Патент на изобретение №2273044
|
||||||||||||||||||||||||||
(54) СПОСОБ И УСТРОЙСТВО ДЛЯ ПАРАЛЛЕЛЬНОГО ОБЪЕДИНЕНИЯ ДАННЫХ СО СДВИГОМ ВПРАВО
(57) Реферат:
Изобретение относится к области микропроцессоров и компьютерных систем, более конкретно к способу и устройству для параллельного объединения данных со сдвигом вправо. Техническим результатом является обеспечение эффективной поддержки операций SIMD без существенного снижения эффективности в целом. Указанный результат достигается за счет того, что параллельно со сдвигом влево на ‘L – М’ элементов данных первого операнда, имеющего первый набор из L элементов данных, сдвигают второй операнд, имеющий второй набор из L элементов данных, вправо на М элементов данных, и объединяют упомянутый сдвинутый первый набор с упомянутым сдвинутым вторым набором для получения результата, имеющего L элементов данных. 6 н. и 38 з.п. ф-лы, 23 ил., 1 табл.
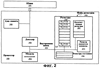
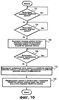
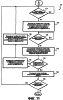
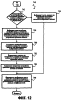
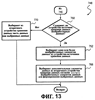
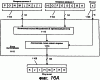
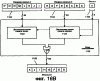
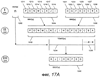
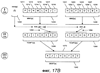
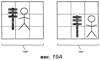
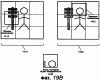
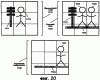
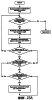
ОБЛАСТЬ ИЗОБРЕТЕНИЯ Настоящее изобретение относится в общем случае к области микропроцессоров и компьютерных систем. Более конкретно, настоящее изобретение относится к способу и устройству для параллельного объединения данных со сдвигом вправо. ПРЕДШЕСТВУЮЩИЙ УРОВЕНЬ ТЕХНИКИ По мере развития технологии процессоров также создаются новые коды программ для работы на компьютерах с этими процессорами. Пользователи в общем случае ожидают и требуют более высокой производительности от своих компьютеров независимо от типа используемого программного обеспечения. Одна из таких проблем может возникнуть из-за типов команд и операций, которые в текущий момент выполняются в процессоре. Некоторые типы операций требуют большего времени для завершения из-за сложности операций и/или необходимых для них схем. Это создает возможность оптимизации способа, которым некоторые сложные операции выполняются в процессоре. Медиаприложения (мультимедийные прикладные программы) способствуют разработкам микропроцессоров в течение более десяти лет. Фактически, большинство обновлений вычислительной техники за последние годы были вызваны медиаприложениями. Эти обновления преобладающим образом происходили в пределах потребительского сегмента, хотя существенные усовершенствования также имели место в предпринимательском сегменте, например, для целей образования и коммуникации с учетом развлекательного аспекта. Однако будущие медиаприложения будут предъявлять все более высокие требования к вычислениям. В результате, в ближайшем будущем пользование персональными компьютерами (ПК) будет характеризоваться более интересными аудиовизуальными эффектами, а также будет более легким в практическом применении, и что еще более важно, компьютеры будут объединены со средствами связи. Соответственно, отображение изображений так же, как воспроизведение аудио и видеоданных, которое все вместе упоминается как содержимое, стало все более и более популярными приложениями для существующих вычислительных устройств. Операции фильтрации и свертки являются примерами самых обычных операций, выполняемых с данными содержимого, такого как изображение, аудио и видеоинформация. Как известно специалистам, вычисления фильтрации и корреляции выполняют с помощью операции умножения с накоплением, которая суммирует произведения данных и коэффициентов. Корреляция двух векторов А и B состоит в вычислении суммы S: В случае, когда N-отводный фильтр f применяют к вектору V, сумма S может быть рассчитана следующим образом: Такие операции требуют большого объема вычислений, но обеспечивают высокий уровень параллелизма данных, который может использоваться при эффективном воплощении с использованием различных устройств хранения данных, таких, например, как регистры с одним потоком команд и множеством потоков данных (SIMD). Применение операций фильтрации можно найти в большом множестве задач обработки изображений и видеоинформации, а также связи. Примерами использования фильтров являются уменьшение артефактов формирования блоков данных в видеоизображении стандарта MPEG (стандарт, выработанный экспертной группой по кинематографии), уменьшение шумов и звуков, отделение водяных знаков от значений пикселов для улучшения обнаружения водяных знаков, корреляция для сглаживания, увеличение резкости, сокращение шума, обнаружение краев и масштабирование размеров изображений или видеокадров, дискретизация видеокадров для оценки движения суб-пикселов, улучшение качества аудиосигнала и изменение формы импульсов и коррекция сигналов в связи. Соответственно, операции фильтрации так же, как свертки, жизненно важны для вычислительных устройств, которые обеспечивают воспроизведение содержимого, которое включает в себя изображение, аудио и видеоданные. К сожалению, существующие способы и команды направлены на общие потребности фильтрации и не являются всесторонними. Фактически, многие виды архитектур не поддерживают средство для эффективного вычисления фильтрации для разных длин фильтра и типов данных. Кроме того, упорядочивание данных в устройствах хранения данных, таких как регистры SIMD, так же, как возможность суммирования смежных значений в регистре и частичных переносов данных между регистрами, в общем случае не поддерживаются. В результате, существующие виды архитектур требуют ненужных изменений типа данных, которые минимизируют количество операций за одну команду и значительно увеличивают количество тактовых циклов, требуемых для упорядочивания данных для арифметических операций. КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ Настоящее изобретение показано для примера, а не для ограничения, на чертежах, на которых одинаковые ссылочные позиции обозначают сходные элементы и на которых: Фиг.1 – структурная схема компьютерной системы, реализующей один из вариантов осуществления настоящего изобретения; Фиг.2 – структурная схема варианта осуществления процессора, как показано на фиг.1, в соответствии с другим вариантом осуществления настоящего изобретения; Фиг.3 – иллюстрация видов упакованных данных согласно другому варианту осуществления настоящего изобретения; Фиг.4A – представление в регистре упакованного байта согласно одному из вариантов осуществления настоящего изобретения; Фиг.4B – представление в регистре упакованного слова согласно одному из вариантов осуществления настоящего изобретения; Фиг.4C – представление в регистре упакованного двойного слова согласно одному из вариантов осуществления настоящего изобретения; Фиг.5 – диаграмма, иллюстрирующая действие команды перемещения байтов в соответствии с вариантом осуществления настоящего изобретения; Фиг.6 – диаграмма, иллюстрирующая команду умножения с накоплением байтов в соответствии с вариантом осуществления настоящего изобретения; Фиг.7A-7C – диаграммы, иллюстрирующие команду перемещения байтов по фиг.5, объединенную с командой умножения с накоплением байтов по фиг.6, для получения множества сумм пар произведений в соответствии с другим вариантом осуществления настоящего изобретения; Фиг.8A-8D – диаграммы, иллюстрирующие команду суммирования смежных элементов в соответствии с другим вариантом осуществления настоящего изобретения; Фиг.9A и 9B – команда объединения регистров в соответствии с другим вариантом осуществления настоящего изобретения; Фиг.10 – блок-схема последовательности операций для эффективной обработки данных содержимого в соответствии с одним из вариантов осуществления настоящего изобретения; Фиг.11 – блок-схема способа обработки данных содержимого согласно операции обработки данных в соответствии с другим вариантом осуществления настоящего изобретения; Фиг.12 – блок-схема последовательности операций для продолжения обработки данных содержимого в соответствии с другим вариантом осуществления настоящего изобретения; Фиг.13 – блок-схема последовательности операций, иллюстрирующая операцию объединения регистров в соответствии с другим вариантом осуществления настоящего изобретения. Фиг.14 – блок-схема последовательности операций способа выбора необработанных элементов данных из устройства-источника хранения данных в соответствии с примерным вариантом осуществления настоящего изобретения; Фиг.15 – структурная схема микроархитектуры процессора одного из вариантов осуществления, которая включает в себя логические схемы для параллельного выполнения операции объединения со сдвигом вправо в соответствии с настоящим изобретением; Фиг.16A – структурная схема одного из вариантов осуществления логической схемы для выполнения операции параллельного объединения со сдвигом вправо с операндами данных в соответствии с настоящим изобретением; Фиг.16B – структурная схема другого варианта осуществления логической схемы для выполнения операции объединения со сдвигом вправо; Фиг.17A – иллюстрирующая действия параллельной команды объединения со сдвигом вправо в соответствии с первым вариантом осуществления настоящего изобретения; Фиг.17B – иллюстрирующая действия команды объединения со сдвигом вправо в соответствии со вторым вариантом осуществления; Фиг.18А – последовательность операций одного из вариантов осуществления способа параллельного сдвига вправо и объединения операндов данных; Фиг.18B – последовательность операций другого варианта осуществления способа сдвига вправо и объединения данных; Фиг.19A-B – примеры оценки движения; Фиг.20 – пример применения оценки движения и результирующего предсказания; Фиг.21A-B – пример текущего и предыдущего кадров, обрабатываемых во время оценки движения; Фиг.22A-D – операции оценки движения в кадрах в соответствии с одним из вариантов осуществления настоящего изобретения; и Фиг.23A-B – последовательность операций одного из вариантов осуществления способа предсказания и оценки движения. ПОДРОБНОЕ ОПИСАНИЕ Ниже описаны способ и устройство для выполнения параллельного объединения данных со сдвигом вправо. Также описаны способ и устройство для эффективной фильтрации и свертки данных содержимого. Также раскрыты способ и устройство для оценки движения быстрого полного поиска с помощью операций объединения SIMD. Описанные варианты осуществления описаны в контексте микропроцессора, но не ограничены им. Хотя последующие варианты осуществления описаны со ссылкой на процессор, другие варианты осуществления могут применяться к другим типам интегральных схем и логических устройств. Те же самые методы и идеи настоящего изобретения могут легко применяться к другим типам полупроводниковых схем или устройств, которые могут использовать преимущества более высокой пропускной способности конвейера и улучшенной производительности. Принципы настоящего изобретения применимы к любому процессору или устройству, которые выполняют обработку данных. Однако настоящее изобретение не ограничено процессорами или устройствами, которые выполняют операции с 256-битными, 128-битными, 64-битными, 32-битными или 16-битными данными и могут применяться на любом процессоре и устройстве, в которых необходимо объединение данных со сдвигом вправо. В последующем описании для целей объяснения многочисленные конкретные подробности изложены для обеспечения полного понимания настоящего изобретения. Однако специалистам должно быть ясно, что эти конкретные подробности не являются необходимыми для практической реализации настоящего изобретения. В других случаях известные электрические структуры и схемы не излагаются подробно, чтобы не затенять сущность настоящего изобретения. Кроме того, в последующем описании приведены примеры, и на чертежах показаны различные примеры для целей иллюстрации. Однако эти примеры не должны рассматриваться в качестве ограничения, поскольку они предназначены только для представления примеров настоящего изобретения, а не для обеспечения исчерпывающего списка всех возможных воплощений настоящего изобретения. В одном из вариантов осуществления способы настоящего изобретения воплощены в командах, исполняемых компьютером. Команды могут использоваться для выполнения этапов настоящего изобретения в универсальном процессоре или в специализированном процессоре, который запрограммирован с помощью данных команд. Альтернативно, этапы настоящего изобретения могут выполняться определенными аппаратными компонентами, которые содержат логические схемы с постоянными соединениями для выполнения этапов, или комбинацией программируемых компьютерных компонентов и заказных аппаратных компонентов. Настоящее изобретение может обеспечиваться как компьютерная программа или программное обеспечение, которое может включать в себя считываемый компьютером носитель, который имеет хранящиеся на нем команды, которые могут использоваться для программирования компьютера (или других электронных устройств) для выполнения способа согласно настоящему изобретению. Такое программное обеспечение может храниться в памяти системы. Точно так же код может распространяться через сеть или посредством другого считываемого компьютером носителя. Считываемый компьютером носитель может включать в себя гибкие дискеты, оптические диски, компакт-диски (CD-ROM) и магнитооптические диски, постоянное запоминающее устройство (ПЗУ), оперативную память (ОП), стираемое программируемое постоянное запоминающее устройство (СППЗУ), электрически стираемое программируемое постоянное запоминающее устройство (ЭСППЗУ), магнитные или оптические платы, флэш-память, передачу по Интернет или подобные им средства, но не ограничивается перечисленным. Соответственно, считываемый компьютером носитель включает в себя любой тип среды передачи данных/машинно-считаемых носителей, которые подходят для хранения или передачи электронных команд или информации в форме, считываемой устройством (например, компьютером). Кроме того, настоящее изобретение может также загружаться как компьютерная программа. Также, программа может пересылаться с удаленного компьютера (например, сервера) на запрашивающий компьютер (например, клиент). Пересылка программы может быть выполнена посредством электрического, оптического, акустического сигналов передачи данных или сигналов передачи данных другой формы, воплощенных в несущей или другой среде распространения сигнала через канал связи (например, модем, сетевое соединение или иное подобное средство). В современных процессорах используется множество различных исполнительных модулей для обработки и исполнения различных кодов и команд. Не все команды одинаковы, так некоторые быстрее завершаются, в то время как другие могут занимать огромное количество тактовых циклов. Чем быстрее выполняются команды, тем выше производительность в целом процессора. Таким образом было бы выгодно иметь максимально возможное количество команд, которые выполняются с максимально возможной скоростью. Однако существуют некоторые команды, которые отличаются высокой сложностью и требуют больше ресурсов процессора и времени выполнения. Например, существуют команды с плавающей запятой, операции загрузки/хранения, перемещения данных и т.д. Поскольку все большее количество компьютерных систем используют в приложениях Интернет и мультимедиа, их дополнительная поддержка процессором увеличивается с течением времени. Например, целочисленные/с плавающей запятой команды для обработки в архитектуре с одной командой множеством потоков данных и (SIMD) и расширение для потоковых команд (SIMD) (SSE) являются командами, которые уменьшают общее количество команд, требуемых для выполнения конкретной задачи программы. Эти команды могут увеличивать производительность программного обеспечения, обрабатывая множество элементов данных параллельно. В результате можно достичь увеличения производительности в широком диапазоне приложений, которые включают в себя обработку видеоинформации, речи и изображений/фотографий. Выполнение команд SIMD в микропроцессорах и подобных типах логических схем обычно создает множество проблем. Кроме того, сложность операций SIMD часто требует дополнительных схем для правильной обработки и управления данными. Варианты осуществления настоящего изобретения обеспечивают способ реализации параллельной команды сдвига вправо как алгоритм, который использует относящиеся к архитектуре SIMD аппаратные средства. Для одного из вариантов осуществления алгоритм основан на принципе сдвига вправо требуемого количества сегментов данных одного операнда в сторону наибольшей значимости второго операнда, когда то же самое количество сегментов данных сдвигают в сторону наименьшей значимости второго операнда. В принципе операцию объединения со сдвигом вправо можно рассматривать как объединение двух блоков данных в один блок и сдвиг данного объединенного блока для выравнивания сегментов данных в требуемом положении для формирования новой комбинации данных. Таким образом, варианты осуществления алгоритма объединения со сдвигом вправо в соответствии с настоящим изобретением могут осуществляться в процессоре для эффективной поддержки операций SIMD без существенного снижения эффективности в целом. ВЫЧИСЛИТЕЛЬНАЯ АРХИТЕКТУРА Фиг.1 показывает компьютерную систему 100, в которой может быть воплощен вариант осуществления настоящего изобретения. Компьютерная система 100 содержит шину 101 для передачи информации и процессор 109, присоединенный к шине 101, для обработки информации. Компьютерная система 100 также включает в себя подсистему памяти 104-107, присоединенную к шине 101, предназначенную для хранения информации и команд для процессора 109. Процессор 109 включает в себя модуль 130 исполнения, файл 200 регистров, кэш-память 160, декодер 165 и внутреннюю шину 170. Кэш-память 160 присоединена к модулю 130 исполнения и хранит часто используемую и/или недавно использованную информацию для процессора 109. Файл 200 регистров хранит информацию в процессоре 109 и присоединен к модулю 130 исполнения через внутреннюю шину 170. В одном из вариантов осуществления изобретения файл 200 регистров включает в себя регистры мультимедиа, например регистры SIMD, предназначенные для хранения мультимедийной информации. В одном из вариантов осуществления каждый из регистров мультимедиа хранит до ста двадцати восьми битов упакованных данных. Регистры мультимедиа могут быть специализированными регистрами мультимедиа или регистрами, которые