Патент на изобретение №2276810
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
(54) СПОСОБ И УСТРОЙСТВО ДЛЯ ДИНАМИЧЕСКОЙ РЕГУЛИРОВКИ ЛУЧА В ПОИСКЕ ПО ВИТЕРБИ
(57) Реферат:
Изобретение относится к распознаванию речи и, более конкретно, к способу и устройству для динамической регулировки луча в поиске по Витерби. Его применение позволяет получить технический результат в виде повышения надежности распознавания речи. Этот результат достигается благодаря тому, что способ включает в себя выбор начальной ширины луча, выяснение того, изменяется ли значение вероятности на кадр, динамическую регулировку ширины луча, декодирование входного речевого сигнала, при этом ширина луча динамически регулируется. Также предлагается устройство, включающее в себя процессор, компонент для распознавания речи, соединенный с процессором, память соединенную с процессором. При этом компонент для распознавания речи динамически регулирует ширину луча с целью декодирования входного речевого сигнала. 6 н. и 24 з.п. ф-лы, 6 ил., 4 табл.
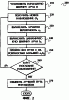
Предпосылки изобретения Область техники, к которой относится изобретение Изобретение относится к распознаванию речи и, более конкретно, к способу и устройству для динамической регулировки луча в поиске по Витерби. Уровень техники Распознавание речи или голоса стало очень широко использоваться для повышения эффективности работы. Для распознавания человеческого голоса в процессе распознавания речи используются несколько технологий. Также распознавание речи используется для преобразования цифровых аудиосигналов, поступающих от устройств, таких как звуковая карта персонального компьютера (ПК), в распознанную речь. Упомянутые сигналы могут проходить через несколько стадий, в которых производятся разного рода математические и статистические преобразования, цель которых состоит в определении того, что на самом деле было сказано. Многие приложения, выполняющие распознавание речи, имеют базы данных, содержащие тысячи частот или “фонем” (также называемых “фонами” в системах распознавания речи). Фонема – это наименьшая единица речи на некотором языке или диалекте (то есть наименьшая единица звука, по которой можно различить два слова языка). Произнесение одной фонемы отличается от произнесения другой фонемы. Таким образом, если в слове одну фонему заменить другой, то слово будет иметь другой смысл. Например, если “В” в слове “bat” заменить на фонему “R”, то получим новое слово: “rat”. Базы данных, содержащие фонемы, используются для сравнения с эталонными диапазонами звуковых частот. Например, если входящая частота звучит как “Т”, то приложение попытается сравнить ее с соответствующей фонемой из базы данных. Также на произношение могут влиять соседние фоны, называемые контекстом. Например, “Т” в слове “that” звучит не так, как “Т” в “truck”. Фону с фиксированным левым (правым) контекстом обычно называют “левой (правой) бифоной”. Фону с фиксированным левым и правым контекстом обычно называют “трифоной”. База данных фонем могут содержать для каждой фонемы несколько записей, соответствующих би- и трифонам. Каждая фонема снабжается номером записи, который затем приписывается входящему сигналу. Может существовать настолько много вариантов звуков, получающихся при различном произнесении слов, что практически невозможно добиться точного совпадения входящего сигнала и записи в базе данных. Более того, различные люди могут по-разному произносить одно и тоже слово. Далее, окружающая обстановка также вносит свой вклад из-за шума. Следовательно, приложение должно использовать сложные технические приемы для аппроксимации входящего сигнала и определения, какие используются фонемы. Другая проблема распознавания речи заключается в определении момента, когда одна фонема (или более маленькая единица) заканчивается и начинается следующая. Для решения подобных задач, может применяться техника, называемая скрытой марковской моделью (СММ). СММ предусматривает подход сопоставления с эталоном при распознавании речи. СММ в общем случае определяется следующими элементами: во-первых, числом N состояний модели; затем, матрицей переходных вероятностей А, где аij – вероятность того, что процесс перейдет из состояния qi; в состояние qj в момент времени t=1, 2, …, причем в момент времени t – 1 процесс находился в состоянии qi распределение вероятности наблюдения Для того чтобы проводить распознавание речи с использованием СММ, языки обычно делятся на ограниченное количество фонем. Например, английский язык можно разбить примерно на 40-50 фонем. Тем не менее, необходимо заметить, что при использовании других единиц, таких как три-фоны, число таких единиц может равняться нескольким тысячам. Затем строится стохастическая модель для каждой единицы (то есть фоны). С учетом акустического наблюдения можно определить наиболее вероятную фонему, соответствующую наблюдению. Тем не менее, необходимо заметить, что