хорошо известной задачи Уол Стрит Джорнал (WSJ) со словарем в 20000 слов, в модели языка используется лишь семь миллионов биграмм и 14 миллионов триграмм. Эти числа зависят от конкретного языка, области задачи и размера корпуса текста, используемого для разработки модели языка. Тем не менее, это все еще огромное количество данных, и размер базы данных модели языка и способ доступа к данным оказывает значительное воздействие на жизненность системы распознавания речи. Ниже приводится описание типичной структуры данных модели языка со ссылками на фиг.1. На фиг.1 показана триграммная структура данных модели языка, согласно уровню техники. Структура 100 данных, показанная на фиг.1, содержит униграммный уровень 105, биграммный уровень 110 и триграммный уровень 115. Запись P(w3|w2,w1), где w3, w2 и w1 являются индексами слов, обозначает вероятность слова w3, при условии, что два предшествующих слова являются словом w1 и следующим за ним словом w2. Для определения такой вероятности слово w1 расположено на униграммном уровне 105, при этом униграммный уровень содержит связь с биграммным уровнем. Получают указатель к соответствующему биграммному уровню 110 и определяют биграмму, соответствующую w1|w2, при этом биграммный узел содержит связь с триграммным уровнем. Отсюда получают указатель к соответствующему триграммному уровню 115 и извлекают вероятность P(w3|w2,w1) триграммы. Обычно, униграммы, биграммы и триграммы структуры данных модели языка, согласно уровню техники, все хранятся в простом последовательном порядке и разыскиваются последовательно. Поэтому, при поиске биграммы получают, например, связь с биграммным уровнем из униграммного уровня, и выполняют последовательный поиск биграммы для получения индекса для второго слова. Системы распознавания речи часто осуществляются в небольших, компактных вычислительных системах, таких как персональные компьютеры, компактные персональные компьютеры и даже переносные компьютерные системы. Такие системы имеют ограниченные возможности по скорости обработки и объему хранения данных, так что желательно уменьшить память, необходимую для хранения структуры данных модели языка. Краткое описание чертежей Настоящее изобретение описано с использованием примера, не ограничивающего его. Пример излагается со ссылками на прилагаемые чертежи, на которых подобные элементы обозначены одинаковыми позициями и на которых изображено: фиг.1 – триграммная структура данных модели языка, согласно уровню техники; фиг.2 – блок-схема примера выполнения вычислительной системы 200 для осуществления базы данных модели языка для системы распознавания слитной речи, согласно данному изобретению; фиг.3 – иерархическая структура хранения, согласно варианту выполнения данного изобретения; и фиг.4 – графическая схема процесса, согласно варианту выполнения данного изобретения. Подробное описание вариантов осуществления изобретения Ниже приводится описание улучшенной структуры данных модели языка. Способ согласно данному изобретению уменьшает размер файла данных модели языка. В одном варианте осуществления изобретения информацию управления (например, индекс слова) для биграммного уровня сжимают с использованием иерархической биграммной структуры хранения. Данное изобретение направлено на получение технического преимущества от того факта, что распределение индексов слов для биграмм конкретной униграммы часто находятся внутри 255 индексов друг от друга (то есть, смещение может быть представлено одним байтом). Это позволяет хранить множество индексов слов в виде основы из 2 байт со смещением в один байт, в противоположность использованию трех байтов для хранения каждого индекса слова. Схем сжатия данных, согласно данному изобретению, применима, в частности, к биграммному уровню. Это объясняется тем, что каждая униграмма имеет в среднем приблизительно 300 биграмм по сравнению с приблизительно тремя триграммами для каждой биграммы. То есть, на уровне биграмм имеется достаточно информации для практического осуществления иерархической структуры хранения. В одном варианте выполнения используется иерархическая структура для хранения биграммной информации только тех униграмм, которые имеют особенно большое число соответствующих биграмм. Биграммную информацию для униграмм, имеющих непрактично малое количество биграмм, сохраняется последовательно, согласно уровню техники. Способ согласно данному изобретению можно распространять на другие применения поиска на основе индексов, имеющих большое число индексов, где каждый индекс требует значительного объема памяти. На фиг.2 показана блок-схема примера выполнения вычислительной системы 200 для осуществления базы данных модели языка для системы распознавания слитной речи, согласно данному изобретению. Различные способы вычисления и сравнения памяти для хранения данных и иерархическую структуру файлов индексов слов, описываемых здесь, можно осуществлять и использовать внутри вычислительной системы 200, которая может представлять компьютер общего пользования, переносной компьютер или другие подобные устройства. Компоненты вычислительной системы 200 приведены в качестве примера, при этом один или более компонентов могут быть опущены или