используются для хранения мультимедийной и другой информации. В одном из вариантов осуществления регистры мультимедиа хранят данные мультимедиа при выполнении операций мультимедиа и хранят данные с плавающей запятой при выполнении операций с плавающей запятой. Модуль 130 исполнения оперирует с упакованными данными согласно командам, принятым процессором 109, которые включены в набор 140 упакованных команд. Модуль 130 исполнения также оперирует со скалярными данными согласно командам, реагируемым в универсальных процессорах. Процессор 109 способен поддерживать набор команд микропроцессора Pentium® и набора 140 упакованных команд. За счет включения набора 140 упакованных команд в стандартный набор команд микропроцессора, такой как набор команд микропроцессора Pentium®, команды с упакованными данными могут быть легко помещены в существующее программное обеспечение (ранее написанное для стандартного набора команд микропроцессора). Другие стандартные наборы команд, такие как наборы команд процессоров PowerPC В одном из вариантов осуществления набор 140 упакованных команд включает в себя команды (как описано более подробно ниже) для операции 143 пересылки данных (MOVD) и операции 145 перемещения данных (PSHUFD) для организации данных в пределах устройства хранения данных; операцию упакованного умножения с накоплением для первого регистра-источника без знака и второго регистра-источника со знаком (операция 147 PMADDUSBW); операцию упакованного умножения с накоплением (операция 149 PMADDUUBW) для выполнения умножения с накоплением для первого регистра-источника без знака и второго регистра-источника без знака; операцию упакованного умножения с накоплением (операция 151 PMADDSSBW) для первого и второго регистров-источников со знаком, и стандартного умножения с накоплением (операция 153 PMADDWD) для первого и второго регистров-источников со знаком, содержащих 16-разрядные данные. Наконец, система упакованных команд включает в себя команду суммирования смежных значений для суммирования смежных байтов (операция 155 PAADDNB), слов (операция 157 PAADDNWD) и двойных слов (PAADDNDWD 159), двух значений слова (PAADDWD 161), двух слов для получения 16-разрядного результата (операция 163 PAADDNWW), двух учетверенных слов квадраслов для получения результата в виде квадраслова (операция 165 PAADDNDD) и операцию 167 объединения регистров. За счет включения набора 140 упакованных команд в набор команд универсального процессора 109, вместе с соответствующими схемами для исполнения команд, операции, используемые многими существующими мультимедийными приложениями, могут выполняться с использованием упакованных данных в универсальном процессоре. Таким образом, многие мультимедийные приложения могут выполняться быстрее и эффективнее с использованием полной разрядности шины данных процессора для выполнения операций с упакованными данными. Это устраняет потребность перемещения небольших блоков данных по шине данных процессора для выполнения одной или более операций с одним элементом данных в определенный момент времени. Согласно Фиг.1 компьютерная система 100, соответствующая настоящему изобретению, может включать в себя устройство 121 отображения, такое как монитор. Устройство 121 отображения может включать в себя промежуточное устройство, такое как буфер кадров. Компьютерная система 100 также включает в себя устройство 122 ввода данных, такое как клавиатура, и устройство 123 управления курсором, такое как «мышь», или шаровой манипулятор («трекбол»), или сенсорная панель. Устройство 121 отображения, устройство 122 ввода данных и устройство 123 управления курсором присоединены к шине 101. Компьютерная система 100 может также включать в себя средство 124 соединения с сетью, так что компьютерная система 100 является частью локальной сети (ЛС) или глобальной сети (ГС). Дополнительно, компьютерная система 100 может быть присоединена к устройству 125 для записи и/или воспроизведения звука, такому как устройство преобразования в цифровую форму аудиоинформации, соединенное с микрофоном для записи речевого ввода для распознавания речи. Компьютерная система 100 может также включать в себя устройство 126 преобразования в цифровую форму видеоинформации, которое может использоваться для ввода видеоизображений, устройство 127 для создания твердой (документальной) копии, такое как принтер, и устройство 128 CD-ROM. Устройства 124 – 128 также присоединены к шине 101. Процессор Фиг.2 показывает подробную схему процессора 109. Процессор 109 может быть осуществлен на одной или более подложках, используя любую из множества технологий процесса, такую как BiCMOS (биполярная комплементарная структура металл-оксид-полупроводник (КМОП)), CMOS (КМОП) и NMOS (n-канальный металл-оксид-полупроводник). Процессор 109 содержит декодер 202 для декодирования сигналов управления и данных, используемых процессором 109. Затем данные могут сохраняться в файле 200 регистров через внутреннюю шину 205. Следует уточнить, что регистры варианта осуществления не ограничиваются конкретным типом схемы. Регистр в рассматриваемом варианте осуществления должен быть способен только обеспечивать хранение и передачу данных и выполнение описанных функций. В зависимости от типа данных данные могут храниться в целочисленных регистрах 201, регистрах 209, регистрах 208 состояния или регистре 211 указателя команды. Файл 204 регистров может включать в себя другие регистры, например регистр с плавающей запятой. В одном из вариантов осуществления целочисленные регистры 201 хранят тридцатидвухбитные целочисленные данные. В одном из вариантов осуществления регистры 209 содержат восемь регистров мультимедиа R0 212a-R7 212h, например, регистры SIMD, содержащие упакованные данные. Каждый регистр в регистрах 209 имеет длину сто двадцать восемь битов. R1 212a, R2 212b и R3 212c – примеры отдельных регистров в регистрах 209. Тридцать два бита данных в регистрах 209 могут перемещаться в один из целочисленных регистров 201. Точно так же значение целочисленного регистра может быть перемещено в тридцать два бита одного из регистров 209. Регистры 208 состояния указывают состояние процессора 109. Регистр 211 указателя команды хранит адрес следующей команды, которая будет выполняться. Целочисленные регистры 201, регистры 209, регистры 208 состояния и регистр 211 указатель команды, все они соединяются с внутренней шиной 205. Любые дополнительные регистры также соединяются с внутренней шиной 205. В другом варианте осуществления некоторые из этих регистров могут использоваться для двух различных типов данных. Например, регистры 209 и целочисленные регистры 201 могут быть объединены, причем каждый регистр может хранить или целочисленные данные, или упакованные данные. В другом варианте осуществления регистры 209 могут использоваться как регистры с плавающей запятой. В данном варианте осуществления в регистрах 209 могут храниться упакованные данные или данные с плавающей запятой. В одном из вариантов осуществления объединенные регистры имеют длину сто двадцать восемь битов, и целые числа представлены как сто двадцать восемь битов. В данном варианте осуществления при хранении упакованных данных и целочисленных данных не требуется, чтобы регистры различали между собой эти два типа данных. Функциональный модуль 203 выполняет операции, выполняемые процессором 109. Такие операции могут включать в себя сдвиг, сложение, вычитание и умножение и т.д. Функциональный модуль 203 соединяется с внутренней шиной 205. Кэш 160 – дополнительный элемент процессора 109 и может использоваться для кэширования данных и/или сигналов управления, например, из оперативной памяти 104. Кэш 160 соединен с декодером 202 и подсоединен с возможностью приема сигналов 207 управления. Форматы данных и памяти Фиг.3 иллюстрирует три типа упакованных данных: упакованный байт 221, упакованное слово 222 и упакованное двойное слово (dword) 223. Упакованный байт 221 имеет длину сто двадцать восемь битов и содержит шестнадцать элементов данных – упакованных байтов. В общем случае, элемент данных – отдельная часть данных, которая хранится в одном регистре (или ячейке памяти) с другими элементами данных той же самой длины. В упакованных последовательностях данных количество элементов данных, хранящихся в регистре, равно 128 битам, деленным на длину в битах элемента данных. Упакованное слово 222 имеет длину 128 битов и содержит восемь элементов данных упакованного слова. Каждое упакованное слово содержит 16 битов информации. Упакованное двойное слово 223 имеет длину 128 битов и содержит четыре элемента данных упакованного двойного слова. Каждый элемент данных упакованного двойного слова содержит 32 бита информации. Упакованное квадраслово имеет длину 128 битов и содержит два элемента данных упакованного квадраслова. Фиг.4A – 4C иллюстрируют представление в регистре хранения упакованных данных согласно одному из вариантов осуществления изобретения. Представление 310 в регистре упакованного байта без знака показывает хранение упакованного байта 201 без знака в одном из регистров 209 мультимедиа, который показан на Фиг.4A. Информация для каждого элемента данных – байта – хранится в битах с седьмого по нулевой (с 7 по 0) для нулевого байта, с 15 по 8 для первого байта, с 23 по 16 для второго байта и, наконец, с 120 по 127 для 15-го байта. Таким образом, все доступные биты используются в регистре. Такая структура памяти увеличивает эффективность хранения данных процессора. Также, при обращении к 16 элементам данных теперь одна операция может одновременно выполняться с 16 элементами данных. Представление 311 в регистре упакованного байта со знаком показывает хранение упакованного байта 221 со знаком. Следует обратить внимание, что восьмой бит каждого элемента данных – байта – является индикатором знака. Представление 312 в регистре упакованного слова без знака показывает, как слова с седьмого по нулевое хранятся в регистре 209 мультимедиа, который показан на Фиг.4B. Представление 313 в регистре упакованного слова со знаком подобно представлению 312 в регистре упакованного слова без знака. Следует обратить внимание, что 16 бит каждого элемента данных типа слова является индикатором знака. Представление 314 в регистре упакованного двойного слова без знака показывает регистр 209 мультимедиа, хранящий два элемента данных типа двойного слова, как показано на Фиг.4C. Представление 315 в регистре упакованного двойного слова со знаком подобно представлению 314 в регистре упакованного двойного слова без знака. Заметим, что знаковым разрядом является 32-й бит элемента данных типа двойного слова. Эффективная фильтрация и свертка данных содержимого, как раскрывается в настоящем изобретении, начинаются с загрузки устройства-источника данных коэффициентами фильтрации/свертки и данными. Во многих случаях порядок данных или коэффициентов в устройстве хранения данных, таком, например, как регистр SIMD, требует изменения, прежде чем смогут быть выполнены арифметические вычисления. Соответственно, эффективные вычисления фильтрации и свертки требуют не только соответствующих арифметических команд, но также и эффективных способов организации данных, требуемых для вычислений. Например, как упомянуто при описании предшествующего уровня техники, изображения фильтруются с помощью замены значения, например, заданного пиксела I на S [I]. Значения пикселов с обеих сторон от пиксела I используют при вычислении фильтра S [I]. Точно так же пикселы с обеих сторон от пиксела I+1 требуются для вычисления S [I+1]. Следовательно, чтобы вычислить результаты фильтрации для больше, чем одного пиксела в регистре SIMD, данные копируются и размещаются в регистре ОКМД для вычисления. К сожалению, современные вычислительные архитектуры испытывают недостаток в эффективном способе упорядочения данных для всех соответствующих размеров данных в пределах вычислительной архитектуры. Соответственно, как изображено на Фиг.5, настоящее изобретение включает в себя команду перемещения байтов (PSHUFB) 145, которая эффективно упорядочивает данные любого размера. Операция 145 перемещения байтов упорядочивает данные, размеры которых больше, чем байт, поддерживая относительное расположение байтов в пределах больших данных во время операции перемещения. Кроме того, операция 145 перемещения байтов может изменять относительное расположение данных в регистре SIMD и может также копировать данные. На Фиг.5 показан пример операции 145 перемещения байтов для фильтра с тремя коэффициентами. Используя обычные методы, коэффициенты фильтра (не показаны) применяют к трем пикселам, и затем коэффициенты фильтра перемещают к другому пикселу и снова применяют. Однако для параллельного выполнения этих операций настоящее изобретение описывает новую команду для упорядочения данных. Соответственно, как изображено на Фиг.5, данные 404 формируются в устройстве-адресате 406 хранения данных, которое в одном из вариантов осуществления является устройством-источником 404 хранения данных, используя маску 402 для определения адреса, по которому соответствующие элементы данных хранятся в регистре-адресате 406. В одном из вариантов осуществления конфигурация маски основана на требуемой операции обработки данных, которая может включать в себя, например, операцию фильтрации, операцию свертки или подобные им. Соответственно, используя маску 402, обработка данных 406 вместе с коэффициентами может выполняться параллельно. В описанном примере запоминающим устройством-источником 404 данных является 128-битный регистр SIMD, который первоначально хранит 16 8-битных пикселов. При использовании фильтра пикселов с тремя коэффициентами четвертый коэффициент устанавливают в ноль. В одном из вариантов осуществления в зависимости от количества элементов данных в запоминающем устройстве-источнике 404 данных регистр-источник 404 может использоваться как устройство-адресат хранения данных, или регистр-адресат, таким образом сокращая количество регистров, которые необходимы в общем случае. Также, перезаписываемые данные в устройстве-источнике 404 хранения данных могут повторно загружаться из памяти или из другого регистра. Кроме того, множество регистров могут использоваться в качестве устройства-источника 404 хранения данных, причем их соответствующие данные формируются в устройстве-адресате 406 хранения данных, когда требуется. Когда упорядочивание элементов данных, а также коэффициентов закончено, данные и соответствующие коэффициенты должны обрабатываться в соответствии с операцией обработки данных. Специалистам должно быть понятно, что для вычислений фильтрации необходимы операции с различной точностью так же, как для вычислений свертки с использованием различного количества коэффициентов фильтра и различных размеров данных. Базовая операция фильтрации умножает две пары чисел и суммирует их результаты. Эту операцию называют командой умножения с накоплением. К сожалению, существующая вычислительная архитектура не обеспечивает поддержки эффективного вычисления умножения с накоплением для множества длин массива или фильтра и множества размеров данных с использованием коэффициентов без знака или со знаком. Кроме того, не поддерживаются операции с байтами. В результате, вычислительные системы обычной архитектуры должны преобразовывать 16-битные данные, используя команды распаковывания. Эти виды архитектур вычислительной системы в общем случае включают в себя поддержку операции умножения с накоплением, которые вычисляют произведения 16-разрядных данных в отдельных регистрах и затем складывают смежные произведения для получения 32-разрядного результата. Это решение приемлемо для коэффициентов фильтра для данных, которые требуют 16-разрядной точности, но для 8-битных коэффициентов фильтра для 8-битных данных (что является общим случаем для изображений и видеоинформации) параллелизм уровня команд и данных бесполезен. Фиг.6 изображает первый регистр-источник 452 и второй регистр-источник 454. В одном из вариантов осуществления первый и второй регистры-источники являются регистрами SIMD длиной N-бит, такие, например, как 128-битные регистры XMM технологии SSE2 корпорации Intel®. Команда умножения с накоплением, выполненная с таким регистром, дает следующие результаты для двух векторов 452 и 454 пикселов, которые сохраняют в регистре-адресате 456. Соответственно, пример показывает команду умножения с накоплением 8-битного байта на 16 слов, которая называется операцией 147 PMADDUSBW (фиг.1), в которой символы U и S в команде относятся к байтам со знаком и без знака. В одном из регистров-источников байты используют со знаком, а в другом они без знака. В одном из вариантов осуществления настоящего изобретения регистр с данными без знака является адресатом и содержит 16 результатов умножения с накоплением. Причиной для такого выбора является то, что в большинстве реализаций данные используют без знака, а коэффициенты – со знаком. Соответственно, предпочтительно перезаписать данные, потому что менее вероятно, что эти данные будут необходимы в будущих вычислениях. Дополнительные команды умножения с накоплением байтов, как показано на фиг.1, являются операцией 149 PMADDUUBW для байтов без знака в обоих регистрах и операцией 151 PMADDSSBW для байтов со знаком в обоих регистрах-источниках. Команды умножения с накоплением заканчиваются командой 153 PMADDWD, которая применяется к парам 16-разрядных слов со знаком для получения 32-разрядного произведения со знаком. Как в общем случае операций фильтрации, второй вектор обычно содержит коэффициенты фильтра. Соответственно, чтобы подготовить регистр XMM, коэффициенты могут загружаться в часть регистра и копироваться в остальную часть регистра, используя команду 145 перемещения. Например, как изображено на Фиг.7A, устройство 502 хранения данных коэффициентов, такое, например, как 128-битный регистр XMM, первоначально загружают тремя коэффициентами в ответ на выполнение команды загрузки данных. Однако специалистам должно быть понятно, что коэффициенты фильтра могут быть сформированы в памяти до обработки данных. Также, коэффициенты могут первоначально загружаться, как показано на фиг.7B, на основе их организации в памяти, до операции фильтрации. Регистр 502 коэффициентов включает в себя коэффициенты фильтра F3, F2 и F1, которые могут кодироваться как байты со знаком или без знака. Когда регистр 502 коэффициентов загружен, существующая команда PSHUFD может использоваться для копирования коэффициентов фильтра в оставшуюся часть регистра коэффициентов для получения следующего результата, как изображено на фиг.7B. Регистр 504 