при использовании контекстных единиц, таких как би-фоны или три-фоны, число указанных выше единиц может составлять несколько тысяч. Таким образом, для каждой единицы будет построена вероятностная модель. Способ определения наиболее вероятной фонемы, соответствующей акустическому наблюдению, использует оценку по Витерби (названо в честь A.J.Viterbi). Краткое описание чертежей Настоящее изобретение иллюстрируется с помощью примера и не ограничивается приведенными поясняющими чертежами, на которых одинаковые позиции обозначают одинаковые элементы. Фиг.1 изображает четыре шага типового алгоритма поиска по Витерби. Фиг.2 изображает блок-схему одной реализации настоящего изобретения, содержащей динамическую регулировку луча. Фиг.3 показывает блок-схему одной реализации настоящего изобретения, применяющей динамическую регулировку луча (когда существует достаточное количество активных путей) или декодирование N лучших (если слишком много или слишком мало активных путей). Фиг.4 иллюстрирует типовую систему, которая может быть использована для задач распознавания речи. Фиг.5 иллюстрирует реализацию данного изобретения, содержащую процесс динамической регулировки луча, входящий в систему. Фиг.6 изображает реализацию данного изобретения, содержащую устройство для динамической регулировки луча. Подробное описание изобретения В целом изобретение касается способа и устройства для динамической регулировки луча в поиске по Витерби. Далее, со ссылками на фигуры, будут описаны типичные реализации настоящего изобретения. Типичные реализации выбраны для того, чтобы проиллюстрировать изобретение и не должны рассматриваться в качестве какого-либо ограничения изобретения. Фиг.1 иллюстрирует четыре шага типового алгоритма поиска по Витерби. В данном методе сличаются акустическое наблюдение и стохастическая модель фонемы с целью оценки вероятности того, что данное наблюдение соответствует данной фонеме. При оценке по Витерби определяется единственная наилучшая последовательность состояний, то есть путь переходов из состояние в состояние, который дает наибольшую вероятность того, что наблюдение соответствует модели. Такая работа проводится для каждой из 40-50 фонем (или более мелких единиц, таких как три-фоны) английского языка. Таким образом определяется фонема, которая с наибольшей вероятностью соответствует акустическому наблюдению. Если акустическое наблюдение содержит более одной фонемы, например сказанное слово, то описанную выше процедуру можно повторить, чтобы определить множество фонем, наиболее соответствующих акустическому наблюдению. В системе распознавания речи, после того, как модель определена, например, декодирование слова “ask”, система выбирает все возможные продолжения, сцепляет СММи, соответствующие продолжениям и продолжает декодирование. Например, после декодирования второй три-фоны “AE-S+K”, система распознавания речи может выбрать три-фону “S-K+*” (где * обозначает любую другую фону). Затем, после декодирования некоторой части входных данных (например, соответствующей предложению или нескольким словам), система распознавания речи выбирает наилучшие гипотезы в качестве результата. Алгоритм Витерби обычно используется при распознавании речи с СММ. Алгоритм Витерби обычно используется для поиска наилучшей последовательности слов, соответствующей распознаваемой речи. Здесь соответствие выражается в терминах величин вероятности, и поиск ведется по всем возможным последовательностям слов. Для систем с большим словарем пространство для поиска резко возрастает. Более точно, пространство поиска возрастает как NL, где N – мощность словаря, a L – длина рассматриваемого предложения. Чтобы избежать экспоненциального увеличения поискового пространства в алгоритмах поиска, применяют процедуру регулировки луча. Это делается для удаления маловероятных гипотез или путей поиска. Поиск с использованием луча требует вычисления эталонной оценки, называемой наименьшей гранью (ВГ), представляющей собой логарифм вероятности наиболее вероятной гипотезы. Оценка представляет собой отрицательное число – логарифм значения вероятности; высокие оценки обычно означают малую вероятность и низкие оценки веса означают большие вероятности. При использовании регулируемого луча в системах непрерывного распознавания речи (НРР) применяется статическое значение, ширина луча, для регулирования множества значений вероятности (в соответствии с наибольшим значением вероятности), которое имеется у путей в некоторый момент времени. Четыре шага типового алгоритма поиска по Витерби – это шаг 110 предварительной обработки, шаг 120 инициализации, шаг 130 рекурсии и шаг 140 окончания. Необходимо заметить, что в системах распознавания речи шаг 110 предварительной обработки может еще не полностью закончить работу, а другие шаги уже начнут выполняться. Существует несколько причин начать выполнять другие шаги до завершения работы шага 110 предварительной обработки, такие как: все модели, рассматриваемые при распознавании речи, не известны до начала процесса распознавания из-за сцепления скрытых марковских моделей (СММ), которые зависят от промежуточных результатов процесса распознавания, невозможность составления списка всех последовательностей слов для непрерывного процесса распознавания речи или данные входных наблюдений для декодирования в реальном времени могут быть не доступны. Для каждой модели речи предварительная обработка 110:
инициализация 120:
рекурсия 130:
окончание 140:
где оценка
является приближением логарифма вероятности наиболее вероятного пути, проходящего вершину j в момент времени t и
где
Во время шага 110 предварительной обработки логарифмы значений вероятностей начальных состояний
где 1 и 1 переходные вероятности состояний aij, где 1 На шаге 120 инициализации вычисляются оценки путей На шаге 130 рекурсии оценки Во время шага 140 окончания по вычислениям, проделанным на шаге 130 рекурсии, определяется результат с наибольшей вероятностью (или наилучшая оценка пути) для каждой конкретной модели. Общая наилучшая оценка пути получается после сравнения наилучших оценок путей, полученных для каждой модели. В одной реализации настоящего изобретения, во время распознавания, механизм регулировки луча динамически изменяет ширину луча в зависимости от данных, что делается для улучшения эффективности. В начале распознавания речи целесообразно использовать более широкий луч, из-за неопределенности того, что было сказано, а по мере получения данных можно использовать более узкий луч. Другими словами луч с постоянной шириной может хорошо работать для одного фрагмента речи, но плохо – для середины речевого фрагмента или может быть слишком широким для других фрагментов речи, что приводит к обработке множества бесполезных гипотез. Таким образом, в соответствии с одной реализацией изобретения, способ регулировки луча динамически управляется шириной луча в зависимости от данных, полученных в ходе распознавания. Одна реализация данного изобретения будет описываться следующим образом. Пусть Фt обозначает множество активных путей времени t. Пусть Nt является числом путей в Фt. Пусть р(
Также пусть В некоторой реализации изобретения по Фt с шириной луча
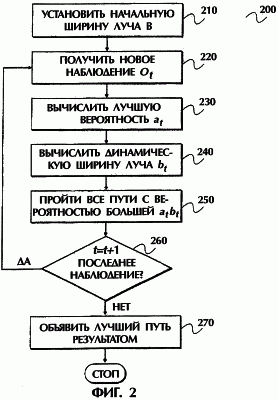
где и [b1, b2] – это границы изменения коэффициентов, данные границы определяются эвристически. Например, начальные значения Фиг.2 изображает блок-схему реализации настоящего изобретения, включающую в себя процесс 200 динамического регулирования луча. После начального тестирования системы распознавания речи выбирается множество оптимальных параметров. Выбор происходит на основе оптимальной скорости декодирования и ЧОС. Оптимальная скорость декодирования и ЧОС определяются на основе количества активных гипотез. Например, чем больше активных гипотез, тем меньше скорость декодирования и меньше количество ошибок. При поиске с лучом все гипотезы, которые хуже, при выбранной ширине луча, лучших гипотез, отбрасываются. В блоке 210 процесса 200 происходит присвоение ширине луча заданного заранее значения. Заранее заданное значение основано на множестве оптимальных параметров. В блоке 220 получают следующий речевой кадр (наблюдение). В блоке 230 определяют наилучшую вероятность для лучших гипотез. В блоке 240 определяют значение ширины луча с целью выбора гипотез для текущего речевого кадра. Если в блоке 240 устанавливают, что значение вероятности на кадр растет (вес растет медленнее), то процесс 200 уменьшает ширину луча по сравнению с заранее выбранной начальной шириной луча. Эта уменьшенная ширина используется для декодирования речи. В блоке 240 также определяют, не уменьшается ли значение вероятности на кадр (вес растет быстрее). Если в блоке 240 устанавливают, что значение вероятности на кадр уменьшается, то в этом блоке значение ширины луча увеличивается. В одной реализации настоящего изобретения ширина луча в блоке 240 уменьшается/увеличивается на величину, определенную пользователем. В другой реализации изобретения система распознавания речи автоматически уменьшает/увеличивает ширину луча на небольшое значение, основанное на выбранном проценте, таком как 10%. Необходимо заметить, что можно внедрять другие способы уменьшения или увеличения ширины луча без отступления от различных вариантов реализации данного изобретения. Процесс 200 продолжают в блоке 250. В блоке 250 проходят все активные пути при новой ширине луча (динамически изменяемой). В блоке 260 проверяют, не закончено ли декодирование речи. Если в блоке 260 определяют, что декодирование не закончено, то процесс 200 продолжают в блоке 220. Если в блоке 260 определяют, что декодирование закончено, то процесс 200 продолжают в блоке 270. В блоке 270 наилучший путь объявляют результатом распознавания речи. Когда в процессе 200, при декодировании речи, текущая ширина луча уменьшается, увеличивается или остается