добавлены. Например, можно использовать одно или более устройств памяти для вычислительной системы 200. Как показано на фиг.2, вычислительная система 200 содержит центральный процессор 202 и сигнальный процессор 203, соединенный с дисплейной схемой 205, основной памятью 204, статической памятью 206 и устройством 207 массовой памяти через шину 201. Вычислительная система 200 может быть также соединена с дисплеем 221, клавиатурой 222 ввода, устройством 223 управления курсором, устройством 224 для получения твердых копий, устройствами 225 ввода/вывода и звуковым/речевым устройством 226 через шину 201. Шина 201 является стандартной системной шиной для передачи информации и сигналов. Центральный процессор 202 и сигнальный процессор 203 являются блоками обработки для вычислительной системы 200. Центральный процессор 202 или сигнальный процессор 203 или оба можно использовать для обработки информации и/или сигналов для вычислительной системы 200. Центральный процессор 202 содержит блок 231 управления, блок 232 арифметической логики и несколько регистров 233, которые используются для обработки информации и сигналов. Сигнальный процессор 203 может содержать компоненты, аналогичные компонентам центрального процессора 202. Основное устройство 204 памяти может быть, например, оперативным запоминающим устройством (памятью с произвольным доступом RAM) или другим устройством динамичной памяти для хранения информации или команд (программных кодов), которые используются центральным процессором 202 или сигнальным процессором 203. Основное устройство 204 памяти может хранить временные переменные или другую промежуточную информацию во время выполнения команд центральным процессором 202 или сигнальным процессором 203. Статическая память 206 может быть, например, постоянным запоминающим устройством (ROM) и/или другим статическим устройством хранения, для хранения информации или команд, которые могут также использоваться центральным процессором 202 или сигнальным процессором 203. Устройство 207 массового хранения может быть, например, приводом жесткого или гибкого диска или приводом оптического диска для хранения информации или команд для вычислительной системы 200. Дисплей 221 может быть, например, катодно-лучевой трубкой или жидкокристаллическим дисплеем. Дисплей 221 отображает информацию или графическую информацию для пользователя. Вычислительная система 200 может взаимодействовать с дисплеем 221 через интерфейс-дисплейную схему 205. Клавиатура 222 ввода является буквенно-цифровым устройством ввода с аналого-цифровым преобразователем. Устройство 223 управления курсором может быть, например, мышью, шаровым манипулятором или клавишами управления курсором для управления перемещением объекта на дисплее 221. Устройство 224 для получения твердых копий может быть, например, лазерным принтером для печати информации на бумаге, пленке или другом подобном носителе. С вычислительной системой 200 может быть соединено несколько устройств 225 ввода/вывода. Иерархическую структуру файлов индексов слов согласно данному изобретению можно осуществлять с помощью аппаратурного обеспечения и/или программного обеспечения, содержащегося внутри вычислительной системы 200. Например, центральный процессор 202 или сигнальный процессор 203 могут выполнять коды или команды, хранящиеся в машинно-считываемом носителе информации, например, в основном устройстве 204 памяти. Машинно-считываемый носитель информации может содержать механизм, который обеспечивает (т.е. хранит и/или передает) информацию в считываемом машиной виде, такой как компьютер или цифровое устройство обработки. Например, машинно-считываемый носитель информации может включать постоянную память, оперативную память, средство хранения данных на магнитном диске, средство хранения данных на оптическом диске, устройства флэш-памяти. Коды или команды могут быть представлены сигналами несущей частоты, инфракрасными сигналами, цифровыми сигналами и другими подобными сигналами. На фиг.3 показана иерархическая структура хранения данных согласно одному варианту выполнения данного изобретения. Иерархическая структура 300, показанная на фиг.3, содержит униграммный уровень 310, биграммный уровень 320 и триграммный уровень 330. На униграммном уровне 310, униграммная вероятность и возвратный вес – оба являются индексами в таблице величин и не подлежат дальнейшему сокращению. В среднем униграммы имеют 300 биграмм, что делает иерархическое хранение практичным, однако отдельные униграммы могут иметь слишком мало биграмм для оправдания рабочих полей иерархической структуры. Униграммы разделены на две группы: униграммы 311 с достаточным числом биграмм, для того чтобы иерархическое хранение данных биграмм было практичным, и униграммы 312 со слишком малым числом соответствующих биграмм, для того чтобы иерархическое хранение было практичным. Например, для задачи Уол Стрит Джорнал (WSJ), имеющей 19958 униграмм, 16738 униграмм имеют достаточно биграмм для оправдания иерархического хранения, и поэтому биграммная информация, соответствующая этим униграммам, хранится в иерархическом порядке 321 биграмм. Такие униграммы содержат биграммную связь с иерархическим биграммным порядком 321. Остальные 3220 униграмм не имеют достаточного числа биграмм для оправдания иерархического хранения, и поэтому соответствующая биграммная информация хранится в простом последовательном порядке. Эти униграммы содержат биграммную связь с последовательным биграммным порядком 322. В типичном текстовом корпусе имеется очень немного униграмм, которые не имеют биграмм, и поэтому они не хранятся отдельно. На биграммном уровне 320 каждая биграмма (т.