коэффициентов теперь включает в себя перемещенные (скопированные) коэффициенты, как требуется для параллельного выполнения операции обработки данных. Как известно специалистам, фильтры, которые включают в себя три коэффициента, являются обычными в алгоритмах обработки изображений. Однако специалистам должно быть понятно, что некоторые операции фильтрации, такие как JPEG 2000, используют девять и семь 16-разрядных коэффициентов. Соответственно, обработка такого коэффициента превышает емкость регистров коэффициентов, приводя к частично фильтрованному результату. Следовательно, обработка продолжается с использованием каждого коэффициента, пока конечный результат не будет получен. Фиг.7C иллюстрирует расположение данных пикселов в регистре-источнике 506, которые первоначально содержались в регистре-источнике 404, как показано на Фиг.5, и были перемещены в регистр-адресат 406. Соответственно, в ответ на выполнение операции обработки данных команда PMADDUSBW может использоваться для вычисления суммы этих двух результатов перемножения с сохранением результата в регистре-адресате 510. К сожалению, для завершения вычисления и генерации результатов обработки данных для выбранной операции обработки данных необходимо суммировать смежные пары сумм результатов умножения в регистре-адресате 510. Соответственно, если сумма команд умножения с накоплением длиннее, чем два пиксела, что имеет место в общем случае, то нужно сложить отдельные суммы. К сожалению, существующая вычислительная архитектура не обеспечивает эффективного способа сложения смежных сумм вследствие того, что смежные суммы находятся в пределах того же самого регистра-адресата. Соответственно, настоящее изобретение использует команды суммирования смежных элементов, результаты которых изображены на Фиг.8A – 8D. Фиг.8A изображает регистр-адресат 552 после суммирования двух смежных 16-битных значений (операция 157 PADDD2WD) для получения 32-битной суммы. Также, Фиг.8A изображает два смежных 16-битных результата выполнения команды умножения с накоплением, которые суммируют для получения 32-битной суммы 4-байтовых произведений. Фиг.8B изображает команду суммирования смежных значений (операция 157 PAADDD4WD), которая суммирует 4 смежных 16-разрядных значения для получения 32-разрядной суммы. Также, 4 смежных 16-разрядных результата команды умножения с накоплением байтов суммируют для получения 32-разрядной суммы 8-байтовых произведений. Фиг.8C показывает команду суммирования смежных значений (операция 157 PAADD8WD), которая суммирует 8 смежных 16-разрядных значений для получения 32-разрядной суммы. Также, данный пример показывает 8 смежных 16-разрядных результатов операции умножения с накоплением байтов, которые суммируются для получения 32-разрядной суммы 16-байтовых произведений. Соответственно, выбор команды для выполнения операции суммирования смежных значений основан на количестве звеньев в сумме (N). Например, используя фильтр с тремя коэффициентами, как изображено на Фиг.7A – 7C, первая команда (операция 157 PAADD2WD) получает результат, как показано на Фиг.8D. Однако из-за корреляции между двумя 16-битными векторами (например, первая строка макроблока) пикселов используется последняя команда (операция 157 PAADD8WD), как изображено на Фиг.8C. Такая операция становится все более важной для эффективной реализации, так как регистры ОКМД увеличиваются в размере. Без такой операции требуется много дополнительных команд. Набор команд суммирования смежных элементов согласно настоящему изобретению поддерживает широкий диапазон количества смежных значений, которые можно суммировать, и весь диапазон обычных типов данных. В одном из вариантов осуществления суммирование смежных 16-битных значений включает в себя набор команд (операция 157 PAADDNWD), диапазон которых начинается с суммирования двух смежных значений (N=2) и количество слагаемых удваивается до четырех (N=4), затем до восьми (N=8) и до общего количества в регистре. Размер данных суммы 16-битных результатов суммирования смежных значений равен 32 битам. В другом варианте осуществления смежные 16-битные значения (операция 161 PAADDWD) суммируются для получения 32-битной суммы. Этот вариант осуществления не включает в себя никакую другую команду с 16-битным размером данных, потому что команды суммирования смежных элементов с 32-битной входной информацией используются для сложения суммы, сформированной командой, с 16-битными входными значениями. Оба варианта осуществления включают в себя набор команд суммирования смежных 32-битных значений (операция 159 PAADDNDWD), диапазон которых начинается с суммирования двух смежных значений (N=2) и количество слагаемых удваивается до четырех (N=4), затем до восьми (N=8) и т.д. до общего количества в регистре. Размер данных суммы 32-битных результатов операции суммирования смежных значений равен 32 битам. В некоторых случаях результаты не заполняют регистр. Например, для команд, которые показаны на фиг.8A, 8B и 8C, суммирование трех различных смежных значений приводит к 4, 2 и 1 32-разрядному результату. В одном из вариантов осуществления результаты хранятся в младшей, наименее значимой части устройства-адресата хранения данных. Соответственно, когда существуют два 32-разрядных результата, как показано на Фиг.8B, результаты хранятся в младших 64 битах. В случае одного 32-разрядного результата, как показано на Фиг.8C, результаты хранятся в младших 32 битах. Специалистам должно быть понятно, что некоторые приложения используют сумму смежных байтов. Настоящее изобретение поддерживает суммирование смежных байтов с помощью команды (операция 155 PAADDNB), которая суммирует два смежных байта со знаком, получая 16-разрядное слово, и команды, которая суммирует два смежных байта без знака, получая в результате 16-разрядное слово. Приложения, которые требуют суммирования более двух смежных байтов, суммируют 16-разрядную сумму двух байтов с соответствующим результатом 16-битной операции суммирования смежных значений. Как только результаты операции обработки данных рассчитаны, следующая операция состоит в направлении результатов назад в запоминающее устройство. Как показано с помощью описанных выше вариантов осуществления, результаты могут кодироваться с 32-разрядной точностью. Поэтому результаты могут записываться назад в память, используя простые операции пересылки, оперирующие с двойными словами, например, описанную выше операцию 143 MOVD, а также логические операции сдвига вправо, действующие на целый регистр (PSRLDQ), логический сдвиг вправо двойного квадраслова. Для записи всех результатов назад в память нужно четыре операции MOVD и три операции PSRLDQ в первом случае (Фиг.8A), две операции MOVD и одна операция PSRLDQ во втором случае (Фиг.8B) и, наконец, только одна операция MOVD в последнем случае, как изображено на Фиг.8C. К сожалению, хотя операции суммирования смежных значений, как изображено на Фиг.1C, могут выполняться параллельно, вычисления фильтрации в общем случае требуют наличия следующего пиксела изображения. Один или более пикселов должны быть загружены в устройство-источник хранения данных или в регистр. Чтобы избежать загрузки в регистры этих восьми пикселов каждый раз, предложены два решения для этой операции. В одном из вариантов осуществления настоящее изобретение описывает операцию 163 объединения регистров, как изображено на фиг.9A. Для обработки пикселов A1 – A8 в регистре-адресате 606 пикселы A7 – A1 соединяют с пикселем A8 для формирования пикселов A8 – A1 в регистре-адресате 606. Соответственно, операция объединения регистров использует определенное количество байтов для выбранных регистров, которое обеспечивается входным параметром. Фиг.9B изображает альтернативный вариант осуществления для выполнения операции объединения регистров. Первоначально восемь пикселов загружают в первый регистр-источник 608 (MM0). Затем последующие восемь пикселов загружают во второй регистр-источник 610 (MM1). Затем выполняют операцию перестановки во втором регистре-источнике 610. После выполнения данный регистр 610 копируют в третий регистр-источник (MM2) 612. Затем первый регистр-источник 608 сдвигают вправо на восемь бит. Кроме того, второй регистр-источник 610 и регистр 614 маски объединяют в соответствии с командой упакованное «логическое И» и сохраняют в первом регистре-источнике 608. Затем выполняют операцию «логическое ИЛИ» со вторым регистром-источником 610 и первым регистром-источником 608 для получения следующего результата в регистре-адресате 620, что приводит к операции объединения регистров. Процесс продолжается, как показано, с помощью операции сдвига первого регистра-источника 608. Затем второй регистр-источник 610 сдвигают для получения значения регистра 612. Затем выполняют операцию «логическое И» для регистра 614 маски и второго регистра-источника 612, причем результаты сохраняют в регистре-адресате 622. Наконец, выполняют операцию упакованное «логическое ИЛИ» для второго регистра-источника 612 и первого регистра-источника 608, что приводит к последующей операции объединения регистров в регистре-адресате 624. Далее описаны способы процедур для реализации принципов настоящего изобретения. Работа Фиг.10 изображает схему, иллюстрирующую способ 700 для эффективной фильтрации и свертки данных содержимого, например, в компьютерной системе 100, которая изображена на Фиг.1 и 2. Как описано, данные содержимого относятся к данным изображения, аудио-, видеоинформации и речи. Кроме того, настоящее изобретение относится к устройствам хранения данных, которые, как понятно специалистам, включают в себя различные устройства хранения цифровых данных, которые включают в себя, например, регистры данных, такие как 128-битные регистры MMX архитектуры SSE2 Intel®. Согласно фиг.10 способ начинается на этапе 702, на котором определяют, выполняется ли операция обработки данных. Как описано, операция обработки данных включает в себя операции свертки и фильтрации, которые выполняются с данными пикселов, но не ограничена ими. Если «да», то выполняется этап 704 процесса. На этапе 704 процесса выполняется команда загрузки данных. В ответ на выполнение команды загрузки данных на этапе 706 процесса входной поток данных загружается в устройство-источник 212A хранения данных и вторичное устройство 212B хранения данных, например, как изображено на Фиг.2. На этапе 708 процесса определяют, выполнила ли операция обработки данных команду перемещения данных. В ответ на выполнение команды перемещения данных на этапе 710 процесса выбранная часть данных из, например, устройства-источника 212B хранения данных формируется в устройстве-адресате хранения данных или в соответствии с упорядочением коэффициентов – в устройстве хранения данных коэффициентов (см. фиг.5). Коэффициенты в устройстве хранения данных коэффициентов упорядочены согласно требуемым вычислениям операции обработки данных (например, как показано на фиг.7A и 7B). В одном из вариантов осуществления коэффициенты упорядочивают в памяти до каких-либо операций фильтрации. Соответственно, коэффициенты могут загружаться в запоминающее устройство данных коэффициентов без необходимости в перемещении (см. фиг.7B). Как описано выше, упорядочение данных и коэффициентов требуется для реализации параллельных вычислений, как это требуется для операций обработки, как изображено на фиг.7A-7C. Однако так как коэффициенты известны до операции обработки данных, коэффициенты могут упорядочиваться в памяти для обеспечения загрузки в регистр коэффициентов, как упорядочено в памяти, не требуя перемещения коэффициентов во время операции обработки данных. Наконец, на этапе 720 процесса загруженные данные обрабатываются согласно операции обработки данных для получения одного или более результатов обработки данных. После получения результатов операции обработки данных они могут записываться назад в память. Фиг.11 изображает схему, иллюстрирующую способ 722 обработки данных согласно операции обработки данных. На этапе 724 процесса определяется, выполнила ли операция обработки данных команду умножения с накоплением. В ответ на выполнение команды умножения с накоплением на этапе 726 процесса генерируются множество сумм пар произведений данных в запоминающем устройстве-адресате и коэффициентов в устройстве хранения данных коэффициентов, как изображено на Фиг.1C. Затем на этапе 728 процесса определяют, выполнила ли операция обработки данных команду суммирования смежных значений. В ответ на выполнение команды суммирования смежных значений на этапе 730 процесса смежные суммы пар произведений в устройстве-адресате хранения данных 510 (фиг.7C) суммируются в ответ на выполнение команды суммирования смежных значений для формирования одного или более результатов операции обработки данных (см. фиг.8D). Однако в некоторых вариантах осуществления, когда количество коэффициентов превышает емкость регистра коэффициентов (см. этап 732 процесса), получают частичные результаты обработки данных. Следовательно, обработка и упорядочение коэффициентов (этап 734 процесса) и данных (этап 736 процесса) продолжается, пока не будут получены заключительные результаты операции обработки данных, как указано на дополнительных этапах процесса 732-736. В противном случае, на этапе 738 процесса сохраняют один или больше результатов операции обработки данных. Наконец, на этапе 790 процесса определяют, закончена ли обработка входного потока данных. Этапы 724-732 процесса повторяют до тех пор, пока обработка входного потока данных не будет закончена. Как только обработка закончена, последовательность операций возвращается к этапу 720 обработки, на котором способ 700 заканчивается. Фиг.12 изображает схему, показывающую дополнительный способ 740 обработки дополнительных входных данных. На этапе 742 процесса определяется, имеются ли данные в устройстве-источнике 212A хранения данных, к которым не было обращения. Как уже описано, данные, к которым не было обращения, относятся к данным в устройстве-источнике 212A хранения данных, которые не перемещались в устройстве хранения данных для выполнения команды умножения с накоплением. Если устройство хранения данных содержит данные, к которым не было обращения, на этапе 744 процесса из устройства-источника хранения данных выбирают часть данных в качестве выбранных данных. После выбора выполняют этап 786 процесса. В противном случае, на этапе 746 процесса один или более необработанных элементов данных выбирают из устройства-источника хранения данных, а также как один или более элементов данных из вторичного устройства хранения данных. Как уже описано, необработанные элементы данных относятся к элементам данных, для которых результат операции обработки данных еще не был вычислен. Затем на этапе 780 процесса выполняется команда объединения регистров (см. фиг.9A и 9B), которая соединяет необработанные элементы данных устройства-источника хранения данных с элементами данных, выбранными из вторичного устройства хранения данных для формирования выбранных данных. Затем на этапе 782 процесса данные от вторичного устройства хранения данных перемещаются в устройство-источник хранения данных. По существу, данные в устройстве-источнике хранения данных больше не требуются, так как к ним всем уже обращались. Соответственно, вторичное устройство хранения данных, которое содержит данные, к которым не было обращения, может использоваться для перезаписи данных в устройство-источник хранения данных. На этапе 784 процесса вторичное устройство хранения данных загружается входным потоком данных из памяти, который требует дополнительной обработки данных, такой как фильтрация или свертка. Наконец, на этапе 786 процесса выбранные данные упорядочиваются в устройстве-адресате хранения данных или в соответствии с упорядочением коэффициентов – в устройстве хранения данных коэффициентов (см. Фиг.5). После выполнения последовательность операций управления возвращается на этап 790 обработки для продолжения обработки выбранных данных, как изображено на фиг.11. Фиг.13 изображает дополнительный способ 748 для выбора необработанных элементов данных. На этапе 750 процесса определяется, содержит ли устройство-источник хранения данных необработанные данные. Если каждая часть данных в устройстве-источнике хранения данных обработана, выполняется этап 770 процесса. На этапе 770 процесса из вторичного устройства хранения данных выбирается часть данных, которая функционирует как выбранные данные, которые затем обрабатывают в соответствии с операцией обработки данных. В противном случае, на этапе 752 процесса один или более необработанных элементов данных выбираются из устройства-источника хранения данных. Наконец, на этапе 766 процесса дополнительные элементы данных выбираются из вторичного устройства хранения данных согласно отсчету необработанных элементов данных для формирования выбранных данных. Данные, выбранные для перемещения в устройство-адресат хранения данных до выполнения операции обработки данных, ограничены отсчетом элементов данных на основе числа коэффициентов фильтра. Соответственно, с использованием этого отсчета элементов данных число необработанных элементов данных вычитается из отсчета элементов данных для определения числа элементов, которые надо выбрать из вторичного устройства хранения данных для выполнения операции объединения регистров. Фиг.14 изображает дополнительный способ 754 для выбора необработанных элементов данных этапа 752 процесса, как изображено на Фиг.13. На этапе 756 процесса из устройства-источника хранения данных выбирают элемент данных. Затем на этапе 758 процесса определяют, был ли результат операции обработки данных вычислен для данного элемента данных. Если такой результат был вычислен, выбранный элемент данных игнорируется. В противном случае, на этапе 760 процесса выбранный элемент данных является необработанным элементом данных и сохраняется. Затем на этапе 762 процесса отсчет необработанных элементов данных получает приращение. Наконец, на этапе 764 процесса этапы 756 – 762 процесса повторяют до тех пор, пока каждый элемент данных в устройстве-источнике хранения данных не будет обработан. Используя принципы настоящего изобретения, можно избежать ненужных изменений типа данных, что позволяет максимизировать число операций SIMD на одну команду. Кроме того, также достигается существенное сокращение числа тактовых циклов, требуемых для упорядочивания данных для арифметических операций. Соответственно, таблица 1 дает оценочные значения ускорения для различных приложений фильтрации с использованием принципов и команды, раскрытых в настоящем изобретении.