постоянной, ЧОС не компрометируется, тогда как увеличивается быстрота окончания декодирования (то есть уменьшается время декодирования). Таблица I иллюстрирует результаты решения задачи распознавания речи на китайском языке с использованием реализации настоящего изобретения, содержащей процесс динамической регулировки луча. Необходимо отметить, что другие языки также могут использоваться в качестве входных данных для распознавания речи. Из Таблицы I ясно, что использование реализации изобретения с динамической регулировкой луча для задачи распознавания речи на китайском языке увеличивает скорость распознавания на шестьдесят процентов (60%), то есть масштаб реального времени уменьшается от 3.14 до 1.24. Необходимо заметить, что масштаб реального времени – это время, необходимое центральному процессору (ЦП) для завершения декодирования, деленное на продолжительность речи. Другими словами, если масштаб реального времени меньше единицы, то возможно декодирование в реальном времени.
Таблица II показывает результаты решения задачи распознавания речи на английском языке с использованием реализации настоящего изобретения, содержащей процесс динамической регулировки луча. Из Таблицы II видно, что использование реализации изобретения увеличивает скорость распознавания на сорок пять процентов (45%) (масштаб реального времени уменьшается от 3.4 до 1.85). Как в задаче распознавания китайской речи, так и в задаче распознавания английской речи не наблюдается сколько-нибудь заметного увеличения ЧОС. Заметим, что результаты, представленные в Таблице I и Таблице II были получены на компьютере с процессором Intel Pentium® с тактовой частотой 550 МГц, объем кэш-памяти составлял 512К, а объем синхронной динамической памяти с произвольным доступом (SDRAM) составлял 512 Мегабайт. Необходимо заметить, что для реализации могут использоваться другие компьютерные системы с другими скоростями обработки и памятью. В примерах задач с китайским языком и английским языком начальные значения луча были положены равными 140 и 180 соответственно. Использовался один и тот же промежуток [b1, b2], который положили равным [0.5, 1.05].
В одной реализации изобретения динамическая регулировка луча используется в поиске по Витерби, при котором ширина луча регулируется только в случае, если существует нормальное число активных путей (не слишком много или слишком мало). В данной реализации обозначим через
где 0
В данной реализации изобретения ширина луча регулируется только в случае, если существует нормальное число активных путей (не слишком много или слишком мало), а именно число путей находится в интервале [2N2, 2N3]. В данной реализации изобретения, если число активных путей выходит за границы [2N2, 2N3], то выполняется усечение для того, чтобы число активных путей попало обратно в указанный интервал. Если общее число активных путей меньше порога N1, то уменьшения количества путей не производится [то есть ширина луча равна бесконечности]. Фиг.3 иллюстрирует реализацию настоящего изобретения, содержащую процесс 300, который при декодировании выполняет динамическую регулировку луча только если существует нормальное количество активных путей (не слишком много или слишком мало) или использует декодирование N лучших, если слишком много или слишком мало активных путей. В методе декодирования N лучших, для каждого временного кадра, оставляется только N лучших гипотез, а остальные гипотезы отбрасываются. Таким образом список N лучших гипотез постоянно пересчитывается. Процесс 300 начинают в блоке 310, в котором задают начальную ширину луча. Начальная ширина луча определяется посредством распознавания некоторого примера из входного речевого сигнала. Процесс 300 продолжает работу в блоке 320, где определяют граничные коэффициенты. После начального тестирования системы распознавания речи выбирают множество оптимальных параметров. Выбор происходит на основе оптимальной скорости декодирования и ЧОС. Оптимальную скорость декодирования и ЧОС определяют на основе количества активных гипотез. Работа процесса 300 продолжается в блоке 330, где определяют статистику примера входного речевого сигнала. Так как в блоке 330 обработают пример входного речевого сигнала и определят статистику для данного входа, в блоке 340 устанавливается порог для количества активных гипотез. Заметим, что пороги устанавливаются в соответствии с равенством 2. В одной реализации изобретения порог 2N3 является таким числом гипотез, которое может превышаться не более чем примерно в 10% временных кадров. В одной реализации изобретения порог 2N2 является таким числом гипотез, что примерно 10% временных кадров содержат меньше, чем 2N2 гипотез. Необходимо отметить, что в других реализациях изобретения могут использоваться другие пороги. В одной реализации изобретения порог N1 полагается равным N2/5. Заметим, что порог N1 используется в критических ситуациях, когда число гипотез очень мало. В одной