е. те, которые имеют соответствующие триграммы) имеет связь с триграммным уровнем 330. Для типичного текстового корпуса имеется сравнительно больше биграмм, которые не имеют триграмм, чем униграмм, которые не имеют биграмм. Например, в задаче Уол Стрит Джорнал (WSJ), имеющей 6850083 биграмм, 3414195 биграмм имеют соответствующие триграммы, а 3435888 биграмм не имеют соответствующих триграмм. В одном варианте выполнения биграммы, которые не имеют триграмм, хранятся отдельно, что обеспечивает устранение четырех байтного поля связей триграмм в этих случаях. Обычно, индексы слов биграмм для одной униграммы являются очень близкими друг другу. Близость этих индексов слов является особенностью, присущей языку. Это распределение существующих индексов биграмм позволяет разделять индексы на группы, так что смещение между первым индексом слов биграмм и последним индексом слов биграмм составляет менее 256. Таким образом, это смещение можно сохранять в одном байте. Это позволяет представлять, например, индекс слова из трех байт в виде суммы основы из двух байт и смещения в один байт. Таким образом, поскольку два байта высокого порядка индекса слова повторяются для нескольких биграмм, то эти два байта можно исключить из хранения для некоторых групп биграмм. Такое хранение согласно данному изобретению обеспечивает значительное сжатие на биграммном уровне. Как указывалось выше, это не относится к биграммам, соответствующим каждой униграмме. Согласно данному изобретению вычисляют объем хранения для определения, можно ли его сократить за счет иерархического хранения. Если нет, то индексы биграмм для конкретной униграммы хранят последовательно согласно уровню техники. На фиг.4 показана графическая схема процесса согласно варианту выполнения данного изобретения. Процесс 400, показанный на фиг.4, начинается операцией 405, в которой оценивают биграммы, соответствующие заданной униграмме, для определения объема памяти, необходимого для простой схемы последовательного хранения. В операции 410 требования к памяти для последовательного хранения сравнивают с требованиями к памяти для хранения иерархической структуры данных. Если не имеется сжатия данных (т.е. сокращения требований к памяти), то индексы слов биграмм сохраняют последовательно в операции 415. Если иерархическое хранение данных уменьшает требования к памяти, то индексы слов биграмм сохраняют в виде общей основы с характерным смещением в операции 420. Например, для индекса слова в три байта, общая основа может состоять из двух байтов со смещением в один байт. Степень сжатия зависит от вероятностей биграмм в модели языка. Модель языка, используемая в задаче Уол Стрит Джорнал (WSJ), имеет приблизительно шесть миллионов вероятностей биграмм, что требует объема памяти приблизительно 97 МБайт. Осуществление иерархической структуры хранения, согласно данному изобретению, обеспечивает сжатие в 32% индексов биграмм, что сокращает общий объем памяти на 12 МБайт (т.е. в целом приблизительно на 11%). Для других моделей языка степень сжатия может быть выше. Например, осуществление иерархической структуры хранения биграмм для модели языка для задачи 863 китайского языка обеспечивает степень сжатия индексов биграмм приблизительно на 61,8%. Это дает полную степень сжатия в 26,7% (т.е. 70,3 МБайт сжимаются до 51,5 МБайт). Это сокращение файла данных модели языка значительно уменьшает требования к объему памяти и к времени обработки данных. Технология сжатия согласно данному изобретению не является практичной на триграммном уровне, поскольку здесь имеется, в среднем, только приблизительно три триграммы на одну биграмму для модели языка для задачи Уол Стрит Джорнал (WSJ). Триграммный уровень также не содержит возвратного веса или полей связи, поскольку нет более высокого уровня. Данный патент можно распространить на использование в других сценариях структурированного поиска, где индекс слова является ключом; каждый индекс слова требует значительного объема памяти; и число индексов слов является огромным. Хотя изобретение описано применительно к нескольким вариантам выполнения и иллюстративным фигурам, для специалистов в данной области техники понятно, что изобретение не ограничивается приведенными вариантами выполнения или конкретными фигурами. В частности, изобретение может быть реализовано в нескольких альтернативных вариантах выполнения, которые обеспечивают иерархическую структуру данных для уменьшения размера базы данных модели языка. Поэтому следует понимать, что способ и устройство согласно изобретению могут быть реализованы с различными модификациями и изменениями, оставаясь в пределах прилагаемой формулы изобретения. Таким образом, настоящее описание следует рассматривать как иллюстрацию, а не ограничение изобретения.