Альтернативные варианты осуществления Выше описаны различные аспекты реализации вычислительной архитектуры для обеспечения эффективной фильтрации и свертки данных содержимого с использованием регистров SIMD. Однако различные реализации вычислительной архитектуры обеспечивают множество признаков, которые включают в себя, дополняют и/или заменяют описанные выше признаки. Признаки могут быть реализованы как часть вычислительной архитектуры или как часть конкретных программных или аппаратных компонентов в различных реализациях. Кроме того, в предшествующем описании для целей объяснения использована определенная терминология для обеспечения полного понимания изобретения. Однако специалистам будет очевидно, что данные конкретные подробности не требуются для практического использования данного изобретения. Кроме того, хотя описанный вариант осуществления направлен на систему эффективной фильтрации и свертки данных содержимого с использованием регистров SIMD, специалистам должно быть понятно, что принципы настоящего изобретения могут быть применены к другим системам. Фактически, системы для обработки изображений, аудио и видеоданных охватываются настоящим изобретением без изменения сущности и объема настоящего изобретения. Описанные выше варианты осуществления были выбраны и описаны для наилучшего объяснения принципов изобретения и его практического применения. Эти варианты осуществления были выбраны для того, чтобы таким образом дать возможность другим специалистам лучшим образом использовать данное изобретение и различные варианты его осуществления с различными изменениями, которые подходят для конкретного рассматриваемого применения. Варианты осуществления настоящего изобретения обеспечивают много преимуществ по сравнению с известными методами. Настоящее изобретение включает в себя возможность эффективного осуществления операции фильтрации/свертки для множества длин массивов и размеров данных и знаков коэффициентов. Эти операции выполняются с использованием небольшого количества команд, которые являются частью небольшой группы команд обработки в архитектуре SIMD. Соответственно, настоящее изобретение позволяет избежать ненужных изменений типа данных. В результате, настоящее изобретение увеличивает количество операций SIMD за одну команду, значительно сокращая количество тактовых циклов, требуемых для упорядочивания данных для арифметических операций, таких как операции умножения с накоплением. На Фиг.15 представлена структурная схема микроархитектуры процессора одного из вариантов осуществления, который включает в себя логические схемы для выполнения параллельных операций объединения со сдвигом вправо в соответствии с настоящим изобретением. Операция объединения со сдвигом вправо может также упоминаться, как операция объединения регистров и команда объединения регистров, как в приведенном выше обсуждении. Для одного из вариантов осуществления команды объединения со сдвигом вправо (PSRMRG), команда дает те же самые результаты, что операция 167 объединения регистров на Фиг.1, 9A и 9B. Входной блок 1001 упорядоченной обработки является частью процессора 1000, которая выбирает макрокоманды, которые будут выполняться, и подготавливает их для последующего использования в конвейерной обработке процессора. Входной блок данного варианта осуществления включает в себя несколько модулей. Модуль 1026 предварительной выборки команд выбирает макрокоманды из памяти и передает их на декодер 1028 команд, который в свою очередь декодирует их в примитивы, которые называют микрокомандами или микрооперациями (также называют МОП), исполнение которых понятно машине. Трассировочный кэш 1030 берет декодированные микрооперации и транслирует их в программно упорядоченные последовательности, или трассы, в очереди 1034 микроопераций для исполнения. Когда трассировочный кэш 1030 обнаруживает сложную макрокоманду, ПЗУ 1032 микропрограмм обеспечивает микрооперации, которые нужны для завершения операции. Многие макрокоманды преобразуются в одну микрооперацию, а другие нуждаются в нескольких микрооперациях для завершения всей операции. В данном варианте осуществления, если для завершения макрокоманды необходимы больше, чем четыре микрокоманды, то декодер 1028 обращается к ПЗУ 1032 микропрограммы для выполнения макрокоманды. В одном из вариантов осуществления команда для алгоритма параллельного объединения со сдвигом вправо может храниться в пределах ПЗУ 1032 микропрограмм, когда для выполнения операции необходимо множество микроопераций. Трассировочный кэш 1030 ссылается на точку входа в программируемую логическую матрицу (ПЛМ, PLA) для определения правильного указателя микрокоманды для считывания последовательности микропрограммы для разделенных алгоритмов в ПЗУ 1032 микропрограмм. После того как ПЗУ 1032 микропрограмм закончит упорядочивание микроопераций для текущей макрокоманды, входной блок 1001 устройства возобновляет выборку микроопераций из трассировочного кэша 1030. Некоторые команды SIMD и другие мультимедийные типы команд рассматриваются как сложные команды. Большинство команд, относящихся к командам с плавающей запятой также являются сложными командами. Когда декодер 1028 команд обнаруживает сложную макрокоманду, осуществляется обращение в ПЗУ 1032 микропрограмм в соответствующие ячейки для извлечения последовательности микропрограммы для данной макрокоманды. Различные микрооперации, необходимые для выполнения этой макрокоманды, передаются на средство 1003 исполнения с изменением последовательности для исполнения в соответствующих модулях исполнения: целочисленном и с плавающей запятой. В средстве 1003 исполнения с изменением последовательности микрокоманды подготавливаются к исполнению. Логические схемы исполнения с изменением последовательности имеют множество буферов для сглаживания и переупорядочивания потока микрокоманд для оптимизации производительности, когда они продвигаются вниз по конвейеру и планируются для исполнения. Логические схемы средства распределения распределяют машинные буфера и ресурсы, требуемые каждой микрооперации для исполнения. Логические схемы переименования регистров переименовывают логические регистры в записи в файле регистров. Средство распределения также распределяет запись для каждой микрооперации в одну из двух очередей микроопераций, одна – для операций с памятью и одна – для операций без обращения к памяти, перед следующими планировщиками команд: планировщик памяти, быстрый планировщик 1002, медленный/общий планировщик 1004 для операций с плавающей запятой и простой планировщик 1006 для операций с плавающей запятой. Планировщики 1002, 1004, 1006 микроопераций определяют, когда микрооперация готова для исполнения на основании готовности зависимых от них регистров-источников входных операндов и доступности ресурсов выполнения, требуемых микрооперации для завершения операции. Быстрый планировщик 1002 для данного варианта осуществления может выполнять планирование на каждую половину основного тактового цикла, в то время как другие планировщики могут выполнять планирование только один раз за основной тактовый цикл процессора. Планировщики решают конфликты для портов отправки при планировании микроопераций для выполнения. Файлы 1008, 1010 регистров находятся между планировщиками 1002, 1004, 1006 и модулями 1012, 1014, 1016, 1018, 1020, 1022, 1024 исполнения в блоке 1011 исполнения. Существуют отдельные файлы 1008, 1010 регистров для операций с целыми числами и с плавающей запятой соответственно. Каждый файл 1008, 1010 регистров данного варианта осуществления также включает в себя сеть обхода, которая может обойти или передать только что завершенные результаты, которые еще не были записаны в файл регистров, к новой зависимой микрооперации. Файл 1008 целочисленных регистров и файл 1010 регистров с плавающей запятой также способны передавать данные друг другу. Для одного из вариантов осуществления файл 1008 целочисленных регистров разбит на два отдельных файла регистров, один файл регистров для младших 32 разрядов данных и второй файл регистров для старших 32 разрядов данных. Файл 1010 регистров с плавающей запятой одного из вариантов осуществления содержит записи длиной 128 битов, потому что команды с плавающей запятой в типовом случае имеют операнды длиной от 64 до 128 битов. Блок 1011 исполнения содержит модули 1012, 1014, 1016, 1018, 1020, 1022, 1024 исполнения, где команды фактически исполняются. Эта часть включает в себя файлы 1008, 1010 регистров, которые хранят данные значений целочисленных операндов и операндов с плавающей запятой, которые необходимы для выполнения микрокоманд. Процессор 1000 данного варианта осуществления состоит из множества модулей исполнения: модуль генерации адресов (МГА, AGU) 1012, МГА 1014, быстродействующее арифметико-логическое устройство 1016, быстродействующее арифметико-логическое устройство 1018, медленнодействующее арифметико-логическое устройство 1020, арифметико-логическое устройство 1022 с плавающей запятой, модуль 1024 перемещения с плавающей запятой. Для данного варианта осуществления модули 1022, 1024 исполнения с плавающей запятой исполняют операции MMX, ОКМД и SSE с плавающей запятой. Арифметико-логическое устройство 322 с плавающей запятой данного варианта осуществления включает в себя модуль деления 64 бита на 64 бита с плавающей запятой для исполнения микроопераций деления, извлечения квадратного корня и определения остатка. Для вариантов осуществления настоящего изобретения любое действие с использованием значения с плавающей запятой осуществляется с использованием аппаратных средств с плавающей запятой. Например, преобразования из целочисленного формата в формат с плавающей запятой предусматривают использование файла регистров с плавающей запятой. Точно так же операция деления с плавающей запятой осуществляется в модуле деления с плавающей запятой. С другой стороны, числа, которые не являются числами с плавающей запятой, и целые числа обрабатываются с помощью целочисленных аппаратных средств. Простые, очень частые операции АЛУ направляются в быстродействующие модули 1016, 1018 исполнения АЛУ. Быстродействующие АЛУ 1016, 1018 данного варианта осуществления могут выполнять быстрые операции с эффективным временем ожидания, равным половине тактового цикла. Для одного из вариантов осуществления самые сложные целочисленные операции направляются в медленнодействующие АЛУ 1020, поскольку медленнодействующие АЛУ 1020 включает в себя целочисленные аппаратные средства выполнения для операций с длительным временем ожидания, таких как умножение, сдвиги, обработка логики флажков и обработка переходов. Операции загрузить/сохранить в памяти выполняют МГА 1012, 1014. Для данного варианта осуществления целочисленные АЛУ 1016, 1018, 1020 описаны в контексте выполнения целочисленных операций с 64-битными операндами данных. В альтернативных вариантах осуществления АЛУ 1016, 1018, 1020 могут быть реализованы для поддержки различной разрядности, включая 16, 32, 128, 256 битов и т.д. Точно так же модули 1022, 1024 для операций с плавающей запятой могут быть осуществлены для поддержки диапазона операндов с различным количеством битов. Для одного из вариантов осуществления модули 1022, 1024 для операций с плавающей запятой могут обрабатывать упакованные операнды данных длиной 128 битов во взаимосвязи с SIMD и мультимедийными командами. В данном варианте осуществления планировщики 1002, 1004, 1006 микроопераций осуществляют диспетчеризацию зависимых операций прежде, чем порождающая загрузка закончит выполняться. Поскольку микрооперации в процессоре 1000 планируются и выполняются по предположению, процессор 1000 также включает в себя логические схемы для обработки пропусков в памяти. Если загружаемые данные отсутствуют в кэше данных, то в конвейерной обработке могут иметь место зависимые операции, которые вышли из планировщика с временно неправильными данными. Средство повторного исполнения отслеживает и повторно исполняет команды, которые используют неправильные данные. Должны повторно исполняться только зависимые операции, а независимые операции имеют возможность завершения. Планировщики и средство повторного исполнения одного из вариантов осуществления процессора также предназначены для исполнения последовательности команд для целочисленных операций деления с расширенной точностью. Термин «регистры» используется для обращения к встроенным ячейкам памяти процессора, которые используются как часть макрокоманд для идентификации операндов. Другими словами, упоминаемые регистры «видимы» извне процессора (с точки зрения программиста). Однако описанные регистры могут быть реализованы с помощью схем в процессоре с использованием различных методов, например, выделенных физических регистров, динамически распределяемых физических регистров, использующих переименование регистра, комбинаций выделенных и динамически распределяемых физических регистров и т.д. Для последующего обсуждения понимается, что регистры являются регистрами данных, предназначенными для хранения упакованных данных, например, имеющие длину 64 бита регистры MMX В примерах, представленных на следующих чертежах, описан ряд операндов данных. Для простоты, сегменты данных помечены от буквы А в алфавитном порядке, причем сегмент А находится в самом младшем адресе, а сегмент Z должен был бы находиться в самом старшем адресе. Таким образом, А может находиться по адресу 0, B – по адресу 1, C – по адресу 3 и т.д. Хотя последовательности данных в некоторых из примеров показаны буквами, размещаемыми в обратном алфавитном порядке, адресация все равно начинается с А в 0, B в 1 и т.д. В принципе, операция сдвига вправо, такая как объединение со сдвигом вправо для одного из вариантов осуществления, влечет за собой сдвиг вправо сегментов данных с младшим адресом, если последовательность соответствует D, C, B, A. Таким образом, сдвиг вправо просто сдвигает элементы данных блока данных направо относительно постоянной линии. Кроме того, операция объединения со сдвигом вправо может в принципе сдвинуть вправо крайние правые сегменты данных одного операнда в левую сторону другого операнда данных, как если бы эти два операнда были бы непрерывными. Фиг.16A представлена структурная схема одного из вариантов осуществления логической схемы для выполнения параллельной операции объединения со сдвигом вправо с операндами данных в соответствии с настоящим изобретением. Команда (PSRMRG) для операции объединения со сдвигом вправо (также сдвиг регистра) для данного варианта осуществления начинается с трех частей информации: первый операнд 1102 данных, второй операнд 1104 данных и счетчик 1106 сдвига. В одном из вариантов осуществления команда сдвига PSRMRG декодируется в одну микрооперацию. В альтернативном варианте осуществления команда может декодироваться в различное количество микроопераций для выполнения операции объединения со сдвигом с операндами данных. Для данного примера операнды 1102, 1104 данных являются частями 64-битных данных, хранящихся в регистре/памяти, а отсчет 1106 сдвига является непосредственным значением длиной 8 битов. В зависимости от конкретной реализации операнды данных и отсчет сдвига могут иметь другие размеры, например, 128/256 битов и 16 битов соответственно. Первый операнд 1102 в данном примере состоит из восьми сегментов данных: P, O, N, М, L, K, J и I. Второй операнд 1104 состоит также из восьми сегментов данных: H, G, F, E, D, C, B и A. Сегменты данных имеют равную длину, и каждый содержит один байт (8 битов) данных. Однако другой вариант осуществления настоящего изобретения работает с более длинными 128-битовыми операндами, причем каждый из сегментов данных состоит из одного байта (8 битов), и операнд длиной 128 битов имеет шестнадцать сегментов данных длиной один байт. Точно так же, если каждый сегмент данных является двойным словом (32 бита) или квадрасловом (64 бита), то 128-битный операнд имеет четыре сегмента данных длиной в двойное слово или два сегмента данных длиной в квадраслово соответственно. Таким образом варианты осуществления настоящего изобретения не ограничены определенной длиной операндов данных, сегментов данных или отсчет сдвига и могут иметь размер, соответствующий каждой реализации. Операнды 1102, 1104 могут находиться или в регистре, или в ячейке памяти, или файле регистров, или в комбинации указанных средств. Операнды 1102, 1104 данных и отсчет 1106 подаются на модуль 1110 исполнения в процессоре вместе с командой объединения со сдвигом вправо. Ко времени, когда команда объединения со сдвигом вправо достигает модуля 1110 исполнения, команда должна быть декодирована ранее в конвейере процессора. Таким образом команда объединения со сдвигом вправо может быть в форме микрооперации (МОП) или в некотором другом декодированном формате. Для данного варианта осуществления два операнда 1102, 1104 данных принимаются в логической схеме объединения и временном регистре. Логическая схема объединения объединяет/присоединяет сегменты данных для этих двух операндов и размещает новый блок данных во временном регистре. Новый блок данных состоит из шестнадцати сегментов данных: P, O, N, М, L, K, J, I, H, G, F, E, D, C, B, A. Поскольку данный пример работает с операндами длиной 64 бита, временный регистр должен содержать объединенные данные длиной 128 битов. Для операндов данных длиной 128 битов необходим временный регистр длиной 256 битов. Логическая схема 1114 сдвига вправо в модуле 1110 исполнения берет содержимое временного регистра и выполняет логический сдвиг вправо блока данных на n сегментов данных, как запрашивается отсчетом 1106. В данном варианте осуществления отсчет 1106 указывает количество байтов, на которые будет выполнен сдвиг вправо. В зависимости от конкретной реализации отсчет 1106 может также использоваться для указания количества битов, полубайтов, слов, двойных слов, квадраслов и т.