реализации данного изобретения блоки 310-340 могут быть выделены из процесса 300 и выполняться при формировании и тестировании системы распознавания речи или они могут выполняться тогда, когда система распознавания речи адаптируется (косвенно или прямым образом) к говорящему и/или окружающей среде. Процесс 300 продолжают в блоке 350, где получают следующее наблюдение (или фрагмент). Работа процесса 300 продолжается в блоке 355. В блоке 355 определяют, не превосходит ли число активных гипотез порога 2N3. Если в блоке 355 определяют, что число активных гипотез превосходит порог 2N3, то процесс 300 переходит к блоку 356. В блоке 356 производят декодирование N лучших гипотез, где N полагается равным N3. В данном случае важно сохранить таким же параметр ЧОС. Присваивание N=N3 ускоряется процесс декодирования. Если в блоке 355 определяют, что число активных гипотез не превосходит порог 2N3, то процесс 300 переходит к блоку 365. В блоке 365 проверяют, число активных гипотез больше, меньше или равно порогу 2N2. Если в блоке 365 определяют, что число активных гипотез не меньше порога 2N2, то процесс 300 переходит к блоку 366. В блоке 366 определяют наилучшую вероятность В блоке 380 определяют, является ли следующее наблюдение последним. Если в блоке 380 определяют, что наблюдение является последним, то работу процесса 300 продолжают в блоке 350. Если в блоке 380 определяют, что наблюдение в момент времени t=t+1 не является последним, то работа процесса 300 продолжается в блоке 385. В блоке 385 наилучший путь выдают в качестве результата процесса распознавания речи. Если в блоке 365 определяют, что число активных гипотез меньше порога 2N2, то процесс 300 переходит к блоку 375. В блоке 375 проверяют: число активных гипотез больше, меньше или равно порогу 2N1. Если в блоке 375 определяют, что число активных гипотез не меньше порога 2N1, то процесс 300 переходит к блоку 376. В блоке 376 декодируют активные гипотезы посредством декодирования N лучших гипотез, при этом параметру N присваивается значение N2. Работа процесса 300 продолжается в блоке 380. Если в блоке 375 определяют, что число активных гипотез меньше порога 2N1, то процесс 300 переходит к блоку 390. Затем в блоке 390 все гипотезы распространяются далее. Таблица III иллюстрирует сравнение результатов решения задачи распознавания речи на китайском языке, полученных с помощью следующих способов: статистическое распознавание речи, использующее поиск по Витерби при статическом луче, распознавание речи с использованием реализации настоящего изобретения, содержащей процесс динамической регулировки луча (процесс 200) и распознавание речи с использованием реализации изобретения, содержащей процесс динамической регулировки луча, где ширина луча регулируется только в случае, если существует нормальное число активных путей (не слишком много или слишком мало) или использующей декодирование N лучших, если слишком много или слишком мало активных путей (процесс 300). Необходимо отметить, что другие языки также могут использоваться в качестве входных данных для распознавания речи. В Таблице III результаты иллюстрируют реализацию изобретения (модифицированный процесс динамического регулирования ширины луча; третий столбец), имеющую динамическую регулировку луча (процесс 200) и динамическую регулировку луча, в случае, когда существует нормальное количество активных путей (не слишком много или слишком мало) или использующую декодирование N лучших, в случае, если слишком много или слишком мало активных путей (процесс 300), при этом первый проход использовал только реализацию изобретения, имеющего динамическую регулировку луча (200), а второй проход использовал реализацию изобретения, имеющего динамическую регулировку луча, где ширина луча изменяется только тогда, когда “достаточно” активных путей (процесс 300). В Таблице III использование реализации изобретения, содержащей процесс модифицированной динамической регулировки луча (третий столбец), позволило добиться улучшения ЧОС от 8.3 до 7.8, по сравнению с реализацией изобретения, содержащей только процесс динамической регулировки луча, без изменения ширины луча в случае, когда существует нормальное количество активных путей (не слишком много или слишком мало) или использовании декодирования N лучших в случае, если слишком много или слишком мало активных путей. Результаты примера, проиллюстрированного в Таблице III, получены для реализации изобретения, использующей те же параметры, что и реализация изобретения, результаты которой показаны в Таблице I. При этом параметры для реализации, использующей и динамическую регулировку луча, и динамическую регулировку луча, где ширина луча изменяется только в случае, если существует нормальное число активных путей (не слишком много или слишком мало) или использующей декодирование N лучших в случае, если слишком много или слишком мало активных путей, равны N1=160, N2=800 и N3=5000.