Формула изобретения
1. Способ хранения множества индексов слов биграмм, в котором каждый индекс слов биграмм соответствует заданной униграмме, в виде общей основы с характерным смещением, при этом индексы слов биграмм являются частью триграммной модели языка системы распознавания слитной речи, и модель языка моделирует задачу Уол Стрит Джорнал, причем способ содержит следующие этапы: сопоставление объема памяти, необходимого для последовательного хранения множества индексов слов биграмм, и объема памяти, необходимого для хранения иерархической структуры данных множества индексов слов биграмм, и осуществление хранения иерархической структуры данных множества индексов слов биграмм, если объем памяти, необходимый для хранения иерархической структуры данных множества индексов слов биграмм, оказался меньше объема памяти, необходимого для последовательного хранения множества индексов слов биграмм. 2. Способ по п.1, отличающийся тем, что хранение иерархической структуры данных множества индексов слов биграмм включает хранение каждого индекса слов биграмм в виде общей основы с характерным смещением. 3. Способ по п.2, отличающийся тем, что каждый индекс слов биграммы имеет длину в три байта, общая основа имеет длину в два байта и характерное смещение имеет длину в один байт. 4. Машинно-считываемый носитель информации, на который записаны команды, при выполнении которых процессором последний выполняет способ хранения множества индексов слов биграмм, при этом индексы слов биграмм являются частью триграммной модели языка системы распознавания слитной речи, и модель языка моделирует задачу Уол Стрит Джорнал, причем способ содержит следующие этапы: сопоставление объема памяти, необходимого для последовательного хранения множества индексов слов биграмм, и объема памяти, необходимого для хранения иерархической структуры данных множества индексов слов биграмм; и осуществление хранения иерархической структуры данных множества индексов слов биграмм, если объем памяти, необходимый для хранения иерархической структуры данных множества индексов слов биграмм, оказался меньше объема памяти, необходимого для последовательного хранения множества индексов слов биграмм. 5. Машинно-считываемый носитель информации по п.4, отличающийся тем, что хранение иерархической структуры данных множества индексов слов биграмм включает хранение каждого индекса слов биграмм в виде общей основы с характерным смещением. 6. Машинно-считываемый носитель информации по п.5, отличающийся тем, что каждый индекс слов биграммы имеет длину в три байта, общая основа имеет длину в два байта и характерное смещение имеет длину в один байт. 7. Устройство для хранения множества индексов слов биграмм, содержащее процессор и соединенное с ним устройство памяти, отличающееся тем, что в устройстве памяти хранятся команды, при выполнении которых процессором процессор осуществляет сопоставление объема памяти, необходимого для последовательного хранения множества индексов слов биграмм, при этом индексы слов биграмм являются частью триграммной модели языка системы распознавания слитной речи, модель языка моделирует задачу Уол Стрит Джорнал, и объема памяти, необходимого для хранения иерархической структуры данных множества индексов слов биграмм, и осуществляет хранение иерархической структуры данных множества индексов слов биграмм, если объем памяти, необходимый для хранения иерархической структуры данных множества индексов слов биграмм, оказался меньше объема памяти, необходимого для последовательного хранения множества индексов слов биграмм. 8. Устройство по п.7, отличающееся тем, что хранение иерархической структуры данных множества индексов слов биграмм включает хранение индексов слов биграмм, соответствующих заданной униграмме, в виде общей основы с характерным смещением. 9. Устройство по п.8, отличающееся тем, что индекс слов биграммы имеет длину в три байта, общая основа имеет длину в два байта и характерное смещение имеет длину в один байт. 10. Способ хранения множества индексов слов биграмм, состоящий в том, что хранят множество индексов слов биграмм, соответствующих заданной униграмме, в виде общей основы с характерным смещением, при этом используют индексы слов биграмм, которые являются частью триграммной модели языка системы распознавания слитной речи, при этом модель языка моделирует задачу 863 китайского языка. 