д., на которые будет выполнен сдвиг, в зависимости от степени детализации сегментов данных. Для данного примера значение n равно 3, так что содержимое временного регистра сдвигается на три байта. Если каждый сегмент данных имеет длину слова или двойного слова, то отсчет может указывать количество слов или двойных слов, на которые будет выполнен сдвиг, соответственно. Для данного варианта осуществления 0 сдвигаются с левой стороны временного регистра для заполнения освобождающегося пространства, по мере того как данные в регистре сдвигаются вправо. Таким образом, если отсчет 1106 сдвига больше, чем количество сегментов данных в операнде данных (в данном случае восемь), то один или более 0 могут появиться в результирующем значении 1108. Кроме того, если отсчет 1106 сдвига равен или превышает общее количество сегментов данных для обоих операндов, то результат будет содержать все 0, поскольку все сегменты данных будут сдвинуты и выведены. Логическая схема 1114 сдвига вправо выводит соответствующее количество сегментов данных из временного регистра в качестве результата 1108. В другом варианте осуществления схема может включать в себя мультиплексор вывода или регистр-защелку после логической схемы сдвига вправо для вывода результирующего значения. Для данного примера результат имеет длину 64 бита и включает в себя восемь байтов. При операции объединения со сдвигом вправо с этими двумя операндами 1102, 1104 данных результат состоит из следующих восьми сегментов данных: K, J, I, H, G, F, E и D. На фиг.16B представлена структурная схема другого варианта осуществления логической схемы для выполнения операции объединения со сдвигом вправо. Подобно предыдущему примеру на Фиг.16A, операция объединения со сдвигом вправо данного варианта осуществления начинается с трех частей информации: первый операнд 1102 данных длиной 64 бита, второй операнд 1104 данных длиной 64 бита и отсчет 1106 сдвига длиной 8 битов. Отсчет 1106 сдвига указывает, на сколько разрядов нужно сдвинуть сегменты данных. Для данного варианта осуществления отсчет 1106 устанавливается в количестве байтов. В альтернативном варианте осуществления отсчет может указывать количество битов, полубайтов, слов, двойных слов или квадраслов, на которые будет выполнен сдвиг данных. В данном примере первый операнд 1102 состоит из восьми имеющих одинаковую длину в один байт сегментов данных (H, G, F, E, D, C, B, A), и второй операнд 1104 состоит из восьми сегментов данных (P, O, N, М, L, K, J, I). Счетчик n равен 3. Другой вариант осуществления изобретения может работать с операндами и сегментами данных альтернативного размера, например, с операндами длиной 128/256/512 битов и сегментами данных размером бит/байт/слово/двойное слово/квадраслово и отсчет сдвига длиной 8/16/32 битов. Таким образом варианты осуществления настоящего изобретения не ограничены определенной длиной операндов данных, сегментов данных или счетчика сдвига и могут иметь размер, соответствующий каждой реализации. Операнды 1102, 1104 данных и отсчет 1106 подаются на модуль 1120 исполнения в процессоре вместе с командой объединения со сдвигом вправо. Для данного варианта осуществления первый операнд 1102 данных и второй операнд 1104 данных принимаются логической схемой 1122 сдвига влево и логической схемой 1124 сдвига вправо соответственно. Отсчет 1106 также подается на логические схемы 1122, 1124 сдвига. Логическая схема 1122 сдвига сдвигает влево сегменты данных для первого операнда 1102 на количество сегментов, равное «количеству сегментов данных в первом операнде – n». По мере того как сегменты данных сдвигаются влево, с правой стороны вводятся 0 для заполнения освобождающегося пространства. В данном случае существует восемь сегментов данных, так что первый операнд 1102 сдвигается влево на восемь минус три, или пять разрядов. Первый операнд 1102 сдвигается на значение этой разницы для достижения правильного выравнивания данных для объединения в схеме 1126 «логическое ИЛИ». После сдвига влево первый операнд данных принимает вид: K, J, I, 0, 0, 0, 0, 0. Если отсчет 1106 больше количества сегментов данных в операнде, то вычисление сдвига влево может привести к отрицательному числу, указывая на отрицательный сдвиг влево. Логический сдвиг влево с отрицательным отсчетом интерпретируется как сдвиг в отрицательном направлении и по существу логический сдвиг вправо. Отрицательный сдвиг влево вводит 0 с левой стороны первого операнда 1102. Точно так же логическая схема 1124 сдвига вправо сегментов данных сдвигает вправо второй операнд на n сегментов. По мере того как сегменты данных сдвигаются вправо, 0 вводятся с левой стороны для заполнения освобождающегося пространства. Второй операнд данных принимает вид: 0, 0, 0, H, G, F, E, D. Сдвинутые операнды выводятся из логических схем 1122, 1124 сдвига влево/вправо и объединяются в схеме 1126 «логическое ИЛИ». Схема «логическое ИЛИ» выполняет операцию «логическое ИЛИ» сегментов данных и обеспечивает результат 1108 длиной 64 бита для данного варианта осуществления. Осуществление операции «ИЛИ» для «K, J, I, 0, 0, 0, 0, 0» и «0, 0, 0, H, G, F, E, D» формирует результат 1108, содержащий восемь байтов: K, J, I, H, G, F, E, D. Этот результат такой же, как для первого варианта осуществления настоящего изобретения, показанного на Фиг.16A. Следует обратить внимание, что для отсчета 1106 n, превышающего количество элементов данных в операнде, соответствующее количество 0 может появиться в результате, начиная с левой стороны. Кроме того, если отсчет 1106 больше или равен общему количеству элементов данных в обоих операндах, то результат будет содержать все 0. Фиг.17A иллюстрирует действие команды параллельного объединения со сдвигом вправо в соответствии с первым вариантом осуществления настоящего изобретения. Для данного обсуждения MM1 1204, MM2 1206, TMP 1232 и DEST 1242 в общем случае упоминаются как операнды или блоки данных, а также включают в себя регистры, файлы регистров и ячейки памяти, но не ограничены ими. В одном из вариантов осуществления MM1 1204 и MM2 1206 – регистры MMX длиной 64 бита (в некоторых случаях их также называют ‘mm’). В состоянии I 1200, отсчет сдвига imm [y] 1202, первый операнд MM1 [x] 1204 и второй операнд MM2 [x] 1206 подаются с командой параллельного объединения со сдвигом вправо. Отсчет 1202 представляет собой непосредственное значение длиной y битов. Первый 1204 и второй 1206 операнды являются блоками данных, которые включают в себя x сегментов данных и имеют полную длину 8x битов каждый, если каждый сегмент данных равен байту (8 битам). Первый 1204 и второй 1206 операнды каждый упакованы с помощью множества меньших сегментов данных. Для данного примера первый операнд 1204 данных MM1 состоит из восьми сегментов данных равной длины: P 1211, O 1212, N 1213, М 1214, L 1215, K 1216, J 1217, I 1218. Точно так же второй операнд 1206 данных MM2 состоит из восьми сегментов данных равной длины: H 1221, G 1222, F 1223, E 1224, D 1225, C 1226, B 1227, А 1228. Таким образом каждый из этих сегментов данных имеет длину ‘x·8’ битов. Так, если значение x равно 8, то каждый операнд имеет длину 8 байтов, или 64 бита. Для других вариантов осуществления элемент данных может быть полубайтом (4 бита), словом (16 битов), двойным словом (32 бита), квадрасловом (64 бита) и т.д. В альтернативных вариантах осуществления значение x может быть равно 16, 32, 64 и т.д. элементов данных. Счетчик y равен 8 для данного варианта осуществления, и непосредственное значение может быть представлено как байт. В альтернативных вариантах осуществления значение y может быть равно 4, 16, 32 и т.д. битов. Кроме того, отсчет 1202 не ограничен непосредственным значением и может также храниться в ячейке памяти или в регистре. Операнды 1204 MM1 и 1206 MM2 объединяются вместе в состоянии II 1230 для формирования временного блока данных TEMP [2x] 1232 длиной 2x элементов данных (или байтов в данном случае). Объединенные данные 1232 для данного примера состоят из шестнадцати сегментов данных, размещенных следующим образом: P, O, N, М, L, K, J, I, H, G, F, E, D, C, B и A. Окно 1234 длиной восемь байтов обрамляет восемь сегментов данных временного блока 1232 данных, начиная с младшего разряда (правого края). Таким образом, правый край окна 1234 выравнивается с правым краем блока 1232 данных так, что окно 1234 обрамляет сегменты данных: H, G, F, E, D, C, B и A. Отсчет 1202 сдвига n указывает требуемое количество сдвигов вправо объединенных данных. Значение отсчета может устанавливать величину сдвига в битах, полубайтах, байтах, словах, двойных словах, квадрасловах и т.д. или конкретное число сегментов данных. Основываясь на значении отсчета 1202, блок 1232 данных сдвигается вправо 1236 на n сегментов данных в данном случае. Для данного примера значение n равно 3, и блок 1232 данных сдвигается вправо на три разряда. Иначе это можно рассматривать как сдвиг окна 1234 в противоположном направлении. Другими словами, окно 1234 может в принципе рассматриваться, как сдвинутое на три разряда влево от правого края временного блока 1232 данных. Для одного из вариантов осуществления, если отсчет сдвига n больше общего количества сегментов данных 2x, существующих в объединенном блоке данных, то результат содержит все 0. Точно так же, если отсчет сдвига n больше или равен количеству сегментов данных x в первом операнде 1204, то результат включает в себя один или более 0, начиная с левой стороны результата. В состоянии III 1240 сегменты данных (K, J, I, H, G, F, E, D), обрамленные окном 1234, выводятся как результат к адресату DEST [x] 1242, имеющему длину x элементов данных. Фиг.17B иллюстрирует действие команды объединения со сдвигом вправо в соответствии со вторым вариантом осуществления. Команда объединения со сдвигом вправо в состоянии I 1250 сопровождается отсчетом imm [y] длиной y битов, первым операндом данных MM1 [x], состоящим из x сегментов данных, и вторым операндом данных MM2 [х], состоящим из x сегментов данных. Как в примере по фиг.17A, значение y равно 8 и значение x равно 8, причем каждый из MM1 и MM2 имеет длину 64 битов, или 8 байтов. Первый 1204 и второй 1206 операнды для данного варианта осуществления упакованы с помощью множества имеющих одинаковый размер сегментов данных, в данном случае каждый из них имеет длину один байт, «P 1211, O 1212, N 1213, М 1214, L 1215, K 1216, J 1217, I 1218» и «H 1221, G 1222, F 1223, E 1224, D 1225, C 1226, B 1227, А 1228» соответственно. В состоянии II 1260 отсчет 1202 сдвига n используется для сдвига первого 1204 и второго 1206 операндов. Отсчет для данного варианта осуществления указывает количество сегментов данных для сдвига вправо объединенных данных. Для данного варианта осуществления сдвиг происходит перед объединением первого 1204 и второго 1206 операндов. В результате первый операнд 1204 сдвигается по-другому. В данном примере первый операнд 1204 сдвигается влево на x минус n сегментов данных. Вычисление «х – n» учитывает надлежащее выравнивание данных при последующем объединении данных. Таким образом для значения отсчета n, равного 3, первый операнд 1204 сдвигается влево на пять сегментов данных, или на пять байтов. Имеются 0, которые вводят с правой стороны для заполнения освобождающегося пространства. Но если отсчет 1202 сдвига n больше, чем количество сегментов данных x, доступных в первом операнде 1204, то для сдвига влево вычисление «x – n» может привести к отрицательному числу, которое в сущности указывает на отрицательный сдвиг влево. В одном из вариантов осуществления логический сдвиг влево с отрицательным отсчетом интерпретируется как сдвиг влево в отрицательном направлении и, по существу, как логический сдвиг вправо. При отрицательном сдвиге влево 0 вводятся с левой стороны первого операнда 1204. Точно так же второй операнд 1206 сдвигается вправо на значение отсчета сдвига, равного 3, и 0 вводятся с левой стороны для заполнения свободного места. Результаты выполнения сдвига для первого 1204 и второго 1206 операндов хранятся в регистрах длиной x сегментов данных ТЕМP1 1266 и TEMP2 1268 соответственно. Сдвинутые результаты из ТЕМP1 1266 и TEMP2 1268 объединяются 1272 для получения требуемого объединения со сдвигом данных в регистре-адресате DEST 1242 в состоянии III 1270. Если отсчет 1202 сдвига n больше x, то операнд может содержать один или более 0 в результате с левой стороны. Кроме того, если отсчет 1202 сдвига n равен или больше 2x, то результат в регистре DEST 1242 будет содержать все 0. В приведенных выше примерах, например, на фиг.17A и 17B один или оба регистра MM1 и MM2 могут быть 64-битными регистрами данных в процессоре, реализующем технологию MMX/SSE, или 128-битными регистрами данных технологии SSE2. В зависимости от реализации эти регистры могут иметь длину 64/128/256 битов. Точно так же один или оба регистра MM1 и MM2 могут быть другими ячейками памяти, отличными от регистров. В архитектуре процессора одного из вариантов осуществления MM1 и MM2 – исходные операнды для команды объединения со сдвигом вправо (PSRMRG), как описано выше. Отсчет сдвига IMM также является непосредственным числом для такой команды PSRMRG. Для одного из вариантов осуществления адресатом для результата DEST является также регистр данных MMX или XMM. Кроме того, регистр DEST может быть тем же самым регистром, что и один из исходных операндов. Например, в одной из архитектур команда PSRMRG имеет первый исходный операнд MM1 и второй исходный операнд MM2. Предварительно определенным адресатом для результата может быть регистр первого исходного операнда, в данном случае регистр MM1. На фиг.18А представлена последовательность операций, иллюстрирующая один из вариантов осуществления способа сдвига вправо и операнды данных для параллельного объединения. Значения длины L в общем случае используются для представления длины блоков данных и операндов. В зависимости от конкретного варианта осуществления L может использоваться для определения длины в сегментах данных, битах, байтах, словах и т.д. На этапе 1302 первый операнд данных длиной L принимается для использования при выполнении операции объединения со сдвигом. На этапе 1304 также принимается второй операнд данных длиной L для операции объединения со сдвигом. На этапе 1306 принимается отсчет сдвига, указывающий количество сегментов данных или расстояние в битах/полубайтах/байтах/словах/двойных словах/квадрасловах. На этапе 1308 логические схемы исполнения объединяют первый операнд и второй операнд. Для одного из вариантов осуществления временный регистр длиной 2L содержит объединенный блок данных. В альтернативном варианте осуществления объединенные данные хранятся в ячейке памяти. На этапе 1310 составной блок данных сдвигается вправо на значение отсчета сдвига. Если отсчет выражен в сегментах данных, то блок данных сдвигается вправо на данное количество сегментов данных и слева вводятся 0 со старших значащих разрядов блока данных для заполнения освободившегося места. Если отсчет выражен, например, в битах или байтах, то блок данных подобным образом сдвигается вправо на это расстояние. На этапе 1312 результат длиной L генерируется с правой стороны, или с младших значащих разрядов, сдвинутого блока данных. Для одного из вариантов осуществления L сегментов данных мультиплексируются из сдвинутого блока данных в регистр-адресат или в ячейку памяти. На фиг.18B представлена последовательность операций, иллюстрирующая другой вариант осуществления способа объединения и сдвига вправо данных. Первый операнд данных длиной L принимается для обработки с помощью операции сдвига вправо и объединения на этапе 1352. На этапе 1354 принимается второй операнд данных длиной L. На этапе 1356 отсчет сдвига указывает требуемое расстояние для сдвига вправо. На этапе 1358 первый операнд данных сдвигается влево на основе вычисления с помощью отсчета сдвига. Вычисление в одном из вариантов осуществления содержит вычитание отсчета сдвига из L. Например, если длина операнда L и отсчет сдвига указаны в сегментах данных, то первый операнд сдвигается влево на «L – отсчет сдвига» сегментов, причем 0 вводятся с младших значащих разрядов операнда. Точно так же, если L выражен в битах, а отсчет выражен в байтах, то первый операнд сдвигается влево на «L – отсчет сдвига·8» битов. На этапе 1360 второй операнд данных сдвигается вправо на значение отсчета сдвига, и 0 вводятся со старших значащих разрядов второго операнда для заполнения освободившегося места. На этапе 1362 сдвинутый первый операнд и сдвинутый второй операнд объединяются вместе для получения результата длиной L. Для одного из вариантов осуществления при объединении получается результат, содержащий требуемые сегменты данных и от первого, и от второго операндов. Одним из все более популярных видов использования компьютеров является обработка чрезвычайно больших видео и аудиофайлов. Даже при том, что такие видео и аудиофайлы в типовом случае передаются через сети с очень высокой пропускной способностью или через носители данных большой емкости, сжатие данных все еще необходимо для обработки трафика. В результате, различные алгоритмы сжатия становятся важными частями схем представления или кодирования многих популярных форматов аудио, видео и изображений. Видеоизображения в соответствии с одним из стандартов MPEG являются одним из приложений, которые используют сжатие. Видеоизображения формата MPEG разбивают на иерархию уровней для обеспечения обработки ошибок, случайного поиска и редактирования и синхронизации. Для целей иллюстрации кратко описаны эти уровни, которые составляют одно видеоизображение стандарта MPEG. На верхнем уровне находится уровень видеопоследовательности, который включает в себя независимый поток битов. Второй уровень вниз – группа изображений, составленных из одной или более групп внутренних кадров и/или невнутренних кадров. Третий уровень вниз – уровень собственно изображений, и следующий уровень под ним – уровень срезов. Каждый срез – непрерывная последовательность упорядоченных по растру макроблоков, наиболее часто на основе строк в типичных видеоприложениях, но не ограничен ими. Каждый срез состоит из макроблоков, которые являются массивами 16×16 пикселов яркости, или элементов изображения, с двумя массивами 8×8 связанных пикселов цветности. Макроблоки могут дополнительно разделяться на различные блоки 8×8 для дополнительной обработки, такой как кодирование преобразования. Макроблок является фундаментальной единицей для компенсации и оценки движения, и может иметь связанные с ним векторы движения. В зависимости от варианта осуществления макроблоки могут иметь 16 строк на 16 столбцов или другие различные размеры. Один из методов прогнозирования во времени, используемый в видеоизображениях стандарта MPEG, основан на оценке движения. Оценка движения основана на предпосылке, что последовательные видеокадры в общем случае будут подобны между собой за исключением изменений, вызванных объектами, движущимися в пределах кадров. Если существует нулевое движение между кадрами, то кодер может легко и эффективно предсказать текущий кадр, как дубликат предыдущего кадра, или кадр предсказания. Предыдущий кадр можно также назвать опорным кадром. В другом варианте осуществления опорным кадром может быть следующий кадр или даже некоторый другой кадр в последовательности. Варианты осуществления оценки движения не обязаны сравнивать текущий кадр с предыдущим кадром. Таким образом при сравнении может использоваться любой другой кадр. Затем на кодер передается синтаксическая служебная информация, необходимая для восстановления изображения из первоначального эталонного кадра. Но когда существует движение между изображениями, ситуация становится более сложной. Различия между наиболее совпадающими макроблоками и текущим макроблоком в идеале являются множеством 0-х значений. При кодировании макроблока различия между совпадающим наилучшим образом и текущим макроблоком преобразуются и квантуются. Для одного из вариантов осуществления квантуемые значения передаются в средство кодирования с переменной длиной для сжатия. Поскольку 0 можно сжать очень хорошо, желательно иметь лучшее соответствие с множеством 0-ых различий. Векторы движения могут, таким образом, быть получены из значений различия. На фиг.19A иллюстрируется первый пример оценки движения. Левый кадр 1402 является выборкой предыдущего видеокадра, который включает в себя фигуру из палочек и указатель. Правый кадр 1404 является образцом текущего видеокадра, который включает в себя такие же фигуру из палочек и указатель. В текущем кадре 1404 панорамирование привело к тому, что указатель подвинулся вправо и вниз от его первоначального положения в предыдущем кадре 1402. Фигура из палочек, теперь с поднятыми руками, в текущем кадре также сдвинулась вниз к правой стороне от центра предыдущего кадра 1402. Для соответствующего представления изменений между двумя видеокадрами 1402, 1404 могут использоваться алгоритмы оценки движения. Для одного из вариантов осуществления алгоритм оценки движения выполняет полный двумерный (2D) пространственный поиск для каждого макроблока яркости. В зависимости от реализации оценка движения не может непосредственно применяться к цветности в видеоизображении стандарта MPEG, поэтому цветное движение может быть адекватно представлено с помощью той же самой информации о движении, что и сигнал яркости. Много