Таблица IV иллюстрирует сравнение результатов решения задачи распознавания речи на английском языке, полученных с помощью следующих способов: поиск по Витерби при статическом луче, реализация настоящего изобретения, содержащая процесс динамической регулировки луча и реализация изобретения, содержащая процесс динамической регулировки луча, где ширина луча регулируется только в случае нормального числа активных путей (не слишком много или слишком мало) или использующая декодирование N лучших, если слишком много или слишком мало активных путей. Необходимо отметить, что реализации данного изобретения могут решать задачи распознавания речи с другими языками. Результаты, проиллюстрированные в Таблице IV для реализации данного изобретения, используют те же параметры, что и реализация изобретения, результаты которой показаны в Таблице II. При этом параметры для реализации, использующей и динамическую регулировку луча, и динамическую регулировку луча, где ширина луча регулируется только в случае, если существует нормальное число активных путей (не слишком много или слишком мало) или использующей декодирование N лучших в случае, если слишком много или слишком мало активных путей, равны N1=300, N2=1500 и N3=6000. Результаты из Таблицы IV иллюстрируют, что улучшение ЧОС с 11.4 до 11 видно из сравнения реализации настоящего изобретения, содержащей процесс динамической регулировки луча для первого прохода и реализации изобретения, содержащей процесс динамической регулировки луча, где ширина луча регулируется только в случае нормального числа активных путей (не слишком много или слишком мало) или использующей декодирование N лучших, если слишком много или слишком мало активных путей для второго прохода. Результаты из Таблиц III и IV были получены с использованием компьютера с процессором Intel Pentium
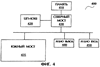
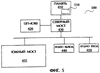
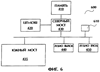
Необходимо отметить, что реализации изобретения, которые обсуждались выше, могут применяться для задач с количеством гипотез слишком большим, чтобы это количество можно было определить за разумное время, и где обычно применяется усечение ширины луча. Фиг.4 иллюстрирует типовую вычислительную систему 400, которая может быть использована для распознавания речи. Система 400 содержит память 410, центральный процессор (ЦП) с кэш-памятью 420, северный мост 430, южный мост 435, устройство вывода аудио информации 440 и устройство ввода аудио информации 450. Устройство вывода аудио информации 440 может представлять собой устройство подобное акустической системе. Устройство ввода аудио информации 450 может быть таким устройством, как микрофон. Фиг.5 показывает систему 500, содержащую некоторую реализацию данного изобретения с процессом 510 динамической регулировки луча. В одной реализации изобретения процесс 510 динамической регулировки луча осуществляется в виде процесса 200 (проиллюстрированного на Фиг.2). В другой реализации изобретения процесс 510 динамической регулировки луча осуществляется в виде процесса 300 (проиллюстрированного на Фиг.3). В третьей реализации изобретения процесс 510 динамической регулировки луча осуществляется как в виде процесса 200, так и в виде процесса 300, где процесс 200 используется для первого прохода, а процесс 300 используется для остальных проходов. Процесс 510 может быть реализован в виде приложения, содержащегося в памяти 410. Память 410 может представлять собой запоминающие устройства, такие как оперативное запоминающее устройство (RAM), динамическая RAM или синхронная DRAM (SDRAM). Заметим, что наряду с перечисленными, могут использоваться другие запоминающие устройства, включая будущие разработки в данной области. Также отметим, что процесс 510 может быть реализован на других носителях, информацию с которых можно прочитать, таких как флоппи-диски, компакт диски (CD-ROM), и так далее. Фиг.6 показывает вариант осуществления данного изобретения с процессом 610 (показанном на Фиг.5, как процесс 510), причем процесс 610 реализован аппаратно. В одном варианте осуществления изобретения, процесс 610 реализуется с использованием программируемых логических матриц (ПЛМ). Необходимо заметить, что процесс 510 может быть реализован с использованием других электронных устройств, таких как регистры и транзисторы. В другой реализации изобретения процесс осуществляется в виде аппаратно реализованного программного обеспечения. Использование при распознавании речи реализации настоящего изобретения с методом поиска по Витерби позволяет увеличить скорость обработки без увеличения ЧОС. Таким образом, требуется меньше времени для