11. Способ по п.10, отличающийся тем, что каждый индекс слов биграммы имеет длину в три байта, общая основа имеет длину в два байта и характерное смещение имеет длину в один байт. 12. Способ хранения множества индексов слов биграмм, в котором каждый индекс слов биграмм соответствует заданной униграмме, в виде общей основы с характерным смещением, причем индексы слов биграмм являются частью триграммной модели языка системы распознавания слитной речи, модель языка моделирует задачу 863 китайского языка, при этом способ содержит следующие этапы: сопоставление объема памяти, необходимого для последовательного хранения множества индексов слов биграмм, и объема памяти, необходимого для хранения иерархической структуры данных множества индексов слов биграмм; и осуществление хранения иерархической структуры данных множества индексов слов биграмм, если объем памяти, необходимый для хранения иерархической структуры данных множества индексов слов биграмм, оказался меньше объема памяти, необходимого для последовательного хранения множества индексов слов биграмм. 13. Способ по п.12, отличающийся тем, что хранение иерархической структуры данных множества индексов слов биграмм включает хранение каждого индекса слов биграмм в виде общей основы с характерным смещением. 14. Способ по п.13, отличающийся тем, что каждый индекс слов биграммы имеет длину в три байта, общая основа имеет длину в два байта и характерное смещение имеет длину в один байт. 15. Машинно-считываемый носитель информации, на который записывают команды, при выполнении которых процессором последний выполняет способ хранения множества индексов слов биграмм, при этом индексы слов биграмм являются частью триграммной модели языка системы распознавания слитной речи, модель языка моделирует задачу 863 китайского языка, причем способ содержит следующие этапы: сопоставление объема памяти, необходимого для последовательного хранения множества индексов слов биграмм, и объема памяти, необходимого для хранения иерархической структуры данных множества индексов слов биграмм; и осуществление хранения иерархической структуры данных множества индексов слов биграмм, если объем памяти, необходимый для хранения иерархической структуры данных множества индексов слов биграмм, оказался меньше объема памяти, необходимого для последовательного хранения множества индексов слов биграмм. 16. Машинно-считываемый носитель информации по п.15, отличающийся тем, что хранение иерархической структуры данных множества индексов слов биграмм включает хранение каждого индекса слов биграмм в виде общей основы с характерным смещением. 17. Машинно-считываемый носитель информации по п.16, отличающийся тем, что каждый индекс слов биграммы имеет длину в три байта, общая основа имеет длину в два байта и характерное смещение имеет длину в один байт. 18. Устройство для хранения множества индексов слов биграмм, включающее процессор и соединенное с ним устройство памяти, отличающееся тем, что в устройстве памяти хранятся команды, при выполнении которых процессором последний совершает следующие действия: сопоставляет объем памяти, необходимый для последовательного хранения множества индексов слов биграмм, при этом индексы слов биграмм являются частью триграммной модели языка системы распознавания слитной речи, и модель языка моделирует задачу 863 китайского языка, определяет объем памяти, необходимый для хранения иерархической структуры данных множества индексов слов биграмм, и осуществляет хранение иерархической структуры данных множества индексов слов биграмм, если объем памяти, необходимый для хранения иерархической структуры данных множества индексов слов биграмм, оказался меньше объема памяти, необходимого для последовательного хранения множества индексов слов биграмм. 19. Устройство по п.18, отличающееся тем, что хранение иерархической структуры данных множества индексов слов биграмм включает хранение индексов слов биграмм, соответствующих заданной униграмме, в виде общей основы с характерным смещением. 20. Устройство по п.19, отличающееся тем, что индекс слов биграммы имеет длину в три байта, общая основа имеет длину в два байта и характерное смещение имеет длину в один байт.
РИСУНКИ
|
||||||||||||||||||||||||||