различных способов возможны для осуществления оценки движения, и конкретная схема выполнения оценки движения в некоторой степени зависит от отношения сложности к качеству для данного конкретного применения. Полный, исчерпывающий перебор по широкой 2-мерной (2D) области может в общем случае привести к лучшим результатам сравнения. Однако такое качество приводит к большой стоимости вычислений, поскольку оценка движения часто является наиболее дорогостоящей в вычислительном отношении частью видеокодирования. Попытки снизить стоимость за счет ограничения диапазона поиска пикселов или типа поиска могут стоить некоторой потери качества видеоизображения. Фиг.19B показывает пример макроблочного поиска. Каждый из кадров 1410, 1420 включает в себя различные макроблоки. Целевым макроблоком 1430 текущего кадра является текущий макроблок, который будет сравниваться с предыдущими макроблоками предыдущих кадров 1410, 1420. В первом кадре 1410 макроблок 1412 плохого соответствия содержит часть указателя и плохо соответствует текущему макроблоку. Во втором кадре 1420 макроблок 1420 хорошего соответствия содержит биты указателя и головы фигуры из палочек, как в текущем макроблоке 1430, который должен кодироваться. Эти два макроблока 1422, 1430 имеют некоторую общность, и видна только небольшая ошибка. Поскольку найдено относительно хорошее соответствие, кодер назначает векторы движения данному макроблоку. Эти векторы указывают, насколько далеко данный макроблок должен быть перемещен по горизонтали и вертикали для того, чтобы получить соответствие. Фиг.20 показывает пример применения оценки движения и результирующее предсказание при генерации второго кадра. Предыдущий кадр 1510 опережает по времени текущий кадр 1520. Для данного примера текущий кадр 1520 вычитается из предыдущего кадра 1510 для получения менее сложного остаточного изображения 1530 ошибки, которое может кодироваться и передаваться. Предыдущий кадр 1510 данного примера состоит из указателя 1511 и фигуры 1513 из палочек. Текущий кадр 1520 состоит из указателя 1521 и двух фигур из палочек 1522, 1523 на доске 1524. Чем точнее движение будет оценено и согласовано, тем более вероятно, что остаточная ошибка сможет приблизиться к нулю и привести к высокой эффективности кодирования. Макроблочное предсказание может способствовать уменьшению размера окна поиска. Эффективность кодирования может быть достигнута за счет использования факта, что векторы движения высоко коррелированы между макроблоками. Таким образом, горизонтальный компонент может сравниваться с предыдущим достоверным горизонтальным компонентом вектора движения, и различие между ними – кодироваться. Точно так же может вычисляться различие для вертикального компонента перед кодированием. Для данного примера вычитание текущего кадра 1520 из предыдущего кадра 1510 приводит к остаточному изображению 1530, которое включает в себя вторую фигуру 1532 из палочек с поднятыми руками и доску 1534. Это остаточное изображение 1530 сжимается и передается. В идеале, это остаточное изображение 1530 менее сложно для кодирования и требует меньшего объема памяти, чем в случае сжатия и передачи всего текущего кадра 1520. Однако не каждый макроблочный поиск приводит к приемлемому соответствию. Если кодер определяет, что не существует приемлемого соответствия, то может кодироваться данный конкретный макроблок. Фиг.21A – B показывают пример текущего 1601 и предыдущего 1650 кадров, которые обрабатываются во время оценки движения. Предыдущий кадр 1650 предшествует текущему кадру 1601 в хронологическом порядке для последовательности видеокадров. Каждый кадр состоит из очень большого количества пикселов, которые простираются по кадру в горизонтальном и вертикальном направлениях. Текущий кадр 1601 состоит из множества макроблоков 1610, 1621-1627, которые упорядочены по горизонтали и по вертикали. Для данного варианта осуществления текущий кадр 1601 разделен на имеющие одинаковый размер непересекающиеся макроблоки 1610, 1621-1627. Каждый из этих квадратных макроблоков дополнительно подразделяется на равное количество строк и столбцов. Для того же самого макроблока 1610 показана матрица из восьми строк и восьми столбцов. Каждый квадрат макроблока 1610 соответствует одному пикселу. Таким образом этот макроблок 1610 выборки включает в себя 64 пиксела. В других вариантах осуществления макроблоки имеют размер шестнадцать строк на шестнадцать столбцов (16×16). Для одного из вариантов осуществления данные для каждого пиксела состоят из восьми информационных разрядов, или одного слова. В альтернативных вариантах осуществления пиксел данных может иметь другие размеры, включая полубайты, слова, двойные слова, квадраслова и т.д. Эти текущие макроблоки текущего кадра пытаются сравнивать с макроблоками в предыдущем кадре 1650 для оценки движения. Для данного варианта осуществления предыдущий кадр 1650 включает в себя окно 1651 поиска, причем окно 1651 поиска заключает в себе часть кадра. Окно 1651 поиска содержит область, в которой отыскивается согласование текущего макроблока текущего кадра 1601. Подобно текущему кадру, окно поиска разделено на множество имеющих одинаковый размер макроблоков. Показан примерный макроблок 1660, имеющий восемь строк и восемь столбцов, но макроблоки могут иметь другие отличающиеся размеры, включая шестнадцать строк и шестнадцать столбцов. Во время работы алгоритма оценки движения одного из вариантов осуществления каждый из отдельных макроблоков окна 1651 поиска сравнивается последовательно с текущим макроблоком текущего кадра для поиска приемлемого соответствия. Для одного из вариантов осуществления верхний левый угол первого предыдущего макроблока в окне 1651 поиска выравнивается с верхним левым углом окна 1651 поиска. Во время работы одного из алгоритмов оценки движения направление обработки макроблоков проходит от левой стороны окна поиска к правому краю, от пиксела к пикселу. Таким образом крайний левый край второго макроблока находится на один пиксел дальше от левого края окна поиска и т.д. В конце первой строки пикселов алгоритм возвращается к левому краю окна поиска и продолжается от первого пиксела следующей строки. Этот процесс повторяется до тех пор, пока макроблоки для каждого из пикселов в окне 1651 поиска не будут сравнены с текущим макроблоком. Фиг.22A – D иллюстрируют операции оценки движения в кадрах в соответствии с одним из вариантов осуществления настоящего изобретения. Обсуждаемые варианты осуществления настоящего изобретения используют алгоритмы оценки движения полного поиска. При полном поиске макроблоки для всех позиций пикселов в окне поиска предыдущего (опорного) кадра пытаются сравнивать с макроблоком текущего кадра. Для одного из вариантов осуществления быстрый алгоритм оценки движения полного поиска использует SIMD операции объединения со сдвигом вправо для быстрой обработки упакованных данных кадров. Операции SIMD объединения со сдвигом вправо одного из вариантов осуществления могут также улучшить производительность процессора путем сокращения количества загрузок данных, особенно невыровненных загрузок памяти, и других команд управления данными. В общем случае процедура оценки движения в одном из вариантов осуществления может быть описана в псевдокоде как: для каждого текущего блока в каждом из направлений x и y { для всех позиций с коэффициентом 1 на оси Y окна поиска { для всех позиций с коэффициентом 4 на оси X окна поиска { загружают данные пикселов из памяти в регистры; пытаются сравнить блоки для 4 смежных предыдущих макроблоков; отслеживают минимальное значение и расположение индекса для данного предыдущего макроблока; }}}в которой операция сравнения блоков определяется следующим образом: для каждой строки с 1 до m { для каждого макроблока, начиная со столбца 1 до 4 { генерируют правильные данные для этой предыдущей [строки] из данных, хранящихся в регистрах; оцениваемые данные [строки] += сумма абсолютных различий (текущая [строка], предыдущая [строка]); }}. Таким образом для данного варианта осуществления для каждого местоположения пиксела в окне поиска предыдущие макроблоки сравнивают с текущим макроблоком. Как указано выше, данный вариант осуществления оценивает четыре смежных предыдущих макроблока за цикл. Данные пикселов загружаются из памяти, причем информацию из памяти в регистры загружают с выравниванием. С помощью операций объединения со сдвигом вправо можно манипулировать этими данными пикселов для формирования различных комбинаций сдвинутых сегментов данных, соответствующих смежным макроблокам. Например, первый, второй, третий и четвертый пикселы первой строки первого предыдущего макроблока могут начинаться с адресов памяти 0, 1, 2 и 3 соответственно. Для первого пиксела первой строки второго предыдущего макроблока этот пиксел начинается с адреса памяти 1. Таким образом операция объединения со сдвигом вправо с данными регистра может сформулировать те необходимые данные строки пикселов для второго предыдущего макроблока с помощью многократного использования данных, уже загруженных из памяти для первого предыдущего макроблока, что приводит к сбережению времени и ресурсов. Подобные операции объединения со сдвигом могут генерировать данные строки для других смежных предыдущих макроблоков, например, для третьего, четвертого и т.д. Таким образом процедура сравнения блоков для алгоритма оценки движения одного из вариантов осуществления может быть описана в псевдокоде следующим образом: сравнивают блоки для четырех смежных предыдущих макроблоков { для каждой строки с 1 до m { загружают данные пикселов для одной строки текущего макроблока; выполняют выровненную загрузку из памяти в регистры двух последовательных «порций» данных пикселов для одной строки окна поиска; генерируют правильные строки данных пикселов для каждого из четырех смежных предыдущих макроблоков из загруженных данных посредством операции объединения со сдвигом вправо; вычисляют сумму абсолютных различий между строкой предыдущего макроблока и соответствующей строкой текущего макроблока для каждого из четырех смежных предыдущих макроблоков; накапливают четыре отдельные суммы абсолютных значений различий для каждого из четырех смежных предыдущих макроблоков; }} Данная процедура дополнительно описана ниже. Хотя эти примеры описаны в терминах действий над четырьмя смежными макроблоками окна поиска, альтернативные варианты осуществления настоящего изобретения этим не ограничены. Впрочем, варианты осуществления настоящего изобретения не ограничены обработкой смежных макроблоков. Также многочисленные опорные макроблоки, обрабатываемые вместе, не обязательно должны отличаться на расстояние одного пиксела. Для одного из вариантов осуществления любые опорные макроблоки, имеющие расположение пикселов в пределах окна 16 на 16 относительно конкретного местоположения пиксела, могут обрабатываться вместе. В зависимости от количества аппаратных ресурсов, например от доступных регистров данных и модулей исполнения, другие варианты осуществления могут выполнять сравнение блоков и вычисление сумм абсолютных различий на большем или меньшем количестве макроблоков. Например, другой вариант осуществления, использующий по меньшей мере 8 регистров упакованных данных для хранения 4 различных комбинаций данных пикселов, генерированных операциями объединения со сдвигом вправо с двумя «порциями» данных, имеющими длину 8 сегментов данных, может обрабатывать 4 смежных предыдущих макроблока с помощью просто двух выровненных загрузок из памяти длиной 8 сегментов данных. Четыре из 8 регистров упакованных данных используют для вычисления служебной информации: они содержат первые 8 сегментов данных предыдущего кадра, следующие 8 сегментов данных предыдущего кадра, 8 сегментов данных текущего кадра и 8 сегментов данных из операции объединения со сдвигом вправо. Другие четыре регистра упакованных данных используются для накопления итоговых значений для сумм абсолютных значений разностей (САР) для каждого из этих четырех макроблоков. Можно добавить больше регистров упакованных данных для вычисления и накопления САР, хотя бы для увеличения количества опорных макроблоков, которые обрабатываются вместе. Таким образом, если четыре дополнительных регистра упакованных данных доступны, то также могут обрабатываться четыре дополнительных предыдущих макроблока. Количество доступных регистров упакованных данных для хранения накопленной суммы абсолютных разностей в одном из вариантов осуществления может ограничивать количество одновременно обрабатываемых макроблоков. Кроме того, в некоторых архитектурах процессоров обращения к памяти имеет конкретные гранулярности и выравнены в определенных границах. Например, один процессор может делать выборки из памяти на основе 16- или 32-байтовых блоков. В этом случае обращение к данным, которые не выровнены по 16- или 32-байтовой границе, могло бы потребовать невыровненного доступа к памяти, который является дорогостоящим по времени выполнения и ресурсам. Еще хуже, когда желательная часть данных пересекает границу и перекрывается с множеством блоков памяти. Разбиение строк кэш-памяти, которое потребовало бы невыровненных загрузок при обращении к данным, расположенным на двух отдельных строках кэш-памяти, может быть дорогостоящим. Ситуация усугубляется, когда строки данных пересекают границу страниц памяти. Например, в случае процесса, который работает с 8-байтовыми блоками памяти, и макроблока, охватывающего 8 пикселов, имеющего один байт данных на пиксел, одна выровненная загрузка из памяти была бы достаточна для данной макроблочной строки. Но для следующего смежного макроблока, расположенного на один столбец пикселов дальше, данные, необходимые для этой строки пикселов, охватывали бы 7 байтов данных блока памяти из первого макроблока, но также пересекали бы границу памяти на 1 байт данных следующего блока памяти. Варианты осуществления настоящего изобретения используют операции объединения со сдвигом вправо для эффективной обработки данных. В одном из вариантов осуществления два последовательных блока памяти загружаются при выровненных границах памяти и сохраняются в регистрах для многократного использования. При выполнении операций объединения со сдвигом вправо эти блоки памяти могут использоваться и сегменты данных в них могут сдвигаться на необходимые расстояния для получения правильной строки данных. Так в данном примере команда объединения со сдвигом вправо может использовать два уже загруженных блока памяти и вывести один байт данных из второго блока, а затем ввести один байт данных во второй блок из первого для генерации данных для первой строки второго макроблока, не требуя выполнения невыровненной загрузки. Варианты осуществления оценки движения могут также нарушить цепочки зависимости, основываясь на том, каким образом реализуется алгоритм. Например, изменяя порядок вычислений, зависимость от данных/команд может быть удалена или изменена так, что некоторые вычисления и команды могут выполняться не по порядку, как в процессоре 1000 на фиг.15. Повышение производительности может стать даже большим для новых поколений архитектуры процессора ввиду увеличенного времени ожидания исполнения и доступных вычислительных ресурсов. Используя вариант осуществления команды объединения со сдвигом вправо, можно избежать некоторой зависимости в последовательности сравнения блоков. Например, многократные операции суммирования абсолютных разностей и/или операции накопления могут выполняться параллельно. Фиг.22A иллюстрирует перемещение текущих макроблоков по текущему кадру 1701. Для данного варианта осуществления каждый текущий макроблок 1710 разделен на 16 строк и 16 столбцов, и таким образом содержит 256 отдельных пикселов. Для данного варианта осуществления пикселы в каждом макроблоке 1710 обрабатывают как отдельную строку 1711 за один момент времени. Когда все шестнадцать строк текущего блока обработаны по отношению к необходимым макроблокам в окне поиска, обрабатывают следующий текущий макроблок. Макроблоки в данном варианте осуществления обрабатывают в горизонтальном направлении 1720 с левой стороны к правой стороне текущего кадра 1701, каждый раз сдвигаясь на размер макроблока. Другими словами, текущие макроблоки не перекрываются в данном варианте осуществления, и текущие макроблоки упорядочены так, что каждый макроблок является смежным со следующим. Например, первый макроблок может располагаться от столбца 1 пикселов до столбца 16 пикселов. Второй макроблок располагается от столбца 17 до столбца 32, и т.д. В конце строки макроблоков процесс возвращается 1722 к левому краю и опускается вниз на одну высоту макроблока, на шестнадцать строк в данном примере. Макроблоки, расположенные ниже на один размер макроблока, затем обрабатывают по горизонтали 1724 слева направо до тех пор, пока не будут завершены предпринятые сравнения для всего кадра 1701. Фиг.22B иллюстрирует перемещение макроблоков по окну 1751 поиска предыдущего (опорного) кадра. В зависимости от конкретной реализации окно 1751 поиска может быть сфокусировано на определенной области и таким образом может быть меньше, чем весь предыдущий кадр. В другом варианте осуществления окно поиска может полностью перекрывать предыдущий кадр. Подобно текущему блоку, каждый предыдущий макроблок 1760, 1765, 1770, 1775 разделен на 16 строк и 16 столбцов для получения общего количества 256 пикселов в каждом макроблоке. Для данного варианта осуществления настоящего изобретения четыре предыдущих макроблока 1760, 1765, 1770, 1775 окна 1751 поиска обрабатывают параллельно по отношению к одному текущему блоку при поиске соответствия. В отличие от текущих макроблоков текущего кадра предыдущие макроблоки 1760, 1765, 1770, 1775 в окне 1751 поиска могут перекрываться, и перекрываются в данном примере. В данном случае каждый предыдущий макроблок сдвигается на один столбец пикселов. Таким образом крайний левый пиксел в первой строке макроблока BLK 1 – пиксел 1761, для макроблока BLK 2 – пиксел 1766, для макроблока BLK 3 – пиксел 1771, и пиксел 1776 – для макроблока BLK 4. При реализации алгоритма оценки движения каждую строку предыдущего макроблока 1760, 1765, 1770, 1775 сравнивают с соответствующей строкой текущего блока. Например, каждую строку 1 макроблоков BLK 1 1760, BLK 2 1765, BLK 3 1770 и BLK 4 1775 обрабатывают по сравнению со строкой 1 текущего блока. Построчное сравнение для четырех перекрывающихся смежных макроблоков продолжается, пока все 16 строк макроблоков не будут обработаны. Для обработки следующих четырех макроблоков алгоритм, соответствующий данному варианту осуществления, предусматривает сдвиг на четыре столбца пикселов. Таким образом для данного примера крайним левым первым столбцом пикселов для следующих четырех макроблоков являются пиксел 1796, пиксел 1797, пиксел 1798 и пиксел 1799 соответственно. Для данного варианта осуществления обработка предыдущего макроблока продолжается вправо 1780 по окну 1751 поиска с возвратом 1782 для возобновления с позиции на одну строку пикселов ниже, с крайнего левого пиксела окна 1751 поиска до тех пор, пока окно поиска не будет закончено. Хотя текущие макроблоки текущего кадра данного варианта осуществления не перекрываются, и следующие отдельные макроблоки имеют высоту или длину в один макроблок, предыдущие макроблоки предыдущего или опорного кадра перекрываются, и следующие макроблоки увеличиваются на одну строку или столбец пикселов. Хотя четыре опорных макроблока 1760, 1765, 1770, 1775 данного примера являются смежными и отличаются на один столбец пикселов, любой макроблок в окне 1751 поиска, который перекрывает