решения задачи распознавания речи. Указанные выше реализации также могут храниться на устройстве или машинно-считываемом носителе и считываться машиной с целью выполнения команд. Машинно-считываемые носители включают в себя любые механизмы, которые содержат (то есть хранят и/или передают) информацию, которая может быть считана машиной (например, компьютером). Например, машинно-считываемый носитель может быть постоянным запоминающим устройством (ROM); оперативным запоминающим устройством или памятью с произвольным доступом (RAM); накопителем на магнитных дисках; оптическим диском; флэш-памятью; электрическим, оптическим, звуковым сигналом или любой другой формой распространяемого сигнала (например, несущие волны, инфракрасные сигналы, цифровые сигнала и так далее). Устройство или машинно-считываемый носитель может быть полупроводниковым устройством памяти и/или вращающимся магнитным или оптическим диском. Устройство или машинно-считываемый носитель может быть распределенным, когда части команд разделены между различными машинами, например между соединенными в сеть компьютерами. Несмотря на то, что некоторые типичные реализации описаны и показаны на сопровождающих чертежах, необходимо понять, что такие реализации являются лишь иллюстрациями и не ограничивают рамки изобретения, и что данное изобретение не ограничивается конкретными структурами и конструкциями, здесь показанными и описанными, так как специалист в соответствующей области может предложить множество других модификаций.
Формула изобретения
1. Способ динамической регулировки луча в поиске по Витерби, включающий выбор начальной ширины луча; определение, изменяется ли значение вероятности на кадр; динамическую регулировку ширины луча; декодирование входного речевого сигнала с динамически регулируемой шириной луча. 2. Способ по п.1, в котором указанное декодирование включает усечение множества активных путей с динамически регулируемой шириной луча. 3. Способ по п.1, в котором указанное декодирование дополнительно включает использование скрытой марковской модели (СММ). 4. Способ по п.3, в котором СММ является оценочным поиском по Витерби. 5. Способ по п.1, в котором указанная динамическая регулировка включает эвристическое определение первого и второго граничных коэффициентов. 6. Способ по п.1, в котором меняется значение на кадр, при этом вероятность на кадр одной гипотезы из группы лучших увеличивается, а вероятность наилучшей гипотезы на кадр уменьшается. 7. Способ динамической регулировки луча в поиске по Витерби, включающий определение начальной ширины луча; определение множества пороговых значении, используемых для множества активных гипотез; определение текущего числа активных гипотез; сравнение текущего числа активных гипотез с пороговыми значениями; динамическую регулировку ширины луча для множества активных гипотез; декодирование входного речевого сигнала. 8. Способ по п.7, в котором указанное декодирование включает усечение множества активных гипотез либо с помощью динамически регулируемой ширины луча, либо с помощью усечения N лучших, причем усечение происходит на основе множества пороговых значений. 9. Способ по п.8, в котором указанное декодирование дополнительно включает использование скрытой марковской модели (СММ). 10. Способ по п.9, в котором СММ является оценочным поиском по Витерби. 11. Способ по п.7, в котором указанная динамическая регулировка включает эвристическое определение первого и второго граничных коэффициентов. 12. Способ по п.7, в котором указанное определение множества пороговых значений включает в себя определение статистики по фрагменту входного речевого сигнала. 13. Система динамической регулировки луча в поиске по Витерби, содержащая процессор; шину, соединенную с процессором; память, соединенную с процессором, в которой записан процесс распознавания речи; устройство для ввода данных, соединенное с процессором; устройство для вывода информации, соединенное с процессором, где процесс распознавания речи динамически регулирует ширину луча с целью декодирования входного речевого сигнала. 14. Система по п.13, в которой процесс распознавания речи декодирует входной речевой сигнал посредством усечения множества активных гипотез либо с помощью динамически регулируемой ширины луча, либо с помощью усечения N лучших, причем усечение происходит на основе множества пороговых значений, хранимых в памяти. 15. Система по п.14, в которой процесс распознавания речи декодирует входной речевой сигнал, используя, кроме перечисленного, скрытую марковскую модель (СММ). 16. Система по п.15, в которой СММ является оценочным поиском по Витерби. 17. Устройство динамической регулировки луча в поиске по Витерби, содержащее процессор; первую схему, предназначенную для выполнения процесса распознавания речи, соединенную с процессором; память, соединенную с процессором, где процесс распознавания речи динамически регулирует ширину луча с целью декодирования входного речевого сигнала. 18. Устройство по п.17, в котором процесс распознавания речи декодирует входной речевой сигнал посредством усечения множества активных гипотез либо с помощью динамически регулируемой ширины луча, либо с помощью усечения N лучших, причем усечение происходит на основе множества пороговых значений, хранимых в памяти. 19. Устройство по п.18, в котором процесс распознавания речи декодирует входной речевой сигнал, используя, кроме перечисленного, скрытую марковскую модель (СММ). 20. Устройство по п.19, в которой СММ является оценочным поиском по Витерби. 21. Устройство по п.17, в котором первая схема является программируемой логической матрицей. 22. Устройство динамической регулировки луча в поиске по Витерби, содержащее машинно-считываемый носитель с записанными командами, исполнение которых машиной приводит к тому, что машина выполняет операции, включающие выбор начальной ширины пуча; определение, изменяется ли значение вероятности на кадр; динамическую регулировку ширины луча; декодирование входного речевого сигнала с динамически регулируемой шириной луча. 23. Устройство по п.22, в котором указанное декодирование включает усечение множества активных путей с динамически регулируемой шириной луча. 24. Устройство по п.23, где указанное декодирование дополнительно включает использование скрытой марковской модели (СММ). 25. Устройство по п.24, в котором СММ является оценочным поиском по Витерби. 26. Устройство по п.24, в котором указанная регулировка дополнительно содержит команды, исполнение которых машиной приводит к тому, что машина выполняет операции, включающие в себя эвристическое определение первого и второго граничных коэффициентов. 27. Устройство по п.22, в котором меняется значение на кадр, при этом вероятность на кадр одной гипотезы из группы лучших увеличивается, а вероятность наилучшей гипотезы на кадр уменьшается. 28. Устройство динамической регулировки луча в поиске по Витерби, содержащее машинно-считываемый носитель с записанными командами, исполнение которых машиной приводит к тому, что машина выполняет операции, включающие определение начальной ширины луча; определение множества пороговых значений, используемых для множества активных гипотез; определение текущего числа активных гипотез; сравнение текущего числа активных гипотез с пороговыми значениями; динамическую регулировку ширины луча для множества активных гипотез; декодирование входного речевого сигнала. 29. Устройство по п.28, в котором указанное декодирование дополнительно содержит команды, исполнение которых машиной приводит к тому, что машина выполняет операции, включающие усечение множества активных гипотез либо с помощью динамически регулируемой ширины луча, либо с помощью усечения N лучших, причем усечение происходит на основе множества пороговых значений. 30. Устройство по п.29, в котором указанное декодирование дополнительно включает в себя оценочный поиск по Витерби.
РИСУНКИ
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
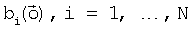
 i, i=1, …, N.
i, i=1, …, N. n (где
n (где 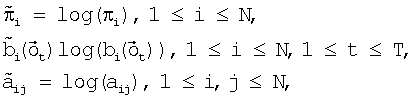
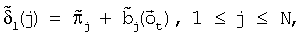
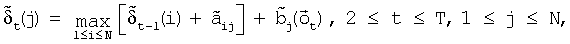

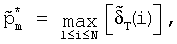
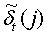
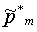
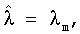
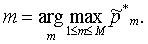
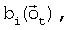
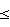 i
i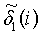
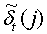
 Фt. Пусть
Фt. Пусть 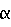 t обозначает значение наибольшей вероятности во множестве Фt,
t обозначает значение наибольшей вероятности во множестве Фt, 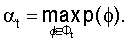
 обозначает ширину луча.
обозначает ширину луча.
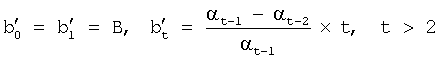
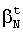
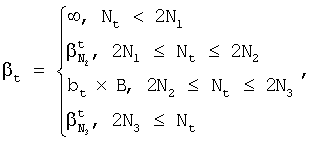

 с тактовой частотой 550 МГц, с 512К кэш-памяти и 512 Мб SDRAM. Необходимо заметить, что для реализации могут использоваться другие компьютерные системы с другими скоростями обработки и памятью.
с тактовой частотой 550 МГц, с 512К кэш-памяти и 512 Мб SDRAM. Необходимо заметить, что для реализации могут использоваться другие компьютерные системы с другими скоростями обработки и памятью.