конкретную область относительно выбранного месторасположения пиксела, может обрабатываться вместе с макроблоком в этом месторасположении пиксела. Например, обрабатывается макроблок 1760 с пикселом 1796. Любой макроблок в пределах окна 16×16 относительно пиксела 1796 может обрабатываться вместе с макроблоком 1760. Окно 16×16 в данном примере обусловлено размерами макроблока и длины строки. В данном случае одна строка данных имеет 16 элементов данных. Поскольку эта функция сравнения блоков для данного варианта осуществления алгоритма оценки движения может загрузить две строки данных из 16 элементов данных и выполнить объединение со сдвигом вправо для получения различных строк данных, имеющих сдвинутые/объединенные версии этих двух строк данных, другие макроблоки, которые перекрывают окно 16×16, для которого будут загружаться данные для этого макроблока, будут иметь возможность по меньшей мере частично повторно использовать эти загруженные данные. Таким образом, любой макроблок, перекрывающийся макроблок 1760, например макроблоки 1765, 1765, 1770, 1775 или макроблок, начинающийся с правой нижней позиции пикселя макроблока 1760, может обрабатываться вместе с макроблоком 1760. Различие в степени перекрытия влияет на количество данных из предыдущих загрузок данных, которые могут многократно использоваться. В вариантах осуществления оценки движения в соответствии с настоящим изобретением макроблочный анализ содержит сравнение между предыдущим (эталонным) макроблоком и текущим макроблоком на построчной основе для получения суммы абсолютных значений разностей между двумя макроблоками. Сумма абсолютных значений разностей может указывать на то, насколько отличаются макроблоки и насколько они совпадают. Каждый предыдущий макроблок для одного из вариантов осуществления может быть представлен с помощью значения, полученного с помощью накопления суммы абсолютных разностей для всех шестнадцати строк в макроблоке. Для текущего анализируемого макроблока поддерживается запись макроблока с самым близким соответствием. Например, отслеживается минимальная накопленная сумма абсолютных значений разностей и индекс местоположения для этого соответствующего предыдущего макроблока. По мере того как оценка движения продвигается по окну поиска, накопленная сумма каждого предыдущего макроблока сравнивается с минимальным значением. Если более поздний предшествующий макроблок имеет меньшее накопленное значение разностей, чем отслеженное минимальное значение, таким образом указывая на более близкое соответствие, чем существующее самое близкое соответствие, то накопленное значение разностей и индексная информация для этого более позднего предшествующего макроблока становятся новым минимальным значением разностей и индексом. Когда доступные макроблоки для всех пикселов в окне поиска обработаны, согласно одному из вариантов осуществления, индексированный макроблок с минимальным значением разностей может использоваться для получения остаточного изображения для сжатия данного текущего кадра. Фиг.22C показывает параллельную обработку четырех эталонных макроблоков 1810, 1815, 1820, 1825 для заданного окна поиска с текущим блоком 1840 для одного из вариантов осуществления настоящего изобретения. Для данного примера, данные для пикселов в окне поиска упорядочиваются как «A, B, C, D, E, F, G, H, I, J, K, L, М, N, O, P» 1860, причем «A» – младший адресный разряд (0) в наборе данных, и «P» – старший адресный разряд (15). Этот набор пикселов 1860 содержит два раздела 1681, 1682, каждый из которых имеет восемь (m) сегментов данных. Использование операций объединения со сдвигом вправо, как описано выше, позволяет вариантам осуществления настоящего изобретения управлять операндами с помощью этих двух разделов данных 1618, 1682 и генерировать должным образом выровненные данные строки 1830 для различных предыдущих макроблоков 1810, 1815, 1820, 1825. Все макроблоки, предыдущие 1810, 1815, 1820, 1825 и текущий 1840, имеют размер m строк на m столбцов. Для целей обсуждения и упрощения в данном примере значение m равно восьми. Альтернативные варианты осуществления могут иметь макроблоки других размеров, в которых, например, значение m равно 4, 16, 32, 64, 128, 256 и т.д. В данном примере алгоритм оценки движения применяется к первой строке этих четырех предыдущих блоков 1810, 1815, 1820, 1825 с первой строкой текущего блока 1840. Для одного из вариантов осуществления данные пикселов, которые включают в себя эти два раздела данных 1861,1862 длиной, равной двум макроблокам (2m), загружаются из памяти с помощью двух операций выровненной загрузки из памяти и хранятся во временных регистрах. Операции объединения со сдвигом вправо с этими двумя разделами данных 1861, 1862 позволяют генерировать девять возможных комбинаций данных 1830 строки без многочисленных обращений к памяти. Кроме того, можно избежать невыровненной загрузки из памяти, которая является дорогостоящей по времени выполнения и ресурсам. В данном примере эти два раздела данных 1861, 1862 выравнивают в границах байта. Загрузки из памяти, которые не начинаются с адреса на границе байта, например, с сегментов данных B, D или D, в типовом случае требуют операции невыровненной загрузки из памяти. Данные 1830 строки для каждого из блоков являются такими, как описано далее, причем крайний левый сегмент данных имеет самый младший адрес. В блоке 1 1810 строка 1 1811 содержит «A, B, C, D, E, F, G, H». Так как данные в строке 1 1811 те же самые, как в первом разделе данных 1861, в сдвиге нет необходимости. Но строка 1 1816 блока 2 1815 содержит «B, C, D, E, F, G, H, I». Поскольку предыдущие блок 1 1810 и блок 2 1815 отделены друг от друга одним пикселом по горизонтали, блок 2 1815 начинается с данных пиксела B, тогда как блок 1 1810 начинается с данных пиксела А, и данные второго пиксела – B. Таким образом объединение со сдвигом вправо этих двух разделов данных 1861, 1862 со счетчиком сдвига может привести к данным строки 1 блока 2. Точно так же блок 3 1820 находится еще на один пиксел дальше вправо, и строка 1 1821 блока 3 1820 начинается с данных пиксела C и содержит «C, D, E, F, G, H, I, J». Операция объединения со сдвигом вправо с операндами этих двух разделов данных 1861, 1862 со счетчиком сдвига, равным двум, формирует данные строки 1 блока 3. Строка 1 1826 блока 4 1825 состоит из «D, E, F, G, H, I, J, K». Эти данные могут быть сформулированы с помощью операции объединения со сдвигом вправо с отсчетом четыре, с теми же самыми операндами данных. Таким образом использование операций объединения со сдвигом вправо с временно сохраненными предварительно загруженными разделами данных 1861, 1862 позволяет повторно использовать данные при генерации данных строки для других смежных макроблоков и сохраняет время/ресурсы, сокращая количество загрузок из памяти, особенно невыровненных загрузок из памяти. Заметим, что данные пикселов для текущего блока являются теми же самыми для всех сравнений сумм абсолютных разностей с опорными макроблоками предыдущего кадра. Одна выровненная загрузка из памяти может потребоваться для данных 1842 строки текущего блока 1840, поскольку текущий блок 1840 может быть выровнен в границах памяти. Продолжая пример одного из вариантов осуществления оценки движения, каждая строка предыдущих макроблоков 1810, 1815, 1820, 1825 сравнивается с соответствующей строкой текущего блока 1840 для получения значения суммы абсолютных разностей. Таким образом строка 1 1811 блока 1 1810 сравнивается со строкой 1 1841 текущего блока 1840 с помощью операции 1850 вычисления сумм абсолютных разностей (САР). То же самое происходит с другими тремя обрабатываемыми блоками. Хотя оказалось, что эти четыре макроблока 1810, 1815, 1820, 1825 обрабатываются одновременно или параллельно, другие варианты осуществления настоящего изобретения не ограничены этим. Так, операции с этими четырьмя макроблоками могут происходить последовательно во времени, но как последовательность из четырех операций. Например, строку 1 каждого опорного блока подвергается операции 1850 САР со строкой текущего блока 1840 в порядке: блок 1 1810, блок 2 1815, блок 3 1820 и блок 4 1825. Затем строка 2 каждого опорного блока подвергается операции 1850 САР, и т.д. После каждой операции 1850 САР текущее общее значение сумм абсолютных разностей накапливается во временном регистре. Таким образом, в данном примерном варианте осуществления четыре регистра накапливают сумму абсолютных разностей до тех пор, пока все m строк данного макроблока не будут обработаны. Накопленное значение для каждого блока сравнивается с существующим минимальным значением разностей, как часть поиска лучшего соответствия макроблоков. Хотя данный пример описывает обработку четырех смежных перекрывающихся предыдущих макроблоков, другие макроблоки, которые перекрывают первый блок BLK 1810 в окне поиска, могут также обрабатываться вместе с загрузками данных для BLK 1810, если строки данных релевантны. Таким образом также может обрабатываться макроблок в пределах окна 16×16 вокруг обрабатываемого в настоящий момент макроблока. Фиг.22D показывает операции 1940 вычисления сумм абсолютных разностей (САР) и суммирование этих значений САР. Здесь, каждая из строк от строки А до строки P опорного макроблока БЛОК 1 1900 и соответствующие им строки для текущего макроблока 1920 подвергаются операции 1940 САР. Операция 1940 САР сравнивает данные, представляющие пикселы в каждой строке, и вычисляет значение, представляющее абсолютные разности между этими двумя строками, одна из предыдущего макроблока 1900 и одна из текущего макроблока 1920. Значения этих операций 1940 САР для всех строк, с А до P, суммируются вместе, как сумма 1942 блока. Эта сумма 1942 блока обеспечивает накопленное значение суммы абсолютных разностей всего предыдущего макроблока 1900 и текущего макроблока 1920. Основываясь на этой сумме 1942 блока, алгоритм оценки движения может определить, насколько подобны, или близки, соответствия предыдущего макроблока 1900 относительно данного текущего макроблока 1920. Хотя данный вариант осуществления обрабатывает четыре опорных макроблока одновременно, альтернативные варианты осуществления могут обрабатывать другое количество макроблоков в зависимости от количества загруженных данных пикселов и количества доступных регистров. Кроме того, множество регистров может использоваться во время процесса оценки движения. Например, расширенные регистры, такие как регистры mm технологии MMX или регистры XMM технологии SSE2, могут использоваться для хранения упакованных данных, например данных пикселов. В одном из вариантов осуществления регистр MMX длиной 64 бита может содержать восемь байтов, или восемь отдельных пикселов, если каждый пиксел имеет восемь битов данных. В другом варианте осуществления регистр XMM длиной 128 битов может содержать шестнадцать байтов, или шестнадцать отдельных пикселов, если каждый пиксел имеет восемь битов данных. Точно так же регистры других размеров, например длиной 32/128/256/512 битов, которые могут содержать упакованные данные, могут также использоваться в вариантах осуществления настоящего изобретения. С другой стороны вычисления, которые не требуют использования регистров упакованных данных, например обычные целочисленные операции, могут использовать целочисленные регистры и аппаратные средства для работы с целочисленными данными. На фиг.23A представлена последовательность операций, показывающая один из вариантов осуществления способа предсказания и оценки движения. На этапе 2002 инициализируется отслеженное минимальное (мин.) значение и индекс местоположения для этого минимального значения. Для данного варианта осуществления отслеженное минимальное значение и индекс указывают, который из обработанных предыдущих (опорных) макроблоков из окна поиска имеет самое близкое соответствие с текущим макроблоком. На этапе 2004 выполняется проверка того, была ли закончена обработка всех требуемых макроблоков в текущем кадре. Если да, то эта часть алгоритма оценки движения выполнена. Если не все требуемые текущие макроблоки были обработаны, то на этапе 2006 выбирается необработанный текущий макроблок для текущего кадра. На этапе 2008 сравнение блоков продвигается от расположения первого пиксела в окне поиска предыдущего (опорного) кадра. На этапе 2010 выполняется проверка того, была ли закончена обработка окна поиска. При первом проходе окно поиска не было обработано. Но при последующих проходах, если все окно поиска было обработано, то последовательность операций возвращается к этапу 2004 для определения, доступны ли другие текущие макроблоки. Если все окно поиска не было проанализировано, то на этапе 2012 определяется, были ли обработаны все пикселы строки по оси X. Если эта строка была обработана, то значение отсчета строк увеличивается до значения следующей строки и процедура обработки возвращается к этапу 2010 для проверки, доступны ли еще макроблоки на этой новой строке в окне поиска. Но если не все доступные макроблоки для пикселов в строке были обработаны, на этапе 2014 выполняется проверка того, был ли обработан макроблок для пиксела в этих столбце и строке. Если данный макроблок был обработан, то отсчет столбцов увеличивается, и процедура обработки возвращается к этапу 2012 для проверки, был ли обработан макроблок для пиксела в этом новом столбце. Но если макроблок для пиксела в этих столбце и строке не был обработан, то выполняется сравнение блоков между этим опорным макроблоком и текущим макроблоком. Последовательность операций в данном примере для простоты описана с приращением строк и столбцов для пикселов, расположенных по осям X и Y, на один пиксел за один раз. Однако для одного из вариантов осуществления настоящего изобретения четыре предыдущих макроблока обрабатывают за один проход. Таким образом отсчет столбцов по оси Y увеличивают на четыре столбца за один проход. Другие варианты осуществления могут также обрабатывать 8, 16, 32 и т.д. макроблоков одновременно, и таким образом отсчет столбцов соответственно увеличивается на 8, 16, 32 и т.д. столбцов для указания на правильную позицию пиксела для последующего прохода алгоритма. Хотя процесс сравнения блоков данного варианта осуществления использует поиск по осям X и Y упорядоченным образом, сравнение блоков другого варианта осуществления может использовать другой алгоритм, например алгоритм ромбовидного поиска, который использует отличающийся шаблон, или логарифмический поиск. На фиг.23B представлена последовательность операций, дополнительно описывающая сравнение блоков на Фиг.23A. На этапе 2222 загружаются данные для опорного макроблока и текущего макроблока. Для одного из вариантов осуществления данные опорного макроблока загружаются как две «порции» упакованных данных, которые включают в себя данные для множества последовательных пикселов. В одном из вариантов осуществления каждая «порция» упакованных данных содержит восемь элементов данных. На этапе 2224 при необходимости для получения «порции» правильных данных выполняется операция объединения со сдвигом вправо с «порциями» данных. Для приведенного выше варианта осуществления, когда вместе обрабатываются четыре предыдущих макроблока, могут выполняться операции объединения со сдвигом вправо для «порций» данных, которые соответствуют строкам, расположенным в каждом макроблоке. «Порция» данных для каждого смежного макроблока, который находится на одну позицию пиксела дальше, также сдвигается на одну порцию дальше, причем представляется, что макроблоки скользят по окну поиска на один пиксел в каждый данный момент времени для каждой строки пикселов в окне поиска. На этапах 2226, 2228, 2230 и 2232 операции применяются к каждому из четырех обрабатываемых вместе предыдущих макроблоков. Для одного из вариантов осуществления все четыре макроблока подвергают той же самой операции, прежде чем возникнет следующая операция. Для другого варианта осуществления все операции с одним предыдущим макроблоком могут быть завершены прежде, чем будет обрабатываться следующий предыдущий макроблок с «порцией» данных, которая включает в себя соответственным образом сдвинутые сегменты данных. На этапе 2226 для каждой строки макроблоков рассчитывается сумма абсолютных разностей между соответствующими строками предыдущего макроблока и текущего макроблока. На этапе 2228 накапливается (суммируется нарастающим итогом) сумма абсолютных разностей для всех строк предыдущего макроблока. На этапе 2230 накопленное значение разностей для предыдущего макроблока сравнивается с текущим минимальным значением. Если на этапе 2232 определено, что значение разностей для данного предыдущего макроблока меньше текущего минимального значения, то минимальное значение обновляют этим новым значением разностей. Индекс обновляется, чтобы он отражал местоположение этого предыдущего макроблока для указания, что этот предыдущий макроблок пока имеет самое близкое соответствие. Но если на этапе 2232 определено, что новое значение разностей больше текущего минимального значения, то этот предыдущий блок не имеет более близкого соответствия, чем те, которые уже были сравнены. Варианты осуществления алгоритмов оценки движения в соответствии с настоящим изобретением могут также улучшить производительность процессора и системы с существующими аппаратными ресурсами. Но поскольку технология продолжает улучшаться, варианты осуществления настоящего изобретения при объединении с большим количеством аппаратных ресурсов и более быстрыми, более эффективными логическими схемами могут иметь даже более глубокое воздействие на повышение производительности. Таким образом один эффективный вариант осуществления оценки движения может иметь различное и большее воздействие, чем появление нового поколения процессора. Простое добавление большего количества ресурсов в современной архитектуре процессора не гарантирует улучшения производительности. Но если также поддерживать эффективность приложений, например, как в одном из вариантов осуществления оценки движения и команды объединения со сдвигом вправо (PSRMRG), возможно большее повышение производительности. Хотя вышеприведенные примеры в общем случае описываются в контексте аппаратных средств/регистров/операндов длиной 64 бита для упрощения обсуждения, другие варианты осуществления используют аппаратные средства/регистры/операнды длиной 128 битов для выполнения операций объединения регистров, операций объединения со сдвигом вправо и вычисления оценки движения. Кроме того, варианты осуществления настоящего изобретения не ограничены определенными аппаратными средствами или типами технологии, например технологиями MMX/SSE/SSE2, и они могут использоваться с другим воплощениями SIMD и другими технологиями обработки графических данных. Хотя варианты осуществления оценки движения и сравнения блоков, которые описаны выше для фиг.20 – 23B, описаны в контексте строк длиной восемь пикселов или восемь элементов данных и макроблоков размером восемь строк на восемь столбцов, другие варианты осуществления включают в себя другие размеры. Например, строки могут иметь длину шестнадцать пикселов, или шестнадцать элементов данных, а макроблоки могут иметь размер шестнадцать строк на шестнадцать столбцов. В предшествующем описании изобретение было описано со ссылкой на определенные примерные варианты его осуществления, однако, будет очевидно, что различные модификации и изменения могут быть сделаны без отклонения от более широкого объема и сущности изобретения, как установлено в формуле изобретения. Соответственно, описание и чертежи должны рассматриваться в иллюстративном, а не ограничительном смысле.
Формула изобретения
1. Способ параллельного объединения данных со сдвигом вправо, содержащий этапы, на которых принимают команду объединения со сдвигом вправо, содержащую отсчет сдвига на М, сдвигают первый операнд из первого регистра-источника, определяемого командой объединения со сдвигом вправо, причем первый операнд имеет первый набор из L элементов данных, влево на ‘L – М’ элементов данных, параллельно со сдвигом первого операнда сдвигают вправо второй операнд из вторичного блока хранения данных, определяемого командой объединения со сдвигом вправо, причем второй операнд имеет второй набор из L элементов данных, вправо на М элементов данных, объединяют упомянутый сдвинутый первый набор с упомянутым сдвинутым вторым набором для получения результата, имеющего L элементов данных. 2. Способ по п.1, отличающийся тем, что упомянутый сдвиг первого операнда формирует упомянутый сдвинутый первый набор, содержащий М элементов данных, выровненных по левому краю первого операнда. 3. Способ по п.2, отличающийся тем, что упомянутый сдвиг влево удаляет ‘L – М’ элементов данных из первого операнда, причем нули вводят с правого края первого операнда для заполнения пространства, освобожденного ‘L – М’ элементами данных, которые сдвинуты. 4. Способ по п.3, отличающийся тем, что упомянутый сдвиг второго операнда формирует упомянутый сдвинутый второй набор, содержащий ‘L – М’ элементов данных, выровненных по правому краю второго операнда. 5. Способ по п.4, отличающийся тем, что упомянутый сдвиг вправо удаляет М элементов данных из второго операнда, при этом нули вводят с левого края второго операнда для заполнения пространства, освобожденного сдвинутыми М элементами данных. 6. Способ по п.5, отличающийся тем, что упомянутое объединение включает выполнение операции Логическое ИЛИ с упомянутым сдвинутым первым набором и упомянутым сдвинутым вторым набором. 7. Способ по п.6, отличающийся тем, что упомянутый результат состоит из М элементов данных упомянутого сдвинутого первого набора и ‘L – М’ элементов данных упомянутого сдвинутого второго набора, при этом М элементов данных сдвинутого первого набора не пересекаются с ‘L – М’ элементами данных сдвинутого второго набора. 8. Способ по п.7, отличающийся тем, что первый операнд, второй операнд и результат являются операндами упакованных данных. 9. Способ по п.8, отличающийся тем, что каждый элемент данных является байтом данных. 10. Способ по п.9, отличающийся тем, что значение L равно 8. 11. Способ по п.10, отличающийся тем, что М имеет значение в пределах от 0 до 15. 12. Способ по п.9, отличающийся тем, что значение L равно 16. 13. Способ по п.12, отличающийся тем, что М является числом в пределах от 0 до 31. 14. Способ параллельного объединения данных со сдвигом вправо, содержащий этапы, на которых принимают команду объединения со сдвигом вправо, определяющую отсчет, первый операнд данных из первого регистра-источника, включающий в себя первый набор элементов данных, и второй операнд данных из вторичного блока данных, включающий в себя второй набор элементов данных, сдвигают влево первый набор элементов данных до тех пор, пока количество элементов данных, которые остаются в первом операнде данных, не будет равно упомянутому отсчету, параллельно со сдвигом первого набора элементов данных сдвигают вправо второй набор элементов данных для того, чтобы удалить количество элементов данных, равное упомянутому отсчету, из упомянутого второго операнда данных, и объединяют вместе сдвинутый первый набор элементов данных со сдвинутым вторым набором элементов данных для получения результата, который включает в себя элементы данных первого операнда данных и второго операнда данных. 15. Способ по п.14, отличающийся тем, что упомянутый сдвиг влево первого набора элементов данных включает этапы, на которых удаляют элементы данных с левого края первого операнда данных и вводят нули с правого края первого операнда данных для заполнения позиций освобожденных удаленными элементами данных. 16. Способ по п.15, отличающийся тем, что сдвиг вправо второго набора элементов данных включает в себя этапы, на которых удаляют элементы данных с правого края второго операнда данных и вводят нули с левого края второго операнда для заполнения позиций, освобожденных удаленными элементами данных. 17. Способ по п.16, в котором объединение включает осуществление операции Логическое ИЛИ для сдвинутого первого набора элементов данных и сдвинутого второго набора элементов данных. 18. Способ по п.17, отличающийся тем, что первый операнд и второй операнд загружают данными из смежных ячеек памяти непрерывного блока данных, при этом первый набор элементов данных и второй набор элементов данных не перекрываются. 19. Способ параллельного объединения данных со сдвигом вправо, содержащий этапы, на которых принимают команду объединения со сдвигом и отсчет сдвига на М, сочленяют первый операнд из первого регистра-источника, определенного командой объединения со сдвигом, причем первый операнд имеет первый набор из L элементов данных со вторым операндом из вторичного блока хранения для ячейки памяти, определенной командой объединения со сдвигом, причем второй операнд имеет второй набор из L элементов данных для формирования блока элементов данных длиной 2L, сдвигают вправо упомянутый блок на М позиций, причем М самых правых элементов данных отбрасывают, и выводят L самых правых элементов данных из упомянутого сдвинутого блока как результат для команды объединения со сдвигом. 20. Способ по п.19, отличающийся тем, что упомянутый сдвиг вправо дополнительно включает ввод нулей с левого края упомянутого блока для заполнения пространства, освобожденного М элементами данных. 21. Способ по п.20, отличающийся тем, что первый операнд и второй операнд являются операндами упакованных данных. 22. Способ по п.21, отличающийся тем, что каждый элемент данных содержит один байт данных. 23. Способ по п.22, отличающийся тем, что значение L равно 8. 24. Способ по п.23, отличающийся тем, что М имеет значение в пределах от 0 до 15. 25. Способ по п.24, отличающийся тем, что упомянутый блок сохраняют во временном регистре упакованных данных, имеющем объем, достаточный для 2L элементов данных. 26. Устройство для параллельного объединения данных со сдвигом вправо, содержащее декодер для декодирования команды объединения со сдвигом вправо, планировщик для посылки упомянутой команды для выполнения с использованием первого регистра-источника, имеющего первый операнд, состоящий из первого набора из L элементов данных, вторичного блока хранения данных, имеющего второй операнд, состоящий из второго набора из L элементов данных, и отсчета сдвига на М, и модуль исполнения для исполнения упомянутой команды, причем модуль исполнения содержит логику сдвига влево для сдвига первого операнда влево на отсчет сдвига на ‘L-М’ элементов данных, логику сдвига вправо для сдвига второго операнда вправо на М элементов данных параллельно со сдвигом первого операнда, логику объединения для объединения сдвинутого первого операнда со сдвинутым вторым операндом для получения результата, имеющего L элементов данных. 27. Устройство по п.26, отличающееся тем, что команда объединения со сдвигом вправо состоит из одной микрокоманды (микрооперации). 28. Устройство по п.27, отличающееся тем, что сдвиг влево первого операнда обеспечивает получение сдвинутого первого набора данных, состоящего из М элементов данных, выровненных по левому краю первого операнда. 29. Устройство по п.28, отличающееся тем, что сдвиг влево удаляет ‘L – М’ элементов данных из первого операнда, причем нули вводятся с правого края первого операнда для заполнения пространства, освобожденного сдвинутыми ‘L-М’ элементами данных. 30. Устройство по п.29, отличающееся тем, что сдвиг вправо второго операнда формирует сдвинутый второй набор, содержащий ‘L – М’ элементов данных, выровненных по правому краю второго операнда. 31. Устройство по п.30, отличающееся тем, что сдвиг вправо удаляет М элементов данных из второго операнда, причем нули вводятся с левого края второго операнда для заполнения пространства, освобожденного сдвинутыми М элементами данных. 32. Устройство по п.31, отличающееся тем, что первый операнд, второй операнд и результат являются регистрами упакованных данных. 33. Устройство по п.32, отличающееся тем, что каждый элемент данных является байтом данных. 34. Устройство по п.33, отличающееся тем, что значение L равно 8. 35. Устройство по п.34, отличающееся тем, что М имеет значение в пределах от 0 до 15. 36. Устройство по п.35, отличающееся тем, что упомянутое устройство имеет 64-битную архитектуру. 37. Устройство по п.33, отличающееся тем, что значение L равно 16, М имеет значение в пределах от 0 до 31, а упомянутое устройство имеет 128-битную архитектуру. 38. Система параллельного объединения данных со сдвигом вправо, содержащая память для хранения данных и команд, процессор, присоединенный к памяти посредством шины, причем процессор имеет возможность выполнения операции объединения со сдвигом вправо, при этом процессор содержит шинный модуль для приема команды из памяти, декодер для декодирования команды для выполнения объединения со сдвигом вправо на значение отсчета сдвига М первого операнда из первого регистра-источника, имеющего первый набор из K элементов данных, и второго операнда из вторичного блока хранения данных, имеющего второй набор из L элементов данных, планировщик для посылки декодированной команды на исполнение и модуль исполнения для исполнения упомянутой команды, содержащий логику сдвига влево для сдвига первого операнда влево на отсчет сдвига на ‘K – М’ элементов данных, логику сдвига вправо для сдвига второго операнда вправо на отсчет сдвига на М элементов данных параллельно со сдвигом первого операнда, логику объединения для объединения сдвинутого первого операнда со сдвинутым вторым операндом для получения результата, имеющего K элементов данных. 39. Система по п.38, отличающаяся тем, что значение K равно значению L, и оба они (и K, и L) равны 8. 40. Система по п.38, отличающаяся тем, что упомянутый сдвиг влево удаляет ‘K – М’ элементов данных из первого операнда, причем нули вводятся с правого края первого операнда для заполнения пространства, освобожденного сдвинутыми ‘K – М’ элементами данных, и упомянутый сдвиг вправо удаляет М элементов данных из второго операнда, причем нули вводятся с левого края второго операнда для заполнения пространства, освобожденного сдвинутыми М элементами данных. 41. Система по п.38, отличающаяся тем, что каждый элемент данных содержит один байт данных, а первый операнд и второй операнд являются операндами упакованных данных. 42. Машиночитаемый носитель, имеющий воплощенную на нем компьютерную программу, причем компьютерная программа выполняется компьютером для выполнения способа, включающего в себя этапы приема первой команды и отсчета сдвига на М, сдвига в ответ на первую команду первого операнда из первого регистра-источника, имеющего первый набор из L элементов данных, влево отсчет сдвига на ‘L – М’ элементов данных, сдвига параллельно и в ответ на первую команду второго операнда из вторичного блока хранения данных, имеющего второй набор из L элементов данных, на М элементов данных, объединение в ответ на первую команду сдвинутого первого набора со сдвинутым вторым набором для получения результата, имеющего L элементов данных. 43. Машиночитаемый носитель по п.42, в котором упомянутый сдвиг влево удаляет ‘L – М’ элементов данных из первого операнда, при этом вводятся нули с правого края первого операнда для заполнения пространства, освобожденного упомянутыми сдвинутыми ‘L – M’ элементами данных, упомянутый сдвиг вправо удаляет М элементов данных из второго операнда, при этом вводятся нули с левого края второго операнда для заполнения пространства, освобожденного упомянутыми сдвинутыми М элементами данных, и упомянутое объединение включает в себя выполнение операции Логическое ИЛИ для упомянутого сдвинутого первого набора и упомянутого сдвинутого второго набора. 44. Машиночитаемый носитель по п.43, в котором первый операнд, второй операнд и результат являются операндами упакованных данных.
РИСУНКИ
|
||||||||||||||||||||||||||
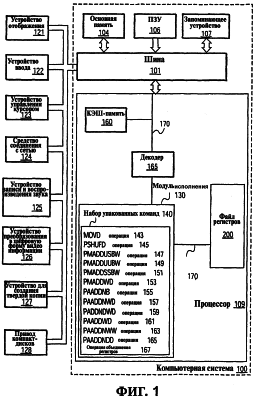
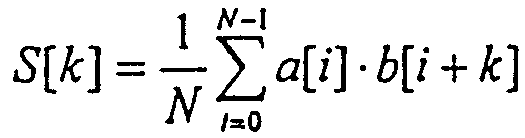
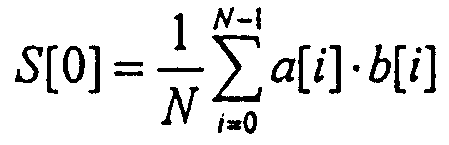
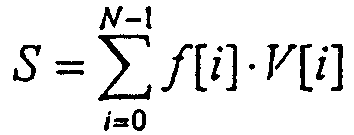
 и Альфа
и Альфа